Resumen rápido: Los costos de inferencia de LLM se han reducido diez veces anualmente desde 2021, con un rendimiento similar al de GPT-4 que ahora cuesta $0.40 por millón de tokens, en comparación con $30 por millón de tokens de entrada y $60 por millón de tokens de salida en marzo de 2023. Sin embargo, los modelos de razonamiento pueden consumir internamente hasta 100 veces más tokens de los que generan, lo que crea una paradoja de costos donde un precio por token más bajo conlleva facturas totales más altas. Comprender los costos reales de la infraestructura, las técnicas de optimización y la elección entre servicios API e implementaciones autogestionadas es esencial para una economía de IA sostenible.
La economía de la inteligencia artificial ha entrado en una fase que desafía la lógica convencional. Mientras los titulares celebran la caída en picado de los precios de los tokens, las empresas de IA están descubriendo una verdad incómoda: sus costes siguen aumentando.
Lo que costaba $60 por millón de tokens en noviembre de 2021 ahora cuesta entre $0,06 y 0,40 por millón de tokens para un rendimiento equivalente al de GPT-4, lo que representa una reducción de entre 150 y 1000 veces, dependiendo del modelo. Sin embargo, muchas startups que se basan en grandes modelos de lenguaje reportan costos de infraestructura que consumen entre 40 y 60% de sus ingresos.
¿El culpable? Un cambio fundamental en la forma en que los modelos de IA modernos generan respuestas, y un patrón de consumo de tokens que nadie previó.
La drástica caída en los precios de las inferencias de LLM
Los costes de inferencia de LLM han disminuido más rápidamente que casi cualquier otro recurso informático en la historia. Según un estudio que analiza las tendencias de precios, la tasa de reducción de costes varía drásticamente en función del nivel de rendimiento alcanzado, oscilando entre 9 y 900 veces al año.
La tasa de descenso varía drásticamente según la tarea. Para algunos indicadores, los precios cayeron nueve veces al año. Para otros, la disminución alcanzó las 900 veces anuales, aunque estas caídas extremas se produjeron principalmente en 2024 y podrían no mantenerse.
Así es como se ve en la práctica. Cuando GPT-3 se hizo público en noviembre de 2021, era el único modelo que alcanzaba una puntuación MMLU de 42. ¿Su coste? $60 por millón de tokens. Para marzo de 2026, varios modelos superan ese valor de referencia con $0,06 por millón de tokens o menos.
Gemini Flash-Lite 3.1 de Google lidera el mercado de precios económicos con $0.25 por millón de tokens de entrada y $1.50 por millón de tokens de salida. Los modelos de código abierto de proveedores como Together.ai ofrecen precios aún más bajos: Llama 3.2 3B funciona a $0.06 por millón de tokens de entrada.
¿Por qué cayeron los precios tan rápido?
Varios factores impulsan estas reducciones de costos. Los modelos son cada vez más pequeños, manteniendo el mismo rendimiento, gracias a las técnicas de entrenamiento mejoradas. Un modelo de 13 mil millones de parámetros ahora puede alcanzar el 95% de la puntuación MMLU de GPT-3 con una huella de inferencia considerablemente menor.
Los costos de hardware por unidad de cómputo continúan disminuyendo. Los precios de Cloud H100 se estabilizaron entre $2.85 y $3.50 por hora, tras haber descendido desde los picos de 2023. Según una investigación de arXiv, el costo horario base por tarjeta A800 de 80 GB es de aproximadamente $0.79/hora, generalmente dentro del rango de $0.51 a $0.99/hora.
Las técnicas de optimización como la cuantización, el procesamiento por lotes continuo y PagedAttention han transformado la capacidad de procesamiento. Los sistemas en la prueba comparativa MLPerf Inference v5.1 mejoraron hasta en 50% con respecto al mejor sistema de la versión 5.0, seis meses antes (septiembre de 2025).
Pero hay un inconveniente.
La paradoja del consumo de tokens
Un precio por token más bajo solo cuenta la mitad de la historia. La otra mitad tiene que ver con la cantidad de tokens que consumen realmente los modelos modernos.
Los modelos de lenguaje tradicionales generan respuestas de forma lineal: se formula una pregunta y se obtiene una respuesta. El consumo de tokens se corresponde aproximadamente con la longitud de la respuesta. Una respuesta de 200 palabras consume entre 250 y 300 tokens.
Los modelos de razonamiento funcionan de manera diferente. Analizan los problemas internamente antes de producir un resultado. Este proceso de razonamiento interno consume tokens, muchos de ellos.
Ejemplos reales revelan la magnitud de este cambio. Una pregunta sencilla podría utilizar internamente 10 000 tokens de razonamiento, mientras que la respuesta solo requiere 200 tokens. Esto representa 50 veces más tokens de los que sugiere el resultado visible.
En casos extremos documentados por los usuarios, algunos modelos de razonamiento consumieron más de 600 tokens para generar tan solo dos palabras de resultado. Una consulta básica que usaría 50 tokens con un modelo estándar puede llegar a consumir más de 30 000 tokens con un razonamiento agresivo activado.
El impacto empresarial
Esto genera lo que algunos denominan la “paradoja del coste de LLM”. El precio por token se redujo diez veces, pero el consumo de tokens aumentó cien veces para ciertas cargas de trabajo. Las cifras no favorecen a las empresas de IA.
Las startups que basaron sus modelos de precios en la economía de tokens tradicional se enfrentan a una reducción de márgenes. Un cliente que paga $20 al mes podría generar entre $18 y $25 en costes de inferencia durante tareas de razonamiento complejas. La economía unitaria simplemente no funciona.
Algunos proveedores respondieron limitando los tokens de razonamiento, restringiendo la capacidad de procesamiento interno de un modelo. Otros implementaron precios escalonados, donde las solicitudes que requieren un mayor razonamiento cuestan más. Sin embargo, estas soluciones generan fricción y complejidad.
Comprender los verdaderos costos de la infraestructura
Más allá de los precios de la API, los equipos que consideran implementaciones autogestionadas deben comprender la estructura de costos completa. Las cifras revelan cuándo el autogestionamiento es económicamente viable y cuándo no.
Economía de la infraestructura de GPU
Según las directrices de evaluación comparativa de NVIDIA publicadas en junio de 2025, para calcular los costes reales de inferencia es necesario tener en cuenta la adquisición de hardware, el consumo de energía, la refrigeración, el ancho de banda de la red y los gastos operativos.
Las instancias H100 en la nube cuestan entre $2,85 y $3,50 por hora, dependiendo del proveedor y la duración del contrato. Las instancias H100 autogestionadas requieren una inversión inicial más los costos operativos. El cálculo del punto de equilibrio depende de las tasas de utilización.
Las investigaciones demuestran que la infraestructura autogestionada se vuelve viable cuando la utilización de la GPU supera los 50% de forma sostenible. Por debajo de ese umbral, los servicios API suelen ofrecer una mejor relación calidad-precio.
| Componente de costo | Proveedor de servicios en la nube | Autogestionado |
|---|---|---|
| Costo de la GPU | $2,85-3,50/hora | $30.000-40.000 (H100) |
| Potencia (por GPU) | Incluido | $0,40-0,60/hora |
| Enfriamiento | Incluido | $0,15-0,25/hora |
| Red | $0,08-0,12/GB de salida | Fijo mensual |
| Operaciones | Mínimo | 1-2 ingenieros a tiempo completo |
| Punto de equilibrio | — | Utilización de 50%+ |
La ecuación de utilización
La utilización lo determina todo. Una GPU que funciona con una utilización de 30% cuesta 3,3 veces más por inferencia que una que funciona con 100%. Pero para lograr una alta utilización se requiere un volumen de carga de trabajo constante y estrategias de procesamiento por lotes sofisticadas.
El procesamiento por lotes puede reducir el costo por token de salida hasta en 30% en comparación con el procesamiento de solicitudes individuales. Técnicas como el procesamiento continuo por lotes, donde el motor de inferencia combina dinámicamente las solicitudes a medida que llegan, maximizan el rendimiento.
Las mejoras en la eficiencia del modelo mediante la cuantización, las arquitecturas de mezcla de expertos y la poda de datos pueden aumentar la rentabilidad entre 2 y 5 veces sin sacrificar la calidad. Según la información del proveedor Together.ai, la arquitectura MoE de DeepSeek está diseñada para ofrecer un rendimiento comparable al de GPT-4 de forma rentable.
Estructura de costos según el tamaño del modelo
El tamaño del modelo influye directamente en los costes de inferencia, pero la relación no es lineal. Los modelos más pequeños no siempre implican costes proporcionalmente menores, y los modelos más grandes a veces ofrecen una mejor relación calidad-precio para tareas complejas.
Modelos pequeños (parámetros 3B-7B)
Los modelos de esta gama destacan por su eficiencia en costes para tareas sencillas. Llama 3.2 3B cuesta aproximadamente $0.06 por millón de tokens. Estos modelos gestionan eficazmente la clasificación, la respuesta a preguntas simples y la extracción de datos estructurados.
La desventaja radica en la capacidad. Los modelos pequeños tienen dificultades con el razonamiento complejo, la comprensión de lenguajes matizados y las tareas que requieren un amplio conocimiento del mundo. Para muchas cargas de trabajo de producción, esto es aceptable.
Modelos medianos (parámetros 13B-70B)
Este rango representa el punto óptimo para muchas aplicaciones. Un modelo de 13B que alcance una puntuación MMLU de 95% de GPT-3 podría costar $0,25 por millón de tokens, un coste superior al de los modelos pequeños, pero con capacidades de razonamiento sustancialmente mejores.
Los modelos de la clase 70B, como Llama 3.1 70B, ofrecen un rendimiento cercano al de la frontera tecnológica, con un coste aproximado de $0,80 por millón de tokens. Para aplicaciones que requieren un razonamiento sólido sin necesidad de capacidades de vanguardia absolutas, estos modelos ofrecen una excelente rentabilidad por unidad.
Modelos grandes (más de 175 mil millones de parámetros)
Los modelos de vanguardia como GPT-4, Claude y Gemini Ultra cuestan entre $2 y 15 por millón de tokens, dependiendo del modelo y del proveedor. Destacan en el razonamiento complejo, las tareas creativas y los problemas que requieren un profundo conocimiento del dominio.
El mayor coste por token resulta económico cuando el modelo completa las tareas en menos iteraciones, proporciona respuestas más precisas o permite casos de uso que los modelos más pequeños simplemente no pueden gestionar.

¿Necesita ayuda para diseñar e implementar un sistema LLM?
Si planeas ejecutar un modelo de lenguaje complejo en producción, te resultará útil trabajar con un equipo que desarrolle e implemente sistemas de IA a diario. IA superior Desarrollan aplicaciones de IA personalizadas basadas en aprendizaje automático y modelos LLM, desde el análisis de viabilidad inicial hasta la implementación e integración. Su equipo de científicos de datos e ingenieros trabaja en el desarrollo de modelos, sistemas de PNL, flujos de datos e implementación en producción. También ayudan a evaluar si un caso de uso requiere realmente un modelo LLM y cómo estructurar el sistema para que funcione de manera eficiente.
¿Listo para planificar la implementación de su programa LLM?
Habla con una IA superior a:
- Evalúe su caso de uso de LLM y sus requisitos técnicos.
- Diseñar y construir sistemas personalizados de IA o PNL.
- desplegar modelos e integrarlos en el software existente.
👉 Solicita una consulta de IA con IA superior para hablar sobre tu proyecto de máster en Derecho (LLM).
Servicios API frente a economía de alojamiento propio
La elección entre servicios API e infraestructura autogestionada depende de la escala, los patrones de uso y las capacidades técnicas. Ninguna de las dos opciones es universalmente superior.
Cuando los servicios API ganan
Los servicios API de OpenAI, Anthropic, Google y proveedores como Together.ai ofrecen una rentabilidad atractiva para numerosos escenarios. La ausencia de gestión de infraestructura permite que los equipos se centren en la lógica de la aplicación en lugar de en la orquestación de la GPU.
Los costos aumentan linealmente con el uso. Los meses de bajo uso cuestan proporcionalmente menos que los meses de alto uso. No hay gastos de capital, ni capacidad ociosa durante los períodos de baja demanda, ni costos operativos para la infraestructura que da soporte al modelo.
Para aplicaciones con patrones de tráfico variables, demanda estacional o trayectorias de crecimiento impredecibles, las API suelen ofrecer una mejor relación coste-beneficio, a menos que el rendimiento sostenido supere un umbral bastante alto.
Cuándo tiene sentido el autoalojamiento
El autoalojamiento se vuelve económicamente viable cuando la utilización de la GPU puede superar de forma sostenible los 50%. Según los datos de evaluación comparativa, esto requiere un volumen de carga de trabajo constante: aproximadamente más de 10 millones de tokens diarios para una configuración de GPU única.
Más allá de las razones puramente económicas, algunas organizaciones optan por el autoalojamiento por motivos de privacidad de datos, requisitos de personalización o necesidades específicas de latencia. Las aplicaciones de servicios financieros, atención médica y gobierno a menudo no pueden enviar datos a API de terceros, independientemente de las ventajas en cuanto a costos.
Los motores de inferencia de código abierto como vLLM permiten implementaciones autogestionadas de alto rendimiento. Las técnicas de PagedAttention y procesamiento por lotes continuo de vLLM maximizan la utilización de la GPU, lo que hace que la autogestión sea más competitiva económicamente.
| Factor | Favorece las API | Favorece el autoalojamiento |
|---|---|---|
| Volumen | <10 millones de tokens/día | >50 millones de tokens/día |
| Patrón de tráfico | Variable/puntiagudo | Consistente/predecible |
| Necesidades de latencia | Flexible | Se requiere muy poco |
| Sensibilidad de los datos | Estándar | Altamente sensible |
| Personalización | Modelos estándar OK | Necesito modelos personalizados |
| Capacidad técnica | Operaciones de aprendizaje automático limitadas | Equipo de operaciones de aprendizaje automático sólido |
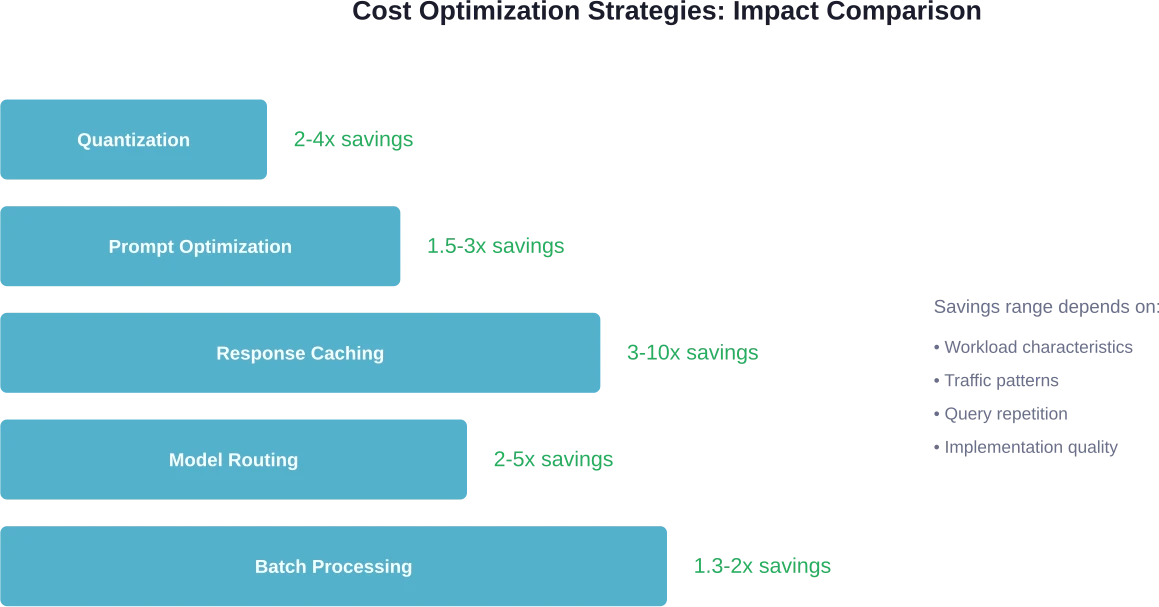
Técnicas de optimización que transforman la economía
Varias técnicas pueden reducir los costos de inferencia entre 2 y 10 veces sin sacrificar la calidad. Estas optimizaciones funcionan tanto si se utilizan API como si se implementan soluciones de autoalojamiento.
Cuantización
La cuantización reduce la precisión del modelo, pasando de números de coma flotante de 16 o 32 bits a enteros de 8 o incluso 4 bits. Esto disminuye el consumo de memoria y acelera la inferencia.
Los métodos de cuantificación modernos mantienen la calidad de forma notable. Según investigaciones sobre el entrenamiento FP8, la mayoría de las variables en el entrenamiento e inferencia de modelos lineales de lógica difusa (LLM) pueden emplear formatos de baja precisión sin comprometer la exactitud. Proveedores como Together.ai ofrecen modelos cuantificados a precios reducidos y afirman mantener la calidad.
Optimización inmediata
La longitud de las indicaciones influye directamente en los costes. Una indicación de 5000 tokens procesada 1000 veces cuesta lo mismo que 5 millones de tokens de inferencia. Optimizar las indicaciones para que sean concisas sin sacrificar la eficacia genera reducciones de costes inmediatas.
Las investigaciones demuestran que la optimización de las indicaciones puede mejorar la precisión de las tareas y, al mismo tiempo, reducir el consumo de tokens. Las indicaciones bien estructuradas guían a los modelos de manera más eficiente, lo que reduce la cantidad de tokens de razonamiento necesarios para llegar a las respuestas correctas.
Almacenamiento en caché de respuestas
Muchas aplicaciones realizan solicitudes similares o idénticas repetidamente. Almacenar en caché las respuestas a las consultas comunes elimina por completo los costos de inferencia redundantes.
Las estrategias de almacenamiento en caché inteligentes consideran la similitud de las solicitudes, no solo las coincidencias exactas. El almacenamiento en caché semántico compara el significado de las solicitudes y devuelve respuestas almacenadas en caché para consultas suficientemente similares, incluso cuando la redacción difiere.
Enrutamiento de modelos
No todas las solicitudes requieren el modelo más potente. Dirigir las consultas sencillas a modelos pequeños y rápidos, y las consultas complejas a modelos más grandes, optimiza la relación coste-calidad.
Esto requiere una lógica previa para clasificar la complejidad de las solicitudes, pero la rentabilidad suele justificar la inversión. Enrutar 70% de tráfico a un modelo de token de $0,10/millón y 30% a un modelo de token de $3/millón produce un coste combinado de $0,97/millón, considerablemente inferior al de utilizar el modelo más caro para todo.
Panorama de los proveedores en 2026
El mercado de proveedores de inferencia ha evolucionado considerablemente. Actualmente, varias categorías de proveedores satisfacen diferentes necesidades.
API del modelo Frontier
OpenAI, Anthropic y Google ofrecen capacidades de vanguardia con precios premium. Los modelos de la clase GPT-4 cuestan entre $2 y 15 por millón de tokens, dependiendo de la variante específica del modelo. Estos proveedores invierten fuertemente en seguridad, confiabilidad y capacidades de punta.
Los modelos o3 y o4-mini de OpenAI, lanzados en 2025, representan avances en la capacidad de razonamiento. Según las evaluaciones de OpenAI, o3 comete menos errores graves que o1 en tareas difíciles del mundo real, destacando especialmente en aplicaciones de programación y consultoría empresarial.
Plataformas de modelos de código abierto
Proveedores como Together.ai, Fireworks y Replicate ofrecen modelos de código abierto con precios significativamente más bajos. Los modelos DeepSeek de Together.ai ofrecen un ahorro de costes de entre el 70 % y el 90 % en comparación con las alternativas de código cerrado, a la vez que brindan un rendimiento de vanguardia.
Estas plataformas combinan modelos de código abierto estándar con infraestructura de servidores propietaria. El resultado: un rendimiento excelente a precios mucho más bajos, aunque a veces con un filtrado de seguridad y una moderación de contenido menos exhaustivos.
Servicios de IA de proveedores de nube
AWS, Azure y Google Cloud ofrecen tanto sus propios modelos como modelos de terceros a través de API unificadas. Los precios varían, pero los proveedores de servicios en la nube suelen añadir un margen de beneficio al acceso directo a la API, a la vez que ofrecen funciones empresariales como acuerdos de nivel de servicio (SLA), certificaciones de cumplimiento e integración con la infraestructura en la nube existente.
Proveedores de inferencia especializados
Empresas como Groq se centran específicamente en la optimización de la inferencia. Groq se enfoca en la optimización de la inferencia mediante silicio personalizado para lograr un rendimiento de baja latencia.
Trayectoria de costos futuros
¿Qué sucederá con los costos de inferencia a partir de ahora? Varias tendencias influyen en las expectativas.
Es probable que las reducciones de costos de diez veces anuales observadas entre 2021 y 2025 no se mantengan al mismo ritmo. Ya se han aprovechado las oportunidades de optimización más sencillas. Las mejoras de hardware continúan, pero a un ritmo más moderado. Las innovaciones en la arquitectura de los modelos siguen produciéndose, pero con menor frecuencia que durante el período de gran crecimiento de 2022 a 2024.
Una previsión más realista contempla reducciones anuales de 3 a 5 veces hasta 2027, para luego disminuir gradualmente hasta alcanzar entre 1,5 y 2 veces al año. Esto sigue representando una mejora considerable, aunque no al ritmo extraordinario de los últimos años.
El desafío del consumo de tokens en el razonamiento impulsará innovaciones arquitectónicas. Los modelos que logren un razonamiento sólido con menor consumo de tokens dominarán el mercado. Se prevé que continúe la investigación sobre mecanismos de razonamiento eficientes.
La competencia sigue siendo feroz. La entrada de DeepSeek revolucionó los precios en todo el mercado, obligando a las empresas ya establecidas a reducirlos o a diferenciarse en otros aspectos. Es probable que surjan más disrupciones de fuentes inesperadas: startups con arquitecturas novedosas o actores regionales con estructuras económicas diferentes.
Construyendo una economía de IA sostenible
Las organizaciones que se basan en modelos de negocio legales (LLM) necesitan estrategias que funcionen independientemente de las fluctuaciones específicas de precios. Varios principios permiten una economía sostenible.
- En primer lugar, diseñe modelos flexibles. No codifique dependencias fijas de proveedores o modelos específicos. Abstraiga la inferencia detrás de interfaces que permitan cambiar de proveedor según cambien las circunstancias económicas.
- En segundo lugar, instrumenta todo. Mide el consumo de tokens, el costo por solicitud y el costo por resultado comercial. Muchas organizaciones descubren que 20% de casos de uso consumen 80% de costos, y algunos casos de uso de alto costo ofrecen un valor mínimo.
- En tercer lugar, invierta en optimización. Las técnicas mencionadas anteriormente (cuantización, almacenamiento en caché, enrutamiento, optimización de solicitudes) generan efectos acumulativos con el tiempo. Una mejora del doble puede parecer modesta hasta que se comprende que implica una reducción de costos de 50% cada mes a partir de entonces.
- En cuarto lugar, adapte la capacidad del modelo a los requisitos de la tarea. Utilizar modelos de vanguardia para cada tarea supone un derroche de dinero. Implementar una lógica de clasificación que dirija las solicitudes adecuadamente resulta rentable.
- Por último, planifique la visibilidad del consumo de tokens. El problema de los tokens de razonamiento sorprende a los equipos cuando no supervisan su consumo interno. Los proveedores ofrecen cada vez más telemetría que muestra el uso oculto de tokens; utilícela.
Preguntas frecuentes
¿Cuánto cuesta la inferencia LLM por solicitud?
Los costos de inferencia de LLM varían drásticamente según el tamaño del modelo y la complejidad de la solicitud. Las solicitudes simples a modelos pequeños (3B-7B parámetros) cuestan fracciones de centavo, aproximadamente $0.01-0.05 por cada 1000 solicitudes. Los modelos medianos (13B-70B) cuestan $0.10-0.80 por cada 1000 solicitudes. Los modelos de frontera grandes (175B+) cuestan $2-15 por cada 1000 solicitudes. Sin embargo, los modelos de razonamiento pueden consumir entre 50 y 100 veces más tokens de lo que sugiere la longitud de la salida, lo que aumenta drásticamente los costos reales.
¿Es más económico el autoalojamiento que el uso de servicios API?
El autoalojamiento resulta más económico que las API cuando la utilización de la GPU supera de forma constante aproximadamente los 50%. Esto suele requerir el procesamiento de más de 10 millones de tokens diarios por GPU. Por debajo de ese umbral, las API suelen ofrecer una mejor relación coste-beneficio, ya que se evitan los gastos de capital y no se paga por la capacidad ociosa. El autoalojamiento también requiere experiencia en operaciones de aprendizaje automático y una mayor gestión de la infraestructura.
¿Por qué son tan caros los modelos de razonamiento?
Los modelos de razonamiento generan una gran cantidad de tokens internos de "pensamiento" antes de producir un resultado. Una respuesta con 200 tokens visibles puede consumir entre 10 000 y 30 000 tokens en total durante el proceso de razonamiento. Este consumo interno de tokens se factura, pero permanece invisible en el resultado, lo que genera situaciones en las que el precio por token parece bajo, pero los costos totales son altos. Algunas consultas de razonamiento consumen más de 600 tokens para generar respuestas de dos palabras.
¿Cómo puedo reducir los costos de inferencia de LLM?
Cinco estrategias principales reducen los costos de inferencia: cuantización (ahorro de 2 a 4 veces), almacenamiento en caché de respuestas para consultas repetidas (ahorro de 3 a 10 veces), optimización de solicitudes para reducir el uso de tokens (ahorro de 1,5 a 3 veces), enrutamiento de modelos para usar modelos más pequeños en tareas simples (ahorro de 2 a 5 veces) y procesamiento por lotes para cargas de trabajo orientadas al rendimiento (ahorro de 1,3 a 2 veces). Estas técnicas se potencian mutuamente cuando se combinan eficazmente.
¿Cuál es el coste actual para un rendimiento similar al de GPT-4?
A marzo de 2026, alcanzar un rendimiento similar al de GPT-4 costaría aproximadamente entre $0,40 y 0,80 por millón de tokens utilizando alternativas competitivas como DeepSeek V3 o modelos de gama media de los principales proveedores. El GPT-4 de OpenAI costaría entre $2 y 15 por millón de tokens, dependiendo de la variante específica. Esto representa una drástica disminución con respecto a finales de 2022, cuando un rendimiento equivalente costaba más de $20 por millón de tokens.
¿Cómo se comparan los costos de las GPU en la nube entre los diferentes proveedores?
El precio de las GPU Cloud H100 se ha estabilizado en $2,85-3,50 por hora en los principales proveedores a principios de 2026. Los proveedores regionales de nube a veces ofrecen tarifas más bajas ($2,20-2,60 por hora) con SLA reducidos. Las tarjetas A800, comunes en ciertas regiones, cuestan aproximadamente $0,79 por hora según la economía de la infraestructura. Las configuraciones multi-GPU suelen ofrecer descuentos por volumen de 10-20%.
¿Seguirán disminuyendo los costes de inferencia de LLM?
Es probable que los costos de inferencia sigan disminuyendo, pero a un ritmo más lento que la reducción anual de 10x observada entre 2021 y 2025. Las expectativas realistas apuntan a reducciones anuales de 3 a 5x hasta 2027, para luego estabilizarse en 1,5 a 2x anuales a medida que las oportunidades de optimización se vuelvan más escasas. Las mejoras de hardware y las innovaciones arquitectónicas impulsarán una deflación continua, pero el ritmo extraordinario de los últimos años probablemente no se mantendrá indefinidamente.
Conclusiones estratégicas para aplicaciones basadas en IA
Comprender la economía de la inferencia de LLM es más importante que nunca. La diferencia entre una implementación básica y una implementación optimizada puede representar una diferencia de costos de 5 a 10 veces, suficiente para determinar si la rentabilidad por unidad es viable.
El precio de los tokens solo cuenta una parte de la historia. El consumo total de tokens, incluidos los tokens de razonamiento oculto, determina los costos reales. Monitorear y controlar este consumo es esencial para operaciones sostenibles.
La elección entre servicios API y alojamiento propio depende de la escala, los patrones de uso y las capacidades organizativas. Ninguna opción es la mejor en todos los casos. Analice su situación particular en lugar de seguir las tendencias del sector a ciegas.
Las técnicas de optimización se acumulan. La cuantización, el almacenamiento en caché, la ingeniería de solicitudes y el enrutamiento de modelos, en conjunto, pueden reducir los costos hasta diez veces o más en comparación con las implementaciones de referencia. Invertir en estas optimizaciones genera beneficios sostenidos.
El mercado sigue evolucionando rápidamente. Constantemente surgen nuevos proveedores, modelos y estructuras de precios. Desarrollar arquitecturas flexibles que se adapten a los cambios económicos protege tanto del aumento de costes como de la pérdida de oportunidades derivadas de mejores alternativas.
En serio: los costes de inferencia de LLM han disminuido drásticamente, pero eso no significa que la infraestructura de IA sea barata. Significa que la economía ha pasado de ser prohibitivamente cara a ser manejable con una optimización cuidadosa. Los equipos que comprendan esta economía y diseñen sus arquitecturas en consecuencia construirán negocios de IA sostenibles. Quienes traten la inferencia como un producto básico sin comprender los factores subyacentes que influyen en los costes tendrán dificultades.
¿Listo para optimizar los costos de inferencia de LLM? Comience midiendo sus patrones actuales de consumo de tokens, incluyendo los tokens de razonamiento ocultos. Identifique sus casos de uso de mayor costo y evalúe si el enrutamiento del modelo o la optimización de las indicaciones podrían reducir los gastos. Compare su volumen actual con el punto de equilibrio del autoalojamiento para determinar si le conviene tener infraestructura propia. La información que obtenga tendrá un impacto directo en sus resultados.