Résumé rapide : Les solutions de pointe en science des données en 2026 incluent des plateformes d'analyse augmentée qui démocratisent l'accès aux données au sein des organisations, des outils d'apprentissage automatique automatisés qui accélèrent le développement de modèles, des systèmes d'analyse en temps réel pour une prise de décision instantanée et des cadres de gouvernance des données basés sur l'IA. Ces solutions permettent aux entreprises d'exploiter la valeur d'ensembles de données complexes tout en réduisant les obstacles techniques traditionnellement associés à l'analyse avancée.
Les organisations sont aujourd'hui confrontées à un défi sans précédent : des masses de données, mais une capacité limitée à en extraire des informations pertinentes. Le fossé entre la collecte de données et l'analyse exploitable n'a jamais été aussi grand.
Les solutions de science des données comblent ce fossé. Elles transforment les données brutes en décisions stratégiques, en avantages concurrentiels et en résultats commerciaux mesurables. Mais face à la multitude de plateformes, d'outils et de cadres disponibles, choisir les solutions les plus adaptées nécessite de comprendre ce qui fonctionnera réellement en 2026.
Ce guide examine les solutions de science des données les plus efficaces qui transforment actuellement les secteurs d'activité. De l'analyse augmentée, qui rend les données accessibles aux équipes non techniques, à l'apprentissage automatique automatisé, qui accélère les délais de déploiement, ces technologies représentent le nec plus ultra en matière d'applications pratiques.
L'évolution des solutions en science des données
La science des données a considérablement mûri depuis ses débuts, marqués par des algorithmes codés sur mesure et une ingénierie manuelle des caractéristiques. Les solutions modernes privilégient l'accessibilité, l'automatisation et l'intégration aux processus métier existants.
Ce changement reflète une évolution fondamentale dans la manière dont les organisations abordent l'analyse de données. Au lieu de s'appuyer uniquement sur des data scientists spécialisés travaillant isolément, les entreprises déploient désormais des plateformes qui favorisent la collaboration interdépartementale. Les équipes marketing exploitent des modèles prédictifs. Les équipes opérationnelles optimisent la logistique grâce à l'apprentissage automatique. Les services financiers automatisent l'évaluation des risques.
Cette démocratisation n'est pas le fruit du hasard. Les fournisseurs de technologies ont constaté que la plupart des entreprises ne pouvaient pas recruter suffisamment de spécialistes des données pour répondre à la demande.
Les normes régissant ces systèmes ont également évolué. Le référentiel NIST SP 800-181 a défini les domaines de compétences pour les métiers de la cybersécurité et des sciences des données. La version actuelle (2.2.0) a été publiée le 28 avril 2025, la révision de 2020 (NIST SP 800-181r1) ayant été publiée antérieurement. Le document NISTIR 8355 (publié en juin 2023) fournit des recommandations complémentaires sur les domaines de compétences pour la formation d'une main-d'œuvre en cybersécurité opérationnelle, en définissant des parcours plus clairs pour le développement des compétences et la mise en œuvre des technologies.

Créez des solutions de science des données grâce à une IA supérieure
IA supérieure Ils conçoivent des applications basées sur l'IA et des logiciels sur mesure utilisant des modèles d'apprentissage automatique, l'analyse de données, le traitement automatique du langage naturel (TALN), la vision par ordinateur, la BI et l'analyse de données massives. Leur expertise peut accompagner des projets depuis la phase de découverte et d'analyse des données jusqu'au développement d'un prototype, à l'intégration et à l'évaluation des résultats.
Pour les entreprises qui évaluent des solutions de science des données, cela peut aider à passer de données éparses et d'idées approximatives à des outils opérationnels qui facilitent les prévisions, l'automatisation et des décisions plus claires.
Besoin de données scientifiques conçues pour des flux de travail réels ?
AI Superior peut vous aider avec :
- création de solutions personnalisées en science des données
- développement de modèles d'apprentissage automatique et d'analyse
- Tester des idées par le biais d'une preuve de concept ou d'un développement MVP
- intégrer l'IA dans les systèmes quotidiens
👉 Contactez l'IA supérieure pour discuter de votre projet.
Analyse augmentée : rendre les données accessibles
L'analyse augmentée représente l'une des évolutions les plus marquantes de ces dernières années. Ces plateformes utilisent l'apprentissage automatique pour automatiser la préparation des données, la génération d'informations et leur interprétation — des tâches qui exigeaient traditionnellement une expertise statistique approfondie.
La proposition de valeur est simple : les utilisateurs métiers posent leurs questions en langage naturel, et le système gère la complexité technique en arrière-plan. Pas de requêtes SQL. Pas de tableaux croisés dynamiques. Pas de difficultés avec les outils de visualisation.
Mais est-ce vraiment efficace ? En pratique, oui, avec quelques réserves. L’analyse augmentée excelle dans l’analyse exploratoire et les rapports réguliers. Les responsables marketing peuvent identifier les segments de clientèle dont l’engagement est en baisse. Les analystes de la chaîne d’approvisionnement peuvent repérer les anomalies de stock. Les directeurs commerciaux peuvent prévoir les performances trimestrielles.
Selon l'analyse de Top Data Science Solutions, le marché de l'analyse augmentée devrait atteindre $102,78 milliards d'ici 2030 avec un TCAC de 28,09%. Cette croissance reflète une véritable adoption par les entreprises, et non pas seulement le battage médiatique des fournisseurs.
Principales capacités de l'analyse augmentée moderne
Les principales plateformes partagent plusieurs fonctionnalités essentielles. La préparation automatisée des données gère le nettoyage, la transformation et l'intégration des données provenant de sources multiples. Les interfaces de requête en langage naturel acceptent les questions saisies ou formulées oralement. Les moteurs de visualisation intelligents sélectionnent les types de graphiques appropriés en fonction des caractéristiques des données et du contexte analytique.
La couche explicative est sans doute la plus importante. Lorsqu'une plateforme détecte une tendance ou une anomalie, elle ne se contente pas d'afficher un graphique : elle génère un texte explicatif détaillant le changement observé, son importance et les actions à entreprendre. Ces explications rendent les données exploitables par des personnes n'ayant pas de formation en statistiques.
Soyons francs : l’analyse augmentée ne remplacera pas les analystes qualifiés de sitôt. Les enquêtes complexes, la modélisation personnalisée et l’interprétation stratégique requièrent toujours l’expertise humaine. Mais pour la plupart des tâches analytiques courantes, qui consistent en l’exploration et la production de rapports, ces plateformes permettent des gains d’efficacité considérables.
Considérations relatives à la mise en œuvre
Le déploiement réussi de l'analyse augmentée exige une attention particulière à la gouvernance des données, à la formation des utilisateurs et à l'architecture d'intégration. La plateforme doit accéder à des sources de données propres et bien structurées. Les utilisateurs doivent disposer du contexte nécessaire pour poser les bonnes questions et interpréter correctement les résultats. Les équipes informatiques doivent définir des protocoles clairs en matière de sécurité, de contrôle d'accès et de maintenance du système.
Les organisations qui considèrent l'analyse augmentée comme un simple déploiement technique rencontrent souvent des difficultés. Celles qui l'abordent comme une initiative de gestion du changement – avec le soutien de la direction, l'implication des utilisateurs et un déploiement progressif – constatent des taux d'adoption bien plus élevés.
Plateformes d'apprentissage automatique automatisées
L’apprentissage automatique automatisé (AutoML) s’attaque à un autre obstacle : le temps et l’expertise nécessaires au développement, à l’optimisation et au déploiement de modèles prédictifs. Les projets d’apprentissage automatique traditionnels impliquent un travail manuel considérable : ingénierie des caractéristiques, sélection des algorithmes, optimisation des hyperparamètres et tests de validation.
Les plateformes AutoML automatisent une grande partie de ce processus. Les data scientists définissent la variable cible et les indicateurs de performance, et le système teste différents algorithmes, combinaisons de caractéristiques et paramètres. Résultat : des modèles opérationnels en quelques heures ou jours au lieu de plusieurs semaines ou mois.
Des évaluations comparatives récentes montrent que l'écart de performance entre les plateformes commerciales basées sur les API et les alternatives open source continue de se réduire. Les performances varient selon les plateformes.
Ce que l'AutoML fait bien
L'apprentissage automatique (AutoML) excelle dans les scénarios comportant des données structurées et des objectifs de prédiction clairement définis. Prédiction du taux d'attrition client, prévision de la demande, détection des fraudes, prédiction des pannes d'équipement : ces applications impliquent généralement des données tabulaires et des résultats bien définis.
Ces plateformes gèrent automatiquement l'ingénierie des caractéristiques, en testant des transformations telles que les caractéristiques polynomiales, les termes d'interaction et les stratégies de discrétisation. Elles évaluent des dizaines, voire des centaines, de combinaisons d'algorithmes, des modèles linéaires au gradient boosting en passant par les réseaux de neurones. L'optimisation des hyperparamètres utilise des techniques comme l'optimisation bayésienne ou les algorithmes évolutionnaires pour trouver les configurations qui maximisent les performances.
Les processus de déploiement se sont considérablement améliorés. De nombreuses plateformes génèrent désormais des points de terminaison conteneurisés qui s'intègrent directement aux applications existantes. Une équipe marketing peut ainsi déployer un modèle de valeur vie client qui évalue chaque nouveau prospect en temps réel, sans nécessiter de développement spécifique.
Limites et meilleures pratiques
L'apprentissage automatique automatisé (AutoML) n'est pas magique. Il est optimal lorsque le problème est clairement défini, les données relativement propres et la relation entre les caractéristiques et la cible peut être déduite des tendances historiques. Il peine face aux situations inédites, aux environnements en constante évolution et aux tâches nécessitant une ingénierie des caractéristiques spécifique au domaine.
La critique du modèle “ boîte noire ” n'est pas dénuée de fondement. Si les plateformes modernes fournissent des scores d'importance des caractéristiques et des graphiques de dépendance partielle, il peut s'avérer difficile de comprendre précisément pourquoi un modèle effectue certaines prédictions. Les secteurs réglementés pourraient nécessiter des approches plus interprétables.
Il est recommandé d'utiliser l'apprentissage automatique pour accélérer le développement initial, puis de faire examiner, valider et éventuellement affiner les résultats par des experts. Imaginez un data scientist junior très productif qui gère les tâches routinières, permettant ainsi aux data scientists seniors de se concentrer sur les défis stratégiques.
Systèmes d'analyse en temps réel
Le traitement par lots a parfaitement répondu aux besoins analytiques pendant des décennies. Les entreprises collectaient des données tout au long de la journée, lançaient des traitements nocturnes et consultaient les tableaux de bord le lendemain matin. Ce cycle fonctionnait bien lorsque le rythme des affaires était plus lent.
Ce n'est plus le cas. Les systèmes d'analyse en temps réel traitent les données en flux continu, fournissant des informations avec une latence de l'ordre de la seconde ou de la milliseconde, et non plus de plusieurs heures. Les sociétés de services financiers détectent les transactions frauduleuses avant leur règlement. Les plateformes de commerce électronique adaptent leurs recommandations en fonction du comportement de navigation. Les usines de fabrication identifient les problèmes de qualité avant que les produits défectueux ne quittent la chaîne de production.
L'architecture technique diffère sensiblement des systèmes de traitement par lots traditionnels. Des moteurs de traitement de flux comme Apache Kafka et Apache Flink, ainsi que des services natifs du cloud, gèrent l'ingestion et la transformation des données. Des bases de données en mémoire stockent l'état actuel pour des requêtes instantanées. Les architectures événementielles déclenchent automatiquement des actions lorsque les conditions sont remplies.
Cas d'utilisation favorisant l'adoption
Plusieurs catégories d'applications favorisent l'adoption de l'analyse en temps réel. La détection des fraudes exige une évaluation immédiate des transactions par rapport aux schémas comportementaux ; un retard de quelques minutes seulement peut permettre la validation d'achats frauduleux. Les systèmes de trading algorithmique prennent des décisions d'achat/vente en microsecondes à partir de flux de données de marché et de modèles prédictifs.
La supervision opérationnelle utilise l'analyse en temps réel pour suivre l'état du système, les performances des applications et les indicateurs d'infrastructure. Les équipes informatiques identifient et résolvent les problèmes avant qu'ils n'affectent les utilisateurs. Les processus DevOps intègrent la supervision continue dans les pipelines de déploiement.
Les moteurs de personnalisation mettent à jour instantanément les recommandations en fonction du comportement actuel. Un client consultant des manteaux d'hiver voit des accessoires pertinents. Un lecteur terminant un article reçoit des suggestions correspondant à ses centres d'intérêt. Pour une expérience utilisateur optimale, une latence inférieure à la seconde est indispensable.
Complexité de la mise en œuvre
Les systèmes d'analyse en temps réel sont nettement plus complexes que les systèmes par lots. L'architecture distribuée soulève des défis en matière de cohérence des données, de tolérance aux pannes et de surveillance opérationnelle. Les équipes doivent posséder une expertise dans les frameworks de traitement de flux, la conception de systèmes distribués et l'optimisation des performances.
Les structures de coûts diffèrent également. Les systèmes temps réel nécessitent des ressources de calcul et de stockage continues, et non pas seulement pendant les phases de traitement par lots. Les fournisseurs de cloud proposent des services gérés qui simplifient le déploiement, mais facturent le débit soutenu. Les organisations doivent évaluer avec soin si leurs cas d'utilisation spécifiques justifient la complexité et les dépenses supplémentaires.
Cela dit, le seuil de “ temps réel ” varie selon l'application. Tous les cas d'utilisation n'exigent pas une latence de l'ordre de la milliseconde. De nombreux scénarios métier fonctionnent parfaitement avec un traitement “ quasi temps réel ” qui fournit des résultats en 30 secondes ou quelques minutes. Il est souvent plus judicieux de commencer par des architectures plus simples et d'ajouter de la complexité au fur et à mesure des besoins plutôt que de concevoir dès le départ une solution répondant à des exigences de performance extrêmes.
Solutions de gouvernance des données basées sur l'IA
La gouvernance des données peut paraître ennuyeuse jusqu'à ce qu'on soit confronté aux conséquences d'une mauvaise qualité des données, d'une propriété floue ou de violations de la conformité. Face à l'augmentation constante du volume et de la complexité des données, les organisations peinent à maintenir leurs catalogues de données, à appliquer les politiques d'accès, à assurer la traçabilité et à garantir la conformité réglementaire.
Les solutions de gouvernance basées sur l'IA automatisent de nombreuses tâches traditionnellement manuelles. L'apprentissage automatique classe les données, identifie les informations sensibles, recommande des balises de métadonnées et détecte les anomalies dans les habitudes d'utilisation. Le traitement automatique du langage naturel extrait le sens de la documentation et suggère des améliorations aux définitions de données.
Les progrès récents en matière d'algorithmes d'équité démontrent leur potentiel. Des recherches montrent une réduction des biais du modèle 30%, évaluée par des ajustements d'équité indépendants du domaine et applicables à différents ensembles de données, du secteur bancaire au jugement médical. Ces techniques aident les organisations à identifier et à atténuer les biais algorithmiques avant la mise en production des modèles.
Capacités de gouvernance de base
Les plateformes de gouvernance modernes offrent plusieurs fonctions essentielles. La découverte automatisée des données explore les référentiels, les bases de données et les systèmes de fichiers afin de créer des catalogues exhaustifs des ressources de données disponibles. Les moteurs de classification attribuent aux données des étiquettes selon leur niveau de sensibilité, leur domaine d'activité et leurs indicateurs de qualité.
Le suivi de la lignée permet de suivre les données de leur source à leur utilisation finale, en passant par leurs transformations. Lorsqu'un rapport affiche des valeurs inattendues, les analystes peuvent remonter le flux de données pour identifier l'origine des problèmes. Si les auditeurs réglementaires demandent le détail des calculs, la documentation disponible explique l'intégralité du processus.
L'automatisation du contrôle d'accès applique des politiques basées sur la classification des données, les rôles des utilisateurs et le contexte. Le personnel marketing peut accéder aux coordonnées des clients, mais pas à leurs informations de paiement. Les analystes de certaines régions visualisent uniquement les données pertinentes pour leur zone géographique. Les prestataires bénéficient d'autorisations limitées qui expirent automatiquement.
Respect des exigences réglementaires
Les cadres réglementaires tels que le RGPD, le CCPA et l'HIPAA imposent des exigences spécifiques en matière de traitement, de conservation et de droits des données. Les plateformes de gouvernance aident les organisations à respecter ces obligations grâce à la détection automatisée des informations personnelles, au suivi du consentement et à la facilitation des demandes de suppression.
Le cadre de référence NIST pour le Big Data, finalisé en 2019, fournit des recommandations architecturales aux organisations développant des capacités d'analyse à grande échelle. Il aborde les aspects liés à la sécurité, à la confidentialité et à la gouvernance, ainsi que les modèles de mise en œuvre technique. Les organisations peuvent s'appuyer sur ce cadre lors de la conception de programmes de gouvernance favorisant la conformité réglementaire et la réalisation des objectifs commerciaux.
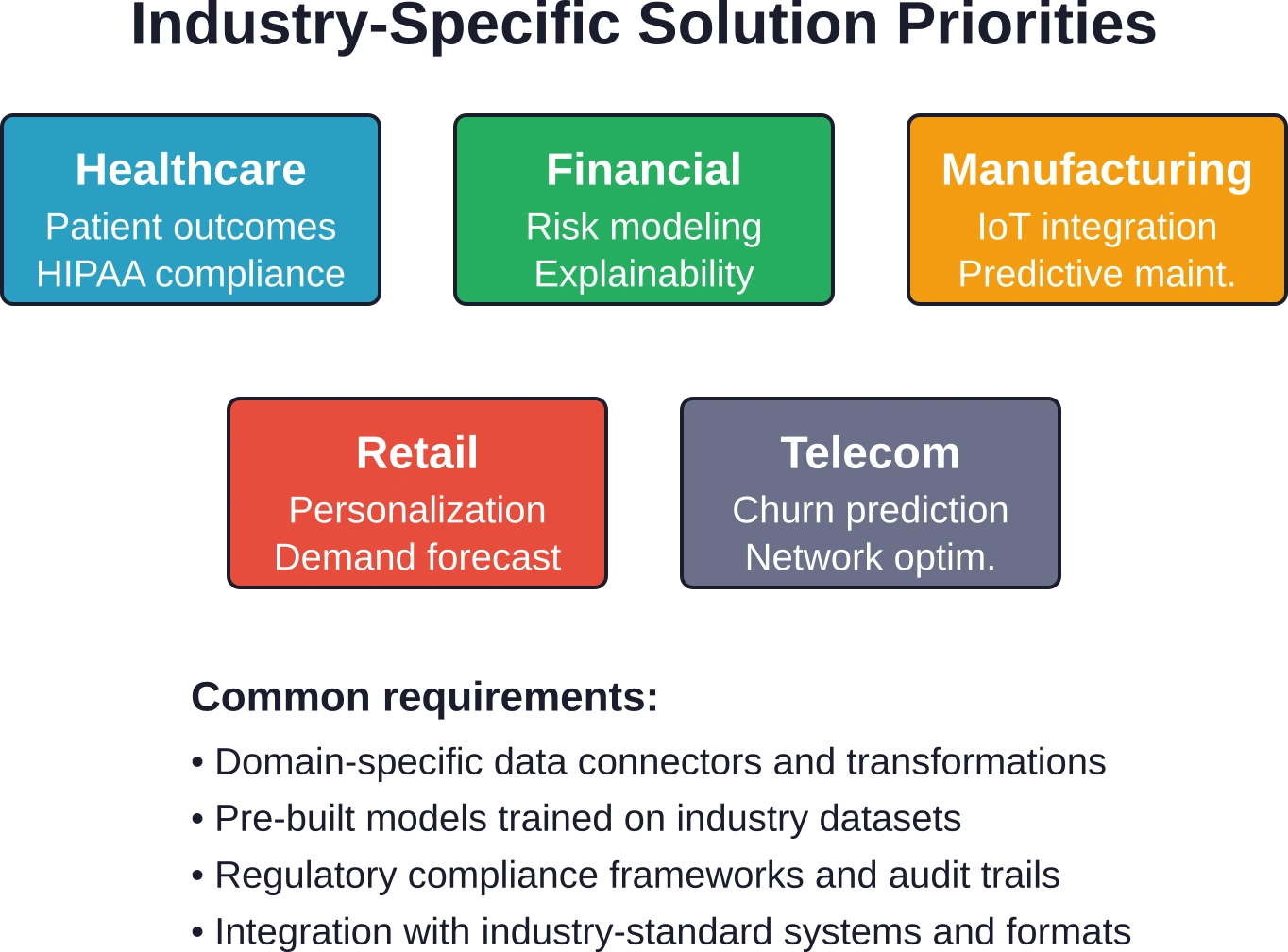
Solutions spécialisées pour les industries clés
Si les plateformes généralistes répondent à de nombreux besoins, certains secteurs bénéficient de solutions de science des données spécialisées, adaptées aux défis spécifiques à chaque domaine et aux exigences réglementaires.
Analyse des soins de santé
Les organismes de santé doivent prendre des décisions complexes et cruciales concernant les soins aux patients, l'allocation des ressources et la gestion de la santé des populations. Des plateformes spécialisées s'intègrent aux dossiers médicaux électroniques, aux systèmes d'imagerie médicale et aux bases de données de remboursement.
Les modèles prédictifs identifient les patients à risque de réadmission, d'aggravation de leur état ou de non-observance thérapeutique. L'analyse des données de santé populationnelle segmente les populations de patients et recommande des interventions ciblées. Les systèmes d'aide à la décision clinique fournissent des recommandations fondées sur des données probantes au chevet du patient.
Le respect des réglementations demeure essentiel. Les exigences de la loi HIPAA régissent l'accès aux données, leur dépersonnalisation et la notification des violations de données. Les recommandations de la FDA s'appliquent aux outils d'aide à la décision clinique qui correspondent à la définition des dispositifs médicaux. Les plateformes dédiées au secteur de la santé intègrent ces considérations dès leur conception, au lieu de considérer la conformité comme une simple formalité.
Services financiers
Les banques, les compagnies d'assurance et les sociétés d'investissement ont été pionnières dans de nombreuses techniques d'analyse de données. Les plateformes spécialisées actuelles prennent en charge la modélisation des risques, le reporting réglementaire, la détection des fraudes et le trading algorithmique, avec des fonctionnalités spécifiques au secteur financier.
Les outils de gestion des risques liés aux modèles aident les organisations à se conformer aux exigences réglementaires en matière de validation, de documentation et de suivi continu des modèles. Les outils d'explicabilité génèrent des pistes d'audit répondant aux exigences des examinateurs. Les cadres de tests de résistance évaluent la performance des modèles dans des situations défavorables.
La complexité des données financières — fuseaux horaires multiples, opérations sur titres, conventions de marché variées — confère une grande valeur aux solutions spécialisées. Les plateformes génériques nécessitent une personnalisation poussée pour gérer correctement ces spécificités.
Production et chaîne d'approvisionnement
Les fabricants utilisent la science des données pour la prédiction de la qualité, la maintenance prédictive, la prévision de la demande et l'optimisation de la chaîne d'approvisionnement. Des solutions spécialisées s'intègrent aux capteurs IoT industriels, aux systèmes d'exécution de la production et aux plateformes de planification des ressources de l'entreprise.
Les modèles de maintenance prédictive analysent les données des capteurs pour anticiper les pannes d'équipement avant qu'elles ne surviennent, permettant ainsi une maintenance planifiée lors des arrêts programmés plutôt que des réparations d'urgence en pleine production. La prédiction de la qualité identifie les conditions de processus à l'origine des défauts, permettant des ajustements en temps réel.
L'analyse de la chaîne d'approvisionnement optimise les niveaux de stock, les itinéraires de transport et les calendriers de production au sein de réseaux complexes de fournisseurs, d'installations et de clients. Les recherches montrent que les agents autonomes voient leurs performances se dégrader progressivement sur les tâches nécessitant plus de 10 secondes de temps d'exécution, soulignant ainsi l'importance d'algorithmes optimisés pour les décisions en temps réel concernant la chaîne d'approvisionnement.
Tendances émergentes qui façonnent les solutions en science des données
Plusieurs évolutions transforment la manière dont les organisations abordent la mise en œuvre de la science des données. Comprendre ces tendances facilite la planification stratégique et le choix des technologies.
Intégration multimodale de l'IA
L'analyse de données traditionnelle se concentrait principalement sur les données structurées : nombres, catégories, horodatages. Les plateformes modernes gèrent de plus en plus de modalités de données multiples : texte, images, vidéo, audio, flux de capteurs.
Des recherches récentes sur NeuroFusion démontrent une amélioration de 34% par rapport aux benchmarks multimodaux existants dans le traitement multimodal en temps réel. Ces systèmes traitent simultanément des données en direct provenant d'appels vidéo, d'environnements de réalité augmentée et d'appareils IoT, permettant une analyse plus riche que les approches monomodales.
Les applications du secteur de la santé associent l'imagerie médicale aux dossiers médicaux électroniques et aux notes cliniques. Les systèmes de vente au détail analysent conjointement les images des produits, les avis clients et les données transactionnelles. Les solutions de fabrication intègrent les relevés de capteurs, les images d'inspection visuelle et les journaux de maintenance.
Flux de travail automatisés en science des données
La tendance à l'automatisation s'étend au-delà des tâches individuelles pour englober des flux de travail analytiques complets. Les plateformes modernes orchestrent des séquences complexes : ingestion des données, validation de la qualité, ingénierie des caractéristiques, entraînement des modèles, évaluation, déploiement et surveillance.
Ces flux de travail de bout en bout réduisent les interventions manuelles nécessaires pour passer des données brutes aux modèles de production. Les organisations qui avaient auparavant besoin de plusieurs semaines pour déployer un nouveau modèle peuvent désormais réaliser ce même processus en quelques jours, voire quelques heures. Cette itération plus rapide favorise l'expérimentation et une meilleure adaptation aux évolutions de la situation.
HardML, un outil d'évaluation des connaissances en science des données et en apprentissage automatique, comprend 100 questions à choix multiples difficiles couvrant divers domaines, notamment l'apprentissage profond, l'apprentissage automatique classique, le traitement du langage naturel, la vision par ordinateur, l'ingénierie des données et les statistiques. Les plateformes performantes sur cette large gamme de domaines démontrent une applicabilité plus large que celles optimisées pour des cas d'utilisation étroits.
Edge Analytics
L'analyse des données ne se limite pas aux centres de données centralisés ou aux environnements cloud. L'analyse en périphérie traite les données sur les appareils situés à la périphérie du réseau : smartphones, capteurs IoT, véhicules autonomes, équipements industriels.
Cette approche présente plusieurs avantages. La latence diminue considérablement grâce au traitement local, évitant ainsi les allers-retours vers des serveurs distants. Les coûts de bande passante sont réduits puisque les données brutes n'ont plus besoin d'être transmises. La confidentialité est renforcée car les informations sensibles peuvent être traitées et agrégées directement sur l'appareil, sans être envoyées à des systèmes externes.
Le déploiement en périphérie de réseau impose des contraintes. Les ressources de calcul limitées nécessitent des modèles optimisés. La connectivité intermittente exige une gestion robuste des périodes d'indisponibilité. La diversité des appareils complexifie le déploiement et la maintenance. Les plateformes spécialisées relèvent ces défis grâce à la compression des modèles, l'apprentissage fédéré et les mises à jour à distance.
Choisir les bonnes solutions en science des données
Face à la multitude de plateformes et d'outils disponibles, le choix peut s'avérer complexe. Une démarche d'évaluation structurée permet d'identifier les solutions les mieux adaptées aux besoins spécifiques de l'organisation.
Définir des objectifs clairs
Commencez par définir clairement les problèmes commerciaux à résoudre. “ Mettre en œuvre la science des données ” n’est pas un objectif, mais une capacité. “ Réduire le taux d’attrition client de 151 000 $ ” ou “ Diminuer les coûts de stockage de 201 000 $ ” sont des objectifs mesurables qui orientent le choix technologique.
Des objectifs différents nécessitent des solutions différentes. L'analyse exploratoire et les tableaux de bord de direction suggèrent des plateformes d'analyse augmentée. Le déploiement à grande échelle du ML en production indique le recours à des outils d'AutoML ou de MLOps. Les exigences de conformité réglementaire orientent vers des solutions de gouvernance.
Évaluer les capacités organisationnelles
Une évaluation objective des compétences, des ressources et des processus internes permet d'éviter les décalages entre la sophistication des solutions et la capacité de l'organisation à les mettre en œuvre. Une plateforme exigeant une expertise DevOps pointue ne pourra pas fonctionner dans une organisation aux ressources techniques limitées. À l'inverse, des outils trop simplistes risquent de décourager les équipes aux compétences avancées.
Prenons l'exemple du modèle de maturité en science des données. Les organisations qui débutent dans l'analyse de données ont besoin d'outils différents de celles qui ont des pratiques bien établies. Les plateformes low-code permettent aux équipes moins expérimentées d'obtenir plus rapidement des résultats concrets. Les frameworks avancés offrent une plus grande flexibilité aux utilisateurs avertis.
Évaluer les exigences d'intégration
Les solutions de science des données fonctionnent rarement de manière isolée. Elles doivent se connecter aux sources de données existantes, aux applications métier et aux systèmes de flux de travail. La complexité de l'intégration a un impact significatif sur les délais de mise en œuvre et la charge de maintenance continue.
Vérifiez la présence de connecteurs natifs pour vos bases de données, applications SaaS et entrepôts de données. Évaluez les capacités des API pour les intégrations personnalisées. Tenez compte des protocoles d'authentification et de sécurité. Les organisations disposant d'environnements techniques complexes devraient privilégier les plateformes dotées de frameworks d'intégration robustes.
| Critère d'évaluation | Questions à poser | Impact sur la sélection |
|---|---|---|
| Objectifs commerciaux | Quels sont les résultats précis qui motivent cet investissement ? | Détermine la catégorie de solution nécessaire |
| Compétences techniques | Quelles sont les compétences disponibles en interne aujourd'hui ? | Influence le niveau de complexité réalisable |
| Environnement de données | Où se trouvent actuellement les données pertinentes ? | Affecte les efforts d'intégration et l'architecture |
| Exigences d'échelle | Quels volumes de données et quel nombre d'utilisateurs sont prévus ? | décisions relatives à l'infrastructure et aux licences des guides |
| Besoins de conformité | Quelles sont les exigences réglementaires applicables ? | Peut nécessiter des plateformes spécifiques à l'industrie ou certifiées |
Effectuer des tests de validation de concept
Les démonstrations des fournisseurs présentent des scénarios idéalisés avec des données propres et des cas d'utilisation simples. Le déploiement en conditions réelles révèle souvent des complications. Les tests de validation de concept avec les données réelles de l'organisation offrent une évaluation bien plus fiable.
Définissez des critères de réussite précis avant de commencer. La plateforme peut-elle ingérer et traiter vos formats de données ? Offre-t-elle des performances acceptables à une échelle réaliste ? Les utilisateurs finaux peuvent-ils l’utiliser sans formation approfondie ? S’intègre-t-elle facilement à vos systèmes existants ?
Limitez la durée de l'évaluation (généralement de 4 à 8 semaines) à des livrables clairement définis. Une preuve de concept qui s'éternise pendant des mois sans produire de résultats concrets indique probablement des problèmes de compatibilité fondamentaux.
Meilleures pratiques de mise en œuvre
Le choix de la technologie n'est que le point de départ. Une mise en œuvre réussie exige de prendre en compte le changement organisationnel, l'adoption par les utilisateurs et les processus opérationnels.
Commencez petit, augmentez progressivement
La tentation de s'attaquer d'emblée au cas d'usage le plus complexe et à plus forte valeur ajoutée est compréhensible, mais généralement contre-productive. Les projets complexes présentent davantage de risques d'échec et des délais plus longs. Commencer par un cas d'usage plus restreint et bien défini permet à l'équipe de se familiariser avec la plateforme, de mettre en place des processus et de démontrer sa valeur ajoutée avant de s'attaquer à des défis plus importants.
Choisissez des projets initiaux à forte valeur ajoutée, au périmètre maîtrisable et aux données accessibles. Le succès engendre une dynamique positive et renforce la confiance au sein de l'organisation. Les premiers succès créent des ambassadeurs qui contribuent à une adoption plus large.
Investissez dans la formation des utilisateurs
Même les plateformes les plus intuitives nécessitent un apprentissage. Les organisations qui considèrent la formation comme facultative constatent systématiquement un taux d'adoption plus faible et des résultats moins bons que celles qui investissent dans une formation structurée.
Concevoir des programmes de formation adaptés aux différents rôles des utilisateurs. Les cadres dirigeants ont besoin d'un contexte stratégique et de compétences de haut niveau. Les analystes fonctionnels requièrent une pratique concrète des flux de travail spécifiques. Le personnel informatique a besoin de comprendre l'architecture et les procédures opérationnelles.
La formation juste à temps — dispensée lorsque les utilisateurs sont prêts à appliquer leurs nouvelles compétences — s'avère généralement plus efficace que les sessions de formation génériques organisées des mois avant l'utilisation réelle.
Mettre en place une gouvernance dès le début
La démocratisation de la science des données engendre de nouveaux risques liés à la qualité des données, à la validité des modèles et à la prise de décision. Les cadres de gouvernance offrent des garde-fous sans entraver l'innovation.
Définir des politiques claires pour l'accès aux données, le développement des modèles, les approbations de déploiement et le suivi continu. Mettre en place des processus d'examen qui allient rigueur et rapidité. Créer des normes de documentation qui rendent le travail reproductible et maintenable.
Les organisations qui mettent en œuvre la gouvernance de manière réactive — après l'apparition des problèmes — sont confrontées à des discussions plus difficiles et à des changements plus perturbateurs que celles qui établissent des cadres de manière proactive.
Mesurer le succès et le retour sur investissement
Les investissements en science des données doivent générer une valeur commerciale mesurable. La définition et le suivi d'indicateurs pertinents garantissent la responsabilisation et orientent l'amélioration continue.
Indicateurs de résultats commerciaux
Les mesures les plus importantes sont directement liées aux objectifs commerciaux. Si l'objectif est de réduire le taux d'attrition client, il convient de le suivre avant et après la mise en œuvre. Pour optimiser les stocks, il faut mesurer les coûts de stockage et la fréquence des ruptures de stock. Croissance du chiffre d'affaires, réduction des coûts, satisfaction client : ce sont ces résultats qui comptent le plus.
L'attribution des résultats peut s'avérer complexe. Les performances commerciales ont rarement une cause unique. Il est donc essentiel d'établir des données de référence avant la mise en œuvre, de contrôler les facteurs externes autant que possible et de faire preuve de transparence quant à l'incertitude des estimations d'impact.
Indicateurs opérationnels
L'amélioration des processus représente une autre source de valeur. Combien de temps l'équipe d'analystes gagne-t-elle grâce à la préparation automatisée des données ? Combien de modèles supplémentaires sont déployés chaque trimestre ? Avec quelle rapidité les utilisateurs métiers obtiennent-ils des réponses à leurs questions analytiques ?
Ces gains d'efficacité n'apparaissent peut-être pas directement dans les états financiers, mais ils libèrent des ressources pour des tâches à plus forte valeur ajoutée et accélèrent les cycles de prise de décision.
Indicateurs d'adoption
Une technologie inutilisée ne génère aucune valeur. Suivez les utilisateurs actifs, le volume de requêtes, les modèles en production et autres indicateurs d'utilisation. Un faible taux d'adoption révèle des lacunes en matière de formation, des problèmes d'ergonomie ou une inadéquation avec les besoins réels.
Interrogez régulièrement les utilisateurs sur leur satisfaction, les points faibles rencontrés et leurs demandes de fonctionnalités. Les retours qualitatifs révèlent souvent des pistes d'amélioration que les indicateurs quantitatifs ne permettent pas de déceler.
Défis courants de mise en œuvre
Comprendre les obstacles typiques aide les organisations à planifier des stratégies d'atténuation plutôt que d'être surprises par des problèmes évitables.
Qualité et accessibilité des données
Les organisations sous-estiment systématiquement les difficultés liées à la préparation des données. Systèmes hérités aux formats incohérents. Valeurs manquantes et erreurs de saisie. Définitions imprécises et transformations non documentées. Sources de données cloisonnées aux schémas incompatibles.
Les plateformes de science des données ne peuvent pas corriger des données fondamentalement erronées. Il est essentiel de consacrer du temps et des ressources à l'amélioration de la qualité des données dès la planification de la mise en œuvre. Définissez des indicateurs de qualité des données et une responsabilité claire. En cas de problèmes généralisés, envisagez des initiatives de gestion des données de référence.
Lacunes en matière de compétences
Même les plateformes low-code exigent une pensée analytique et une connaissance approfondie du domaine. Les organisations constatent souvent que la démocratisation de l'accès aux outils ne crée pas automatiquement une culture de la prise de décision fondée sur les données.
Comblez les lacunes en compétences par la formation, le recrutement ou les partenariats. Envisagez d'intégrer des experts en science des données au sein des unités opérationnelles pour les conseiller et les accompagner. Créez des communautés de pratique où les utilisateurs partagent leurs connaissances et leurs bonnes pratiques.
Complexité de l'intégration
Ce qui paraissait simple lors de la validation de concept se complexifie souvent en production. Les exigences de sécurité restreignent l'accès au réseau. Les politiques de gouvernance des données imposent des procédures d'approbation. Les applications existantes sont dépourvues d'API. Les performances se dégradent en production.
Impliquez les équipes informatiques et de sécurité dès le début de la planification. Prévoyez un délai suffisant pour l'intégration. Effectuez des tests à une échelle réaliste avant la mise en production. Anticipez les problèmes techniques imprévus.
Orientations futures
Plusieurs évolutions à l'horizon façonneront les solutions en science des données dans les années à venir.
Automatisation accrue
L'automatisation s'étendra à des tâches qui requièrent actuellement un jugement humain. L'AutoML évoluera vers l'AutoDS, une science des données automatisée couvrant l'intégralité du cycle de vie, de la définition du problème au déploiement et à la surveillance. Les organisations spécifieront leurs objectifs et contraintes métier, et les systèmes proposeront des approches analytiques, les exécuteront et mesureront les résultats.
Cela n'élimine pas l'intervention humaine, mais déplace l'attention vers les décisions stratégiques, l'interprétation et la gouvernance plutôt que vers l'exécution technique.
Meilleure explicabilité
Les pressions réglementaires et les préoccupations éthiques alimentent la demande de modèles plus interprétables. Les prédictions opaques sont de moins en moins acceptables dans des domaines à forts enjeux comme la santé, la finance et la justice pénale.
La recherche continue d'améliorer les techniques d'explication applicables aux modèles complexes. Les explications contrefactuelles montrent les éléments qui devraient être modifiés pour obtenir une prédiction différente. Les fonctions d'influence identifient les exemples d'entraînement qui ont le plus affecté une prédiction spécifique. Les mécanismes d'attention révèlent les entrées sur lesquelles le modèle se concentre.
Les plateformes intégreront nativement ces techniques, faisant de l'explicabilité une fonctionnalité standard plutôt qu'un module complémentaire spécialisé.
Apprentissage distribué et fédéré
Les réglementations relatives à la protection de la vie privée et aux exigences en matière de souveraineté des données compliquent l'agrégation centralisée des données. L'apprentissage fédéré permet d'entraîner des modèles sur des ensembles de données distribués sans déplacer les données sous-jacentes.
Les organismes de santé peuvent collaborer au développement de modèles sans partager les dossiers des patients. Les institutions financières peuvent améliorer la détection des fraudes grâce à l'intelligence collective tout en préservant la confidentialité des données transactionnelles. Les fabricants peuvent comparer leurs performances à celles de leurs concurrents sans divulguer d'informations confidentielles.
Ce changement architectural nécessite de nouveaux outils, mais il permet de surmonter les obstacles fondamentaux à l'analyse collaborative dans les domaines sensibles à la protection de la vie privée.
Questions fréquemment posées
Quelle est la différence entre les plateformes de science des données et les outils de veille stratégique ?
Les outils de veille stratégique se concentrent principalement sur la création de rapports et la visualisation des données historiques. Les plateformes de science des données, quant à elles, privilégient la modélisation prédictive, l'apprentissage automatique et l'analyse avancée. Si les solutions modernes estompent de plus en plus ces frontières, les outils de veille stratégique visent généralement l'analyse descriptive, tandis que les plateformes de science des données offrent des capacités prédictives et prescriptives.
Combien coûte la mise en œuvre de solutions de science des données ?
Les coûts varient énormément selon la plateforme choisie, l'échelle du déploiement et les besoins de l'organisation. Les services gérés dans le cloud facturent généralement à l'usage : heures de calcul, données traitées, appels d'API. Les licences pour entreprises coûtent de plusieurs dizaines de milliers à plusieurs millions de dollars par an. Les solutions open source impliquent des coûts d'infrastructure et de personnel plutôt que des frais de licence. Consultez les sites web officiels des fournisseurs pour connaître les tarifs en vigueur, car les modèles évoluent fréquemment.
Faut-il embaucher des data scientists pour utiliser ces plateformes ?
Cela dépend de la plateforme et de vos objectifs. Les plateformes d'analyse augmentée low-code permettent aux utilisateurs métiers d'effectuer de nombreuses analyses sans compétences en programmation. Les outils d'apprentissage automatique (AutoML) réduisent l'expertise spécialisée nécessaire au développement de modèles. Cependant, les projets complexes, les solutions personnalisées et les déploiements en production bénéficient généralement de l'expertise de data scientists chevronnés. De nombreuses organisations adoptent une approche hybride : elles autonomisent les utilisateurs métiers pour les tâches courantes tout en conservant une équipe spécialisée pour les projets de pointe.
Combien de temps faut-il pour constater les résultats des investissements dans la science des données ?
Le calendrier varie selon l'envergure du projet et la capacité de l'organisation à le mettre en œuvre. Des cas d'utilisation simples, avec des données claires et accessibles, peuvent donner des résultats en quelques semaines. Les implémentations complexes impliquant plusieurs systèmes, des développements spécifiques ou des changements organisationnels importants peuvent nécessiter de 6 à 12 mois avant de générer une valeur ajoutée significative. Commencer par des projets pilotes de plus petite envergure permet de démontrer plus rapidement la valeur ajoutée et de créer une dynamique positive pour les initiatives plus importantes.
Quels secteurs tirent le plus grand profit des solutions issues de la science des données ?
Presque tous les secteurs tirent profit de la science des données, mais certains en subissent un impact particulièrement important. Les services financiers utilisent l'analyse avancée pour l'évaluation des risques, la détection des fraudes et le trading algorithmique. Le secteur de la santé applique des modèles prédictifs aux soins aux patients, à l'efficacité opérationnelle et à la découverte de médicaments. Le commerce de détail exploite la science des données pour la personnalisation, la prévision de la demande et l'optimisation de la chaîne d'approvisionnement. Le secteur manufacturier utilise la maintenance prédictive et le contrôle qualité. Les télécommunications utilisent la prévision du taux de désabonnement et l'optimisation du réseau.
Comment garantir que nos initiatives en matière de science des données sont conformes à la réglementation ?
La conformité exige une attention particulière à la gestion des données, à la gouvernance des modèles et à la documentation. Utilisez des plateformes intégrant des fonctionnalités de conformité adaptées à votre secteur : HIPAA pour la santé, SOC 2 pour les services financiers et RGPD pour les opérations en Europe. Mettez en œuvre des cadres de gouvernance des données permettant de suivre la traçabilité, de contrôler les accès et de conserver les pistes d’audit. Documentez les processus de développement, de validation et de surveillance des modèles. Impliquez les équipes juridiques et de conformité dès les premières étapes de la planification du projet. Envisagez des plateformes de gouvernance spécialisées si les exigences réglementaires sont importantes.
Les solutions de science des données sont-elles compatibles avec nos systèmes existants ?
La plupart des plateformes modernes offrent des fonctionnalités d'intégration étendues grâce à des connecteurs prédéfinis, des API et des outils d'import/export de données. Vérifiez que la plateforme envisagée prend en charge nativement vos bases de données, entrepôts de données, applications métier et formats de fichiers spécifiques. La complexité de l'intégration varie considérablement : les solutions cloud se connectent généralement plus facilement à d'autres services cloud, tandis que les déploiements sur site peuvent nécessiter un middleware personnalisé. Évaluez les exigences d'intégration lors du choix de la plateforme plutôt que de découvrir des problèmes de compatibilité après coup.
Conclusion : Développer des capacités axées sur les données
Les solutions de science des données sont passées du statut de technologies expérimentales à celui d'infrastructures essentielles pour les entreprises. Aujourd'hui, les organisations de tous les secteurs dépendent de ces plateformes pour rester compétitives, optimiser leurs opérations et mieux servir leurs clients.
Les implémentations les plus réussies présentent des caractéristiques communes. Elles privilégient des objectifs commerciaux clairs plutôt qu'une approche technologique pour elle-même. Elles adaptent la sophistication de la solution aux capacités et à la maturité de l'organisation. Elles investissent dans la qualité des données, la formation des utilisateurs et les cadres de gouvernance parallèlement au déploiement technologique. Elles mesurent rigoureusement les résultats et procèdent à des ajustements en fonction des données recueillies.
Aucune plateforme n'est universelle et ne convient à toutes les organisations. La “ meilleure ” solution dépend des besoins, contraintes et objectifs spécifiques. Les plateformes d'analyse augmentée démocratisent l'accès aux informations, mais ne remplacent pas une expertise analytique pointue. L'AutoML accélère le développement de modèles, mais exige des données de qualité et des problèmes bien définis. Les systèmes en temps réel permettent une action immédiate, mais complexifient les opérations. Les solutions sectorielles spécialisées répondent à des exigences spécifiques, mais peuvent s'avérer plus coûteuses que les plateformes généralistes.
Le paysage de la science des données continue d'évoluer rapidement. De nouvelles capacités émergent. Les performances s'améliorent. Les prix fluctuent. Les organisations qui établissent des critères d'évaluation clairs, effectuent des tests approfondis et restent flexibles quant aux choix technologiques se positionnent pour s'adapter à l'évolution du domaine.
Prêt à transformer l'utilisation des données au sein de votre organisation ? Commencez par identifier un cas d'usage à forte valeur ajoutée, avec des données accessibles et des indicateurs de performance clairs. Évaluez les plateformes adaptées à votre environnement technique et à votre niveau de compétences. Réalisez des tests pratiques avec des données réelles. Développez ensuite votre solution.
L'avantage concurrentiel revient de plus en plus aux organisations qui transforment les données en actions plus rapidement et plus efficacement que leurs concurrents. Les solutions de science des données fournissent les outils nécessaires, mais le succès exige un engagement envers le changement organisationnel, l'apprentissage continu et la prise de décision fondée sur des données probantes.