

Op basis daarvan hebben wij een end-to-end oplossing ontwikkeld Natuurlijke taalverwerking technieken en Deep Learning-modellen die gegevens uit verschillende bronnen verzamelen, verwerken, analyseren en weergeven en gebruikers in staat stellen semantische en syntactische zoekopdrachten uit te voeren, clusters van bedrijven te verkennen, vergelijkbare bedrijven te beoordelen en meer.
Om dit te doen, maakt onze oplossing gebruik van een robuuste scrapper om informatie uit openbare gegevensbronnen te extraheren en deze vervolgens samen te voegen in een database die de volgende velden bevat: bedrijfsnaam, registratiedatum, bedrijfsstatus (actief/inactief) en beschrijving van de commerciële activiteit. . Door gebruik te maken van een component die gebruik maakt van diepgaande leermodellen, zogenaamde vooraf getrainde netwerken zoals meertalige BERT, vectoriseert onze oplossing vervolgens de beschrijvingen van bedrijven, waardoor clustering van entiteiten mogelijk wordt gemaakt op basis van hun semantische gelijkenis. Bovendien kunnen gebruikers semantische zoekopdrachten uitvoeren door dezelfde aanpak te gebruiken: het vectoriseert het ingevoerde trefwoord en zoekt vervolgens naar de semantisch meest nabije beschrijving in de database. De gebruiker kan ook de grootte van deze clusters bepalen en de drempel voor semantische gelijkenis definiëren. Ten slotte maakt de oplossing het ook mogelijk om financiële gegevens te extraheren en samen te voegen om te zien hoe relevante bedrijven (individueel of als groep) zich in de loop van de tijd ontwikkelen en al deze informatie in een pdf-rapport te exporteren.
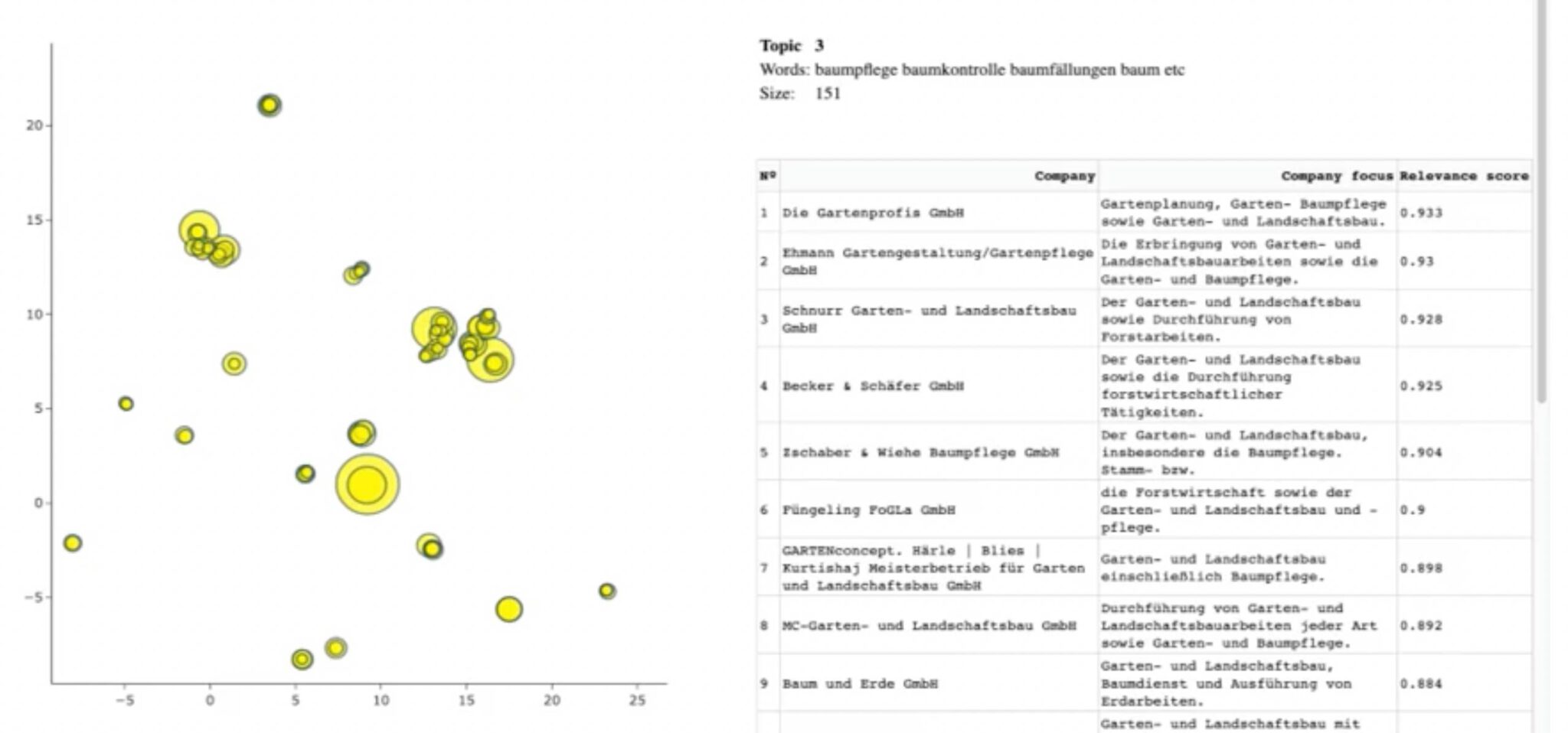
Deze afbeelding toont het dashboard van de tool (de linkerkant toont clusters van entiteiten gegroepeerd op hun semantische gelijkenis. De rechterkant toont de lijst met bedrijven binnen het geselecteerde cluster)