Descripción general: Los costos de alojamiento de LLM varían drásticamente según el modelo de implementación, desde $0.025 por millón de tokens para servicios API como GPT-5-nano de OpenAI hasta $1,500-$5,000 mensuales para infraestructura autoalojada. Las organizaciones con más de 50,000 solicitudes diarias a menudo logran ahorros de costos de 25-50% al autoalojar, mientras que las operaciones más pequeñas se benefician de precios de API de pago por uso. Los requisitos de hardware escalan con el tamaño del modelo: los modelos de 7B parámetros necesitan aproximadamente 3.5 GB de VRAM con cuantización de 4 bits, mientras que los modelos de 70B requieren 35 GB o configuraciones multi-GPU.
El gasto empresarial en grandes modelos de lenguaje se ha disparado. Solo los costes de las API de modelos se duplicaron hasta alcanzar los 8.400 millones de dólares en 2025, y la mayoría de las empresas planean aumentar aún más sus presupuestos de IA este año.
Pero aquí está la clave: no todas las organizaciones deberían pagar de la misma manera. La rentabilidad del alojamiento de programas de maestría en derecho (LLM) depende totalmente de la escala, los patrones de uso y los requisitos técnicos. Los servicios API ofrecen una comodidad increíble, pero el autoalojamiento puede reducir los costos en 501 TP3T o más a una escala suficiente.
Esta guía desglosa los costes reales de cada una de las principales opciones de alojamiento web, desde las API comerciales hasta la infraestructura totalmente autogestionada.
Costes de LLM basados en API: Precios de pago por token
Los servicios API comerciales funcionan con modelos de pago por uso, cobrando en función de los tokens de entrada y salida procesados. Según la documentación de precios de OpenAI de 2026, los costes varían drásticamente entre los diferentes modelos.
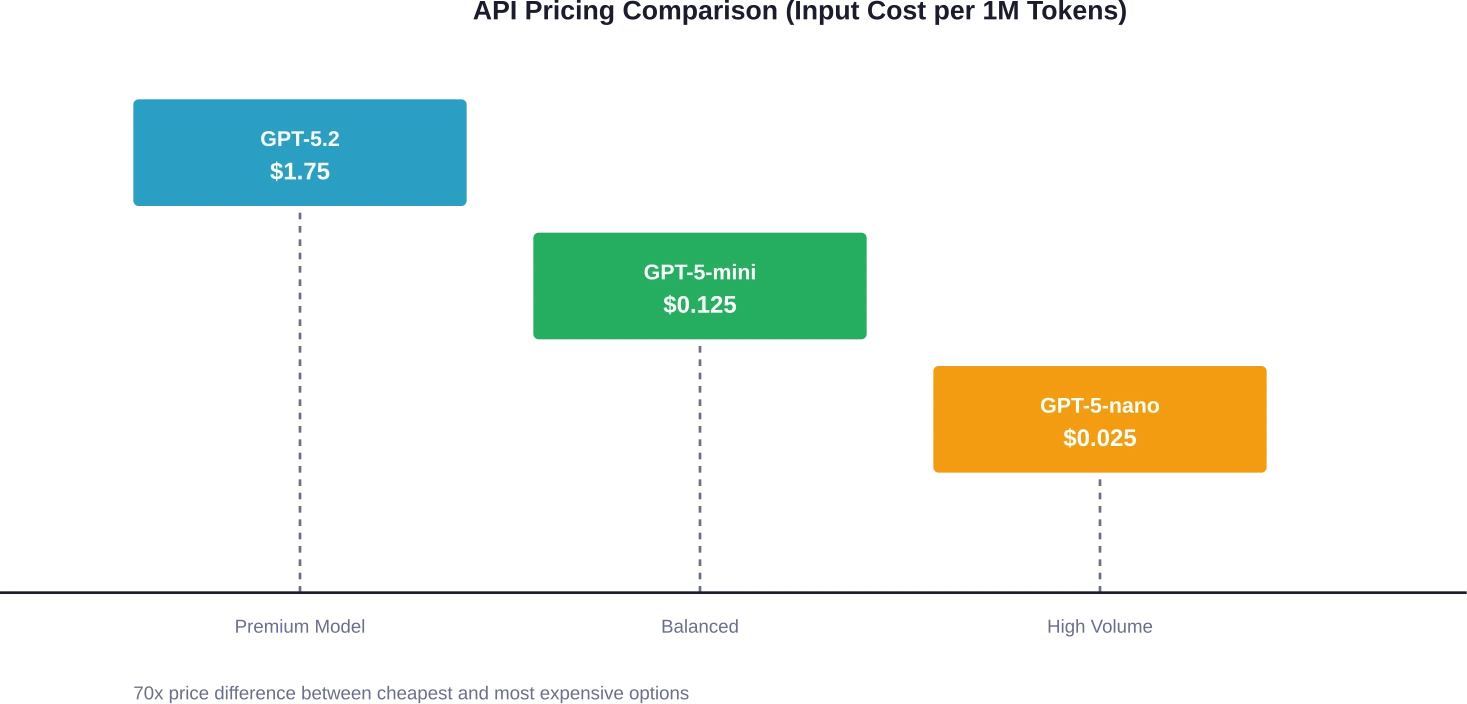
GPT-5.2 tiene un costo de $1.75 por millón de tokens de entrada y $14.00 por millón de tokens de salida. Este es el modelo insignia diseñado para tareas complejas de razonamiento y codificación. En comparación, GPT-5-mini cuesta solo $0.125 por millón de tokens de entrada y $1.00 por millón de tokens de salida, lo que representa un costo 14 veces menor tanto para entradas como para salidas.
La versión más reciente, GPT-5-nano, redujo aún más su precio a $0,025 por millón de tokens de entrada y $0,20 por millón de tokens de salida. Para los equipos que ejecutan tareas sencillas de alto volumen, esto representa una reducción de costos de 80% en comparación con GPT-5-mini.
Ahorro de datos de entrada en caché
OpenAI introdujo un sistema de precios para entradas en caché que cobra solo 10% de las tarifas estándar para contenido repetido. Las entradas en caché de GPT-5.2 cuestan $0.175 por millón de tokens en lugar de $1.75. Para aplicaciones con indicaciones del sistema o documentos de referencia consistentes, esta optimización es importante.
La API Batch reduce los costos en 50% para cargas de trabajo que no son en tiempo real y que se procesan de forma asíncrona en un plazo de 24 horas.
Precios de Anthropic y Google
Los precios de Google Vertex AI para los modelos Gemini 3 (a partir de febrero de 2026) muestran estructuras similares basadas en tokens. Se aplican precios estándar para solicitudes con menos de 200 000 tokens de entrada, con tarifas diferentes para contextos más grandes y entradas almacenadas en caché.
Estos servicios comerciales solo cobran por las solicitudes exitosas que devuelven códigos de respuesta 200. Las solicitudes fallidas no generan costos, lo que evita la facturación por errores.
Costos de alojamiento en la plataforma en la nube
AWS SageMaker, Google Vertex AI y Azure Foundry ofrecen alojamiento gestionado de LLM con mayor control que los servicios de API puros. Estas plataformas cobran por los recursos informáticos en lugar de por los tokens.
Estructura de precios de AWS SageMaker
Según la documentación de AWS actualizada en febrero de 2026, SageMaker cobra por las horas de instancia, el almacenamiento y la transferencia de datos. El nivel gratuito de AWS incluye 250 horas de instancias ml.t3.medium durante los dos primeros meses, además de 4000 solicitudes de API gratuitas al mes.
Para cargas de trabajo de producción, el precio de las instancias varía según la potencia de la GPU. Las organizaciones que ejecutan inferencia en instancias ml.g5.xlarge (GPU NVIDIA A10G) pagan tarifas diferentes según la región y el nivel de compromiso.
Las instancias reservadas de AWS ofrecen ahorros significativos en comparación con los precios bajo demanda. Los compromisos de reserva por un año pueden reducir sustancialmente los costos para cargas de trabajo predecibles.
Economía de la IA de Google Vertex
La documentación de precios de Vertex AI de Google muestra cargos basados en horas de procesamiento, tiempo de implementación del modelo y solicitudes de predicción. Los modelos que no se implementan correctamente no generan cargos, y los fallos de entrenamiento (excepto las cancelaciones iniciadas por el usuario) no se facturan.
Este modelo basado en el consumo protege contra el pago por operaciones fallidas, lo cual es importante al experimentar con configuraciones del modelo.
Costos de infraestructura para programas de LLM autogestionados
El autoalojamiento traslada los costos de las tarifas de uso variables a una inversión fija en infraestructura. Para las organizaciones con más de 50 000 solicitudes diarias, esto suele ser económicamente viable.
Los requisitos de hardware dependen completamente del tamaño del modelo. Como regla general, se necesitan aproximadamente 0,5 GB de VRAM por cada mil millones de parámetros al usar cuantización de 4 bits. La precisión completa (FP16) duplica ese requisito.
| Tamaño del modelo | Parámetros | VRAM (4 bits) | Memoria RAM virtual (FP16) | Hardware típico |
|---|---|---|---|---|
| Pequeño | 7B-13B | 3,5-6,5 GB | 14-26 GB | Individual A100/H100 |
| Medio | 30B-40B | 15-20 GB | 60-80 GB | A100 80 GB |
| Grande | 70B+ | 35 GB o más | 140 GB o más | Configuración multi-GPU |
Si el modelo no cabe en la VRAM, el sistema recurre al procesamiento por CPU, que es entre 10 y 100 veces más lento. Esto no es viable para la producción.
Costes mensuales de infraestructura por nivel
Un estudio de la Universidad Carnegie Mellon que analiza la economía de la implementación local de programas LLM muestra la aparición de claros niveles de costos:
| Nivel | Tamaño del modelo | Configuración de hardware | Rango de costo mensual | Mejor para |
|---|---|---|---|---|
| Entrada | 7B-13B | 1x A100/H100 | $1,500-$5,000 | Prototipos, herramientas internas |
| Medio | 30B-70B | Clúster de 4 a 8 GPU | $8,000-$20,000 | Aplicaciones de producción, escala moderada |
| Empresa | 70B+ | Clúster de 8 o más GPU | $20,000-$50,000+ | Producción de alto volumen |
Estas cifras incluyen la amortización del hardware, la energía, la refrigeración y el mantenimiento básico. El artículo de investigación de arxiv.org sobre análisis de costo-beneficio señala que los costos por hora de la GPU para las tarjetas A800 80G son aproximadamente $0.79/hora bajo supuestos comunes, generalmente dentro del rango de $0.51-$0.99/hora.
Ahorros con instancias reservadas de AWS EC2
Un análisis exhaustivo de los costos de alojamiento de LLM de LinkedIn muestra que las instancias reservadas de AWS EC2 ofrecen ahorros significativos en comparación con los precios bajo demanda. Para las instancias g5.xlarge (adecuadas para modelos con 8 mil millones de parámetros), los compromisos de reserva de un año pueden reducir los costos mensuales de aproximadamente $530 a tarifas mucho más bajas.
La opción más económica identificada para los modelos 8B fue Deep Infra a $5,40/mes, mientras que AWS SageMaker representó la más cara a $529,92/mes. El costo medio se sitúa en torno a $237/mes.

Conozca el costo de alojamiento de su LLM.
La organización de programas de máster en derecho (LLM) implica tomar decisiones en torno a la latencia, la escalabilidad, la seguridad y el presupuesto. IA superior Te ayuda a elegir el modelo de alojamiento adecuado (nube, borde o híbrido), estimar el uso de recursos y calcular los costos recurrentes vinculados al tráfico y al rendimiento. Su evaluación incluye consideraciones sobre almacenamiento, monitorización, escalabilidad y mantenimiento continuo. Esto te proporciona una previsión fiable de los gastos de alojamiento.
¿Listo para planificar el presupuesto de alojamiento de tu LLM?
Habla con una IA superior a:
- Seleccione la arquitectura de alojamiento adecuada.
- Estimar los costos de recursos y operativos.
- Reciba un desglose claro de los costos de alojamiento.
👉 Solicitar un Costo de alojamiento del LLM Estimación de AI Superior.
Alcanzando el punto de equilibrio: ¿Cuándo tiene sentido el autoalojamiento?
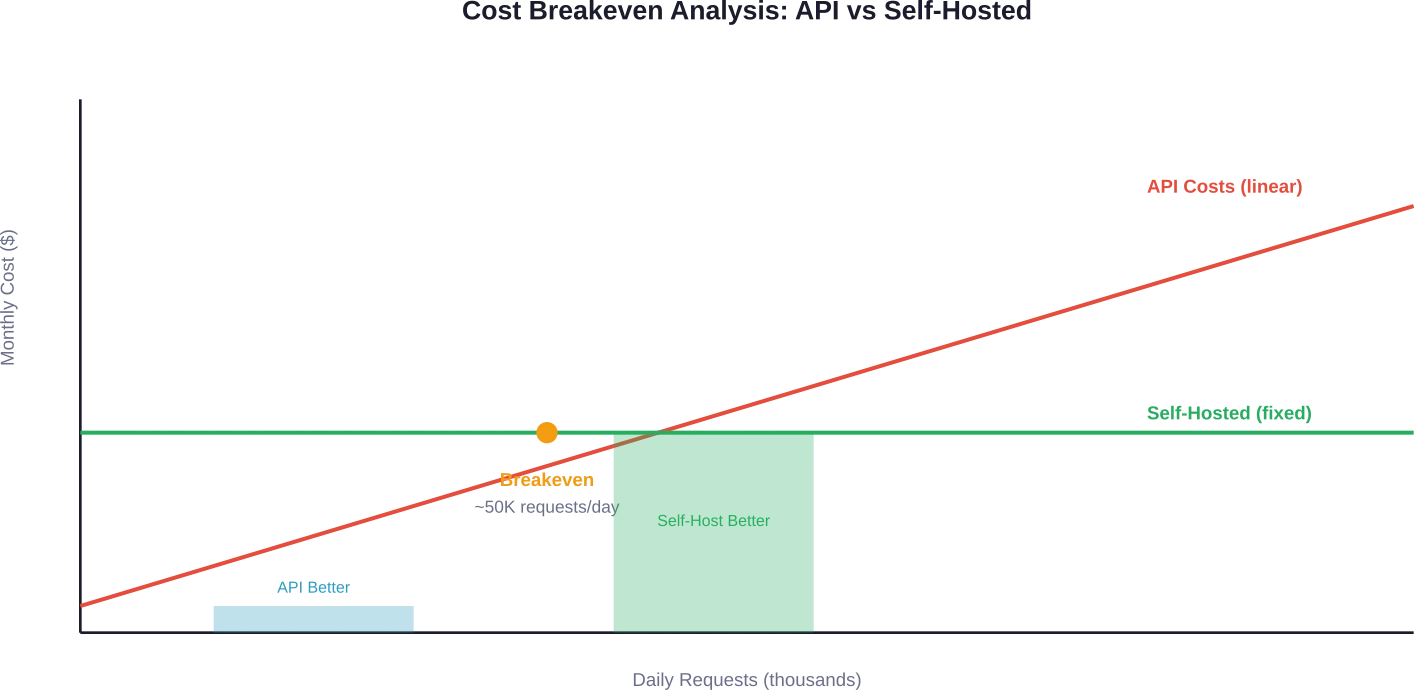
El punto de equilibrio depende del volumen de solicitudes. Los debates en la comunidad y los análisis de costes coinciden en que 50.000 solicitudes diarias o más es el umbral a partir del cual el autoalojamiento resulta económicamente atractivo.
He aquí la razón: los costos de la API aumentan linealmente con el uso. Los costos fijos de infraestructura se mantienen constantes independientemente del volumen de solicitudes (dentro de los límites de capacidad).
Una organización que procesa 50 000 solicitudes diarias con 500 tokens de entrada y 500 tokens de salida por solicitud utilizando GPT-5-mini gastaría aproximadamente $3,125 al mes solo en llamadas a la API. Esto sin tener en cuenta la infraestructura de la aplicación, las capas de almacenamiento en caché ni la monitorización.
Un modelo 7B autogestionado en hardware básico ($1.500-$5.000/mes) maneja volúmenes similares y ofrece un control total de los datos. La rentabilidad mejora drásticamente con más de 100.000 solicitudes diarias.
Costes ocultos de los que nadie habla
El precio indicado solo cuenta una parte de la historia. Tanto las soluciones basadas en API como las de alojamiento propio conllevan gastos ocultos que repercuten en el coste total de propiedad.
Costos ocultos de los servicios API
Las limitaciones de velocidad obligan a tomar decisiones arquitectónicas. Al alcanzar los límites de rendimiento, las aplicaciones necesitan sistemas de colas, lógica de reintentos y mecanismos de respaldo. Esto implica tiempo de ingeniería y costes de infraestructura.
Las tarifas de salida de datos se acumulan para aplicaciones de alto volumen. Si bien el procesamiento del token en sí cuesta $X, la transferencia de grandes conjuntos de datos hacia y desde los proveedores de API genera cargos adicionales.
La dependencia de un proveedor genera costos de cambio. Las aplicaciones desarrolladas en torno a formatos de respuesta de API específicos, integraciones de herramientas o técnicas de ingeniería de mensajes no pueden migrar fácilmente de proveedor.
Costos ocultos del alojamiento propio
La sobrecarga de DevOps es importante. Alguien debe encargarse de las actualizaciones de modelos, los parches de seguridad, la monitorización y la respuesta a incidentes. Según el informe de IA empresarial de Kong de 2025, el 441 % de las organizaciones citan la privacidad y la seguridad de los datos como las principales barreras; el autoalojamiento requiere recursos dedicados para abordar estas preocupaciones adecuadamente.
Los costos de energía y refrigeración superan los costos brutos de procesamiento. Los centros de datos informan que el consumo real de energía es entre 1,5 y 2 veces mayor que el consumo nominal de la GPU, si se tienen en cuenta las ineficiencias de la refrigeración y la fuente de alimentación.
La escalabilidad no es automática. Aumentar la capacidad implica plazos de entrega para la adquisición de hardware, consideraciones sobre el espacio en los racks y la planificación de la infraestructura de red. Los servicios API se escalan instantáneamente.
Estrategias de optimización que realmente funcionan
Independientemente de la plataforma de alojamiento elegida, existen varias técnicas que reducen sistemáticamente los costes de LLM sin sacrificar el rendimiento.
Selección de modelos y cuantificación
Los modelos más pequeños suelen tener un rendimiento mejor del esperado en tareas específicas de un dominio. Según la investigación de Together AI, optimizar un modelo de código abierto de 27 mil millones de dólares para tareas especializadas puede superar el rendimiento de Claude Sonnet 4 de 60%, con un coste entre 10 y 100 veces menor.
La cuantización de 4 bits reduce a la mitad los requisitos de memoria con un impacto mínimo en la calidad para la mayoría de las aplicaciones. Esta técnica permite ejecutar modelos más grandes en el mismo hardware o ejecutar el mismo modelo en hardware más económico.
Procesamiento por lotes
La API Batch de OpenAI ahorra 50% en entradas y salidas con procesamiento asíncrono durante 24 horas. La documentación de la API Batch de Together AI muestra ahorros similares: las tareas que no requieren respuestas en tiempo real siempre deben usar puntos finales de procesamiento por lotes.
Las investigaciones de AWS sobre la optimización de SageMaker demuestran que el procesamiento por lotes de las solicitudes de inferencia mejora drásticamente la utilización de la GPU, lo que reduce el coste por predicción.
Almacenamiento en caché y deduplicación de solicitudes
Las indicaciones del sistema, los documentos de referencia y las consultas repetidas suponen un derroche de dinero. Implementar el almacenamiento en caché de las indicaciones en la capa de aplicación elimina el procesamiento redundante de tokens.
En las implementaciones autogestionadas, el middleware de deduplicación de solicitudes puede detectar consultas idénticas antes de que lleguen al modelo, sirviendo en su lugar respuestas almacenadas en caché.
Previsión de tráfico y escalado automático
Un estudio de Microsoft sobre la eficiencia del servicio LLM (SageServe) logró ahorros de hasta 251 TP3T en horas de GPU mediante el escalado automático con conocimiento de pronósticos, con un potencial ahorro de costos mensuales de hasta $2,5 millones. El sistema analiza los patrones históricos de solicitudes y ajusta la capacidad de forma preventiva.
Esto reduce el desperdicio de horas de GPU debido al escalado automático ineficiente hasta en 80% en comparación con los enfoques de escalado reactivo.
Variaciones de costos regionales
Los costos de alojamiento de LLM varían significativamente según la región geográfica. AWS, Google Cloud y Azure aplican precios regionales que reflejan los costos de infraestructura local, los precios de la energía y las condiciones del mercado.
Un análisis de datos reales de producción, que abarca 10 millones de solicitudes en varias regiones, revela variaciones en los costos regionales. En el caso de los servicios API, estas diferencias suelen obviarse. Sin embargo, para la infraestructura autogestionada, elegir la región adecuada influye considerablemente en los costos mensuales.
En el caso de los servicios API, estas diferencias suelen obviarse. Sin embargo, para la infraestructura autogestionada, elegir la región adecuada influye considerablemente en los costes mensuales.
Tendencias de costos para 2026
Varios factores están contribuyendo a la disminución de los costes de alojamiento de los programas de LLM este año.
Las mejoras en la eficiencia algorítmica son más importantes que los avances en el hardware. Según una investigación de MIT FutureTech sobre eficiencia algorítmica, las mejoras en la complejidad espacial para problemas grandes (n=1000 millones) han superado las mejoras de la DRAM en 20% de los casos analizados.
Las nuevas arquitecturas de modelos, como Mixture-of-Experts (MoE), generan perfiles de costos diferentes. Las investigaciones que analizan el costo de MoE demuestran que estos modelos presentan ineficiencias únicas: desequilibrio de carga durante el prellenado y mayor transferencia de memoria durante la decodificación. Sin embargo, las implementaciones optimizadas de MoE pueden ofrecer una mejor relación costo-rendimiento que los modelos densos.
AWS anunció nuevos contenedores de inferencia de modelos grandes en 2023 que redujeron la latencia en 33% para cargas de trabajo Llama-2 70B. Las versiones actualizadas continúan mejorando la eficiencia. Para Llama-2 70B con una concurrencia de 16, la latencia se redujo en 28% y el rendimiento aumentó en 44% con los contenedores TensorRT-LLM.
Preguntas frecuentes
¿Cuál es la forma más económica de organizar un máster en Derecho (LLM) en 2026?
Para un uso de bajo volumen (menos de 10 000 solicitudes diarias), GPT-5-nano de OpenAI, con un coste de $0,025 por millón de tokens de entrada, ofrece la menor barrera de entrada y cero costes de infraestructura. Para una producción de alto volumen (más de 50 000 solicitudes diarias), alojar modelos de 7 000 a 13 000 millones de parámetros en hardware básico ($1500-$5000/mes) suele costar menos que el uso equivalente de la API.
¿Cuánta VRAM necesito para ejecutar un modelo de 70 mil millones de parámetros?
Un modelo con 70 mil millones de parámetros requiere aproximadamente 35 GB de VRAM con cuantización de 4 bits o 140 GB con precisión FP16 completa. Esto generalmente implica una GPU A100 de 80 GB (con requisitos ajustados y cuantización) o una configuración multi-GPU para un funcionamiento óptimo. Sin suficiente VRAM, el modelo recurre al procesamiento por CPU a velocidades entre 10 y 100 veces menores.
¿Merecen la pena las instancias reservadas de AWS para el alojamiento de LLM?
Las instancias reservadas son ideales para cargas de trabajo predecibles y continuas que se ejecutan las 24 horas del día, los 7 días de la semana. Los compromisos de reserva de un año de AWS EC2 muestran ahorros significativos en comparación con los precios bajo demanda para instancias con GPU. Sin embargo, el compromiso fija la capacidad; las organizaciones con patrones de uso variables podrían pagar de más durante los períodos de baja demanda.
¿Pueden las pequeñas organizaciones permitirse programas de máster en derecho (LLM) autogestionados?
El alojamiento propio de nivel básico comienza en torno a $1.500-$5.000 mensuales para modelos de parámetros de 7B-13B. Las organizaciones que procesan más de 50.000 solicitudes diarias suelen alcanzar el punto de equilibrio en comparación con los costes de las API a esta escala. Por debajo de ese umbral, los servicios de API suelen ser más económicos si se tienen en cuenta los gastos generales de DevOps, el mantenimiento y la gestión.
¿Cuál es la diferencia de precio real entre GPT-5.2 y GPT-5-mini?
Según los precios de OpenAI para 2026, GPT-5.2 cuesta 1,75 TP4T por millón de tokens de entrada y 14,00 TP4T por millón de tokens de salida, mientras que GPT-5-mini cuesta 0,125 TP4T de entrada y 1,00 TP4T de salida, una diferencia de 14 veces tanto en la entrada como en la salida. Para una aplicación típica que procesa 1 millón de tokens al día (500.000 de entrada y 500.000 de salida), GPT-5.2 cuesta aproximadamente 7.875 TP4T al mes, frente a los 562,50 TP4T de GPT-5-mini.
¿Realmente el almacenamiento en caché ahorra dinero en los costes de LLM?
Sí, de forma drástica. El sistema de precios de entrada en caché de OpenAI cobra solo 10% de las tarifas estándar para contenido repetido. Para aplicaciones con indicaciones del sistema o documentos de referencia consistentes, esto significa que las entradas en caché de GPT-5.2 cuestan $0.175 por millón de tokens en lugar de $1.75. Las aplicaciones con 50% de contenido almacenable en caché pueden reducir los costos de la API en aproximadamente 45%.
¿Cómo sé cuándo debo cambiar de una API a un alojamiento propio?
Calcula los costos mensuales actuales de la API y proyecta su crecimiento. Compáralos con la infraestructura de autoalojamiento básica ($1500-$5000/mes) más los costos generales de DevOps (normalmente entre 0,25 y 0,5 FTE de tiempo de ingeniería). Si los costos de la API superan los $5000 mensuales y el uso es predecible, el autoalojamiento suele ser económicamente viable. Los requisitos de privacidad de datos, las necesidades de cumplimiento y los requisitos de personalización también influyen en la decisión, más allá del mero costo.
Reflexiones finales
Los costes de alojamiento de LLM no son iguales para todos los casos. La elección correcta depende del volumen de solicitudes, los requisitos de rendimiento, la confidencialidad de los datos y las capacidades técnicas.
Los servicios API son ideales para empezar rápidamente, gestionar cargas de trabajo variables y evitar la administración de infraestructura. Casi siempre resultan más económicos para volúmenes inferiores a 50 000 solicitudes diarias.
El autoalojamiento resulta económicamente viable a gran escala, especialmente cuando la privacidad de los datos es crucial o cuando la optimización específica del dominio ofrece mejores resultados que los modelos de propósito general. Sin embargo, requiere un compromiso con DevOps y una inversión inicial en infraestructura.
¿Cuál es el mejor enfoque? Empezar con API para validar la adecuación del producto al mercado y, posteriormente, evaluar el autoalojamiento una vez que los patrones de uso se estabilicen y los costos justifiquen la inversión en infraestructura. Muchas organizaciones utilizan implementaciones híbridas: API para experimentación y capacidad de reserva, e infraestructura autoalojada para las cargas de trabajo de producción principales.
Sea cual sea el camino que mejor se adapte a las necesidades actuales, planifique con flexibilidad. La economía y las capacidades de las instituciones que ofrecen programas de LLM siguen evolucionando rápidamente.