Korte samenvatting: Toepassingen van big data zijn te vinden in sectoren zoals de gezondheidszorg, financiën, detailhandel, productie en overheid. Organisaties kunnen hiermee fraude opsporen, klantervaringen personaliseren, toeleveringsketens optimaliseren en betere beslissingen nemen. Door enorme datasets in realtime te analyseren, behalen bedrijven concurrentievoordelen dankzij voorspellende analyses, gedragsinzichten en operationele efficiëntiewinsten die traditionele datasystemen niet kunnen bieden.
Big data is allang geen modewoord meer. Het is de motor achter de beslissingen van organisaties die consequent beter presteren dan hun concurrenten.
De cijfers bevestigen dit. Volgens onderzoek dat in diverse brancheanalyses wordt aangehaald, is de kans dat bedrijven die datagestuurde beslissingen nemen hun omzetdoelstellingen halen groter dan bij bedrijven die dat niet doen. Datagedreven organisaties genereren gemiddeld meer dan 301 biljoen dollar groei per jaar.
Maar hoe ziet dit er in de praktijk uit?
Dat is waar dit artikel over gaat. Echte implementaties. Specifieke gebruiksscenario's. Meetbare resultaten van organisaties die enorme, onoverzichtelijke datasets hebben omgezet in strategische troeven.
Inzicht in toepassingen van big data
Toepassingsvoorbeelden van big data zijn concrete situaties waarin organisaties grote hoeveelheden data verzamelen, verwerken en analyseren om taken uit te voeren en doelen te bereiken. Dit zijn geen theoretische oefeningen, maar praktische toepassingen die echte bedrijfsproblemen oplossen.
Volgens het National Institute of Standards and Technology (NIST) beschrijft big data de enorme hoeveelheid gegevens in de netwerkgestuurde, gedigitaliseerde, met sensoren uitgeruste en informatiegedreven wereld. Volume alleen is niet voldoende om het te definiëren. Waar het om gaat, is wat organisaties met die gegevens doen.
De bepalende kenmerken komen naar voren in wat professionals in de sector de V's van big data noemen: volume, snelheid, variëteit, betrouwbaarheid en waarde. Sommige frameworks voegen variabiliteit toe als een zesde dimensie.
Maar er is iets belangrijks om te onthouden: deze kenmerken creëren zowel kansen als uitdagingen. De snelheid die realtime fraudedetectie mogelijk maakt, vereist ook een infrastructuur die miljoenen transacties per seconde kan verwerken. De diversiteit die klantprofielen verrijkt, vereist bovendien systemen die zowel gestructureerde databases als ongestructureerde berichten op sociale media kunnen verwerken.
Organisaties die succesvol zijn met big data richten zich op specifieke toepassingen in plaats van te proberen alles tegelijk te doen. Ze identificeren bedrijfsproblemen waar grootschalige data-analyse meetbare waarde oplevert en bouwen vervolgens de technische en organisatorische capaciteiten op om dit te realiseren.
Toepassingen van big data in de gezondheidszorg
De gezondheidszorg genereert dagelijks enorme hoeveelheden data: elektronische patiëntendossiers, medische beelden, declaraties van zorgverzekeraars, patiëntenenquêtes, draagbare apparaten, genomische data en farmaceutisch onderzoek. De uitdaging is altijd geweest om deze informatiestroom om te zetten in betere resultaten voor de patiënt.
Dat verandert snel.
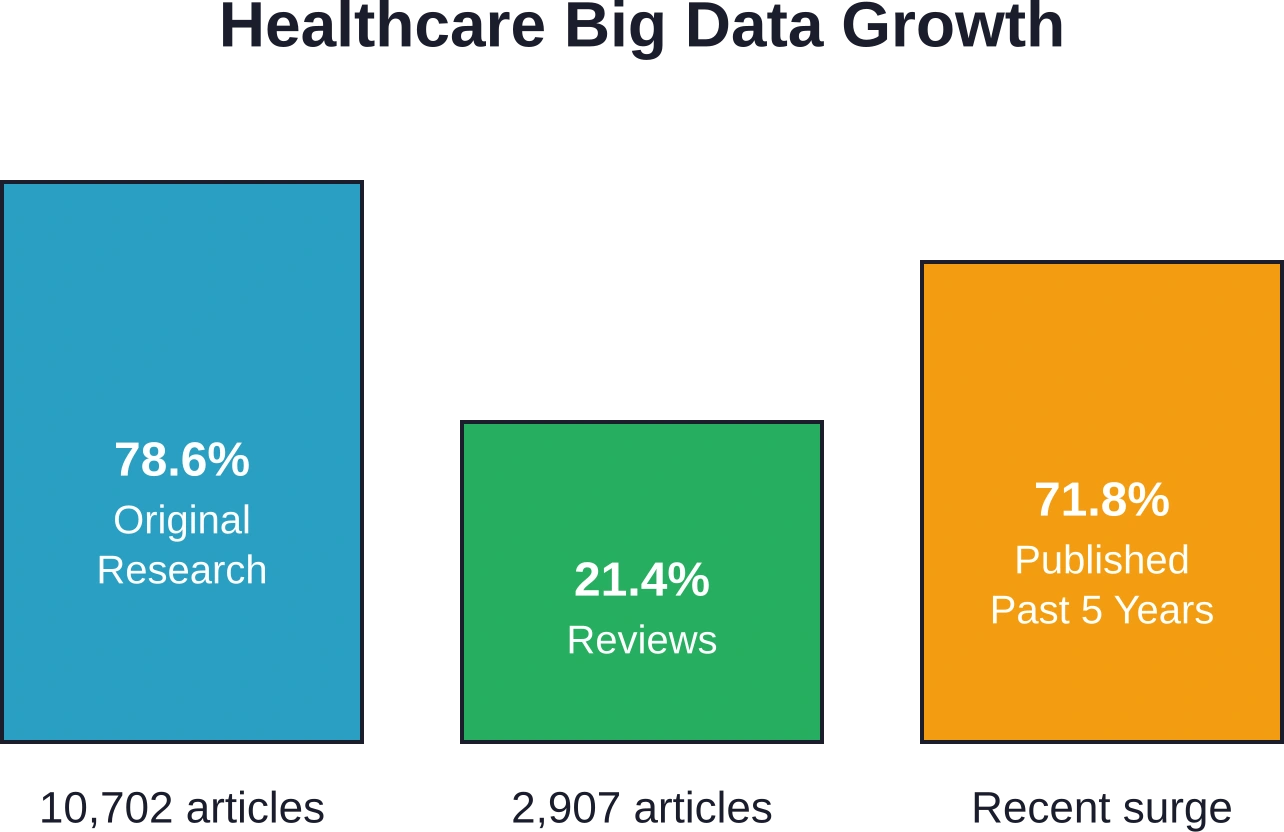
Een bibliometrische analyse, gepubliceerd in medische onderzoeksdatabases, onderzocht 13.609 artikelen over big data-toepassingen in de medische sector. Uit het onderzoek bleek dat 10.702 artikelen (78,61 TP3T) origineel onderzoek betroffen, terwijl 2.907 (21,41 TP3T) reviews waren. Opvallend is dat 71,81 TP3T van de literatuur in de afgelopen vijf jaar is gepubliceerd, wat wijst op een explosieve recente groei in de toepassing van data-analyse in de gezondheidszorg.
Wetenschappers publiceren al sinds 2009 artikelen over de toepassingen van big data-technologie in de medische sector, maar de versnelling is pas veel recenter ingezet. De VS loopt voorop met 4.053 publicaties, gevolgd door China met 3.184 artikelen.
Voorspellende analyses voor patiëntenzorg
Zorgverleners gebruiken big data-analyse om de verslechtering van de patiënttoestand te voorspellen voordat deze kritiek wordt. Door vitale functies, laboratoriumresultaten, medicatiegegevens en historische patronen van duizenden patiënten te analyseren, identificeren voorspellende modellen vroegtijdige waarschuwingssignalen die menselijke artsen mogelijk over het hoofd zien.
Deze aanpak ondersteunt op bewijs gebaseerde en resultaatgerichte besluitvorming in de klinische praktijk. Data-analyse in de gezondheidszorg identificeert patronen, verbetert de patiëntenzorg en verhoogt de systeemefficiëntie.
Operationeel beheer en beheer van middelen in de gezondheidszorg
Onderzoek uitgevoerd door het Centrum voor Onderzoek en Expertise van de Economische Universiteit van Katowice onderzocht de toepassing van big data door zorginstellingen. Uit de studie bleek dat 23,51 TP3T van de onderzochte instellingen gefinancierd werd uit publieke bronnen (het Nationaal Zorgfonds), 11,51 TP3T commercieel opereerde en 64,91 TP3T een hybride financieringsvorm had (publiek en commercieel).
De verdeling van de bedrijfsgroottes liet zien dat 34% middelgrote bedrijven waren (10-50 werknemers) en 27% grote bedrijven (51-250 werknemers). Deze organisaties gebruiken big data om de personeelsbezetting te optimaliseren, wachttijden te verkorten en de toewijzing van middelen over de verschillende vestigingen te verbeteren.
Medisch onderzoek en geneesmiddelenontwikkeling
Farmaceutische bedrijven analyseren genomische gegevens, resultaten van klinische onderzoeken en de daadwerkelijke uitkomsten bij patiënten om de ontdekking en ontwikkeling van geneesmiddelen te versnellen. Wat vroeger jaren duurde, kan nu in maanden gebeuren door patronen te identificeren in miljoenen datapunten.
Big data stelt onderzoekers in staat om patiëntengroepen te identificeren die het meest waarschijnlijk baat hebben bij specifieke behandelingen, ongewenste interacties tussen geneesmiddelen te voorspellen en het ontwerp van klinische studies te optimaliseren voordat er miljoenen in de ontwikkeling worden geïnvesteerd.
Toepassingsvoorbeelden van big data in de financiële dienstverlening
Financiële instellingen waren er vroeg bij om big data-analyse toe te passen, en met goede reden. De belangen zijn groot, de datavolumes zijn enorm en de concurrentievoordelen zijn meetbaar.
Eerlijk gezegd: een enkele handelsdag op grote beurzen genereert terabytes aan transactiegegevens. Creditcardmaatschappijen verwerken jaarlijks miljarden transacties. Banken bewaren tientallen jaren aan financiële gegevens van hun klanten. Dat is precies het soort volume, snelheid en variëteit waarbij big data echt tot zijn recht komt.
Fraudedetectie en -preventie
Financiële fraude kost jaarlijks miljarden. Big data-analyse maakt directe detectie mogelijk door patronen in miljoenen transacties in realtime te analyseren.
De analyse kan snel ongebruikelijke patronen en klantgedrag signaleren die kunnen wijzen op creditcardfraude, identiteitsdiefstal of andere frauduleuze activiteiten. Directe detectie betekent snelle interventie – de wereldwijde financiële dienstverlener JP Morgan Chase heeft een realtime fraudedetectiesysteem ontwikkeld dat transactiepatronen van al hun klanten tegelijkertijd analyseert.
Traditionele, op regels gebaseerde systemen detecteren bekende fraudepatronen. Machine learning-modellen, getraind op big data, sporen nieuwe fraudeschema's op door subtiele afwijkingen te identificeren die door regels over het hoofd worden gezien.
Risicomanagement en kredietscore
Banken gebruiken big data om kredietrisico's nauwkeuriger in te schatten dan met traditionele scoringsmodellen. Door duizenden variabelen te analyseren – transactiegeschiedenis, betalingspatronen, sociale contacten, werkstabiliteit en zelfs smartphonegebruik – kunnen kredietverstrekkers het risico op wanbetaling beter voorspellen.
Dit is gunstig voor zowel instellingen als consumenten. Banken verminderen verliezen als gevolg van wanbetalingen. Kredietwaardige klanten die op basis van traditionele beoordelingsmethoden zouden zijn afgewezen, worden nu wel goedgekeurd.
Algoritmische handel
Beleggingsfirma's analyseren marktgegevens, nieuwsberichten, sentiment op sociale media en economische indicatoren in realtime om transacties binnen milliseconden uit te voeren. Het voordeel is niet alleen de snelheid, maar ook het vermogen om duizenden signalen tegelijk te verwerken en patronen te herkennen die voor menselijke handelaren onzichtbaar zijn.
Handelsfirma's die zich bezighouden met hoogfrequent handelen verwerken marktgegevens op een schaal waarbij microseconden ertoe doen. De investering in infrastructuur is aanzienlijk, maar het concurrentievoordeel is meetbaar.
Klantpersonalisatie
Banken analyseren klanttransactiegegevens om productaanbevelingen te personaliseren, de dienstverlening te optimaliseren en de klanttevredenheid te verhogen. Door inzicht te krijgen in bestedingspatronen, levensgebeurtenissen en financiële doelen, kunnen instellingen relevante producten op het juiste moment aanbieden.
Dit is niet alleen goede service, het is ook winstgevend. Gepersonaliseerde aanbiedingen leiden tot aanzienlijk hogere conversiepercentages dan generieke marketingcampagnes.
Toepassingsvoorbeelden van big data in de detailhandel
De detailhandel genereert een van de rijkste bronnen van gedragsdata die er zijn. Elke klik, elke aankoop, elk verlaten winkelmandje vertelt een verhaal. Retailers die deze verhalen ontcijferen, winnen.
De transformatie is zichtbaar. Traditionele retailers hadden moeite om te concurreren met digitaal georiënteerde bedrijven, juist omdat ze de datagestuurde personalisatie die online platforms boden niet konden evenaren. Nu wordt die kloof kleiner, doordat fysieke retailers big data-analyse inzetten voor hun gehele bedrijfsvoering.
Gedragsanalyse en klantinzichten
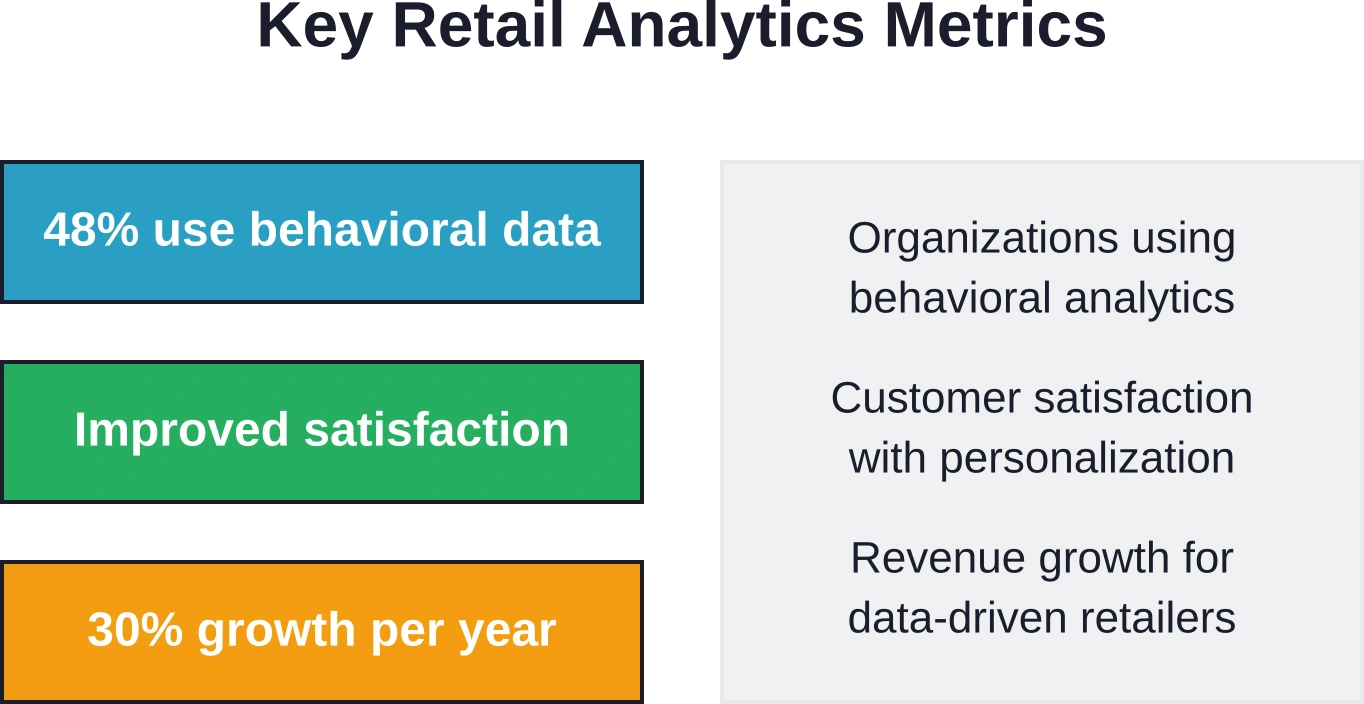
Uit analyses blijkt dat 481.300.000 organisaties big data gebruiken om waardevolle inzichten te verkrijgen uit klantgedragsgegevens. Organisaties zetten gedragsanalyses in om aanzienlijke waarde voor hun bedrijf te creëren.
Nordstrom meldt een verbeterde klanttevredenheid dankzij gepersonaliseerde ervaringen op basis van gedragsdata-analyse. Het systeem beveelt producten aan die klanten waarschijnlijk willen hebben, nog voordat ze ernaar zoeken.
Voorraad- en toeleveringsketenoptimalisatie
Retailers gebruiken voorspellende analyses om de voorraadniveaus te optimaliseren voor duizenden verschillende producten en honderden locaties. Door historische verkoopgegevens, seizoenspatronen, weersvoorspellingen, lokale gebeurtenissen en trendsignalen te analyseren, voorspellen systemen de vraag met opmerkelijke nauwkeurigheid.
De voordelen zijn aanzienlijk. Optimale voorraadniveaus verlagen de opslagkosten en minimaliseren voorraadtekorten die omzetverlies veroorzaken. Supply chain-optimalisatie breidt deze logica uit naar het gehele distributienetwerk.
Dynamische prijsstelling
Big data stelt retailers in staat om prijzen in realtime aan te passen op basis van vraag, concurrentieprijzen, voorraadniveaus en klantsegmenten. Luchtvaartmaatschappijen waren decennia geleden al pioniers op dit gebied. Nu verspreidt het zich naar alle retailsectoren.
De systemen analyseren miljoenen datapunten om de prijs te vinden die de omzet voor elk product op elk moment maximaliseert. Goed toegepast verhoogt dynamische prijsstelling de winstgevendheid zonder klanten af te schrikken.
Winkelindeling en merchandising
Winkeliers analyseren de looproutes in hun winkels met behulp van sensoren en camera's om de winkelindeling te optimaliseren. Welke gangpaden worden het meest bezocht? Waar blijven klanten staan? Welke plaatsing stimuleert impulsaankopen?
Deze datagedreven aanpak van merchandising vervangt intuïtie door bewijs. Testen, meten, optimaliseren, herhalen.
Toepassingsvoorbeelden van big data in de maakindustrie
De maakindustrie genereert continu datastromen afkomstig van sensoren, machines, kwaliteitscontrolesystemen en toeleveringsketens. Het industriële internet der dingen (IoT) heeft deze trend dramatisch versterkt.
De transformatie van General Electric illustreert de mogelijkheden. Zoals beschreven in de casestudies van MIT Sloan Management Review, lanceerde GE een grootschalig initiatief om een leider te worden in het industriële internet, waarbij miljarden werden ingezet op data- en analysecapaciteiten.
De belofte: data gebruiken om processen te optimaliseren op een schaal die met traditionele methoden onmogelijk is.
Voorspellend onderhoud
Sensoren op productiemachines genereren continu operationele gegevens, zoals temperatuur, trillingen, druk, outputkwaliteit en energieverbruik. Door patronen te analyseren van duizenden machines gedurende jarenlange werking, identificeren voorspellende modellen subtiele signalen die voorafgaan aan storingen in de apparatuur.
De waardepropositie is eenvoudig. Ongeplande stilstand kost fabrikanten miljoenen. Voorspellend onderhoud verschuift de focus van reactieve reparaties (duur, storend) naar gepland onderhoud (ingepland, geoptimaliseerd). Vervang onderdelen voordat ze defect raken, tijdens geplande stilstand, wanneer vervangende onderdelen op voorraad zijn.
Kwaliteitscontrole en defectdetectie
Computervisiesystemen analyseren producten met een snelheid en nauwkeurigheid die die van menselijke inspecteurs overtreffen. Machine learning-modellen, getraind op miljoenen afbeeldingen, detecteren defecten die traditionele geautomatiseerde systemen missen.
De systemen worden continu verbeterd. Elk gedetecteerd defect wordt gebruikt als input voor de trainingsdata, waardoor het model nauwkeuriger wordt. Het resultaat is een hogere kwaliteit van de producten tegen lagere inspectiekosten.
Optimalisatie van de toeleveringsketen en de productie
Fabrikanten analyseren gegevens over hun gehele toeleveringsketen om productieplanningen te optimaliseren, voorraden te minimaliseren en kosten te verlagen. Door inzicht te krijgen in vraagpatronen, leveranciersbetrouwbaarheid, transportlogistiek en beperkingen in de productiecapaciteit, optimaliseren systemen beslissingen waarbij duizenden variabelen een rol spelen.
Wat vroeger legioenen analisten en weken werk vergde, gebeurt nu automatisch en continu, op basis van realtime gegevens.
Energiebeheer
Productie is energie-intensief. Big data-analyse identificeert mogelijkheden om het energieverbruik te verminderen zonder de productie in gevaar te brengen. Door energieverbruikspatronen van apparatuur, productieplanningen en operationele omstandigheden te analyseren, identificeren systemen inefficiënties en optimalisatiemogelijkheden.
De besparingen stapelen zich op. Een verlaging van de energiekosten met 5% in een grote productieomgeving vertaalt zich in miljoenen per jaar.
Toepassingen van big data in de entertainment- en mediawereld.
Entertainmentbedrijven waren pioniers in personalisatie op grote schaal. De aanbevelingsalgoritmes die suggereren wat je vervolgens moet kijken, luisteren of lezen – deze systemen analyseren miljarden gebruikersinteracties om voorkeuren met een ongekende nauwkeurigheid te voorspellen.
Inhoudsaanbevelingen
Streamingplatforms analyseren kijkgedrag van miljoenen gebruikers om content aan te bevelen. De systemen matchen niet alleen genres, maar identificeren ook subtiele voorkeurspatronen op basis van kijktijd, voltooiingspercentages, herhalingsgedrag en honderden andere signalen.
Dit zorgt niet alleen voor een betere gebruikerservaring. Aanbevelingssystemen hebben een directe invloed op het behoud van abonnees en de consumptie van content, wat de omzet verhoogt.
Beslissingen over contentproductie
Mediabedrijven gebruiken big data om beslissingen te nemen over contentproductie. Welke genres zijn populair? Welke acteurs of regisseurs trekken veel kijkers? Welke verhaalelementen spreken specifieke doelgroepen aan?
Door kijkcijfers, de buzz op sociale media en markttrends te analyseren, kunnen studio's beter onderbouwde beslissingen nemen over welke projecten ze groen licht geven en hoe ze die op de markt brengen.
Advertentieoptimalisatie
Mediaplatforms analyseren gebruikersgegevens om op grote schaal gerichte advertenties te leveren. Dezelfde technologie die content aanbeveelt, koppelt gebruikers ook aan relevante advertenties, waardoor de effectiviteit van advertenties toeneemt en de gebruikerservaring verbetert doordat er relevantere advertenties worden getoond.
Adverteerders betalen hogere tarieven voor deze targetingmogelijkheid, omdat het aantoonbaar betere resultaten oplevert dan traditionele reclame.
Toepassingsvoorbeelden van big data in de overheid en de publieke sector.
Overheidsinstanties beheren enorme datasets: censusgegevens, belastinggegevens, informatie over de gezondheidszorg, transportsystemen, gegevens over openbare veiligheid en nog veel meer. De uitdaging is altijd geweest om deze gegevens om te zetten in betere resultaten voor de burgers.
Dat verandert nu organisaties in de publieke sector big data-analyse omarmen.
Openbare veiligheid en misdaadpreventie
Politie- en justitieorganisaties gebruiken voorspellende analyses om middelen effectiever in te zetten. Door misdaadpatronen, seizoensgebonden trends, evenementenplanning en omgevingsfactoren te analyseren, voorspellen systemen waar de kans op misdrijven het grootst is.
Dit maakt proactief politieoptreden mogelijk: agenten worden op de juiste plaatsen en tijdstippen ingezet om misdrijven te voorkomen in plaats van pas te reageren nadat ze hebben plaatsgevonden.
Vervoer en stedenbouw
Steden analyseren verkeerspatronen, het gebruik van openbaar vervoer en infrastructuurgegevens om transportsystemen te optimaliseren. Sensoren op wegen en voertuigen genereren realtime data die gebruikt worden voor de afstelling van verkeerslichten, routeplanning en investeringsbeslissingen in infrastructuur.
Het resultaat is minder files, kortere reistijden en efficiëntere openbaarvervoerssystemen.
Volksgezondheidsmonitoring
Gezondheidsinstanties analyseren gegevens over de volksgezondheid om ziekte-uitbraken te identificeren, trends in de volksgezondheid te volgen en middelen voor de gezondheidszorg toe te wijzen. De COVID-19-pandemie heeft zowel de mogelijkheden als de uitdagingen van big data-analyse in de volksgezondheid aangetoond.
Door testgegevens, ziekenhuisopnames, vaccinatiegraad en mobiliteitspatronen te analyseren, kunnen instanties beter onderbouwde beslissingen nemen over interventies op het gebied van de volksgezondheid.
Optimalisatie van sociale diensten
Overheidsinstanties gebruiken data-analyse om burgers te identificeren die diensten nodig hebben, fraude bij uitkeringen op te sporen en de dienstverlening te optimaliseren. Door patronen in meerdere databronnen te analyseren, kunnen instanties gerichter ingrijpen en verspilling tegengaan.
| Industrie | Primair gebruiksscenario | Belangrijkste voordeel | Implementatie-uitdaging |
|---|---|---|---|
| Gezondheidszorg | Voorspellende patiëntenzorg | Verbeterde resultaten | Regelgeving inzake gegevensbescherming |
| Financiële diensten | Fraude detectie | Realtime preventie | Systeemlatentievereisten |
| Detailhandel | Gedragsanalyse | Gepersonaliseerde ervaring | Complexiteit van gegevensintegratie |
| Productie | Voorspellend onderhoud | Minder uitvaltijd | kosten voor sensorinfrastructuur |
| Amusement | Inhoudsaanbevelingen | Verhoogde betrokkenheid | Algoritme transparantie |
| Regering | Analyse van openbare veiligheid | Misdaadpreventie | Vooroordelen en zorgen over eerlijkheid |
Marketinganalyse en klantsegmentatie
Marketing is getransformeerd door big data-analyse. De mogelijkheid om de effectiviteit van campagnes te meten, specifieke klantsegmenten te targeten en uitgaven in realtime te optimaliseren, heeft de marketingaanpak van bedrijven veranderd.
Onderzoek gepubliceerd door de Stanford Graduate School of Business onderzocht big data en marketinganalyse in de gamingindustrie. De studie beschreef de inspanningen om een raamwerk voor marketinganalyse te ontwikkelen, implementeren en evalueren bij MGM Resorts International, gebruikmakend van transactiegegevens op individueel niveau.
Het raamwerk maakte gebruik van empirische modellen van consumentenreacties op marketinginspanningen om segmentatie en targeting te optimaliseren. De modellen integreerden consumentenheterogeniteit en afhankelijkheid van de situatie in de keuzemodellering, met controlemechanismen voor de endogeniteit van historische targetingregels.
Het onderzoek toonde aan dat de marketingeffectiviteit aanzienlijk verbeterde door datagestuurde analyses toe te passen op de daadwerkelijke bedrijfsvoering van casino's.
De casestudie onderstreept de waarde van het gebruik van empirisch relevante marketinganalyseoplossingen voor het verbeteren van resultaten in de praktijk.
Klantsegmentatie
Big data maakt gedetailleerde klantsegmentatie mogelijk op basis van honderden variabelen, zoals demografische gegevens, aankoopgeschiedenis, surfgedrag, activiteit op sociale media en meer. In plaats van brede categorieën zoals 'millennialvrouwen' kunnen bedrijven microsegmenten identificeren met specifieke voorkeuren en gedragingen.
Deze precisie maakt gepersonaliseerde marketing op grote schaal mogelijk. Verschillende berichten, aanbiedingen en kanalen voor verschillende segmenten, allemaal geoptimaliseerd op basis van data in plaats van intuïtie.
Attributiemodellering
Multitouch-attributie analyseert klanttrajecten over tientallen contactmomenten – advertenties, e-mails, sociale media, websitebezoeken, winkelbezoeken – om te begrijpen welke marketingactiviteiten daadwerkelijk tot conversies leiden.
Traditionele methoden kenden alle credits toe aan de laatste klik vóór de aankoop. Big data-analyse onthult echter de complexe realiteit: klanten interageren via meerdere kanalen met merken gedurende een bepaalde periode voordat ze tot aankoop overgaan. Inzicht in dit klanttraject maakt een slimmere budgettoewijzing mogelijk.
Campagne Optimalisatie
Marketeers gebruiken A/B-testen en multivariate testen op grote schaal om campagnes continu te optimaliseren. Test verschillende berichten, afbeeldingen, aanbiedingen en targetingparameters. Meet de resultaten in realtime. Zet vol in op wat werkt.
De doorlooptijd is teruggebracht van maanden naar dagen of uren. Campagnes worden continu verbeterd op basis van prestatiegegevens, in plaats van te wachten op een analyse na afloop van de campagne.

Zet Big Data-toepassingen om in werkende AI-oplossingen.
Big data wordt waardevoller wanneer bedrijven weten wat ze willen voorspellen, optimaliseren, automatiseren of begrijpen. AI Superieur Het bedrijf ondersteunt dit soort werk door middel van AI-consultancy, AI- en datastrategie, business intelligence-oplossingen, machine learning, voorspellende analyses en de ontwikkeling van maatwerk AI-software. Voor industriële toepassingen kan dit betrekking hebben op klantanalyses, operationele rapportage, prognoses, anomaliedetectie, procesanalyse en besluitvorming op basis van grote datasets.
Voor big data-projecten kan AI Superior ondersteuning bieden:
- Het identificeren van praktische toepassingen van AI en analyses.
- Voorspellende modellen bouwen op basis van bedrijfsgegevens.
- Het ontwikkelen van tools voor business intelligence en data-analyse.
- Het ontwikkelen van AI-software rondom grote of complexe datasets.
- Analyse-uitkomsten koppelen aan bestaande systemen
👉Neem contact op met AI Superior Om te onderzoeken hoe toepassingen van big data kunnen worden omgezet in praktische AI- of analyseoplossingen.
Uitdagingen en aandachtspunten bij de implementatie van big data
Big data levert meetbare waarde op. Maar de implementatie is niet eenvoudig. Organisaties staan voor technische, organisatorische en ethische uitdagingen.
Gegevenskwaliteit en -integratie
Big data is alleen waardevol als het accuraat is. Problemen met de datakwaliteit – onvolledige records, inconsistente formaten, dubbele vermeldingen, verouderde informatie – ondermijnen analyses.
Integratie maakt de uitdaging nog groter. Organisaties moeten doorgaans gegevens uit tientallen bronnen combineren, elk met verschillende schema's, formaten en kwaliteitsnormen. Het bouwen van pipelines die gegevens betrouwbaar opschonen, transformeren en integreren, vereist een aanzienlijke technische investering.
Technische infrastructuur
Het verwerken van big data vereist een gespecialiseerde infrastructuur. Traditionele databasesystemen zijn niet ontworpen voor het volume, de snelheid en de diversiteit van big data. Organisaties hebben gedistribueerde computersystemen, cloudinfrastructuur, gespecialiseerde opslagoplossingen en analyseplatformen nodig.
De kosten kunnen aanzienlijk zijn. Maar het alternatief – proberen big data-analyses uit te voeren op traditionele infrastructuur – werkt niet.
Vaardigheden en talenten
Big data vereist specialistische vaardigheden. Data-engineers bouwen data-pipelines. Datawetenschappers ontwikkelen modellen. Analisten interpreteren de resultaten. Zakelijke belanghebbenden vertalen inzichten naar beslissingen.
Het tekort aan talent is reëel. Organisaties concurreren om professionals die zowel de technische aspecten van big data begrijpen als de zakelijke context waarin het waarde creëert.
Privacy en beveiliging
Big data bevat vaak gevoelige informatie. Medische dossiers. Financiële transacties. Persoonlijk gedrag. Organisaties moeten deze gegevens beschermen, ook wanneer ze deze voor analyses gebruiken.
Regelgeving zoals GDPR en HIPAA legt strenge eisen op. Overtredingen kunnen aanzienlijke sancties tot gevolg hebben. Beveiligingslekken schaden de reputatie en het klantvertrouwen.
Organisaties hebben technische controles, governanceprocessen en een organisatiecultuur nodig die prioriteit geeft aan privacy en beveiliging.
Vooroordelen en rechtvaardigheid
Machine learning-modellen die getraind zijn op historische data kunnen bestaande vooroordelen in stand houden of versterken. Als historische kredietgegevens discriminerende praktijken weerspiegelen, zullen modellen die op die data getraind zijn, leren om te discrimineren.
Dit is niet alleen een ethisch probleem, maar ook een zakelijk en juridisch risico. Organisaties hebben processen nodig om vooroordelen in hun data en modellen te identificeren en te verminderen.
Organisatieverandering
Om datagedreven te werken, is een cultuurverandering nodig. Beslissingen die voorheen gebaseerd waren op intuïtie, ervaring of politiek, moeten nu gebaseerd zijn op bewijs. Dat is ongemakkelijk voor organisaties die gewend zijn aan traditionele besluitvorming.
Steun van het management is essentieel. Maar dat geldt ook voor opleiding, stimulansen en processen die datagestuurde besluitvorming in de dagelijkse werkzaamheden verankeren.
| Uitdaging | Invloed | Mitigatiestrategie |
|---|---|---|
| Problemen met de datakwaliteit | Onnauwkeurige inzichten | Geautomatiseerde validatie- en opschoningsprocessen |
| Infrastructuurkosten | Hoge initiële investering | Cloudplatforms met een pay-as-you-go prijsmodel. |
| Tekort aan talent | Implementatievertragingen | Trainingsprogramma's en beheerde diensten |
| Privacyregelgeving | Compliance risico | Privacy-by-design en governance-frameworks |
| Algoritmische vooringenomenheid | Oneerlijke uitkomsten | Bias-testen en diverse trainingsgegevens |
| Cultureel verzet | Lage adoptie | Sponsoring door het management en verandermanagement |
Aan de slag met big data
Organisaties hoeven niet meteen het onmogelijke te doen. De meest succesvolle big data-initiatieven beginnen klein, bewijzen de waarde ervan en schalen vervolgens op.
Identificeer waardevolle gebruiksscenario's
Begin met het identificeren van bedrijfsproblemen waarbij data-analyse meetbare waarde kan opleveren. Richt u op problemen waarbij de organisatie al relevante gegevens verzamelt of deze gemakkelijk kan verzamelen.
De beste eerste projecten hebben duidelijke succesindicatoren, een beheersbare omvang en steun van het management. Zorg eerst voor succes op dat gebied, en pak daarna de moeilijkere problemen aan.
Beoordeel de gereedheid van de gegevens
Welke gegevens heeft de organisatie al? In welke staat verkeren deze gegevens? Welke hiaten bestaan er? Een data-inventarisatie en kwaliteitsbeoordeling voorkomen verrassingen achteraf.
Organisaties ontdekken vaak dat ze meer data hebben dan ze dachten. De uitdaging is om die data toegankelijk en bruikbaar te maken.
Ontwikkel of koop capaciteiten
Organisaties kunnen intern big data-capaciteiten ontwikkelen, gebruikmaken van beheerde services of een hybride aanpak hanteren. De juiste keuze hangt af van de technische volwassenheid, het budget en het strategische belang.
Veel organisaties beginnen met cloudgebaseerde platforms die infrastructuur en tools bieden zonder dat er een enorme investering vooraf nodig is. Dit verlaagt de drempel en maakt sneller experimenteren mogelijk.
Begin met pilotprojecten.
Pilotprojecten testen hypotheses en bewijzen de waarde voordat er overgegaan wordt tot grootschalige implementatie. Kies een afgebakend probleem, pas analyses toe en meet de resultaten.
Leer van de piloten. Wat werkte? Wat niet? Wat verraste je? Gebruik die lessen om de aanpak te verfijnen voordat je op grotere schaal gaat vliegen.
Schaal wat werkt
Zodra pilotprojecten hun waarde hebben aangetoond, kunnen succesvolle benaderingen worden opgeschaald. Bouw de infrastructuur, processen en organisatorische capaciteiten op die nodig zijn om datagestuurde besluitvorming tot een routine te maken in plaats van een uitzondering.
Hier komt de cumulatieve waarde naar voren. Eén succesvol analyseproject levert waarde op. Een dozijn projecten levert nog meer op. Een organisatie waar datagestuurde beslissingen de standaard zijn, transformeert de prestaties.
Toekomstige trends in big data
Big data blijft zich razendsnel ontwikkelen. Verschillende trends bepalen de volgende generatie toepassingsmogelijkheden.
Realtime-analyse
De tijd tussen dataverzameling en inzichten wordt steeds korter. Realtime analyses maken onmiddellijke reacties mogelijk: fraudedetectie in milliseconden, dynamische prijsstelling die continu wordt bijgewerkt, voorspellende onderhoudswaarschuwingen die storingen voorkomen.
Infrastructuur en algoritmen die realtime verwerking op grote schaal mogelijk maken, ontsluiten toepassingsmogelijkheden die met batchverwerking onmogelijk zijn.
Edge-computers
Door data dichter bij de bron te verwerken, worden de latentie en bandbreedtekosten verlaagd. In plaats van alle sensorgegevens naar gecentraliseerde cloudsystemen te sturen, voeren edge-apparaten een voorverwerking uit en verzenden ze alleen de relevante informatie.
Dit is van belang voor toepassingen waarbij milliseconden tellen, zoals autonome voertuigen, industriële automatisering en medische apparaten.
Integratie van AI en Machine Learning
Machine learning-modellen worden steeds vaker standaardonderdelen van big data-systemen. De combinatie is krachtig: big data levert de trainingsdata en realtime input die machine learning nodig heeft, terwijl machine learning inzichten uit data haalt op een schaal die voor menselijke analisten onmogelijk is.
Naarmate de mogelijkheden van AI zich ontwikkelen, vervaagt de grens tussen big data-analyse en kunstmatige intelligentie. Ze worden steeds meer geïntegreerde mogelijkheden in plaats van afzonderlijke disciplines.
Privacybehoudende analyses
Technieken zoals differentiële privacy, federated learning en veilige meerpartijenberekening maken analyses van gevoelige gegevens mogelijk zonder individuele records bloot te leggen. Dit opent de weg voor gebruiksscenario's die voorheen werden geblokkeerd door privacybezwaren.
De sectoren gezondheidszorg, financiële dienstverlening en overheid profiteren met name van analysemethoden die de privacy waarborgen en tegelijkertijd waardevolle inzichten opleveren.
Veelgestelde vragen
Wat zijn de meest voorkomende toepassingen van big data?
De meest voorkomende toepassingen van big data zijn onder andere fraudedetectie in de financiële sector, voorspellend onderhoud in de productie, analyse van klantgedrag in de detailhandel, gepersonaliseerde aanbevelingen in de entertainmentindustrie en optimalisatie van patiëntenzorg in de gezondheidszorg. Deze toepassingen hebben gemeenschappelijke kenmerken: grote hoeveelheden data, de behoefte aan realtime of bijna realtime verwerking en meetbare zakelijke waarde door verbeterde besluitvorming.
Hoe meten bedrijven het rendement op hun investering (ROI) met behulp van big data-initiatieven?
Bedrijven meten de ROI van big data aan de hand van statistieken die gekoppeld zijn aan specifieke bedrijfsresultaten. Financiële dienstverleners volgen de vermindering van fraudeverliezen en valse positieven. Retailers meten de toegenomen conversieratio's en de klantwaarde op lange termijn. Fabrikanten volgen de verminderde uitvaltijd en onderhoudskosten. Onderzoek bij MGM Resorts toonde aanzienlijke verbeteringen in de marketingeffectiviteit aan door middel van datagestuurde analyses.
Wat is het verschil tussen big data-analyse en traditionele analyse?
Traditionele analyses verwerken doorgaans gestructureerde data uit beperkte bronnen met behulp van standaard databasetools en statistische methoden. Big data-analyse verwerkt enorme hoeveelheden gestructureerde en ongestructureerde data uit diverse bronnen, vaak in realtime, met behulp van gedistribueerde computersystemen en geavanceerde machine learning-algoritmen. De schaal, snelheid en variëteit van de verwerkte data verschillen fundamenteel, waardoor inzichten mogelijk worden die met traditionele benaderingen onmogelijk zijn.
Welke sectoren profiteren het meest van big data?
De gezondheidszorg, financiële dienstverlening, detailhandel, productie en entertainment profiteren bijzonder sterk van big data. Onderzoek toont aan dat er alleen al in de medische sector 13.609 artikelen over big data zijn gepubliceerd, waarvan 71,81 ton in de afgelopen vijf jaar. Financiële dienstverleners gebruiken big data voor fraudedetectie en risicobeheer. De detailhandel past het toe voor personalisatie en optimalisatie van de toeleveringsketen. De productie gebruikt het voor voorspellend onderhoud. De entertainmentindustrie vertrouwt erop voor contentaanbevelingen.
Wat zijn de grootste uitdagingen bij de implementatie van big data?
Organisaties staan voor diverse grote uitdagingen: problemen met de datakwaliteit en -integratie vanuit verschillende bronnen, aanzienlijke infrastructuurkosten voor gespecialiseerde computer- en opslagsystemen, tekorten aan talent in data science- en engineeringfuncties, privacy- en beveiligingsrisico's met betrekking tot gevoelige data, algoritmische vooringenomenheid die discriminatie in stand kan houden, en weerstand binnen organisaties tegen datagestuurde besluitvorming. Succesvolle implementaties pakken deze problemen aan door middel van goede planning, governance en verandermanagement.
Hebben kleine bedrijven big data nodig?
Kleine bedrijven kunnen profiteren van de principes van data-analyse, zelfs zonder de schaal van een 'big data'-infrastructuur. De vraag is niet zozeer de hoeveelheid data, maar of datagedreven inzichten een concurrentievoordeel opleveren. Onderzoek toont aan dat bedrijven die datagestuurde beslissingen nemen, een grotere kans hebben om hun omzetdoelstellingen te overtreffen. Kleine bedrijven kunnen beginnen met cloudgebaseerde analyseplatformen die geen enorme investeringen vereisen, en zich richten op waardevolle toepassingen zoals klantsegmentatie of voorraadoptimalisatie.
Welke technische vaardigheden zijn nodig voor big data-projecten?
Big data-projecten vereisen uiteenlopende technische vaardigheden, waaronder data-engineering (het bouwen van pipelines, het beheren van infrastructuur), data science (statistische analyse, het ontwikkelen van machine learning-modellen), databasebeheer (het beheren van gedistribueerde systemen) en software-engineering (het integreren van analyses in applicaties). Vaardigheden op het gebied van businessanalyse vertalen technische inzichten naar concrete aanbevelingen. De meest succesvolle projecten maken gebruik van multidisciplinaire teams in plaats van dat van individuen wordt verwacht dat ze alle vaardigheden beheersen.
Conclusie
Toepassingen van big data zijn te vinden in alle belangrijke sectoren en leveren meetbare concurrentievoordelen op voor organisaties die ze effectief implementeren. Van analyses in de gezondheidszorg die de patiëntresultaten verbeteren tot financiële dienstverleners die fraude in realtime opsporen, van retailers die de klantervaring personaliseren tot fabrikanten die apparatuurstoringen voorkomen: de toepassingen zijn bewezen en de resultaten zijn meetbaar.
De data bevestigen de hype. Bedrijven die datagestuurde beslissingen nemen, hebben 581 TP3T meer kans om hun omzetdoelstellingen te overtreffen. Datagedreven organisaties genereren gemiddeld meer dan 301 TP3T groei per jaar. Specifieke implementaties, zoals de marketinganalyses van MGM Resorts, hebben aanzienlijke verbeteringen in de marketingeffectiviteit aangetoond door middel van datagedreven benaderingen.
Maar het zit zo: succes komt niet vanzelf.
Organisaties die succesvol zijn met big data beginnen met waardevolle toepassingen, bouwen de nodige technische mogelijkheden op, pakken privacy- en beveiligingskwesties proactief aan en stimuleren organisatorische veranderingen die datagestuurde besluitvorming in de dagelijkse bedrijfsvoering verankeren.
Organisaties die nog steeds uitsluitend op intuïtie en ervaring vertrouwen, lopen achter op concurrenten die hun beslissingen baseren op bewijs uit enorme datasets. Deze kloof wordt elk kwartaal groter.
Begin klein. Kies een afgebakend probleem waar analyses meetbare waarde kunnen opleveren. Bewijs het concept. Bouw van daaruit verder. Het cumulatieve voordeel van tientallen datagedreven verbeteringen groeit in de loop der tijd uit tot een duurzaam concurrentievoordeel.
De vraag is niet of big data waarde creëert – het bewijs daarvoor is overweldigend. De vraag is of uw organisatie die waarde zal benutten voordat uw concurrenten dat doen.