Korte samenvatting: Het verzamelen van AI-data is het systematische proces van het verzamelen, voorbereiden en beheren van datasets om kunstmatige intelligentiemodellen te trainen en te valideren. Succes vereist een evenwicht tussen datakwaliteit, diversiteit, privacybescherming en ethische overwegingen, terwijl tegelijkertijd de juiste governancekaders worden geïmplementeerd. Organisaties die realtime, hoogwaardige dataverzameling beheersen – in combinatie met verantwoorde AI-praktijken – positioneren zichzelf voor de ontwikkeling van nauwkeurigere, eerlijkere en betrouwbaardere AI-systemen.
Kunstmatige intelligentiesystemen slagen of falen met de data die ze verwerken. Elk antwoord van een chatbot, elke gezichtsherkenning, elke voorspellende aanbeveling is terug te voeren op één fundamenteel ingrediënt: data.
Zonder hoogwaardige, correct verzamelde data leveren zelfs de meest geavanceerde algoritmen onbetrouwbare resultaten op. Experts benadrukken dat bij een AI-model geldt: 'garbage in, garbage out'.
De uitdaging? Dataverzameling voor AI draait niet alleen om het vergaren van grote hoeveelheden informatie. Het vereist strategische planning, ethische overwegingen, naleving van regelgeving en continue kwaliteitscontrole.
Deze handleiding doorloopt de volledige levenscyclus van gegevensverzameling: van het begrijpen van kernconcepten tot het implementeren van verzamelmethoden, het waarborgen van kwaliteit, het navigeren door privacyregelgeving en het toepassen van best practices die aansluiten bij de normen van 2026.
Wat is AI-dataverzameling?
Het verzamelen van AI-gegevens omvat de methoden, processen en technologieën die worden gebruikt om informatie te verzamelen waarmee machine learning-modellen worden getraind, getest en gevalideerd. Deze gegevens vormen de basis waarop algoritmen patronen leren, voorspellingen doen en resultaten genereren.
In tegenstelling tot traditionele dataverzameling voor analyses of rapportages, dient AI-gerichte dataverzameling een specifiek doel: het creëren van datasets die het probleemgebied voldoende volledig weergeven, zodat een model kan generaliseren van voorbeelden naar nieuwe, onbekende scenario's.
Het proces omvat verschillende afzonderlijke fasen. Eerst komt de identificatie: bepalen welke gegevens het model nodig heeft op basis van het probleemgebied. Vervolgens is er de acquisitie, waarbij ruwe data uit verschillende bronnen worden verzameld. Daarna volgt de voorbereiding en annotatie, waarbij de ruwe data worden omgezet in gestructureerde, gelabelde formaten die algoritmen kunnen verwerken. Ten slotte zorgt de validatie ervoor dat de dataset voldoet aan de kwaliteits- en representativiteitsnormen.
Soorten gegevens voor AI-systemen
Verschillende AI-toepassingen vereisen fundamenteel verschillende gegevenstypen:
- Gestructureerde gegevensGeorganiseerde informatie in databases, spreadsheets of tabellen met duidelijk gedefinieerde velden, zoals klantgegevens, transactielogboeken en sensorwaarden.
- Ongestructureerde gegevens: Tekstdocumenten, e-mails, berichten op sociale media, audio-opnames, videobestanden die niet vooraf georganiseerd zijn.
- BeeldgegevensFoto's, medische scans, satellietbeelden en productafbeeldingen worden gebruikt voor computervisie-taken.
- TijdreeksgegevensSequentiële metingen in de tijd: aandelenkoersen, weerpatronen, IoT-sensorstromen.
- GedragsgegevensGebruikersinteracties, klikgedrag, navigatiepatronen, betrokkenheidsstatistieken.
Elk type vereist specifieke methoden voor het verzamelen van gegevens, annotatiestandaarden en een eigen opslaginfrastructuur.

Maak je data klaar voor AI met AI Superior
AI Superieur Ze helpen bedrijven bij het definiëren van AI-mogelijkheden, het beoordelen van beschikbare datasets en het controleren of machine learning geschikt is voordat de ontwikkeling begint. Hun proces omvat ontdekking, data-analyse, MVP-ontwikkeling, schaalvergroting, integratie en resultaatsevaluatie.
Voor het verzamelen van AI-data kan dit teams helpen te begrijpen welke data ze hebben, welke data er nog ontbreekt en hoe ze deze kunnen voorbereiden voor een praktisch AI-systeem.
Heeft u hulp nodig bij het beoordelen van uw AI-gegevens?
AI Superior kan u helpen met:
- het beoordelen van beschikbare datasets
- het definiëren van toepassingsgevallen voor AI en machine learning
- planning van PoC- of MVP-ontwikkeling
- Werkprocessen voorbereiden voor AI-integratie
👉 Neem contact op met AI Superior om uw project te bespreken.
Waarom dataverzameling cruciaal is voor het succes van AI
De kwaliteit en kenmerken van de trainingsdata bepalen direct de prestaties van het model. Verschillende factoren maken dataverzameling tot de spil van de AI-ontwikkeling:
- De nauwkeurigheid van een model hangt af van de representativiteit van de data. Als de trainingsdata niet de volledige diversiteit van scenario's uit de praktijk weergeven, ontwikkelt het model blinde vlekken. Een AI die voornamelijk is getraind op data van één demografische groep, zal minder goed presteren wanneer deze met andere groepen te maken krijgt.
- Vooroordelen ontstaan door keuzes bij het verzamelen van gegevens. Systematische hiaten of oververtegenwoordiging in datasets creëren vertekende modellen die bestaande ongelijkheden in stand houden of versterken. De Federal Trade Commission heeft handhavingsmaatregelen genomen tegen bedrijven die misleidende beweringen doen over AI, waaronder gevallen waarin ontoereikende gegevens leidden tot misleidende prestatiebeloftes.
- Continue verbetering vereist actuele data. AI-modellen die getraind zijn op statische datasets raken verouderd naarmate de omstandigheden in de praktijk veranderen. Mechanismen voor realtime dataverzameling zorgen ervoor dat modellen actueel blijven en inspelen op nieuwe trends.
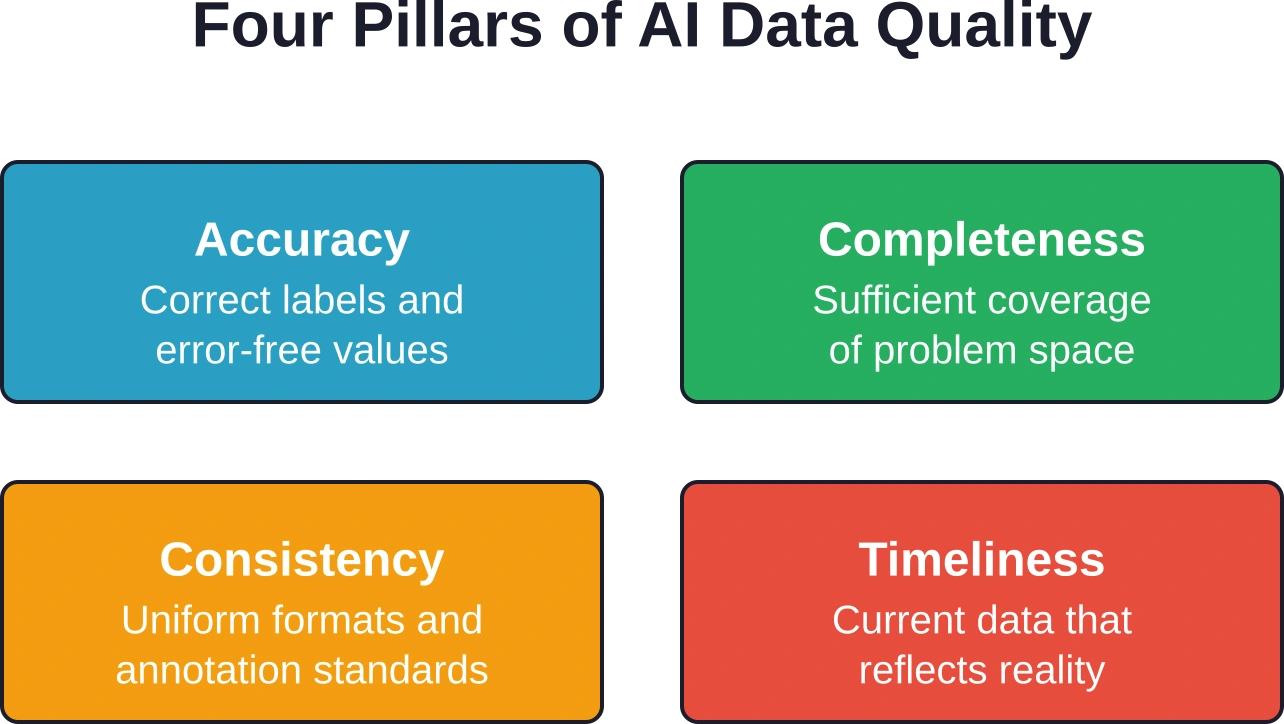
Kernmethoden voor gegevensverzameling voor AI
Organisaties hanteren verschillende dataverzamelingsstrategieën, afhankelijk van de datavereisten, de beschikbare middelen en de toepassingsgebieden.
Primaire gegevensverzameling
Primaire dataverzameling houdt in dat er specifiek voor het betreffende AI-project nieuwe data worden gegenereerd. Deze aanpak biedt maximale controle over de kwaliteit en relevantie, maar vergt doorgaans meer tijd en middelen.
- Enquêtes en vragenlijsten verzamelen rechtstreeks informatie van de doelgroep op basis van zelfrapportage. Goed ontworpen enquêtes kunnen attitudes, voorkeuren en gedragingen vastleggen die met andere methoden niet aan het licht komen. De grootste uitdaging ligt in het ontwerpen van vragen die accurate, onbevooroordeelde antwoorden opleveren en in het bereiken van een representatieve steekproef.
- Sensor- en IoT-datastromen leveren continue, realtime metingen van fysieke omgevingen. Productiebedrijven zetten sensoren in om prestatiegegevens van apparatuur te verzamelen. Slimme steden verzamelen gegevens over verkeer, luchtkwaliteit en infrastructuur. Deze datastromen genereren enorme hoeveelheden data die robuuste verwerkingssystemen en opslaginfrastructuur vereisen.
- Gecontroleerde experimenten variëren systematisch de omstandigheden om gegevens te verzamelen onder bekende parameters. Deze aanpak werkt bijzonder goed voor het trainen van modellen waarbij de werkelijke situatie nauwkeurig moet worden gedefinieerd, zoals bij A/B-testen van interfaces, klinische studies of laboratoriummetingen.
- Het vastleggen van gebruikersinteracties registreert hoe mensen met systemen omgaan: klikken, navigatiepaden, zoekopdrachten, tijd doorgebracht op pagina's. Deze gedragsgegevens onthullen patronen die vaak verborgen blijven in uitgesproken voorkeuren. Privacyoverwegingen zijn van cruciaal belang bij het verzamelen van interactiegegevens, wat duidelijke toestemmingsmechanismen en zorgvuldige anonimisering vereist.
Secundaire gegevensverzameling
Secundaire dataverzameling maakt gebruik van bestaande datasets die voor andere doeleinden zijn aangemaakt. Deze aanpak versnelt projecttijdlijnen en verlaagt de kosten, maar biedt minder controle over de data-eigenschappen.
- Openbare datasets en repositories bieden vooraf verzamelde, vaak van annotaties voorziene data voor veelvoorkomende AI-taken. Overheidsinstanties, onderzoeksinstellingen en brancheorganisaties beheren repositories die domeinen bestrijken van natuurlijke taalverwerking tot medische beeldvorming. Organisaties zoals het National Institute of Standards and Technology (NIST) bieden gestandaardiseerde datasets die de ontwikkeling van AI ondersteunen en tegelijkertijd prestatievergelijkingen tussen systemen mogelijk maken.
- Web scraping extraheert automatisch informatie van websites en online platforms. Deze techniek kan snel grote hoeveelheden tekst, productinformatie of content van sociale media verzamelen. Juridische en ethische overwegingen spelen echter een belangrijke rol: de gebruiksvoorwaarden van websites, auteursrechten en privacywetgeving leggen beperkingen op aan wat er gescrapet mag worden en hoe die gegevens gebruikt mogen worden.
- Externe data-aanbieders zijn gespecialiseerd in het verzamelen, beheren en licentiëren van datasets voor commercieel gebruik. Deze leveranciers bieden toegang tot eigen datasets uit diverse sectoren, zoals consumentengedrag, financiële markten en medische dossiers. Zorgvuldig onderzoek is essentieel om de herkomst van de gegevens, de verzamelmethoden en de naleving van de geldende regelgeving te verifiëren.
- Interne organisatiedata vormen mogelijk de meest waardevolle secundaire bron: klantdatabases, transactiegeschiedenissen, operationele logboeken en supporttickets. Deze data weerspiegelen direct de contexten waarin AI zal opereren, hoewel ze vaak aanzienlijke opschoning en herstructurering vereisen voordat ze gebruikt kunnen worden voor modeltraining.
Generatie van synthetische gegevens
Het creëren van synthetische data maakt gebruik van algoritmen om kunstmatige datasets te genereren die de dataverdeling in de echte wereld nabootsen, zonder daadwerkelijk individuele records te bevatten. Deze aanpak biedt een oplossing voor privacyproblemen, dataschaarste voor zeldzame scenario's en de behoefte aan perfect gebalanceerde trainingssets.
Generatieve modellen kunnen realistische afbeeldingen, tekst of numerieke gegevens creëren op basis van patronen die zijn geleerd uit kleinere, reële datasets. Simulatieomgevingen genereren trainingsgegevens voor autonome systemen: zelfrijdende auto's die in virtuele omgevingen worden getraind voordat ze in de echte wereld worden ingezet, en robots die manipulatietaken leren in fysica-simulatoren.
Het nadeel? Synthetische data leggen mogelijk niet alle complexiteit en uitzonderingen uit de realiteit vast. Modellen die puur op synthetische data zijn getraind, hebben soms moeite met de rommeligheid van de echte wereld. De beste werkwijze combineert vaak synthetische data voor de initiële training en uitbreiding met echte data voor verfijning en validatie.
Hulpmiddelen en platforms voor gegevensverzameling
Het technologische landschap biedt tal van instrumenten die inspelen op verschillende behoeften op het gebied van gegevensverzameling:
| Gereedschapscategorie | Belangrijkste gebruiksscenario's | Belangrijkste competenties |
|---|---|---|
| Data-integratieplatformen | Gegevens uit meerdere bronnen samenvoegen | API-connectoren, ETL-pipelines, realtime streaming, datatransformatie |
| Annotatietools | Labelen van afbeeldingen, tekst en video voor begeleid leren | Samenwerking bij het labelen, kwaliteitscontroleprocessen en actieve leerintegratie |
| Web scraping frameworks | Gegevens extraheren van websites | HTML-parsing, JavaScript-rendering, anti-blokkeringsmechanismen, planning |
| Enquêteplatforms | Het verzamelen van antwoorden op de vragenlijst | Formulierbouwers, logische vertakkingen, responsanalyse, paneelbeheer |
| Datawarehouses | Gecentraliseerde opslag en beheer | Schaalbare opslag, SQL-query's, toegangscontrole, versiebeheer |
| Kenmerkende winkels | Het beheren van ML-functies in verschillende pipelines. | Functieversiebeheer, serverinfrastructuur, monitoring, hergebruik in verschillende modellen |
De platformkeuze hangt af van technische vereisten, de bestaande infrastructuur, de expertise van het team en budgettaire beperkingen. Organisaties combineren vaak meerdere tools tot geïntegreerde dataverzamelingsarchitecturen in plaats van te vertrouwen op afzonderlijke oplossingen.
Het waarborgen van datakwaliteit en -validatie
Het verzamelen van data is slechts de eerste stap. Ruwe data bevat onvermijdelijk fouten, inconsistenties en hiaten die de modeltraining ondermijnen. Systematische kwaliteitsborging transformeert de verzamelde data in betrouwbare trainingsgegevens.
Gegevens opschonen en voorbewerken
Door middel van opschonen worden problematische gegevens verwijderd of gecorrigeerd voordat ze de trainingssets vervuilen:
- Dubbele records worden gedetecteerd en verwijderd, waardoor bepaalde patronen tijdens de training onevenredig zwaar zouden wegen.
- Het afhandelen van ontbrekende waarden pakt onvolledige records aan door ze te verwijderen, aan te vullen of te markeren, afhankelijk van de omvang en het patroon van de ontbrekende waarden.
- Uitschieteranalyse onderscheidt echte uitzonderlijke gevallen die het waard zijn om te behouden van invoerfouten of sensorstoringen die verwijdering vereisen.
- Formaatstandaardisatie zorgt voor consistentie in eenheden, datumformaten, tekstcodering en categorische waarden in de gehele dataset.
- Ruisonderdrukking filtert meetfouten en willekeurige variaties die ware patronen verbergen, zonder legitieme variabiliteit te verwijderen.
Voorverwerking transformeert de opgeschoonde data naar formaten die geoptimaliseerd zijn voor gebruik door het model: normalisatie, feature engineering, dimensionaliteitsreductie en tokenisatie.
Validatie- en testprotocollen
Validatie bevestigt dat de verzamelde gegevens daadwerkelijk het beoogde doel dienen. Verschillende complementaire benaderingen bieden die zekerheid:
- Statistische profilering onderzoekt verdelingen, correlaties en samenvattende statistieken om onverwachte patronen te detecteren die wijzen op problemen met de monsterneming. Door profielen van nieuwe batches te vergelijken met vastgestelde basislijnen worden potentiële problemen aan het licht gebracht.
- Schemavalidatie verifieert of de gegevens voldoen aan de verwachte structuren: of de vereiste velden aanwezig zijn, de gegevenstypen correct zijn, de waarden binnen acceptabele bereiken liggen en de referentiële integriteit behouden blijft.
- Steekproefaudits omvatten handmatige inspectie van willekeurige subsets om fouten op te sporen die geautomatiseerde controles missen. Menselijke beoordelaars evalueren de kwaliteit van de annotaties, identificeren ambigue gevallen en brengen systematische problemen aan het licht.
- Holdout-testenG Een deel van de verzamelde data wordt uitsluitend gereserveerd voor modelvalidatie. Deze testsets bieden onbevooroordeelde prestatieschattingen, omdat modellen deze data nooit te zien krijgen tijdens de training. Door een strikte scheiding tussen trainings- en testdata wordt overfitting voorkomen en wordt ervoor gezorgd dat modellen daadwerkelijk generaliseren.
Privacy, naleving en ethische overwegingen
Het verzamelen van data voor AI vindt plaats binnen complexe, steeds strengere regelgeving en ethische kaders. Organisaties die niet aan deze eisen voldoen, lopen het risico op juridische consequenties, reputatieschade en verlies van publiek vertrouwen.
Regelgevingskaders en nalevingsnormen
Organisaties die data verzamelen, verwerken of opslaan voor AI-doeleinden, moeten zich houden aan regels die verschillen per land, sector en datatype.
NIST heeft richtlijnen voor AI ontwikkeld die zich richten op betrouwbaarheid, transparantie en risicobeheer, waaronder het AI Risk Management Framework en lopende standaardiseringswerkzaamheden. De FTC heeft ook meer aandacht besteed aan de omgang met AI-data, met name op het gebied van transparantie, toestemming, verantwoording en het gebruik van klantgegevens voor het trainen van modellen.
Brancheregels voegen daar nog een extra laag aan toe. Gezondheidsgegevens vallen mogelijk onder HIPAA, financiële gegevens onder consumentenbeschermings- en beveiligingsregelgeving en onderwijsgegevens onder FERPA. Bedrijven die internationaal actief zijn, moeten bovendien rekening houden met de AVG in Europa en andere opkomende kaders voor gegevensbeheer wereldwijd.
Vereisten inzake toestemming en transparantie
Betekenisvolle toestemming vormt de ethische basis voor verantwoorde gegevensverzameling. Verschillende principes vormen de leidraad voor toestemmingsprocedures:
- Geïnformeerde toestemming vereist een duidelijke uitleg over welke gegevens worden verzameld, hoe ze worden gebruikt, wie er toegang toe krijgt en hoe lang ze worden bewaard. Technisch jargon en juridische complexiteit mogen deze basisprincipes niet verhullen; de uitleg moet begrijpelijk zijn voor de gemiddelde gebruiker.
- Een specifieke doelbeperking betekent dat gegevens alleen worden verzameld voor expliciet vermelde doeleinden en niet zonder aanvullende toestemming worden hergebruikt voor ongerelateerde AI-projecten. De verleiding om extra waarde uit de verzamelde gegevens te halen, moet worden afgewogen tegen de grenzen van de toestemming.
- Opt-in- en opt-out-architecturen hebben verschillende ethische implicaties. Opt-in-benaderingen – waarbij actieve toestemming vereist is vóór het verzamelen van gegevens – respecteren de autonomie meer dan opt-out-systemen die standaard gegevens verzamelen, tenzij gebruikers actie ondernemen om dit te voorkomen.
- Herroepbare toestemming stelt individuen in staat hun toestemming in te trekken en te verzoeken om verwijdering van gegevens. Systemen moeten eenvoudige mechanismen bieden voor het intrekken van toestemming, in plaats van obstakels te creëren die het uitoefenen van dit recht ontmoedigen.
Vooroordelen tegengaan en eerlijkheid
De keuzes die gemaakt worden bij het verzamelen van data hebben een directe invloed op de vraag of AI-systemen maatschappelijke vooroordelen in stand houden of juist verminderen. Verschillende strategieën dragen bij aan het bevorderen van eerlijkheid:
- Representatieve steekproeven zorgen ervoor dat de trainingsdata een adequate vertegenwoordiging bevatten van relevante demografische groepen, geografische regio's en gebruikssituaties. Gemakkelijkheidssteekproeven, waarbij gemakkelijk toegankelijke populaties oververtegenwoordigd zijn, introduceren vertekening.
- Bij een bias-audit worden verzamelde datasets onderzocht op systematische hiaten of vertekeningen voordat de training begint. Statistische analyse kan onevenwichtigheden aan het licht brengen die gecorrigeerd moeten worden door middel van aanvullende, gerichte dataverzameling of herwegingsstrategieën.
- Bij inclusieve dataverzameling worden actief perspectieven en voorbeelden gezocht van gemarginaliseerde of ondervertegenwoordigde groepen, in plaats van genoegen te nemen met de gegevens die het gemakkelijkst te verkrijgen zijn.
- Metrieken voor eerlijkheid kwantificeren of datasets en de daaruit voortvloeiende modellen verschillende groepen op gelijke wijze behandelen op gebieden zoals nauwkeurigheid, vals-positieve percentages en vals-negatieve percentages. Deze metrieken vormen een leidraad bij beslissingen over de vraag of aanvullende gegevensverzameling nodig is om ongelijkheden aan te pakken.
Richtlijnen voor academisch en onderzoekswerk
Onderzoeksinstellingen hebben specifieke richtlijnen ontwikkeld voor het verantwoord verzamelen van AI-gegevens in academische contexten. De 'Considerations for the Responsible and Ethical Use of AI' van Virginia Tech, gepubliceerd in november 2025 en herzien in februari 2026, vertaalt het 'Responsible and Ethical AI Framework' (2025) van de universiteit naar praktische stappen in de onderzoekslevenscyclus.
Deze richtlijnen benadrukken dat onderzoekers geen vertrouwelijke of bedrijfseigen informatie – waaronder subsidieaanvragen, niet-gepubliceerde gegevens of uitvindingen – mogen invoeren in AI-tools die niet door de instelling zijn goedgekeurd. Het kader behandelt de herkomst van gegevens, correcte bronvermelding en het waarborgen van de onderzoeksintegriteit bij het gebruik van AI voor gegevensverzameling en -analyse.
Northeastern University en het University of Illinois System hebben eveneens standaarden gepubliceerd voor het gebruik van AI in onderzoek, waarbij de nadruk ligt op principes van verantwoord gedrag, waaronder eerlijkheid, nauwkeurigheid, efficiëntie en objectiviteit.
Uitdagingen bij het verzamelen van gegevens in de praktijk
Theorie en praktijk lopen uiteen wanneer organisaties dataverzameling op grote schaal proberen te implementeren. Er doen zich daarbij verschillende terugkerende uitdagingen voor:
Volume- en snelheidsbeheer
Moderne AI-toepassingen vereisen vaak enorme datasets. Computervisiemodellen worden getraind op miljoenen afbeeldingen. Grote taalmodellen verwerken miljarden teksttokens. Tijdreeksmodellen voor anomaliedetectie verwerken continue sensorstromen.
De infrastructuur die nodig is om deze hoeveelheden data te verwerken, opslaan en verwerken, legt een enorme druk op budgetten en technische mogelijkheden. Streaming data-pipelines moeten duizenden of miljoenen gebeurtenissen per seconde verwerken zonder dataverlies. Opslagsystemen moeten een balans vinden tussen toegangssnelheid, redundantie en kosten voor petabytes aan informatie.
Maar wacht even: meer data betekent niet automatisch betere modellen. Boven bepaalde drempels levert een groter volume steeds minder op, tenzij het daadwerkelijk nieuwe informatie oplevert. Strategische dataverzameling, waarbij diversiteit en kwaliteit boven pure kwantiteit gaan, levert vaak betere resultaten op met minder benodigde middelen.
Kn knelpunten bij het labelen van gegevens
Begeleid leren – nog steeds het dominante AI-paradigma – vereist gelabelde trainingsvoorbeelden. Mensen moeten afbeeldingen annoteren, audio transcriberen, tekst classificeren of objecten markeren. Dit annotatiewerk vormt vaak de beperkende factor in veel AI-projecten.
De kosten voor het labelen van gegevens schalen lineair met de omvang van de dataset, wat budgettaire druk uitoefent. Kwaliteitscontrole voegt complexiteit toe: meerdere annotatoren moeten subsets labelen om overeenstemming te meten, en meningsverschillen vereisen oplossingsprocessen. Vereisten op het gebied van domeinexpertise beperken bovendien het aantal annotatoren voor gespecialiseerde toepassingen.
Verschillende strategieën helpen bij het aanpakken van knelpunten in de etikettering:
- Bij actief leren identificeren modellen de meest informatieve voorbeelden voor handmatige annotatie, waardoor de totale behoefte aan annotaties afneemt.
- Semi-supervised learning maakt gebruik van grote, niet-gelabelde datasets in combinatie met kleinere, gelabelde datasets, om zo uit beide datasets signalen te extraheren.
- Crowdsourcingplatforms verdelen de taken voor het labelen van documenten over grote groepen annotatoren, waardoor de doorvoer wordt versneld, maar dit brengt wel uitdagingen met zich mee op het gebied van kwaliteitsbeheer.
- Transfer learning maakt gebruik van modellen die vooraf getraind zijn op algemene datasets, waardoor er minder gelabelde data nodig is voor specialisatie op specifieke taken.
Data-drift en concept-drift
De werkelijkheid verandert in de loop der tijd. Klantvoorkeuren verschuiven. Marktomstandigheden evolueren. Tegenstanders passen hun tactieken aan. Productcatalogi worden bijgewerkt. Wettelijke voorschriften veranderen.
Modellen die getraind zijn op historische data verliezen geleidelijk aan relevantie naarmate de verdelingen die ze hebben geleerd, verder afwijken van de huidige realiteit. De prestaties verslechteren ongemerkt, tenzij monitoringsystemen de afwijking detecteren.
Om drift tegen te gaan, is continue dataverzameling nodig die de huidige omstandigheden vastlegt, monitoringsystemen die prestatievermindering signaleren en hertrainingsprocessen die modellen bijwerken met nieuwe data. De frequentie hangt af van hoe snel het domein evolueert: sommige toepassingen vereisen dagelijkse updates, andere blijven maandenlang stabiel.
Afweging tussen privacy en nut
Sterke privacybescherming die de persoonlijke vertrouwelijkheid waarborgt, kan soms botsen met het nut van data voor modeltraining. Technieken zoals differentiële privacy voegen wiskundige ruis toe die individuen beschermt, maar het beschikbare signaal voor training vermindert.
Aggregatie en anonimisering bieden privacyvoordelen, maar elimineren gedetailleerde patronen die modellen zouden kunnen benutten. Het genereren van synthetische data waarborgt de privacy, maar legt mogelijk niet alle complexiteit van de werkelijkheid vast.
Organisaties moeten deze afwegingen maken op basis van toepassingsvereisten, risicotolerantie en wettelijke verplichtingen. Gebruiksscenario's waarbij de privacyrisico's hoog zijn, maar de gebruikseisen bescheiden, kunnen een agressievere bescherming vereisen. Toepassingen waarbij de prestaties van het model direct van invloed zijn op de veiligheid of kritieke functies, kunnen kleinere privacymarges binnen de wettelijke grenzen accepteren.
Beste werkwijzen voor het verzamelen van AI-gegevens in 2026
Succesvolle dataverzamelingsprogramma's integreren lessen die zijn geleerd uit vroege AI-implementaties en opkomende standaarden:
Stel kaders voor gegevensbeheer op.
Formele bestuursstructuren definiëren rollen, verantwoordelijkheden en processen rondom gegevensverzameling en -beheer. Belangrijke onderdelen zijn onder meer:
- Bij data stewardship wordt eigenaarschap en verantwoordelijkheid voor datakwaliteit, -beveiliging en -naleving toegewezen.
- Toegangsbeheer beperkt wie verschillende gegevenstypen kan bekijken, wijzigen of exporteren, op basis van rol en behoefte.
- Auditlogboeken registreren gegevenstoegang en -transformaties ter ondersteuning van nalevingscontroles en incidentonderzoek.
- Bewaarbeleid bepaalt hoe lang gegevens bewaard moeten worden en wanneer ze verwijderd moeten worden, waarbij het nut wordt afgewogen tegen de opslagkosten en privacyprincipes.
- Documentatiestandaarden vereisen metadata die de herkomst van de gegevens, de verzamelmethoden, de bekende beperkingen en het beoogde gebruik beschrijven.
Implementeer monitoring van de datakwaliteit.
Kwaliteitsborging mag geen eenmalige validatie bij het verzamelen van gegevens zijn. Continue monitoring detecteert kwaliteitsvermindering voordat deze de modellen beïnvloedt:
- Geautomatiseerde profilering genereert statistische samenvattingen van binnenkomende databatches en vergelijkt deze met basiswaarden.
- Anomaliedetectie signaleert ongebruikelijke patronen die kunnen duiden op problemen met de gegevensverzameling of wijzigingen in de bovenliggende processen.
- Volledigheidscontroles verifiëren dat de verwachte hoeveelheden gegevens op schema aankomen, zonder onverklaarbare hiaten.
- Het bewaken van de actualiteit van de gegevens zorgt ervoor dat datapijplijnen recente informatie leveren in plaats van verouderde momentopnamen.
Geef prioriteit aan realtime-gegevensverzamelingsmogelijkheden.
Batchverwerking van historische data is nuttig voor sommige toepassingen, maar veel moderne AI-toepassingen vereisen realtime respons. Streamingarchitecturen die data verwerken zodra deze binnenkomt, maken het volgende mogelijk:
- Directe modelupdates die de actuele omstandigheden weerspiegelen.
- Realtime personalisatie op basis van recent gedrag
- Fraudedetectiesystemen die bedreigingen opsporen voordat er schade ontstaat.
- Operationele monitoring die binnen enkele seconden waarschuwt bij afwijkingen.
Het opzetten van realtime dataverzameling vereist investeringen in streaminginfrastructuur, maar de concurrentievoordelen rechtvaardigen de kosten vaak in snel veranderende sectoren.
Ontwerp gericht op verklaarbaarheid en controleerbaarheid.
Wanneer AI-systemen beslissingen nemen die mensen raken – zoals kredietgoedkeuringen, medische diagnoses en aanbevelingen voor aanwerving – eisen belanghebbenden terecht uitleg. De methoden voor gegevensverzameling moeten die uitleg ondersteunen:
- Houd herkomstgegevens bij die de trainingsgegevens herleiden naar de oorspronkelijke bronnen.
- Documenteer gegevenstransformaties en voorverwerkingsstappen
- Bewaar metadata die context geven over waarom bepaalde gegevens wel of niet zijn opgenomen.
- Maak het mogelijk om de exacte datasets te reconstrueren die zijn gebruikt om de geïmplementeerde modellen te trainen.
Auditors, toezichthouders en onderzoekers moeten mogelijk jaren later de gegevensverzamelingspraktijken onderzoeken. Documentatie die op het moment zelf overdreven lijkt, blijkt vaak van onschatbare waarde tijdens onderzoeken.
Bevorder samenwerking tussen verschillende afdelingen.
Het verzamelen van data mag niet alleen aan data-engineeringteams worden overgelaten. Effectieve programma's omvatten:
- Domeinexperts die begrijpen welke data er echt toe doet en welke uitzonderlijke gevallen er bestaan.
- Datawetenschappers die de modelvereisten en voorkeuren voor dataformaten kennen.
- Juridische adviseurs die nalevingsverplichtingen en risicogebieden identificeren.
- Ethiekbeoordelaars die de eerlijkheid en maatschappelijke implicaties beoordelen.
- Beveiligingsteams die gegevens beschermen tegen ongeautoriseerde toegang of datalekken.
- Productmanagers die databehoeften koppelen aan bedrijfsdoelstellingen en gebruikerswaarde.
Regelmatige, multidisciplinaire evaluaties signaleren problemen die binnen afzonderlijke afdelingen onopgemerkt zouden blijven.
| Beste praktijk | Primair voordeel | Implementatiecomplexiteit |
|---|---|---|
| Data governance framework | Naleving en verantwoording | Gemiddeld – vereist beleidsontwikkeling en training. |
| Realtime verzamelpipelines | Actuele gegevens voor responsieve modellen | Investeringen in streaminginfrastructuur met hoge eisen |
| Geautomatiseerde kwaliteitsbewaking | Vroegtijdige probleemdetectie | Gemiddeld - vereist gereedschap en het vaststellen van een basislijn. |
| Uitgebreide documentatie | Controleerbaarheid en reproduceerbaarheid | Laag – voornamelijk procesdiscipline |
| Cross-functionele samenwerking | Holistische risicobeoordeling | Lage organisatorische coördinatie |
| Privacybehoudende technieken | Naleving van regelgeving en vertrouwen | Gemiddeld tot hoog – afhankelijk van de techniek |
Vooruitblik: Toekomstige trends in AI-gegevensverzameling
Een aantal opkomende trends zal de gegevensverzamelingspraktijken in de komende jaren beïnvloeden:
Gefedereerd leren en gedecentraliseerde verzameling
Traditionele benaderingen centraliseren data in repositories waar modellen worden getraind. Federated learning draait dit om: modellen gaan naar de locatie van de data, trainen lokaal en delen alleen de geleerde parameters in plaats van de ruwe data.
Deze architectuur pakt privacyproblemen aan door gevoelige gegevens binnen de grenzen van de organisatie of het apparaat te houden. Medische instellingen kunnen samenwerken aan modelontwikkeling zonder patiëntendossiers te delen. Mobiele apparaten kunnen de personalisatie verbeteren zonder gebruikersgedrag te uploaden.
Er blijven uitdagingen bestaan op het gebied van coördinatiecomplexiteit, communicatiekosten en het waarborgen van de veiligheid van het aggregatieproces. Maar de voordelen op het gebied van privacy maken federatieve benaderingen steeds aantrekkelijker naarmate de regelgeving strenger wordt.
Zelfgestuurde en niet-gestuurde methoden
Het verminderen van de afhankelijkheid van gelabelde data is een belangrijk onderzoeksgebied. Zelflerend leren genereert trainingssignalen uit de datastructuur zelf – bijvoorbeeld voor het voorspellen van gemaskeerde woorden in tekst, het reconstrueren van beschadigde afbeeldingen en het voorspellen van de volgende frames in videosequenties.
Deze benaderingen verlagen de labelkosten aanzienlijk en maken tegelijkertijd gebruik van enorme, ongelabelde datasets. Naarmate zelflerende technieken zich verder ontwikkelen, zal de nadruk bij dataverzameling verschuiven van uitputtende labeling naar het verzamelen van diverse ruwe data op grote schaal.
Multimodale data-integratie
Om de werkelijkheid te begrijpen, is het vaak nodig om informatie uit verschillende modaliteiten te combineren: beelden met bijschriften, video met audio, sensoraflezingen met contextuele metadata. Modellen die multimodale input verwerken, kunnen rijkere representaties ontwikkelen dan systemen die slechts één modaliteit gebruiken.
Verzamelstrategieën richten zich steeds meer op het verzamelen van op elkaar afgestemde multimodale datasets, waarbij verschillende gegevenstypen overeenkomen met dezelfde entiteiten of gebeurtenissen. De complexiteit van de infrastructuur neemt toe, maar de mogelijkheden van de modellen verbeteren navenant.
Continue leersystemen
Statische trainings- en implementatiecycli maken plaats voor continu leren, waarbij modellen voortdurend worden bijgewerkt naarmate er nieuwe gegevens binnenkomen. Deze aanpak zorgt ervoor dat modellen actueel blijven, maar brengt uitdagingen met zich mee op het gebied van stabiliteit, catastrofale vergeetachtigheid en kwaliteitscontrole.
Voor het verzamelen van data voor continu leren ligt de nadruk op het rechtstreeks invoeren van gegevens, snelle validatie en mechanismen om te detecteren wanneer nieuwe data de modelprestaties juist verslechteren in plaats van verbeteren.
Veelgestelde vragen
Wat is het verschil tussen dataverzameling voor AI en traditionele analyses?
Traditionele dataverzameling voor analyses richt zich op het vastleggen van informatie voor menselijke analyse, rapportage en business intelligence. Dataverzameling voor AI dient een ander doel: het creëren van trainingssets die algoritmen leren patronen te herkennen en voorspellingen te doen. AI-datasets vereisen andere kenmerken: grotere volumes, meer diverse voorbeelden die ook extreme gevallen omvatten, zorgvuldige labeling voor supervised learning en representativiteit over de gehele probleemruimte. Traditionele analyses accepteren mogelijk steekproeven die centrale tendensen vastleggen; AI-training vereist een uitgebreide dekking, inclusief zeldzame scenario's die het model zou kunnen tegenkomen.
Hoeveel data heb ik eigenlijk nodig om een AI-model te trainen?
Er bestaat geen universeel antwoord: de vereisten variëren sterk afhankelijk van de complexiteit van het probleem, de modelarchitectuur en de prestatiedoelen. Eenvoudige classificatietaken met duidelijke beslissingsgrenzen kunnen goede resultaten behalen met honderden gelabelde voorbeelden. Computervisiemodellen hebben doorgaans duizenden tot miljoenen afbeeldingen nodig. Grote taalmodellen trainen op miljarden teksttokens. Over het algemeen geldt dat complexere problemen met hogere-dimensionale invoerruimtes en meer genuanceerde beslissingsgrenzen grotere datasets vereisen. Transfer learning en voorgegetrainde modellen kunnen de databehoefte voor specifieke toepassingen drastisch verminderen door te leren van algemene datasets.
Wat zijn de grootste fouten die organisaties maken bij het verzamelen van AI-gegevens?
Veelvoorkomende valkuilen zijn onder andere: het prioriteren van kwantiteit boven kwaliteit en het verzamelen van enorme datasets zonder de nauwkeurigheid en relevantie te waarborgen; het negeren van diversiteit en het verzamelen van gegevens uit beperkte bronnen die niet het volledige probleemgebied vertegenwoordigen; het negeren van privacy- en compliance-vereisten totdat er juridische problemen ontstaan; het behandelen van dataverzameling als een eenmalig project in plaats van een continu proces; gebrekkige documentatie waardoor toekomstige teams de herkomst en beperkingen van de gegevens niet kunnen begrijpen; en ontoereikende validatie waardoor problematische gegevens in trainingspipelines terechtkomen. Organisaties onderschatten ook vaak de tijd en kosten die nodig zijn voor data-annotatie, wat leidt tot projectvertragingen wanneer annotatie een knelpunt wordt.
Kan ik gebruikmaken van openbaar beschikbare datasets of moet ik mijn eigen gegevens verzamelen?
Beide benaderingen hebben voordelen, afhankelijk van de omstandigheden. Openbare datasets bieden snellere projectstarts, lagere kosten en soms een betere kwaliteit dankzij gespecialiseerde curatie. Academische benchmarks maken prestatievergelijkingen mogelijk tussen verschillende modelleringsbenaderingen. Openbare data komen echter mogelijk niet overeen met de specifieke distributie, randgevallen of bedrijfseigen aspecten van een bepaald toepassingsgebied. Het verzamelen van data op maat levert data die precies op het probleem zijn afgestemd, maar vereist meer middelen en tijd. Veel succesvolle projecten combineren benaderingen: ze beginnen met openbare datasets voor de initiële ontwikkeling en voegen vervolgens bedrijfseigen data toe om modellen te specialiseren voor specifieke implementatiecontexten.
Hoe vind ik de juiste balans tussen datakwaliteit, verzamelsnelheid en kosten?
Deze afweging vereist strategisch nadenken over de minimaal haalbare kwaliteitsdrempels. Begin met het definiëren van de kwaliteitsaspecten die het belangrijkst zijn voor de specifieke toepassing: sommige gebruiksscenario's vereisen bijna perfecte nauwkeurigheid, terwijl andere ruisigere data tolereren als het volume dit compenseert. Implementeer gefaseerde dataverzameling, waarbij een subset intensief wordt gevalideerd, terwijl bulkdataverzameling gebruikmaakt van goedkopere methoden met steekproefsgewijze controles. Maak gebruik van technieken zoals actief leren om de kostbare labelinspanning te richten op de meest informatieve voorbeelden. Overweeg gefaseerde benaderingen, waarbij initiële modellen worden getraind op kleinere datasets van hoge kwaliteit en vervolgens worden uitgebreid naar grotere, ruisigere datasets zodra de basisprestaties zijn vastgesteld. Monitor de prestatiestatistieken van het model om te bepalen wanneer kwaliteitsproblemen daadwerkelijk van invloed zijn op de resultaten en wanneer ze theoretische problemen blijven.
Welke rol speelt synthetische data bij het trainen van AI?
Synthetische data vervult diverse waardevolle functies in de dataverzamelingsmethode. Het pakt privacyproblemen aan door kunstmatige records te genereren die statistische eigenschappen behouden zonder daadwerkelijke persoonsgegevens te bevatten. Synthetische generatie helpt bij het aanpakken van klasse-onbalans door extra voorbeelden van zeldzame scenario's te creëren. Simulatieomgevingen produceren synthetische trainingsdata voor autonome systemen waar het verzamelen van data in de echte wereld gevaarlijk, duur of tijdrovend zou zijn. De beperkingen? Synthetische data leggen mogelijk niet alle complexiteit van de echte wereld vast, en modellen die puur op synthetische data zijn getraind, kunnen problemen ondervinden met verschuivingen in de dataverdeling wanneer ze in de praktijk worden ingezet. De beste werkwijze is doorgaans om synthetische data te combineren voor initiële training, data-augmentatie of balancering met data uit de echte wereld voor validatie en finetuning.
Hoe moet ik omgaan met dataverzameling voor AI in gereguleerde sectoren?
Gereguleerde sectoren – zoals de gezondheidszorg, financiën, onderwijs en overheid – worden geconfronteerd met extra compliance-eisen bovenop de algemene privacywetgeving. Begin met het identificeren van alle toepasselijke regelgeving voor de specifieke gegevenstypen en rechtsgebieden. Schakel juridisch adviseurs en compliance-specialisten vroegtijdig in tijdens de projectplanning, in plaats van achteraf. Implementeer technische beheersmaatregelen, waaronder encryptie, toegangsbeperkingen, auditregistratie en dataminimalisatie. Verkrijg de juiste toestemming met duidelijke uitleg over het gebruik van AI. Overweeg privacybeschermende technieken zoals differentiële privacy, federated learning of het genereren van synthetische data om het regelgevingsrisico te verlagen. Documenteer alle verzamelprocessen, datastromen en compliance-maatregelen grondig. Regelgeving blijft zich ontwikkelen – denk aan NIST-normen, FTC-richtlijnen en agentschapspecifieke regels – dus ontwikkel monitoringprocessen die relevante updates met betrekking tot gegevensverzamelingspraktijken bijhouden.
AI-systemen bouwen op een solide datafundament
Het verzamelen van data lijkt misschien slechts infrastructuurwerk – de technische infrastructuur die de spannende modelontwikkeling verderop in de keten ondersteunt. Die zienswijze miskent echter de fundamentele waarheid: geen enkele mate van algoritmische verfijning kan een tekort aan trainingsdata compenseren.
De organisaties die de meest capabele en betrouwbare AI-systemen bouwen, erkennen dat dataverzameling strategische aandacht, aanzienlijke middelen en voortdurende verfijning vereist. Ze stellen governancekaders op die innovatie en verantwoordelijkheid in evenwicht brengen. Ze investeren in kwaliteitsborging om problemen vroegtijdig op te sporen. Ze ontwerpen dataverzamelingsarchitecturen die aanpasbaar zijn naarmate de eisen veranderen.
Succes in deze omgeving vereist dat dataverzameling wordt beschouwd als een kerncompetentie in plaats van een routineklus. De technische aspecten zijn belangrijk: het kiezen van geschikte verzamelmethoden, het implementeren van robuuste dataverwerkingsprocessen en het systematisch valideren van de kwaliteit. Maar dat geldt ook voor de organisatorische en ethische dimensies: samenwerking tussen verschillende afdelingen, transparante werkwijzen, bescherming van de privacy, het tegengaan van vooringenomenheid en zorgvuldige naleving van de regelgeving.
De AI-modellen die de krantenkoppen domineren, vertegenwoordigen de zichtbare resultaten. De dataverzamelingsprocessen die aan die modellen ten grondslag liggen, blijven grotendeels onzichtbaar voor eindgebruikers. Toch bepalen die onzichtbare methoden uiteindelijk of AI-systemen waarde leveren of problemen creëren – of ze mogelijkheden uitbreiden of vooroordelen versterken, of ze de privacy respecteren of misbruiken, of ze vertrouwen winnen of ondermijnen.
Organisaties die AI-initiatieven starten, zouden evenveel strategische planning moeten investeren in dataverzameling als in de selectie van modelarchitectuur. Bouw schaalbare dataverzamelingscapaciteiten op. Stel kwaliteitsnormen vast die standhouden. Creëer een governancekader dat bescherming biedt. Documenteer werkwijzen die bestand zijn tegen kritische analyse.
Begin met data. Doe het goed. De rest volgt daaruit.