Korte samenvatting: De prijsstelling van LLM API's varieert in 2026 enorm tussen aanbieders, van DeepSeek's budgetvriendelijke $0,28 per miljoen tokens tot OpenAI's GPT-5.2 Pro met $21 per miljoen inputtokens. Inzicht in op tokens gebaseerde prijsmodellen, verborgen kosten zoals caching en embeddings, en optimalisatiestrategieën kan de kosten met 30-90% verlagen, terwijl de prestaties behouden blijven.
De markt voor API's voor grote taalmodellen is explosief gegroeid. Meer dan 300 modellen strijden nu om de aandacht van ontwikkelaars, elk met zeer uiteenlopende prijsstructuren.
De keuze voor de verkeerde aanbieder kan leiden tot maandelijkse overbesteding van duizenden euro's. Sommige bronnen suggereren dat organisaties mogelijk te veel betalen voor LLM API's, hoewel de precieze percentages van de overbetaling per gebruikssituatie verschillen, simpelweg omdat ze hun modelselectie en gebruikspatronen nog niet hebben geoptimaliseerd.
Deze vergelijking geeft een overzicht van de huidige prijzen bij de belangrijkste aanbieders, onthult verborgen kosten waar teams onverwacht mee te maken krijgen en laat precies zien waar uw geld naartoe gaat wanneer u een LLM API aanroept.
Inzicht in LLM API-prijsmodellen
De meeste LLM API's rekenen per token. Maar wat betekent dat concreet voor je budget?
Een token vertegenwoordigt ongeveer vier tekens tekst. Het woord 'understanding' bevat ongeveer drie tokens. Uw API-aanroepen worden apart gefactureerd voor inputtokens (wat u verzendt) en outputtokens (wat het model genereert).
Uitvoertokens kosten doorgaans 3 tot 6 keer meer dan invoertokens. Die asymmetrie is belangrijk wanneer je lange reacties genereert.
De drie belangrijkste prijsniveaus
Aanbieders baseren hun prijsstelling op drie verbruiksmodellen:
- Op aanvraag (standaard): Betalen per token zonder verplichtingen. Hoogste kosten per token, maar maximale flexibiliteit. Ideaal voor prototyping of onvoorspelbare werklasten.
- Batchverwerking: Dien verzoeken in die asynchroon binnen 24 uur worden verwerkt. Amazon Bedrock en OpenAI bieden beide 50%-kortingen voor batchverzoeken in vergelijking met de tarieven voor verzoeken op aanvraag. Perfect voor niet-urgente taken zoals data-analyse of contentgeneratie.
- Geconfigureerde doorvoer: Reserveer dedicated capaciteit met gegarandeerde responstijden. Facturering per uur of per maand. Ideaal wanneer u constant grote volumes verwerkt en voorspelbare latentie nodig hebt.
OpenAI heeft extra prijsniveaus toegevoegd aan hun nieuwste prijsstructuur. Het "Flex"-niveau biedt bescheiden kortingen, terwijl "Priority" snellere verwerking garandeert tijdens piekuren.
Prijsopgave van de belangrijkste aanbieders
Laten we de marketingpraatjes even achterwege laten en naar de daadwerkelijke cijfers kijken, zoals die te vinden zijn op de officiële prijspagina's.
OpenAI API-prijzen (2026)
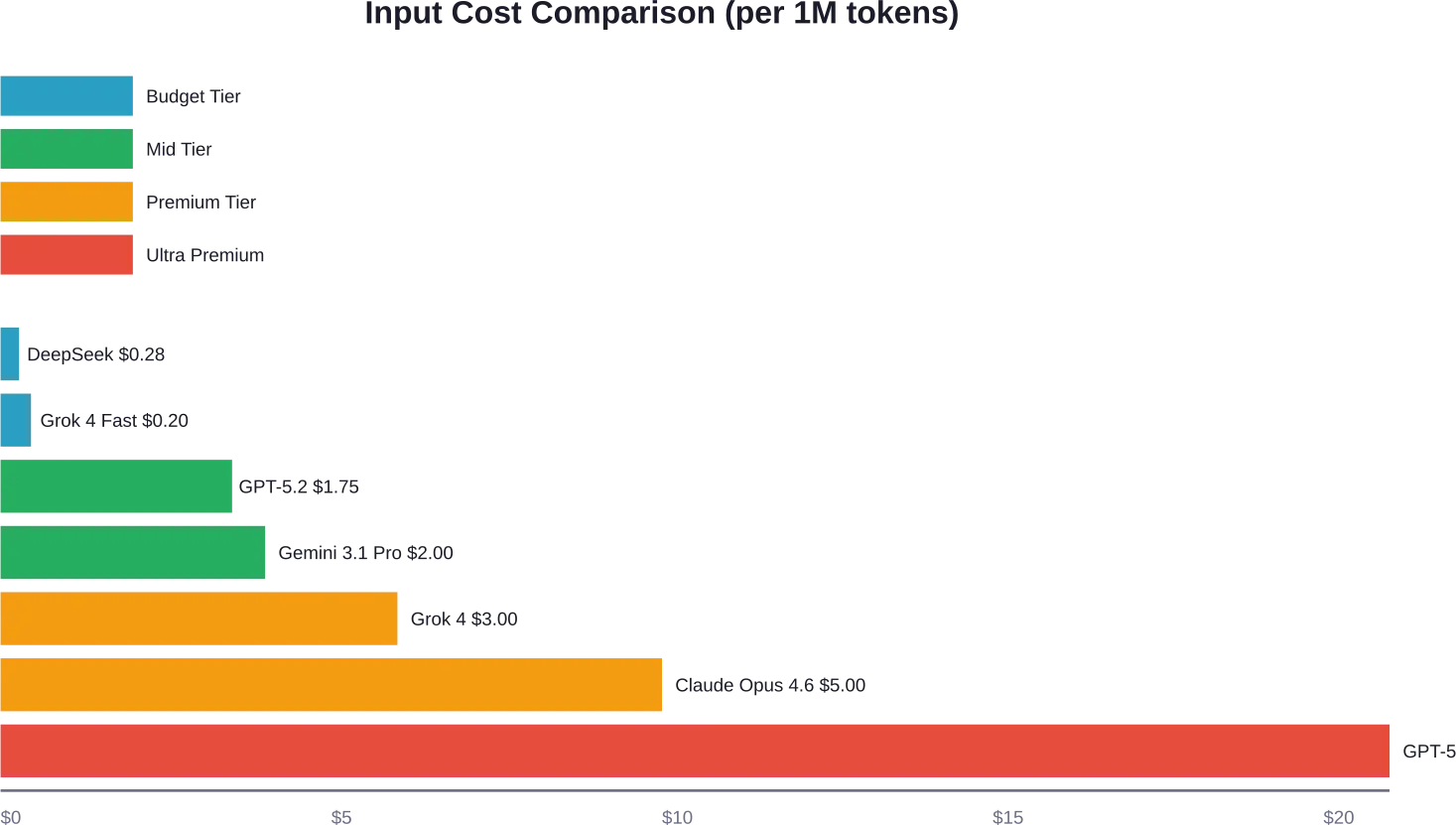
Het aanbod van OpenAI is aanzienlijk uitgebreid. Volgens de officiële prijslijst van OpenAI zijn dit de kosten per miljoen tokens:
| Model | Invoerkosten | Invoer in cache | Productiekosten |
|---|---|---|---|
| GPT-5.2 Pro | $21.00 | Niet van toepassing | $168.00 |
| GPT-5.2 | $1.75 | $0.175 | $14.00 |
| GPT-5 Mini | $0.25 | $0.025 | $2.00 |
| GPT-5 Nano | $0.025 | $0.0025 | $0.20 |
| GPT-4.1 | $1.00 | Niet van toepassing | $4.00 |
| GPT-4o | $1.25 | Niet van toepassing | $5.00 |
Het vlaggenschip GPT-5.2 is ontworpen voor complexe redeneer- en agentgebaseerde workflows. De GPT-5 Nano biedt het voordeligste instapmodel in het huidige OpenAI-aanbod en is geschikt voor eenvoudige classificatie- of extractietaken.
Hun batch-API halveert deze prijzen. De batch-tarieven van GPT-5.2 bedragen $0,875 input en $7,00 output per miljoen tokens, wat een korting van 50% oplevert ten opzichte van de standaardtarieven.
Antropische Claude-prijzen
De Claude-modellen van Anthropic volgen een andere architectuur met prominente mogelijkheden voor contextcaching. Uit hun officiële documentatie:
| Model | Basisinvoer | Cache-hits | Uitvoer |
|---|---|---|---|
| Claude Opus 4.6 | $5.00 | $0.50 | $25.00 |
| Claude Opus 4.5 | $5.00 | $0.50 | $25.00 |
| Claude Opus 4.1 | $15.00 | $1.50 | $75.00 |
Het cachesysteem van Claude biedt een korting van 90% bij hergebruik van context. Als je een chatbot bouwt die herhaaldelijk dezelfde kennisbank raadpleegt, betekent een cachehit van $0,50 per miljoen tokens versus $5,00 voor nieuwe invoer een enorme besparing.
Anthropic biedt ook batchverwerking aan met een korting van 50% op de standaardtarieven, wat overeenkomt met de kortingsstructuur van OpenAI.
Google Vertex AI (Gemini-modellen)
Het Vertex AI-platform van Google biedt plaats aan hun Gemini-familie en modellen van derden. De prijzen op hun officiële Vertex AI-pagina zijn als volgt:
| Model | Invoer ≤200K tokens | Invoer >200K | Uitvoer |
|---|---|---|---|
| Voorbeeldweergave van Gemini 3.1 Pro | $2.00 | $4.00 | $12.00 |
| Gemini 3.1 Flash | Lagere prijsklasse | Zie de officiële documentatie. | Zie de officiële documentatie. |
Google hanteert prijsdrempels voor zoekopdrachten met een lange context. Zoekopdrachten die meer dan 200.000 tokens bevatten, worden tegen hogere tarieven berekend voor alle tokens in die zoekopdracht. Gemini 2.5 Pro biedt dagelijks 10.000 standaard zoekopdrachten (integratie met webzoekmachines) gratis aan, waarna 1 TP4T35 per 1.000 extra standaard zoekopdrachten in rekening wordt gebracht.
Hun kosten voor webfundering voor bedrijven bedragen $45 per 1.000 zoekopdrachten. Deze zoekversterkende functies lopen snel op als je het gebruik niet bijhoudt.
Amazon Bedrock Multi-Model Platform
AWS Bedrock bundelt modellen van meerdere aanbieders onder één factuur. Volgens hun prijsupdate van februari 2026:
- Claude 3.5 Sonnet begint bij $3 input / $15 output per miljoen tokens
- Gemma 3 4B kost $0.04 input / $0.08 output
- Gemma 3 12B voert $0.09 ingang / $0.18 uitgang uit
Bedrock biedt batch-inferentie aan voor 50% tegen tarieven op aanvraag. Hun geprovisioneerde doorvoermodel rekent per model-eenheid uur in plaats van tokens, met contractvoorwaarden die kortingen bieden voor contracten van 1 of 6 maanden.
Amazon biedt ook hun Nova-modellen aan tegen concurrerende prijzen, hoewel de exacte tarieven per regio verschillen.
Budgetopties: DeepSeek en xAI
Het in China gevestigde DeepSeek heeft de markt opgeschud met agressieve prijsstelling voor hun V3.2-Exp-modellen. De V3.2-Exp-modellen van DeepSeek worden aangeboden voor $0,60 per miljoen inputtokens (cache-miss) en $0,40 voor reasoning output tokens, volgens beschikbare prijsgegevens met cache-misses en $0,40 voor reasoning output tokens.
xAI lanceerde Grok 4 met een input van $3 en een output van $15 per miljoen tokens. Hun snellere Grok 4.1 Fast-variant kost $0.20 aan input en $0.50 aan output, en is gericht op ontwikkelaars die snelheid belangrijker vinden dan maximale functionaliteit.
Verborgen kosten die uw rekening verhogen
De kosten voor tokens halen de krantenkoppen. Maar diverse minder voor de hand liggende kosten kunnen je werkelijke uitgaven verdubbelen.
Promptcache en contextvensters
Grote contextvensters klinken geweldig, totdat je beseft dat je voor elk token apart betaalt. OpenAI en Anthropic bieden beide promptcaching aan om de kosten voor herhaalde contexten te verlagen.
Volgens de documentatie van OpenAI kosten gecachede invoertokens 90% minder dan standaardinvoer. Voor GPT-5.2 kosten gecachede tokens $0.175, tegenover $1.75 voor niet-gecachede tokens.
Het addertje onder het gras? Het schrijven naar de cache kost geld. De prijsstelling van Anthropic laat zien dat de tarieven voor het schrijven naar de cache variëren afhankelijk van de duur: 5 minuten schrijven kost $6,25 per miljoen tokens en 1 uur schrijven kost $10 per miljoen voor Claude Opus 4.6.
Als je de context niet vaak genoeg hergebruikt, kost caching meer dan het bespaart.
Inbeddingen en vectorzoekactie
Het bouwen van een RAG-systeem (retrieval-augmented generation) vereist het genereren van embeddings. Deze kosten staan los van de kosten voor de hoofdinferentie.
Volgens de AWS-documentatie kost Amazon Titan Text Embeddings V2 $0.00002 per 1.000 invoertokens. Dat klinkt goedkoop, totdat je miljoenen documenten moet insluiten.
Je betaalt ook voor vectoropslag. Google's Vertex AI RAG Engine brengt kosten in rekening voor data-invoer, LLM-parsing voor chunking en vectorzoekbewerkingen, bovenop de kosten voor modelinferentie.
Aarding en gereedschapsgebruik
Google rekent $35 per 1.000 zoekopdrachten (webzoekopdrachten) op Gemini na het verstrijken van het gratis dagelijkse quotum. Volgens de officiële prijsdocumentatie van Anthropic voor Vertex AI kost Claude webzoekopdrachten $10 per 1.000 zoekopdrachten.
Deze functies verbeteren de nauwkeurigheid van realtime-informatie aanzienlijk. Maar ze verhogen de kosten met 10-15% als ze veelvuldig worden gebruikt.
Snelheidslimieten en throttling
Gratis abonnementen en abonnementen met een lager gebruikslimiet hanteren strikte snelheidslimieten. Het tiersysteem van OpenAI laat zien dat gebruikers van Tier 1 500 verzoeken per minuut met 500.000 tokens per minuut kunnen verwerken op GPT-5.2. Gebruikers van Tier 5 hebben toegang tot 40 miljoen TPM.
Het bereiken van limieten voor het aantal aanvragen leidt tot mislukte verzoeken en herhalingslogica, wat zowel tokens als ontwikkeltijd verspilt. Upgraden naar een hoger abonnement vereist een minimale maandelijkse uitgave, maar elimineert knelpunten.

Bouw de juiste LLM-architectuur met AI Superior
De keuze tussen verschillende LLM API's draait niet alleen om de prijs van de tokens. Prestatie-eisen, promptontwerp, systeemarchitectuur en schaalstrategie hebben allemaal invloed op de totale kosten van een applicatie.
AI Superieur Helpt bedrijven bij het ontwerpen van productiegereed LLM-systemen en het kiezen van de meest geschikte architectuur voor hun specifieke toepassing.
Hun team kan helpen met:
- Het selecteren van de juiste LLM-aanbieders
- het ontwerpen van schaalbare LLM-architecturen
- het optimaliseren van prompts en tokengebruik
- het integreren van LLM's in bestaande systemen
Als u een product wilt ontwikkelen dat gebruikmaakt van LLM-technologie, AI Superieur kan helpen bij het ontwerpen van de technische architectuur en het implementeren van de oplossing.
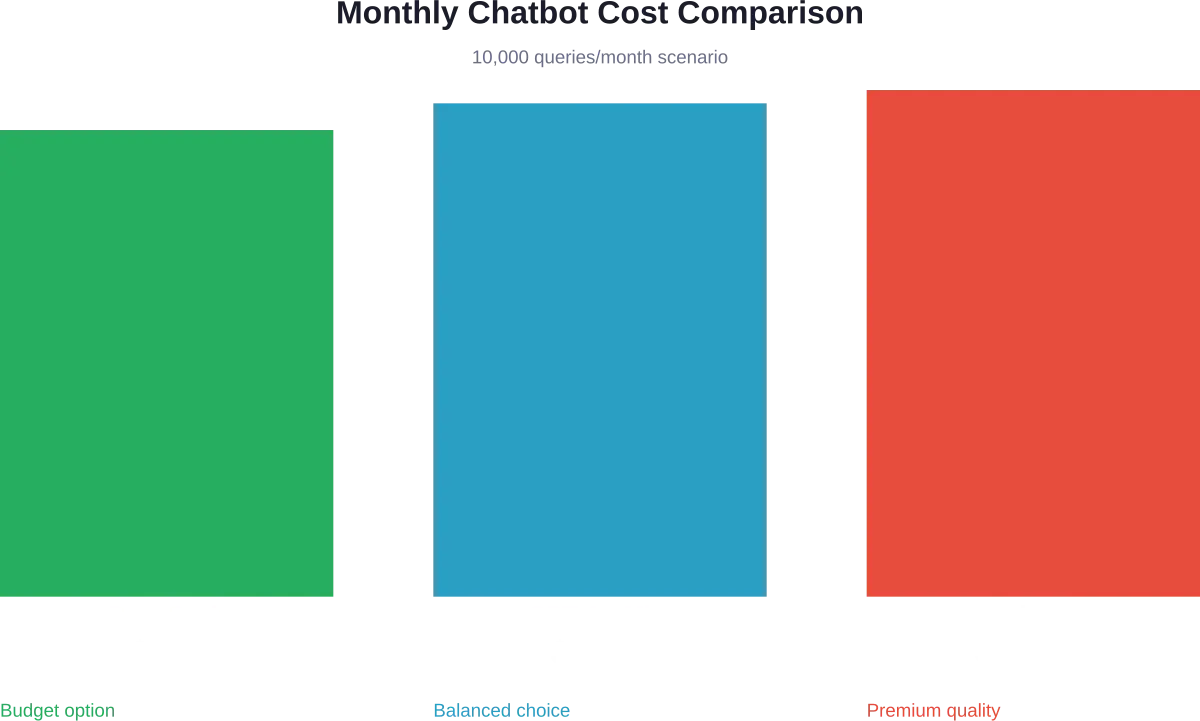
Kostenanalyse in de praktijk: voorbeeld van een chatbot
Laten we de werkelijke kosten modelleren voor een klantenservicechatbot die maandelijks 10.000 vragen afhandelt.
Aannames gebaseerd op typische callcenterpatronen uit de AWS-documentatie:
- 5 miljoen tokens voor de kennisbank (eenmalig + updates)
- 50.000 embeddings voor semantisch zoeken
- Gemiddeld 100 tokens per gebruikersquery
- Gemiddeld 100 tokens per reactie
- Totaal: 2 miljoen tokens per maand (1 miljoen input, 1 miljoen output)
OpenAI GPT-4.1 Mini
- Invoer: 1M tokens × $0.20 = $200
- Uitvoer: 1M tokens × $0.80 = $800
- Inbeddingen: 50K × $0.00002 = $1
- Maandelijks totaal: ~$1.001
Claude Opus 4.6 met caching
- Kennisbank in cache opgeslagen: 90% cache hits
- Invoer in cache: 900K × $0.50 = $450
- Nieuwe invoer: 100K × $5.00 = $500
- Uitvoer: 1M × $25.00 = $25.000
- Maandelijks totaal: ~$25.950
Wacht even, dat is 26 keer duurder. Maar het zit zo: Claude Opus levert aanzienlijk betere resultaten bij complexe redeneertaken. De hogere prijs is gerechtvaardigd voor bedrijfskritische toepassingen waar nauwkeurigheid belangrijker is dan kosten.
DeepSeek V3.2 Budgetoptie
- Invoer: 1M × $0.28 = $280
- Uitvoer: 1M × $0.40 = $400
- Inbeddingen: $1
- Maandelijks totaal: ~$681
DeepSeek biedt de goedkoopste optie, maar de betrouwbaarheid ervan voor zakelijke toepassingen is minder bewezen. Prestatiebenchmarks tonen aan dat het in standaardtests binnen 20% van de beste commerciële modellen scoort, waardoor het een geschikte keuze is voor kostenbewuste toepassingen.
Kostenoptimalisatiestrategieën die daadwerkelijk werken
Teams die de kosten van een LLM-opleiding effectief beheren, volgen een aantal beproefde patronen.
Intelligente promptroutering
Niet elke vraag vereist uw krachtigste model. Leid eenvoudige vragen door naar kleinere modellen en complexe redeneringen naar de meest geavanceerde opties.
Volgens de AWS-documentatie kan intelligente promptroutering de kosten met wel 301 TP3T verlagen zonder dat dit ten koste gaat van de nauwkeurigheid. Implementeer classificatielogica die query's toewijst aan de juiste modellen op basis van complexiteit.
Amazon Bedrock ondersteunt dit via hun intelligente promptrouteringsfunctie, die automatisch de optimale modellen per verzoek selecteert.
Agressieve promptcaching
Structureer uw prompts zo dat ze optimaal hergebruikt kunnen worden in de cache. Plaats stabiele context (systeeminstructies, fragmenten uit de kennisbank) aan het begin, waar deze in de cache kan worden opgeslagen.
Het caching-systeem van Anthropic biedt een kostenbesparing tot wel 90% op gecachede tokens in vergelijking met de standaard invoerprijzen. Voor applicaties die een consistente context gebruiken, kan deze ene optimalisatie de kosten halveren.
Batchverwerking voor niet-urgente taken
Zowel OpenAI als Amazon Bedrock bieden 50%-kortingen voor batch-API-verzoeken. Alle taken die binnen 24 uur verwerkt kunnen worden, dienen via batch-endpoints te worden afgehandeld.
Het genereren van content, data-analyse en het creëren van trainingsdata werken allemaal perfect als batchverwerking. Organisaties kunnen aanzienlijke kostenbesparingen realiseren door batchverwerking, die doorgaans 50%-kortingen biedt ten opzichte van tarieven op aanvraag.
Uitvoertokenbeheer
Uitvoertokens kosten 4-6 keer meer dan invoertokens. Beperk de lengte van de respons nauwkeurig met behulp van de parameter max_tokens en prompt engineering.
Het opvragen van reacties van 500 tokens terwijl 200 tokens volstaan, is een verspilling van geld bij elke aanroep. Stel conservatieve uitvoerlimieten in en breid deze alleen uit voor query's die daadwerkelijk langere reacties vereisen.
Modelselectie op basis van taaktype
Stem de mogelijkheden van het model af op de vereisten:
- Eenvoudige classificatie/extractie: Gebruik nano/mini-modellen (GPT-5 Nano met $0.025 ingang, $0.20 uitgang)
- Algemene reacties van de chatbot: Middenklasse modellen (GPT-4.1 Mini, Claude Sonnet varianten)
- Complex redeneren/coderen: Topmodellen (GPT-5.2, Claude Opus)
- Massaverwerking: Gebruik altijd batch-API's voor 50%-besparingen.
Een kosten-batenanalyse suggereert dat organisaties het break-evenpunt kunnen bereiken met een on-premise LLM-implementatie, afhankelijk van het gebruiksniveau en de prestatiebehoeften, evenals de infrastructuurkosten. Voor de meeste teams levert het optimaliseren van het gebruik van cloud-API's echter een beter rendement op dan zelfhosting.
Monitoring- en kostenbeheertools
Je kunt niet optimaliseren wat je niet meet. Er zijn verschillende methoden om de uitgaven voor LLM-opleidingen in kaart te brengen:
Provider-eigen dashboards
OpenAI, Anthropic en Google bieden alle drie dashboards aan die het tokenverbruik per model, project en tijdsperiode weergeven. Deze dashboards werken, maar missen de mogelijkheid om de gegevens van verschillende aanbieders met elkaar te vergelijken.
Met de Usage & Cost API van Anthropic kunt u programmatisch toegang krijgen tot verbruiksgegevens met een nauwkeurigheid van 1 minuut tot 1 dag. Alle kosten worden weergegeven in USD als decimale getallen in centen.
Platformen voor monitoring door derden
Helicone en vergelijkbare diensten bundelen het gebruik bij meerdere LLM-aanbieders. Ze houden de kosten per aanvraag bij, identificeren dure zoekopdrachten en waarschuwen wanneer budgetdrempels worden overschreden.
Deze platforms rekenen doorgaans 1-2% aan LLM-uitgaven of vaste maandelijkse kosten. De investering waard voor teams die met meerdere leveranciers werken of gedetailleerde toewijzing per gebruiker/project nodig hebben.
Budgetwaarschuwingen instellen
De meeste providers ondersteunen bestedingslimieten en waarschuwingen. Configureer deze vóór de implementatie in de productieomgeving:
- Stel harde limieten in voor ontwikkel-/testomgevingen.
- Configureer waarschuwingen bij budgetdrempels van 50%, 75% en 90%.
- Implementeer circuit breakers die verzoeken pauzeren wanneer de limieten worden bereikt.
AWS Cost Explorer biedt budgetbewaking voor Bedrock-gebruik. Google Cloud biedt vergelijkbare functionaliteit voor uitgaven aan Vertex AI.
Opkomende trends in LLM-prijsstelling
Het concurrentielandschap blijft zich in hoog tempo ontwikkelen.
Neerwaartse spiraal bij grondstoffentaken
De prijzen voor eenvoudige tekstgeneratie en -classificatie zijn sinds 2023 met 80-90% gedaald. Modellen zoals de GPT-5 Nano ($0.025 input) en DeepSeek ($0.28 input) drukken de prijzen voor simpele taken naar bijna nul.
Deze commoditisering betekent dat differentiatie plaatsvindt op basis van gespecialiseerde vaardigheden – redeneren, multimodaal begrip, gebruik van tools – in plaats van op het simpelweg genereren van tekst.
Hogere prijzen voor redeneermodellen
Voor geavanceerde redeneersystemen geldt de tegenovergestelde trend. De GPT-5.2 Pro met $21-ingang / $168-uitgang brengt aanzienlijk hogere prijzen met zich mee dan standaardmodellen.
Deze "trage denkmodellen" besteden meer rekentijd aan redeneren voordat ze reageren, wat de hogere prijzen rechtvaardigt voor complexe problemen waarbij nauwkeurigheid belangrijker is dan snelheid.
Contextvenster Economie
Aanbieders rekenen hogere tarieven voor zoekopdrachten met een lange context. De drempel van Google van meer dan 200.000 tokens zorgt ervoor dat alle tokens in die zoekopdracht duurder uitvallen.
Naarmate de contextvensters groter worden (OpenAI's GPT-5.2 ondersteunt 400.000 tokens), zal prijsdifferentiatie op basis van contextgebruik naar verwachting de standaard worden. Efficiënt contextbeheer door middel van samenvatting en caching zal steeds belangrijker worden.
Prijsstelling voor gespecialiseerde modellen
Domeinspecifieke modellen (medisch, juridisch, financieel) hanteren hogere prijzen vanwege de specialistische opleiding. Verwacht een verdere groei van nichemodellen met prijzen die 2-3 keer zo hoog liggen als die van algemene modellen.
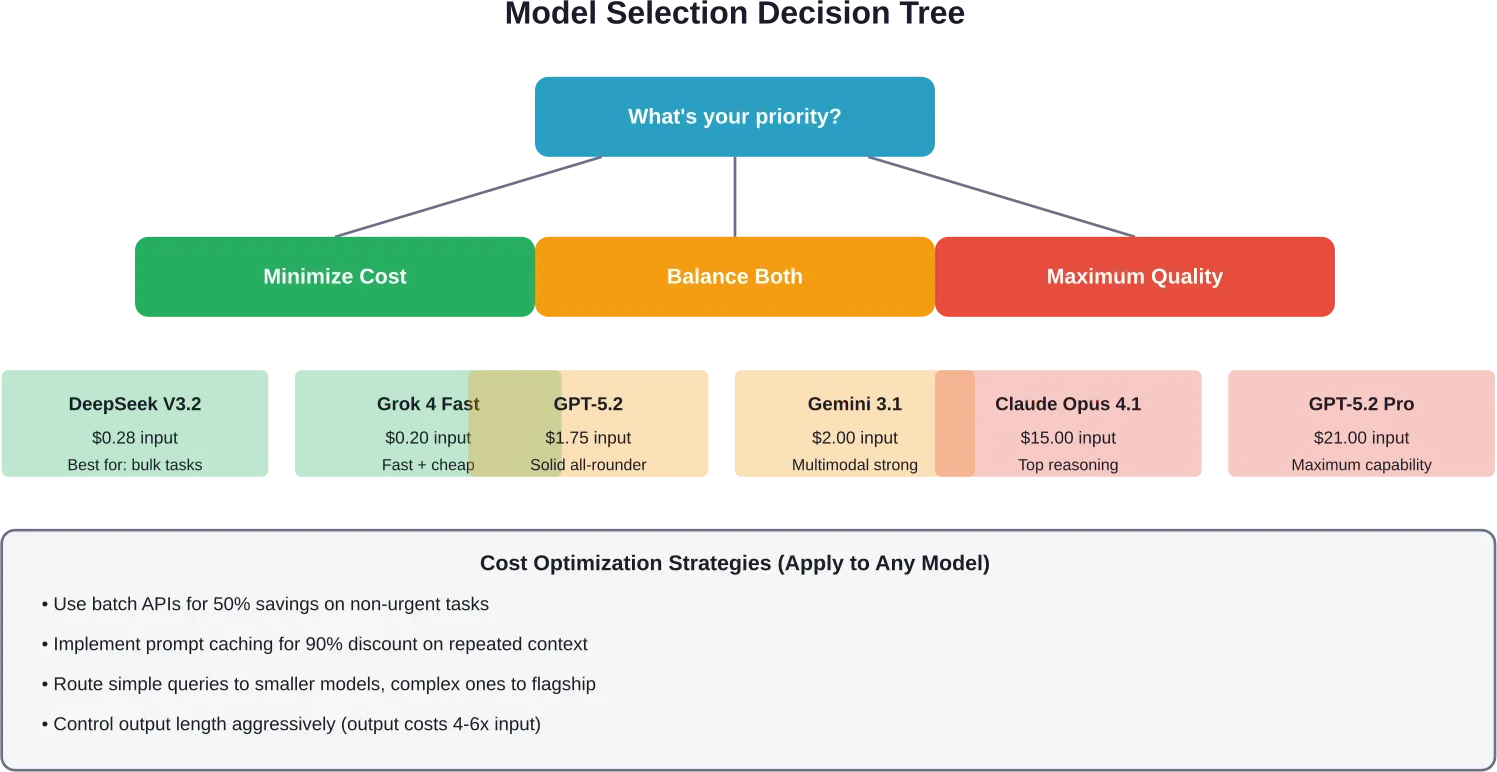
Welke aanbieder moet u kiezen?
Er bestaat geen universeel antwoord, maar hier is een besluitvormingskader gebaseerd op prioriteiten:
Voor krappe budgetten
DeepSeek V3.2 biedt de laagste kosten per token met behoud van een redelijke kwaliteit. Grok 4 Fast is een andere budgetvriendelijke optie met een betere ondersteuningsinfrastructuur.
Combineer budgetmodellen voor eenvoudige taken met strategisch gebruik van premiummodellen voor kritieke query's. Leid 80% aan verkeer door naar goedkope modellen en 20% naar dure modellen.
Voor maximale kwaliteit
OpenAI's GPT-5.2 Pro en Claude Opus 4.1 vertegenwoordigen momenteel de hoogste kwaliteitsstandaard. Reken op een prijs die 10 tot 30 keer hoger ligt dan die van middenklasse opties.
Alleen gerechtvaardigd wanneer nauwkeurigheid direct van invloed is op de inkomsten of het risico (juridische analyses, medische toepassingen, kritieke infrastructuur).
Voor een evenwichtige prestatie
De GPT-5.2 ($1.75-ingang) en de Claude Opus 4.6 ($5.00-ingang) bieden de ideale oplossing voor de meeste productietoepassingen. Sterke prestaties zonder extreem hoge kosten.
De Google Gemini 3.1 Pro met $2.00-ingang biedt een concurrerende prijs met uitstekende multimodale mogelijkheden.
Voor Google Cloud-gebruikers
Vertex AI biedt uniforme toegang tot Gemini en modellen van derden. Het geïntegreerde ecosysteem vereenvoudigt de implementatie als u al gebruikmaakt van de GCP-infrastructuur.
Profiteer dagelijks van de 10.000 gratis, relevante suggesties van Gemini 2.5 Pro voor zoekmachine-ondersteunde applicaties.
Voor AWS-omgevingen
Bedrock biedt de ruimste modelkeuze met uniforme facturering. Een goede keuze voor organisaties die gestandaardiseerd zijn op AWS en via één interface toegang willen tot Anthropic, Meta en andere providers.
Veelgestelde vragen
Wat is de goedkoopste LLM API in 2026?
DeepSeek V3.2 biedt momenteel de laagste prijs per token, namelijk ongeveer $0.28 per miljoen inputtokens en $0.40 voor de redeneeroutput. Grok 4 Fast van xAI werkt met $0.20 input / $0.50 output. Voor OpenAI-gebruikers kost GPT-5 Nano $0.025 input / $0.20 output per miljoen tokens.
Wat is het prijsverschil tussen GPT-5 en GPT-4?
Volgens de officiële prijsstelling van OpenAI kost GPT-5.2 $1,75 input / $14,00 output per miljoen tokens. De traditionele GPT-4 kost $30,00 input / $60,00 output. GPT-5.2 is aanzienlijk goedkoper (94% minder input, 77% minder output) en biedt tegelijkertijd betere prestaties.
Zijn batch-API's echt 50% goedkoper?
Ja. Zowel OpenAI als Amazon Bedrock bieden 50%-kortingen voor batchverwerking met een doorlooptijd van 24 uur. De batchprijzen van OpenAI laten zien dat GPT-5.2 daalt naar $0.875 input / $7.00 output, vergeleken met de standaard $1.75 / $14.00. Voor alle niet-urgente workloads is het aan te raden batchverwerking te gebruiken.
Wat zijn de kosten van promptcaching?
OpenAI rekent 10% aan standaard invoerkosten voor gecachede tokens. GPT-5.2 gecachede invoer kost $0,175 in plaats van $1,75 voor reguliere invoer. Anthropic biedt 90% korting op cache-hits, maar brengt kosten in rekening voor cache-schrijfbewerkingen. Claude Opus 4.6 cache-schrijfbewerkingen kosten $6,25-$10,00 per miljoen tokens, afhankelijk van de duur, terwijl cache-hits $0,50 kosten in plaats van $5,00 voor standaard invoer.
Hoe bereken ik het tokengebruik voor mijn applicatie?
Gebruik tokenisatietools die specifiek zijn voor uw aanbieder. OpenAI biedt bijvoorbeeld de TikToken-bibliotheek aan. Over het algemeen komt één token overeen met ongeveer vier tekens of 0,75 woorden. Een document van 1.000 woorden bevat ongeveer 1.333 tokens. Test uw daadwerkelijke prompts en antwoorden met tokenisatietools om een nauwkeurige telling te krijgen voordat u de kosten inschat.
Is Claude duurder dan GPT?
Dat hangt af van de vergeleken modellen. Claude Opus 4.6 ($5.00 input) kost meer dan GPT-5.2 ($1.75 input), maar minder dan GPT-5.2 Pro ($21.00 input). De outputkosten laten grotere verschillen zien: Claude Opus rekent $25.00 output tegenover $14.00 voor GPT-5.2. De agressieve cachingkortingen van Claude (90% korting) kunnen het echter goedkoper maken voor applicaties met veel contexthergebruik.
Wat is het meest kosteneffectieve model voor chatbots?
Voor algemene klantenservice-chatbots bieden de GPT-4.1 Mini ($0.20-ingang / $0.80-uitgang) of de GPT-5 Mini ($0.25-ingang / $2.00-uitgang) de beste balans tussen kwaliteit en kosten. Voor eenvoudigere FAQ-bots is de GPT-5 Nano ($0.025-ingang / $0.20-uitgang) een goede keuze. Implementeer intelligente routering om de nano/mini-modellen te gebruiken voor eenvoudige vragen en upgrade alleen naar de vlaggenschipmodellen wanneer de complexiteit dit vereist.
Uw LLM API-beslissing nemen
Prijs mag niet uw enige overweging zijn. Modelkwaliteit, latentie, contextvenstergrootte en het integratie-ecosysteem zijn allemaal van belang.
Maar inzicht in kostenstructuren helpt je de veelvoorkomende valkuil te vermijden van te veel uitgeven aan functionaliteit die je niet nodig hebt. De meeste toepassingen halen 90% van de waarde uit middenklasse modellen voor slechts 2% van de prijs van topmodellen.
Begin met deze stappen:
Breng eerst uw daadwerkelijke gebruikspatronen in kaart. Houd het aantal tokens, de lengte van de reacties en de complexiteit van de query's bij voor uw specifieke gebruikssituatie. Echte data zijn beter dan aannames.
Ten tweede, test meerdere aanbieders op uw daadwerkelijke werklast. Prestatiebenchmarks zijn niet altijd representatief voor uw specifieke situatie. Voer A/B-tests uit om zowel de kwaliteit als de kosten te meten.
Ten derde, implementeer kostenbeheersing vóór het opschalen. Stel budgetwaarschuwingen in, schakel caching in en routeer query's intelligent. Deze optimalisaties leveren grotere besparingen op dan het overstappen naar een andere provider.
Het prijslandschap voor lasergeleide lasertechnologie (LLM) zal voortdurend veranderen. Er komen maandelijks nieuwe modellen op de markt, de prijzen schommelen en de mogelijkheden verbeteren constant. Maar de basisprincipes blijven consistent.
Begrijp tokengebaseerde prijsstelling. Monitor het daadwerkelijke gebruik. Stem de mogelijkheden van het model af op de taakvereisten. Optimaliseer voor hergebruik van de cache. Gebruik batchverwerking waar mogelijk.
Organisaties die kostenoptimalisatie toepassen, kunnen aanzienlijk meer besparen door een geoptimaliseerde modelselectie en gebruikspatronen dan organisaties die simpelweg een leverancier kiezen en API's tegen de volle prijs aanroepen. Dat is het verschil tussen duurzame AI-implementatie en budgetoverschrijdende experimenten die uiteindelijk worden stopgezet.
Klaar om uw LLM-uitgaven te optimaliseren? Begin met een analyse van uw huidige verbruik en implementeer slimme promptroutering. De besparingen lopen snel op.