Korte samenvatting: Voorspellende analyses maken gebruik van historische gegevens, statistische modellen en machine learning om toekomstige uitkomsten in diverse sectoren te voorspellen. Van onderhoud van productiemachines tot het voorspellen van klantverloop in de banksector: voorspellende modellen helpen organisaties risico's te verminderen, processen te optimaliseren en datagestuurde beslissingen te nemen. De implementatie omvat het verzamelen van gegevens, het trainen van modellen, validatie en implementatie – waardoor reactieve sectoren worden omgevormd tot proactieve, autonome systemen.
Productielijnen vallen niet volgens schema stil. Klanten kondigen hun vertrek niet van tevoren aan. Toeleveringsketens geven geen waarschuwingen af voordat ze instorten.
Maar er zitten patronen in de data – verborgen signalen die erop wijzen dat er iets mis dreigt te gaan. Voorspellende analyses sporen die signalen op voordat problemen zich voordoen.
Voorspellende analyses vormen een tak van geavanceerde analyses die voorspellingen doet over toekomstige uitkomsten door gebruik te maken van historische gegevens in combinatie met statistische modellen, data mining-technieken en machine learning. Bedrijven gebruiken tools voor voorspellende analyses om patronen in gegevens te vinden die helpen bij het identificeren van risico's en kansen.
De verschuiving van reactieve naar proactieve besluitvorming is een fundamentele transformatie. In plaats van apparatuur te repareren nadat deze defect is geraakt, voorspellen organisaties storingen weken van tevoren. In plaats van te reageren op het vertrek van klanten, identificeren banken risicovolle rekeningen voordat er sprake is van klantverlies.
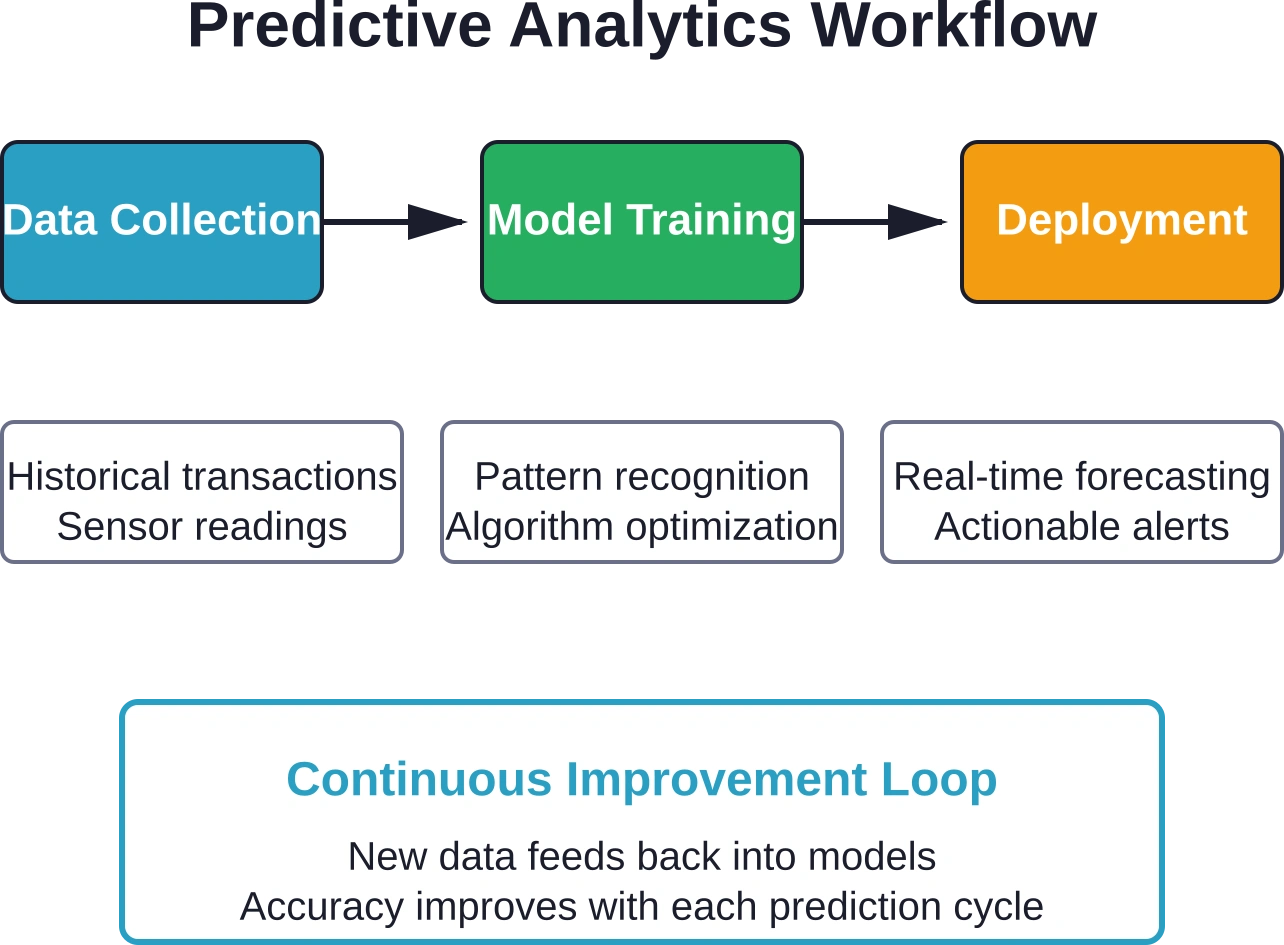
Hoe voorspellende analyses daadwerkelijk werken
Het proces begint met historische gegevens. Heel veel gegevens.
Organisaties verzamelen transactiegegevens, sensorwaarden, klantinteracties, productiestatistieken – alle gegevens die vastleggen wat er in het verleden is gebeurd. Deze historische basis voedt statistische modellen die patronen leren herkennen.
Machine learning-algoritmen analyseren deze patronen. Ze identificeren welke variabelen correleren met specifieke uitkomsten. Temperatuurpieken voorafgaand aan apparatuurstoringen. Transactiepatronen voorafgaand aan het sluiten van rekeningen. Voorraadniveaus voorafgaand aan verstoringen in de toeleveringsketen.
De modellen signaleren niet alleen correlaties, ze kwantificeren ook waarschijnlijkheden. Een specifieke machineconfiguratie heeft een 78%-uitvalrisico binnen twee weken. Een account met drie gedragsindicatoren heeft een 82%-klantverloopkans binnen 90 dagen.
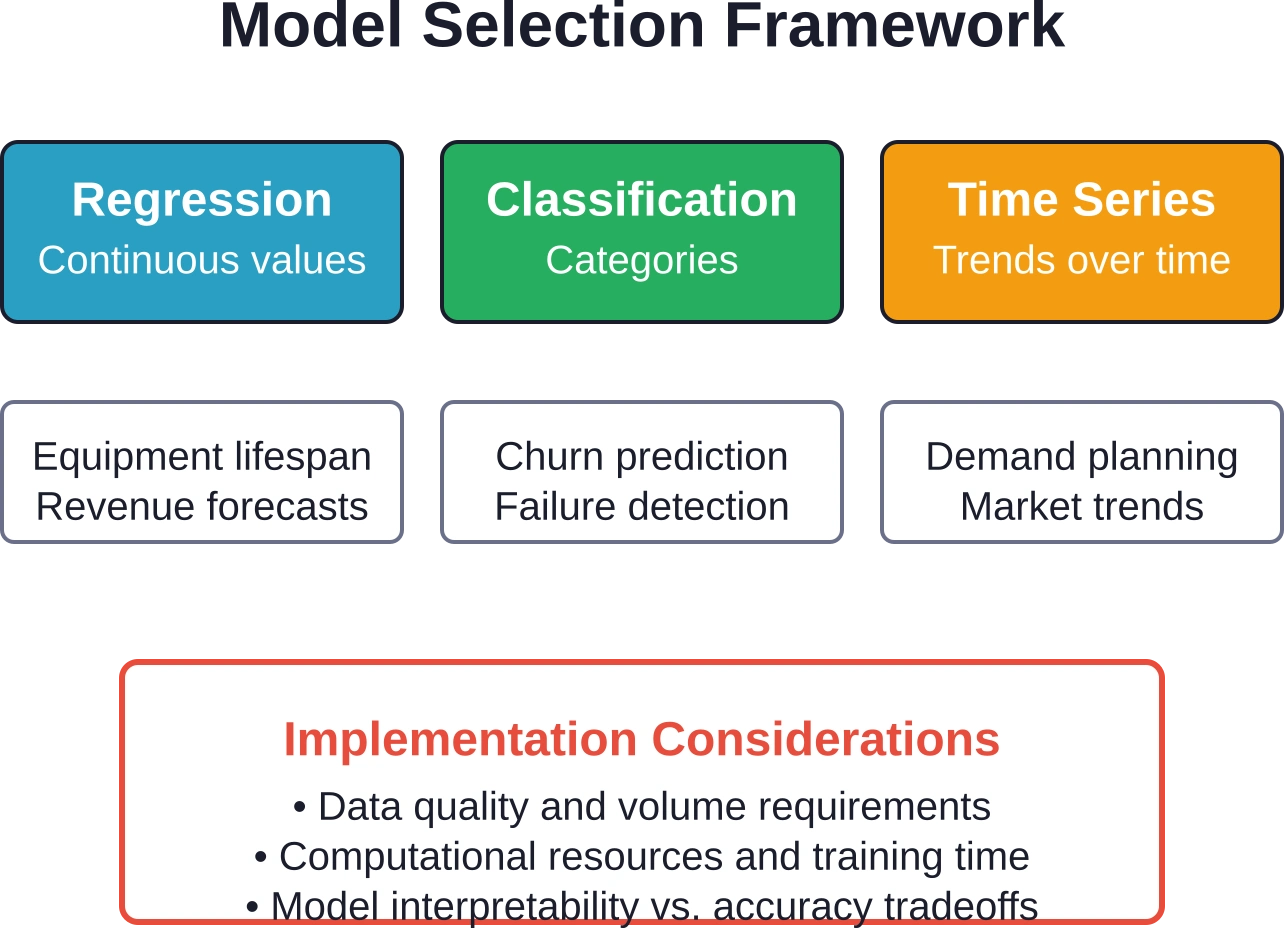
Statistische modelleringstechnieken variëren afhankelijk van de toepassing. Regressiemodellen voorspellen continue waarden zoals de levensduur van apparatuur of de omzet. Classificatiemodellen voorspellen categorische uitkomsten zoals geslaagd/gezakt of blijven/vertrekken. Tijdreeksmodellen voorspellen trends over specifieke perioden.
Dataminingtechnieken extraheren deze patronen uit enorme datasets. Neurale netwerken met meerdere verborgen lagen identificeren niet-lineaire verbanden die mensen zouden missen. Beslissingsbomen brengen vertakkende logische paden in kaart die leiden tot verschillende uitkomsten.
Industriële toepassingen voor voorspellend onderhoud
Productiebedrijven genereren enorme hoeveelheden sensorgegevens. Temperatuurmetingen, trillingsmetingen, drukniveaus, elektrische stroom – alles wordt continu geregistreerd door productieapparatuur.
Voorspellende onderhoudsmodellen analyseren deze sensorstroom om apparatuurstoringen te voorspellen voordat ze zich voordoen. De technische literatuur van de IEEE beschrijft implementaties die de beschikbaarheid van productieapparatuur in automobielbedrijven verbeteren door onderhoudsbehoeften te voorspellen.
Industriële IoT-toepassingen integreren nu voorspellende analyses voor proactief onderhoud. Sensoren in motoren, pompen, transportbanden en assemblagerobots verzenden realtime operationele gegevens. Machine learning-algoritmen verwerken deze gegevens om slijtagepatronen te identificeren.
| Onderhoudsaanpak | Strategie | Impact van downtime | Kostenefficiëntie |
|---|---|---|---|
| reactief | Repareer na een mislukking | Hoog - ongeplande stroomuitval | Laag - noodreparaties duur |
| Preventief | Gepland onderhoud | Gemiddelde tijd - geplande downtime | Gemiddeld - enig onnodig werk |
| Voorspellend | Voorspellingsgestuurde interventie | Laag - gericht onderhoud | Hoog—optimale timing |
De maakindustrie staat voor complexe uitdagingen zoals tekorten aan grondstoffen en verstoringen in de toeleveringsketen. Voorspellende modellen helpen operationele risico's te verminderen door deze verstoringen te voorspellen voordat ze de productie beïnvloeden.
Autofabrikanten gebruiken voorspellende analyses om productieschema's te optimaliseren rond verwachte onderhoudsmomenten van apparatuur. In plaats van complete productielijnen stil te leggen voor routinecontroles, vindt onderhoud precies plaats wanneer sensoren aangeven dat het nodig is.
Toepassingsvoorbeelden in de bank- en financiële dienstverlening
Klantenbinding is de drijvende kracht achter de winstgevendheid in de financiële dienstverlening. Het behouden van bestaande klanten is goedkoper dan het werven van nieuwe klanten.
Neurale netwerken verbeteren de voorspellingsnauwkeurigheid van klantverloop in de banksector aanzienlijk. Onderzoek met een dataset van 10.000 records met 14 kenmerken laat zien hoe machine learning voorspelt welke klanten hun rekening zullen opzeggen.

Logistische regressie behaalde een nauwkeurigheid van 89,61 TP3T met een recall van 96,81 TP3T en een AUC-score van 0,91 voor onderscheidend vermogen. Naïeve Bayes behaalde een nauwkeurigheid van 86,71 TP3T met een precisie van 92,01 TP3T en een recall van 92,21 TP3T, plus een AUC-score van 0,83.
Deze modellen identificeren niet alleen klanten met een verhoogd risico. Ze rangschikken ze op waarschijnlijkheid en suggereren interventiestrategieën. Waardevolle accounts die vroegtijdige waarschuwingssignalen vertonen, activeren gepersonaliseerde aanbiedingen om klanten te behouden, nog voordat ze besluiten te vertrekken.
Banken gebruiken meerlaagse perceptronarchitecturen met verschillende neuronconfiguraties die zijn geoptimaliseerd voor hun specifieke taken op het gebied van klantverloopvoorspelling. Deze neurale netwerken verwerken transactiepatronen, trends in rekeningsaldi, interacties met de klantenservice en demografische factoren.
Financiële instellingen passen voorspellende analyses toe voor fraudedetectie, kredietrisicobeoordeling en optimalisatie van beleggingsportefeuilles. Elke toepassing volgt hetzelfde kernprincipe: historische patronen voorspellen toekomstig gedrag.
Voorspellingen voor de toeleveringsketen en logistiek
Toeleveringsketens worden beïnvloed door talloze variabelen. Vraagfluctuaties, transportvertragingen, voorraadniveaus, betrouwbaarheid van leveranciers, seizoenspatronen – alles is met elkaar verbonden.
Voorspellende analysemodellen verwerken deze complexiteit om de vraag te voorspellen, de voorraad te optimaliseren en verstoringen te voorkomen. Het gebruik van data en voorspellende analyses in de logistiek helpt organisaties om van reactief handelen over te stappen op planmatige reacties.
Vraagvoorspellingsmodellen analyseren historische verkoopgegevens in combinatie met externe factoren zoals het weer, economische indicatoren en markttrends. Retailers voorspellen de productvraag weken van tevoren en passen hun voorraad aan voordat er tekorten of overschotten ontstaan.
Transport- en routeoptimalisatie maken gebruik van voorspellende modellen om levertijden te voorspellen, rekening houdend met verkeerspatronen, weersomstandigheden en historische vertragingsgegevens. Logistieke bedrijven verlagen zo de brandstofkosten en verbeteren de nauwkeurigheid van de leveringen.
Maar voorspellende analyses voor de toeleveringsketen gaan verder. Modellen identificeren leveranciersrisico's door de leveringsconsistentie, kwaliteitsindicatoren en externe factoren zoals geopolitieke instabiliteit of de kans op natuurrampen in de regio's van de leveranciers te analyseren.
Modelarchitectuur en technische implementatie
Het bouwen van effectieve voorspellende modellen vereist zorgvuldige architectuurkeuzes.
Neurale netwerken bieden krachtige patroonherkenning, maar vereisen aanzienlijke trainingsdata en rekenkracht. Eenvoudigere modellen zoals logistische regressie werken goed voor binaire classificatieproblemen met duidelijke relaties tussen kenmerken.
De keuze hangt af van de kenmerken van de data en de complexiteit van de voorspelling. Lineaire modellen behandelen eenvoudige verbanden. Niet-lineaire modellen leggen complexe interacties vast, maar lopen het risico op overfitting als de trainingsdata beperkt zijn.
Het voorbewerken van data kost veel implementatietijd. Ruwe data bevat inconsistenties, ontbrekende waarden en uitschieters. Het opschonen en normaliseren van data vóór de modeltraining heeft een grote impact op de voorspellingsnauwkeurigheid.
Feature engineering transformeert ruwe variabelen in betekenisvolle voorspellers. De transactiefrequentie wordt een nuttigere feature dan de pure tijdstempels van de transacties. De snelheid waarmee de temperatuur verandert, voorspelt storingen vaak beter dan de absolute temperatuur.
Modelvalidatie voorkomt overfitting. Trainingsdata leren patronen aan. Validatiedata testen of die patronen generaliseren naar nieuwe gevallen. Testdata leveren de uiteindelijke prestatiemetingen op volledig onbekende voorbeelden.
Bij kruisvalidatie worden gegevens op meerdere manieren opgedeeld om ervoor te zorgen dat modellen consistent presteren op verschillende subsets. K-fold validatie verdeelt de gegevens in segmenten, waarbij op de meeste segmenten wordt getraind en op de rest wordt getest. Vervolgens wordt afgewisseld welk segment als testset dient.

Voorspellende analyses toepassen op industriële werkprocessen
Voorspellende analyses kunnen industriële bedrijven ondersteunen wanneer ze worden gekoppeld aan planning, bedrijfsvoering, apparatuur, productie, kwaliteit of resourcebeheer. AI Superieur Ze werken met AI-consultancy, machine learning, voorspellende analyses, business intelligence, computervisie en de ontwikkeling van maatwerk AI-software. Hun team kan helpen bij het definiëren van de juiste voorspellingstaken, het voorbereiden van bedrijfs- of operationele data, het bouwen van modellen en het koppelen van resultaten aan bestaande systemen. Dit is nuttig voor bedrijven die data willen gebruiken om risico's eerder te signaleren, met meer vertrouwen te plannen of vermijdbare inefficiënties te verminderen.
Kies voor AI Superior voor:
- Het definiëren van gebruiksscenario's voor voorspellende analyses
- Het bouwen van voorspellings- en anomaliedetectiemodellen
- Ondersteuning van voorspellend onderhoud en kwaliteitsanalyse
- BI-tools ontwikkelen rondom operationele data.
- Het integreren van voorspellende inzichten in bedrijfsprocessen.
Neem contact op met AI Superior om toepassingsmogelijkheden van voorspellende analyses te verkennen voor uw industriële data, operationele processen of planningsprocessen.
Implementatie en continue verbetering
Getrainde modellen moeten worden geïntegreerd in operationele systemen.
De implementatiearchitectuur bepaalt hoe voorspellingen de besluitvormers bereiken. Batchverwerking genereert voorspellingen volgens een vast schema, bijvoorbeeld dagelijkse vraagvoorspellingen of wekelijkse rapporten over onderhoudsrisico's. Realtimeverwerking beoordeelt transacties zodra ze plaatsvinden, bijvoorbeeld voor fraudedetectie of directe kwaliteitscontrole.
API-eindpunten stellen meerdere systemen in staat om voorspellingen op te vragen. Een CRM-systeem raadpleegt het klantverloopmodel wanneer de klantenservice contact heeft met een klant. Een voorraadbeheersysteem vraagt vraagvoorspellingen op bij het plannen van aanvullingen van de voorraad.
Het monitoren van ingezette modellen voorkomt een afname van de nauwkeurigheid. Bedrijfsomstandigheden veranderen. Patronen die vorig jaar opgingen, gelden mogelijk niet meer in het volgende kwartaal. Prestatiemetingen van modellen volgen de nauwkeurigheid van voorspellingen op basis van actuele uitkomsten.
Trainingsschema's zorgen ervoor dat modellen worden bijgewerkt met recente gegevens. Sommige organisaties trainen maandelijks. Andere activeren een training wanneer de nauwkeurigheid onder bepaalde drempelwaarden daalt. Kritieke applicaties kunnen continu worden getraind zodra er nieuwe gelabelde gegevens binnenkomen.
Het concept van autonome data-naar-AI-platformen vertegenwoordigt de volgende evolutie. Organisaties gaan verder dan eenvoudige voorspellingen en creëren intelligente agenten die op basis van voorspellingen handelen. Systemen passen automatisch de voorraad aan op basis van vraagvoorspellingen of plannen onderhoud in op basis van risicoscores van apparatuur.
Branchespecifieke implementatie-uitdagingen
Elke branche staat voor unieke uitdagingen op het gebied van voorspellende analyses.
In de productie speelt de kwaliteit van sensorgegevens een belangrijke rol. Industriële omgevingen genereren elektrische ruis, extreme temperaturen en trillingen die metingen kunnen verstoren. Modellen moeten onderscheid kunnen maken tussen daadwerkelijke degradatiesignalen en omgevingsinvloeden.
De financiële sector moet zich aan de regelgeving houden. Modelbeslissingen die van invloed zijn op leningen of verzekeringen vereisen vaak verklaarbaarheid. Complexe neurale netwerken die als black boxes fungeren, stuiten op compliance-uitdagingen, zelfs wanneer ze een superieure nauwkeurigheid leveren.
Voorspellende modellen in de gezondheidszorg verwerken gevoelige patiëntgegevens onder strikte privacyregelgeving. Het trainen van modellen op beschermde gezondheidsinformatie vereist zorgvuldige anonimisering. De implementatie moet het risico op heridentificatie voorkomen.
Retailprognoses hebben te maken met snelle trendveranderingen en externe verstoringen. Vraagpatronen die jarenlang standhielden, kunnen van de ene op de andere dag veranderen als gevolg van virale berichten op sociale media of onverwachte gebeurtenissen.
| Industrie | Primaire toepassing | Belangrijkste uitdaging | Succesindicator |
|---|---|---|---|
| Productie | Onderhoud van apparatuur | Kwaliteit van sensorgegevens | Vermindering van uitvaltijd |
| Bankieren | Voorspelling van klantverloop | Model verklaarbaarheid | Verbetering van de retentie |
| Detailhandel | Eis voorspelling | Snelle trendveranderingen | Voorraadoptimalisatie |
| Logistiek | Route-optimalisatie | Realtime aanpassing | Leveringsnauwkeurigheid |
Voorspellende modellen in de energiesector voorspellen verbruikspatronen en storingen in apparatuur voor energieopwekking en -distributie. Netbeheerders gebruiken deze voorspellingen om vraag en aanbod in evenwicht te brengen, stroomuitval te voorkomen en het gebruik van energiebronnen te optimaliseren.
In de bouwsector worden voorspellende analyses toegepast op projectplanningen, budgetoverschrijdingen en veiligheidsincidenten. Modellen die getraind zijn op historische projectgegevens identificeren risicofactoren die doorgaans leiden tot vertragingen of budgetverhogingen.
Het meten van het succes van voorspellende modellen
De nauwkeurigheid van een model alleen is geen maatstaf voor succes.
Classificatiemodellen gebruiken precisie, recall en F1-score. Precisie meet welk percentage van de positieve voorspellingen correct is. Recall geeft aan welk percentage van de daadwerkelijke positieve voorspellingen het model correct identificeert. De F1-score is een evenwichtige maatstaf voor beide.
Regressiemodellen zijn gebaseerd op de gemiddelde absolute fout of de wortel van de gemiddelde kwadratische fout. Deze meetwaarden kwantificeren hoe sterk de voorspellingen gemiddeld afwijken van de werkelijke waarden.
Maar de impact op de bedrijfsvoering is het belangrijkst. Een churn-model met een nauwkeurigheid van 90% levert geen enkele waarde op als de organisatie niet reageert op de voorspellingen. Omgekeerd kan een onderhoudsmodel met een nauwkeurigheid van 75% miljoenen besparen als het zelfs maar een paar kritieke storingen voorkomt.
De berekening van het rendement op investering vergelijkt de implementatiekosten van het model met de operationele verbeteringen. Minder stilstand, lagere voorraadkosten en een betere klantretentie vertalen zich allemaal in een positief financieel effect.
De echte test vindt plaats in de praktijk. Voorspellingen worden gevalideerd wanneer voorspelde gebeurtenissen zich voordoen of juist niet. Continue monitoring van de voorspelling versus de werkelijkheid laat zien of modellen hun nauwkeurigheid behouden naarmate de omstandigheden veranderen.
Toekomstige ontwikkelingen in industriële voorspellende analyses
De voorspellende mogelijkheden blijven zich ontwikkelen naarmate de hoeveelheid data toeneemt en de algoritmes verbeteren.
Edge computing brengt voorspellende modellen rechtstreeks naar industriële apparatuur. In plaats van sensorgegevens naar cloudservers te sturen voor analyse, draaien de modellen op lokale processors die in de machines zijn ingebouwd. Dit vermindert de latentie en maakt een onmiddellijke reactie op voorspelde storingen mogelijk.
Geautomatiseerde machine learning-platforms vereenvoudigen de modelontwikkeling. Systemen testen automatisch meerdere algoritmen, optimaliseren hyperparameters en selecteren de best presterende aanpak. Datawetenschappers kunnen zich richten op bedrijfsproblemen in plaats van op het handmatig afstemmen van modellen.
Federated learning maakt het mogelijk om modellen te trainen over gedistribueerde datasets zonder gevoelige gegevens te centraliseren. Organisaties werken samen om de nauwkeurigheid van voorspellingen te verbeteren en tegelijkertijd de privacy van gegevens te waarborgen.
Verklaarbare AI-technieken maken complexe modellen beter interpreteerbaar. SHAP-waarden en LIME-analyse onthullen welke kenmerken specifieke voorspellingen sturen, waardoor organisaties modelbeslissingen beter kunnen begrijpen en erop kunnen vertrouwen.
De overgang van voorspellende naar prescriptieve analyses vertegenwoordigt de volgende grens. Modellen zullen niet alleen voorspellen wat er gaat gebeuren, maar ook aanbevelen welke acties ondernomen moeten worden. Prescriptieve systemen optimaliseren beslissingen over meerdere doelstellingen en beperkingen heen.
Aan de slag met voorspellende analyses
Organisaties die beginnen met voorspellende analyses, moeten stap voor stap te werk gaan:
- Identificeer een specifiek bedrijfsprobleem met duidelijke succesindicatoren: Het tegelijkertijd proberen te voorspellen van alles leidt gegarandeerd tot mislukking. Neem bijvoorbeeld één praktijkvoorbeeld: het voorspellen van apparatuurstoringen in een kritieke productielijn of het voorspellen van klantverloop bij waardevolle klantsegmenten.
- Beoordeel de beschikbaarheid en kwaliteit van de gegevens: Voorspellende modellen hebben historische voorbeelden nodig die de te voorspellen uitkomst omvatten. Als gegevens over apparatuurstoringen niet systematisch werden bijgehouden, vereist het bouwen van een storingsvoorspellingsmodel dat er eerst een registratieproces wordt opgezet.
- Begin eenvoudig: Logistische regressie of beslissingsbomen bieden vaak verrassende nauwkeurigheid met minimale complexiteit. Bewijs de waarde met eenvoudige modellen voordat u investeert in geavanceerde neurale netwerkarchitecturen.
- Stel feedbackloops in: Implementeer de modellen in eerste instantie in een schaduwmodus, waarbij ze voorspellingen genereren naast bestaande processen zonder daarop in te grijpen. Vergelijk de voorspellingen met de werkelijke resultaten. Verfijn de modellen voordat u ze beslissingsbevoegdheid geeft.
- Ontwikkel organisatorische capaciteiten: Succesvolle voorspellende analyses vereisen data-engineering, statistische expertise, domeinkennis en verandermanagement. Niemand beschikt over al deze vaardigheden – stel daarom multidisciplinaire teams samen.
Veelgestelde vragen
Wat is het verschil tussen voorspellende analyses en traditionele business intelligence?
Traditionele business intelligence analyseert historische gegevens om te begrijpen wat er is gebeurd en waarom. Dashboards, rapporten en beschrijvende statistieken beantwoorden vragen over prestaties uit het verleden. Voorspellende analyses gebruiken die historische gegevens om toekomstige resultaten te voorspellen. In plaats van het klantverloop van het afgelopen kwartaal te rapporteren, identificeren voorspellende modellen welke huidige klanten waarschijnlijk in het volgende kwartaal zullen vertrekken.
Hoeveel historische gegevens heb ik nodig om nauwkeurige voorspellende modellen te bouwen?
De benodigde hoeveelheid data hangt af van de complexiteit van de voorspelling en het aantal kenmerken. Eenvoudige problemen met weinig variabelen kunnen bruikbare modellen opleveren met honderden voorbeelden. Complexe problemen met veel onderling samenwerkende kenmerken vereisen doorgaans duizenden tot tienduizenden voorbeelden. De dataset over klantverloop die een nauwkeurigheid van 89,61 TP3T behaalde, bevatte 10.000 records met 14 kenmerken. Over het algemeen geldt dat meer data de nauwkeurigheid verbetert, maar de kwaliteit van de data is belangrijker dan de kwantiteit.
Kunnen kleine bedrijven voorspellende analyses implementeren zonder data science-teams?
Ja, maar de verwachtingen moeten wel aansluiten bij de beschikbare middelen. Cloudplatformen bieden tegenwoordig geautomatiseerde machine learning-tools die een groot deel van de technische complexiteit afhandelen. Kleine bedrijven kunnen beginnen met gerichte toepassingen zoals het voorspellen van de klantlevenswaarde of het optimaliseren van de voorraad met behulp van deze platforms. De sleutel is om te beginnen met schone data en een goed gedefinieerd bedrijfsprobleem. Overweeg om voor de initiële implementatie samen te werken met analytics-consultants, terwijl u tegelijkertijd de interne capaciteiten opbouwt.
Hoe vaak moeten voorspellende modellen opnieuw getraind worden met nieuwe gegevens?
De frequentie van het bijscholen hangt af van hoe snel patronen veranderen in de onderliggende bedrijfsomgeving. Vraagmodellen in de detailhandel moeten mogelijk maandelijks worden bijgeschoold om seizoensschommelingen en trendveranderingen vast te leggen. Modellen voor storingen in industriële apparatuur kunnen kwartalen lang accuraat blijven als de bedrijfsomstandigheden stabiel blijven. Monitor de prestatiecijfers van het model continu: als de nauwkeurigheid onder de acceptabele drempelwaarde daalt, moet er bijgeschoold worden. Veel organisaties hanteren een kwartaalschema voor bijscholen als basis.
Wat gebeurt er als voorspellingen onjuist blijken?
Geen enkel voorspellingsmodel bereikt perfecte nauwkeurigheid. Organisaties moeten processen ontwerpen die rekening houden met voorspellingsfouten. Vals-positieven – het voorspellen van een gebeurtenis die niet plaatsvindt – kunnen leiden tot verspilling van middelen aan onnodige interventies. Vals-negatieven – het missen van gebeurtenissen die wél plaatsvinden – betekenen gemiste kansen om problemen te voorkomen. De acceptabele foutenmarge hangt af van de kosten van elk type fout. Het voorspellen van een defect aan apparatuur terwijl dit niet gebeurt, kost een onderhoudsbezoek. Het missen van een daadwerkelijk defect kost een volledige productiestop.
Heb ik realtime voorspellingen nodig of zijn batchprognoses voldoende?
Dit hangt af van de timing van de besluitvorming. Fraudebestrijding vereist realtime verwerking, omdat transacties onmiddellijk moeten worden goedgekeurd of afgewezen. Vraagvoorspelling voor voorraadplanning werkt prima met nachtelijke batchverwerking, aangezien inkoopbeslissingen over langere tijd worden genomen. Realtime systemen brengen complexiteit en kosten met zich mee – implementeer ze alleen wanneer onmiddellijke actie op basis van voorspellingen daadwerkelijk zakelijke waarde oplevert.
Hoe overtuig ik het management om te investeren in voorspellende analyses?
Begin met een pilotproject dat een zichtbaar, kostbaar bedrijfsprobleem aanpakt. Bereken de potentiële ROI op basis van conservatieve aannames. Als het voorkomen van slechts drie defecten aan apparatuur meer bespaart dan de implementatiekosten van het model, is de businesscase duidelijk. Gebruik de resultaten van de pilot om de waarde aan te tonen voordat u grotere investeringen aanvraagt. Focus op bedrijfsresultaten in plaats van technische mogelijkheden – het management is geïnteresseerd in lagere kosten en hogere inkomsten, niet in de complexiteit van het algoritme.
Voorspellingen inzetten voor uw branche
Voorspellende analyses transformeren reactieve organisaties in proactieve organisaties. Apparatuur gaat minder vaak kapot omdat onderhoud plaatsvindt voordat er storingen optreden. Klanten blijven langer klant omdat interventies problemen aanpakken voordat ontevredenheid tot vertrek leidt. Toeleveringsketens verlopen soepel omdat verstoringen worden voorspeld en beperkt.
De technologie blijft zich ontwikkelen, maar de kernprincipes blijven constant. Schone historische data in combinatie met geschikte statistische technieken maken het mogelijk om toekomstige resultaten te voorspellen. De nauwkeurigheid van het model is belangrijk, maar de impact op de bedrijfsvoering bepaalt het succes.
Industrieën die voorspellende analyses effectief inzetten, behalen concurrentievoordelen. Ze optimaliseren processen die anderen niet kunnen evenaren. Ze voorkomen problemen waar concurrenten pas achteraf op reageren. Ze nemen datagestuurde beslissingen, terwijl anderen op intuïtie vertrouwen.
De vraag is niet of voorspellende analyses waarde opleveren – bewezen implementaties in de productie, financiën, detailhandel en logistiek bewijzen het tegendeel. De vraag is of organisaties bereid zijn te investeren in de data-infrastructuur, analytische mogelijkheden en culturele veranderingen die nodig zijn om die waarde te benutten.
Begin gericht. Bewijs de waarde aan de hand van specifieke gebruiksscenario's. Bouw de mogelijkheden stapsgewijs op. Organisaties die vandaag de dag voorspellende analyses beheersen, positioneren zichzelf om morgen een leidende rol in hun branche te spelen.