Resumen rápido: ChatGPT se basa en grandes modelos de lenguaje (LLM, por sus siglas en inglés), redes neuronales basadas en transformadores entrenadas con vastos conjuntos de datos de texto para predecir y generar texto similar al humano. Estos modelos utilizan mecanismos de atención para comprender el contexto y, a continuación, generan respuestas token por token. Si bien son increíblemente potentes para la generación de texto, la codificación y la conversación, presentan limitaciones como imprecisiones ocasionales, falta de conocimiento en tiempo real y sensibilidad a la formulación de las indicaciones.
Gracias a ChatGPT, la inteligencia artificial ha pasado del ámbito tecnológico a la conversación cotidiana. La gente la usa para escribir correos electrónicos, depurar código, generar ideas e incluso redactar documentos legales.
Pero, ¿cómo funciona realmente? ¿Qué sucede cuando escribes una pregunta y recibes una respuesta coherente, similar a la de un humano, en cuestión de segundos?
La respuesta reside en los grandes modelos de lenguaje: sofisticadas redes neuronales que han transformado radicalmente la forma en que las máquinas comprenden y generan texto. Esta guía explica la arquitectura, el proceso de entrenamiento y las aplicaciones prácticas sin caer en la exageración.
¿Qué son los modelos de lenguaje a gran escala?
Los grandes modelos de lenguaje son sistemas de IA diseñados para comprender y generar lenguaje humano. En esencia, son motores de predicción: a partir de un texto de entrada, predicen qué palabras deberían seguir.
Pero esa simple descripción no hace justicia a lo que han logrado. Los sistemas de aprendizaje automático modernos como GPT-5.5 pueden escribir código, responder preguntas, traducir idiomas, resumir documentos y mantener conversaciones que resultan sorprendentemente naturales.
La parte “grande” es importante. Estos modelos contienen miles de millones de parámetros: ponderaciones ajustables que determinan cómo el modelo procesa la información. GPT-5.5 representa la última generación y ofrece capacidades de razonamiento mejoradas en comparación con versiones anteriores.
La Fundación: Arquitectura Transformadora
Los modelos de lenguaje de gran tamaño se basan en la arquitectura Transformer, introducida en el artículo de investigación fundamental "Attention Is All You Need". Esta arquitectura reemplazó los modelos de secuencia más antiguos con un enfoque más eficiente.
Lo que hace especiales a los transformadores es que procesan secuencias completas de texto simultáneamente, en lugar de palabra por palabra. Este procesamiento paralelo les permite manejar contextos mucho más largos y entrenarse de forma mucho más eficiente.
La arquitectura Transformer se basa en un mecanismo denominado de atención. Este mecanismo permite que el modelo pondere la importancia de las diferentes palabras en una secuencia al generar predicciones.
Consideremos la oración: “El animal no cruzó la calle porque estaba demasiado cansado”. Para comprender a qué se refiere “eso”, el modelo debe prestar atención a “animal” en lugar de a “calle”. Los mecanismos de atención manejan precisamente este tipo de razonamiento contextual.
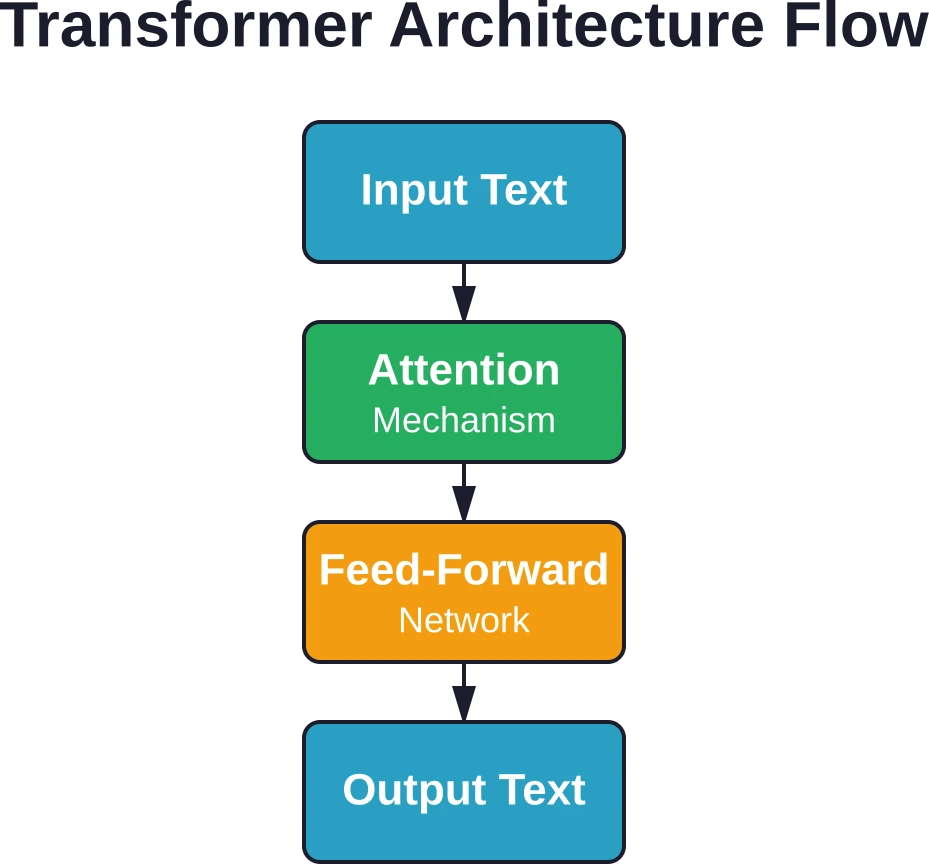
Cómo el texto se convierte en números
Los modelos de lenguaje en realidad no trabajan con palabras, sino con números. Antes de que comience el procesamiento, el texto se convierte en tokens, que luego se asignan a vectores numéricos.
La tokenización divide el texto en unidades más pequeñas. A veces, un token es una palabra completa; otras veces, solo unos pocos caracteres. La palabra "chatbot" podría convertirse en un token, mientras que "sin precedentes" podría dividirse en "sin", "pre" y "cedente".“
Cada token se asigna a un vector de alta dimensión, que es esencialmente una lista de números que representa el "significado" de ese token en un espacio matemático. Las palabras con significados similares terminan con vectores similares.
Esta representación numérica permite al modelo realizar operaciones matemáticas sobre el lenguaje, encontrando patrones y relaciones que serían imposibles de codificar manualmente.

Desarrollar herramientas progresivas con IA superior
IA superior Desarrolla aplicaciones basadas en IA y productos de software personalizados utilizando aprendizaje automático y modelos de IA. Sus servicios incluyen desarrollo de software de IA, consultoría, I+D, capacitación, PNL, análisis predictivo, BI y análisis de big data.
¿Necesitas una herramienta de IA diseñada para tu flujo de trabajo?
AI Superior puede ayudar con:
- Desarrollo de herramientas personalizadas de PLN y LLM
- Probar ideas de chatbots mediante pruebas de concepto o trabajos de producto mínimo viable (MVP).
- análisis de datos de texto y documentos
- Integración de herramientas de IA en sistemas existentes
👉 Contacta con IA Superior para hablar sobre su proyecto.
Cómo ChatGPT genera texto
Cuando envías una solicitud a ChatGPT, se inicia un sofisticado proceso de predicción. El modelo no genera la respuesta completa de una sola vez, sino que produce un token a la vez.
Esta es la secuencia: el modelo toma tu mensaje, lo procesa a través de múltiples capas transformadoras y predice el siguiente token más probable. Ese token predicho se agrega a la entrada y el proceso se repite hasta que el modelo genera una señal de parada.
Este enfoque autorregresivo implica que cada palabra influye en la siguiente. Si el modelo comete un error al principio de su respuesta, este error puede acumularse a medida que el modelo se basa en su propia salida incorrecta.
El papel de la temperatura y el muestreo
El modelo no siempre elige la palabra más probable a continuación. Eso haría que las respuestas fueran predecibles y repetitivas.
En cambio, los modelos de lenguaje utilizan aleatoriedad controlada. El parámetro de temperatura controla la cantidad de aleatoriedad que se introduce. Una temperatura baja hace que el modelo sea más determinista y preciso. Una temperatura alta introduce mayor variedad, pero conlleva el riesgo de incoherencia.
La API de OpenAI permite a los desarrolladores ajustar estos parámetros. Para tareas que requieren precisión, como la generación de código o la extracción de datos, las temperaturas más bajas funcionan mejor. La escritura creativa se beneficia de valores ligeramente más altos.
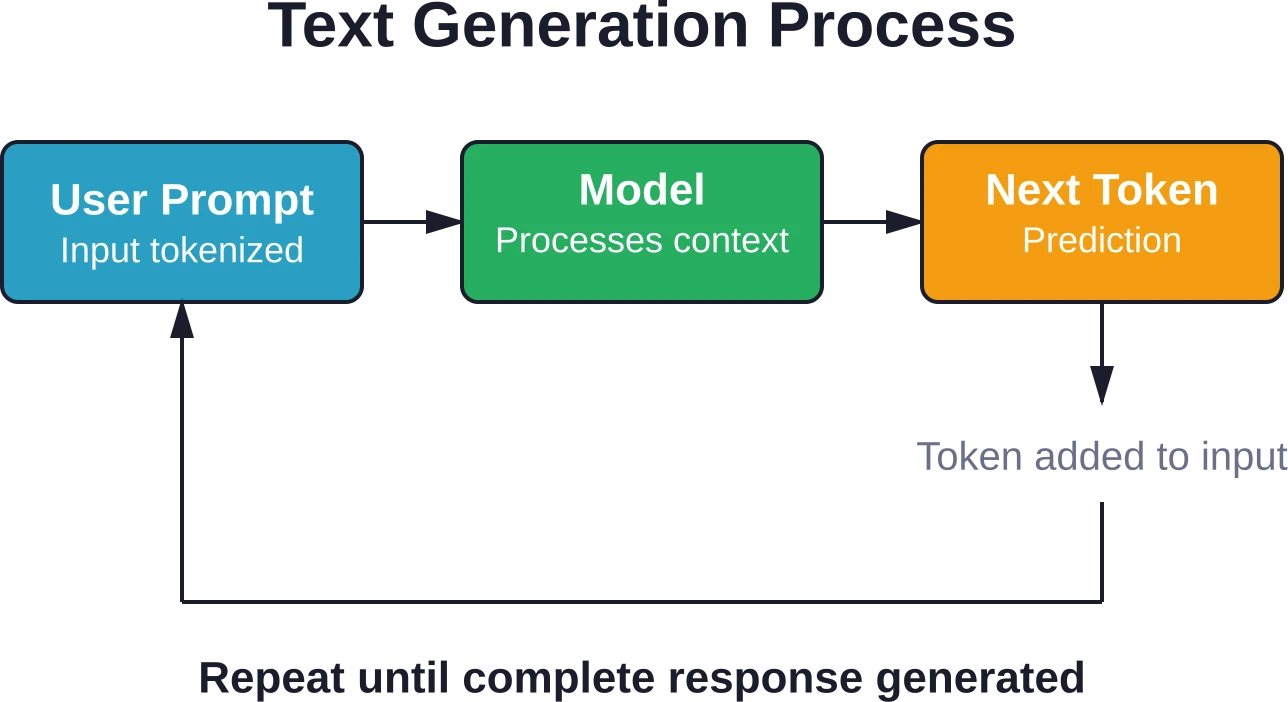
Entrenamiento de modelos de lenguaje a gran escala
La creación de un modelo como ChatGPT implica múltiples etapas de entrenamiento, cada una con un propósito distinto.
Preparación previa: Aprendizaje de patrones lingüísticos
En la fase de preentrenamiento, el modelo aprende a comprender el lenguaje básico. Durante esta fase, el modelo procesa enormes conjuntos de datos: libros, sitios web, artículos, repositorios de código y mucho más.
El objetivo del entrenamiento es sencillo: predecir la siguiente palabra. Al realizar esta tarea miles de millones de veces en textos diversos, el modelo aprende gramática, datos, patrones de razonamiento e incluso algo de sentido común.
Esta fase requiere enormes recursos computacionales. Las pruebas de entrenamiento pueden durar semanas o meses en clústeres de hardware especializado.
Ajuste fino: comportamiento especializado
Los modelos preentrenados poseen conocimientos, pero no siempre son útiles. Pueden generar respuestas precisas pero inapropiadas, o no seguir las instrucciones correctamente.
El ajuste fino aborda este problema. Según una investigación de Stanford HAI, el ajuste fino personaliza los modelos básicos para tareas o comportamientos específicos, aunque también introduce riesgos de seguridad si no se controla cuidadosamente.
En el caso de ChatGPT, el ajuste fino implica el entrenamiento con conjuntos de datos seleccionados de conversaciones de alta calidad, con retroalimentación humana que guía al modelo hacia respuestas útiles, inofensivas y honestas.
Aprendizaje por refuerzo a partir de la retroalimentación humana
La etapa final de entrenamiento utiliza el aprendizaje por refuerzo. Evaluadores humanos clasifican las diferentes respuestas del modelo ante la misma indicación. Estas clasificaciones entrenan un modelo de recompensa que predice las preferencias humanas.
Posteriormente, el modelo de lenguaje se optimiza para generar respuestas que obtengan una puntuación más alta en este modelo de recompensa. Este enfoque ayuda a alinear el comportamiento del modelo con los valores y expectativas humanas.
No es perfecto: el modelo aprende a optimizarse según las preferencias de los evaluadores, lo cual no siempre coincide con lo que es objetivamente mejor. Pero actualmente es la técnica de alineación más eficaz disponible.
La API de OpenAI y GPT-5.5
Si bien ChatGPT proporciona una interfaz para el usuario, la API de OpenAI ofrece a los desarrolladores acceso programático a los modelos subyacentes. Según la documentación oficial, la API utiliza puntos finales RESTful que funcionan mediante solicitudes HTTP estándar.
Según la documentación oficial de la API de OpenAI, la autenticación utiliza claves API mediante autenticación HTTP Bearer. Estas claves nunca deben exponerse en el código del cliente; están destinadas únicamente a aplicaciones del servidor.
Opciones del modelo actual
La API ofrece acceso a múltiples modelos con diferentes capacidades y precios. Según la documentación oficial de OpenAI, GPT-5.5 es la familia de modelos más reciente, diseñada para flujos de trabajo de producción complejos.
GPT-5.5 destaca en tareas de codificación, flujos de trabajo de agentes con gran cantidad de herramientas, recuperación de contexto extenso y aplicaciones de atención al cliente donde la calidad de la respuesta es fundamental. Según las directrices oficiales, debe considerarse una nueva familia de modelos para la que hay que optimizarla, no un reemplazo directo para versiones anteriores.
La documentación oficial muestra tres variantes de GPT-5.5 disponibles para los usuarios de ChatGPT Business: GPT-5.5 Instant, con un uso prácticamente ilimitado para tareas rutinarias; GPT-5.5 Thinking, con 3000 solicitudes por semana para usuarios de ChatGPT Business que requieren razonamiento complejo; y GPT-5.5 Pro, con 15 solicitudes por mes para las cargas de trabajo más exigentes.
| Modelo | Mejor para | Punto fuerte clave |
|---|---|---|
| GPT-5.5 Instant | Tareas de alto volumen | Velocidad y disponibilidad |
| GPT-5.5 Pensamiento | razonamiento complejo | Resolución de problemas en múltiples pasos |
| GPT-5.5 Pro | Cargas de trabajo premium | Capacidad máxima |
Realizar llamadas a la API
Según la documentación oficial de la API, la API Responses gestiona las solicitudes directas de modelos para la generación de texto. El patrón básico consiste en crear un cliente, especificar un modelo y proporcionar el texto de entrada.
La API devuelve respuestas estructuradas con el texto generado en el campo output_text. Los desarrolladores pueden ajustar parámetros como la temperatura, el número máximo de tokens y las secuencias de parada para controlar el comportamiento de la generación.
Para aplicaciones de producción, es fundamental un manejo adecuado de errores y la limitación de velocidad. La API impone límites de uso según el nivel de cuenta y puede generar errores de límite de velocidad durante períodos de alto tráfico.
Planes de suscripción de ChatGPT
OpenAI ofrece varios planes de suscripción con diferentes funcionalidades y limitaciones. Los precios y las características se actualizan periódicamente, por lo que se recomienda consultar la página oficial de precios para obtener información actualizada.
Planes para el consumidor
Según el Centro de Ayuda oficial de OpenAI, ChatGPT Go es una suscripción de bajo costo que ofrece acceso ampliado a funciones populares. Incluye acceso ilimitado a GPT-5.5 Instant, generación de imágenes ampliada, carga de archivos y análisis de datos avanzado.
ChatGPT Plus tiene un precio de $20 al mes, según fuentes oficiales. Ofrece acceso a funciones avanzadas como Codex e Investigación Profunda para proyectos seleccionados durante toda la semana.
ChatGPT Pro viene en dos niveles según la documentación oficial: $100 por mes para proyectos reales con límites 5 veces superiores a Plus (y 10 veces el uso de Codex por tiempo limitado), y $200 por mes para flujos de trabajo intensivos con límites 20 veces superiores a Plus (y 25 veces el uso de Codex por tiempo limitado).
Negocios y empresas
ChatGPT Business proporciona espacios de trabajo colaborativos seguros para equipos. Según la documentación de ayuda oficial, incluye inicio de sesión único (SSO) mediante SAML, controles de administración y compatibilidad con el cumplimiento del RGPD y la CCPA.
Según las páginas de precios oficiales, Codex es un plan enfocado en el desarrollo con precios basados en el uso y sin tarifas fijas por usuario. Incluye ingeniería de software con IA, revisiones de código automatizadas y entornos integrados para flujos de trabajo multiagente.
Los planes empresariales ofrecen soluciones personalizadas para grandes organizaciones. Los precios y las características específicas varían según las necesidades de cada organización.

Aplicaciones prácticas de los modelos de lenguaje a gran escala
Los modelos de lenguaje a gran escala han demostrado ser útiles en ámbitos sorprendentemente diversos. Algunas aplicaciones funcionan mejor que otras.
Creación y redacción de contenido
La asistencia en redacción es uno de los casos de uso más comunes. Los másteres en Derecho pueden redactar artículos, generar textos publicitarios, escribir correos electrónicos y crear contenido para redes sociales.
La calidad varía. Para contenido informativo y directo, los másteres en Derecho (LLM) funcionan bien. Para contenido que requiere conocimientos especializados, argumentos complejos o investigación original, la intervención humana sigue siendo fundamental.
Muchos escritores utilizan a los LLM como colaboradores para generar ideas o borradores iniciales, en lugar de como productores de contenido final. Este enfoque colaborativo suele producir mejores resultados que el trabajo exclusivamente humano o el trabajo exclusivamente con IA.
Generación y depuración de código
La programación es donde los másteres en Derecho modernos destacan especialmente. Pueden escribir funciones, depurar errores, traducir entre lenguajes de programación y explicar código complejo.
Según la documentación oficial, GPT-5.5 demuestra una gran capacidad para tareas de codificación. Maneja proyectos con múltiples archivos, mantiene el contexto en grandes bases de código y genera código de calidad para producción en muchos escenarios.
Dicho esto, el código generado por LLM requiere revisión. Los modelos pueden producir código que funciona, pero que sigue malas prácticas, contiene errores sutiles o incluye vulnerabilidades de seguridad.
Análisis y extracción de datos
Los modelos de lenguaje pueden procesar texto no estructurado y extraer información estructurada. Analizan documentos, categorizan el contenido, extraen datos clave y dan formato a los datos para su análisis.
Para aplicaciones empresariales, esto permite el procesamiento automatizado de documentos, el análisis de los comentarios de los clientes y la síntesis de información a partir de grandes colecciones de texto.
El desafío radica en la fiabilidad. En ocasiones, los modelos omiten información importante o introducen errores. Para aplicaciones críticas, son necesarios pasos de verificación.
Interfaces conversacionales
Los chatbots y asistentes virtuales impulsados por LLM pueden gestionar el servicio al cliente, responder preguntas y guiar a los usuarios a través de procesos complejos.
Estas aplicaciones se benefician de la capacidad del modelo para comprender el contexto, manejar diferentes formulaciones y generar respuestas naturales. La conversación resulta menos robótica que en los sistemas tradicionales basados en reglas.
Pero los errores ocurren. A veces, los modelos proporcionan información incorrecta que suena segura, un comportamiento conocido como alucinación. Las aplicaciones que manejan decisiones importantes necesitan medidas de seguridad.
Ingeniería rápida: Cómo obtener mejores resultados
La forma en que se redactan las indicaciones influye significativamente en la calidad del resultado. La ingeniería de indicaciones se ha consolidado como una habilidad centrada en la elaboración de instrucciones eficaces.
Principios fundamentales
La claridad es fundamental. Las indicaciones vagas producen resultados vagos. Las instrucciones específicas con requisitos claros generan resultados más útiles.
El contexto es importante. Proporcionar información de fondo, ejemplos y limitaciones guía al modelo hacia mejores respuestas.
Las especificaciones de formato funcionan bien. Si necesita salida JSON, datos CSV o formato Markdown, indicar explícitamente ese requisito mejora el cumplimiento.
Técnicas comunes
El aprendizaje con pocos ejemplos consiste en proporcionar ejemplos antes de la solicitud real. Muestre al modelo 2 o 3 ejemplos de la tarea que desea realizar y, a continuación, preséntele la entrada real. Esto mejora notablemente el rendimiento en patrones específicos.
La indicación de roles —pedirle al modelo que adopte una perspectiva específica— puede mejorar las respuestas específicas del dominio. Frases como “Como desarrollador de Python con experiencia” o “Desde la perspectiva del cumplimiento legal” centran el enfoque del modelo.
La función de inducción de cadena de pensamiento solicita explícitamente al modelo que explique su razonamiento paso a paso. Esto mejora el rendimiento en problemas de razonamiento lógico y matemático.
| Técnica | Cuándo usar | Ejemplo |
|---|---|---|
| Aprendizaje con pocos ejemplos | Se necesita un formato de salida específico. | Proporcione 2-3 ejemplos antes de la tarea. |
| Indicaciones de roles | Se requiere experiencia en el dominio. | “Como experto en ciberseguridad…” |
| Cadena de pensamiento | Tareas de razonamiento complejo | “Explica tu razonamiento paso a paso” |
| Instrucciones del sistema | Restricciones de comportamiento | Defina el tono, el estilo y los límites. |
Limitaciones y desafíos
Los modelos de lenguaje complejos no son mágicos. Tienen limitaciones reales que afectan a las aplicaciones prácticas.
Desconexión del conocimiento y obsolescencia
Los modelos aprenden durante el entrenamiento, no durante su uso. Los datos de entrenamiento tienen una fecha límite, después de la cual el modelo no sabe nada.
Ante preguntas sobre eventos recientes, nuevas tecnologías o información actualizada, los modelos proporcionan respuestas obsoletas o inventadas. Esto resulta especialmente problemático en ámbitos donde el tiempo es crucial.
Algunos sistemas solucionan esto mediante la recuperación de información, es decir, obteniendo información actualizada de fuentes externas e incluyéndola en la solicitud. Sin embargo, esto aumenta la complejidad y el costo.
Alucinación
Cuando los modelos desconocen algo, no dicen "No lo sé". Generan información que suena plausible pero que es incorrecta.
Esto sucede porque el objetivo del modelo es generar texto coherente, no garantizar la exactitud de los hechos. El proceso de entrenamiento optimiza los patrones lingüísticos, no la verdad.
Las alucinaciones son particularmente peligrosas en aplicaciones de alto riesgo. Es necesario verificar el asesoramiento médico, la orientación legal y las especificaciones técnicas.
Limitaciones del razonamiento
A pesar de su impresionante rendimiento, los modelos lógicos lineales no razonan como los humanos. Comparan patrones con los datos de entrenamiento en lugar de construir modelos lógicos.
Esto funciona bien para patrones comunes, pero falla en problemas novedosos que requieren un razonamiento genuino. Las matemáticas, los acertijos de lógica y las tareas que exigen una comprensión profunda ponen de manifiesto estas limitaciones.
Los modelos más recientes, como GPT-5.5 Thinking, muestran mejoras en el razonamiento de varios pasos, pero persisten limitaciones fundamentales.
Prejuicios y equidad
Los modelos aprenden a partir de textos de internet, que contienen sesgos humanos. Los datos de entrenamiento incluyen estereotipos, prejuicios y asociaciones problemáticas.
Los procesos de ajuste fino y alineación reducen, pero no eliminan, estos sesgos. Los modelos pueden generar resultados que reflejen sesgos de género, raciales o culturales presentes en los datos de entrenamiento.
Las aplicaciones que afectan directamente a las personas requieren pruebas de sesgo exhaustivas y estrategias de mitigación.
Consideraciones sobre seguridad y privacidad
El uso de modelos de lenguaje extensos introduce riesgos de seguridad y privacidad que requieren atención.
Privacidad de datos
El texto enviado a los puntos finales de la API se procesa en servidores externos. No se debe incluir información confidencial (datos personales, secretos comerciales, código propietario) sin las medidas de seguridad adecuadas.
Según la documentación oficial de OpenAI, los datos de la API no se utilizan para el entrenamiento de forma predeterminada, pero aun así transitan por su infraestructura. Para aplicaciones altamente sensibles, esto representa un riesgo inaceptable.
Algunas organizaciones utilizan modelos de código abierto autogestionados para mantener el control de los datos. Esto implica sacrificar la funcionalidad en aras de la privacidad.
Inyección inmediata
Cuando los modelos de lógica descriptiva (LLM) impulsan aplicaciones orientadas al usuario, los usuarios malintencionados pueden intentar ataques de inyección de comandos, creando entradas que manipulen el modelo para que ignore sus instrucciones.
Por ejemplo, un chatbot programado para "ser siempre útil" podría ser engañado para generar contenido dañino mediante mensajes ingeniosamente redactados que anulen las instrucciones originales.
Para protegerse contra la inyección instantánea se requiere validación de entrada, filtrado de salida y medidas de seguridad arquitectónicas que limiten a qué puede acceder o qué puede hacer el modelo.
Seguridad de la clave API
La documentación de la API de OpenAI subraya que las claves de API son secretos que requieren protección. Las claves expuestas permiten un uso no autorizado, lo que podría generar costes significativos.
Las claves nunca deben aparecer en el código del cliente, repositorios públicos ni registros. Deben almacenarse en variables de entorno o sistemas de gestión de secretos con los controles de acceso adecuados.
El futuro de los modelos de lenguaje a gran escala
Las capacidades de los modelos de lenguaje siguen avanzando rápidamente. Varias tendencias están dando forma a su desarrollo.
Modelos multimodales
Los modelos actuales, como GPT-5.5, ya procesan texto e imágenes. Los sistemas futuros integrarán de forma más completa audio, vídeo y otras modalidades.
Esto permite interacciones más enriquecedoras: analizar contenido de vídeo, generar imágenes a partir de descripciones o procesar el habla de forma natural. Los modelos multimodales pueden abordar problemas que requieren múltiples tipos de entrada y salida.
Mejoras en la eficiencia
Según estudios académicos, la investigación sobre arquitecturas eficientes se centra en reducir los costos computacionales manteniendo la capacidad. Técnicas como la cuantización, la poda y los mecanismos de atención eficientes permiten crear modelos más pequeños y rápidos.
Esto es importante para la implementación. Los modelos más pequeños funcionan con hardware menos costoso, reducen la latencia y permiten el procesamiento en el dispositivo para aplicaciones que requieren privacidad.
Ventanas de contexto más largas
Los primeros modelos solo procesaban unos pocos cientos de tokens de contexto. Los modelos modernos manejan miles o decenas de miles.
Según las investigaciones sobre la arquitectura de transformadores, ampliar la longitud del contexto permite nuevas aplicaciones: procesar documentos completos, mantener conversaciones más largas y razonar sobre más información simultáneamente.
Persisten desafíos técnicos en torno a la eficiencia computacional y la calidad de la atención en secuencias muy largas, pero el progreso continúa.
Mejor razonamiento
Los modelos actuales destacan en el reconocimiento de patrones, pero tienen dificultades con el razonamiento novedoso. La investigación explora arquitecturas y enfoques de entrenamiento que mejoran el razonamiento lógico, la resolución de problemas matemáticos y la planificación.
Los enfoques híbridos que combinan redes neuronales con sistemas de razonamiento simbólico resultan prometedores. Estos podrían abordar las limitaciones manteniendo la flexibilidad de los modelos aprendidos.
Preguntas frecuentes
¿Qué diferencia a ChatGPT de los chatbots tradicionales?
Los chatbots tradicionales utilizan reglas y guiones predefinidos: asocian las entradas del usuario con respuestas preestablecidas. ChatGPT utiliza un modelo de lenguaje complejo que genera respuestas dinámicamente a partir de patrones aprendidos de vastos conjuntos de datos de texto. Esto le permite gestionar preguntas inesperadas, comprender el contexto y generar conversaciones similares a las humanas, en lugar de seguir árboles de decisión rígidos.
¿Puedo usar ChatGPT para mi negocio sin preocuparme por la privacidad?
Depende de los datos que compartas. Según la documentación oficial, los datos de la API no se utilizan para el entrenamiento de forma predeterminada, pero la información pasa por sus sistemas. Para datos sensibles (registros de clientes, información confidencial, documentos de propiedad exclusiva), debes usar planes empresariales con controles de seguridad adecuados, implementar filtros de datos o considerar alternativas de alojamiento propio para garantizar la máxima privacidad.
¿Por qué ChatGPT a veces proporciona información incorrecta?
ChatGPT genera respuestas prediciendo secuencias de texto probables, no recuperando información verificada de una base de datos. Cuando desconoce algo, produce un texto que suena plausible basándose en patrones de los datos de entrenamiento. Esta "ilusión" se produce porque el modelo optimiza la generación de lenguaje coherente, no la precisión factual. Siempre verifique la información importante, especialmente en temas especializados o urgentes.
¿Cuánto cuesta integrar la API de OpenAI en una aplicación?
El modelo de precios de la API se basa en el pago por token: se cobra en función de la cantidad de texto procesado y generado. Los costes varían según el modelo, siendo los modelos más avanzados los que tienen un coste mayor por token. Para consultar los precios actuales, visite la página oficial de precios de OpenAI, ya que las tarifas cambian y dependen del volumen de uso. La mayoría de las aplicaciones comienzan con pruebas a pequeña escala para estimar los costes antes de la implementación completa.
¿Pueden los modelos de lenguaje complejos reemplazar a los escritores o programadores humanos?
No del todo. Los másteres en Derecho (LLM) destacan en la elaboración de borradores, la gestión de tareas rutinarias y la provisión de puntos de partida, pero carecen de verdadera comprensión, creatividad original y criterio. En la redacción, producen contenido genérico que requiere edición humana para lograr un estilo, precisión y profundidad adecuados. En la programación, escriben código funcional, pero pueden introducir errores, problemas de seguridad o decisiones arquitectónicas deficientes. Considérelos como valiosos asistentes, no como sustitutos.
¿Cuál es la diferencia entre GPT-5.5 Instant y GPT-5.5 Thinking?
Según la documentación oficial, GPT-5.5 Instant está optimizado para la velocidad y gestiona solicitudes prácticamente ilimitadas; está diseñado para tareas rutinarias de alto volumen. GPT-5.5 Thinking se centra en el razonamiento complejo y los problemas de varios pasos, con un límite de 3000 solicitudes por semana para los usuarios de ChatGPT Business. Elija Instant para obtener respuestas rápidas y un alto rendimiento; elija Thinking cuando los problemas requieran un análisis más profundo.
¿Cómo puedo evitar que los usuarios manipulen mi chatbot?
Implemente múltiples medidas de seguridad: valide y sanee todas las entradas del usuario, utilice instrucciones del sistema más difíciles de eludir, implemente filtros de salida para detectar respuestas inapropiadas y diseñe el sistema de manera que el modelo no pueda acceder directamente a funciones sensibles. Las pruebas periódicas con solicitudes adversarias ayudan a identificar vulnerabilidades. Para aplicaciones críticas, añada puntos de control de revisión humana para decisiones de alto riesgo.
Conclusión
Los modelos de lenguaje a gran escala representan un cambio fundamental en la forma en que las máquinas interactúan con el lenguaje humano. ChatGPT y sistemas similares demuestran capacidades que parecían imposibles hace tan solo unos años: desde generar textos largos y coherentes hasta escribir código funcional y entablar conversaciones con matices.
Pero comprender sus limitaciones es tan importante como reconocer sus fortalezas. Se trata de sistemas de reconocimiento de patrones que generan texto estadísticamente probable, no de máquinas pensantes con una comprensión genuina. Tienen alucinaciones, muestran sesgos, les cuesta razonar sobre conceptos novedosos y no pueden acceder a información más allá de su límite de entrenamiento.
El camino práctico a seguir implica considerar los sistemas de gestión del lenguaje como herramientas poderosas que complementan las capacidades humanas, en lugar de reemplazarlas. Úselos para redactar, generar ideas, automatizar tareas rutinarias y procesar grandes volúmenes de texto. Sin embargo, es fundamental mantener la participación humana para la evaluación, la verificación, la creatividad y la rendición de cuentas.
¿Listo para integrar modelos de lenguaje complejos en tu flujo de trabajo? Comienza con la documentación de la API de OpenAI, experimenta con diferentes técnicas de indicaciones y establece medidas de seguridad adecuadas para tu caso de uso. Esta tecnología es potente; para usarla eficazmente, es necesario comprender tanto sus capacidades como sus limitaciones.