Quick Summary: Top data science solutions in 2026 include augmented analytics platforms that democratize insights across organizations, automated machine learning tools that accelerate model development, real-time analytics systems for instant decision-making, and AI-powered data governance frameworks. These solutions enable businesses to extract value from complex datasets while reducing the technical barriers traditionally associated with advanced analytics.
Organizations today face an unprecedented challenge: mountains of data, but limited ability to extract meaningful insights from it. The gap between data collection and actionable intelligence has never been wider.
Data science solutions bridge that gap. They transform raw information into strategic decisions, competitive advantages, and measurable business outcomes. But with hundreds of platforms, tools, and frameworks available, choosing the right solutions requires understanding what actually works in 2026.
This guide examines the most effective data science solutions currently reshaping industries. From augmented analytics that makes data accessible to non-technical teams, to automated machine learning that accelerates deployment timelines, these technologies represent the cutting edge of practical application.
The Evolution of Data Science Solutions
Data science has matured significantly since its early days of custom-coded algorithms and manual feature engineering. Modern solutions emphasize accessibility, automation, and integration with existing business processes.
The shift reflects a fundamental change in how organizations approach analytics. Rather than relying solely on specialized data scientists working in isolation, companies now deploy platforms that enable collaboration across departments. Marketing teams run predictive models. Operations staff optimize logistics with machine learning. Finance departments automate risk assessment.
This democratization didn’t happen by accident. Technology providers recognized that most businesses couldn’t hire enough data scientists to meet demand.
The standards governing these systems have also evolved. The NIST SP 800-181 framework established competency areas for cybersecurity and data science roles. The current version (2.2.0) was released April 28, 2025, with the 2020 revision (NIST SP 800-181r1) published earlier for cybersecurity and data science roles. NISTIR 8355 (published June 2023) provides companion guidance on competency areas for preparing a job-ready cybersecurity workforce, creating clearer pathways for workforce development and technology implementation.

Create Data Science Solutions With AI Superior
AI Superior builds AI-based applications and custom software products using machine learning models, data analysis, NLP, computer vision, BI, and big data analytics. Their work can support projects from discovery and data review to MVP development, integration, and result evaluation.
For companies reviewing data science solutions, this can help move from scattered data and rough ideas to working tools that support forecasting, automation, and clearer decisions.
Need Data Science Built for Real Workflows?
AI Superior can help with:
- building custom data science solutions
- developing machine learning and analytics models
- testing ideas through PoC or MVP development
- integrating AI into daily systems
👉 Contact AI Superior to discuss your project.
Augmented Analytics: Making Data Accessible
Augmented analytics represents one of the most impactful developments in recent years. These platforms use machine learning to automate data preparation, insight generation, and explanation—tasks that traditionally required deep statistical expertise.
The core value proposition is simple: business users ask questions in natural language, and the system handles the technical complexity behind the scenes. No SQL queries. No pivot tables. No struggling with visualization tools.
But does that actually work? In practice, yes—with caveats. Augmented analytics excels at exploratory analysis and routine reporting. Marketing managers can identify which customer segments show declining engagement. Supply chain analysts can spot inventory anomalies. Sales directors can forecast quarterly performance.
According to Top Data Science Solutions analysis, the augmented analytics market is expected to grow to $102.78 billion by 2030 at a CAGR of 28.09% That growth reflects genuine business adoption, not just vendor hype.
Key Capabilities of Modern Augmented Analytics
Leading platforms share several core features. Automated data preparation handles cleaning, transformation, and integration from multiple sources. Natural language query interfaces accept questions typed or spoken in everyday language. Smart visualization engines select appropriate chart types based on data characteristics and analytical context.
The explanation layer might be most important. When a platform identifies a trend or anomaly, it doesn’t just display a chart—it generates a narrative explaining what changed, why it matters, and what actions make sense. These explanations make insights usable by people who lack statistical training.
Real talk: augmented analytics won’t replace skilled analysts anytime soon. Complex investigations, custom modeling, and strategic interpretation still require human expertise. But for the 80% of analytical tasks that involve routine exploration and reporting, these platforms deliver substantial efficiency gains.
Implementation Considerations
Deploying augmented analytics successfully requires attention to data governance, user training, and integration architecture. The platform needs access to clean, well-structured data sources. Users need enough context to ask good questions and interpret results appropriately. IT teams need clear protocols for security, access control, and system maintenance.
Organizations that treat augmented analytics as a purely technical deployment often struggle. Those that approach it as a change management initiative—with executive sponsorship, user champions, and iterative rollout—see much higher adoption rates.
Automated Machine Learning Platforms
Automated machine learning (AutoML) addresses a different bottleneck: the time and expertise required to develop, tune, and deploy predictive models. Traditional machine learning projects involve extensive manual work—feature engineering, algorithm selection, hyperparameter tuning, validation testing.
AutoML platforms automate much of that pipeline. Data scientists specify the target variable and success metrics, and the system experiments with different algorithms, feature combinations, and parameter settings. The result: production-ready models in hours or days instead of weeks or months.
Recent benchmark evaluations show the performance gap between API-based commercial platforms and open-source alternatives continues to narrow. Performance varies across platforms.
What AutoML Does Well
AutoML shines in scenarios with structured data and clear prediction targets. Customer churn prediction, demand forecasting, fraud detection, equipment failure prediction—these applications typically involve tabular data and well-defined outcomes.
The platforms handle feature engineering automatically, testing transformations like polynomial features, interaction terms, and binning strategies. They evaluate dozens or hundreds of algorithm combinations, from linear models to gradient boosting to neural networks. Hyperparameter optimization uses techniques like Bayesian optimization or evolutionary algorithms to find configurations that maximize performance.
Deployment workflows have improved dramatically. Many platforms now generate containerized endpoints that integrate directly with existing applications. A marketing team can deploy a customer lifetime value model that scores every new lead in real-time, with no custom coding required.
Limitations and Best Practices
AutoML isn’t magic. It works best when the problem is clearly defined, the data is reasonably clean, and the relationship between features and target is learnable from historical patterns. It struggles with novel situations, rapidly changing environments, and tasks requiring domain-specific feature engineering.
The “black box” critique has some merit. While modern platforms provide feature importance scores and partial dependence plots, understanding exactly why a model makes specific predictions can be difficult. Regulated industries may require more interpretable approaches.
Best practice involves using AutoML to accelerate initial development, then having experienced practitioners review, validate, and potentially refine the results. Think of it as a highly productive junior data scientist that handles routine work, freeing senior staff for strategic challenges.
Real-Time Analytics Systems
Batch processing served analytics needs well for decades. Organizations collected data throughout the day, ran overnight processing jobs, and reviewed dashboards the next morning. That cycle worked fine when business moved at a slower pace.
Not anymore. Real-time analytics systems process streaming data continuously, delivering insights with latency measured in seconds or milliseconds instead of hours. Financial services firms detect fraudulent transactions before they settle. E-commerce platforms adjust recommendations as browsing behavior unfolds. Manufacturing facilities identify quality issues before defective products leave the production line.
The technical architecture differs significantly from traditional batch systems. Stream processing engines like Apache Kafka, Apache Flink, and cloud-native services handle data ingestion and transformation. In-memory databases store current state for instant querying. Event-driven architectures trigger actions automatically when conditions are met.
Use Cases Driving Adoption
Several application categories drive real-time analytics adoption. Fraud detection requires immediate scoring of transactions against behavioral patterns—delays of even minutes can result in completed fraudulent purchases. Algorithmic trading systems make buy/sell decisions in microseconds based on market data feeds and predictive models.
Operational monitoring uses real-time analytics to track system health, application performance, and infrastructure metrics. IT teams identify and resolve issues before they impact users. DevOps workflows incorporate continuous monitoring into deployment pipelines.
Personalization engines update recommendations instantly based on current behavior. A customer browsing winter coats sees relevant accessories. A reader finishing an article receives suggestions aligned with demonstrated interests. These experiences require sub-second latency to feel responsive.
Implementation Complexity
Real-time analytics systems are substantially more complex than batch alternatives. The distributed architecture introduces challenges around data consistency, fault tolerance, and operational monitoring. Teams need expertise in stream processing frameworks, distributed systems design, and performance optimization.
Cost structures differ too. Real-time systems require continuous compute and storage resources, not just during batch windows. Cloud providers offer managed services that simplify deployment but charge for sustained throughput. Organizations should carefully evaluate whether specific use cases justify the additional complexity and expense.
That said, the threshold for “real-time” varies by application. Not every use case requires millisecond latency. Many business scenarios work fine with “near real-time” processing that delivers results in 30 seconds or a few minutes. Starting with simpler architectures and adding sophistication as needed often makes more sense than building for extreme performance requirements upfront.
AI-Powered Data Governance Solutions
Data governance sounds boring until you’ve dealt with the consequences of poor data quality, unclear ownership, or compliance violations. Organizations struggle to maintain data catalogs, enforce access policies, track lineage, and ensure regulatory compliance as data volumes and complexity grow.
AI-powered governance solutions automate many traditionally manual tasks. Machine learning classifies data assets, identifies sensitive information, recommends metadata tags, and detects anomalies in usage patterns. Natural language processing extracts meaning from documentation and suggests improvements to data definitions.
Recent advances in fairness algorithms demonstrate the potential. Research demonstrates 30% bias reduction benchmarked through domain-agnostic fairness adjustments that work transversely across datasets from banking to medical judgment These techniques help organizations identify and mitigate algorithmic bias before models reach production.
Core Governance Capabilities
Modern governance platforms provide several essential functions. Automated data discovery crawls repositories, databases, and file systems to create comprehensive catalogs of available data assets. Classification engines tag data with sensitivity levels, business domains, and quality metrics.
Lineage tracking follows data from source through transformations to final consumption. When a report shows unexpected values, analysts can trace back through the pipeline to identify where issues originated. When regulatory auditors ask how specific numbers were calculated, documentation exists to explain the full chain of processing.
Access control automation applies policies based on data classification, user roles, and contextual factors. Marketing staff can access customer contact information but not payment details. Analysts in specific regions see only data relevant to their geography. Contractors receive limited permissions that expire automatically.
Addressing Regulatory Requirements
Compliance frameworks like GDPR, CCPA, and HIPAA impose specific requirements around data handling, retention, and subject rights. Governance platforms help organizations meet those obligations through automated discovery of personal information, tracking of consent, and facilitation of deletion requests.
The NIST Big Data Framework, finalized in 2019, provides architectural guidance for organizations building large-scale analytics capabilities. It addresses security, privacy, and governance considerations alongside technical implementation patterns. Organizations can reference this framework when designing governance programs that support both regulatory compliance and business objectives.
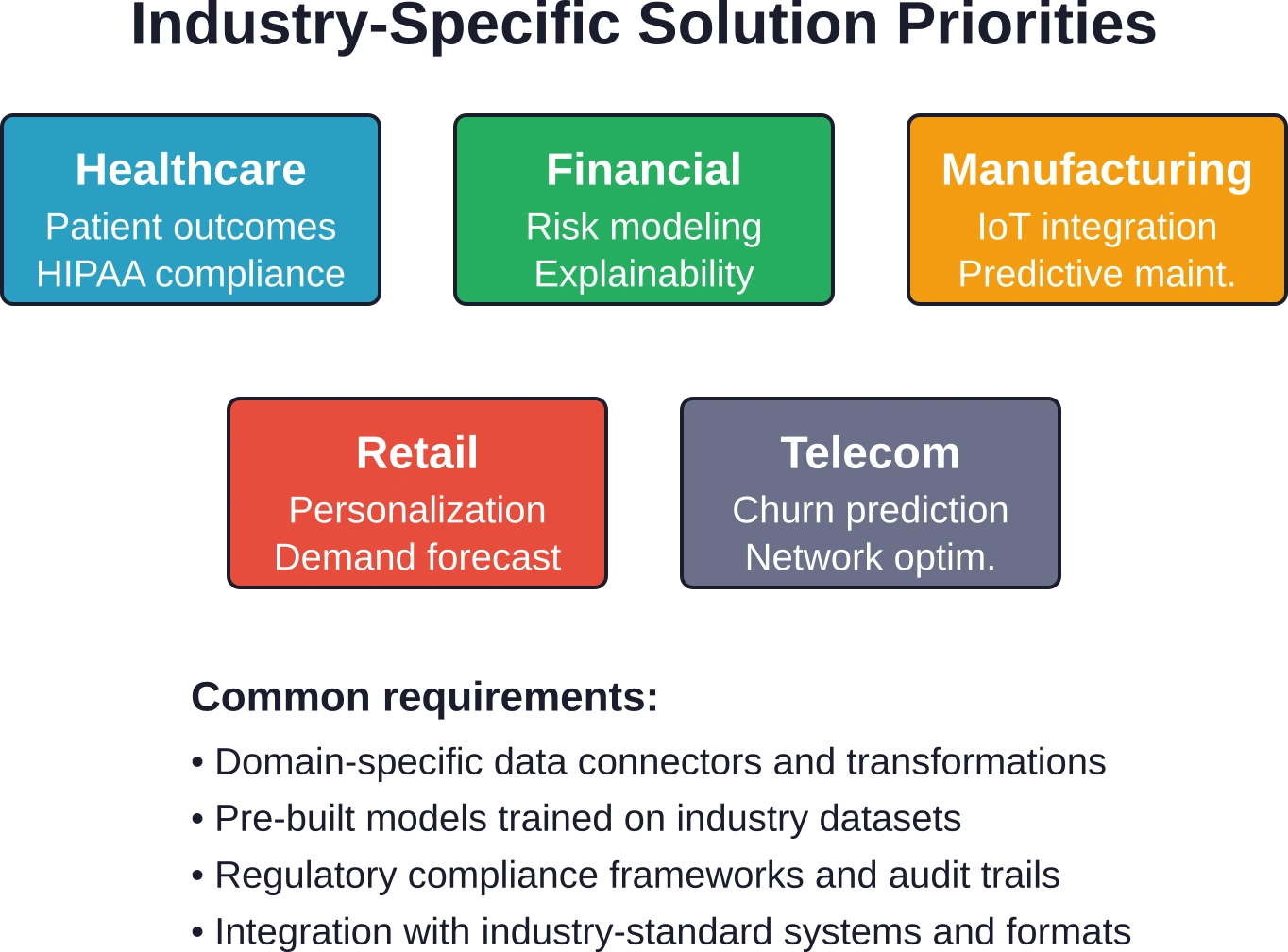
Specialized Solutions for Key Industries
While general-purpose platforms serve many needs, certain industries benefit from specialized data science solutions tailored to domain-specific challenges and regulatory requirements.
Healthcare Analytics
Healthcare organizations deal with complex, high-stakes decisions around patient care, resource allocation, and population health management. Specialized platforms integrate with electronic health records, medical imaging systems, and claims databases.
Predictive models identify patients at risk for readmission, deterioration, or medication non-adherence. Population health analytics segment patient populations and recommend targeted interventions. Clinical decision support systems provide evidence-based recommendations at the point of care.
Regulatory compliance remains critical. HIPAA requirements govern data access, de-identification, and breach notification. FDA guidance applies to clinical decision support tools that meet the definition of medical devices. Healthcare-focused platforms build these considerations into their architecture rather than treating compliance as an afterthought.
Financial Services
Banks, insurers, and investment firms pioneered many data science techniques. Today’s specialized platforms address risk modeling, regulatory reporting, fraud detection, and algorithmic trading with finance-specific features.
Model risk management capabilities help organizations meet regulatory expectations around model validation, documentation, and ongoing monitoring. Explainability tools generate audit trails that satisfy examiner requirements. Stress testing frameworks evaluate model performance under adverse scenarios.
The complexity of financial data—multiple time zones, corporate actions, varying market conventions—makes domain-specific solutions valuable. Generic platforms require extensive customization to handle these nuances correctly.
Manufacturing and Supply Chain
Manufacturers use data science for quality prediction, predictive maintenance, demand forecasting, and supply chain optimization. Specialized solutions integrate with industrial IoT sensors, manufacturing execution systems, and enterprise resource planning platforms.
Predictive maintenance models analyze sensor data to forecast equipment failures before they occur, enabling scheduled maintenance during planned downtime rather than emergency repairs during production runs. Quality prediction identifies process conditions that lead to defects, allowing real-time adjustments.
Supply chain analytics optimizes inventory levels, transportation routes, and production schedules across complex networks of suppliers, facilities, and customers. Research shows that autonomous agents progressively degrade performance on tasks requiring more than 10 seconds of execution time, highlighting the importance of optimized algorithms for real-time supply chain decisions
Emerging Trends Shaping Data Science Solutions
Several developments are reshaping how organizations approach data science implementation. Understanding these trends helps with strategic planning and technology selection.
Multimodal AI Integration
Traditional data science focused primarily on structured data—numbers, categories, timestamps. Modern platforms increasingly handle multiple data modalities: text, images, video, audio, sensor streams.
Recent research on NeuroFusion demonstrates a 34% improvement over existing multimodal benchmarks in real-time multimodal processing These systems process live data from video calls, augmented reality environments, and IoT devices simultaneously, enabling richer analysis than single-modality approaches.
Healthcare applications combine medical imaging with electronic health records and clinical notes. Retail systems analyze product images, customer reviews, and transaction data together. Manufacturing solutions integrate sensor readings, visual inspection imagery, and maintenance logs.
Automated Data Science Workflows
The trend toward automation extends beyond individual tasks to entire analytical workflows. Modern platforms orchestrate complex sequences: data ingestion, quality validation, feature engineering, model training, evaluation, deployment, and monitoring.
These end-to-end workflows reduce the manual effort required to move from raw data to production models. Organizations that previously needed weeks to deploy a new model can now complete the same process in days or hours. The faster iteration enables more experimentation and quicker response to changing conditions.
HardML, a benchmark for evaluating data science and machine learning knowledge, comprises 100 challenging multiple-choice questions covering diverse domains including deep learning, classical machine learning, natural language processing, computer vision, data engineering, and statistics Platforms that perform well across this diverse range demonstrate broader applicability than those optimized for narrow use cases.
Edge Analytics
Not all data science happens in centralized data centers or cloud environments. Edge analytics processes data on devices at the network periphery—smartphones, IoT sensors, autonomous vehicles, industrial equipment.
This approach offers several advantages. Latency drops dramatically when processing occurs locally rather than requiring round trips to distant servers. Bandwidth costs decrease since raw data doesn’t need transmission. Privacy improves because sensitive information can be processed and aggregated on-device rather than sent to external systems.
Edge deployment introduces constraints. Limited compute resources require optimized models. Intermittent connectivity demands robust handling of offline periods. Device diversity complicates deployment and maintenance. Specialized platforms address these challenges with model compression, federated learning, and over-the-air update capabilities.
Selecting the Right Data Science Solutions
With hundreds of platforms and tools available, selection decisions can feel overwhelming. A structured evaluation process helps identify solutions that align with specific organizational needs.
Define Clear Objectives
Start by articulating what business problems need solving. “Implement data science” isn’t an objective—it’s a capability. “Reduce customer churn by 15%” or “Decrease inventory carrying costs by 20%” represent measurable goals that guide technology selection.
Different objectives favor different solutions. Exploratory analytics and executive dashboards suggest augmented analytics platforms. Production ML deployment at scale indicates AutoML or MLOps tools. Regulatory compliance needs point toward governance solutions.
Assess Organizational Capabilities
Honest evaluation of internal skills, resources, and processes prevents mismatches between solution sophistication and organizational readiness. A platform requiring extensive DevOps expertise won’t succeed in an organization with limited technical staff. Conversely, overly simplistic tools may frustrate teams with advanced capabilities.
Consider the data science maturity model. Organizations just starting their analytics journey need different tools than those with established practices. Low-code platforms accelerate time-to-value for less experienced teams. Advanced frameworks provide flexibility for sophisticated users.
Evaluate Integration Requirements
Data science solutions rarely operate in isolation. They need to connect with existing data sources, business applications, and workflow systems. Integration complexity significantly impacts implementation timelines and ongoing maintenance burden.
Check for native connectors to your specific databases, SaaS applications, and data warehouses. Evaluate API capabilities for custom integrations. Consider authentication and security protocols. Organizations with complex technical environments should prioritize platforms with robust integration frameworks.
| Evaluation Criterion | Questions to Ask | Impact on Selection |
|---|---|---|
| Business Objectives | What specific outcomes drive this investment? | Determines category of solution needed |
| Technical Skills | What expertise exists in-house today? | Influences complexity level that’s feasible |
| Data Environment | Where does relevant data currently reside? | Affects integration effort and architecture |
| Scale Requirements | What data volumes and user counts are expected? | Guides infrastructure and licensing decisions |
| Compliance Needs | What regulatory requirements apply? | May require industry-specific or certified platforms |
Conduct Proof of Concept Testing
Vendor demonstrations show idealized scenarios with clean data and straightforward use cases. Real-world deployment often reveals complications. Proof of concept testing with actual organizational data provides much more reliable assessment.
Define specific success criteria before starting. Can the platform ingest and process your data formats? Does it deliver acceptable performance at realistic scale? Can intended users operate it without extensive training? Does it integrate cleanly with your existing systems?
Time-box the evaluation—typically 4-8 weeks—with clearly defined deliverables. A proof of concept that drags on for months without producing concrete results probably indicates fundamental compatibility issues.
Implementation Best Practices
Technology selection is just the beginning. Successful implementation requires attention to organizational change, user adoption, and operational processes.
Start Small, Scale Gradually
The temptation to tackle the most complex, highest-value use case first is understandable but usually counterproductive. Complex projects have more failure modes and longer timelines. Starting with a smaller, well-defined use case allows the team to learn the platform, establish processes, and demonstrate value before taking on bigger challenges.
Choose initial projects with clear business value, manageable scope, and accessible data. Success builds momentum and organizational confidence. Early wins create advocates who help drive broader adoption.
Invest in User Training
Even the most intuitive platform requires some learning. Organizations that treat training as optional consistently see lower adoption and poorer outcomes than those that invest in structured education.
Develop training programs tailored to different user roles. Executives need strategic context and high-level capabilities. Business analysts require hands-on practice with specific workflows. IT staff need architectural understanding and operational procedures.
Just-in-time training—delivered when users are ready to apply new skills—typically proves more effective than generic training sessions months before actual usage.
Establish Governance Early
Data science democratization creates new risks around data quality, model validity, and decision-making. Governance frameworks provide guardrails without stifling innovation.
Define clear policies for data access, model development, deployment approvals, and ongoing monitoring. Establish review processes that balance rigor with speed. Create documentation standards that make work reproducible and maintainable.
Organizations that implement governance reactively—after problems emerge—face harder conversations and more disruptive changes than those that establish frameworks proactively.
Measuring Success and ROI
Data science investments should deliver measurable business value. Defining and tracking appropriate metrics ensures accountability and guides continuous improvement.
Business Outcome Metrics
The most important measures tie directly to business objectives. If the goal was reducing customer churn, track churn rates before and after implementation. For inventory optimization, measure carrying costs and stockout frequencies. Revenue growth, cost reduction, customer satisfaction—these outcomes matter most.
Attribution can be tricky. Business results rarely have a single cause. Establish baselines before implementation, control for external factors where possible, and be honest about uncertainty in impact estimates.
Operational Metrics
Process improvements represent another value category. How much time does the analytics team save with automated data preparation? How many more models get deployed per quarter? How much faster do business users get answers to analytical questions?
These efficiency gains may not appear directly in financial statements, but they free resources for higher-value work and accelerate decision-making cycles.
Adoption Metrics
Technology that sits unused delivers no value. Track active users, query volumes, models in production, and other utilization indicators. Low adoption signals training gaps, usability issues, or misalignment with actual needs.
Survey users periodically about satisfaction, pain points, and feature requests. Qualitative feedback often reveals opportunities for improvement that quantitative metrics miss.
Common Implementation Challenges
Understanding typical obstacles helps organizations plan mitigation strategies rather than being surprised by preventable problems.
Data Quality and Accessibility
Organizations consistently underestimate data readiness challenges. Legacy systems with inconsistent formats. Missing values and data entry errors. Unclear definitions and undocumented transformations. Siloed data sources with incompatible schemas.
Data science platforms can’t fix fundamentally broken data. Allocate time and resources for data quality improvement as part of implementation planning. Establish data quality metrics and accountability. Consider master data management initiatives if problems are pervasive.
Skills Gaps
Even low-code platforms require analytical thinking and domain knowledge. Organizations often discover that democratizing access to tools doesn’t automatically create a culture of data-driven decision-making.
Address skills gaps through training, hiring, or partnership. Consider embedding data science experts within business units to provide guidance and support. Create communities of practice where users share knowledge and best practices.
Integration Complexity
What appeared straightforward during proof of concept often becomes complicated in production. Security requirements restrict network access. Data governance policies require approval workflows. Existing applications lack APIs. Performance degrades at production scale.
Engage IT and security teams early in planning. Budget adequate time for integration work. Test at realistic scale before going live. Have contingency plans for unexpected technical obstacles.
Future Directions
Several developments on the horizon will shape data science solutions in coming years.
Increased Automation
Automation will extend further into tasks currently requiring human judgment. AutoML evolves into AutoDS—automated data science covering the entire lifecycle from problem definition through deployment and monitoring. Organizations will specify business objectives and constraints, and systems will propose analytical approaches, execute them, and measure results.
This doesn’t eliminate human involvement, but shifts focus toward strategic decisions, interpretation, and governance rather than technical execution.
Better Explainability
Regulatory pressure and ethical concerns drive demand for more interpretable models. Black-box predictions become less acceptable in high-stakes domains like healthcare, finance, and criminal justice.
Research continues improving explanation techniques that work with complex models. Counterfactual explanations show what would need to change for a different prediction. Influence functions identify which training examples most affected a specific prediction. Attention mechanisms reveal which inputs the model focuses on.
Platforms will incorporate these techniques natively, making explainability a standard feature rather than a specialized add-on.
Distributed and Federated Learning
Privacy regulations and data sovereignty requirements complicate centralized data aggregation. Federated learning trains models across distributed datasets without moving the underlying data.
Healthcare organizations can collaborate on model development without sharing patient records. Financial institutions can improve fraud detection using collective intelligence while keeping transaction data isolated. Manufacturers can benchmark performance against competitors without revealing proprietary information.
This architectural shift requires new tooling, but addresses fundamental barriers to collaborative analytics in privacy-sensitive domains.
Frequently Asked Questions
What’s the difference between data science platforms and business intelligence tools?
Business intelligence tools focus primarily on reporting and visualization of historical data. Data science platforms emphasize predictive modeling, machine learning, and advanced analytics. Modern solutions increasingly blur these boundaries, but BI tools generally target descriptive analytics while data science platforms enable predictive and prescriptive capabilities.
How much does it cost to implement data science solutions?
Costs vary enormously based on platform choice, deployment scale, and organizational needs. Cloud-based managed services typically charge based on usage—compute hours, data processed, API calls. Enterprise licenses range from tens of thousands to millions of dollars annually. Open-source solutions require infrastructure and personnel costs rather than license fees. Check official provider websites for current pricing, as models change frequently.
Do we need to hire data scientists to use these platforms?
It depends on the platform and your objectives. Low-code augmented analytics platforms enable business users to perform many analyses without coding skills. AutoML tools reduce the specialized expertise needed for model development. However, complex projects, custom solutions, and production deployments typically benefit from experienced data science practitioners. Many organizations use a hybrid approach—empowering business users for routine work while maintaining specialized staff for advanced projects.
How long does it take to see results from data science investments?
Timeline varies by project scope and organizational readiness. Simple use cases with clean, accessible data can show results in weeks. Complex implementations involving multiple systems, custom development, or significant organizational change may require 6-12 months before delivering substantial value. Starting with smaller proof-of-concept projects helps demonstrate value faster and builds momentum for larger initiatives.
What industries benefit most from data science solutions?
Virtually every industry finds value in data science, but some see particularly dramatic impact. Financial services uses advanced analytics for risk assessment, fraud detection, and algorithmic trading. Healthcare applies predictive models to patient care, operational efficiency, and drug discovery. Retail leverages data science for personalization, demand forecasting, and supply chain optimization. Manufacturing employs predictive maintenance and quality control. Telecommunications uses churn prediction and network optimization.
How do we ensure our data science initiatives comply with regulations?
Compliance requires attention to data handling, model governance, and documentation. Use platforms with built-in compliance features for your industry—HIPAA for healthcare, SOC 2 for financial services, GDPR for European operations. Implement data governance frameworks that track lineage, enforce access controls, and maintain audit trails. Document model development, validation, and monitoring processes. Engage legal and compliance teams early in project planning. Consider specialized governance platforms if regulatory requirements are extensive.
Can data science solutions work with our existing systems?
Most modern platforms offer extensive integration capabilities through pre-built connectors, APIs, and data import/export tools. Check whether the platform you’re considering has native support for your specific databases, data warehouses, business applications, and file formats. Integration complexity varies significantly—cloud-based solutions often connect more easily to other cloud services, while on-premise deployments may require custom middleware. Evaluate integration requirements during platform selection rather than discovering compatibility issues after commitment.
Conclusion: Building Data-Driven Capabilities
Data science solutions have evolved from experimental technologies to essential business infrastructure. Organizations across industries now depend on these platforms to compete effectively, operate efficiently, and serve customers better.
The most successful implementations share common characteristics. They start with clear business objectives rather than technology for its own sake. They match solution sophistication to organizational capabilities and maturity. They invest in data quality, user training, and governance frameworks alongside technology deployment. They measure results rigorously and adjust based on evidence.
Look, no platform solves every problem or fits every organization. The “best” solution depends on specific needs, constraints, and objectives. Augmented analytics platforms democratize insights but won’t replace deep analytical expertise. AutoML accelerates model development but requires good data and well-defined problems. Real-time systems enable immediate action but introduce operational complexity. Specialized industry solutions address domain-specific requirements but may cost more than general platforms.
The data science landscape continues evolving rapidly. New capabilities emerge. Performance improves. Prices shift. Organizations that establish clear evaluation criteria, test thoroughly, and remain flexible about technology choices position themselves to adapt as the field advances.
Ready to transform how your organization uses data? Start by identifying one high-value use case with accessible data and clear success metrics. Evaluate platforms that fit your technical environment and skill levels. Conduct hands-on testing with real data. Build from there.
The competitive advantage increasingly goes to organizations that turn data into action faster and more effectively than peers. Data science solutions provide the tools—but success requires commitment to organizational change, continuous learning, and evidence-based decision-making.