Quick Summary: ChatGPT is built on large language models (LLMs) — transformer-based neural networks trained on vast text datasets to predict and generate human-like text. These models use attention mechanisms to understand context, then generate responses token by token. While incredibly powerful for text generation, coding, and conversation, they have limitations like occasional inaccuracies, lack of real-time knowledge, and sensitivity to prompt phrasing.
Thanks to ChatGPT, artificial intelligence has moved from tech circles into everyday conversation. People use it for writing emails, debugging code, brainstorming ideas, and even drafting legal documents.
But how does it actually work? What’s happening when you type a prompt and get back a coherent, human-like response in seconds?
The answer lies in large language models — sophisticated neural networks that have fundamentally changed how machines understand and generate text. This guide breaks down the architecture, training process, and practical applications without the hype.
What Are Large Language Models?
Large language models are AI systems designed to understand and generate human language. At their core, they’re prediction engines — given some input text, they predict what words should come next.
But that simple description undersells what they’ve achieved. Modern LLMs like GPT-5.5 can write code, answer questions, translate languages, summarize documents, and carry on conversations that feel remarkably natural.
The “large” part matters. These models contain billions of parameters — adjustable weights that determine how the model processes information. GPT-5.5 represents the latest generation, offering improved reasoning capabilities compared to earlier versions.
The Foundation: Transformer Architecture
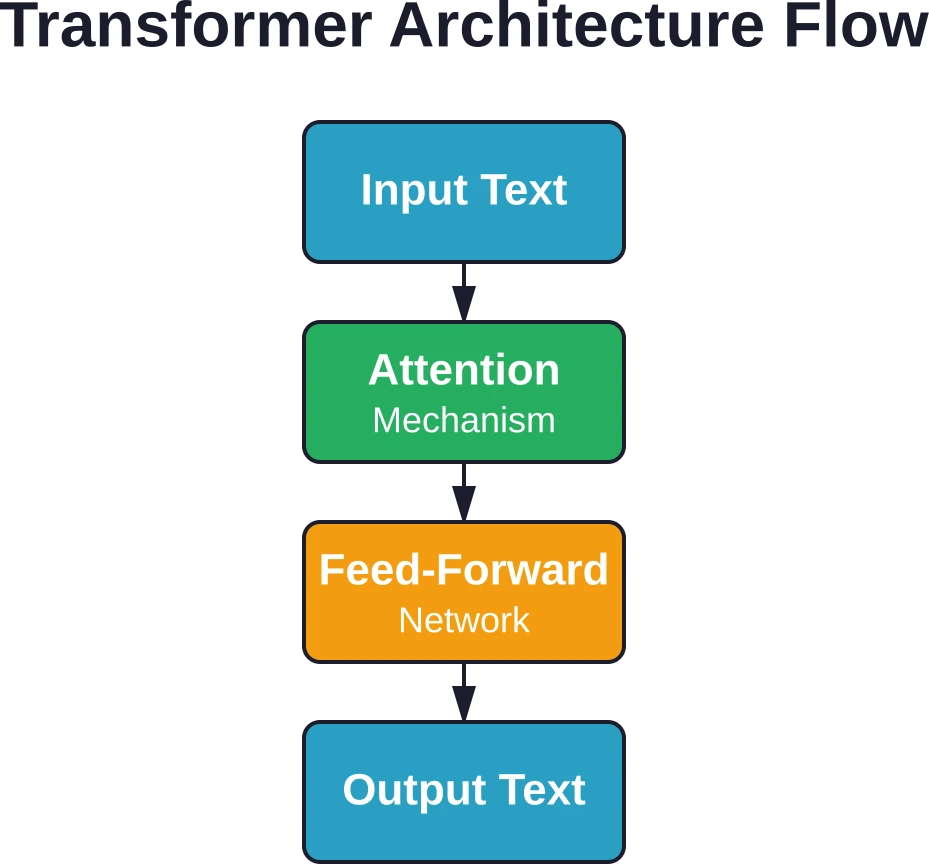
Large language models are built on transformer architecture, introduced in the foundational research paper “Attention Is All You Need.” This architecture replaced older sequence models with a more efficient approach.
Here’s what makes transformers special: they process entire sequences of text simultaneously rather than word by word. This parallel processing enables them to handle much longer contexts and train far more efficiently.
The transformer architecture relies on something called the attention mechanism. This allows the model to weigh the importance of different words in a sequence when generating predictions.
Think about the sentence: “The animal didn’t cross the street because it was too tired.” To understand what “it” refers to, the model needs to pay attention to “animal” rather than “street.” Attention mechanisms handle exactly this kind of contextual reasoning.
How Text Becomes Numbers
Language models don’t actually work with words — they work with numbers. Before processing begins, text gets converted into tokens, which are then mapped to numerical vectors.
Tokenization breaks text into smaller units. Sometimes a token is a whole word; sometimes it’s just a few characters. The word “chatbot” might become one token, while “unprecedented” might split into “un,” “pre,” and “cedented.”
Each token gets mapped to a high-dimensional vector — essentially a list of numbers that represents that token’s “meaning” in a mathematical space. Words with similar meanings end up with similar vectors.
This numerical representation allows the model to perform mathematical operations on language, finding patterns and relationships that would be impossible to code manually.

Develop Progressive Tools With AI Superior
AI Superior builds AI-based applications and custom software products using machine learning and AI models. Their services include AI software development, consulting, R&D, training, NLP, predictive analytics, BI, and big data analytics.
Need an AI Tool Built for Your Workflow?
AI Superior can help with:
- building custom NLP and LLM tools
- testing chatbot ideas through PoC or MVP work
- analyzing text and document data
- integrating AI tools into existing systems
👉 Contact AI Superior to discuss your project.
How ChatGPT Generates Text
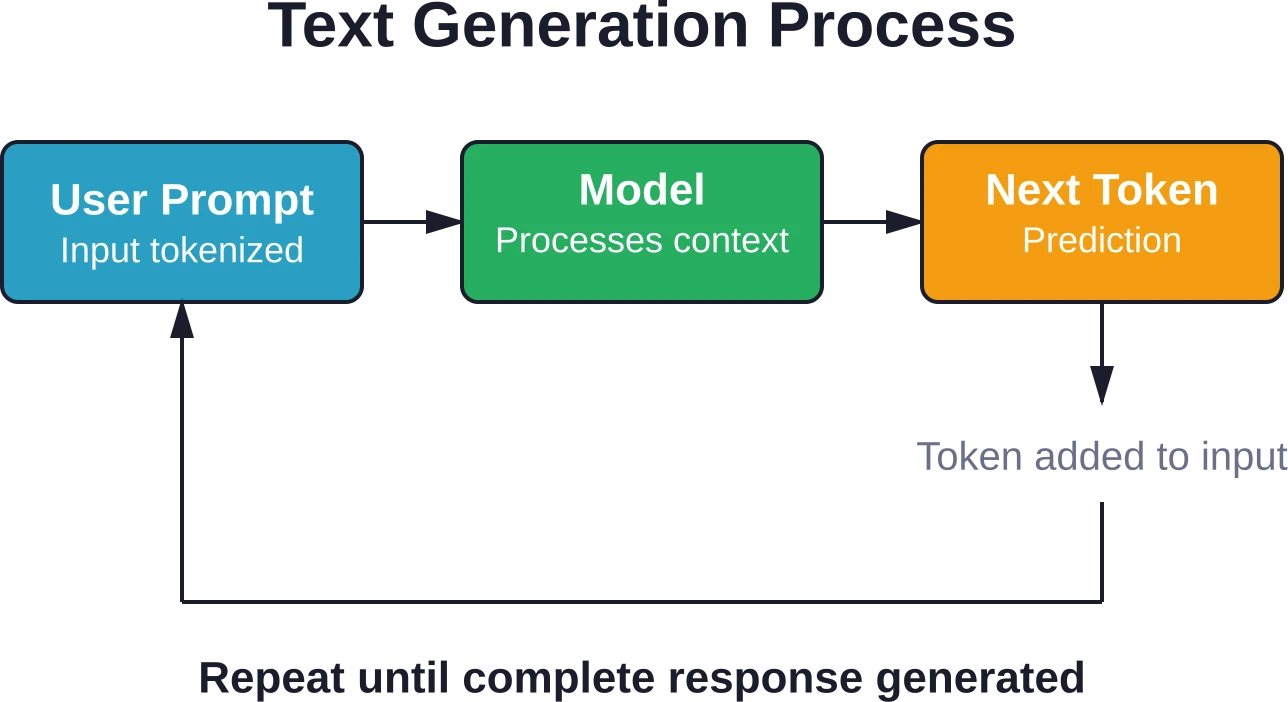
When you send a prompt to ChatGPT, a sophisticated prediction process kicks off. The model doesn’t generate the entire response at once — it produces one token at a time.
Here’s the sequence: the model takes your prompt, processes it through multiple transformer layers, and predicts the most likely next token. That predicted token gets added to the input, and the process repeats until the model generates a stopping signal.
This autoregressive approach means each word influences the next. When the model makes an error early in its response, that error can compound as the model builds on its own incorrect output.
The Role of Temperature and Sampling
The model doesn’t always pick the single most likely next word. That would make responses predictable and repetitive.
Instead, language models use controlled randomness. The temperature parameter controls how much randomness to introduce. Low temperature makes the model more deterministic and focused. High temperature introduces more variety but risks incoherence.
OpenAI’s API allows developers to adjust these parameters. For tasks requiring precision — like code generation or data extraction — lower temperatures work better. Creative writing benefits from slightly higher values.
Training Large Language Models
Creating a model like ChatGPT involves multiple training stages, each serving a distinct purpose.
Pre-Training: Learning Language Patterns
Pre-training is where the model learns basic language understanding. During this phase, the model processes enormous datasets — books, websites, articles, code repositories, and more.
The training objective is simple: predict the next word. By performing this billions of times across diverse text, the model learns grammar, facts, reasoning patterns, and even some common sense.
This phase requires massive computational resources. Training runs can take weeks or months on clusters of specialized hardware.
Fine-Tuning: Specializing Behavior
Pre-trained models are knowledgeable but not always helpful. They might generate accurate but inappropriate responses, or fail to follow instructions properly.
Fine-tuning addresses this. According to research from Stanford HAI, fine-tuning customizes foundation models for specific tasks or behaviors, though it also introduces safety risks if not carefully controlled.
For ChatGPT, fine-tuning involves training on curated datasets of high-quality conversations, with human feedback guiding the model toward helpful, harmless, and honest responses.
Reinforcement Learning from Human Feedback
The final training stage uses reinforcement learning. Human evaluators rank different model responses to the same prompt. These rankings train a reward model that predicts human preferences.
The language model then gets optimized to generate responses that score higher on this reward model. This approach helps align the model’s behavior with human values and expectations.
It’s not perfect — the model learns to optimize for what the evaluators prefer, which doesn’t always match what’s objectively best. But it’s currently the most effective alignment technique available.
The OpenAI API and GPT-5.5
While ChatGPT provides a consumer interface, the OpenAI API gives developers programmatic access to the underlying models. As of the official documentation, the API uses RESTful endpoints that work via standard HTTP requests.
According to the official OpenAI API documentation, authentication uses API keys via HTTP Bearer authentication. These keys should never be exposed in client-side code — they’re meant for server-side applications only.
Current Model Options
The API offers access to multiple models at different capability and price points. Based on official OpenAI documentation, GPT-5.5 is the latest model family, designed for complex production workflows.
GPT-5.5 excels at coding tasks, tool-heavy agent workflows, long-context retrieval, and customer-facing applications where response quality is critical. According to official guidance, it should be treated as a new model family to tune for, not a drop-in replacement for older versions.
The official documentation shows three GPT-5.5 variants available for ChatGPT Business users: GPT-5.5-Instant with virtually unlimited usage for routine tasks, GPT-5.5 Thinking with 3000 requests per week for ChatGPT Business users for complex reasoning, and GPT-5.5 Pro with 15 requests per month for the most demanding workloads.
| Model | Best For | Key Strength |
|---|---|---|
| GPT-5.5 Instant | High-volume tasks | Speed and availability |
| GPT-5.5 Thinking | Complex reasoning | Multi-step problem solving |
| GPT-5.5 Pro | Premium workloads | Maximum capability |
Making API Calls
According to the official API documentation, the Responses API handles direct model requests for text generation. The basic pattern involves creating a client, specifying a model, and providing input text.
The API returns structured responses with the generated text in the output_text field. Developers can adjust parameters like temperature, maximum tokens, and stop sequences to control generation behavior.
For production applications, proper error handling and rate limiting are essential. The API enforces usage limits based on your account tier and can return rate limit errors during high-traffic periods.
ChatGPT Subscription Plans
OpenAI offers several subscription tiers with different capabilities and limits. Pricing and features are updated regularly, so checking the official pricing page is recommended for current information.
Consumer Plans
According to the official OpenAI Help Center, ChatGPT Go is a low-cost subscription providing expanded access to popular features. It includes unlimited access to GPT-5.5 Instant, extended image generation, file uploads, and advanced data analysis.
ChatGPT Plus is priced at $20 per month according to official sources. It provides access to advanced capabilities like Codex and Deep Research for select projects throughout the week.
ChatGPT Pro comes in two tiers per official documentation: $100 per month for real projects with 5x higher limits than Plus (and 10x Codex usage for a limited time), and $200 per month for heavy workflows with 20x higher limits than Plus (and 25x Codex usage for a limited time).
Business and Enterprise
ChatGPT Business provides secure collaborative workspaces for teams. According to official help documentation, it includes SAML SSO, admin controls, and compliance support for GDPR and CCPA.
Codex, based on official pricing pages, is a development-focused plan with usage-based pricing and no fixed seat fees. It includes AI-powered software engineering, automated code reviews, and built-in environments for multi-agent workflows.
Enterprise plans offer custom solutions for large organizations. Specific pricing and features vary based on organizational needs.

Practical Applications of Large Language Models
Large language models have proven useful across surprisingly diverse domains. Some applications work better than others.
Content Creation and Writing
Writing assistance is one of the most common use cases. LLMs can draft articles, generate marketing copy, write emails, and create social media content.
The quality varies. For straightforward, informational content, LLMs perform well. For content requiring deep expertise, nuanced argument, or original research, human involvement remains essential.
Many writers use LLMs as brainstorming partners or first-draft generators rather than finished-content producers. This collaborative approach often produces better results than either pure human or pure AI work.
Code Generation and Debugging
Programming is where modern LLMs particularly shine. They can write functions, debug errors, translate between programming languages, and explain complex code.
GPT-5.5 shows particular strength in coding tasks according to official documentation. It handles multi-file projects, maintains context across large codebases, and generates production-quality code in many scenarios.
That said, LLM-generated code requires review. Models can produce code that works but follows poor practices, contains subtle bugs, or includes security vulnerabilities.
Data Analysis and Extraction
Language models can process unstructured text and extract structured information. They parse documents, categorize content, extract key facts, and format data for analysis.
For business applications, this enables automated document processing, customer feedback analysis, and information synthesis from large text collections.
The challenge is reliability. Models occasionally miss important information or introduce errors. For critical applications, verification steps are necessary.
Conversational Interfaces
Chatbots and virtual assistants powered by LLMs can handle customer service, answer questions, and guide users through complex processes.
These applications benefit from the model’s ability to understand context, handle varied phrasings, and generate natural responses. The conversation feels less robotic than traditional rule-based systems.
But mistakes happen. Models sometimes provide confident-sounding incorrect information — a behavior called hallucination. Applications handling important decisions need safeguards.
Prompt Engineering: Getting Better Results
How you phrase prompts significantly affects output quality. Prompt engineering has emerged as a skill focused on crafting effective instructions.
Core Principles
Clarity helps. Vague prompts produce vague results. Specific instructions with clear requirements generate more useful outputs.
Context matters. Providing background information, examples, and constraints guides the model toward better responses.
Format specifications work well. If you need JSON output, CSV data, or markdown formatting, explicitly stating that requirement improves compliance.
Common Techniques
Few-shot learning involves providing examples before your actual request. Show the model 2-3 examples of the task you want, then present the real input. This dramatically improves performance on specific patterns.
Role prompting — asking the model to take on a specific perspective — can improve domain-specific responses. “As an experienced Python developer” or “From a legal compliance perspective” focuses the model’s approach.
Chain-of-thought prompting explicitly asks the model to explain its reasoning step-by-step. This improves performance on logical reasoning and math problems.
| Technique | When to Use | Example |
|---|---|---|
| Few-shot learning | Specific output format needed | Provide 2-3 examples before task |
| Role prompting | Domain expertise required | “As a cybersecurity expert…” |
| Chain-of-thought | Complex reasoning tasks | “Explain your reasoning step by step” |
| System instructions | Behavioral constraints | Set tone, style, and boundaries |
Limitations and Challenges
Large language models aren’t magic. They have real limitations that affect practical applications.
Knowledge Cutoff and Staleness
Models learn during training, not during use. The training data has a cutoff date, after which the model knows nothing.
For questions about recent events, new technologies, or updated information, models provide outdated or fabricated answers. This is particularly problematic for time-sensitive domains.
Some systems address this through retrieval augmentation — fetching current information from external sources and including it in the prompt. But this adds complexity and cost.
Hallucination
When models don’t know something, they don’t say “I don’t know.” They generate plausible-sounding but incorrect information.
This happens because the model’s objective is generating coherent text, not ensuring factual accuracy. The training process optimizes for linguistic patterns, not truth.
Hallucination is particularly dangerous in high-stakes applications. Medical advice, legal guidance, and technical specifications require verification.
Reasoning Limitations
Despite impressive performance, LLMs don’t reason the way humans do. They pattern-match against training data rather than building logical models.
This works well for common patterns but fails on novel problems requiring genuine reasoning. Math, logic puzzles, and tasks requiring true understanding expose these limitations.
Newer models like GPT-5.5 Thinking show improvements in multi-step reasoning, but fundamental limitations remain.
Bias and Fairness
Models learn from internet text, which contains human biases. Training data includes stereotypes, prejudices, and problematic associations.
Fine-tuning and alignment processes reduce but don’t eliminate these biases. Models can generate outputs reflecting gender, racial, or cultural biases present in training data.
Applications affecting people directly require careful bias testing and mitigation strategies.
Security and Privacy Considerations
Using large language models introduces security and privacy risks that require attention.
Data Privacy
Text sent to API endpoints gets processed on external servers. Sensitive information — personal data, trade secrets, proprietary code — should not be included without appropriate safeguards.
According to official OpenAI documentation, API data is not used for training by default, but data still traverses their infrastructure. For highly sensitive applications, this represents an unacceptable risk.
Some organizations use self-hosted open-source models to maintain data control. This trades off capability for privacy.
Prompt Injection
When LLMs power user-facing applications, malicious users can try prompt injection attacks — crafting inputs that manipulate the model into ignoring its instructions.
For example, a chatbot instructed to “always be helpful” might be tricked into generating harmful content through cleverly worded prompts that override original instructions.
Defending against prompt injection requires input validation, output filtering, and architectural safeguards that limit what the model can access or do.
API Key Security
The OpenAI API documentation emphasizes that API keys are secrets requiring protection. Exposed keys enable unauthorized usage, potentially incurring significant costs.
Keys should never appear in client-side code, public repositories, or logs. They should be stored in environment variables or secret management systems with appropriate access controls.
The Future of Large Language Models
Language model capabilities continue advancing rapidly. Several trends are shaping development.
Multimodal Models
Current models like GPT-5.5 already handle text and images. Future systems will more deeply integrate audio, video, and other modalities.
This enables richer interactions — analyzing video content, generating images from descriptions, or processing speech naturally. Multimodal models can tackle problems requiring multiple types of input and output.
Efficiency Improvements
Research on efficient architectures, according to academic surveys, focuses on reducing computational costs while maintaining capability. Techniques like quantization, pruning, and efficient attention mechanisms enable smaller, faster models.
This matters for deployment. Smaller models run on less expensive hardware, reduce latency, and enable on-device processing for privacy-sensitive applications.
Longer Context Windows
Early models handled only a few hundred tokens of context. Modern models manage thousands or tens of thousands.
According to transformer architecture research, extending context length enables new applications — processing entire documents, maintaining longer conversations, and reasoning over more information simultaneously.
Technical challenges remain around computational efficiency and attention quality across very long sequences, but progress continues.
Better Reasoning
Current models excel at pattern matching but struggle with novel reasoning. Research explores architectures and training approaches that improve logical reasoning, mathematical problem-solving, and planning.
Hybrid approaches combining neural networks with symbolic reasoning systems show promise. These could address limitations while retaining the flexibility of learned models.
Frequently Asked Questions
What makes ChatGPT different from traditional chatbots?
Traditional chatbots use predefined rules and scripts — they match user inputs to preset responses. ChatGPT uses a large language model that generates responses dynamically based on patterns learned from vast text datasets. This enables it to handle unexpected questions, understand context, and produce human-like conversation rather than following rigid decision trees.
Can I use ChatGPT for my business without privacy concerns?
It depends on what data you’re sharing. According to official documentation, API data is not used for training by default, but information still passes through their systems. For sensitive data — customer records, proprietary information, confidential documents — you should use business plans with appropriate security controls, implement data filtering, or consider self-hosted alternatives for maximum privacy.
Why does ChatGPT sometimes provide incorrect information?
ChatGPT generates responses by predicting likely text sequences, not by retrieving verified facts from a database. When it doesn’t know something, it produces plausible-sounding text based on patterns from training data. This “hallucination” happens because the model optimizes for coherent language generation, not factual accuracy. Always verify important information, especially for specialized or time-sensitive topics.
How much does it cost to integrate OpenAI’s API into an application?
API pricing uses a pay-per-token model — you’re charged based on the amount of text processed and generated. Costs vary by model, with more capable models costing more per token. For current pricing, check the official OpenAI pricing page, as rates change and depend on usage volume. Most applications start with small-scale testing to estimate costs before full deployment.
Can large language models replace human writers or programmers?
Not entirely. LLMs excel at generating drafts, handling routine tasks, and providing starting points, but they lack true understanding, original creativity, and judgment. For writing, they produce generic content that requires human editing for voice, accuracy, and depth. For programming, they write functional code but can introduce bugs, security issues, or poor architectural decisions. Think of them as powerful assistants rather than replacements.
What’s the difference between GPT-5.5 Instant and GPT-5.5 Thinking?
According to official documentation, GPT-5.5 Instant is optimized for speed and handles virtually unlimited requests — it’s designed for high-volume routine tasks. GPT-5.5 Thinking focuses on complex reasoning and multi-step problems with a limit of 3000 requests per week for ChatGPT Business users. Choose Instant for quick responses and high throughput; choose Thinking when problems require deeper analysis.
How do I prevent my chatbot from being manipulated by users?
Implement multiple safeguards: validate and sanitize all user inputs, use system-level instructions that are harder to override, implement output filtering to catch inappropriate responses, and architect the system so the model can’t access sensitive functions directly. Regular testing with adversarial prompts helps identify vulnerabilities. For critical applications, add human review checkpoints for high-stakes decisions.
Conclusion
Large language models represent a fundamental shift in how machines interact with human language. ChatGPT and similar systems demonstrate capabilities that seemed impossible just a few years ago — from generating coherent long-form text to writing functional code to engaging in nuanced conversation.
But understanding their limitations is as important as recognizing their strengths. These are pattern-matching systems that generate statistically likely text, not thinking machines with genuine understanding. They hallucinate, show biases, struggle with novel reasoning, and can’t access information beyond their training cutoff.
The practical path forward involves treating LLMs as powerful tools that augment human capabilities rather than replace them. Use them for drafting, brainstorming, automating routine tasks, and processing large volumes of text. But keep humans in the loop for judgment, verification, creativity, and accountability.
Ready to integrate large language models into your workflow? Start with the OpenAI API documentation, experiment with different prompting techniques, and build safeguards appropriate to your use case. The technology is powerful — using it effectively requires understanding both what it can do and what it can’t.