Korte samenvatting: De beste data science-oplossingen van 2026 omvatten augmented analytics-platforms die inzichten toegankelijk maken voor iedereen binnen organisaties, geautomatiseerde machine learning-tools die de modelontwikkeling versnellen, realtime analysesystemen voor directe besluitvorming en AI-gestuurde frameworks voor databeheer. Deze oplossingen stellen bedrijven in staat waarde te halen uit complexe datasets en tegelijkertijd de technische drempels te verlagen die traditioneel gepaard gaan met geavanceerde analyses.
Organisaties staan vandaag de dag voor een ongekende uitdaging: bergen data, maar beperkte mogelijkheden om er zinvolle inzichten uit te halen. De kloof tussen dataverzameling en bruikbare informatie is nog nooit zo groot geweest.
Data science-oplossingen overbruggen die kloof. Ze transformeren ruwe informatie in strategische beslissingen, concurrentievoordelen en meetbare bedrijfsresultaten. Maar met honderden beschikbare platforms, tools en frameworks vereist het kiezen van de juiste oplossingen inzicht in wat daadwerkelijk werkt in 2026.
Deze gids onderzoekt de meest effectieve data science-oplossingen die momenteel sectoren transformeren. Van augmented analytics die data toegankelijk maakt voor niet-technische teams tot geautomatiseerd machine learning dat implementatietijden versnelt: deze technologieën vertegenwoordigen de voorhoede van praktische toepassingen.
De evolutie van data science-oplossingen
Datawetenschap is aanzienlijk volwassener geworden sinds de begindagen van op maat gemaakte algoritmes en handmatige feature engineering. Moderne oplossingen leggen de nadruk op toegankelijkheid, automatisering en integratie met bestaande bedrijfsprocessen.
Deze verschuiving weerspiegelt een fundamentele verandering in de manier waarop organisaties met analyses omgaan. In plaats van uitsluitend te vertrouwen op gespecialiseerde datawetenschappers die geïsoleerd werken, zetten bedrijven nu platforms in die samenwerking tussen afdelingen mogelijk maken. Marketingteams draaien voorspellende modellen. Operationele medewerkers optimaliseren de logistiek met behulp van machine learning. Financiële afdelingen automatiseren risicobeoordelingen.
Deze democratisering is niet toevallig gebeurd. Technologieaanbieders realiseerden zich dat de meeste bedrijven niet genoeg datawetenschappers konden aannemen om aan de vraag te voldoen.
De standaarden die deze systemen reguleren, zijn ook geëvolueerd. Het NIST SP 800-181-raamwerk heeft competentiegebieden vastgesteld voor functies op het gebied van cybersecurity en data science. De huidige versie (2.2.0) werd uitgebracht op 28 april 2025, terwijl de herziening van 2020 (NIST SP 800-181r1) eerder werd gepubliceerd voor functies op het gebied van cybersecurity en data science. NISTIR 8355 (gepubliceerd in juni 2023) biedt aanvullende richtlijnen voor competentiegebieden om een inzetbaar personeelsbestand in de cybersecuritysector op te leiden, waardoor duidelijkere trajecten voor personeelsontwikkeling en technologie-implementatie worden gecreëerd.

Ontwikkel data science-oplossingen met superieure AI.
AI Superieur Ze ontwikkelen AI-gebaseerde applicaties en maatwerksoftware met behulp van machine learning-modellen, data-analyse, NLP, computervisie, BI en big data-analyse. Hun werk kan projecten ondersteunen van de verkenningsfase en data-analyse tot de ontwikkeling van een MVP, integratie en resultaatsevaluatie.
Voor bedrijven die data science-oplossingen evalueren, kan dit helpen om van verspreide data en vage ideeën over te stappen naar werkende tools die prognoses, automatisering en duidelijkere beslissingen ondersteunen.
Heeft u behoefte aan data science die is afgestemd op echte workflows?
AI Superior kan u helpen met:
- het bouwen van op maat gemaakte data science-oplossingen
- het ontwikkelen van machine learning- en analysemodellen
- Ideeën testen door middel van PoC- of MVP-ontwikkeling
- AI integreren in dagelijkse systemen
👉 Neem contact op met AI Superior om uw project te bespreken.
Augmented Analytics: Gegevens toegankelijk maken
Augmented analytics is een van de meest impactvolle ontwikkelingen van de afgelopen jaren. Deze platforms gebruiken machine learning om de voorbereiding van gegevens, het genereren van inzichten en de uitleg ervan te automatiseren – taken die traditioneel diepgaande statistische expertise vereisten.
De kernwaarde is eenvoudig: zakelijke gebruikers stellen vragen in natuurlijke taal en het systeem regelt de technische complexiteit achter de schermen. Geen SQL-query's. Geen draaitabellen. Geen gedoe met visualisatietools.
Maar werkt dat ook echt? In de praktijk wel, maar met een paar kanttekeningen. Augmented analytics blinkt uit in verkennende analyses en routinematige rapportages. Marketingmanagers kunnen bijvoorbeeld vaststellen welke klantsegmenten een dalende betrokkenheid vertonen. Supply chain-analisten kunnen voorraadafwijkingen opsporen. Verkoopdirecteuren kunnen de kwartaalprestaties voorspellen.
Volgens een analyse van Top Data Science Solutions zal de markt voor augmented analytics naar verwachting groeien tot $102,78 miljard in 2030 met een samengestelde jaarlijkse groei van 28,09%. Deze groei weerspiegelt daadwerkelijke zakelijke adoptie, en niet slechts marketingpraatjes van leveranciers.
Belangrijkste mogelijkheden van moderne augmented analytics
Toonaangevende platforms delen een aantal kernfuncties. Geautomatiseerde dataverwerking zorgt voor het opschonen, transformeren en integreren van data uit meerdere bronnen. Gebruikersinterfaces voor zoekopdrachten in natuurlijke taal accepteren vragen die in alledaagse taal worden getypt of gesproken. Slimme visualisatie-engines selecteren de juiste grafiektypen op basis van data-eigenschappen en de analytische context.
De verklarende laag is wellicht het belangrijkst. Wanneer een platform een trend of afwijking identificeert, toont het niet alleen een grafiek, maar genereert het ook een verhaal dat uitlegt wat er is veranderd, waarom het belangrijk is en welke acties zinvol zijn. Deze verklaringen maken inzichten bruikbaar voor mensen zonder statistische achtergrond.
Eerlijk gezegd: augmented analytics zal bekwame analisten niet snel vervangen. Complexe onderzoeken, maatwerkmodellen en strategische interpretaties vereisen nog steeds menselijke expertise. Maar voor de talloze analytische taken die routinematig onderzoek en rapportage omvatten, leveren deze platforms aanzienlijke efficiëntievoordelen op.
Overwegingen bij de implementatie
Om augmented analytics succesvol in te zetten, is aandacht voor databeheer, gebruikerstraining en integratiearchitectuur essentieel. Het platform heeft toegang nodig tot schone, goed gestructureerde databronnen. Gebruikers hebben voldoende context nodig om goede vragen te stellen en resultaten correct te interpreteren. IT-teams hebben duidelijke protocollen nodig voor beveiliging, toegangscontrole en systeembeheer.
Organisaties die augmented analytics puur als een technische implementatie beschouwen, ondervinden vaak problemen. Organisaties die het benaderen als een initiatief voor verandermanagement – met steun van het management, gebruikersambassadeurs en een stapsgewijze uitrol – zien veel hogere acceptatiepercentages.
Geautomatiseerde machine learning-platformen
Geautomatiseerd machinaal leren (AutoML) pakt een ander knelpunt aan: de tijd en expertise die nodig zijn om voorspellende modellen te ontwikkelen, af te stemmen en te implementeren. Traditionele machine learning-projecten omvatten veel handmatig werk, zoals feature engineering, algoritmeselectie, hyperparameteroptimalisatie en validatietesten.
AutoML-platforms automatiseren een groot deel van die pipeline. Datawetenschappers specificeren de doelvariabele en succesindicatoren, waarna het systeem experimenteert met verschillende algoritmen, combinaties van kenmerken en parameterinstellingen. Het resultaat: productiegereedde modellen in uren of dagen in plaats van weken of maanden.
Recente benchmarktests tonen aan dat het prestatieverschil tussen API-gebaseerde commerciële platforms en open-source alternatieven steeds kleiner wordt. De prestaties variëren echter per platform.
Wat AutoML goed doet
AutoML blinkt uit in scenario's met gestructureerde data en duidelijke voorspellingsdoelen. Klantverloopvoorspelling, vraagvoorspelling, fraudedetectie, voorspelling van apparatuurstoringen – deze toepassingen hebben doorgaans te maken met tabulaire data en goed gedefinieerde uitkomsten.
De platforms verzorgen automatisch de feature engineering en testen transformaties zoals polynomiale kenmerken, interactietermen en binningstrategieën. Ze evalueren tientallen of honderden algoritmecombinaties, van lineaire modellen tot gradient boosting en neurale netwerken. Hyperparameteroptimalisatie maakt gebruik van technieken zoals Bayesiaanse optimalisatie of evolutionaire algoritmen om configuraties te vinden die de prestaties maximaliseren.
De implementatieworkflows zijn enorm verbeterd. Veel platforms genereren nu gecontaineriseerde endpoints die direct integreren met bestaande applicaties. Een marketingteam kan een klantlevenswaardemodel implementeren dat elke nieuwe lead in realtime beoordeelt, zonder dat er maatwerkcode nodig is.
Beperkingen en beste praktijken
AutoML is geen toverkunst. Het werkt het beste wanneer het probleem duidelijk is gedefinieerd, de data redelijk schoon is en de relatie tussen kenmerken en doelvariabelen kan worden afgelezen uit historische patronen. Het heeft moeite met nieuwe situaties, snel veranderende omgevingen en taken die domeinspecifieke feature engineering vereisen.
De kritiek op de "black box" heeft wel degelijk iets te zeggen. Hoewel moderne platforms scores voor het belang van kenmerken en partiële afhankelijkheidsgrafieken bieden, kan het lastig zijn om precies te begrijpen waarom een model bepaalde voorspellingen doet. Gereguleerde sectoren vereisen mogelijk meer interpreteerbare benaderingen.
De beste werkwijze is om AutoML te gebruiken om de initiële ontwikkeling te versnellen, waarna ervaren professionals de resultaten beoordelen, valideren en eventueel verfijnen. Zie het als een zeer productieve junior data scientist die routinewerk afhandelt, waardoor senior medewerkers zich kunnen richten op strategische uitdagingen.
Realtime analysesystemen
Batchverwerking voldeed decennialang prima aan de behoeften van data-analyse. Organisaties verzamelden gedurende de dag gegevens, voerden 's nachts verwerkingstaken uit en bekeken de dashboards de volgende ochtend. Die cyclus werkte prima toen de bedrijfsactiviteiten in een rustiger tempo verliepen.
Dat is niet langer het geval. Realtime analysesystemen verwerken continu streaming data en leveren inzichten met een latentie van seconden of milliseconden in plaats van uren. Financiële dienstverleners detecteren frauduleuze transacties voordat ze worden afgerond. E-commerceplatforms passen aanbevelingen aan naarmate het surfgedrag verandert. Productiebedrijven identificeren kwaliteitsproblemen voordat defecte producten de productielijn verlaten.
De technische architectuur verschilt aanzienlijk van traditionele batchsystemen. Streamverwerkingsengines zoals Apache Kafka, Apache Flink en cloud-native services verzorgen de data-invoer en -transformatie. In-memory databases slaan de actuele status op voor directe query's. Event-driven architecturen activeren automatisch acties wanneer aan bepaalde voorwaarden wordt voldaan.
Gebruiksscenario's die de acceptatie stimuleren
Verschillende toepassingscategorieën stimuleren de adoptie van realtime analyses. Fraudebestrijding vereist een onmiddellijke beoordeling van transacties aan de hand van gedragspatronen; zelfs vertragingen van enkele minuten kunnen leiden tot voltooide frauduleuze aankopen. Algoritmische handelssystemen nemen koop-/verkoopbeslissingen in microseconden op basis van marktgegevens en voorspellende modellen.
Operationele monitoring maakt gebruik van realtime analyses om de systeemstatus, applicatieprestaties en infrastructuurstatistieken te volgen. IT-teams identificeren en lossen problemen op voordat ze gebruikers beïnvloeden. DevOps-workflows integreren continue monitoring in implementatieprocessen.
Personalisatiesystemen werken aanbevelingen direct bij op basis van het huidige gedrag. Een klant die winterjassen bekijkt, ziet relevante accessoires. Een lezer die een artikel heeft uitgelezen, krijgt suggesties die aansluiten bij zijn of haar interesses. Deze ervaringen vereisen een reactietijd van minder dan een seconde om responsief aan te voelen.
Implementatiecomplexiteit
Realtime analysesystemen zijn aanzienlijk complexer dan batchverwerkingssystemen. De gedistribueerde architectuur brengt uitdagingen met zich mee op het gebied van dataconsistentie, fouttolerantie en operationele monitoring. Teams hebben expertise nodig in frameworks voor streamverwerking, het ontwerpen van gedistribueerde systemen en prestatieoptimalisatie.
De kostenstructuren verschillen ook. Realtime-systemen vereisen continue reken- en opslagcapaciteit, niet alleen tijdens batchverwerkingen. Cloudproviders bieden beheerde services die de implementatie vereenvoudigen, maar rekenen kosten voor continue doorvoer. Organisaties moeten zorgvuldig evalueren of specifieke gebruiksscenario's de extra complexiteit en kosten rechtvaardigen.
Dat gezegd hebbende, de drempel voor "realtime" varieert per toepassing. Niet elke use case vereist een latentie van milliseconden. Veel zakelijke scenario's werken prima met "bijna realtime" verwerking die resultaten oplevert in 30 seconden of een paar minuten. Beginnen met eenvoudigere architecturen en deze naar behoefte uitbreiden is vaak verstandiger dan vanaf het begin te bouwen voor extreme prestatie-eisen.
AI-gestuurde oplossingen voor gegevensbeheer
Databeheer klinkt misschien saai, totdat je de gevolgen ondervindt van slechte datakwaliteit, onduidelijke eigendomsstructuur of schendingen van de regelgeving. Organisaties worstelen met het onderhouden van datacatalogi, het afdwingen van toegangsbeleid, het traceren van de herkomst van gegevens en het waarborgen van naleving van de wet- en regelgeving, naarmate de hoeveelheid en complexiteit van gegevens toenemen.
AI-gestuurde governance-oplossingen automatiseren veel taken die traditioneel handmatig worden uitgevoerd. Machine learning classificeert data-assets, identificeert gevoelige informatie, adviseert over metadata-tags en detecteert afwijkingen in gebruikspatronen. Natuurlijke taalverwerking extraheert betekenis uit documentatie en suggereert verbeteringen aan datadefinities.
Recente ontwikkelingen in eerlijkheidsalgoritmen tonen het potentieel aan. Onderzoek toont aan dat 30%-biasreductie is bereikt door middel van domeinonafhankelijke eerlijkheidsaanpassingen die werken op verschillende datasets, van de banksector tot medische beoordelingen. Deze technieken helpen organisaties om algoritmische bias te identificeren en te verminderen voordat modellen in productie worden genomen.
Kerncompetenties op het gebied van governance
Moderne governanceplatformen bieden diverse essentiële functies. Geautomatiseerde data-ontdekking doorzoekt repositories, databases en bestandssystemen om uitgebreide catalogi van beschikbare data te creëren. Classificatie-engines labelen data met gevoeligheidsniveaus, bedrijfsdomeinen en kwaliteitsindicatoren.
Gegevenstracering volgt de herkomst van de data vanaf de bron via transformaties tot aan het uiteindelijke gebruik. Wanneer een rapport onverwachte waarden laat zien, kunnen analisten de hele verwerkingsketen terugvolgen om te achterhalen waar de problemen zijn ontstaan. Wanneer toezichthouders vragen hoe specifieke cijfers zijn berekend, is er documentatie beschikbaar die de volledige verwerkingsketen uitlegt.
Toegangsbeheerautomatisering past beleid toe op basis van gegevensclassificatie, gebruikersrollen en contextuele factoren. Marketingmedewerkers hebben toegang tot klantcontactgegevens, maar niet tot betaalgegevens. Analisten in specifieke regio's zien alleen gegevens die relevant zijn voor hun geografische gebied. Aannemers krijgen beperkte toegangsrechten die automatisch verlopen.
Voldoen aan wettelijke vereisten
Compliancekaders zoals GDPR, CCPA en HIPAA stellen specifieke eisen aan de verwerking, bewaring en rechten van betrokkenen met betrekking tot gegevens. Governanceplatforms helpen organisaties aan deze verplichtingen te voldoen door middel van geautomatiseerde detectie van persoonsgegevens, het bijhouden van toestemmingen en het faciliteren van verwijderingsverzoeken.
Het NIST Big Data Framework, dat in 2019 werd afgerond, biedt architectuurrichtlijnen voor organisaties die grootschalige analysecapaciteiten ontwikkelen. Het behandelt overwegingen met betrekking tot beveiliging, privacy en governance, naast technische implementatiepatronen. Organisaties kunnen dit framework raadplegen bij het ontwerpen van governanceprogramma's die zowel de naleving van wet- en regelgeving als de bedrijfsdoelstellingen ondersteunen.
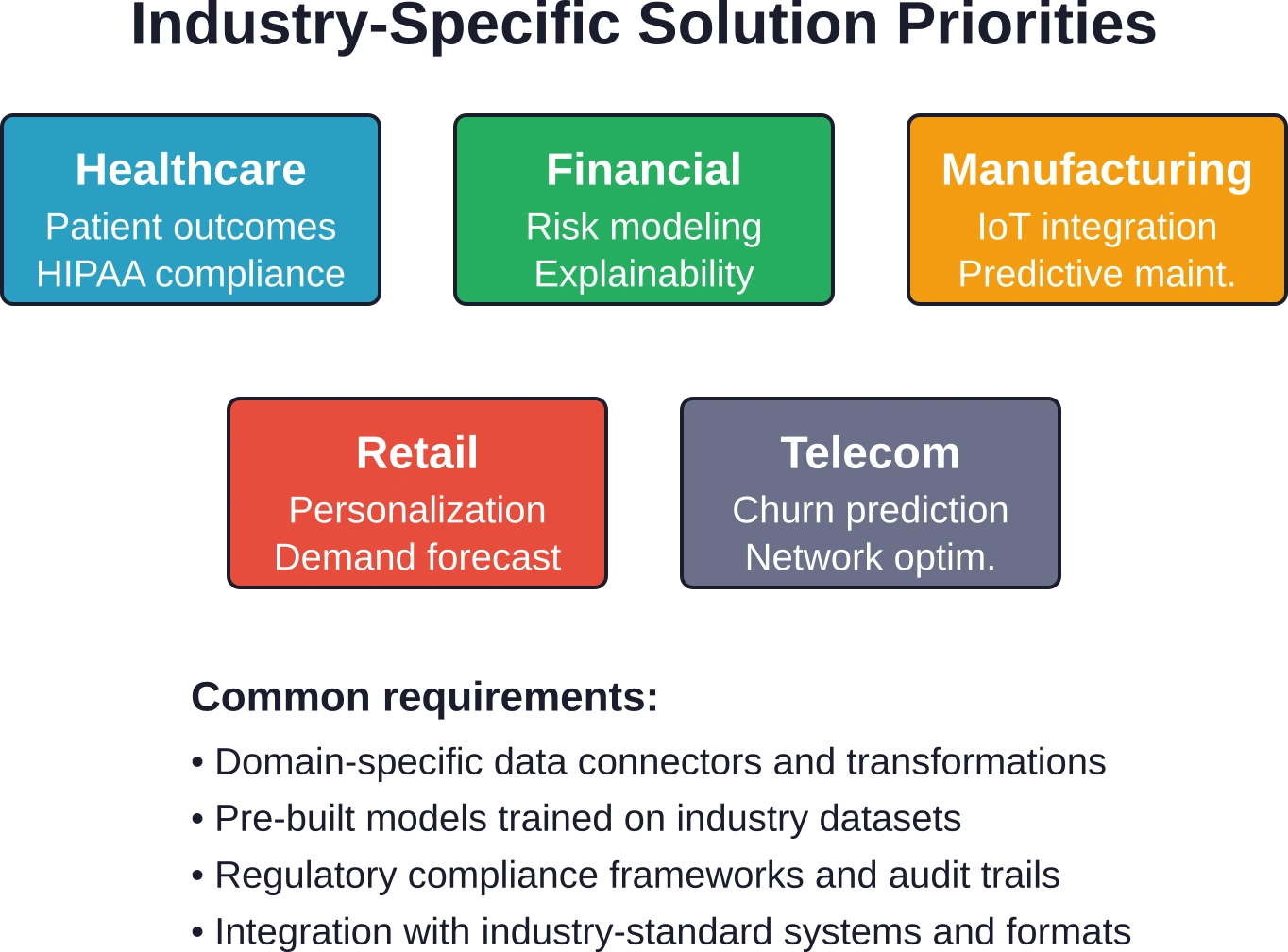
Gespecialiseerde oplossingen voor belangrijke sectoren
Hoewel algemene platformen in veel gevallen aan de behoeften voldoen, profiteren bepaalde sectoren van gespecialiseerde data science-oplossingen die zijn afgestemd op domeinspecifieke uitdagingen en wettelijke vereisten.
Gezondheidszorganalyse
Zorgorganisaties staan voor complexe beslissingen met grote gevolgen op het gebied van patiëntenzorg, toewijzing van middelen en populatiegezondheidsmanagement. Gespecialiseerde platforms integreren met elektronische patiëntendossiers, medische beeldvormingssystemen en declaratiegegevensbanken.
Voorspellende modellen identificeren patiënten met een verhoogd risico op heropname, verslechtering van hun toestand of het niet correct innemen van medicatie. Analyses van de volksgezondheid segmenteren patiëntengroepen en bevelen gerichte interventies aan. Klinische beslissingsondersteunende systemen bieden op bewijs gebaseerde aanbevelingen op het moment van zorgverlening.
Naleving van regelgeving blijft cruciaal. De HIPAA-vereisten regelen de toegang tot gegevens, anonimisering en melding van datalekken. De FDA-richtlijnen zijn van toepassing op tools voor klinische besluitvormingsondersteuning die voldoen aan de definitie van medische hulpmiddelen. Platformen gericht op de gezondheidszorg integreren deze overwegingen in hun architectuur in plaats van naleving als een bijzaak te beschouwen.
Financiële diensten
Banken, verzekeraars en beleggingsondernemingen hebben veel data science-technieken als eerste toegepast. De gespecialiseerde platforms van vandaag de dag richten zich op risicomodellering, wettelijke rapportage, fraudedetectie en algoritmische handel met financiële specifieke functies.
Mogelijkheden voor risicobeheer van modellen helpen organisaties te voldoen aan de wettelijke eisen met betrekking tot modelvalidatie, documentatie en continue monitoring. Verklaarbaarheidstools genereren auditsporen die voldoen aan de eisen van toezichthouders. Stresstestkaders evalueren de prestaties van modellen onder ongunstige omstandigheden.
De complexiteit van financiële data – meerdere tijdzones, bedrijfstransacties, uiteenlopende marktconventies – maakt domeinspecifieke oplossingen waardevol. Generieke platforms vereisen uitgebreide aanpassingen om deze nuances correct te verwerken.
Productie en toeleveringsketen
Fabrikanten gebruiken datawetenschap voor kwaliteitsvoorspelling, voorspellend onderhoud, vraagvoorspelling en optimalisatie van de toeleveringsketen. Gespecialiseerde oplossingen integreren met industriële IoT-sensoren, productie-uitvoeringssystemen en ERP-platformen (Enterprise Resource Planning).
Voorspellende onderhoudsmodellen analyseren sensorgegevens om apparatuurstoringen te voorspellen voordat ze zich voordoen. Dit maakt gepland onderhoud mogelijk tijdens geplande stilstand in plaats van noodreparaties tijdens productieruns. Kwaliteitsvoorspelling identificeert procesomstandigheden die tot defecten leiden, waardoor realtime aanpassingen mogelijk zijn.
Supply chain-analyse optimaliseert voorraadniveaus, transportroutes en productieplanningen binnen complexe netwerken van leveranciers, faciliteiten en klanten. Onderzoek toont aan dat autonome systemen steeds slechter presteren bij taken die meer dan 10 seconden uitvoeringstijd vereisen, wat het belang van geoptimaliseerde algoritmen voor realtime beslissingen in de supply chain onderstreept.
Opkomende trends die de basis vormen voor data science-oplossingen
Verschillende ontwikkelingen veranderen de manier waarop organisaties data science implementeren. Inzicht in deze trends helpt bij strategische planning en de selectie van de juiste technologie.
Multimodale AI-integratie
Traditionele datawetenschap richtte zich voornamelijk op gestructureerde data: getallen, categorieën en tijdstempels. Moderne platforms verwerken steeds vaker meerdere datavormen: tekst, afbeeldingen, video, audio en sensorstromen.
Recent onderzoek naar NeuroFusion toont een verbetering van 34% ten opzichte van bestaande multimodale benchmarks in realtime multimodale verwerking. Deze systemen verwerken gelijktijdig live data van videogesprekken, augmented reality-omgevingen en IoT-apparaten, waardoor een rijkere analyse mogelijk is dan bij benaderingen met één modaliteit.
Toepassingen in de gezondheidszorg combineren medische beeldvorming met elektronische patiëntendossiers en klinische aantekeningen. Retailsystemen analyseren productafbeeldingen, klantbeoordelingen en transactiegegevens. Productieoplossingen integreren sensoraflezingen, visuele inspectiebeelden en onderhoudslogboeken.
Geautomatiseerde data science-workflows
De trend naar automatisering strekt zich niet alleen uit tot individuele taken, maar omvat ook complete analytische workflows. Moderne platforms coördineren complexe processen: data-invoer, kwaliteitsvalidatie, feature engineering, modeltraining, evaluatie, implementatie en monitoring.
Deze end-to-end workflows verminderen de handmatige inspanning die nodig is om van ruwe data naar productiemodellen te gaan. Organisaties die voorheen weken nodig hadden om een nieuw model te implementeren, kunnen hetzelfde proces nu in dagen of uren voltooien. De snellere iteratie maakt meer experimenten mogelijk en zorgt voor een snellere reactie op veranderende omstandigheden.
HardML, een benchmark voor het evalueren van kennis op het gebied van datawetenschap en machine learning, bestaat uit 100 uitdagende meerkeuzevragen over uiteenlopende domeinen, waaronder deep learning, klassieke machine learning, natuurlijke taalverwerking, computervisie, data-engineering en statistiek. Platforms die goed presteren op dit brede scala aan onderwerpen, tonen een bredere toepasbaarheid dan platforms die geoptimaliseerd zijn voor specifieke gebruikssituaties.
Edge Analytics
Niet alle datawetenschap vindt plaats in gecentraliseerde datacenters of cloudomgevingen. Edge analytics verwerkt data op apparaten aan de rand van het netwerk, zoals smartphones, IoT-sensoren, autonome voertuigen en industriële apparatuur.
Deze aanpak biedt verschillende voordelen. De latentie daalt aanzienlijk wanneer de verwerking lokaal plaatsvindt in plaats van dat er heen en weer gereisd moet worden naar servers op afstand. De bandbreedtekosten dalen omdat er geen ruwe data verzonden hoeft te worden. De privacy verbetert omdat gevoelige informatie op het apparaat zelf verwerkt en geaggregeerd kan worden in plaats van naar externe systemen te worden verzonden.
Edge-implementatie brengt beperkingen met zich mee. Beperkte rekenkracht vereist geoptimaliseerde modellen. Intermitterende connectiviteit vereist een robuuste afhandeling van offline perioden. De diversiteit aan apparaten bemoeilijkt de implementatie en het onderhoud. Gespecialiseerde platforms pakken deze uitdagingen aan met modelcompressie, federated learning en draadloze updatefunctionaliteit.
De juiste data science-oplossingen selecteren
Met honderden beschikbare platforms en tools kan het maken van een keuze overweldigend lijken. Een gestructureerd evaluatieproces helpt bij het identificeren van oplossingen die aansluiten bij de specifieke behoeften van een organisatie.
Formuleer duidelijke doelstellingen.
Begin met het formuleren van de zakelijke problemen die moeten worden opgelost. "Data science implementeren" is geen doelstelling, maar een mogelijkheid. "Klantverloop met 15% verminderen" of "Voorraadkosten met 20% verlagen" zijn meetbare doelen die richtinggevend zijn bij de technologiekeuze.
Verschillende doelstellingen vragen om verschillende oplossingen. Verkennende analyses en managementdashboards suggereren augmented analytics-platforms. De grootschalige implementatie van machine learning in productieomgevingen wijst op AutoML- of MLOps-tools. De eisen op het gebied van compliance wijzen op governance-oplossingen.
Beoordeel de capaciteiten van de organisatie
Een eerlijke evaluatie van interne vaardigheden, middelen en processen voorkomt discrepanties tussen de complexiteit van de oplossing en de gereedheid van de organisatie. Een platform dat uitgebreide DevOps-expertise vereist, zal niet succesvol zijn in een organisatie met beperkt technisch personeel. Omgekeerd kunnen te simpele tools teams met geavanceerde vaardigheden frustreren.
Neem het data science-volwassenheidsmodel in overweging. Organisaties die net beginnen met data-analyse hebben andere tools nodig dan organisaties met gevestigde werkwijzen. Low-code platforms versnellen de time-to-value voor minder ervaren teams. Geavanceerde frameworks bieden flexibiliteit voor ervaren gebruikers.
Evalueer de integratievereisten
Data science-oplossingen werken zelden op zichzelf. Ze moeten verbinding maken met bestaande databronnen, bedrijfsapplicaties en workflowsystemen. De complexiteit van de integratie heeft een aanzienlijke invloed op de implementatietijd en de onderhoudslast op de lange termijn.
Controleer of er native connectoren beschikbaar zijn voor uw specifieke databases, SaaS-applicaties en datawarehouses. Evalueer de API-mogelijkheden voor maatwerkintegraties. Houd rekening met authenticatie- en beveiligingsprotocollen. Organisaties met complexe technische omgevingen zouden prioriteit moeten geven aan platforms met robuuste integratiekaders.
| Evaluatiecriterium | Vragen om te stellen | Invloed op de selectie |
|---|---|---|
| Bedrijfsdoelstellingen | Welke specifieke doelstellingen liggen ten grondslag aan deze investering? | Bepaalt de categorie van de benodigde oplossing. |
| Technische vaardigheden | Welke expertise is er momenteel intern aanwezig? | Beïnvloedt het haalbare complexiteitsniveau |
| Gegevensomgeving | Waar bevinden zich de relevante gegevens momenteel? | Beïnvloedt de integratie-inspanning en de architectuur. |
| Schaalvereisten | Welke datavolumes en gebruikersaantallen worden verwacht? | Geeft richting aan beslissingen over infrastructuur en vergunningen. |
| Nalevingseisen | Welke wettelijke vereisten zijn van toepassing? | Mogelijk zijn branchespecifieke of gecertificeerde platforms vereist. |
Voer proof-of-concept-testen uit.
Demonstraties van leveranciers tonen geïdealiseerde scenario's met schone data en eenvoudige gebruiksvoorbeelden. Implementatie in de praktijk brengt echter vaak complicaties aan het licht. Proof-of-concept-testen met daadwerkelijke organisatiedata bieden een veel betrouwbaardere beoordeling.
Definieer specifieke succescriteria voordat u begint. Kan het platform uw dataformaten verwerken? Levert het acceptabele prestaties op een realistische schaal? Kunnen beoogde gebruikers het platform bedienen zonder uitgebreide training? Kan het naadloos worden geïntegreerd met uw bestaande systemen?
Beperk de evaluatie tot een tijdsbestek van 4 tot 8 weken, met duidelijk omschreven resultaten. Een proof of concept dat maandenlang duurt zonder concrete resultaten op te leveren, wijst waarschijnlijk op fundamentele compatibiliteitsproblemen.
Implementatie-best practices
De keuze voor de technologie is slechts het begin. Een succesvolle implementatie vereist aandacht voor organisatorische veranderingen, acceptatie door gebruikers en operationele processen.
Begin klein en schaal geleidelijk op.
De verleiding om meteen de meest complexe en waardevolle use case aan te pakken is begrijpelijk, maar werkt meestal averechts. Complexe projecten kennen meer mogelijke mislukkingen en hebben een langere doorlooptijd. Door te beginnen met een kleinere, goed gedefinieerde use case kan het team het platform leren kennen, processen opzetten en de waarde aantonen voordat ze grotere uitdagingen aangaan.
Kies in eerste instantie projecten met duidelijke zakelijke waarde, een beheersbare omvang en toegankelijke gegevens. Succes zorgt voor momentum en vertrouwen binnen de organisatie. Vroege successen creëren ambassadeurs die de bredere acceptatie bevorderen.
Investeer in gebruikerstraining.
Zelfs het meest intuïtieve platform vereist enige leercurve. Organisaties die training als optioneel beschouwen, zien steevast een lagere acceptatiegraad en slechtere resultaten dan organisaties die investeren in gestructureerde training.
Ontwikkel trainingsprogramma's die zijn afgestemd op verschillende gebruikersrollen. Leidinggevenden hebben strategische context en geavanceerde vaardigheden nodig. Businessanalisten hebben praktische ervaring met specifieke workflows nodig. IT-medewerkers hebben inzicht in de architectuur en operationele procedures nodig.
Just-in-time training – training die wordt aangeboden wanneer gebruikers klaar zijn om nieuwe vaardigheden toe te passen – blijkt doorgaans effectiever dan generieke trainingssessies die maanden voor het daadwerkelijke gebruik plaatsvinden.
Zorg vroegtijdig voor goed bestuur.
De democratisering van datawetenschap brengt nieuwe risico's met zich mee op het gebied van datakwaliteit, modelvaliditeit en besluitvorming. Governance-kaders bieden waarborgen zonder innovatie te belemmeren.
Definieer duidelijke beleidsregels voor gegevenstoegang, modelontwikkeling, goedkeuringen voor implementatie en continue monitoring. Stel beoordelingsprocessen in die een evenwicht vinden tussen grondigheid en snelheid. Creëer documentatiestandaarden die ervoor zorgen dat werk reproduceerbaar en onderhoudbaar is.
Organisaties die pas reactief – nadat problemen zich voordoen – governance implementeren, krijgen te maken met moeilijkere gesprekken en ingrijpendere veranderingen dan organisaties die proactief kaders vaststellen.
Het meten van succes en rendement op investering (ROI).
Investeringen in datawetenschap moeten meetbare zakelijke waarde opleveren. Het definiëren en bijhouden van de juiste meetwaarden zorgt voor verantwoording en stuurt continue verbetering.
Bedrijfsresultaatmetrieken
De belangrijkste meetinstrumenten zijn direct gekoppeld aan de bedrijfsdoelstellingen. Als het doel bijvoorbeeld het verminderen van klantverlies is, meet dan het klantverliespercentage vóór en na de implementatie. Voor voorraadoptimalisatie meet je de voorraadkosten en de frequentie van voorraadtekorten. Omzetgroei, kostenbesparing en klanttevredenheid: dit zijn de belangrijkste resultaten.
Toewijzing van oorzaken kan lastig zijn. Bedrijfsresultaten hebben zelden één enkele oorzaak. Stel uitgangspunten vast vóór de implementatie, houd waar mogelijk rekening met externe factoren en wees eerlijk over de onzekerheid in de impactschattingen.
Operationele meetgegevens
Procesverbeteringen vormen een andere waardecategorie. Hoeveel tijd bespaart het analyseteam met geautomatiseerde dataverwerking? Hoeveel meer modellen worden er per kwartaal ingezet? Hoeveel sneller krijgen zakelijke gebruikers antwoorden op analytische vragen?
Deze efficiëntiewinsten zijn wellicht niet direct terug te vinden in de financiële overzichten, maar ze maken middelen vrij voor waardevoller werk en versnellen de besluitvormingsprocessen.
Adoptiestatistieken
Technologie die niet gebruikt wordt, levert geen waarde op. Houd actieve gebruikers, queryvolumes, modellen in productie en andere gebruiksindicatoren bij. Een lage adoptie duidt op lacunes in de training, gebruiksproblemen of een gebrek aan afstemming op de werkelijke behoeften.
Vraag gebruikers regelmatig naar hun tevredenheid, knelpunten en gewenste nieuwe functies. Kwalitatieve feedback onthult vaak verbeterpunten die met kwantitatieve gegevens niet aan het licht komen.
Veelvoorkomende implementatie-uitdagingen
Inzicht in veelvoorkomende obstakels helpt organisaties bij het plannen van strategieën om deze te beperken, in plaats van verrast te worden door problemen die voorkomen hadden kunnen worden.
Gegevenskwaliteit en -toegankelijkheid
Organisaties onderschatten steevast de uitdagingen op het gebied van data-gereedheid. Verouderde systemen met inconsistente formaten. Ontbrekende waarden en invoerfouten. Onduidelijke definities en ongedocumenteerde transformaties. Geïsoleerde databronnen met incompatibele schema's.
Data science-platformen kunnen fundamenteel gebrekkige data niet repareren. Reserveer tijd en middelen voor het verbeteren van de datakwaliteit als onderdeel van de implementatieplanning. Stel meetbare criteria voor datakwaliteit en verantwoording vast. Overweeg initiatieven voor master data management als de problemen wijdverspreid zijn.
Vaardigheidstekorten
Zelfs low-code platforms vereisen analytisch denken en domeinkennis. Organisaties ontdekken vaak dat het democratiseren van de toegang tot tools niet automatisch leidt tot een cultuur van datagestuurde besluitvorming.
Pak tekorten aan vaardigheden aan door middel van training, aanwerving of samenwerking. Overweeg om data science-experts binnen bedrijfsonderdelen te plaatsen om begeleiding en ondersteuning te bieden. Creëer kennisgemeenschappen waar gebruikers kennis en best practices delen.
Integratiecomplexiteit
Wat tijdens de proof-of-conceptfase eenvoudig leek, blijkt in de praktijk vaak ingewikkeld. Beveiligingsvereisten beperken de netwerktoegang. Beleid voor gegevensbeheer vereist goedkeuringsworkflows. Bestaande applicaties missen API's. De prestaties nemen af op productieschaal.
Betrek IT- en beveiligingsteams vroegtijdig bij de planning. Reserveer voldoende tijd voor integratiewerkzaamheden. Test op realistische schaal voordat de implementatie live gaat. Zorg voor noodplannen voor onverwachte technische problemen.
Toekomstige richtingen
Verschillende ontwikkelingen in de nabije toekomst zullen de oplossingen voor datawetenschap in de komende jaren vormgeven.
Toegenomen automatisering
Automatisering zal zich verder uitbreiden naar taken die momenteel menselijk oordeel vereisen. AutoML evolueert naar AutoDS – geautomatiseerde datawetenschap die de volledige levenscyclus bestrijkt, van probleemdefinitie tot implementatie en monitoring. Organisaties zullen bedrijfsdoelstellingen en -beperkingen specificeren, en systemen zullen analytische benaderingen voorstellen, deze uitvoeren en de resultaten meten.
Dit sluit menselijke betrokkenheid niet uit, maar verschuift de focus van technische uitvoering naar strategische beslissingen, interpretatie en bestuur.
Betere verklaarbaarheid
Regelgeving en ethische bezwaren zorgen voor een groeiende vraag naar beter interpreteerbare modellen. Voorspellingen die niet direct met de werkelijkheid te maken hebben, worden steeds minder acceptabel in sectoren met grote gevolgen zoals de gezondheidszorg, de financiële wereld en het strafrecht.
Onderzoek blijft zich richten op het verbeteren van verklaringstechnieken die werken met complexe modellen. Counterfactuele verklaringen laten zien wat er zou moeten veranderen voor een andere voorspelling. Invloedsfuncties identificeren welke trainingsvoorbeelden de grootste invloed hadden op een specifieke voorspelling. Aandachtsmechanismen onthullen op welke input het model zich concentreert.
Platformen zullen deze technieken standaard integreren, waardoor uitleg een standaardfunctie wordt in plaats van een gespecialiseerde toevoeging.
Gedistribueerd en gefedereerd leren
Privacyregelgeving en eisen op het gebied van gegevenssoevereiniteit compliceren gecentraliseerde gegevensaggregatie. Federated learning traint modellen over gedistribueerde datasets zonder de onderliggende gegevens te verplaatsen.
Zorgorganisaties kunnen samenwerken aan modelontwikkeling zonder patiëntendossiers te delen. Financiële instellingen kunnen fraudedetectie verbeteren door collectieve intelligentie te gebruiken en tegelijkertijd transactiegegevens afgeschermd te houden. Fabrikanten kunnen hun prestaties vergelijken met die van concurrenten zonder vertrouwelijke informatie prijs te geven.
Deze architectonische verschuiving vereist nieuwe tools, maar pakt fundamentele belemmeringen aan voor collaboratieve analyses in privacygevoelige domeinen.
Veelgestelde vragen
Wat is het verschil tussen data science-platformen en business intelligence-tools?
Business intelligence-tools richten zich primair op rapportage en visualisatie van historische gegevens. Data science-platforms leggen de nadruk op voorspellende modellen, machine learning en geavanceerde analyses. Moderne oplossingen vervagen deze grenzen steeds meer, maar BI-tools zijn over het algemeen gericht op beschrijvende analyses, terwijl data science-platforms voorspellende en prescriptieve mogelijkheden bieden.
Wat zijn de kosten voor het implementeren van data science-oplossingen?
De kosten variëren enorm, afhankelijk van het gekozen platform, de schaal van de implementatie en de behoeften van de organisatie. Cloudgebaseerde beheerde services rekenen doorgaans op basis van gebruik: rekenuren, verwerkte data en API-aanroepen. Enterprise-licenties kosten tussen de tienduizenden en miljoenen dollars per jaar. Open-source oplossingen vereisen infrastructuur- en personeelskosten in plaats van licentiekosten. Raadpleeg de officiële websites van de aanbieders voor de actuele prijzen, aangezien de modellen regelmatig wijzigen.
Moeten we datawetenschappers inhuren om deze platforms te gebruiken?
Het hangt af van het platform en uw doelstellingen. Low-code augmented analytics-platforms stellen zakelijke gebruikers in staat om veel analyses uit te voeren zonder programmeerkennis. AutoML-tools verminderen de specialistische expertise die nodig is voor modelontwikkeling. Complexe projecten, maatwerkoplossingen en implementaties in productieomgevingen profiteren echter doorgaans van ervaren datawetenschappers. Veel organisaties hanteren een hybride aanpak: ze stellen zakelijke gebruikers in staat om routinewerk uit te voeren, terwijl gespecialiseerd personeel wordt ingezet voor geavanceerde projecten.
Hoe lang duurt het voordat de resultaten van investeringen in datawetenschap zichtbaar zijn?
De tijdslijn varieert afhankelijk van de projectomvang en de gereedheid van de organisatie. Eenvoudige use cases met schone, toegankelijke data kunnen binnen enkele weken resultaten opleveren. Complexe implementaties met meerdere systemen, maatwerkontwikkeling of ingrijpende organisatorische veranderingen kunnen 6 tot 12 maanden in beslag nemen voordat er substantiële waarde wordt gegenereerd. Beginnen met kleinere proof-of-conceptprojecten helpt om sneller waarde aan te tonen en momentum te creëren voor grotere initiatieven.
Welke sectoren profiteren het meest van data science-oplossingen?
Vrijwel elke sector ziet de waarde van datawetenschap in, maar sommige sectoren ervaren een bijzonder grote impact. De financiële sector gebruikt geavanceerde analyses voor risicobeoordeling, fraudedetectie en algoritmische handel. De gezondheidszorg past voorspellende modellen toe op patiëntenzorg, operationele efficiëntie en geneesmiddelenontwikkeling. De detailhandel benut datawetenschap voor personalisatie, vraagvoorspelling en optimalisatie van de toeleveringsketen. De maakindustrie gebruikt voorspellend onderhoud en kwaliteitscontrole. De telecommunicatiesector maakt gebruik van datawetenschap voor het voorspellen van klantverloop en netwerkoptimalisatie.
Hoe zorgen we ervoor dat onze data science-initiatieven voldoen aan de regelgeving?
Compliance vereist aandacht voor gegevensverwerking, modelbeheer en documentatie. Gebruik platforms met ingebouwde compliancefuncties voor uw branche – HIPAA voor de gezondheidszorg, SOC 2 voor financiële dienstverlening, GDPR voor Europese activiteiten. Implementeer raamwerken voor gegevensbeheer die de herkomst van gegevens traceren, toegangscontroles afdwingen en auditsporen bijhouden. Documenteer de processen voor modelontwikkeling, -validatie en -monitoring. Betrek juridische en compliance-teams vroegtijdig bij de projectplanning. Overweeg gespecialiseerde governanceplatforms als de wettelijke vereisten uitgebreid zijn.
Kunnen data science-oplossingen samenwerken met onze bestaande systemen?
De meeste moderne platforms bieden uitgebreide integratiemogelijkheden via vooraf gebouwde connectors, API's en tools voor data-import en -export. Controleer of het platform dat u overweegt native ondersteuning biedt voor uw specifieke databases, datawarehouses, bedrijfsapplicaties en bestandsformaten. De complexiteit van integratie varieert aanzienlijk: cloudgebaseerde oplossingen maken vaak gemakkelijker verbinding met andere cloudservices, terwijl on-premise implementaties mogelijk aangepaste middleware vereisen. Evalueer de integratievereisten tijdens de platformselectie in plaats van compatibiliteitsproblemen te ontdekken nadat u een keuze heeft gemaakt.
Conclusie: Het opbouwen van datagestuurde capaciteiten
Data science-oplossingen zijn geëvolueerd van experimentele technologieën tot essentiële bedrijfsinfrastructuur. Organisaties in alle sectoren zijn nu afhankelijk van deze platforms om effectief te kunnen concurreren, efficiënt te werken en klanten beter van dienst te zijn.
De meest succesvolle implementaties hebben gemeenschappelijke kenmerken. Ze beginnen met duidelijke bedrijfsdoelstellingen in plaats van technologie omwille van de technologie zelf. Ze stemmen de complexiteit van de oplossing af op de mogelijkheden en volwassenheid van de organisatie. Ze investeren in datakwaliteit, gebruikerstraining en governancekaders naast de implementatie van de technologie. Ze meten de resultaten nauwkeurig en passen zich aan op basis van de bevindingen.
Kijk, geen enkel platform lost elk probleem op of is geschikt voor elke organisatie. De "beste" oplossing hangt af van specifieke behoeften, beperkingen en doelstellingen. Augmented analytics-platforms democratiseren inzichten, maar vervangen geen diepgaande analytische expertise. AutoML versnelt de modelontwikkeling, maar vereist goede data en goed gedefinieerde problemen. Realtime systemen maken direct handelen mogelijk, maar brengen operationele complexiteit met zich mee. Gespecialiseerde brancheoplossingen spelen in op domeinspecifieke eisen, maar kunnen duurder zijn dan algemene platforms.
Het data science-landschap blijft zich razendsnel ontwikkelen. Nieuwe mogelijkheden ontstaan. De prestaties verbeteren. De prijzen veranderen. Organisaties die duidelijke evaluatiecriteria vaststellen, grondig testen en flexibel blijven in hun technologische keuzes, positioneren zich om zich aan te passen aan de voortschrijdende ontwikkelingen in het vakgebied.
Bent u klaar om de manier waarop uw organisatie data gebruikt te transformeren? Begin met het identificeren van één waardevolle use case met toegankelijke data en duidelijke succesindicatoren. Evalueer platforms die passen bij uw technische omgeving en vaardigheidsniveau. Voer praktijktests uit met echte data. Bouw van daaruit verder.
Organisaties die data sneller en effectiever omzetten in actie, behalen steeds vaker een concurrentievoordeel. Data science-oplossingen bieden de tools, maar succes vereist toewijding aan organisatorische verandering, continu leren en op bewijs gebaseerde besluitvorming.