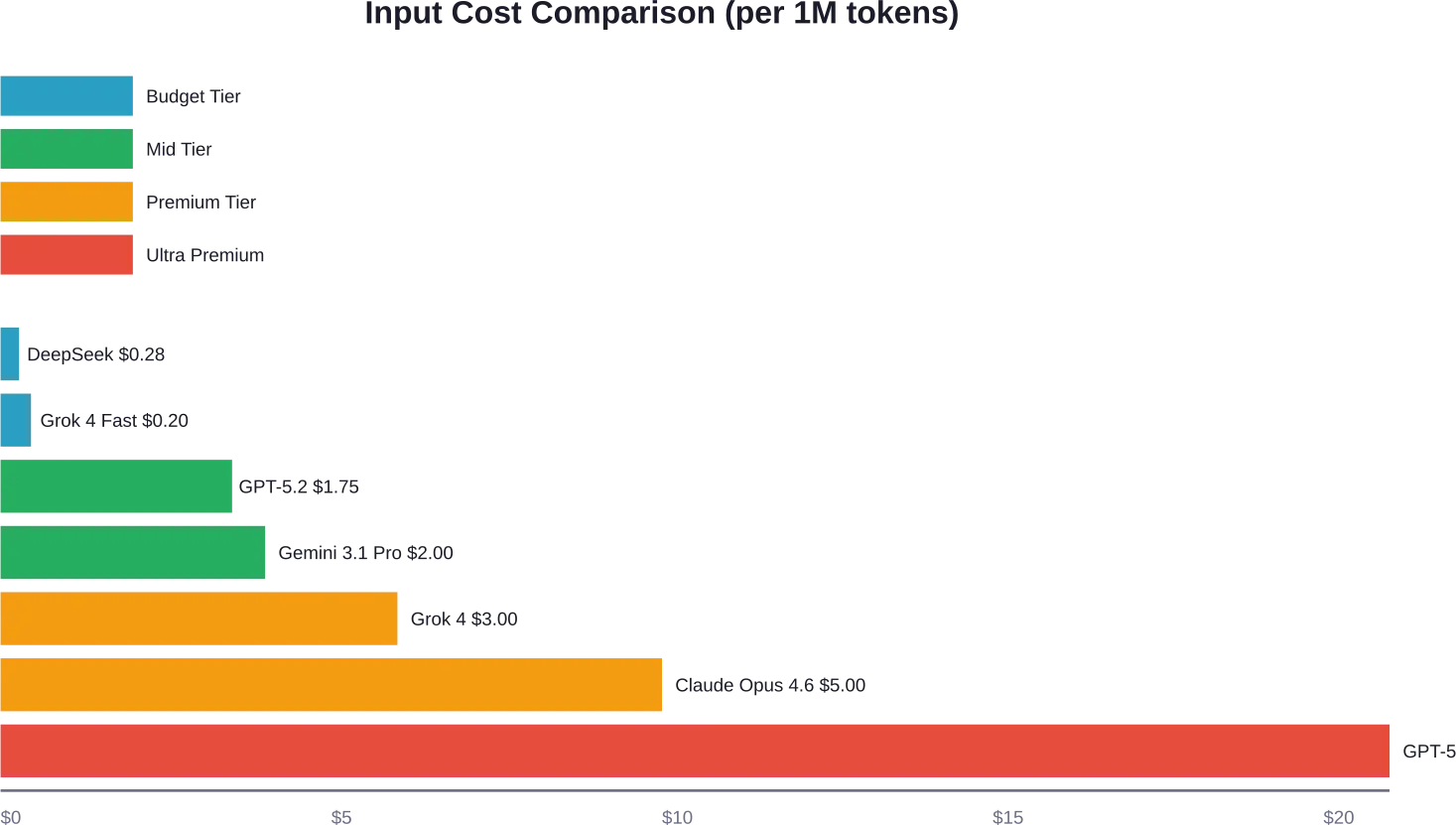
Resumen rápido: En 2026, los precios de las API de LLM varían drásticamente entre los proveedores, desde el económico precio de DeepSeek de $0,28 por millón de tokens hasta el de GPT-5.2 Pro de OpenAI de $21 por millón de tokens de entrada. Comprender los modelos de precios basados en tokens, los costos ocultos como el almacenamiento en caché y las incrustaciones, y las estrategias de optimización puede reducir los gastos entre 30 y 90% manteniendo el rendimiento.
El mercado de las API para modelos de lenguaje a gran escala ha experimentado un crecimiento explosivo. Actualmente, más de 300 modelos compiten por captar la atención de los desarrolladores, cada uno con estructuras de precios muy diferentes.
Elegir el proveedor equivocado puede suponer un gasto excesivo de miles de dólares mensuales. Algunas fuentes sugieren que las organizaciones pueden pagar de más por las API de LLM, aunque los porcentajes exactos de sobrepago varían según el caso de uso, simplemente porque no han optimizado la selección de modelos ni los patrones de uso.
Esta comparativa desglosa los precios actuales de los principales proveedores, revela costes ocultos que pillan desprevenidos a los equipos y muestra exactamente adónde va su dinero cuando llama a una API de LLM.
Comprensión de los modelos de precios de la API de LLM
La mayoría de las API de LLM cobran por token. Pero, ¿qué significa eso realmente para tu presupuesto?
Un token representa aproximadamente cuatro caracteres de texto. La palabra "understanding" contiene alrededor de tres tokens. Tus llamadas a la API se facturan por separado para los tokens de entrada (lo que envías) y los tokens de salida (lo que genera el modelo).
Los tokens de salida suelen costar entre 3 y 6 veces más que los tokens de entrada. Esta asimetría es importante al generar respuestas largas.
Los tres niveles principales de precios
Los proveedores estructuran sus precios en torno a tres modelos de consumo:
- Bajo demanda (estándar): Pago por token sin compromisos. El costo por token es el más alto, pero ofrece máxima flexibilidad. Ideal para la creación de prototipos o cargas de trabajo impredecibles.
- Procesamiento por lotes: Envíe solicitudes que se procesan de forma asíncrona en 24 horas. Tanto Amazon Bedrock como OpenAI ofrecen descuentos 50% para solicitudes por lotes en comparación con los precios bajo demanda. Ideal para tareas no urgentes como el análisis de datos o la generación de contenido.
- Rendimiento aprovisionado: Reserva capacidad dedicada con tiempos de respuesta garantizados. Facturación por hora o mensual. Ideal para procesar grandes volúmenes de datos de forma constante y requerir una latencia predecible.
OpenAI ha introducido niveles adicionales en su última estructura de precios. Su nivel "Flex" ofrece descuentos moderados, mientras que "Priority" garantiza un procesamiento más rápido durante los períodos de mayor uso.
Desglose de precios de los principales proveedores
Dejemos de lado el marketing y veamos las cifras reales de las páginas de precios oficiales.
Precios de la API de OpenAI (2026)
La oferta de OpenAI se ha ampliado significativamente. Según la página oficial de precios de OpenAI, esto es lo que cobran por millón de tokens:
| Modelo | Costo de entrada | Entrada almacenada en caché | Costo de producción |
|---|---|---|---|
| GPT-5.2 Pro | $21.00 | N / A | $168.00 |
| GPT-5.2 | $1.75 | $0.175 | $14.00 |
| GPT-5 Mini | $0.25 | $0.025 | $2.00 |
| GPT-5 Nano | $0.025 | $0.0025 | $0.20 |
| GPT-4.1 | $1.00 | N / A | $4.00 |
| GPT-4o | $1.25 | N / A | $5.00 |
El modelo insignia GPT-5.2 está diseñado para el razonamiento complejo y los flujos de trabajo basados en agentes. GPT-5 Nano ofrece la opción más económica dentro de la gama actual de OpenAI, ideal para tareas sencillas de clasificación o extracción.
Su API por lotes reduce estos precios a la mitad. El precio por lotes de GPT-5.2 cuesta $0.875 de entrada y $7.00 de salida por millón de tokens, lo que representa un descuento de 50% con respecto al precio estándar.
Precios de Claude Antropológico
Los modelos Claude de Anthropic siguen una arquitectura diferente con capacidades destacadas de almacenamiento en caché de contexto. Según su documentación oficial:
| Modelo | Entrada base | Aciertos de caché | Producción |
|---|---|---|---|
| Claude Opus 4.6 | $5.00 | $0.50 | $25.00 |
| Claude Opus 4.5 | $5.00 | $0.50 | $25.00 |
| Claude Opus 4.1 | $15.00 | $1.50 | $75.00 |
El sistema de almacenamiento en caché de Claude ofrece un descuento de 90% al reutilizar el contexto. Si estás creando un chatbot que consulta repetidamente la misma base de conocimientos, un coste de caché de $0,50 por millón de tokens, frente a $5,00 para entradas nuevas, supone un ahorro considerable.
Anthropic también ofrece procesamiento por lotes con un descuento del 501% sobre las tarifas estándar, igualando la estructura de descuentos de OpenAI.
Google Vertex AI (modelos Gemini)
La plataforma Vertex AI de Google aloja su familia de productos Gemini, además de modelos de terceros. Los precios que aparecen en su página oficial de Vertex AI son los siguientes:
| Modelo | Entrada ≤200K Tokens | Entrada >200K | Producción |
|---|---|---|---|
| Vista previa de Gemini 3.1 Pro | $2.00 | $4.00 | $12.00 |
| Géminis 3.1 Flash | Precios de nivel inferior | Consulte la documentación oficial. | Consulte la documentación oficial. |
Google aplica umbrales de precios para consultas de contexto extenso. Las consultas que superan los 200 000 tokens se facturan a tarifas más altas para todos los tokens de la solicitud. Gemini 2.5 Pro incluye 10 000 sugerencias de búsqueda integradas (integración con la búsqueda web) diarias sin costo alguno, y luego cobra $35 por cada 1000 sugerencias adicionales.
El coste de su servicio de conexión web empresarial es de 1 TP4T45 por cada 1000 consultas conectadas. Estas funciones de búsqueda avanzadas se acumulan rápidamente si no se realiza un seguimiento del uso.
Plataforma multimodelos Amazon Bedrock
AWS Bedrock agrega modelos de múltiples proveedores bajo una facturación unificada. Según su actualización de precios de febrero de 2026:
- Claude 3.5 Soneto comienza con $3 de entrada / $15 de salida por millón de tokens
- Gemma 3 4B cuesta $0.04 de entrada / $0.08 de salida
- Gemma 3 12B funciona con entrada $0.09 y salida $0.18.
Bedrock incluye inferencia por lotes a 50% sobre las tarifas bajo demanda. Su modelo de rendimiento aprovisionado cobra por hora de unidad de modelo en lugar de tokens, con condiciones de compromiso que ofrecen descuentos para contratos de 1 o 6 meses.
Amazon también ofrece sus modelos Nova a precios competitivos, aunque las tarifas específicas varían según la región.
Opciones económicas: DeepSeek y xAI
La empresa china DeepSeek ha revolucionado el mercado con precios agresivos en sus modelos V3.2-Exp. Los modelos V3.2-Exp de DeepSeek se cotizan a $0.60 por millón de tokens de entrada (cache-fall) y $0.40 para tokens de salida de razonamiento según los datos de precios disponibles con fallos de caché, y $0.40 para tokens de salida de razonamiento.
xAI lanzó Grok 4 con un costo de entrada de $3 y una salida de $15 por millón de tokens. Su variante más rápida, Grok 4.1 Fast, cuesta $0.20 de entrada y $0.50 de salida, y está dirigida a desarrolladores que priorizan la velocidad sobre la máxima capacidad.
Costos ocultos que inflan su factura
El coste de los tokens acapara los titulares. Pero varios cargos menos evidentes pueden duplicar tu gasto real.
Almacenamiento en caché de avisos y ventanas de contexto
Las ventanas de contexto amplias suenan muy bien hasta que te das cuenta de que estás pagando por cada token cada vez. Tanto OpenAI como Anthropic ofrecen almacenamiento en caché instantáneo para reducir los costos de contexto repetidos.
Según la documentación de OpenAI, los tokens de entrada en caché cuestan 90% menos que los de entrada estándar. Para GPT-5.2, los tokens en caché cuestan $0.175 frente a $1.75 para los no almacenados en caché.
¿El inconveniente? Las escrituras en caché cuestan dinero. Los precios de Anthropic muestran que las tasas de escritura en caché varían según la duración: escrituras de caché de 5 minutos a $6,25 por millón de tokens y escrituras de 1 hora a $10 por millón para Claude Opus 4.6.
Si no reutilizas el contexto con la suficiente frecuencia, el almacenamiento en caché cuesta más de lo que ahorra.
Incrustaciones y búsqueda vectorial
La creación de un sistema RAG (generación aumentada por recuperación) requiere la generación de incrustaciones. Estos costos operan independientemente del precio de la inferencia principal.
Amazon Titan Text Embeddings V2 cuesta $0.00002 por cada 1000 tokens de entrada, según la documentación de AWS. Parece barato hasta que se trata de incrustar millones de documentos.
También se paga por el almacenamiento de vectores. El motor Vertex AI RAG de Google incluye tarifas por la ingesta de datos, el análisis LLM para la segmentación y las operaciones de búsqueda de vectores, además de los costos de inferencia del modelo.
Conexión a tierra y uso de herramientas
Google cobra $35 por cada 1000 consultas (búsquedas web) en Gemini después de agotar la cuota diaria gratuita. La búsqueda web en Claude cuesta $10 por cada 1000 búsquedas, según la documentación oficial de precios de Anthropic para Vertex AI.
Estas funciones mejoran drásticamente la precisión de la información en tiempo real. Sin embargo, si se utilizan con frecuencia, también aumentan los costos típicos entre 10 y 151 TP3T.
Límites de velocidad y regulación del flujo de datos
Los niveles gratuitos y los de menor uso imponen límites de velocidad estrictos. El sistema de niveles de OpenAI muestra que los usuarios del Nivel 1 reciben 500 solicitudes por minuto con 500 000 tokens por minuto en GPT-5.2. Los usuarios del Nivel 5 acceden a 40 millones de TPM.
Alcanzar los límites de solicitudes implica fallos y reintentos, lo que supone un desperdicio de tokens y tiempo de los desarrolladores. Actualizar los planes requiere un gasto mensual mínimo, pero elimina los cuellos de botella.

Construya la arquitectura LLM adecuada con IA superior
Elegir entre las distintas API de LLM no se trata solo del precio de los tokens. Los requisitos de rendimiento, el diseño de las indicaciones, la arquitectura del sistema y la estrategia de escalabilidad influyen en el coste total de una aplicación.
IA superior Ayuda a las empresas a diseñar sistemas LLM listos para la producción y a elegir la arquitectura más adecuada para su caso de uso.
Su equipo puede ayudar con:
- cómo seleccionar los proveedores de LLM adecuados
- Diseño de arquitecturas LLM escalables
- Optimización de las indicaciones y el uso de tokens
- Integración de LLM en sistemas existentes
Si está planificando un producto impulsado por LLM, IA superior puede ayudar a diseñar la arquitectura técnica e implementar la solución.
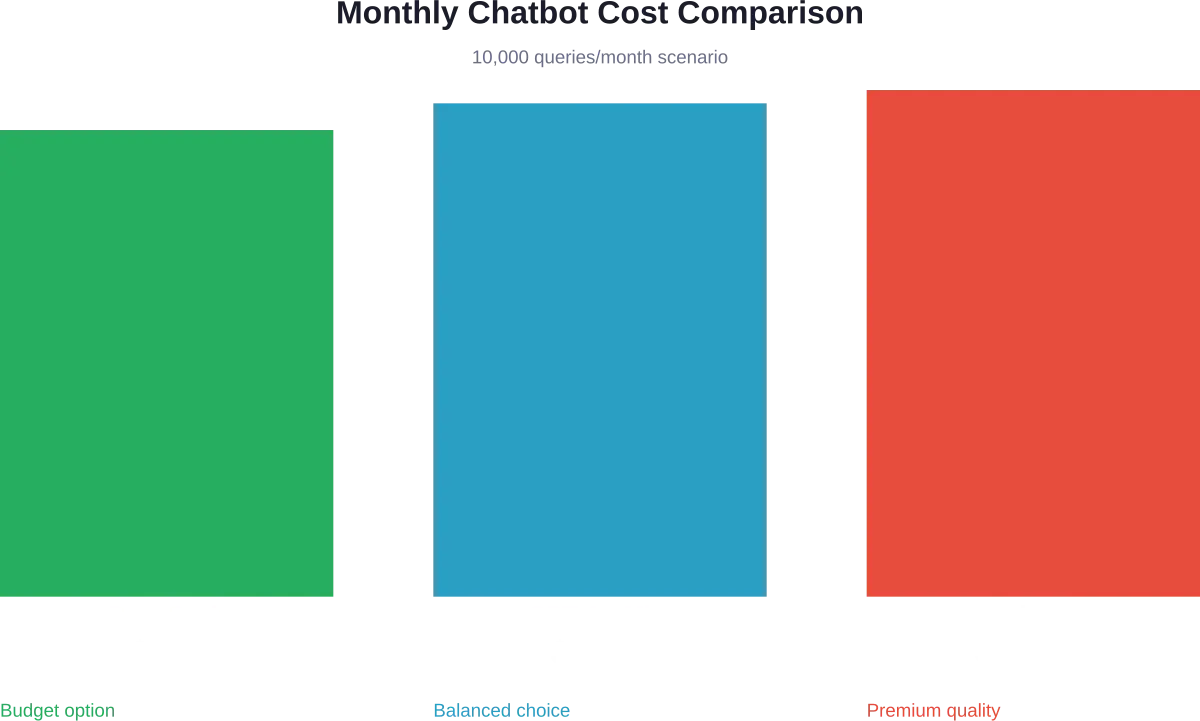
Análisis de costes en el mundo real: Ejemplo de chatbot
Vamos a modelar los costes reales de un chatbot de atención al cliente que gestiona 10.000 consultas al mes.
Suposiciones basadas en patrones típicos de centros de llamadas según la documentación de AWS:
- 5 millones de tokens para la base de conocimientos (pago único + actualizaciones)
- 50.000 incrustaciones para búsqueda semántica
- Promedio de 100 tokens por consulta de usuario.
- Promedio de 100 tokens por respuesta
- Total: 2 millones de tokens mensuales (1 millón de entrada, 1 millón de salida)
OpenAI GPT-4.1 Mini
- Entrada: 1M tokens × $0.20 = $200
- Salida: 1M tokens × $0.80 = $800
- Incrustaciones: 50K × $0.00002 = $1
- Total mensual: ~$1.001
Claude Opus 4.6 con almacenamiento en caché
- Base de conocimientos almacenada en caché: 90% aciertos de caché
- Entrada en caché: 900K × $0.50 = $450
- Entrada nueva: 100K × $5.00 = $500
- Salida: 1M × $25.00 = $25,000
- Total mensual: ~$25,950
Un momento, eso es 26 veces más caro. Pero aquí está la clave: Claude Opus ofrece una calidad significativamente superior en tareas de razonamiento complejas. El precio adicional se justifica en aplicaciones críticas donde la precisión es más importante que el costo.
DeepSeek V3.2 Opción económica
- Entrada: 1M × $0.28 = $280
- Salida: 1M × $0.40 = $400
- Incrustaciones: $1
- Total mensual: ~$681
DeepSeek ofrece la opción más económica, pero con una fiabilidad menos probada para casos de uso empresarial. Las pruebas de rendimiento muestran que obtiene puntuaciones dentro de los 20% de los mejores modelos comerciales en pruebas estándar, lo que lo hace viable para aplicaciones donde el costo es un factor importante.
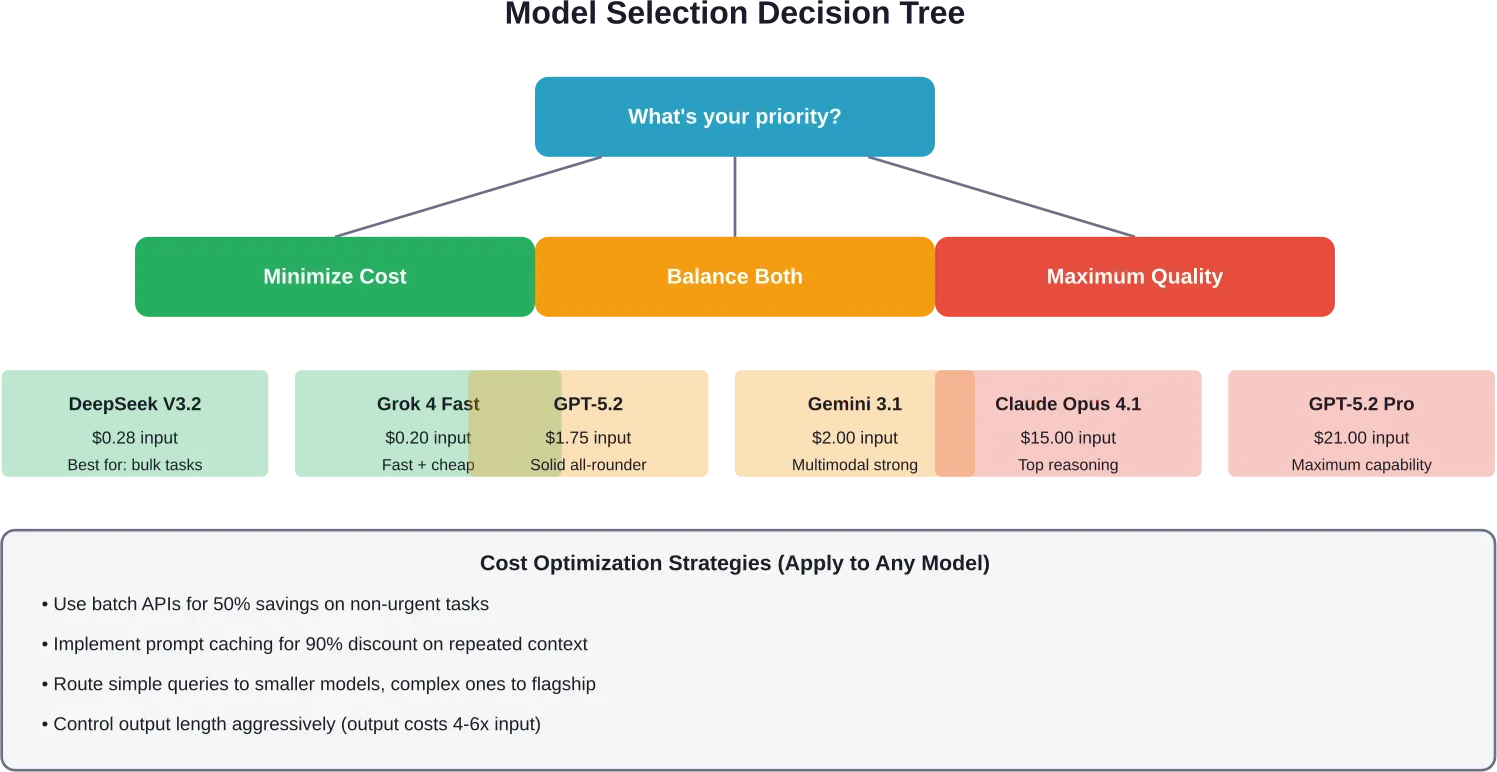
Estrategias de optimización de costes que realmente funcionan.
Los equipos que gestionan eficazmente los costes de los programas de Maestría en Derecho (LLM) siguen varios patrones probados.
Enrutamiento inteligente de avisos
No todas las consultas requieren tu modelo más potente. Dirige las preguntas sencillas a modelos más pequeños y los razonamientos complejos a las opciones principales.
La documentación de AWS indica que el enrutamiento inteligente de solicitudes puede reducir los costos hasta en un 301% sin comprometer la precisión. Implemente una lógica de clasificación que asigne las consultas a los modelos apropiados según su complejidad.
Amazon Bedrock ofrece esta funcionalidad a través de su función de enrutamiento inteligente de sugerencias, que selecciona automáticamente los modelos óptimos para cada solicitud.
Almacenamiento en caché de avisos agresivo
Estructure sus indicaciones para maximizar la reutilización de la caché. Coloque el contexto estable (instrucciones del sistema, extractos de la base de conocimientos) al principio, donde pueda almacenarse en caché.
El sistema de almacenamiento en caché de Anthropic ofrece una reducción de costos de hasta 90% en tokens almacenados en caché en comparación con los precios de entrada estándar. Para aplicaciones que hacen referencia a un contexto consistente, esta única optimización puede reducir el gasto a la mitad.
Procesamiento por lotes para tareas no urgentes
Tanto OpenAI como Amazon Bedrock ofrecen descuentos 50% para solicitudes de API por lotes. Cualquier trabajo que pueda procesarse en 24 horas debería enrutarse a través de los puntos finales de procesamiento por lotes.
La generación de contenido, el análisis de datos y la creación de datos de capacitación funcionan perfectamente como operaciones por lotes. Las organizaciones pueden lograr importantes ahorros de costos mediante el procesamiento por lotes, que generalmente ofrece descuentos 50% en comparación con los precios bajo demanda.
Gestión de tokens de salida
Los tokens de salida cuestan entre 4 y 6 veces más que los de entrada. Controle la longitud de la respuesta de forma rigurosa mediante los parámetros max_tokens y la ingeniería de mensajes.
Solicitar respuestas de 500 tokens cuando 200 tokens son suficientes supone un derroche de dinero en cada llamada. Establezca límites de salida conservadores y amplíelos solo para consultas que realmente requieran respuestas más largas.
Selección de modelos por tipo de tarea
Adaptar las capacidades del modelo a los requisitos:
- Clasificación/extracción simple: Utilice modelos nano/mini (GPT-5 Nano con entrada $0.025 y salida $0.20).
- Respuestas generales del chatbot: Modelos de gama media (GPT-4.1 Mini, variantes de Claude Sonnet)
- Razonamiento/codificación complejos: Modelos insignia (GPT-5.2, Claude Opus)
- Procesamiento a granel: Utilice siempre las API por lotes para ahorrar en la normativa 50%.
Un análisis de costo-beneficio sugiere que las organizaciones pueden alcanzar el punto de equilibrio en la implementación local de LLM, dependiendo de los niveles de uso y las necesidades de rendimiento, que a su vez dependen del volumen de uso y los costos de infraestructura. Sin embargo, para la mayoría de los equipos, optimizar el uso de la API en la nube ofrece un mejor retorno de la inversión que el autoalojamiento.
Herramientas de monitoreo y gestión de costos
No se puede optimizar lo que no se mide. Existen varios enfoques que ayudan a realizar un seguimiento del gasto en LLM:
Paneles de control nativos del proveedor
OpenAI, Anthropic y Google ofrecen paneles de control de uso que muestran el consumo de tokens por modelo, proyecto y período de tiempo. Estos paneles funcionan, pero carecen de comparaciones entre proveedores.
La API de uso y coste de Anthropic permite acceder programáticamente a los datos de consumo con una granularidad de entre 1 minuto y 1 día. Todos los costes se informan en USD como cadenas decimales en centavos.
Plataformas de monitoreo de terceros
Helicone y servicios similares agregan el uso de múltiples proveedores de LLM. Realizan un seguimiento de los costos por solicitud, identifican las consultas costosas y alertan sobre los umbrales de presupuesto.
Estas plataformas suelen cobrar entre 1 y 21 TP3T de gasto en LLM o tarifas mensuales fijas. Vale la pena para equipos que utilizan varios proveedores o que necesitan una atribución detallada por usuario/proyecto.
Configurar alertas de presupuesto
La mayoría de los proveedores admiten límites de gasto y alertas. Configure estos elementos antes de la implementación en producción:
- Establecer límites máximos para los entornos de desarrollo/pruebas
- Configure alertas en los umbrales de presupuesto 50%, 75% y 90%.
- Implementar disyuntores que pausen las solicitudes cuando se alcancen los límites.
AWS Cost Explorer permite realizar un seguimiento del presupuesto para el uso de Bedrock. Google Cloud ofrece una funcionalidad similar para el gasto en Vertex AI.
Tendencias emergentes en la fijación de precios de los másteres en derecho (LLM)
El panorama competitivo sigue evolucionando rápidamente.
Carrera a la baja en las tareas relacionadas con las materias primas
Los precios básicos de generación y clasificación de texto han bajado entre 80 y 90 TP3T desde 2023. Modelos como GPT-5 Nano (1 TP4T0,025 de entrada) y DeepSeek (1 TP4T0,28 de entrada) hacen que los precios se acerquen a cero para tareas sencillas.
Esta mercantilización implica que la diferenciación se basa en capacidades especializadas —razonamiento, comprensión multimodal, uso de herramientas— en lugar de en la generación básica de texto.
Precios Premium para Modelos de Razonamiento
La tendencia opuesta se observa en el razonamiento avanzado. El GPT-5.2 Pro con entrada $21 y salida $168 tiene un precio considerablemente superior al de los modelos estándar.
Estos modelos de "pensamiento lento" dedican más tiempo de procesamiento a razonar antes de responder, lo que justifica precios más elevados para problemas complejos donde la precisión importa más que la velocidad.
Ventana de contexto Economía
Los proveedores cobran tarifas premium por consultas de contexto extenso. El umbral de más de 200.000 tokens de Google activa precios más altos para todos los tokens de esa solicitud.
A medida que se amplían las ventanas de contexto (GPT-5.2 de OpenAI admite 400 000 tokens), es de esperar que la tarificación por niveles basada en el uso del contexto se convierta en la norma. La gestión eficiente del contexto mediante la creación de resúmenes y el almacenamiento en caché cobrará mayor importancia.
Precios de modelos especializados
Los modelos especializados en sectores específicos (médico, legal, financiero) tienen precios más elevados debido a la formación especializada que requieren. Se prevé una expansión continua de los modelos especializados, cuyos precios serán entre dos y tres veces superiores a los de los modelos de uso general.
¿Qué proveedor debería elegir?
No existe una respuesta universal, pero aquí presentamos un marco de decisión basado en prioridades:
Para presupuestos ajustados
DeepSeek V3.2 ofrece los costos por token más bajos manteniendo una calidad razonable. Grok 4 Fast ofrece otra opción económica con una mejor infraestructura de soporte.
Combine modelos económicos para tareas sencillas con el uso estratégico de modelos premium para consultas críticas. Dirija 80% de tráfico a los modelos económicos y 20% a los costosos.
Para obtener la máxima calidad
OpenAI GPT-5.2 Pro y Claude Opus 4.1 representan el máximo nivel de calidad actual. Prepárese para pagar entre 10 y 30 veces más que por las opciones de gama media.
Solo se justifica cuando la precisión impacta directamente en los ingresos o el riesgo (análisis legales, aplicaciones médicas, infraestructura crítica).
Para un rendimiento equilibrado
GPT-5.2 ($1.75 de entrada) y Claude Opus 4.6 ($5.00 de entrada) son ideales para la mayoría de las aplicaciones de producción. Ofrecen un rendimiento sólido sin costes excesivos.
El Google Gemini 3.1 Pro, con una entrada de $2.00, ofrece un precio competitivo con excelentes capacidades multimodales.
Para usuarios de Google Cloud
Vertex AI proporciona acceso unificado a Gemini y a modelos de terceros. El ecosistema integrado simplifica la implementación si ya utiliza la infraestructura de GCP.
Aprovecha las 10.000 sugerencias diarias gratuitas de Gemini 2.5 Pro para aplicaciones con búsqueda mejorada.
Para entornos AWS
Bedrock ofrece la mayor variedad de modelos con facturación unificada. Es una excelente opción para organizaciones estandarizadas en AWS que desean acceder a Anthropic, Meta y otros proveedores a través de una única interfaz.
Preguntas frecuentes
¿Cuál es la API LLM más barata en 2026?
DeepSeek V3.2 ofrece actualmente el precio por token más bajo, aproximadamente $0.28 por millón de tokens de entrada y $0.40 por salida de razonamiento. Grok 4 Fast de xAI tiene un costo de $0.20 por entrada y $0.50 por salida. Para los usuarios de OpenAI, GPT-5 Nano cuesta $0.025 por entrada y $0.20 por salida por millón de tokens.
¿Cuánto cuesta GPT-5 en comparación con GPT-4?
Según los precios oficiales de OpenAI, GPT-5.2 cuesta $1.75 de entrada y $14.00 de salida por millón de tokens. La versión anterior de GPT-4 requiere $30.00 de entrada y $60.00 de salida. GPT-5.2 es considerablemente más económico (reducción de 94% en la entrada y de 77% en la salida) y ofrece un mejor rendimiento.
¿Son realmente más baratas las API por lotes según la sección 50%?
Sí. Tanto OpenAI como Amazon Bedrock ofrecen descuentos de 50% para el procesamiento por lotes con un plazo de entrega de 24 horas. Los precios de OpenAI para el procesamiento por lotes muestran que GPT-5.2 se reduce a $0.875 de entrada / $7.00 de salida en comparación con el estándar de $1.75 / $14.00. Cualquier carga de trabajo no urgente debería utilizar puntos finales de procesamiento por lotes.
¿Cuáles son los costos del almacenamiento en caché instantáneo?
OpenAI cobra 10% de costos de entrada estándar para tokens en caché. Los costos de entrada en caché de GPT-5.2 son $0.175 frente a $1.75 regulares. Anthropic ofrece descuentos de 90% en aciertos de caché, pero cobra por escrituras en caché. Las escrituras en caché de Claude Opus 4.6 cuestan entre $6.25 y $10.00 por millón de tokens, dependiendo de la duración, mientras que los aciertos de caché cuestan $0.50 frente a $5.00 de entrada base.
¿Cómo calculo el uso de tokens para mi aplicación?
Utilice herramientas de tokenización específicas del proveedor. OpenAI ofrece la biblioteca tiktoken. Generalmente, un token equivale a aproximadamente cuatro caracteres o 0,75 palabras. Un documento de 1000 palabras contiene aproximadamente 1333 tokens. Pruebe sus preguntas y respuestas reales con tokenizadores para obtener recuentos precisos antes de estimar los costos.
¿Claude cuesta más que GPT?
Depende de los modelos comparados. Claude Opus 4.6 ($5.00 de entrada) cuesta más que GPT-5.2 ($1.75 de entrada) pero menos que GPT-5.2 Pro ($21.00 de entrada). Los costos de salida muestran mayores diferencias: Claude Opus cobra $25.00 de salida frente a $14.00 para GPT-5.2. Sin embargo, los agresivos descuentos por caché de Claude (90% de descuento) pueden hacerlo más económico para aplicaciones con alta reutilización de contexto.
¿Cuál es el modelo más rentable para los chatbots?
Para chatbots de atención al cliente generales, GPT-4.1 Mini ($0.20 entrada / $0.80 salida) o GPT-5 Mini ($0.25 entrada / $2.00 salida) ofrecen el mejor equilibrio entre calidad y coste. Para bots de preguntas frecuentes más sencillos, GPT-5 Nano ($0.025 entrada / $0.20 salida) funciona bien. Implemente un enrutamiento inteligente para usar los modelos nano/mini en consultas sencillas y actualice a los modelos principales solo cuando la complejidad lo requiera.
Tomando la decisión sobre la API de LLM
El precio no debería ser el único factor a considerar. La calidad del modelo, la latencia, el tamaño de la ventana de contexto y el ecosistema de integración también son importantes.
Pero comprender las estructuras de costos ayuda a evitar la trampa común de gastar de más en funcionalidades innecesarias. La mayoría de las aplicaciones obtienen el 90% del valor de los modelos de gama media con un precio equivalente al 20% del precio de los modelos insignia.
Comience con estos pasos:
Primero, analiza tus patrones de uso reales. Registra el número de tokens, la duración de las respuestas y la complejidad de las consultas para tu caso de uso específico. Los datos reales son más fiables que las suposiciones.
En segundo lugar, prueba con varios proveedores en tu entorno de trabajo real. Los indicadores de rendimiento no siempre se corresponden con tu sector. Realiza pruebas A/B para medir tanto la calidad como el coste.
En tercer lugar, implemente controles de costos antes de escalar. Configure alertas de presupuesto, habilite el almacenamiento en caché y optimice el enrutamiento de consultas. Estas optimizaciones generan mayores ahorros que cambiar de proveedor.
El panorama de precios de los sistemas de gestión de aprendizaje automático (LLM) seguirá cambiando. Cada mes se lanzan nuevos modelos, los precios fluctúan y las funcionalidades mejoran constantemente. Pero los fundamentos se mantienen.
Comprenda los precios basados en tokens. Supervise el uso real. Adapte la capacidad del modelo a los requisitos de la tarea. Optimice la reutilización de la caché. Utilice el procesamiento por lotes siempre que sea posible.
Las organizaciones que implementan prácticas de optimización de costos pueden lograr ahorros significativos mediante la selección de modelos y patrones de uso optimizados, en comparación con aquellas que simplemente eligen un proveedor y comienzan a usar las API a precio completo. Esa es la diferencia entre una adopción sostenible de la IA y experimentos que desequilibran el presupuesto y terminan siendo cancelados.
¿Listo para optimizar el gasto de tu programa LLM? Empieza por auditar tu uso actual e implementar un enrutamiento inteligente de avisos. El ahorro se acumula rápidamente.