Korte samenvatting: ChatGPT is gebouwd op grote taalmodellen (LLM's) — op transformeren gebaseerde neurale netwerken die getraind zijn op enorme tekstdatasets om mensachtige tekst te voorspellen en te genereren. Deze modellen gebruiken aandachtmechanismen om de context te begrijpen en genereren vervolgens token voor token reacties. Hoewel ze ongelooflijk krachtig zijn voor tekstgeneratie, codering en conversatie, hebben ze beperkingen zoals incidentele onnauwkeurigheden, een gebrek aan realtime kennis en gevoeligheid voor de formulering van prompts.
Dankzij ChatGPT heeft kunstmatige intelligentie de overstap gemaakt van technische kringen naar alledaagse gesprekken. Mensen gebruiken het voor het schrijven van e-mails, het debuggen van code, het brainstormen over ideeën en zelfs voor het opstellen van juridische documenten.
Maar hoe werkt het eigenlijk? Wat gebeurt er precies als je een vraag intypt en binnen enkele seconden een samenhangend, menselijk antwoord terugkrijgt?
Het antwoord ligt in grote taalmodellen — geavanceerde neurale netwerken die de manier waarop machines tekst begrijpen en genereren fundamenteel hebben veranderd. Deze gids legt de architectuur, het trainingsproces en de praktische toepassingen uit, zonder de hype.
Wat zijn grote taalmodellen?
Grote taalmodellen zijn AI-systemen die ontworpen zijn om menselijke taal te begrijpen en te genereren. In essentie zijn het voorspellingssystemen: gegeven een gegeven tekst, voorspellen ze welke woorden er vervolgens zouden moeten komen.
Maar die simpele beschrijving doet geen recht aan wat ze hebben bereikt. Moderne LLM's zoals GPT-5.5 kunnen code schrijven, vragen beantwoorden, talen vertalen, documenten samenvatten en gesprekken voeren die opmerkelijk natuurlijk aanvoelen.
Het begrip "groot" is belangrijk. Deze modellen bevatten miljarden parameters – instelbare gewichten die bepalen hoe het model informatie verwerkt. GPT-5.5 vertegenwoordigt de nieuwste generatie en biedt verbeterde redeneermogelijkheden in vergelijking met eerdere versies.
De Stichting: Transformer Architectuur
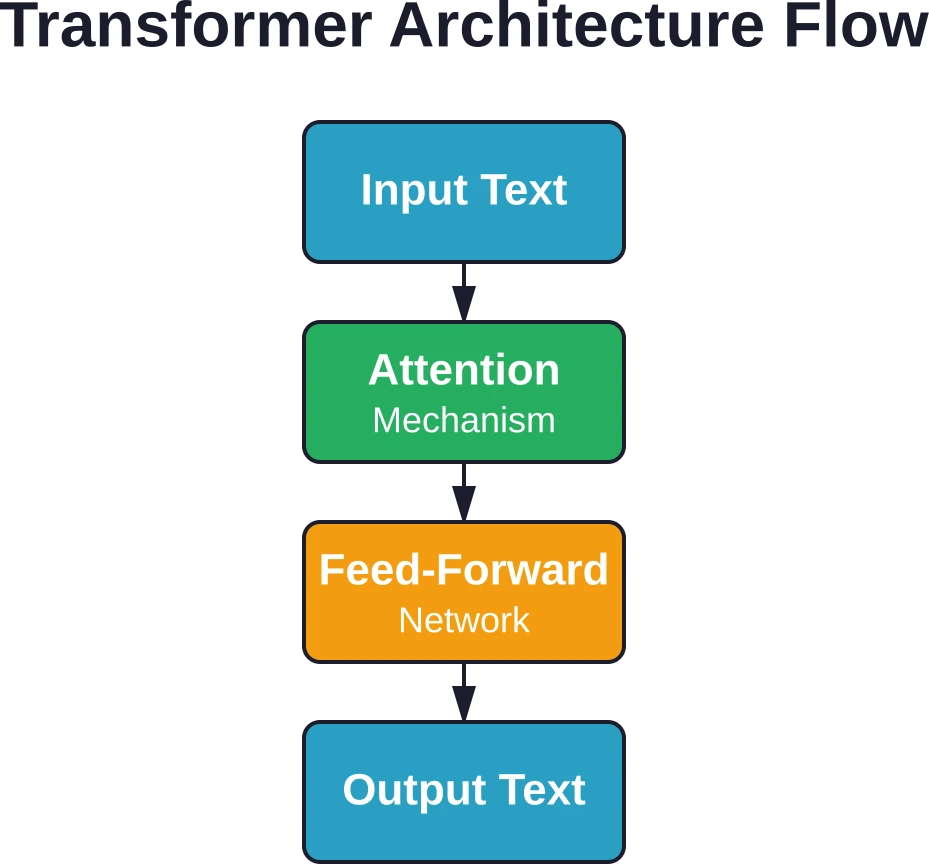
Grote taalmodellen zijn gebouwd op de transformerarchitectuur, die werd geïntroduceerd in het baanbrekende onderzoekspaper "Attention Is All You Need". Deze architectuur verving oudere sequentiemodellen door een efficiëntere aanpak.
Wat transformermodellen zo bijzonder maakt, is dat ze complete tekstreeksen tegelijk verwerken in plaats van woord voor woord. Deze parallelle verwerking stelt hen in staat om veel langere contexten te verwerken en veel efficiënter te trainen.
De transformerarchitectuur maakt gebruik van een zogenaamd aandachtmechanisme. Dit stelt het model in staat om het belang van verschillende woorden in een reeks te wegen bij het genereren van voorspellingen.
Denk eens aan de zin: "Het dier stak de straat niet over omdat het te moe was." Om te begrijpen waar "het" naar verwijst, moet het model aandacht besteden aan "dier" in plaats van aan "straat". Aandachtsmechanismen verwerken precies dit soort contextuele redenering.
Hoe tekst in getallen wordt omgezet
Taalmodellen werken niet met woorden, maar met getallen. Voordat de verwerking begint, wordt tekst omgezet in tokens, die vervolgens worden gekoppeld aan numerieke vectoren.
Tokenisatie verdeelt tekst in kleinere eenheden. Soms is een token een heel woord; soms zijn het maar een paar tekens. Het woord 'chatbot' kan één token worden, terwijl 'ongekend' kan worden opgesplitst in 'on', 'voor' en 'gekend'.“
Elk token wordt gekoppeld aan een hoogdimensionale vector — in wezen een lijst met getallen die de "betekenis" van dat token in een wiskundige ruimte weergeeft. Woorden met een vergelijkbare betekenis krijgen vergelijkbare vectoren.
Deze numerieke weergave stelt het model in staat wiskundige bewerkingen op taal uit te voeren, waardoor patronen en verbanden worden gevonden die handmatig onmogelijk te coderen zouden zijn.

Ontwikkel vooruitstrevende tools met superieure AI.
AI Superieur Ze ontwikkelen AI-gebaseerde applicaties en maatwerksoftwareproducten met behulp van machine learning en AI-modellen. Hun diensten omvatten AI-softwareontwikkeling, consultancy, R&D, training, NLP, voorspellende analyses, BI en big data-analyse.
Heeft u een AI-tool nodig die is afgestemd op uw workflow?
AI Superior kan u helpen met:
- het bouwen van aangepaste NLP- en LLM-tools
- Het testen van chatbotideeën via Proof of Concept (PoC) of Minimum Viable Product (MVP).
- het analyseren van tekst- en documentgegevens
- AI-tools integreren in bestaande systemen
👉 Neem contact op met AI Superior om uw project te bespreken.
Hoe ChatGPT tekst genereert
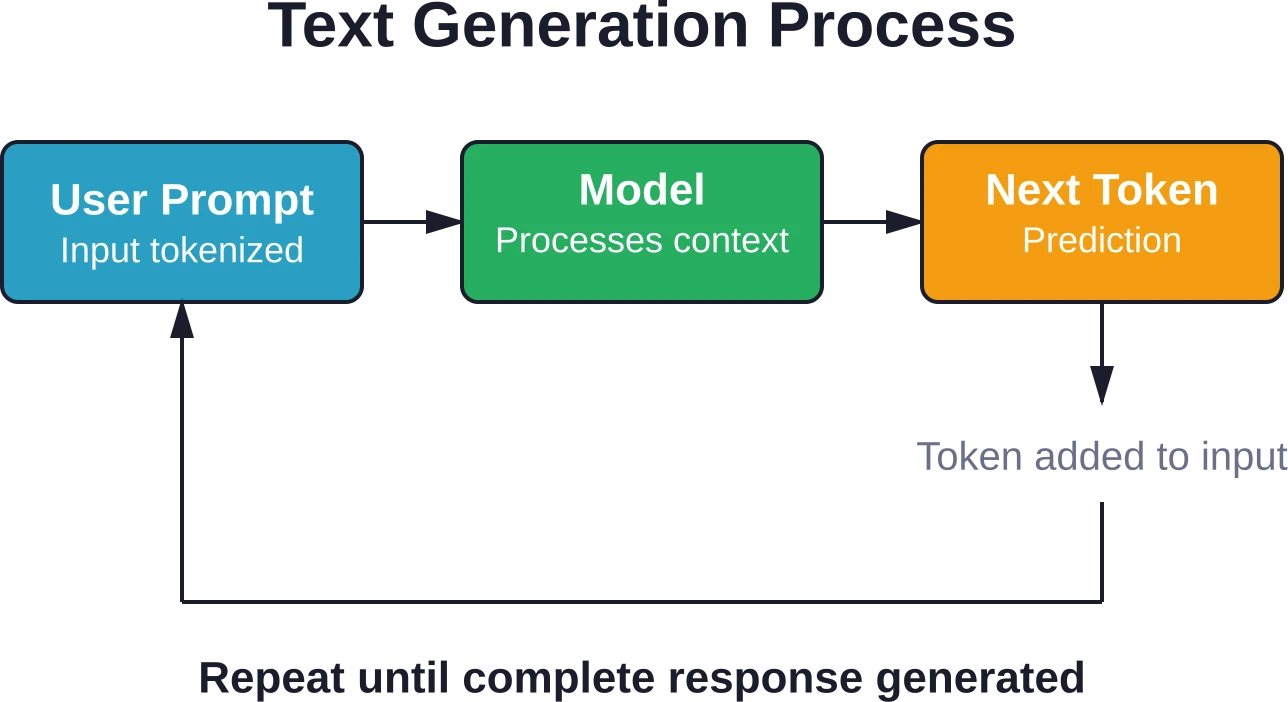
Wanneer je een prompt naar ChatGPT stuurt, start een geavanceerd voorspellingsproces. Het model genereert niet het volledige antwoord in één keer, maar produceert token voor token.
Het proces verloopt als volgt: het model ontvangt je prompt, verwerkt deze via meerdere transformatielagen en voorspelt het meest waarschijnlijke volgende token. Dat voorspelde token wordt toegevoegd aan de invoer en het proces herhaalt zich totdat het model een stopsignaal genereert.
Deze autoregressieve benadering betekent dat elk woord het volgende beïnvloedt. Wanneer het model vroeg in zijn reactie een fout maakt, kan die fout zich opstapelen doordat het model voortbouwt op zijn eigen onjuiste uitvoer.
De rol van temperatuur en bemonstering
Het model kiest niet altijd het meest waarschijnlijke volgende woord. Dat zou de antwoorden voorspelbaar en repetitief maken.
Taalmodellen maken daarentegen gebruik van gecontroleerde willekeurigheid. De temperatuurparameter bepaalt hoeveel willekeurigheid er wordt geïntroduceerd. Een lage temperatuur maakt het model deterministischer en gerichter. Een hoge temperatuur introduceert meer variatie, maar brengt het risico van incoherentie met zich mee.
De API van OpenAI stelt ontwikkelaars in staat deze parameters aan te passen. Voor taken die precisie vereisen, zoals codegeneratie of data-extractie, werken lagere temperaturen beter. Creatief schrijven profiteert van iets hogere waarden.
Het trainen van grote taalmodellen
Het ontwikkelen van een model zoals ChatGPT omvat meerdere trainingsfasen, die elk een eigen doel dienen.
Voorbereiding: Taalpatronen leren
Pre-training is de fase waarin het model basiskennis van taal leert. Tijdens deze fase verwerkt het model enorme datasets, zoals boeken, websites, artikelen, code repositories en meer.
Het trainingsdoel is eenvoudig: voorspel het volgende woord. Door dit miljarden keren te doen met diverse teksten, leert het model grammatica, feiten, redeneerpatronen en zelfs een beetje gezond verstand.
Deze fase vereist enorme rekenkracht. Trainingssessies kunnen weken of maanden duren op clusters van gespecialiseerde hardware.
Fijn afstemmen: gedrag specialiseren
Voorgeprogrammeerde modellen beschikken over kennis, maar zijn niet altijd even behulpzaam. Ze kunnen weliswaar accurate, maar ongepaste antwoorden geven, of instructies niet goed opvolgen.
Fijnafstemming biedt hiervoor een oplossing. Volgens onderzoek van Stanford HAI worden basismodellen door fijnafstemming aangepast aan specifieke taken of gedragingen, hoewel dit ook veiligheidsrisico's met zich meebrengt als het niet zorgvuldig wordt gecontroleerd.
Voor ChatGPT houdt finetuning in dat het model wordt getraind op zorgvuldig samengestelde datasets van kwalitatief hoogwaardige gesprekken, waarbij menselijke feedback het model helpt om behulpzame, onschadelijke en eerlijke antwoorden te geven.
Reinforcement learning op basis van menselijke feedback
De laatste trainingsfase maakt gebruik van reinforcement learning. Menselijke beoordelaars rangschikken verschillende modelreacties op dezelfde prompt. Deze rangschikkingen trainen een beloningsmodel dat menselijke voorkeuren voorspelt.
Het taalmodel wordt vervolgens geoptimaliseerd om reacties te genereren die hoger scoren op dit beloningsmodel. Deze aanpak helpt het gedrag van het model af te stemmen op menselijke waarden en verwachtingen.
Het is niet perfect — het model leert te optimaliseren voor wat de beoordelaars prefereren, wat niet altijd overeenkomt met wat objectief gezien het beste is. Maar het is momenteel de meest effectieve afstemmingstechniek die beschikbaar is.
De OpenAI API en GPT-5.5
Terwijl ChatGPT een gebruikersinterface biedt, geeft de OpenAI API ontwikkelaars programmatische toegang tot de onderliggende modellen. Volgens de officiële documentatie maakt de API gebruik van RESTful-eindpunten die werken via standaard HTTP-verzoeken.
Volgens de officiële API-documentatie van OpenAI vindt authenticatie plaats via API-sleutels met behulp van HTTP Bearer-authenticatie. Deze sleutels mogen nooit in clientcode worden weergegeven; ze zijn uitsluitend bedoeld voor servertoepassingen.
Huidige modelopties
De API biedt toegang tot meerdere modellen met verschillende mogelijkheden en prijspunten. Volgens de officiële OpenAI-documentatie is GPT-5.5 de nieuwste modelfamilie, ontworpen voor complexe productieworkflows.
GPT-5.5 blinkt uit in codeertaken, toolintensieve agentworkflows, het ophalen van lange contexten en klantgerichte applicaties waar de kwaliteit van de respons cruciaal is. Volgens de officiële richtlijnen moet het worden beschouwd als een nieuwe modelfamilie waarvoor optimalisatie nodig is, en niet als een directe vervanging voor oudere versies.
De officiële documentatie toont drie GPT-5.5-varianten die beschikbaar zijn voor ChatGPT Business-gebruikers: GPT-5.5-Instant met vrijwel onbeperkt gebruik voor routinetaken, GPT-5.5 Thinking met 3000 aanvragen per week voor ChatGPT Business-gebruikers voor complexe redeneringen, en GPT-5.5 Pro met 15 aanvragen per maand voor de meest veeleisende workloads.
| Model | Het beste voor | Belangrijkste sterkte |
|---|---|---|
| GPT-5.5 Instant | Taken met een hoog volume | Snelheid en beschikbaarheid |
| GPT-5.5 Denken | Complexe redenering | Probleemoplossing in meerdere stappen |
| GPT-5.5 Pro | Premium workloads | Maximale capaciteit |
API-aanroepen uitvoeren
Volgens de officiële API-documentatie verwerkt de Responses API directe modelaanvragen voor tekstgeneratie. Het basispatroon omvat het aanmaken van een client, het specificeren van een model en het opgeven van invoertekst.
De API retourneert gestructureerde antwoorden met de gegenereerde tekst in het veld `output_text`. Ontwikkelaars kunnen parameters zoals temperatuur, maximum aantal tokens en stopsequenties aanpassen om het generatiegedrag te beïnvloeden.
Voor productieapplicaties zijn een goede foutafhandeling en snelheidsbeperking essentieel. De API hanteert gebruiksbeperkingen op basis van uw accountniveau en kan tijdens piekperioden foutmeldingen geven over het overschrijden van de snelheidslimiet.
ChatGPT-abonnementsplannen
OpenAI biedt verschillende abonnementsniveaus met uiteenlopende mogelijkheden en beperkingen. Prijzen en functies worden regelmatig bijgewerkt, dus het is raadzaam om de officiële prijspagina te raadplegen voor de meest actuele informatie.
Consumentenplannen
Volgens het officiële OpenAI Help Center is ChatGPT Go een voordelig abonnement dat uitgebreidere toegang biedt tot populaire functies. Het omvat onbeperkte toegang tot GPT-5.5 Instant, uitgebreide mogelijkheden voor het genereren van afbeeldingen, het uploaden van bestanden en geavanceerde data-analyse.
ChatGPT Plus kost volgens officiële bronnen $20 per maand. Het biedt toegang tot geavanceerde functies zoals Codex en Deep Research voor geselecteerde projecten gedurende de week.
ChatGPT Pro is volgens de officiële documentatie verkrijgbaar in twee varianten: $100 per maand voor serieuze projecten met 5x hogere limieten dan Plus (en 10x Codex-gebruik gedurende een beperkte periode), en $200 per maand voor zware workflows met 20x hogere limieten dan Plus (en 25x Codex-gebruik gedurende een beperkte periode).
Bedrijf en Ondernemerschap
ChatGPT Business biedt veilige, collaboratieve werkomgevingen voor teams. Volgens de officiële helpdocumentatie omvat het SAML SSO, beheerdersfuncties en ondersteuning voor naleving van de AVG en CCPA.
Codex is, volgens de officiële prijslijsten, een ontwikkelingsgericht abonnement met prijsstelling op basis van gebruik en zonder vaste kosten per gebruiker. Het omvat AI-gestuurde softwareontwikkeling, geautomatiseerde codebeoordelingen en ingebouwde omgevingen voor workflows met meerdere agents.
Enterprise-abonnementen bieden maatwerkoplossingen voor grote organisaties. De specifieke prijzen en functies variëren afhankelijk van de behoeften van de organisatie.

Praktische toepassingen van grote taalmodellen
Grote taalmodellen blijken nuttig te zijn in verrassend uiteenlopende domeinen. Sommige toepassingen werken beter dan andere.
Contentcreatie en -schrijven
Schrijfbegeleiding is een van de meest voorkomende toepassingen. LLM-afgestudeerden kunnen artikelen schrijven, marketingteksten opstellen, e-mails opstellen en content voor sociale media creëren.
De kwaliteit varieert. Voor eenvoudige, informatieve inhoud presteren LLM's goed. Voor inhoud die diepgaande expertise, genuanceerde argumentatie of origineel onderzoek vereist, blijft menselijke tussenkomst essentieel.
Veel schrijvers gebruiken LLM's als brainstormpartners of voor het genereren van eerste versies, in plaats van als producenten van afgewerkte content. Deze samenwerkingsaanpak levert vaak betere resultaten op dan puur menselijk of puur AI-werk.
Codegeneratie en debuggen
Programmeren is waar moderne LLM's echt in uitblinken. Ze kunnen functies schrijven, fouten opsporen, vertalen tussen programmeertalen en complexe code uitleggen.
GPT-5.5 blinkt volgens de officiële documentatie vooral uit in codeertaken. Het kan overweg met projecten die uit meerdere bestanden bestaan, behoudt de context in grote codebases en genereert in veel scenario's code van productiekwaliteit.
Desondanks vereist door LLM gegenereerde code beoordeling. Modellen kunnen code produceren die weliswaar werkt, maar slechte praktijken volgt, subtiele fouten bevat of beveiligingslekken vertoont.
Gegevensanalyse en -extractie
Taalmodellen kunnen ongestructureerde tekst verwerken en gestructureerde informatie eruit halen. Ze ontleden documenten, categoriseren de inhoud, extraheren belangrijke feiten en formatteren gegevens voor analyse.
Voor zakelijke toepassingen maakt dit geautomatiseerde documentverwerking, analyse van klantfeedback en informatiesynthese uit grote tekstverzamelingen mogelijk.
De uitdaging zit hem in de betrouwbaarheid. Modellen missen soms belangrijke informatie of introduceren fouten. Voor kritische toepassingen zijn verificatiestappen noodzakelijk.
Conversatie-interfaces
Chatbots en virtuele assistenten, aangedreven door LLM's, kunnen klantenservice verlenen, vragen beantwoorden en gebruikers door complexe processen leiden.
Deze toepassingen profiteren van het vermogen van het model om context te begrijpen, verschillende formuleringen te verwerken en natuurlijke reacties te genereren. Het gesprek voelt minder robotachtig aan dan bij traditionele, op regels gebaseerde systemen.
Maar fouten gebeuren. Modellen geven soms ogenschijnlijk betrouwbare, maar onjuiste informatie – een gedrag dat hallucinatie wordt genoemd. Applicaties die belangrijke beslissingen nemen, hebben beveiligingen nodig.
Prompt Engineering: Betere resultaten behalen
De manier waarop je aanwijzingen formuleert, heeft een grote invloed op de kwaliteit van het eindresultaat. Het ontwikkelen van effectieve instructies is uitgegroeid tot een vaardigheid die zich richt op het opstellen van duidelijke aanwijzingen.
Kernprincipes
Duidelijkheid is belangrijk. Vage aanwijzingen leiden tot vage resultaten. Specifieke instructies met heldere vereisten genereren nuttigere resultaten.
Context is belangrijk. Het verstrekken van achtergrondinformatie, voorbeelden en beperkingen helpt het model tot betere resultaten te komen.
Formaatspecificaties werken goed. Als je JSON-output, CSV-gegevens of Markdown-opmaak nodig hebt, verbetert het expliciet vermelden van die vereiste de naleving.
Veelgebruikte technieken
Few-shot learning houdt in dat je eerst voorbeelden geeft voordat je de daadwerkelijke opdracht uitvoert. Laat het model 2-3 voorbeelden zien van de taak die je wilt uitvoeren, en presenteer daarna de echte invoer. Dit verbetert de prestaties bij specifieke patronen aanzienlijk.
Door het model te vragen een specifiek perspectief aan te nemen, kan de respons domeinspecifiek worden verbeterd. Bijvoorbeeld: "Als ervaren Python-ontwikkelaar" of "Vanuit een juridisch oogpunt" stuurt de aanpak van het model gerichter.
Bij het expliciet vragen om uitleg van de gedachtegang wordt het model gevraagd om zijn redenering stap voor stap uit te leggen. Dit verbetert de prestaties bij logisch redeneren en wiskundige problemen.
| Techniek | Wanneer te gebruiken | Voorbeeld |
|---|---|---|
| Lessen met weinig schoten | Specifiek uitvoerformaat vereist | Geef 2-3 voorbeelden vóór de opdracht. |
| Rolprompting | Vakinhoudelijke expertise vereist | “Als cybersecurity-expert…” |
| Gedachtenketen | Complexe redeneertaken | “Leg je redenering stap voor stap uit.” |
| Systeeminstructies | Gedragsmatige beperkingen | Bepaal de toon, stijl en grenzen. |
Beperkingen en uitdagingen
Grote taalmodellen zijn geen toverkunst. Ze hebben reële beperkingen die van invloed zijn op praktische toepassingen.
Kennisafsluiting en stagnatie
Modellen leren tijdens de training, niet tijdens het gebruik. De trainingsdata hebben een einddatum, waarna het model niets meer weet.
Voor vragen over recente gebeurtenissen, nieuwe technologieën of bijgewerkte informatie geven modellen verouderde of verzonnen antwoorden. Dit is met name problematisch in domeinen waar tijd een cruciale factor is.
Sommige systemen pakken dit aan door middel van retrieval augmentation — het ophalen van actuele informatie uit externe bronnen en deze in de prompt op te nemen. Maar dit brengt extra complexiteit en kosten met zich mee.
Hallucinatie
Als modellen iets niet weten, zeggen ze niet "Ik weet het niet". Ze genereren plausibel klinkende, maar onjuiste informatie.
Dit komt doordat het doel van het model het genereren van samenhangende tekst is, niet het garanderen van feitelijke juistheid. Het trainingsproces optimaliseert voor taalkundige patronen, niet voor de waarheid.
Hallucinaties zijn bijzonder gevaarlijk bij situaties met hoge inzet. Medisch advies, juridische richtlijnen en technische specificaties vereisen verificatie.
Beperkingen van redenering
Ondanks hun indrukwekkende prestaties redeneren LLM's niet zoals mensen. Ze vergelijken patronen met trainingsdata in plaats van logische modellen te bouwen.
Dit werkt goed voor veelvoorkomende patronen, maar schiet tekort bij nieuwe problemen die echt redeneringsvermogen vereisen. Wiskunde, logische puzzels en taken die een diepgaand begrip vereisen, leggen deze beperkingen bloot.
Nieuwere modellen zoals GPT-5.5 Thinking laten verbeteringen zien in redeneren in meerdere stappen, maar fundamentele beperkingen blijven bestaan.
Vooroordelen en rechtvaardigheid
Modellen leren van internetteksten, die menselijke vooroordelen bevatten. Trainingsdata omvatten stereotypen, vooroordelen en problematische associaties.
Verfijnings- en afstemmingsprocessen verminderen deze vooroordelen, maar elimineren ze niet volledig. Modellen kunnen resultaten genereren die gender-, raciale of culturele vooroordelen weerspiegelen die in de trainingsgegevens aanwezig zijn.
Applicaties die mensen direct raken, vereisen zorgvuldige tests op vooroordelen en strategieën om vooroordelen te beperken.
Beveiligings- en privacyoverwegingen
Het gebruik van grote taalmodellen brengt beveiligings- en privacyrisico's met zich mee die aandacht vereisen.
Gegevensprivacy
Tekst die naar API-eindpunten wordt verzonden, wordt verwerkt op externe servers. Gevoelige informatie – persoonsgegevens, bedrijfsgeheimen, bedrijfseigen code – mag niet zonder passende beveiligingsmaatregelen worden meegestuurd.
Volgens de officiële documentatie van OpenAI worden API-gegevens standaard niet gebruikt voor training, maar de gegevens passeren wel hun infrastructuur. Voor zeer gevoelige toepassingen vormt dit een onaanvaardbaar risico.
Sommige organisaties gebruiken zelfgehoste open-sourcemodellen om de controle over hun gegevens te behouden. Dit gaat ten koste van de functionaliteit ten gunste van de privacy.
Snelle injectie
Wanneer LLM's de basis vormen voor gebruikersgerichte applicaties, kunnen kwaadwillende gebruikers prompt-injectieaanvallen uitvoeren – het creëren van invoergegevens die het model manipuleren zodat het de instructies negeert.
Een chatbot die bijvoorbeeld de instructie heeft gekregen om "altijd behulpzaam te zijn", kan door slim geformuleerde aanwijzingen, die de oorspronkelijke instructies overrulen, worden misleid om schadelijke inhoud te genereren.
Bescherming tegen promptinjectie vereist inputvalidatie, outputfiltering en architectonische beveiligingsmaatregelen die beperken waartoe het model toegang heeft of wat het kan doen.
API-sleutelbeveiliging
De API-documentatie van OpenAI benadrukt dat API-sleutels geheimen zijn die bescherming vereisen. Blootgestelde sleutels maken ongeoorloofd gebruik mogelijk, wat aanzienlijke kosten met zich mee kan brengen.
Sleutels mogen nooit voorkomen in clientcode, openbare repositories of logbestanden. Ze moeten worden opgeslagen in omgevingsvariabelen of systemen voor geheimbeheer met passende toegangscontroles.
De toekomst van grote taalmodellen
De mogelijkheden van taalmodellen blijven zich in hoog tempo ontwikkelen. Verschillende trends bepalen deze ontwikkeling.
Multimodale modellen
Huidige modellen zoals GPT-5.5 kunnen al tekst en afbeeldingen verwerken. Toekomstige systemen zullen audio, video en andere modaliteiten verder integreren.
Dit maakt rijkere interacties mogelijk: het analyseren van videocontent, het genereren van afbeeldingen op basis van beschrijvingen of het op een natuurlijke manier verwerken van spraak. Multimodale modellen kunnen problemen aanpakken die meerdere soorten input en output vereisen.
Efficiëntieverbeteringen
Onderzoek naar efficiënte architecturen richt zich volgens academische onderzoeken op het verlagen van de rekenkosten met behoud van functionaliteit. Technieken zoals kwantisatie, snoeien en efficiënte aandachtmechanismen maken kleinere en snellere modellen mogelijk.
Dit is belangrijk voor de implementatie. Kleinere modellen draaien op goedkopere hardware, verminderen de latentie en maken verwerking op het apparaat zelf mogelijk voor privacygevoelige applicaties.
Langere contextvensters
Vroege modellen verwerkten slechts een paar honderd contexttokens. Moderne modellen verwerken er duizenden of tienduizenden.
Volgens onderzoek naar transformerarchitectuur maakt het verlengen van de contextlengte nieuwe toepassingen mogelijk, zoals het verwerken van complete documenten, het voeren van langere gesprekken en het gelijktijdig redeneren over meer informatie.
Er blijven technische uitdagingen bestaan op het gebied van rekenkundige efficiëntie en aandachtskwaliteit bij zeer lange sequenties, maar er wordt wel vooruitgang geboekt.
Beter redeneren
Huidige modellen blinken uit in patroonherkenning, maar hebben moeite met nieuwe vormen van redeneren. Onderzoek richt zich op architecturen en trainingsmethoden die logisch redeneren, wiskundig probleemoplossend vermogen en planning verbeteren.
Hybride benaderingen die neurale netwerken combineren met symbolische redeneersystemen zijn veelbelovend. Deze zouden beperkingen kunnen aanpakken en tegelijkertijd de flexibiliteit van aangeleerde modellen behouden.
Veelgestelde vragen
Wat maakt ChatGPT anders dan traditionele chatbots?
Traditionele chatbots gebruiken vooraf gedefinieerde regels en scripts — ze koppelen gebruikersinvoer aan vooraf ingestelde antwoorden. ChatGPT gebruikt een groot taalmodel dat dynamisch antwoorden genereert op basis van patronen die zijn geleerd uit enorme tekstdatasets. Hierdoor kan het onverwachte vragen beantwoorden, de context begrijpen en een mensachtige conversatie voeren in plaats van rigide beslissingsbomen te volgen.
Kan ik ChatGPT voor mijn bedrijf gebruiken zonder me zorgen te hoeven maken over de privacy?
Het hangt ervan af welke gegevens u deelt. Volgens de officiële documentatie worden API-gegevens standaard niet gebruikt voor trainingen, maar informatie passeert wel degelijk hun systemen. Voor gevoelige gegevens – klantgegevens, bedrijfseigen informatie, vertrouwelijke documenten – dient u gebruik te maken van bedrijfsplannen met passende beveiligingsmaatregelen, gegevensfiltering te implementeren of zelfgehoste alternatieven te overwegen voor maximale privacy.
Waarom geeft ChatGPT soms onjuiste informatie?
ChatGPT genereert antwoorden door waarschijnlijke tekstsequenties te voorspellen, niet door geverifieerde feiten uit een database op te halen. Wanneer het iets niet weet, produceert het plausibel klinkende tekst op basis van patronen uit trainingsgegevens. Deze "hallucinatie" treedt op omdat het model optimaliseert voor het genereren van coherente taal, niet voor feitelijke juistheid. Controleer altijd belangrijke informatie, vooral bij specialistische of tijdgevoelige onderwerpen.
Wat zijn de kosten om de API van OpenAI in een applicatie te integreren?
De API-prijsstelling is gebaseerd op een pay-per-token-model: u betaalt per verwerkte en gegenereerde tekst. De kosten variëren per model, waarbij krachtigere modellen meer per token kosten. Raadpleeg de officiële OpenAI-prijslijst voor de actuele prijzen, aangezien de tarieven kunnen veranderen en afhankelijk zijn van het gebruiksvolume. De meeste applicaties beginnen met kleinschalige tests om de kosten te schatten voordat ze volledig worden uitgerold.
Kunnen grote taalmodellen menselijke schrijvers of programmeurs vervangen?
Niet helemaal. LLM's blinken uit in het schrijven van concepten, het afhandelen van routinetaken en het aanreiken van uitgangspunten, maar ze missen echt begrip, originele creativiteit en oordeelsvermogen. Bij het schrijven produceren ze generieke content die menselijke bewerking vereist voor stijl, nauwkeurigheid en diepgang. Bij het programmeren schrijven ze functionele code, maar kunnen ze bugs, beveiligingsproblemen of slechte architectuurkeuzes introduceren. Zie ze als krachtige assistenten in plaats van vervangers.
Wat is het verschil tussen GPT-5.5 Instant en GPT-5.5 Thinking?
Volgens de officiële documentatie is GPT-5.5 Instant geoptimaliseerd voor snelheid en kan het vrijwel onbeperkt verzoeken verwerken — het is ontworpen voor routinematige taken met een hoog volume. GPT-5.5 Thinking richt zich op complexe redeneringen en problemen met meerdere stappen, met een limiet van 3000 verzoeken per week voor ChatGPT Business-gebruikers. Kies Instant voor snelle reacties en een hoge doorvoer; kies Thinking wanneer problemen een diepere analyse vereisen.
Hoe voorkom ik dat mijn chatbot door gebruikers gemanipuleerd wordt?
Implementeer meerdere beveiligingsmaatregelen: valideer en zuiver alle gebruikersinvoer, gebruik systeeminstructies die moeilijker te omzeilen zijn, implementeer uitvoerfiltering om ongepaste reacties te onderscheppen en ontwerp het systeem zodanig dat het model geen directe toegang heeft tot gevoelige functies. Regelmatig testen met vijandige prompts helpt bij het identificeren van kwetsbaarheden. Voeg voor kritieke applicaties menselijke controlepunten toe voor beslissingen met grote gevolgen.
Conclusie
Grote taalmodellen vertegenwoordigen een fundamentele verschuiving in de manier waarop machines met menselijke taal omgaan. ChatGPT en vergelijkbare systemen tonen mogelijkheden die een paar jaar geleden nog onmogelijk leken – van het genereren van samenhangende, lange teksten tot het schrijven van functionele code en het voeren van genuanceerde gesprekken.
Maar het begrijpen van hun beperkingen is net zo belangrijk als het erkennen van hun sterke punten. Dit zijn patroonherkenningssystemen die statistisch waarschijnlijke tekst genereren, geen denkende machines met echt begrip. Ze hallucineren, vertonen vooroordelen, hebben moeite met nieuwe redeneringen en kunnen geen informatie verwerken die verder gaat dan hun trainingslimiet.
De praktische weg vooruit is om LLM's te beschouwen als krachtige instrumenten die menselijke capaciteiten aanvullen in plaats van ze te vervangen. Gebruik ze voor het opstellen van concepten, brainstormen, automatiseren van routinetaken en het verwerken van grote hoeveelheden tekst. Maar houd mensen betrokken voor beoordeling, verificatie, creativiteit en verantwoording.
Klaar om grote taalmodellen in je workflow te integreren? Begin met de API-documentatie van OpenAI, experimenteer met verschillende promptingtechnieken en bouw beveiligingsmaatregelen die passen bij jouw specifieke gebruikssituatie. De technologie is krachtig – om er effectief gebruik van te maken, moet je zowel de mogelijkheden als de beperkingen ervan begrijpen.