Kurzzusammenfassung: Zu den führenden Data-Science-Lösungen im Jahr 2026 zählen Augmented-Analytics-Plattformen, die Erkenntnisse unternehmensweit zugänglich machen, automatisierte Machine-Learning-Tools, die die Modellentwicklung beschleunigen, Echtzeit-Analysesysteme für sofortige Entscheidungen sowie KI-gestützte Data-Governance-Frameworks. Diese Lösungen ermöglichen es Unternehmen, aus komplexen Datensätzen Mehrwert zu generieren und gleichzeitig die technischen Hürden zu senken, die traditionell mit fortgeschrittenen Analysen verbunden sind.
Organisationen stehen heute vor einer beispiellosen Herausforderung: riesige Datenmengen, aber nur begrenzte Möglichkeiten, daraus sinnvolle Erkenntnisse zu gewinnen. Die Kluft zwischen Datenerfassung und handlungsrelevanten Informationen war noch nie so groß.
Data-Science-Lösungen schließen diese Lücke. Sie wandeln Rohdaten in strategische Entscheidungen, Wettbewerbsvorteile und messbare Geschäftsergebnisse um. Angesichts Hunderter verfügbarer Plattformen, Tools und Frameworks erfordert die Auswahl der richtigen Lösungen jedoch ein Verständnis dafür, was im Jahr 2026 tatsächlich funktioniert.
Dieser Leitfaden untersucht die effektivsten Data-Science-Lösungen, die derzeit ganze Branchen revolutionieren. Von erweiterter Analytik, die Daten auch für Teams ohne technische Vorkenntnisse zugänglich macht, bis hin zu automatisiertem maschinellem Lernen, das die Implementierungszeiten verkürzt – diese Technologien repräsentieren den neuesten Stand der praktischen Anwendung.
Die Evolution von Data-Science-Lösungen
Die Datenwissenschaft hat sich seit ihren Anfängen mit individuell programmierten Algorithmen und manueller Merkmalsentwicklung deutlich weiterentwickelt. Moderne Lösungen legen Wert auf Zugänglichkeit, Automatisierung und Integration in bestehende Geschäftsprozesse.
Dieser Wandel spiegelt einen grundlegenden Umbruch im Umgang von Unternehmen mit Analysen wider. Anstatt sich ausschließlich auf spezialisierte, isoliert arbeitende Data Scientists zu verlassen, setzen Unternehmen heute Plattformen ein, die die abteilungsübergreifende Zusammenarbeit ermöglichen. Marketingteams nutzen prädiktive Modelle. Mitarbeiter im operativen Bereich optimieren die Logistik mithilfe von maschinellem Lernen. Finanzabteilungen automatisieren die Risikobewertung.
Diese Demokratisierung geschah nicht zufällig. Technologieanbieter erkannten, dass die meisten Unternehmen nicht genügend Datenwissenschaftler einstellen konnten, um die Nachfrage zu decken.
Die Standards für diese Systeme haben sich ebenfalls weiterentwickelt. Das NIST SP 800-181-Framework definierte Kompetenzbereiche für Cybersicherheit und Data Science. Die aktuelle Version (2.2.0) wurde am 28. April 2025 veröffentlicht, die Revision von 2020 (NIST SP 800-181r1) erschien bereits zuvor für diese Bereiche. NISTIR 8355 (veröffentlicht im Juni 2023) bietet ergänzende Leitlinien zu Kompetenzbereichen für die Qualifizierung von Cybersicherheitsexperten und schafft klarere Wege für die Personalentwicklung und die Implementierung von Technologien.

Erstellen Sie Data-Science-Lösungen mit überlegener KI
AI Superior Sie entwickeln KI-basierte Anwendungen und kundenspezifische Softwareprodukte mithilfe von Modellen des maschinellen Lernens, Datenanalyse, NLP, Computer Vision, Business Intelligence und Big-Data-Analysen. Ihre Arbeit kann Projekte von der Recherche und Datenprüfung bis zur MVP-Entwicklung, Integration und Ergebnisevaluierung unterstützen.
Für Unternehmen, die Data-Science-Lösungen prüfen, kann dies dazu beitragen, von verstreuten Daten und vagen Ideen zu funktionierenden Werkzeugen zu gelangen, die Prognosen, Automatisierung und klarere Entscheidungen unterstützen.
Benötigen Sie Data Science, die für reale Arbeitsabläufe entwickelt wurde?
AI Superior kann Ihnen helfen bei:
- Entwicklung maßgeschneiderter Data-Science-Lösungen
- Entwicklung von Modellen für maschinelles Lernen und Analytik
- Ideen durch PoC- oder MVP-Entwicklung testen
- Integration von KI in alltägliche Systeme
👉 Kontaktieren Sie AI Superior um Ihr Projekt zu besprechen.
Erweiterte Analytik: Daten zugänglich machen
Erweiterte Analytik zählt zu den wirkungsvollsten Entwicklungen der letzten Jahre. Diese Plattformen nutzen maschinelles Lernen, um die Datenaufbereitung, die Gewinnung von Erkenntnissen und deren Interpretation zu automatisieren – Aufgaben, die traditionell fundierte statistische Kenntnisse erforderten.
Das zentrale Wertversprechen ist einfach: Geschäftsanwender stellen Fragen in natürlicher Sprache, und das System kümmert sich um die technische Komplexität im Hintergrund. Keine SQL-Abfragen. Keine Pivot-Tabellen. Kein mühsames Hantieren mit Visualisierungstools.
Aber funktioniert das tatsächlich? In der Praxis ja – mit Einschränkungen. Erweiterte Analysen eignen sich hervorragend für explorative Datenanalysen und das routinemäßige Reporting. Marketingmanager können Kundensegmente identifizieren, bei denen das Engagement nachlässt. Supply-Chain-Analysten können Bestandsanomalien aufdecken. Vertriebsleiter können die Quartalsleistung prognostizieren.
Laut einer Analyse von Top Data Science Solutions wird der Markt für Augmented Analytics bis 2030 voraussichtlich auf 102,78 Milliarden US-Dollar anwachsen, was einer durchschnittlichen jährlichen Wachstumsrate (CAGR) von 28,091 entspricht. Dieses Wachstum spiegelt eine echte Akzeptanz in der Wirtschaft wider und nicht nur den Hype der Anbieter.
Wichtigste Funktionen moderner erweiterter Analytik
Führende Plattformen weisen mehrere gemeinsame Kernfunktionen auf. Die automatisierte Datenaufbereitung übernimmt die Bereinigung, Transformation und Integration von Daten aus verschiedenen Quellen. Schnittstellen für Abfragen in natürlicher Sprache akzeptieren Fragen, die in Alltagssprache eingegeben oder gesprochen werden. Intelligente Visualisierungs-Engines wählen die passenden Diagrammtypen basierend auf den Dateneigenschaften und dem analytischen Kontext aus.
Die Erklärungsebene ist womöglich am wichtigsten. Wenn eine Plattform einen Trend oder eine Anomalie erkennt, zeigt sie nicht nur ein Diagramm an, sondern generiert einen Bericht, der erklärt, was sich geändert hat, warum es relevant ist und welche Maßnahmen sinnvoll sind. Diese Erklärungen machen die Erkenntnisse auch für Menschen ohne statistische Vorkenntnisse nutzbar.
Mal ehrlich: Erweiterte Analysen werden qualifizierte Analysten so schnell nicht ersetzen. Komplexe Untersuchungen, individuelle Modellierungen und strategische Interpretationen erfordern weiterhin menschliches Fachwissen. Doch für die 80% der Analyseaufgaben, die routinemäßige Datenerhebung und Berichterstellung umfassen, bieten diese Plattformen erhebliche Effizienzgewinne.
Überlegungen zur Umsetzung
Für den erfolgreichen Einsatz von Augmented Analytics sind Daten-Governance, Anwenderschulungen und eine durchdachte Integrationsarchitektur unerlässlich. Die Plattform benötigt Zugriff auf saubere, gut strukturierte Datenquellen. Anwender benötigen ausreichend Kontext, um die richtigen Fragen zu stellen und Ergebnisse korrekt zu interpretieren. IT-Teams benötigen klare Protokolle für Sicherheit, Zugriffskontrolle und Systemwartung.
Organisationen, die Augmented Analytics als rein technische Maßnahme betrachten, haben oft Schwierigkeiten. Diejenigen, die es als Change-Management-Initiative angehen – mit Unterstützung der Geschäftsleitung, engagierten Anwendern und schrittweiser Einführung – verzeichnen deutlich höhere Akzeptanzraten.
Automatisierte Plattformen für maschinelles Lernen
Automatisiertes maschinelles Lernen (AutoML) adressiert einen anderen Engpass: den Zeit- und Fachkräfteaufwand für die Entwicklung, Optimierung und den Einsatz von Vorhersagemodellen. Traditionelle Projekte im Bereich des maschinellen Lernens erfordern umfangreiche manuelle Arbeit – Merkmalsentwicklung, Algorithmenauswahl, Hyperparameter-Optimierung und Validierungstests.
AutoML-Plattformen automatisieren einen Großteil dieses Prozesses. Data Scientists definieren die Zielvariable und Erfolgsmetriken, und das System experimentiert mit verschiedenen Algorithmen, Merkmalskombinationen und Parametereinstellungen. Das Ergebnis: produktionsreife Modelle in Stunden oder Tagen statt Wochen oder Monaten.
Aktuelle Vergleichsstudien zeigen, dass sich die Leistungslücke zwischen API-basierten kommerziellen Plattformen und Open-Source-Alternativen weiter verringert. Die Leistung variiert jedoch je nach Plattform.
Was AutoML gut kann
AutoML glänzt in Szenarien mit strukturierten Daten und klar definierten Vorhersagezielen. Kundenabwanderungsprognose, Bedarfsplanung, Betrugserkennung, Vorhersage von Geräteausfällen – diese Anwendungen basieren typischerweise auf tabellarischen Daten und klar definierten Ergebnissen.
Die Plattformen übernehmen das Feature Engineering automatisch und testen Transformationen wie Polynommerkmale, Interaktionsterme und Binning-Strategien. Sie evaluieren Dutzende oder Hunderte von Algorithmenkombinationen, von linearen Modellen über Gradient Boosting bis hin zu neuronalen Netzen. Die Hyperparameteroptimierung nutzt Techniken wie Bayes'sche Optimierung oder evolutionäre Algorithmen, um Konfigurationen zu finden, die die Leistung maximieren.
Die Bereitstellungsprozesse haben sich deutlich verbessert. Viele Plattformen generieren mittlerweile containerisierte Endpunkte, die sich direkt in bestehende Anwendungen integrieren lassen. Ein Marketingteam kann ein Customer-Lifetime-Value-Modell implementieren, das jeden neuen Lead in Echtzeit bewertet – ganz ohne individuelle Programmierung.
Einschränkungen und bewährte Verfahren
AutoML ist keine Zauberei. Es funktioniert am besten, wenn das Problem klar definiert ist, die Daten einigermaßen sauber sind und die Beziehung zwischen Merkmalen und Zielgröße aus historischen Mustern erlernt werden kann. Schwierigkeiten hat es mit neuartigen Situationen, sich schnell verändernden Umgebungen und Aufgaben, die domänenspezifisches Feature Engineering erfordern.
Die Kritik an der “Black Box” ist nicht ganz unberechtigt. Moderne Plattformen liefern zwar Wichtigkeitswerte für Merkmale und partielle Abhängigkeitsdiagramme, doch ist es oft schwierig zu verstehen, warum ein Modell bestimmte Vorhersagen trifft. Regulierte Branchen benötigen möglicherweise besser interpretierbare Ansätze.
Bewährte Vorgehensweise ist der Einsatz von AutoML zur Beschleunigung der anfänglichen Entwicklung, gefolgt von der Überprüfung, Validierung und gegebenenfalls Optimierung der Ergebnisse durch erfahrene Anwender. Man kann es sich wie einen hochproduktiven Junior-Data-Scientist vorstellen, der Routinearbeiten übernimmt und so erfahrene Mitarbeiter für strategische Herausforderungen freistellt.
Echtzeit-Analysesysteme
Die Stapelverarbeitung erfüllte die Anforderungen der Datenanalyse jahrzehntelang zuverlässig. Unternehmen sammelten tagsüber Daten, führten über Nacht Verarbeitungsaufträge aus und überprüften am nächsten Morgen die Dashboards. Dieser Zyklus funktionierte gut, solange das Geschäftstempo langsamer war.
Nicht mehr. Echtzeit-Analysesysteme verarbeiten kontinuierlich Streaming-Daten und liefern Erkenntnisse mit einer Latenz von Sekunden oder Millisekunden statt Stunden. Finanzdienstleister erkennen betrügerische Transaktionen, bevor diese abgewickelt werden. E-Commerce-Plattformen passen Empfehlungen an das Surfverhalten der Nutzer an. Produktionsstätten identifizieren Qualitätsprobleme, bevor fehlerhafte Produkte die Fertigungslinie verlassen.
Die technische Architektur unterscheidet sich deutlich von herkömmlichen Batch-Systemen. Stream-Processing-Engines wie Apache Kafka, Apache Flink und Cloud-native Dienste übernehmen die Datenerfassung und -transformation. In-Memory-Datenbanken speichern den aktuellen Zustand für sofortige Abfragen. Ereignisgesteuerte Architekturen lösen Aktionen automatisch aus, sobald bestimmte Bedingungen erfüllt sind.
Anwendungsfälle, die die Akzeptanz fördern
Mehrere Anwendungsbereiche treiben die Verbreitung von Echtzeitanalysen voran. Betrugserkennung erfordert die sofortige Bewertung von Transaktionen anhand von Verhaltensmustern – Verzögerungen von nur wenigen Minuten können zu abgeschlossenen betrügerischen Käufen führen. Algorithmische Handelssysteme treffen Kauf-/Verkaufsentscheidungen in Mikrosekunden auf Basis von Marktdaten und Prognosemodellen.
Die operative Überwachung nutzt Echtzeitanalysen, um Systemzustand, Anwendungsleistung und Infrastrukturkennzahlen zu verfolgen. IT-Teams erkennen und beheben Probleme, bevor diese sich auf die Benutzer auswirken. DevOps-Workflows integrieren die kontinuierliche Überwachung in die Bereitstellungspipelines.
Personalisierungs-Engines aktualisieren Empfehlungen in Echtzeit basierend auf dem aktuellen Nutzerverhalten. Ein Kunde, der sich Wintermäntel ansieht, sieht passende Accessoires. Ein Leser, der einen Artikel beendet hat, erhält Vorschläge, die seinen Interessen entsprechen. Diese Interaktionen erfordern eine Reaktionszeit von unter einer Sekunde.
Implementierungskomplexität
Echtzeit-Analysesysteme sind deutlich komplexer als Batch-Systeme. Die verteilte Architektur bringt Herausforderungen hinsichtlich Datenkonsistenz, Fehlertoleranz und Betriebsüberwachung mit sich. Teams benötigen Expertise in Stream-Processing-Frameworks, dem Design verteilter Systeme und der Leistungsoptimierung.
Auch die Kostenstrukturen unterscheiden sich. Echtzeitsysteme benötigen kontinuierliche Rechen- und Speicherkapazität, nicht nur während der Batch-Verarbeitung. Cloud-Anbieter bieten Managed Services an, die die Bereitstellung vereinfachen, berechnen aber den kontinuierlichen Durchsatz. Unternehmen sollten sorgfältig prüfen, ob die jeweiligen Anwendungsfälle die zusätzliche Komplexität und die höheren Kosten rechtfertigen.
Die Schwelle für “Echtzeit” variiert jedoch je nach Anwendung. Nicht jeder Anwendungsfall erfordert Latenzzeiten im Millisekundenbereich. Viele Geschäftsszenarien funktionieren einwandfrei mit einer nahezu Echtzeitverarbeitung, die Ergebnisse in 30 Sekunden oder wenigen Minuten liefert. Oft ist es sinnvoller, mit einfacheren Architekturen zu beginnen und diese bei Bedarf zu erweitern, anstatt von vornherein auf extreme Leistungsanforderungen ausgelegt zu sein.
KI-gestützte Lösungen für die Datenverwaltung
Daten-Governance klingt langweilig, bis man die Folgen mangelhafter Datenqualität, unklarer Eigentumsverhältnisse oder Compliance-Verstößen erlebt hat. Unternehmen haben zunehmend Schwierigkeiten, Datenkataloge zu pflegen, Zugriffsrichtlinien durchzusetzen, die Datenherkunft nachzuverfolgen und die Einhaltung gesetzlicher Bestimmungen sicherzustellen, wenn Datenvolumen und -komplexität wachsen.
KI-gestützte Governance-Lösungen automatisieren viele traditionell manuelle Aufgaben. Maschinelles Lernen klassifiziert Datenbestände, identifiziert sensible Informationen, empfiehlt Metadaten-Tags und erkennt Anomalien in Nutzungsmustern. Die Verarbeitung natürlicher Sprache extrahiert die Bedeutung aus Dokumentationen und schlägt Verbesserungen für Datendefinitionen vor.
Jüngste Fortschritte bei Fairness-Algorithmen verdeutlichen deren Potenzial. Studien belegen die Reduzierung von 30%-Verzerrungen durch domänenunabhängige Fairness-Anpassungen, die datensatzübergreifend – von Bankdienstleistungen bis hin zu medizinischen Beurteilungen – funktionieren. Diese Techniken helfen Organisationen, algorithmische Verzerrungen zu erkennen und zu minimieren, bevor Modelle produktiv eingesetzt werden.
Kernfunktionen der Unternehmensführung
Moderne Governance-Plattformen bieten mehrere wesentliche Funktionen. Die automatisierte Datenerkennung durchsucht Repositories, Datenbanken und Dateisysteme, um umfassende Kataloge der verfügbaren Datenbestände zu erstellen. Klassifizierungsmodule kennzeichnen Daten mit Sensibilitätsstufen, Geschäftsbereichen und Qualitätsmetriken.
Die Datenherkunftsnachverfolgung lässt sich von der Quelle über die Transformationen bis zur endgültigen Nutzung nachvollziehen. Weist ein Bericht unerwartete Werte auf, können Analysten die Datenkette zurückverfolgen und die Ursache der Probleme ermitteln. Fragt die Aufsichtsbehörde nach der Berechnung bestimmter Zahlen, liegt eine Dokumentation vor, die die gesamte Verarbeitungskette erläutert.
Die automatisierte Zugriffskontrolle wendet Richtlinien basierend auf Datenklassifizierung, Benutzerrollen und Kontextfaktoren an. Marketingmitarbeiter haben Zugriff auf Kundenkontaktdaten, jedoch nicht auf Zahlungsdetails. Analysten in bestimmten Regionen sehen nur die für ihre Region relevanten Daten. Auftragnehmer erhalten eingeschränkte Berechtigungen, die automatisch ablaufen.
Erfüllung regulatorischer Anforderungen
Compliance-Rahmenwerke wie DSGVO, CCPA und HIPAA stellen spezifische Anforderungen an die Datenverarbeitung, -speicherung und die Rechte betroffener Personen. Governance-Plattformen unterstützen Unternehmen bei der Erfüllung dieser Verpflichtungen durch die automatisierte Ermittlung personenbezogener Daten, die Nachverfolgung von Einwilligungen und die Erleichterung von Löschanträgen.
Das 2019 finalisierte NIST Big Data Framework bietet Organisationen, die umfangreiche Analysefunktionen aufbauen, architektonische Leitlinien. Es behandelt neben technischen Implementierungsmustern auch Sicherheits-, Datenschutz- und Governance-Aspekte. Organisationen können dieses Framework als Referenz nutzen, um Governance-Programme zu entwickeln, die sowohl die Einhaltung gesetzlicher Bestimmungen als auch die Erreichung ihrer Geschäftsziele unterstützen.
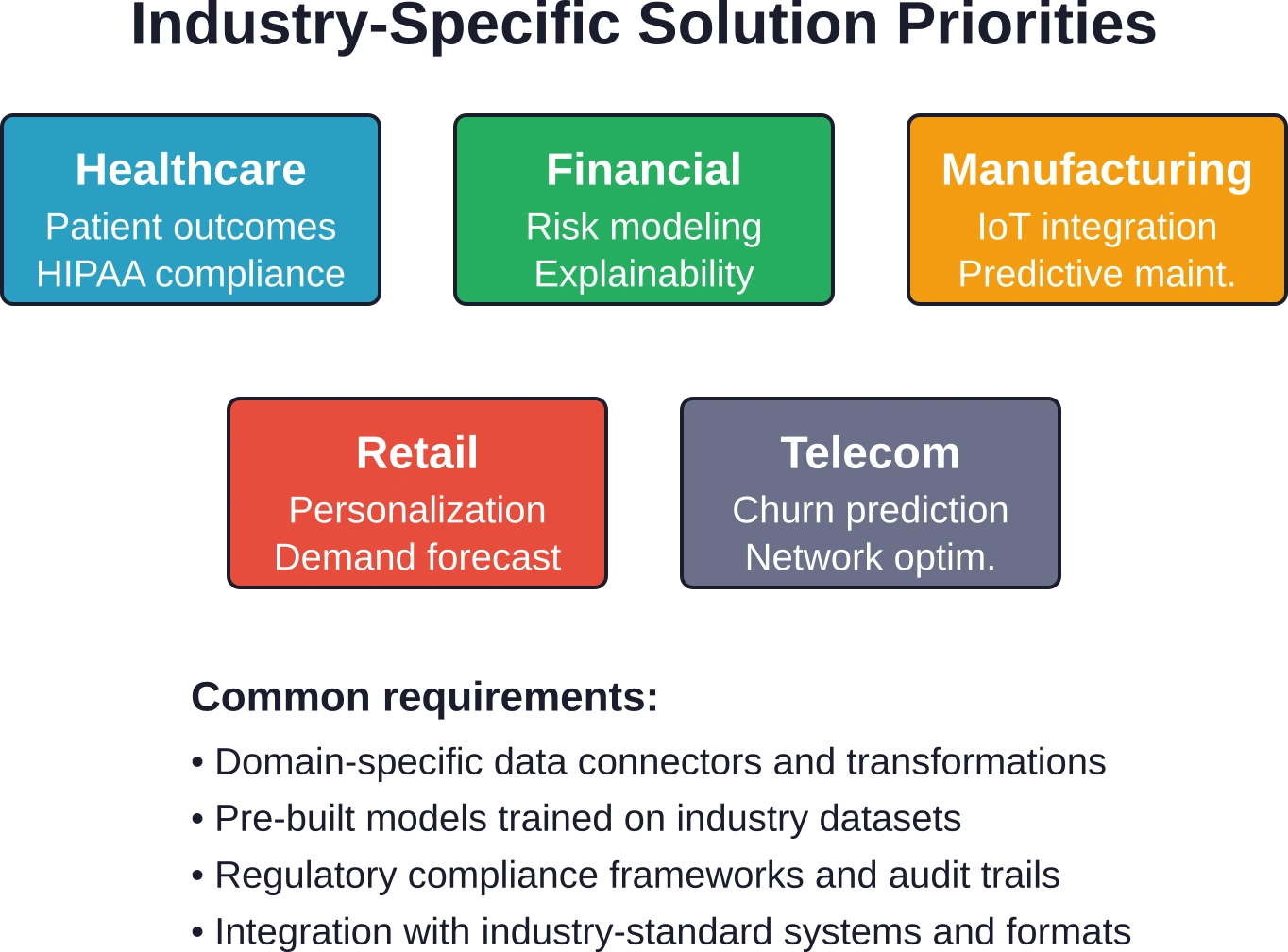
Spezialisierte Lösungen für Schlüsselindustrien
Während universelle Plattformen viele Bedürfnisse erfüllen, profitieren bestimmte Branchen von spezialisierten Data-Science-Lösungen, die auf branchenspezifische Herausforderungen und regulatorische Anforderungen zugeschnitten sind.
Analytik im Gesundheitswesen
Organisationen im Gesundheitswesen stehen vor komplexen und folgenreichen Entscheidungen in Bezug auf Patientenversorgung, Ressourcenverteilung und Bevölkerungsgesundheitsmanagement. Spezialisierte Plattformen integrieren sich in elektronische Patientenakten, medizinische Bildgebungssysteme und Abrechnungsdatenbanken.
Prädiktive Modelle identifizieren Patienten mit einem Risiko für Wiedereinweisung, Verschlechterung des Gesundheitszustands oder mangelnde Therapietreue. Analysen der Bevölkerungsgesundheit segmentieren Patientengruppen und empfehlen gezielte Interventionen. Klinische Entscheidungshilfesysteme liefern evidenzbasierte Empfehlungen direkt am Behandlungsort.
Die Einhaltung gesetzlicher Bestimmungen ist weiterhin von entscheidender Bedeutung. Die HIPAA-Anforderungen regeln den Datenzugriff, die Anonymisierung und die Meldung von Datenschutzverletzungen. Die FDA-Richtlinien gelten für klinische Entscheidungshilfesysteme, die die Definition von Medizinprodukten erfüllen. Plattformen im Gesundheitswesen integrieren diese Aspekte von vornherein in ihre Architektur, anstatt die Einhaltung gesetzlicher Bestimmungen erst im Nachhinein zu berücksichtigen.
Finanzdienstleistungen
Banken, Versicherungen und Investmentfirmen leisteten Pionierarbeit bei vielen Data-Science-Techniken. Die heutigen spezialisierten Plattformen decken Risikomodellierung, regulatorische Berichterstattung, Betrugserkennung und algorithmischen Handel mit finanzspezifischen Funktionen ab.
Funktionen für das Modellrisikomanagement unterstützen Unternehmen bei der Erfüllung regulatorischer Anforderungen hinsichtlich Modellvalidierung, Dokumentation und laufender Überwachung. Tools zur Erklärbarkeit generieren Prüfprotokolle, die den Anforderungen der Prüfer genügen. Stresstest-Frameworks bewerten die Modellleistung unter ungünstigen Szenarien.
Die Komplexität von Finanzdaten – unterschiedliche Zeitzonen, Kapitalmaßnahmen, variierende Marktgepflogenheiten – macht domänenspezifische Lösungen wertvoll. Generische Plattformen erfordern umfangreiche Anpassungen, um diese Nuancen korrekt zu verarbeiten.
Fertigung und Lieferkette
Hersteller nutzen Data Science für Qualitätsprognosen, vorausschauende Wartung, Bedarfsplanung und Lieferkettenoptimierung. Spezialisierte Lösungen lassen sich in industrielle IoT-Sensoren, Manufacturing Execution Systems (MES) und Enterprise-Resource-Planning-Plattformen (ERP) integrieren.
Vorausschauende Wartungsmodelle analysieren Sensordaten, um Geräteausfälle vorherzusagen, bevor sie auftreten. Dies ermöglicht planmäßige Wartungsarbeiten während geplanter Stillstandszeiten anstatt Notfallreparaturen während des laufenden Produktionsbetriebs. Die Qualitätsvorhersage identifiziert Prozessbedingungen, die zu Fehlern führen, und ermöglicht so Anpassungen in Echtzeit.
Die Analyse von Lieferketten optimiert Lagerbestände, Transportwege und Produktionspläne in komplexen Netzwerken von Lieferanten, Standorten und Kunden. Studien zeigen, dass autonome Systeme bei Aufgaben mit einer Ausführungszeit von mehr als 10 Sekunden zunehmend an Leistung einbüßen. Dies unterstreicht die Bedeutung optimierter Algorithmen für Echtzeit-Entscheidungen in der Lieferkette.
Neue Trends, die Datenwissenschaftslösungen prägen
Mehrere Entwicklungen verändern die Art und Weise, wie Unternehmen Data Science implementieren. Das Verständnis dieser Trends hilft bei der strategischen Planung und der Technologieauswahl.
Multimodale KI-Integration
Die traditionelle Datenwissenschaft konzentrierte sich primär auf strukturierte Daten – Zahlen, Kategorien, Zeitstempel. Moderne Plattformen verarbeiten zunehmend verschiedene Datenmodalitäten: Text, Bilder, Video, Audio, Sensordaten.
Aktuelle Forschungsergebnisse zu NeuroFusion zeigen eine Verbesserung von 34% gegenüber bestehenden multimodalen Benchmarks in der Echtzeit-Multimodalverarbeitung. Diese Systeme verarbeiten gleichzeitig Live-Daten aus Videoanrufen, Augmented-Reality-Umgebungen und IoT-Geräten und ermöglichen so eine umfassendere Analyse als Ansätze mit nur einer Modalität.
Anwendungen im Gesundheitswesen kombinieren medizinische Bildgebung mit elektronischen Patientenakten und klinischen Befunden. Systeme im Einzelhandel analysieren gemeinsam Produktbilder, Kundenbewertungen und Transaktionsdaten. Fertigungslösungen integrieren Sensormesswerte, Bilder aus der visuellen Inspektion und Wartungsprotokolle.
Automatisierte Data-Science-Workflows
Der Trend zur Automatisierung erstreckt sich über einzelne Aufgaben hinaus auf ganze Analyse-Workflows. Moderne Plattformen orchestrieren komplexe Abläufe: Datenerfassung, Qualitätsprüfung, Feature Engineering, Modelltraining, Evaluierung, Bereitstellung und Überwachung.
Diese durchgängigen Workflows reduzieren den manuellen Aufwand beim Übergang von Rohdaten zu Produktionsmodellen. Organisationen, die zuvor Wochen für die Implementierung eines neuen Modells benötigten, können denselben Prozess nun in Tagen oder Stunden abschließen. Die schnellere Iteration ermöglicht mehr Experimente und eine raschere Reaktion auf sich ändernde Bedingungen.
HardML, ein Benchmark zur Bewertung von Kenntnissen in Data Science und Machine Learning, umfasst 100 anspruchsvolle Multiple-Choice-Fragen aus verschiedenen Bereichen wie Deep Learning, klassisches Machine Learning, Verarbeitung natürlicher Sprache, Computer Vision, Data Engineering und Statistik. Plattformen, die in diesem breiten Spektrum gut abschneiden, weisen eine größere Anwendbarkeit auf als solche, die für enge Anwendungsfälle optimiert sind.
Edge-Analytics
Nicht alle Datenanalyse findet in zentralisierten Rechenzentren oder Cloud-Umgebungen statt. Edge-Analytics verarbeitet Daten auf Geräten am Netzwerkrand – Smartphones, IoT-Sensoren, autonomen Fahrzeugen und Industrieanlagen.
Dieser Ansatz bietet mehrere Vorteile. Die Latenz sinkt drastisch, da die Verarbeitung lokal erfolgt und keine Daten an entfernte Server übertragen werden müssen. Die Bandbreitenkosten reduzieren sich, da Rohdaten nicht übertragen werden müssen. Der Datenschutz verbessert sich, da sensible Informationen direkt auf dem Gerät verarbeitet und zusammengeführt werden können, anstatt an externe Systeme gesendet zu werden.
Der Einsatz am Netzwerkrand bringt Einschränkungen mit sich. Begrenzte Rechenressourcen erfordern optimierte Modelle. Zeitweise unterbrochene Verbindungen erfordern einen robusten Umgang mit Offline-Phasen. Die Gerätevielfalt erschwert Bereitstellung und Wartung. Spezialisierte Plattformen begegnen diesen Herausforderungen durch Modellkomprimierung, föderiertes Lernen und drahtlose Aktualisierung.
Die richtigen Data-Science-Lösungen auswählen
Angesichts der Hunderte von verfügbaren Plattformen und Tools kann die Auswahlentscheidung überwältigend sein. Ein strukturierter Evaluierungsprozess hilft dabei, Lösungen zu finden, die den spezifischen Bedürfnissen der Organisation entsprechen.
Klare Ziele definieren
Beginnen Sie damit, die zu lösenden Geschäftsprobleme zu formulieren. “Data Science implementieren” ist kein Ziel, sondern eine Fähigkeit. “Kundenabwanderung um 151.030 Tonnen reduzieren” oder “Lagerhaltungskosten um 201.030 Tonnen senken” sind messbare Ziele, die die Technologieauswahl leiten.
Unterschiedliche Ziele erfordern unterschiedliche Lösungen. Explorative Analysen und Management-Dashboards legen Augmented-Analytics-Plattformen nahe. Der großflächige Einsatz von maschinellem Lernen in der Produktion deutet auf AutoML- oder MLOps-Tools hin. Anforderungen an die Einhaltung regulatorischer Vorgaben sprechen für Governance-Lösungen.
Beurteilung der organisatorischen Fähigkeiten
Eine ehrliche Bewertung der internen Kompetenzen, Ressourcen und Prozesse verhindert Diskrepanzen zwischen Lösungskomplexität und organisatorischer Bereitschaft. Eine Plattform, die umfassende DevOps-Expertise erfordert, wird in einem Unternehmen mit begrenztem technischem Personal nicht erfolgreich sein. Umgekehrt können zu simple Tools Teams mit fortgeschrittenen Funktionen frustrieren.
Betrachten wir das Reifegradmodell für Data Science. Organisationen, die gerade erst mit der Datenanalyse beginnen, benötigen andere Werkzeuge als solche mit etablierten Vorgehensweisen. Low-Code-Plattformen beschleunigen die Wertschöpfung für weniger erfahrene Teams. Fortschrittliche Frameworks bieten anspruchsvollen Nutzern Flexibilität.
Bewertung der Integrationsanforderungen
Data-Science-Lösungen funktionieren selten isoliert. Sie müssen mit bestehenden Datenquellen, Geschäftsanwendungen und Workflow-Systemen verbunden werden. Die Komplexität der Integration hat einen erheblichen Einfluss auf die Implementierungszeiten und den laufenden Wartungsaufwand.
Prüfen Sie, ob native Konnektoren zu Ihren spezifischen Datenbanken, SaaS-Anwendungen und Data Warehouses verfügbar sind. Evaluieren Sie die API-Funktionen für individuelle Integrationen. Berücksichtigen Sie Authentifizierungs- und Sicherheitsprotokolle. Unternehmen mit komplexen technischen Umgebungen sollten Plattformen mit robusten Integrationsframeworks priorisieren.
| Bewertungskriterium | Fragen, die man stellen sollte | Auswirkungen auf die Auswahl |
|---|---|---|
| Geschäftsziele | Welche konkreten Ergebnisse sind ausschlaggebend für diese Investition? | Bestimmt die benötigte Lösungskategorie |
| Technische Fähigkeiten | Welche Expertise ist heute im Unternehmen vorhanden? | Beeinflusst den Komplexitätsgrad, der realisierbar ist |
| Datenumgebung | Wo befinden sich die relevanten Daten derzeit? | Beeinträchtigt den Integrationsaufwand und die Architektur |
| Skalierungsanforderungen | Welche Datenmengen und Nutzerzahlen werden erwartet? | Leitet Infrastruktur- und Lizenzierungsentscheidungen |
| Compliance-Anforderungen | Welche regulatorischen Anforderungen gelten? | Möglicherweise sind branchenspezifische oder zertifizierte Plattformen erforderlich. |
Durchführung eines Machbarkeitstests
Die Vorführungen der Anbieter zeigen idealisierte Szenarien mit sauberen Daten und einfachen Anwendungsfällen. Der Einsatz in der Praxis deckt jedoch häufig Komplikationen auf. Machbarkeitsstudien mit realen Organisationsdaten liefern eine wesentlich zuverlässigere Bewertung.
Definieren Sie vor Beginn konkrete Erfolgskriterien. Kann die Plattform Ihre Datenformate verarbeiten? Liefert sie in realistischem Umfang eine akzeptable Leistung? Können die vorgesehenen Benutzer sie ohne umfangreiche Schulung bedienen? Lässt sie sich nahtlos in Ihre bestehenden Systeme integrieren?
Die Evaluierung sollte zeitlich begrenzt werden – typischerweise auf 4–8 Wochen – und mit klar definierten Ergebnissen versehen werden. Ein Machbarkeitsnachweis, der sich über Monate hinzieht, ohne konkrete Ergebnisse zu liefern, deutet wahrscheinlich auf grundlegende Kompatibilitätsprobleme hin.
Bewährte Implementierungsmethoden
Die Technologieauswahl ist nur der Anfang. Für eine erfolgreiche Implementierung müssen organisatorische Veränderungen, die Akzeptanz durch die Nutzer und die betrieblichen Prozesse berücksichtigt werden.
Klein anfangen, schrittweise ausbauen
Die Versuchung, sich zuerst dem komplexesten und wertvollsten Anwendungsfall zu widmen, ist verständlich, aber meist kontraproduktiv. Komplexe Projekte bergen mehr Fehlerquellen und haben längere Laufzeiten. Ein kleinerer, klar definierter Anwendungsfall ermöglicht es dem Team, die Plattform kennenzulernen, Prozesse zu etablieren und den Nutzen zu demonstrieren, bevor es sich größeren Herausforderungen stellt.
Wählen Sie zunächst Projekte mit klarem Geschäftsnutzen, überschaubarem Umfang und leicht zugänglichen Daten. Erfolge schaffen Dynamik und stärken das Vertrauen im Unternehmen. Frühe Erfolge gewinnen Fürsprecher, die zu einer breiteren Akzeptanz beitragen.
Investieren Sie in Anwenderschulungen
Selbst die intuitivsten Plattformen erfordern etwas Einarbeitung. Organisationen, die Schulungen als optional betrachten, verzeichnen durchweg eine geringere Akzeptanz und schlechtere Ergebnisse als solche, die in strukturierte Weiterbildung investieren.
Entwickeln Sie Schulungsprogramme, die auf unterschiedliche Benutzerrollen zugeschnitten sind. Führungskräfte benötigen strategisches Verständnis und fortgeschrittene Kompetenzen. Business-Analysten benötigen praktische Erfahrung mit spezifischen Arbeitsabläufen. IT-Mitarbeiter benötigen Architekturkenntnisse und Kenntnisse der Betriebsabläufe.
Just-in-Time-Schulungen – die dann stattfinden, wenn die Anwender bereit sind, neue Fähigkeiten anzuwenden – erweisen sich in der Regel als effektiver als allgemeine Schulungen, die Monate vor dem tatsächlichen Einsatz stattfinden.
Frühzeitige Etablierung von Governance-Strukturen
Die Demokratisierung der Datenwissenschaft birgt neue Risiken hinsichtlich Datenqualität, Modellvalidität und Entscheidungsfindung. Governance-Rahmen bieten Leitplanken, ohne Innovationen zu ersticken.
Definieren Sie klare Richtlinien für Datenzugriff, Modellentwicklung, Freigabe von Implementierungen und laufende Überwachung. Etablieren Sie Prüfprozesse, die Gründlichkeit und Schnelligkeit gleichermaßen berücksichtigen. Erstellen Sie Dokumentationsstandards, die die Reproduzierbarkeit und Wartbarkeit der Arbeit gewährleisten.
Organisationen, die Governance erst reaktiv – also nach dem Auftreten von Problemen – implementieren, stehen vor schwierigeren Gesprächen und disruptiveren Veränderungen als solche, die Rahmenbedingungen proaktiv schaffen.
Erfolgsmessung und ROI
Investitionen in Data Science sollten einen messbaren Geschäftsnutzen generieren. Die Definition und Überwachung geeigneter Kennzahlen gewährleistet Verantwortlichkeit und steuert die kontinuierliche Verbesserung.
Kennzahlen für Geschäftsergebnisse
Die wichtigsten Maßnahmen sind direkt mit den Geschäftszielen verknüpft. Wenn das Ziel die Reduzierung der Kundenabwanderung war, sollten die Abwanderungsraten vor und nach der Implementierung erfasst werden. Zur Optimierung des Lagerbestands sollten Lagerkosten und Fehlbestandshäufigkeiten gemessen werden. Umsatzwachstum, Kostensenkung, Kundenzufriedenheit – diese Ergebnisse sind von größter Bedeutung.
Die Zuordnung von Erfolgsfaktoren kann schwierig sein. Geschäftsergebnisse haben selten nur eine einzige Ursache. Legen Sie vor der Implementierung Ausgangswerte fest, kontrollieren Sie nach Möglichkeit externe Faktoren und gehen Sie ehrlich mit Unsicherheiten bei den Wirkungsabschätzungen um.
Betriebskennzahlen
Prozessverbesserungen stellen eine weitere Wertkategorie dar. Wie viel Zeit spart das Analyseteam durch die automatisierte Datenaufbereitung? Wie viele Modelle werden pro Quartal zusätzlich implementiert? Wie viel schneller erhalten die Anwender Antworten auf ihre analytischen Fragen?
Diese Effizienzgewinne schlagen sich zwar nicht direkt in den Finanzberichten nieder, setzen aber Ressourcen für höherwertige Tätigkeiten frei und beschleunigen Entscheidungsprozesse.
Adoptionskennzahlen
Ungenutzte Technologie ist wertlos. Erfassen Sie aktive Nutzer, Abfragevolumen, Modelle im Produktiveinsatz und weitere Nutzungsindikatoren. Geringe Akzeptanz deutet auf Schulungslücken, Usability-Probleme oder eine Diskrepanz zu den tatsächlichen Bedürfnissen hin.
Befragen Sie die Nutzer regelmäßig zu ihrer Zufriedenheit, zu Problemen und zu Funktionswünschen. Qualitatives Feedback deckt oft Verbesserungspotenziale auf, die quantitative Kennzahlen übersehen.
Häufige Herausforderungen bei der Implementierung
Das Verständnis typischer Hindernisse hilft Organisationen, Strategien zur Risikominderung zu planen, anstatt von vermeidbaren Problemen überrascht zu werden.
Datenqualität und Zugänglichkeit
Organisationen unterschätzen regelmäßig die Herausforderungen im Zusammenhang mit der Datenaufbereitung. Veraltete Systeme mit inkonsistenten Formaten. Fehlende Werte und Dateneingabefehler. Unklare Definitionen und undokumentierte Transformationen. Isolierte Datenquellen mit inkompatiblen Schemata.
Data-Science-Plattformen können grundlegend fehlerhafte Daten nicht reparieren. Planen Sie daher im Rahmen der Implementierungsplanung Zeit und Ressourcen für die Verbesserung der Datenqualität ein. Legen Sie Kennzahlen und Verantwortlichkeiten für die Datenqualität fest. Bei weit verbreiteten Problemen sollten Sie Stammdatenmanagement-Initiativen in Betracht ziehen.
Qualifikationslücken
Auch Low-Code-Plattformen erfordern analytisches Denken und Fachwissen. Unternehmen stellen oft fest, dass die Demokratisierung des Zugangs zu Tools nicht automatisch eine Kultur datengetriebener Entscheidungsfindung schafft.
Schließen Sie Kompetenzlücken durch Schulungen, Neueinstellungen oder Partnerschaften. Erwägen Sie, Data-Science-Experten in die Geschäftsbereiche zu integrieren, um Beratung und Unterstützung zu leisten. Schaffen Sie Wissensgemeinschaften, in denen Anwender Wissen und Best Practices austauschen.
Integrationskomplexität
Was im Proof of Concept unkompliziert erschien, erweist sich im Produktivbetrieb oft als kompliziert. Sicherheitsanforderungen schränken den Netzwerkzugriff ein. Richtlinien zur Datenverwaltung erfordern Genehmigungsprozesse. Bestehenden Anwendungen fehlen APIs. Die Performance verschlechtert sich im Produktivbetrieb.
Binden Sie IT- und Sicherheitsteams frühzeitig in die Planung ein. Planen Sie ausreichend Zeit für die Integrationsarbeiten ein. Testen Sie unter realistischen Bedingungen, bevor Sie live gehen. Halten Sie Notfallpläne für unerwartete technische Hindernisse bereit.
Zukünftige Ausrichtungen
Mehrere Entwicklungen, die sich abzeichnen, werden die Lösungen im Bereich Data Science in den kommenden Jahren prägen.
Erhöhte Automatisierung
Die Automatisierung wird sich auf Aufgaben ausweiten, die derzeit noch menschliches Urteilsvermögen erfordern. AutoML entwickelt sich zu AutoDS – einer automatisierten Datenwissenschaft, die den gesamten Lebenszyklus von der Problemdefinition über die Bereitstellung bis hin zur Überwachung abdeckt. Unternehmen werden Geschäftsziele und -beschränkungen festlegen, und Systeme werden analytische Ansätze vorschlagen, diese ausführen und die Ergebnisse messen.
Dies beseitigt nicht die menschliche Beteiligung, sondern verlagert den Fokus von der technischen Ausführung hin zu strategischen Entscheidungen, Interpretation und Steuerung.
Bessere Erklärbarkeit
Regulatorischer Druck und ethische Bedenken treiben die Nachfrage nach besser interpretierbaren Modellen an. Black-Box-Vorhersagen werden in sensiblen Bereichen wie dem Gesundheitswesen, dem Finanzwesen und der Strafjustiz zunehmend weniger akzeptiert.
Die Forschung verbessert kontinuierlich Erklärungstechniken für komplexe Modelle. Kontrafaktische Erklärungen zeigen, was sich ändern müsste, um eine andere Vorhersage zu treffen. Einflussfunktionen identifizieren die Trainingsbeispiele, die eine bestimmte Vorhersage am stärksten beeinflusst haben. Aufmerksamkeitsmechanismen decken auf, auf welche Eingaben sich das Modell konzentriert.
Plattformen werden diese Techniken nativ integrieren, wodurch Erklärbarkeit zu einer Standardfunktion und nicht zu einem spezialisierten Zusatzmodul wird.
Verteiltes und föderiertes Lernen
Datenschutzbestimmungen und Anforderungen an die Datensouveränität erschweren die zentrale Datenaggregation. Föderiertes Lernen trainiert Modelle über verteilte Datensätze hinweg, ohne die zugrunde liegenden Daten zu verschieben.
Organisationen im Gesundheitswesen können bei der Modellentwicklung zusammenarbeiten, ohne Patientendaten auszutauschen. Finanzinstitute können die Betrugserkennung durch kollektive Intelligenz verbessern und gleichzeitig Transaktionsdaten isoliert halten. Hersteller können ihre Leistung mit der von Wettbewerbern vergleichen, ohne Betriebsgeheimnisse preiszugeben.
Dieser architektonische Wandel erfordert neue Werkzeuge, beseitigt aber grundlegende Hindernisse für kollaborative Analysen in datenschutzsensiblen Bereichen.
Häufig gestellte Fragen
Worin besteht der Unterschied zwischen Data-Science-Plattformen und Business-Intelligence-Tools?
Business-Intelligence-Tools konzentrieren sich primär auf die Berichterstellung und Visualisierung historischer Daten. Data-Science-Plattformen hingegen legen den Schwerpunkt auf prädiktive Modellierung, maschinelles Lernen und fortgeschrittene Analysen. Moderne Lösungen verwischen diese Grenzen zunehmend, doch BI-Tools zielen im Allgemeinen auf deskriptive Analysen ab, während Data-Science-Plattformen prädiktive und präskriptive Funktionen ermöglichen.
Wie hoch sind die Kosten für die Implementierung von Data-Science-Lösungen?
Die Kosten variieren stark je nach Plattformwahl, Umfang der Implementierung und den Bedürfnissen des Unternehmens. Cloudbasierte Managed Services werden in der Regel nutzungsbasiert abgerechnet – nach Rechenstunden, verarbeiteten Daten und API-Aufrufen. Unternehmenslizenzen kosten jährlich zwischen Zehntausenden und Millionen von Dollar. Open-Source-Lösungen verursachen Infrastruktur- und Personalkosten anstelle von Lizenzgebühren. Aktuelle Preise finden Sie auf den offiziellen Websites der Anbieter, da sich die Modelle häufig ändern.
Müssen wir Datenwissenschaftler einstellen, um diese Plattformen zu nutzen?
Es kommt auf die Plattform und Ihre Ziele an. Low-Code-Plattformen für erweiterte Analysen ermöglichen es Anwendern, viele Analysen ohne Programmierkenntnisse durchzuführen. AutoML-Tools reduzieren den Bedarf an spezialisiertem Fachwissen für die Modellentwicklung. Komplexe Projekte, individuelle Lösungen und Produktivimplementierungen profitieren jedoch in der Regel von erfahrenen Data-Science-Experten. Viele Unternehmen verfolgen einen hybriden Ansatz: Sie befähigen Anwender für Routineaufgaben und setzen gleichzeitig spezialisierte Mitarbeiter für anspruchsvolle Projekte ein.
Wie lange dauert es, bis sich Investitionen in Data Science auszahlen?
Der Zeitrahmen variiert je nach Projektumfang und organisatorischer Bereitschaft. Einfache Anwendungsfälle mit sauberen, leicht zugänglichen Daten können innerhalb weniger Wochen Ergebnisse liefern. Komplexe Implementierungen mit mehreren Systemen, kundenspezifischer Entwicklung oder tiefgreifenden organisatorischen Veränderungen benötigen unter Umständen 6–12 Monate, bis ein substanzieller Mehrwert entsteht. Der Einstieg mit kleineren Proof-of-Concept-Projekten trägt dazu bei, den Nutzen schneller zu demonstrieren und die Dynamik für größere Initiativen zu steigern.
Welche Branchen profitieren am meisten von Data-Science-Lösungen?
Nahezu jede Branche profitiert von Data Science, doch in einigen Branchen sind die Auswirkungen besonders dramatisch. Finanzdienstleister nutzen fortschrittliche Analysen für Risikobewertung, Betrugserkennung und algorithmischen Handel. Im Gesundheitswesen werden prädiktive Modelle für die Patientenversorgung, die betriebliche Effizienz und die Medikamentenentwicklung eingesetzt. Der Einzelhandel nutzt Data Science für Personalisierung, Bedarfsprognosen und die Optimierung der Lieferkette. Die Fertigungsindustrie setzt auf vorausschauende Wartung und Qualitätskontrolle. Telekommunikationsunternehmen nutzen Kundenabwanderungsprognosen und Netzwerkoptimierung.
Wie stellen wir sicher, dass unsere Data-Science-Initiativen den Vorschriften entsprechen?
Compliance erfordert besondere Aufmerksamkeit für Datenverarbeitung, Modellgovernance und Dokumentation. Nutzen Sie Plattformen mit integrierten Compliance-Funktionen für Ihre Branche – HIPAA für das Gesundheitswesen, SOC 2 für Finanzdienstleistungen, DSGVO für europäische Niederlassungen. Implementieren Sie Data-Governance-Frameworks, die die Datenherkunft nachverfolgen, Zugriffskontrollen durchsetzen und Audit-Trails führen. Dokumentieren Sie die Prozesse für Modellentwicklung, -validierung und -überwachung. Binden Sie Rechts- und Compliance-Teams frühzeitig in die Projektplanung ein. Ziehen Sie spezialisierte Governance-Plattformen in Betracht, wenn die regulatorischen Anforderungen umfangreich sind.
Sind Data-Science-Lösungen mit unseren bestehenden Systemen kompatibel?
Die meisten modernen Plattformen bieten umfangreiche Integrationsmöglichkeiten durch vorgefertigte Konnektoren, APIs und Tools zum Importieren und Exportieren von Daten. Prüfen Sie, ob die von Ihnen in Betracht gezogene Plattform Ihre spezifischen Datenbanken, Data Warehouses, Geschäftsanwendungen und Dateiformate nativ unterstützt. Der Integrationsaufwand variiert erheblich: Cloud-basierte Lösungen lassen sich oft einfacher mit anderen Cloud-Diensten verbinden, während On-Premise-Bereitstellungen unter Umständen benutzerdefinierte Middleware erfordern. Bewerten Sie die Integrationsanforderungen bereits bei der Plattformauswahl, anstatt Kompatibilitätsprobleme erst nach der Vertragsunterzeichnung festzustellen.
Fazit: Aufbau datengetriebener Fähigkeiten
Data-Science-Lösungen haben sich von experimentellen Technologien zu unverzichtbarer Geschäftsinfrastruktur entwickelt. Unternehmen aller Branchen sind heute auf diese Plattformen angewiesen, um wettbewerbsfähig zu bleiben, effizient zu arbeiten und ihre Kunden besser zu bedienen.
Die erfolgreichsten Implementierungen weisen gemeinsame Merkmale auf. Sie basieren auf klaren Geschäftszielen und nicht auf Technologie um ihrer selbst willen. Die Komplexität der Lösung wird an die Fähigkeiten und den Reifegrad der Organisation angepasst. Parallel zur Technologieeinführung wird in Datenqualität, Anwenderschulungen und Governance-Rahmen investiert. Die Ergebnisse werden systematisch gemessen und die Maßnahmen evidenzbasiert angepasst.
Sehen Sie, keine Plattform löst jedes Problem oder passt zu jeder Organisation. Die “beste” Lösung hängt von den spezifischen Bedürfnissen, Rahmenbedingungen und Zielen ab. Erweiterte Analyseplattformen demokratisieren zwar Erkenntnisse, ersetzen aber keine fundierte analytische Expertise. AutoML beschleunigt die Modellentwicklung, benötigt jedoch gute Daten und klar definierte Problemstellungen. Echtzeitsysteme ermöglichen sofortiges Handeln, erhöhen aber die operative Komplexität. Branchenspezifische Lösungen erfüllen domänenspezifische Anforderungen, können aber teurer sein als allgemeine Plattformen.
Die Datenwissenschaft entwickelt sich rasant weiter. Neue Funktionen entstehen, die Leistung verbessert sich, und die Preise ändern sich. Organisationen, die klare Bewertungskriterien festlegen, gründlich testen und bei der Technologieauswahl flexibel bleiben, sind gut aufgestellt, um sich an die Fortschritte des Feldes anzupassen.
Sind Sie bereit, die Datennutzung in Ihrem Unternehmen grundlegend zu verändern? Beginnen Sie mit der Identifizierung eines aussagekräftigen Anwendungsfalls mit leicht zugänglichen Daten und klaren Erfolgskennzahlen. Evaluieren Sie Plattformen, die zu Ihrer technischen Umgebung und Ihren Kenntnissen passen. Führen Sie praktische Tests mit realen Daten durch. Darauf aufbauend können Sie Ihre Strategie weiterentwickeln.
Der Wettbewerbsvorteil geht zunehmend an Organisationen, die Daten schneller und effektiver in konkrete Maßnahmen umsetzen als ihre Mitbewerber. Data-Science-Lösungen liefern die Werkzeuge – doch Erfolg erfordert die Bereitschaft zu organisatorischen Veränderungen, kontinuierliches Lernen und evidenzbasierte Entscheidungsfindung.