Quick Summary: Deep learning is a specialized subset of machine learning that uses multi-layered neural networks to automatically learn complex patterns from raw data. Machine learning is a broader field of AI that includes deep learning plus traditional algorithms requiring human-designed features. The key distinction: machine learning needs manual feature engineering and works well with smaller datasets, while deep learning automatically extracts features but demands large amounts of data and computational power.
The terms machine learning and deep learning get thrown around interchangeably in tech circles. But here’s the thing—they’re not the same, and understanding the distinction matters if you’re building AI systems or just trying to make sense of what powers modern technology.
Both fall under the artificial intelligence umbrella. Both learn from data. Yet the way they approach problems, handle information, and deliver results differs fundamentally.
According to Stanford HAI, deep learning is a subset of machine learning that uses large multi-layered neural networks to automatically learn complex patterns from data. Instead of a person manually programming features to look for, these models discover increasingly abstract representations on their own.
Sound familiar? That’s because deep learning powers the voice assistant on your phone, the recommendation engine on streaming platforms, and the language models reshaping how we work.
What Is Machine Learning?
Machine learning is a methodology within artificial intelligence where systems learn from data without being explicitly programmed for every scenario. Rather than writing rules for each possible input, developers train models to recognize patterns and make predictions based on examples.
The approach relies on algorithms that improve through experience. Feed a machine learning model enough labeled data—say, emails marked as spam or not spam—and it learns to classify new emails on its own.
But there’s a catch. Traditional machine learning requires feature engineering—the process where humans manually select and design the data characteristics the model should examine. For image recognition, that might mean programming the system to look for edges, corners, or specific color patterns.
This human intervention shapes what the model learns. Choose the wrong features, and performance suffers. Choose well, and even relatively simple algorithms can deliver solid results on structured data.
Types of Machine Learning
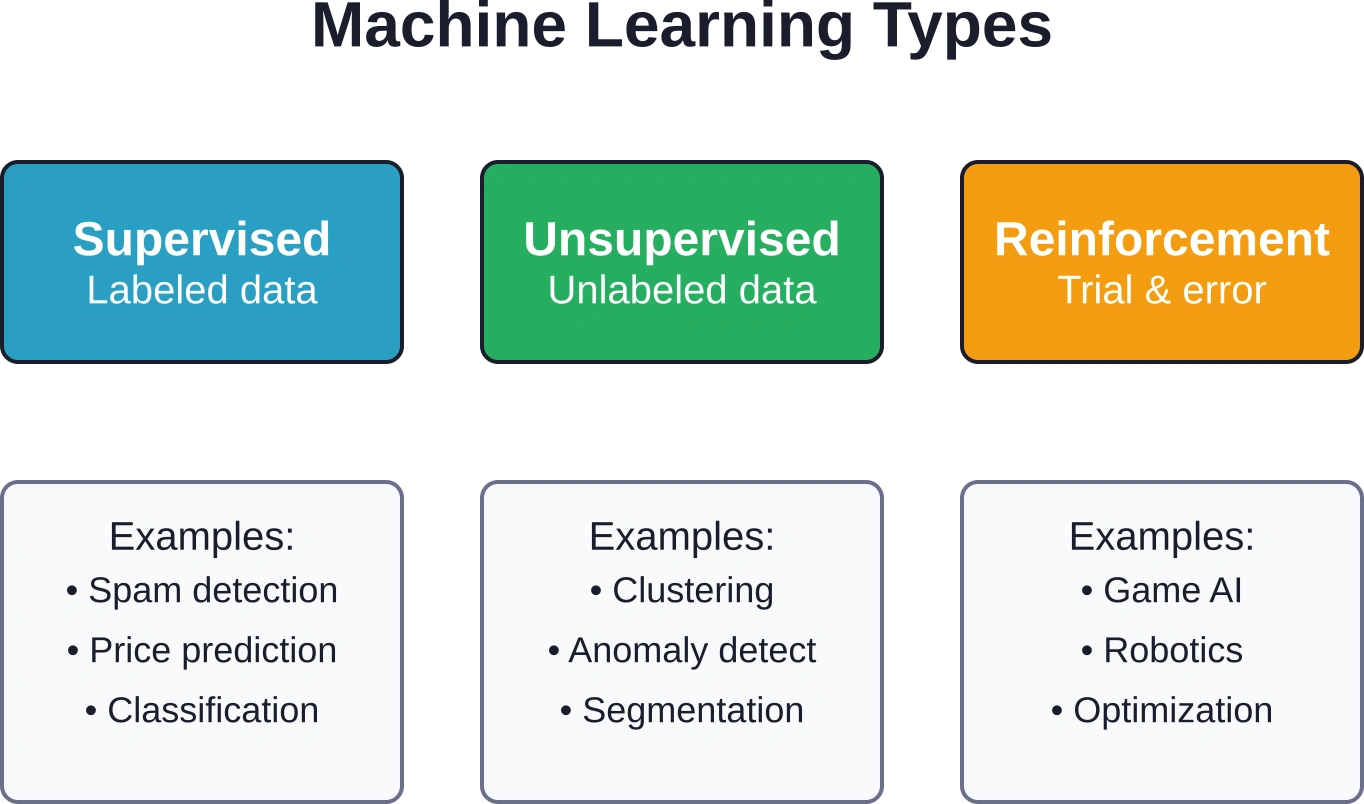
Machine learning splits into three main categories based on how the algorithm learns:
- Supervised learning trains on labeled data where the correct answer is known. The model learns to map inputs to outputs—like predicting house prices based on square footage, location, and age. Most business applications fall into this category.
- Unsupervised learning works with unlabeled data, finding hidden patterns without predefined categories. Clustering customers by purchasing behavior or detecting anomalies in network traffic exemplifies this approach.
- Reinforcement learning trains through trial and error, receiving rewards or penalties based on actions taken. Game-playing AI and robotics often use this method, though it’s less common in traditional business contexts.
What Is Deep Learning?
Deep learning takes machine learning further by using neural networks with multiple layers—hence “deep.” These networks consist of interconnected nodes (neurons) organized in layers that process data sequentially, each layer extracting increasingly complex features.
The architecture mirrors how researchers understand the human brain processes information, though the biological analogy has limits. What matters practically: deep learning models can automatically discover the representations needed for feature detection from raw data.
No manual feature engineering required. Feed a deep learning system raw images, and it learns on its own to recognize edges in early layers, shapes in middle layers, and complete objects in deeper layers.
This automatic feature learning makes deep learning especially powerful for unstructured data—images, audio, text, video. Tasks that stumped traditional machine learning for decades became suddenly tractable.
Neural Networks Explained
At the core of deep learning sits the neural network. Think of it as a series of processing layers, each containing multiple nodes that perform mathematical operations on incoming data.
Information flows forward through the network. Each connection between nodes has a weight that gets adjusted during training. The network learns by tweaking these weights to minimize prediction errors—a process called backpropagation.
Shallow neural networks might have one or two hidden layers between input and output. Deep networks stack dozens or even hundreds of layers, enabling them to model extremely complex relationships.
The depth comes with a cost: computational intensity. Training deep neural networks requires significant processing power, which is why the field exploded alongside advances in GPU computing.
Key Differences Between Machine Learning and Deep Learning
Now, this is where it gets interesting. While deep learning falls under the machine learning umbrella, several fundamental differences separate them in practice.
Data Requirements
Traditional machine learning algorithms can perform well with smaller datasets—sometimes just thousands of examples. Statistical methods like decision trees, random forests, or support vector machines extract meaningful patterns from limited data.
Deep learning demands volume. Neural networks contain millions of parameters that need tuning, requiring massive datasets to train effectively. Feed a deep learning model too little data, and it overfits—memorizing training examples rather than learning generalizable patterns.
Industry reports suggest deep learning typically needs tens of thousands to millions of labeled examples to reach peak performance, though transfer learning techniques can reduce this requirement.
Feature Engineering
Here’s where the workload shifts dramatically. Machine learning practitioners spend considerable time on feature engineering—selecting, transforming, and creating the input variables their models will use.
Got customer data? Developers might create features like “days since last purchase,” “average order value,” or “purchase frequency” before training begins. This domain expertise shapes model performance.
Deep learning automates this process. The neural network layers learn features hierarchically during training. This reduces human effort but also creates a tradeoff: less control over what the model actually learns.
Computational Resources
Run a machine learning model on your laptop? Absolutely. Many traditional algorithms train quickly on standard hardware, making them accessible and practical for resource-constrained scenarios.
Deep learning models are computational beasts. Training state-of-the-art networks requires specialized hardware—GPUs or TPUs—and can take days or weeks even on powerful systems. Operating costs rise accordingly.
Inference (using a trained model) also differs. Machine learning models typically return predictions in milliseconds on basic hardware. Large deep learning models may need dedicated infrastructure to meet real-time latency requirements.
Interpretability
Machine learning models, especially simpler ones like decision trees or linear regression, offer transparency. Developers can trace exactly why a model made a specific prediction, which matters in regulated industries or high-stakes decisions.
Deep learning operates as a black box. With millions of weights across dozens of layers, understanding why a neural network made a particular choice becomes nearly impossible. Research into explainable AI tries to address this, but interpretability remains a persistent challenge.
MIT research from December 2021 highlighted a concern: neural networks trained on datasets like CIFAR-10 made confident predictions even when 95 percent of input images were missing, with the remainder senseless to humans. This overinterpretation raises questions about reliability in critical applications.
Performance Trade-offs
For structured, tabular data—think spreadsheets with rows and columns—traditional machine learning often wins. Decision trees, gradient boosting, and similar methods frequently outperform neural networks on these tasks while training faster and requiring less data.
Deep learning dominates unstructured data. Image recognition, natural language processing, speech recognition—these domains saw revolutionary improvements once deep learning matured. Research indicates deep learning can achieve higher accuracy on image tasks compared to traditional machine learning, with some studies showing performance differences in this range.
The gap widens as task complexity increases. Simple classification might favor traditional approaches. Complex pattern recognition across high-dimensional data swings toward deep learning.

Choose the Right AI Approach With AI Superior
The deep learning vs machine learning question is not just technical. It affects data needs, development time, model complexity, and how the solution will be used in practice. AI Superior helps companies compare AI approaches through AI consulting, core machine learning, deep learning, predictive analytics, NLP, computer vision, and custom AI software development. Before building, their team can review the use case, available data, and expected output. This helps companies avoid choosing a heavier model than necessary while still leaving room for more advanced AI when the problem actually requires it.
AI Superior can help assess:
- Whether machine learning or deep learning fits the task
- Data requirements for different model types
- Predictive analytics use cases and model options
- Deep learning applications in vision or language workflows
- Integration of selected AI models into custom software
👉Contact AI Superior to discuss which AI approach fits your project, data, or product requirements.
Practical Applications and Use Cases
Real talk: choosing between machine learning and deep learning isn’t about which is “better”—it’s about matching the tool to the problem.
When Machine Learning Shines
Structured data problems favor traditional machine learning. Predicting customer churn, detecting credit card fraud, forecasting sales, or recommending products based on purchase history—these scenarios typically involve tabular data where relationships are relatively direct.
Limited data scenarios also point toward machine learning. Training a model with only a few hundred examples? Deep learning will struggle. Algorithms like random forests or gradient boosting can extract meaningful patterns from smaller datasets.
Need interpretability? Machine learning delivers. Financial institutions use decision trees for loan approvals because regulators require explanations for credit decisions. Medical diagnostics benefit similarly—doctors want to understand why a model flagged a particular risk.
When Deep Learning Dominates
Image recognition transformed once deep learning matured. Facial recognition, medical imaging analysis, autonomous vehicle vision systems, quality control in manufacturing—convolutional neural networks revolutionized these domains.
Natural language processing saw similar leaps. Machine translation, sentiment analysis, chatbots, and document summarization all improved dramatically with deep learning architectures like transformers. The language models reshaping business communications in 2026 rely entirely on deep neural networks.
Speech recognition, once frustratingly inaccurate, became reliable through deep learning. Voice assistants, transcription services, and accessibility tools all leverage recurrent or convolutional networks trained on massive audio datasets.
Video analysis, anomaly detection in complex systems, and generative AI—creating new images, text, or audio—all depend on deep learning’s ability to model intricate patterns in high-dimensional data.
Deciding on the Right Approach
So how do practitioners decide? Several factors guide the choice:
- Data volume matters most: Got millions of examples? Deep learning becomes viable. Working with hundreds or thousands? Stick with traditional machine learning.
- Data type shapes the decision: Structured, tabular data leans toward machine learning. Images, text, audio, or video point to deep learning.
- Resource constraints can’t be ignored: Limited budget and computing power favor machine learning’s efficiency. Access to GPUs and time for lengthy training opens deep learning possibilities.
- Accuracy requirements versus interpretability create tension: Need the highest possible accuracy on a complex task? Deep learning might be worth the black-box tradeoff. Require transparency and explainability? Machine learning’s simpler models offer clarity.
- Domain expertise availability influences feature engineering feasibility: Strong subject matter experts can craft effective features for machine learning. Lack of domain knowledge tilts toward letting deep learning discover features automatically.
| Consideration | Machine Learning | Deep Learning |
|---|---|---|
| Dataset Size | Hundreds to thousands | Thousands to millions |
| Data Type | Structured/tabular | Unstructured (image/text/audio) |
| Training Time | Minutes to hours | Hours to weeks |
| Hardware Needs | Standard CPU | GPU/TPU preferred |
| Feature Engineering | Manual, domain-driven | Automatic, learned |
| Interpretability | High (especially simple models) | Low (black box) |
The Relationship to Artificial Intelligence
Both machine learning and deep learning live within the broader artificial intelligence landscape. AI encompasses any technique that enables computers to mimic human intelligence—including rule-based systems that don’t learn at all.
Machine learning represents a subset of AI focused on learning from data. Deep learning narrows further as a subset of machine learning using neural networks with multiple layers.
The hierarchy looks like this: AI contains machine learning, which contains deep learning. All deep learning is machine learning, but not all machine learning is deep learning. All machine learning is AI, but not all AI is machine learning.
According to MIT Sloan research, about 35% of businesses globally were using AI in recent surveys, with another 42% exploring the technology. The development of generative AI—which uses powerful deep learning foundation models—accelerated adoption since 2022.
But wait. This doesn’t mean deep learning replaced machine learning. Different tools serve different purposes. Many production systems combine both approaches, using traditional machine learning for structured data pipelines while applying deep learning to unstructured inputs.
Current Trends and Future Directions
The field keeps evolving. Transfer learning reduces deep learning’s data hunger by starting with pre-trained models and fine-tuning them for specific tasks—sometimes requiring only hundreds rather than millions of examples.
Model compression techniques make deep learning more accessible, shrinking networks to run on mobile devices or edge computing hardware without massive computational overhead.
AutoML platforms automate model selection and hyperparameter tuning for both machine learning and deep learning, reducing the expertise barrier for implementation.
Hybrid approaches combine traditional machine learning’s interpretability with deep learning’s pattern recognition power. Researchers explore neural networks that can explain their decisions or incorporate domain knowledge through structured architectures.
Generative AI—the technology behind tools like ChatGPT—represents deep learning’s latest frontier, creating entirely new content rather than just classifying or predicting. This subset uses transformer architectures and massive datasets to generate text, images, code, and more.
Frequently Asked Questions
Is deep learning better than machine learning?
Neither is universally better—they excel at different tasks. Deep learning outperforms on complex unstructured data like images and text when large datasets are available. Traditional machine learning often wins on structured data, smaller datasets, and scenarios requiring interpretability or limited computational resources.
Does deep learning require coding knowledge?
Building deep learning models from scratch requires programming skills, typically in Python with frameworks like TensorFlow or PyTorch. However, no-code and low-code platforms now exist that allow model training and deployment through visual interfaces, making deep learning more accessible to non-programmers.
How much data does deep learning need compared to machine learning?
Traditional machine learning can work effectively with hundreds to thousands of training examples. Deep learning typically requires at least tens of thousands of examples, with state-of-the-art models often trained on millions or billions of data points. Transfer learning techniques can reduce these requirements significantly.
Can machine learning and deep learning work together?
Absolutely. Many production systems combine both approaches in complementary ways. Teams might use traditional machine learning for structured data features while applying deep learning to process images or text, then combine predictions from both models for final decisions.
Which should I learn first as a beginner?
Starting with traditional machine learning provides stronger foundations. The mathematical concepts, evaluation methods, and workflow principles apply to both fields. Once comfortable with machine learning basics, transitioning to deep learning becomes more intuitive since it builds on the same core ideas.
Do neural networks always outperform traditional algorithms?
Not at all. On structured tabular data, algorithms like gradient boosting or random forests frequently match or exceed neural network performance while training faster and requiring less data. Neural networks show their strength on unstructured data where traditional methods struggle.
How long does it take to train a deep learning model?
Training time varies enormously based on model size, dataset size, and hardware. Simple networks might train in minutes on a laptop. Large language models or computer vision systems can require days or weeks on specialized GPU clusters. Traditional machine learning models typically train much faster, often in minutes to hours.
Moving Forward
Understanding the distinction between machine learning and deep learning clarifies which approach fits specific problems. Machine learning offers versatility, efficiency, and interpretability for structured data and resource-constrained scenarios. Deep learning unlocks unprecedented performance on complex unstructured data when computational resources and large datasets are available.
The choice isn’t about following trends—it’s about matching capabilities to requirements. Some teams jump to deep learning because it’s cutting-edge, then discover traditional machine learning would have delivered better results faster. Others stick with familiar methods when deep learning could solve previously intractable problems.
Both fields continue advancing rapidly. Staying informed about their relative strengths helps developers, data scientists, and business leaders make smarter technology decisions.
Ready to apply these concepts? Start by examining your specific use case: data type, volume, accuracy requirements, and resource constraints. The right tool becomes clear once you understand what each approach truly offers.