Kurzzusammenfassung: ChatGPT basiert auf großen Sprachmodellen (LLMs) – Transformer-basierten neuronalen Netzen, die mit umfangreichen Textdatensätzen trainiert wurden, um menschenähnliche Texte vorherzusagen und zu generieren. Diese Modelle nutzen Aufmerksamkeitsmechanismen, um den Kontext zu verstehen und anschließend Token für Token Antworten zu generieren. Obwohl sie für die Textgenerierung, Codierung und Konversation äußerst leistungsstark sind, weisen sie Einschränkungen auf, wie beispielsweise gelegentliche Ungenauigkeiten, fehlendes Echtzeitwissen und eine Empfindlichkeit gegenüber der Formulierung von Aufforderungen.
Dank ChatGPT hat künstliche Intelligenz den Sprung aus der Tech-Szene in den Alltag geschafft. Sie wird genutzt, um E-Mails zu schreiben, Code zu debuggen, Ideen zu entwickeln und sogar juristische Dokumente zu verfassen.
Aber wie funktioniert das eigentlich? Was passiert, wenn man eine Eingabe macht und innerhalb von Sekunden eine zusammenhängende, menschenähnliche Antwort erhält?
Die Antwort liegt in großen Sprachmodellen – hochentwickelten neuronalen Netzen, die die Art und Weise, wie Maschinen Texte verstehen und generieren, grundlegend verändert haben. Dieser Leitfaden erklärt Architektur, Trainingsprozess und praktische Anwendungen ohne unnötigen Hype.
Was sind große Sprachmodelle?
Große Sprachmodelle sind KI-Systeme, die entwickelt wurden, um menschliche Sprache zu verstehen und zu generieren. Im Kern sind sie Vorhersagemaschinen – anhand eines Eingabetextes sagen sie voraus, welche Wörter als Nächstes folgen sollten.
Doch diese einfache Beschreibung wird ihren Leistungen nicht gerecht. Moderne Sprachcomputer wie GPT-5.5 können Code schreiben, Fragen beantworten, Sprachen übersetzen, Dokumente zusammenfassen und Gespräche führen, die sich bemerkenswert natürlich anfühlen.
Der “große” Aspekt ist entscheidend. Diese Modelle enthalten Milliarden von Parametern – anpassbare Gewichtungen, die bestimmen, wie das Modell Informationen verarbeitet. GPT-5.5 repräsentiert die neueste Generation und bietet im Vergleich zu früheren Versionen verbesserte Schlussfolgerungsfähigkeiten.
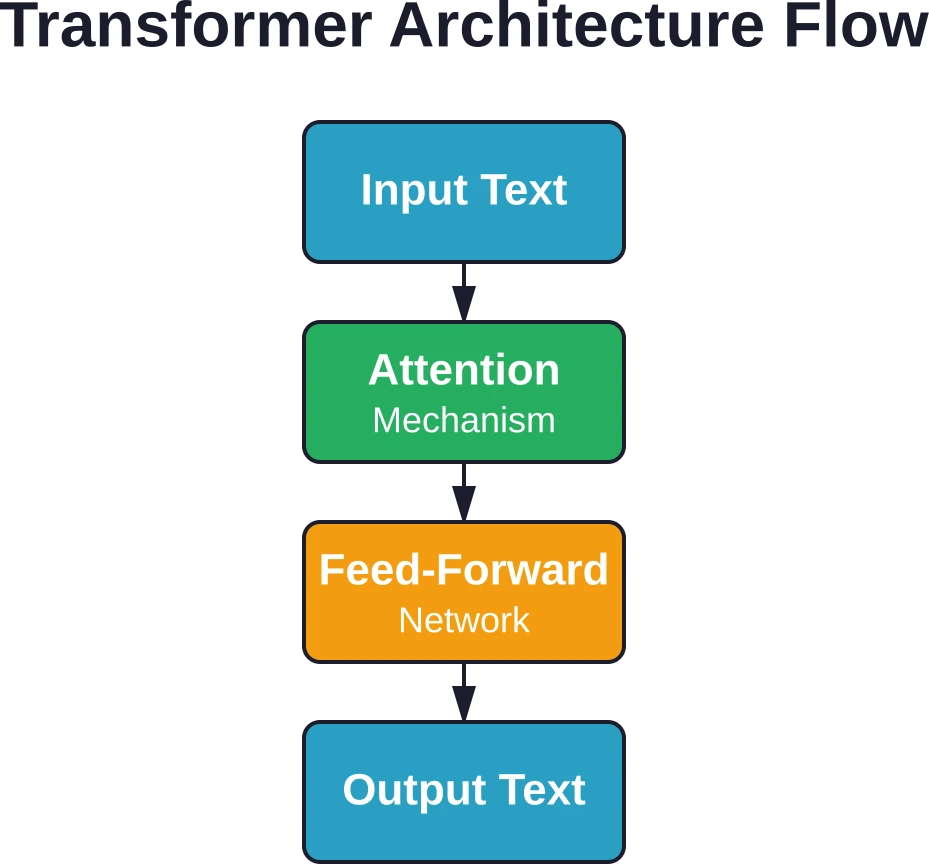
Die Stiftung: Transformatorarchitektur
Große Sprachmodelle basieren auf der Transformer-Architektur, die in der grundlegenden Forschungsarbeit “Attention Is All You Need” vorgestellt wurde. Diese Architektur ersetzte ältere Sequenzmodelle durch einen effizienteren Ansatz.
Das Besondere an Transformer-Prozessoren ist, dass sie ganze Textsequenzen gleichzeitig verarbeiten, anstatt Wort für Wort. Diese parallele Verarbeitung ermöglicht es ihnen, deutlich längere Texte zu bearbeiten und wesentlich effizienter zu trainieren.
Die Transformer-Architektur basiert auf einem sogenannten Aufmerksamkeitsmechanismus. Dieser ermöglicht es dem Modell, die Wichtigkeit verschiedener Wörter in einer Sequenz bei der Generierung von Vorhersagen zu gewichten.
Betrachten wir den Satz: “Das Tier überquerte die Straße nicht, weil es zu müde war.” Um zu verstehen, worauf sich “es” bezieht, muss das Modell dem “Tier” und nicht der “Straße” Aufmerksamkeit schenken. Aufmerksamkeitsmechanismen ermöglichen genau diese Art von kontextbezogenem Denken.
Wie aus Text Zahlen werden
Sprachmodelle arbeiten nicht mit Wörtern, sondern mit Zahlen. Bevor die eigentliche Verarbeitung beginnt, wird der Text in Tokens umgewandelt, die dann numerischen Vektoren zugeordnet werden.
Tokenisierung zerlegt Text in kleinere Einheiten. Manchmal ist ein Token ein ganzes Wort, manchmal nur wenige Zeichen. Das Wort “Chatbot” könnte zu einem Token werden, während “unprecedented” in “un”, “pre” und “cedented” aufgeteilt werden könnte.”
Jedes Token wird einem hochdimensionalen Vektor zugeordnet – im Wesentlichen einer Liste von Zahlen, die die “Bedeutung” dieses Tokens in einem mathematischen Raum repräsentiert. Wörter mit ähnlicher Bedeutung erhalten ähnliche Vektoren.
Diese numerische Darstellung ermöglicht es dem Modell, mathematische Operationen auf die Sprache anzuwenden und Muster und Beziehungen zu finden, die manuell nicht kodierbar wären.

Entwickeln Sie fortschrittliche Werkzeuge mit überlegener KI
AI Superior Das Unternehmen entwickelt KI-basierte Anwendungen und kundenspezifische Softwareprodukte mithilfe von maschinellem Lernen und KI-Modellen. Zu seinen Dienstleistungen gehören KI-Softwareentwicklung, Beratung, Forschung und Entwicklung, Schulungen, NLP, prädiktive Analysen, Business Intelligence und Big-Data-Analysen.
Benötigen Sie ein KI-Tool, das auf Ihren Workflow zugeschnitten ist?
AI Superior kann Ihnen helfen bei:
- Entwicklung kundenspezifischer NLP- und LLM-Tools
- Testen von Chatbot-Ideen durch PoC- oder MVP-Arbeit
- Analyse von Text- und Dokumentendaten
- Integration von KI-Tools in bestehende Systeme
👉 Kontaktieren Sie AI Superior um Ihr Projekt zu besprechen.
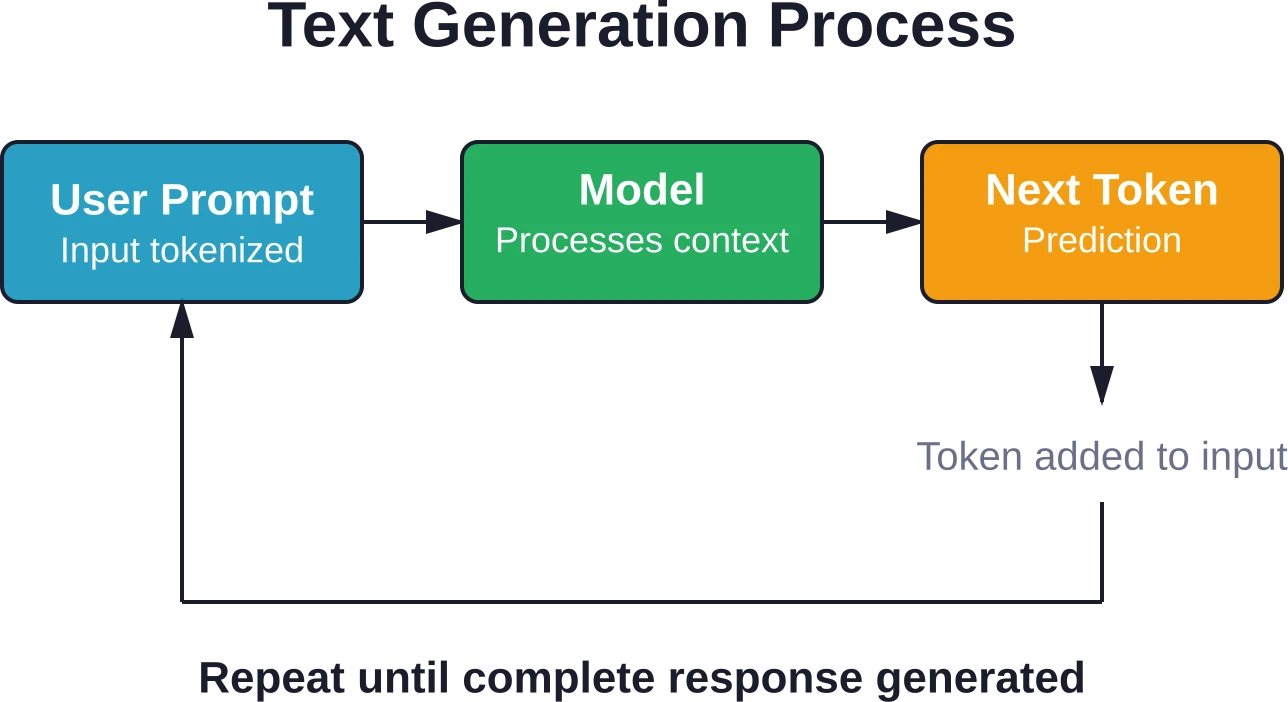
Wie ChatGPT Text generiert
Wenn Sie eine Anfrage an ChatGPT senden, startet ein komplexer Vorhersageprozess. Das Modell generiert nicht die gesamte Antwort auf einmal, sondern erzeugt jeweils ein Token.
Die Abfolge ist folgende: Das Modell nimmt Ihre Eingabe entgegen, verarbeitet sie über mehrere Transformationsebenen und sagt das wahrscheinlichste nächste Token voraus. Dieses vorhergesagte Token wird der Eingabe hinzugefügt, und der Prozess wiederholt sich, bis das Modell ein Abbruchsignal generiert.
Dieser autoregressive Ansatz bedeutet, dass jedes Wort das nächste beeinflusst. Wenn das Modell zu Beginn seiner Reaktion einen Fehler macht, kann sich dieser Fehler verstärken, da das Modell auf seinen eigenen fehlerhaften Ausgaben aufbaut.
Die Rolle von Temperatur und Probenahme
Das Modell wählt nicht immer das wahrscheinlichste nächste Wort aus. Das würde die Antworten vorhersehbar und wiederholend machen.
Sprachmodelle nutzen stattdessen kontrollierte Zufälligkeit. Der Temperaturparameter steuert, wie viel Zufälligkeit eingeführt wird. Eine niedrige Temperatur macht das Modell deterministischer und fokussierter. Eine hohe Temperatur führt zu mehr Vielfalt, birgt aber das Risiko von Inkohärenz.
Die OpenAI-API ermöglicht es Entwicklern, diese Parameter anzupassen. Für Aufgaben, die Präzision erfordern – wie Codegenerierung oder Datenextraktion – sind niedrigere Temperaturen besser geeignet. Kreatives Schreiben profitiert von etwas höheren Werten.
Training großer Sprachmodelle
Die Erstellung eines Modells wie ChatGPT erfordert mehrere Trainingsphasen, von denen jede einem bestimmten Zweck dient.
Vor dem Training: Erlernen von Sprachmustern
Im Vortraining erlernt das Modell grundlegende Sprachkenntnisse. Während dieser Phase verarbeitet es riesige Datensätze – Bücher, Websites, Artikel, Code-Repositories und vieles mehr.
Das Trainingsziel ist einfach: das nächste Wort vorhersagen. Indem das Modell dies Milliarden Male mit unterschiedlichsten Texten durchführt, lernt es Grammatik, Fakten, Denkmuster und sogar gesunden Menschenverstand.
Diese Phase erfordert enorme Rechenressourcen. Trainingsläufe können auf Clustern spezialisierter Hardware Wochen oder Monate dauern.
Feinabstimmung: Spezialisierung des Verhaltens
Vortrainierte Modelle verfügen zwar über Wissen, sind aber nicht immer hilfreich. Sie können zwar korrekte, aber unpassende Antworten liefern oder Anweisungen nicht richtig befolgen.
Feinabstimmung setzt hier an. Laut Forschungsergebnissen von Stanford HAI werden durch Feinabstimmung Basismodelle für spezifische Aufgaben oder Verhaltensweisen angepasst, allerdings birgt sie auch Sicherheitsrisiken, wenn sie nicht sorgfältig kontrolliert wird.
Bei ChatGPT besteht das Feintuning darin, anhand kuratierter Datensätze mit qualitativ hochwertigen Konversationen zu trainieren, wobei menschliches Feedback das Modell zu hilfreichen, harmlosen und ehrlichen Antworten führt.
Verstärkendes Lernen durch menschliches Feedback
Die letzte Trainingsphase nutzt bestärkendes Lernen. Menschliche Testpersonen bewerten verschiedene Modellantworten auf dieselbe Aufforderung. Diese Bewertungen trainieren ein Belohnungsmodell, das menschliche Präferenzen vorhersagt.
Das Sprachmodell wird anschließend optimiert, um Antworten zu generieren, die in diesem Belohnungsmodell eine höhere Punktzahl erreichen. Dieser Ansatz trägt dazu bei, das Verhalten des Modells an menschliche Werte und Erwartungen anzupassen.
Es ist nicht perfekt – das Modell lernt, die Präferenzen der Evaluatoren zu optimieren, was nicht immer dem entspricht, was objektiv am besten ist. Aber es ist derzeit die effektivste verfügbare Methode zur Zielanpassung.
Die OpenAI-API und GPT-5.5
Während ChatGPT eine Benutzerschnittstelle bereitstellt, ermöglicht die OpenAI-API Entwicklern den programmatischen Zugriff auf die zugrundeliegenden Modelle. Laut offizieller Dokumentation verwendet die API RESTful-Endpunkte, die über Standard-HTTP-Anfragen funktionieren.
Laut der offiziellen OpenAI-API-Dokumentation erfolgt die Authentifizierung über API-Schlüssel mittels HTTP-Bearer-Authentifizierung. Diese Schlüssel dürfen niemals im clientseitigen Code offengelegt werden – sie sind ausschließlich für serverseitige Anwendungen bestimmt.
Aktuelle Modelloptionen
Die API bietet Zugriff auf verschiedene Modelle mit unterschiedlichen Leistungsmerkmalen und Preisen. Laut offizieller OpenAI-Dokumentation ist GPT-5.5 die neueste Modellfamilie, die für komplexe Produktionsabläufe entwickelt wurde.
GPT-5.5 eignet sich hervorragend für Codierungsaufgaben, komplexe Agenten-Workflows, die Abfrage langer Kontexte und kundenorientierte Anwendungen, bei denen die Antwortqualität entscheidend ist. Laut offizieller Empfehlung sollte es als neue Modellfamilie betrachtet werden, die entsprechend angepasst werden muss, und nicht als direkter Ersatz für ältere Versionen.
Die offizielle Dokumentation zeigt drei GPT-5.5-Varianten, die für ChatGPT Business-Benutzer verfügbar sind: GPT-5.5-Instant mit praktisch unbegrenzter Nutzung für Routineaufgaben, GPT-5.5 Thinking mit 3000 Anfragen pro Woche für ChatGPT Business-Benutzer für komplexe Schlussfolgerungen und GPT-5.5 Pro mit 15 Anfragen pro Monat für die anspruchsvollsten Arbeitslasten.
| Modell | Am besten geeignet für | Hauptstärke |
|---|---|---|
| GPT-5.5 Instant | Aufgaben mit hohem Volumen | Geschwindigkeit und Verfügbarkeit |
| GPT-5.5 Denken | Komplexes Denken | Mehrstufige Problemlösung |
| GPT-5.5 Pro | Premium-Workloads | Maximale Leistungsfähigkeit |
API-Aufrufe durchführen
Laut offizieller API-Dokumentation verarbeitet die Responses API direkte Modellanfragen zur Textgenerierung. Das grundlegende Vorgehen besteht darin, einen Client zu erstellen, ein Modell anzugeben und den Eingabetext bereitzustellen.
Die API liefert strukturierte Antworten mit dem generierten Text im Feld `output_text`. Entwickler können Parameter wie Temperatur, maximale Tokenanzahl und Stoppsequenzen anpassen, um das Generierungsverhalten zu steuern.
Für Produktionsanwendungen sind eine korrekte Fehlerbehandlung und Ratenbegrenzung unerlässlich. Die API setzt Nutzungslimits basierend auf Ihrem Kontotarif durch und kann bei hohem Datenverkehr Ratenbegrenzungsfehler zurückgeben.
ChatGPT-Abonnementpläne
OpenAI bietet verschiedene Abonnementstufen mit unterschiedlichen Funktionen und Beschränkungen an. Preise und Funktionen werden regelmäßig aktualisiert. Daher empfiehlt es sich, die offizielle Preisseite für aktuelle Informationen zu besuchen.
Verbraucherpläne
Laut dem offiziellen OpenAI-Hilfecenter ist ChatGPT Go ein kostengünstiges Abonnement, das erweiterten Zugriff auf beliebte Funktionen bietet. Es umfasst unbegrenzten Zugriff auf GPT-5.5 Instant, erweiterte Bildgenerierung, Datei-Uploads und fortgeschrittene Datenanalyse.
ChatGPT Plus kostet laut offiziellen Angaben $20 pro Monat. Es bietet Zugriff auf erweiterte Funktionen wie Codex und Deep Research für ausgewählte Projekte während der Woche.
ChatGPT Pro wird laut offizieller Dokumentation in zwei Stufen angeboten: $100 pro Monat für reale Projekte mit 5-fach höheren Limits als Plus (und 10-facher Codex-Nutzung für eine begrenzte Zeit) und $200 pro Monat für intensive Workflows mit 20-fach höheren Limits als Plus (und 25-facher Codex-Nutzung für eine begrenzte Zeit).
Wirtschaft und Unternehmen
ChatGPT Business bietet sichere, kollaborative Arbeitsbereiche für Teams. Laut offizieller Hilfedokumentation umfasst es SAML-SSO, administrative Kontrollfunktionen und Unterstützung bei der Einhaltung von DSGVO und CCPA.
Codex ist laut offizieller Preisseite ein entwicklungsorientiertes Paket mit nutzungsbasierter Abrechnung und ohne feste Lizenzgebühren. Es umfasst KI-gestützte Softwareentwicklung, automatisierte Code-Reviews und integrierte Umgebungen für Multi-Agenten-Workflows.
Enterprise-Tarife bieten maßgeschneiderte Lösungen für große Organisationen. Preise und Funktionen variieren je nach den Bedürfnissen der jeweiligen Organisation.

Praktische Anwendungen großer Sprachmodelle
Große Sprachmodelle haben sich in überraschend vielfältigen Bereichen als nützlich erwiesen. Manche Anwendungen funktionieren besser als andere.
Content-Erstellung und Schreiben
Unterstützung beim Schreiben ist einer der häufigsten Anwendungsfälle. LLMs können Artikel entwerfen, Marketingtexte erstellen, E-Mails schreiben und Social-Media-Inhalte gestalten.
Die Qualität variiert. Für unkomplizierte, informative Inhalte eignen sich LLM-Absolventen gut. Für Inhalte, die tiefgreifendes Fachwissen, differenzierte Argumentation oder originäre Forschung erfordern, bleibt die menschliche Beteiligung unerlässlich.
Viele Autoren nutzen LLMs eher als Brainstorming-Partner oder zur Erstellung von ersten Entwürfen denn als Produzenten fertiger Texte. Dieser kollaborative Ansatz führt oft zu besseren Ergebnissen als rein menschliche oder rein KI-gestützte Arbeit.
Codegenerierung und Debugging
Die Programmierung ist die besondere Stärke moderner LLM-Absolventen. Sie können Funktionen schreiben, Fehler beheben, zwischen Programmiersprachen übersetzen und komplexen Code erklären.
GPT-5.5 zeigt laut offizieller Dokumentation besondere Stärken bei Codierungsaufgaben. Es verarbeitet Projekte mit mehreren Dateien, erhält den Kontext über große Codebasen hinweg und generiert in vielen Szenarien produktionsreifen Code.
Allerdings muss der von LLM generierte Code überprüft werden. Modelle können zwar funktionierenden Code erzeugen, der jedoch schlechten Programmierpraktiken folgt, subtile Fehler enthält oder Sicherheitslücken aufweist.
Datenanalyse und -extraktion
Sprachmodelle können unstrukturierte Texte verarbeiten und strukturierte Informationen extrahieren. Sie analysieren Dokumente, kategorisieren Inhalte, extrahieren wichtige Fakten und formatieren Daten für die Analyse.
Für Geschäftsanwendungen ermöglicht dies die automatisierte Dokumentenverarbeitung, die Analyse von Kundenfeedback und die Informationssynthese aus großen Textsammlungen.
Die Herausforderung liegt in der Zuverlässigkeit. Modelle erfassen mitunter wichtige Informationen nicht oder enthalten Fehler. Für kritische Anwendungen sind Verifizierungsschritte daher unerlässlich.
Konversationelle Schnittstellen
Chatbots und virtuelle Assistenten, die von LLMs unterstützt werden, können den Kundenservice übernehmen, Fragen beantworten und Benutzer durch komplexe Prozesse führen.
Diese Anwendungen profitieren von der Fähigkeit des Modells, den Kontext zu verstehen, mit unterschiedlichen Formulierungen umzugehen und natürliche Antworten zu generieren. Die Konversation wirkt dadurch weniger roboterhaft als bei herkömmlichen regelbasierten Systemen.
Doch Fehler passieren. Modelle liefern mitunter täuschend echt klingende, aber falsche Informationen – ein Phänomen, das als Halluzination bezeichnet wird. Anwendungen, die wichtige Entscheidungen treffen, benötigen daher Schutzmechanismen.
Prompt Engineering: Bessere Ergebnisse erzielen
Die Formulierung von Anweisungen hat einen erheblichen Einfluss auf die Qualität der Ergebnisse. Die Entwicklung effektiver Anweisungen hat sich als eigene Kompetenz etabliert.
Grundprinzipien
Klarheit ist wichtig. Unklare Vorgaben führen zu unklaren Ergebnissen. Präzise Anweisungen mit klaren Anforderungen erzeugen nützlichere Ergebnisse.
Der Kontext ist entscheidend. Die Bereitstellung von Hintergrundinformationen, Beispielen und Einschränkungen führt das Modell zu besseren Ergebnissen.
Formatvorgaben sind eine gute Lösung. Wenn Sie JSON-Ausgabe, CSV-Daten oder Markdown-Formatierung benötigen, verbessert die explizite Angabe dieser Anforderung die Einhaltung der Vorgaben.
Gängige Techniken
Beim Few-Shot-Learning werden dem Modell Beispiele vor der eigentlichen Anfrage präsentiert. Zeigen Sie dem Modell zunächst zwei bis drei Beispiele der gewünschten Aufgabe und anschließend die eigentliche Eingabe. Dies verbessert die Leistung bei bestimmten Mustern deutlich.
Die Rollenvorgabe – also die Aufforderung an das Modell, eine bestimmte Perspektive einzunehmen – kann domänenspezifische Antworten verbessern. Beispiele hierfür sind: “Als erfahrener Python-Entwickler” oder “Aus der Perspektive der Einhaltung gesetzlicher Bestimmungen”. Dadurch wird der Ansatz des Modells fokussiert.
Die Aufforderung zur Gedankenkette fordert das Modell explizit auf, seine Argumentation Schritt für Schritt zu erklären. Dies verbessert die Leistung bei logischen Schlussfolgerungen und mathematischen Problemen.
| Technik | Wann verwenden? | Beispiel |
|---|---|---|
| Lernen mit wenigen Beispielen | Spezifisches Ausgabeformat erforderlich | Geben Sie vor der Aufgabe 2-3 Beispiele an. |
| Rollenaufforderung | Fachkenntnisse erforderlich | “Als Cybersicherheitsexperte…” |
| Gedankenkette | Aufgaben zum komplexen logischen Denken | “Erklären Sie Ihre Argumentation Schritt für Schritt.” |
| Systemanweisungen | Verhaltensbeschränkungen | Ton, Stil und Grenzen festlegen |
Einschränkungen und Herausforderungen
Große Sprachmodelle sind keine Zauberei. Sie haben reale Einschränkungen, die sich auf praktische Anwendungen auswirken.
Wissensabbruch und Veralterung
Modelle lernen während des Trainings, nicht während der Anwendung. Die Trainingsdaten haben einen Stichtag, nach dem das Modell nichts mehr weiß.
Bei Fragen zu aktuellen Ereignissen, neuen Technologien oder aktualisierten Informationen liefern Modelle veraltete oder erfundene Antworten. Dies ist besonders problematisch in zeitkritischen Bereichen.
Einige Systeme begegnen diesem Problem durch die Erweiterung der Abfrageinformationen – sie rufen aktuelle Informationen aus externen Quellen ab und integrieren sie in die Eingabeaufforderung. Dies erhöht jedoch die Komplexität und die Kosten.
Halluzination
Wenn Modelle etwas nicht wissen, sagen sie nicht “Ich weiß es nicht”. Sie generieren plausibel klingende, aber falsche Informationen.
Dies geschieht, weil das Ziel des Modells die Generierung kohärenter Texte ist, nicht die Sicherstellung faktischer Richtigkeit. Der Trainingsprozess optimiert sprachliche Muster, nicht die Wahrheit.
Halluzinationen sind besonders gefährlich bei Anwendungen mit hohem Einsatz. Medizinischer Rat, rechtliche Hinweise und technische Spezifikationen müssen überprüft werden.
Einschränkungen der Argumentation
Trotz ihrer beeindruckenden Leistungsfähigkeit argumentieren LLMs nicht wie Menschen. Sie vergleichen Trainingsdaten mit Mustern, anstatt logische Modelle zu erstellen.
Dies funktioniert gut bei gängigen Mustern, versagt aber bei neuartigen Problemen, die echtes logisches Denken erfordern. Mathematik, Logikrätsel und Aufgaben, die ein tiefes Verständnis voraussetzen, legen diese Grenzen offen.
Neuere Modelle wie GPT-5.5 Thinking zeigen zwar Verbesserungen beim mehrstufigen Denken, aber es bleiben grundlegende Einschränkungen bestehen.
Voreingenommenheit und Fairness
Die Modelle lernen aus Internettexten, die menschliche Vorurteile enthalten. Trainingsdaten beinhalten Stereotypen, Vorurteile und problematische Assoziationen.
Feinabstimmungs- und Angleichungsprozesse reduzieren diese Verzerrungen, beseitigen sie aber nicht vollständig. Modelle können Ausgaben generieren, die geschlechtsspezifische, rassische oder kulturelle Verzerrungen in den Trainingsdaten widerspiegeln.
Anwendungen, die Menschen direkt betreffen, erfordern sorgfältige Tests auf mögliche Verzerrungen und geeignete Strategien zur Risikominderung.
Sicherheits- und Datenschutzaspekte
Die Verwendung großer Sprachmodelle birgt Sicherheits- und Datenschutzrisiken, die Beachtung erfordern.
Datenschutz
An API-Endpunkte gesendete Texte werden auf externen Servern verarbeitet. Sensible Informationen – personenbezogene Daten, Geschäftsgeheimnisse, proprietärer Code – sollten nicht ohne geeignete Sicherheitsvorkehrungen übermittelt werden.
Laut offizieller OpenAI-Dokumentation werden API-Daten standardmäßig nicht für das Training verwendet, durchlaufen aber dennoch deren Infrastruktur. Für hochsensible Anwendungen stellt dies ein inakzeptables Risiko dar.
Einige Organisationen nutzen selbstgehostete Open-Source-Modelle, um die Datenkontrolle zu behalten. Dies geht mit einer Abwägung zwischen Funktionalität und Datenschutz einher.
Sofortige Injektion
Wenn LLMs benutzerorientierte Anwendungen steuern, können böswillige Benutzer versuchen, Prompt-Injection-Angriffe durchzuführen – indem sie Eingaben erstellen, die das Modell so manipulieren, dass es seine Anweisungen ignoriert.
Ein Chatbot, der beispielsweise angewiesen wurde, “immer hilfsbereit zu sein”, könnte durch geschickt formulierte Aufforderungen, die die ursprünglichen Anweisungen außer Kraft setzen, dazu verleitet werden, schädliche Inhalte zu generieren.
Die Abwehr gegen sofortige Manipulation erfordert Eingabevalidierung, Ausgabefilterung und architektonische Schutzmechanismen, die einschränken, worauf das Modell zugreifen oder was es tun kann.
API-Schlüsselsicherheit
Die OpenAI-API-Dokumentation betont, dass API-Schlüssel Geheimnisse sind, die geschützt werden müssen. Offengelegte Schlüssel ermöglichen eine unbefugte Nutzung und können erhebliche Kosten verursachen.
Schlüssel dürfen niemals im clientseitigen Code, in öffentlichen Repositories oder in Protokolldateien erscheinen. Sie sollten in Umgebungsvariablen oder Geheimnisverwaltungssystemen mit entsprechenden Zugriffskontrollen gespeichert werden.
Die Zukunft großer Sprachmodelle
Die Fähigkeiten von Sprachmodellen entwickeln sich weiterhin rasant. Mehrere Trends prägen diese Entwicklung.
Multimodale Modelle
Aktuelle Modelle wie GPT-5.5 verarbeiten bereits Text und Bilder. Zukünftige Systeme werden Audio, Video und weitere Modalitäten stärker integrieren.
Dies ermöglicht komplexere Interaktionen – die Analyse von Videoinhalten, die Generierung von Bildern aus Beschreibungen oder die natürliche Sprachverarbeitung. Multimodale Modelle können Probleme lösen, die mehrere Arten von Eingabe und Ausgabe erfordern.
Effizienzverbesserungen
Laut akademischen Umfragen konzentriert sich die Forschung an effizienten Architekturen auf die Reduzierung des Rechenaufwands bei gleichzeitiger Aufrechterhaltung der Leistungsfähigkeit. Techniken wie Quantisierung, Pruning und effiziente Aufmerksamkeitsmechanismen ermöglichen kleinere und schnellere Modelle.
Dies ist für den Einsatz von Bedeutung. Kleinere Modelle laufen auf kostengünstigerer Hardware, reduzieren die Latenz und ermöglichen die Verarbeitung auf dem Gerät für datenschutzsensible Anwendungen.
Längere Kontextfenster
Frühe Modelle verarbeiteten nur wenige hundert Kontext-Tokens. Moderne Modelle verarbeiten Tausende oder Zehntausende.
Laut der Forschung zur Transformer-Architektur ermöglicht die Erweiterung der Kontextlänge neue Anwendungen – die Verarbeitung ganzer Dokumente, die Aufrechterhaltung längerer Konversationen und die gleichzeitige Verarbeitung von mehr Informationen.
Es bestehen weiterhin technische Herausforderungen hinsichtlich der Recheneffizienz und der Aufmerksamkeitsqualität bei sehr langen Sequenzen, aber es werden Fortschritte erzielt.
Bessere Argumentation
Aktuelle Modelle sind hervorragend im Mustererkennen, haben aber Schwierigkeiten mit neuartigen Schlussfolgerungen. Die Forschung untersucht Architekturen und Trainingsansätze, die logisches Denken, mathematische Problemlösung und Planung verbessern.
Hybride Ansätze, die neuronale Netze mit symbolischen Schlussfolgerungssystemen kombinieren, sind vielversprechend. Sie könnten Einschränkungen beheben und gleichzeitig die Flexibilität gelernter Modelle beibehalten.
Häufig gestellte Fragen
Was unterscheidet ChatGPT von herkömmlichen Chatbots?
Herkömmliche Chatbots verwenden vordefinierte Regeln und Skripte – sie ordnen Nutzereingaben vordefinierten Antworten zu. ChatGPT hingegen nutzt ein umfangreiches Sprachmodell, das Antworten dynamisch auf Basis von Mustern generiert, die aus großen Textdatensätzen gelernt wurden. Dadurch kann es unerwartete Fragen beantworten, den Kontext verstehen und menschenähnliche Konversationen führen, anstatt starren Entscheidungsbäumen zu folgen.
Kann ich ChatGPT für mein Unternehmen nutzen, ohne Bedenken hinsichtlich des Datenschutzes zu haben?
Das hängt davon ab, welche Daten Sie teilen. Laut offizieller Dokumentation werden API-Daten standardmäßig nicht für Trainingszwecke verwendet, Informationen werden aber dennoch über die Systeme des Anbieters übertragen. Für sensible Daten – Kundendaten, Betriebsgeheimnisse, vertrauliche Dokumente – sollten Sie Business-Tarife mit entsprechenden Sicherheitsvorkehrungen nutzen, Datenfilter implementieren oder selbstgehostete Alternativen für maximale Privatsphäre in Betracht ziehen.
Warum liefert ChatGPT manchmal falsche Informationen?
ChatGPT generiert Antworten, indem es wahrscheinliche Textsequenzen vorhersagt, nicht indem es verifizierte Fakten aus einer Datenbank abruft. Wenn es etwas nicht weiß, erzeugt es plausibel klingenden Text basierend auf Mustern aus den Trainingsdaten. Diese “Halluzination” entsteht, weil das Modell auf kohärente Sprachgenerierung und nicht auf faktische Richtigkeit optimiert ist. Überprüfen Sie wichtige Informationen immer, insbesondere bei speziellen oder zeitkritischen Themen.
Wie viel kostet die Integration der OpenAI-API in eine Anwendung?
Die API-Preisgestaltung basiert auf einem Pay-per-Token-Modell – die Kosten richten sich nach der Menge des verarbeiteten und generierten Textes. Die Kosten variieren je nach Modell; leistungsfähigere Modelle sind pro Token teurer. Aktuelle Preise finden Sie auf der offiziellen OpenAI-Preisseite, da sich die Gebühren ändern und vom Nutzungsvolumen abhängen. Die meisten Anwendungen beginnen mit kleinen Tests, um die Kosten vor der vollständigen Implementierung abzuschätzen.
Können große Sprachmodelle menschliche Autoren oder Programmierer ersetzen?
Nicht ganz. LLM-Absolventen sind zwar hervorragend darin, Entwürfe zu erstellen, Routineaufgaben zu erledigen und Ausgangspunkte zu liefern, doch es mangelt ihnen an echtem Verständnis, origineller Kreativität und Urteilsvermögen. Im Bereich Schreiben produzieren sie generische Inhalte, die menschliches Feinschliff hinsichtlich Stil, Genauigkeit und Tiefe erfordern. Im Bereich Programmieren schreiben sie zwar funktionalen Code, können aber Fehler, Sicherheitslücken oder mangelhafte Architekturentscheidungen einbauen. Betrachten Sie sie daher eher als wertvolle Unterstützung denn als Ersatz.
Worin besteht der Unterschied zwischen GPT-5.5 Instant und GPT-5.5 Thinking?
Laut offizieller Dokumentation ist GPT-5.5 Instant auf Geschwindigkeit optimiert und verarbeitet praktisch unbegrenzt viele Anfragen – es ist für Routineaufgaben mit hohem Volumen konzipiert. GPT-5.5 Thinking konzentriert sich auf komplexes Denken und mehrstufige Probleme mit einem Limit von 3000 Anfragen pro Woche für ChatGPT Business-Nutzer. Wählen Sie Instant für schnelle Antworten und hohen Durchsatz; wählen Sie Thinking, wenn Probleme eine tiefergehende Analyse erfordern.
Wie kann ich verhindern, dass mein Chatbot von Nutzern manipuliert wird?
Implementieren Sie mehrere Sicherheitsvorkehrungen: Validieren und bereinigen Sie alle Benutzereingaben, verwenden Sie Systemanweisungen, die schwerer zu überschreiben sind, implementieren Sie Ausgabefilter, um unzulässige Antworten abzufangen, und gestalten Sie das System so, dass das Modell nicht direkt auf sensible Funktionen zugreifen kann. Regelmäßige Tests mit simulierten Eingabeaufforderungen helfen, Schwachstellen zu identifizieren. Fügen Sie für kritische Anwendungen manuelle Prüfpunkte für wichtige Entscheidungen hinzu.
Schlussfolgerung
Große Sprachmodelle stellen einen grundlegenden Wandel in der Interaktion von Maschinen mit der menschlichen Sprache dar. ChatGPT und ähnliche Systeme demonstrieren Fähigkeiten, die noch vor wenigen Jahren unmöglich schienen – von der Generierung zusammenhängender, längerer Texte über das Schreiben funktionalen Codes bis hin zur Teilnahme an differenzierten Gesprächen.
Doch ihre Grenzen zu verstehen ist genauso wichtig wie ihre Stärken zu erkennen. Es handelt sich um Mustererkennungssysteme, die statistisch wahrscheinliche Texte generieren, nicht um denkende Maschinen mit echtem Verständnis. Sie halluzinieren, zeigen Verzerrungen, haben Schwierigkeiten mit neuen Denkprozessen und können nicht auf Informationen zugreifen, die über ihren Trainingsumfang hinausgehen.
Der praktische Weg nach vorn besteht darin, LLMs als leistungsstarke Werkzeuge zu betrachten, die menschliche Fähigkeiten erweitern, anstatt sie zu ersetzen. Nutzen Sie sie für Entwürfe, Brainstorming, die Automatisierung von Routineaufgaben und die Verarbeitung großer Textmengen. Behalten Sie aber den Menschen für Beurteilung, Überprüfung, Kreativität und Verantwortlichkeit im Spiel.
Sind Sie bereit, große Sprachmodelle in Ihren Workflow zu integrieren? Beginnen Sie mit der OpenAI-API-Dokumentation, experimentieren Sie mit verschiedenen Prompting-Techniken und implementieren Sie Sicherheitsvorkehrungen, die auf Ihren Anwendungsfall zugeschnitten sind. Die Technologie ist leistungsstark – ihre effektive Nutzung erfordert ein Verständnis ihrer Möglichkeiten und Grenzen.