Resumen rápido: Las principales soluciones de ciencia de datos para 2026 incluyen plataformas de análisis aumentado que democratizan el acceso a la información en toda la organización, herramientas automatizadas de aprendizaje automático que aceleran el desarrollo de modelos, sistemas de análisis en tiempo real para la toma de decisiones instantánea y marcos de gobernanza de datos basados en IA. Estas soluciones permiten a las empresas extraer valor de conjuntos de datos complejos, al tiempo que reducen las barreras técnicas tradicionalmente asociadas con el análisis avanzado.
Hoy en día, las organizaciones se enfrentan a un desafío sin precedentes: montañas de datos, pero una capacidad limitada para extraer información útil. La brecha entre la recopilación de datos y la inteligencia práctica nunca ha sido mayor.
Las soluciones de ciencia de datos salvan esa brecha. Transforman la información bruta en decisiones estratégicas, ventajas competitivas y resultados empresariales medibles. Pero con cientos de plataformas, herramientas y marcos de trabajo disponibles, elegir las soluciones adecuadas requiere comprender qué funciona realmente en 2026.
Esta guía analiza las soluciones de ciencia de datos más eficaces que están transformando las industrias. Desde el análisis aumentado, que facilita el acceso a los datos a equipos no técnicos, hasta el aprendizaje automático automatizado, que acelera los plazos de implementación, estas tecnologías representan la vanguardia en su aplicación práctica.
La evolución de las soluciones de ciencia de datos
La ciencia de datos ha madurado significativamente desde sus inicios, caracterizados por algoritmos personalizados e ingeniería de características manual. Las soluciones modernas hacen hincapié en la accesibilidad, la automatización y la integración con los procesos de negocio existentes.
Este cambio refleja una transformación fundamental en la forma en que las organizaciones abordan el análisis de datos. En lugar de depender exclusivamente de científicos de datos especializados que trabajan de forma aislada, las empresas ahora implementan plataformas que facilitan la colaboración entre departamentos. Los equipos de marketing ejecutan modelos predictivos. El personal de operaciones optimiza la logística con aprendizaje automático. Los departamentos de finanzas automatizan la evaluación de riesgos.
Esta democratización no se produjo por casualidad. Los proveedores de tecnología reconocieron que la mayoría de las empresas no podían contratar suficientes científicos de datos para satisfacer la demanda.
Los estándares que rigen estos sistemas también han evolucionado. El marco NIST SP 800-181 estableció áreas de competencia para roles de ciberseguridad y ciencia de datos. La versión actual (2.2.0) se publicó el 28 de abril de 2025, y la revisión de 2020 (NIST SP 800-181r1) se publicó anteriormente para roles de ciberseguridad y ciencia de datos. El documento NISTIR 8355 (publicado en junio de 2023) proporciona orientación complementaria sobre áreas de competencia para preparar una fuerza laboral de ciberseguridad lista para el empleo, creando vías más claras para el desarrollo de la fuerza laboral y la implementación de tecnología.

Cree soluciones de ciencia de datos con IA superior
IA superior Desarrolla aplicaciones basadas en IA y productos de software a medida utilizando modelos de aprendizaje automático, análisis de datos, PLN, visión artificial, BI y análisis de macrodatos. Su trabajo abarca proyectos desde la fase de descubrimiento y revisión de datos hasta el desarrollo del producto mínimo viable (MVP), la integración y la evaluación de resultados.
Para las empresas que evalúan soluciones de ciencia de datos, esto puede ayudar a pasar de datos dispersos e ideas vagas a herramientas funcionales que respalden la previsión, la automatización y la toma de decisiones más claras.
¿Necesitas una solución de ciencia de datos diseñada para flujos de trabajo reales?
AI Superior puede ayudar con:
- Creación de soluciones personalizadas de ciencia de datos
- desarrollo de modelos de aprendizaje automático y análisis
- Probar ideas mediante el desarrollo de PoC o MVP.
- Integración de la IA en los sistemas cotidianos
👉 Contacta con IA Superior para hablar sobre su proyecto.
Analítica aumentada: Haciendo que los datos sean accesibles
La analítica aumentada representa uno de los avances más importantes de los últimos años. Estas plataformas utilizan el aprendizaje automático para automatizar la preparación de datos, la generación de información y la explicación, tareas que tradicionalmente requerían profundos conocimientos estadísticos.
La propuesta de valor principal es simple: los usuarios empresariales formulan preguntas en lenguaje natural y el sistema gestiona la complejidad técnica en segundo plano. Sin consultas SQL. Sin tablas dinámicas. Sin complicaciones con las herramientas de visualización.
Pero, ¿funciona realmente? En la práctica, sí, con algunas salvedades. La analítica aumentada destaca en el análisis exploratorio y la elaboración de informes rutinarios. Los gerentes de marketing pueden identificar qué segmentos de clientes muestran una disminución en su participación. Los analistas de la cadena de suministro pueden detectar anomalías en el inventario. Los directores de ventas pueden pronosticar el rendimiento trimestral.
Según el análisis de Top Data Science Solutions, se espera que el mercado de análisis aumentado crezca hasta alcanzar los 102.780 millones de dólares en 2030, con una tasa de crecimiento anual compuesta (CAGR) del 28,091%. Este crecimiento refleja una adopción empresarial genuina, no solo la publicidad exagerada de los proveedores.
Capacidades clave de la analítica aumentada moderna
Las plataformas líderes comparten varias características esenciales. La preparación automatizada de datos se encarga de la limpieza, transformación e integración desde múltiples fuentes. Las interfaces de consulta en lenguaje natural aceptan preguntas escritas o habladas en lenguaje cotidiano. Los motores de visualización inteligentes seleccionan los tipos de gráficos adecuados según las características de los datos y el contexto analítico.
La capa explicativa es quizás la más importante. Cuando una plataforma identifica una tendencia o anomalía, no solo muestra un gráfico, sino que genera una explicación que detalla qué cambió, por qué es relevante y qué acciones son pertinentes. Estas explicaciones hacen que la información sea comprensible para personas sin formación estadística.
En realidad, la analítica aumentada no reemplazará a los analistas expertos a corto plazo. Las investigaciones complejas, el modelado personalizado y la interpretación estratégica aún requieren la experiencia humana. Sin embargo, para las tareas analíticas más comunes, como la exploración y la elaboración de informes rutinarias, estas plataformas ofrecen mejoras sustanciales en la eficiencia.
Consideraciones para la implementación
Para implementar con éxito la analítica aumentada, es fundamental prestar atención a la gobernanza de datos, la capacitación de los usuarios y la arquitectura de integración. La plataforma necesita acceso a fuentes de datos limpias y bien estructuradas. Los usuarios necesitan suficiente contexto para formular buenas preguntas e interpretar los resultados adecuadamente. Los equipos de TI necesitan protocolos claros para la seguridad, el control de acceso y el mantenimiento del sistema.
Las organizaciones que consideran la analítica aumentada como una implementación puramente técnica suelen tener dificultades. Aquellas que la abordan como una iniciativa de gestión del cambio —con el respaldo de la alta dirección, usuarios clave y un despliegue iterativo— logran tasas de adopción mucho más elevadas.
Plataformas de aprendizaje automático automatizado
El aprendizaje automático automatizado (AutoML) aborda un obstáculo diferente: el tiempo y la experiencia necesarios para desarrollar, ajustar e implementar modelos predictivos. Los proyectos tradicionales de aprendizaje automático implican un extenso trabajo manual: ingeniería de características, selección de algoritmos, ajuste de hiperparámetros y pruebas de validación.
Las plataformas AutoML automatizan gran parte de este proceso. Los científicos de datos especifican la variable objetivo y las métricas de éxito, y el sistema experimenta con diferentes algoritmos, combinaciones de características y configuraciones de parámetros. El resultado: modelos listos para producción en horas o días, en lugar de semanas o meses.
Las evaluaciones comparativas recientes muestran que la brecha de rendimiento entre las plataformas comerciales basadas en API y las alternativas de código abierto continúa reduciéndose. El rendimiento varía según la plataforma.
Lo que AutoML hace bien
AutoML destaca en escenarios con datos estructurados y objetivos de predicción claros. La predicción de la deserción de clientes, la previsión de la demanda, la detección de fraudes y la predicción de fallos en equipos son aplicaciones que suelen implicar datos tabulares y resultados bien definidos.
Las plataformas gestionan automáticamente la ingeniería de características, probando transformaciones como características polinómicas, términos de interacción y estrategias de agrupamiento. Evalúan decenas o cientos de combinaciones de algoritmos, desde modelos lineales hasta potenciación de gradiente y redes neuronales. La optimización de hiperparámetros utiliza técnicas como la optimización bayesiana o algoritmos evolutivos para encontrar configuraciones que maximicen el rendimiento.
Los flujos de trabajo de implementación han mejorado drásticamente. Muchas plataformas ahora generan puntos finales en contenedores que se integran directamente con las aplicaciones existentes. Un equipo de marketing puede implementar un modelo de valor de vida del cliente que califica a cada nuevo cliente potencial en tiempo real, sin necesidad de programación personalizada.
Limitaciones y mejores prácticas
AutoML no es magia. Funciona mejor cuando el problema está claramente definido, los datos son razonablemente limpios y la relación entre las características y el objetivo se puede aprender a partir de patrones históricos. Presenta dificultades en situaciones novedosas, entornos que cambian rápidamente y tareas que requieren ingeniería de características específica del dominio.
La crítica a la "caja negra" tiene cierta validez. Si bien las plataformas modernas proporcionan puntuaciones de importancia de las características y gráficos de dependencia parcial, comprender con exactitud por qué un modelo realiza predicciones específicas puede resultar difícil. Las industrias reguladas podrían requerir enfoques más interpretables.
La mejor práctica consiste en usar AutoML para acelerar el desarrollo inicial, y luego contar con profesionales experimentados que revisen, validen y, si es necesario, perfeccionen los resultados. Imagínelo como un científico de datos junior altamente productivo que se encarga del trabajo rutinario, liberando al personal senior para que se enfoque en desafíos estratégicos.
Sistemas de análisis en tiempo real
El procesamiento por lotes satisfizo las necesidades analíticas durante décadas. Las organizaciones recopilaban datos a lo largo del día, ejecutaban tareas de procesamiento durante la noche y revisaban los paneles de control a la mañana siguiente. Ese ciclo funcionaba bien cuando el ritmo de la actividad empresarial era más lento.
Ya no es así. Los sistemas de análisis en tiempo real procesan datos en streaming de forma continua, ofreciendo información valiosa con una latencia de segundos o milisegundos en lugar de horas. Las empresas de servicios financieros detectan transacciones fraudulentas antes de que se liquiden. Las plataformas de comercio electrónico ajustan sus recomendaciones a medida que evoluciona el comportamiento de navegación. Las fábricas identifican problemas de calidad antes de que los productos defectuosos salgan de la línea de producción.
La arquitectura técnica difiere significativamente de los sistemas por lotes tradicionales. Motores de procesamiento de flujo como Apache Kafka, Apache Flink y servicios nativos de la nube gestionan la ingesta y transformación de datos. Las bases de datos en memoria almacenan el estado actual para consultas instantáneas. Las arquitecturas orientadas a eventos activan acciones automáticamente cuando se cumplen ciertas condiciones.
Casos de uso que impulsan la adopción
Diversas categorías de aplicaciones impulsan la adopción de análisis en tiempo real. La detección de fraudes requiere una evaluación inmediata de las transacciones en función de patrones de comportamiento; retrasos de tan solo unos minutos pueden dar lugar a compras fraudulentas. Los sistemas de negociación algorítmica toman decisiones de compra/venta en microsegundos basándose en datos de mercado y modelos predictivos.
La monitorización operativa utiliza análisis en tiempo real para realizar un seguimiento del estado del sistema, el rendimiento de las aplicaciones y las métricas de la infraestructura. Los equipos de TI identifican y resuelven los problemas antes de que afecten a los usuarios. Los flujos de trabajo de DevOps incorporan la monitorización continua en los procesos de implementación.
Los motores de personalización actualizan las recomendaciones al instante según el comportamiento del usuario. Un cliente que busca abrigos de invierno ve accesorios relevantes. Un lector que termina de leer un artículo recibe sugerencias alineadas con sus intereses. Estas experiencias requieren una latencia mínima para ofrecer una respuesta fluida.
Complejidad de la implementación
Los sistemas de análisis en tiempo real son considerablemente más complejos que las alternativas por lotes. La arquitectura distribuida plantea desafíos en cuanto a la consistencia de los datos, la tolerancia a fallos y la monitorización operativa. Los equipos necesitan experiencia en marcos de procesamiento de flujos de datos, diseño de sistemas distribuidos y optimización del rendimiento.
Las estructuras de costos también difieren. Los sistemas en tiempo real requieren recursos continuos de computación y almacenamiento, no solo durante los períodos de procesamiento por lotes. Los proveedores de servicios en la nube ofrecen servicios gestionados que simplifican la implementación, pero cobran por el rendimiento sostenido. Las organizaciones deben evaluar cuidadosamente si los casos de uso específicos justifican la complejidad y el costo adicionales.
Dicho esto, el umbral para considerar un sistema como "en tiempo real" varía según la aplicación. No todos los casos de uso requieren una latencia de milisegundos. Muchos escenarios empresariales funcionan bien con un procesamiento "casi en tiempo real" que ofrece resultados en 30 segundos o unos pocos minutos. A menudo, resulta más conveniente comenzar con arquitecturas más sencillas y añadir complejidad según sea necesario, en lugar de diseñar desde el principio para requisitos de rendimiento extremos.
Soluciones de gobernanza de datos basadas en IA
La gobernanza de datos puede parecer aburrida hasta que uno se enfrenta a las consecuencias de la mala calidad de los datos, la falta de claridad en la propiedad o las infracciones normativas. Las organizaciones tienen dificultades para mantener los catálogos de datos, aplicar las políticas de acceso, rastrear el origen de los datos y garantizar el cumplimiento normativo a medida que aumentan el volumen y la complejidad de los datos.
Las soluciones de gobernanza basadas en IA automatizan muchas tareas tradicionalmente manuales. El aprendizaje automático clasifica los activos de datos, identifica información confidencial, recomienda etiquetas de metadatos y detecta anomalías en los patrones de uso. El procesamiento del lenguaje natural extrae información relevante de la documentación y sugiere mejoras en las definiciones de datos.
Los recientes avances en algoritmos de equidad demuestran su potencial. Las investigaciones demuestran la reducción del sesgo 30%, evaluada mediante ajustes de equidad independientes del dominio que funcionan transversalmente en conjuntos de datos, desde el sector bancario hasta el de la medicina. Estas técnicas ayudan a las organizaciones a identificar y mitigar el sesgo algorítmico antes de que los modelos lleguen a producción.
Capacidades básicas de gobernanza
Las plataformas de gobernanza modernas ofrecen varias funciones esenciales. El descubrimiento automatizado de datos rastrea repositorios, bases de datos y sistemas de archivos para crear catálogos completos de los activos de datos disponibles. Los motores de clasificación etiquetan los datos con niveles de sensibilidad, dominios comerciales y métricas de calidad.
El seguimiento del linaje permite rastrear los datos desde su origen, pasando por las transformaciones, hasta su consumo final. Cuando un informe muestra valores inesperados, los analistas pueden rastrear el proceso para identificar el origen de los problemas. Si los auditores regulatorios preguntan cómo se calcularon ciertas cifras, existe documentación que explica toda la cadena de procesamiento.
La automatización del control de acceso aplica políticas basadas en la clasificación de datos, los roles de usuario y factores contextuales. El personal de marketing puede acceder a la información de contacto de los clientes, pero no a los detalles de pago. Los analistas de regiones específicas solo ven los datos relevantes para su ubicación geográfica. Los contratistas reciben permisos limitados que caducan automáticamente.
Cumplimiento de los requisitos reglamentarios
Los marcos normativos como el RGPD, la CCPA y la HIPAA imponen requisitos específicos en materia de gestión, retención y derechos de los datos. Las plataformas de gobernanza ayudan a las organizaciones a cumplir con estas obligaciones mediante la detección automatizada de información personal, el seguimiento del consentimiento y la gestión de las solicitudes de eliminación.
El Marco de Big Data del NIST, finalizado en 2019, proporciona orientación arquitectónica para las organizaciones que desarrollan capacidades de análisis a gran escala. Aborda consideraciones de seguridad, privacidad y gobernanza, además de patrones de implementación técnica. Las organizaciones pueden consultar este marco al diseñar programas de gobernanza que respalden tanto el cumplimiento normativo como los objetivos comerciales.
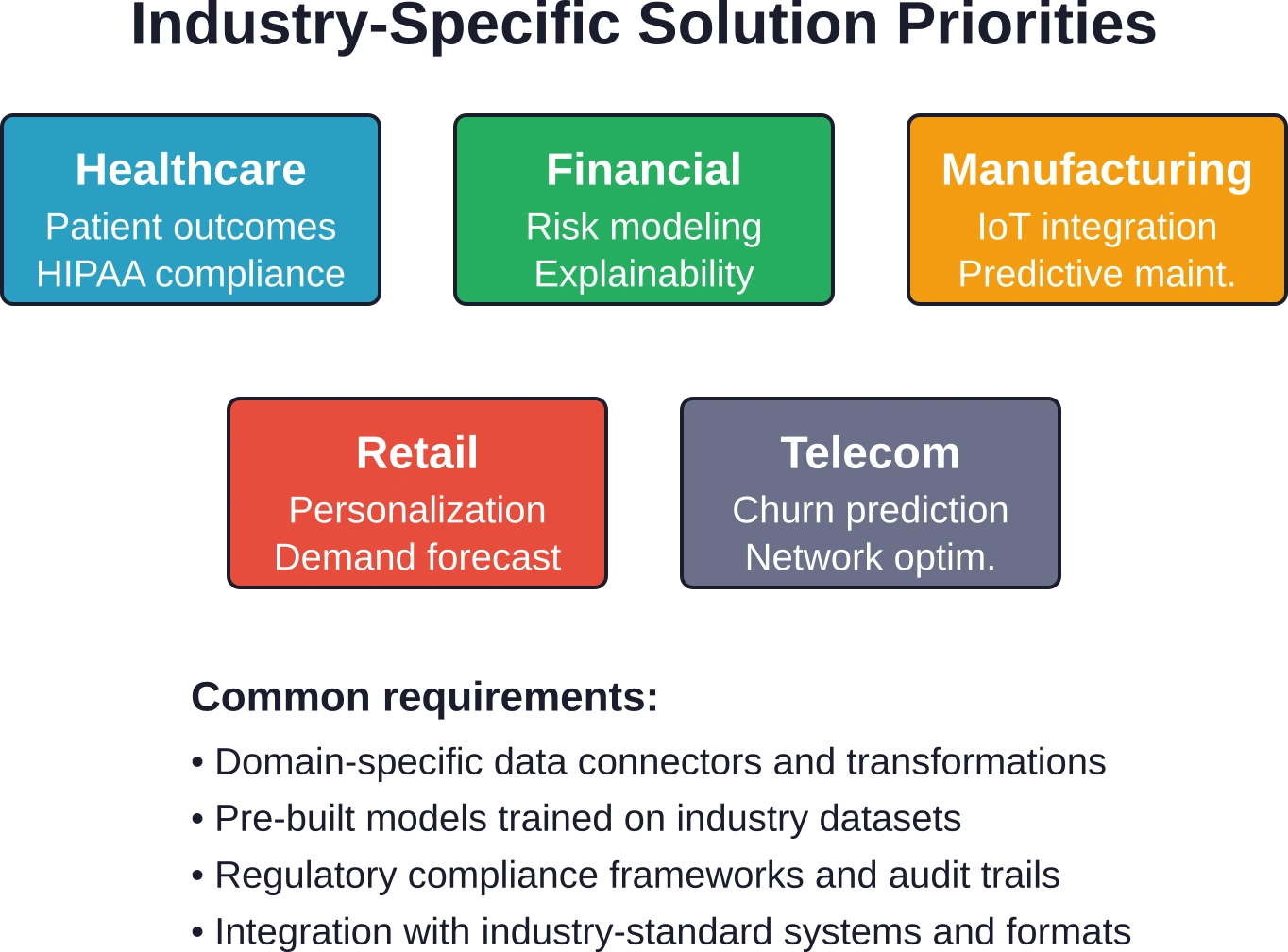
Soluciones especializadas para sectores clave
Si bien las plataformas de propósito general satisfacen muchas necesidades, ciertas industrias se benefician de soluciones de ciencia de datos especializadas, adaptadas a los desafíos específicos del sector y a los requisitos normativos.
Análisis sanitario
Las organizaciones sanitarias se enfrentan a decisiones complejas y de gran trascendencia en torno a la atención al paciente, la asignación de recursos y la gestión de la salud poblacional. Las plataformas especializadas se integran con los registros médicos electrónicos, los sistemas de diagnóstico por imagen y las bases de datos de reclamaciones.
Los modelos predictivos identifican a los pacientes con riesgo de reingreso, deterioro o incumplimiento terapéutico. El análisis de datos de salud poblacional segmenta a los pacientes y recomienda intervenciones específicas. Los sistemas de apoyo a la toma de decisiones clínicas proporcionan recomendaciones basadas en la evidencia en el punto de atención.
El cumplimiento normativo sigue siendo fundamental. Los requisitos de HIPAA rigen el acceso a los datos, la anonimización y la notificación de violaciones de seguridad. Las directrices de la FDA se aplican a las herramientas de apoyo a la toma de decisiones clínicas que cumplen con la definición de dispositivos médicos. Las plataformas centradas en la atención médica integran estas consideraciones en su arquitectura, en lugar de tratar el cumplimiento normativo como algo secundario.
Servicios financieros
Los bancos, las aseguradoras y las empresas de inversión fueron pioneras en muchas técnicas de ciencia de datos. Las plataformas especializadas actuales abordan el modelado de riesgos, la presentación de informes regulatorios, la detección de fraudes y el comercio algorítmico con funcionalidades específicas para el sector financiero.
Las capacidades de gestión de riesgos de modelos ayudan a las organizaciones a cumplir con las expectativas regulatorias en materia de validación, documentación y monitoreo continuo de modelos. Las herramientas de explicabilidad generan registros de auditoría que satisfacen los requisitos de los examinadores. Los marcos de pruebas de estrés evalúan el rendimiento del modelo en escenarios adversos.
La complejidad de los datos financieros —múltiples zonas horarias, operaciones corporativas, diversas convenciones de mercado— hace que las soluciones especializadas sean valiosas. Las plataformas genéricas requieren una amplia personalización para gestionar correctamente estos matices.
Fabricación y cadena de suministro
Los fabricantes utilizan la ciencia de datos para la predicción de la calidad, el mantenimiento predictivo, la previsión de la demanda y la optimización de la cadena de suministro. Las soluciones especializadas se integran con sensores de IoT industrial, sistemas de ejecución de fabricación y plataformas de planificación de recursos empresariales.
Los modelos de mantenimiento predictivo analizan los datos de los sensores para pronosticar fallas en los equipos antes de que ocurran, lo que permite programar el mantenimiento durante los tiempos de inactividad planificados en lugar de realizar reparaciones de emergencia durante las operaciones de producción. La predicción de calidad identifica las condiciones del proceso que provocan defectos, lo que permite realizar ajustes en tiempo real.
El análisis de la cadena de suministro optimiza los niveles de inventario, las rutas de transporte y los cronogramas de producción en redes complejas de proveedores, instalaciones y clientes. Las investigaciones demuestran que los agentes autónomos degradan progresivamente su rendimiento en tareas que requieren más de 10 segundos de ejecución, lo que subraya la importancia de los algoritmos optimizados para la toma de decisiones en tiempo real en la cadena de suministro.
Tendencias emergentes que dan forma a las soluciones de ciencia de datos
Diversos avances están transformando la manera en que las organizaciones abordan la implementación de la ciencia de datos. Comprender estas tendencias facilita la planificación estratégica y la selección de tecnología.
Integración multimodal de IA
La ciencia de datos tradicional se centraba principalmente en datos estructurados: números, categorías y marcas de tiempo. Las plataformas modernas manejan cada vez más múltiples modalidades de datos: texto, imágenes, vídeo, audio y flujos de sensores.
Investigaciones recientes sobre NeuroFusion demuestran una mejora de 34% con respecto a los puntos de referencia multimodales existentes en el procesamiento multimodal en tiempo real. Estos sistemas procesan datos en vivo de videollamadas, entornos de realidad aumentada y dispositivos IoT simultáneamente, lo que permite un análisis más completo que los enfoques de modalidad única.
Las aplicaciones sanitarias combinan imágenes médicas con historiales clínicos electrónicos y notas clínicas. Los sistemas de venta minorista analizan conjuntamente imágenes de productos, reseñas de clientes y datos de transacciones. Las soluciones de fabricación integran lecturas de sensores, imágenes de inspección visual y registros de mantenimiento.
Flujos de trabajo automatizados para la ciencia de datos
La tendencia hacia la automatización se extiende más allá de las tareas individuales y abarca flujos de trabajo analíticos completos. Las plataformas modernas orquestan secuencias complejas: ingesta de datos, validación de calidad, ingeniería de características, entrenamiento de modelos, evaluación, implementación y monitorización.
Estos flujos de trabajo integrales reducen el esfuerzo manual necesario para pasar de los datos brutos a los modelos de producción. Las organizaciones que antes necesitaban semanas para implementar un nuevo modelo ahora pueden completar el mismo proceso en días u horas. La iteración más rápida permite una mayor experimentación y una respuesta más ágil a las condiciones cambiantes.
HardML, una herramienta de evaluación comparativa para el conocimiento en ciencia de datos y aprendizaje automático, consta de 100 preguntas desafiantes de opción múltiple que abarcan diversos dominios, como aprendizaje profundo, aprendizaje automático clásico, procesamiento del lenguaje natural, visión artificial, ingeniería de datos y estadística. Las plataformas que funcionan bien en este amplio espectro demuestran una aplicabilidad más amplia que aquellas optimizadas para casos de uso específicos.
Análisis de borde
No toda la ciencia de datos se desarrolla en centros de datos centralizados o entornos en la nube. El análisis en el borde procesa datos en dispositivos ubicados en la periferia de la red: teléfonos inteligentes, sensores de IoT, vehículos autónomos y equipos industriales.
Este enfoque ofrece varias ventajas. La latencia se reduce drásticamente cuando el procesamiento se realiza localmente en lugar de requerir viajes de ida y vuelta a servidores remotos. Los costos de ancho de banda disminuyen, ya que no es necesario transmitir datos sin procesar. La privacidad mejora porque la información confidencial se puede procesar y agregar en el dispositivo en lugar de enviarla a sistemas externos.
El despliegue en el borde de la red presenta limitaciones. Los recursos informáticos limitados requieren modelos optimizados. La conectividad intermitente exige una gestión eficaz de los periodos sin conexión. La diversidad de dispositivos complica el despliegue y el mantenimiento. Las plataformas especializadas abordan estos desafíos mediante la compresión de modelos, el aprendizaje federado y las capacidades de actualización inalámbrica.
Cómo seleccionar las soluciones de ciencia de datos adecuadas
Con cientos de plataformas y herramientas disponibles, tomar decisiones puede resultar abrumador. Un proceso de evaluación estructurado ayuda a identificar soluciones que se ajusten a las necesidades específicas de la organización.
Definir objetivos claros
Comience por definir qué problemas empresariales necesitan solución. “Implementar ciencia de datos” no es un objetivo, sino una capacidad. “Reducir la pérdida de clientes en 15%” o “Disminuir los costos de mantenimiento de inventario en 20%” representan objetivos medibles que guían la selección de tecnología.
Los distintos objetivos favorecen distintas soluciones. El análisis exploratorio y los paneles de control ejecutivos sugieren plataformas de análisis aumentadas. La implementación a gran escala de aprendizaje automático en producción indica la necesidad de herramientas AutoML o MLOps. Las necesidades de cumplimiento normativo apuntan hacia soluciones de gobernanza.
Evaluar las capacidades organizativas
Una evaluación honesta de las habilidades, los recursos y los procesos internos evita desajustes entre la sofisticación de la solución y la preparación de la organización. Una plataforma que requiere amplia experiencia en DevOps no tendrá éxito en una organización con personal técnico limitado. Por el contrario, las herramientas demasiado simples pueden frustrar a los equipos con capacidades avanzadas.
Consideremos el modelo de madurez de la ciencia de datos. Las organizaciones que recién comienzan su andadura en el análisis de datos necesitan herramientas diferentes a las que ya cuentan con prácticas consolidadas. Las plataformas de bajo código aceleran la obtención de valor para los equipos con menos experiencia. Los marcos de trabajo avanzados ofrecen flexibilidad para los usuarios más sofisticados.
Evaluar los requisitos de integración
Las soluciones de ciencia de datos rara vez funcionan de forma aislada. Necesitan conectarse con las fuentes de datos, las aplicaciones empresariales y los sistemas de flujo de trabajo existentes. La complejidad de la integración repercute significativamente en los plazos de implementación y en la carga de mantenimiento continua.
Verifique la disponibilidad de conectores nativos para sus bases de datos, aplicaciones SaaS y almacenes de datos específicos. Evalúe las capacidades de la API para integraciones personalizadas. Considere los protocolos de autenticación y seguridad. Las organizaciones con entornos técnicos complejos deben priorizar las plataformas con marcos de integración robustos.
| Criterio de evaluación | Preguntas para hacer | Impacto en la selección |
|---|---|---|
| Objetivos empresariales | ¿Qué resultados concretos motivan esta inversión? | Determina la categoría de solución necesaria |
| Habilidades técnicas | ¿Qué conocimientos especializados tiene la empresa actualmente? | Influye en el nivel de complejidad factible. |
| Entorno de datos | ¿Dónde se encuentran actualmente los datos relevantes? | Afecta al esfuerzo de integración y a la arquitectura. |
| Requisitos de escala | ¿Qué volumen de datos y número de usuarios se prevé? | Guía las decisiones sobre infraestructura y licencias. |
| Necesidades de cumplimiento | ¿Qué requisitos reglamentarios se aplican? | Puede requerir plataformas específicas del sector o certificadas. |
Realizar pruebas de concepto
Las demostraciones de los proveedores muestran escenarios idealizados con datos limpios y casos de uso sencillos. Sin embargo, la implementación en el mundo real suele revelar complicaciones. Las pruebas de concepto con datos reales de la organización ofrecen una evaluación mucho más fiable.
Defina criterios de éxito específicos antes de comenzar. ¿La plataforma puede procesar sus formatos de datos? ¿Ofrece un rendimiento aceptable a escala real? ¿Los usuarios previstos pueden operarla sin una formación exhaustiva? ¿Se integra fácilmente con sus sistemas existentes?
Limita el tiempo de evaluación —normalmente de 4 a 8 semanas— con entregables claramente definidos. Una prueba de concepto que se prolonga durante meses sin producir resultados concretos probablemente indica problemas fundamentales de compatibilidad.
Mejores prácticas de implementación
La selección de la tecnología es solo el comienzo. Una implementación exitosa requiere atención al cambio organizacional, la adopción por parte de los usuarios y los procesos operativos.
Empieza poco a poco y ve aumentando gradualmente.
La tentación de abordar primero el caso de uso más complejo y de mayor valor es comprensible, pero suele ser contraproducente. Los proyectos complejos presentan más posibilidades de fallo y plazos de ejecución más largos. Comenzar con un caso de uso más pequeño y bien definido permite al equipo familiarizarse con la plataforma, establecer procesos y demostrar su valor antes de afrontar retos mayores.
Elija proyectos iniciales con un valor comercial claro, un alcance manejable y datos accesibles. El éxito genera impulso y confianza organizacional. Los primeros logros crean defensores que ayudan a impulsar una mayor adopción.
Invierta en la formación de los usuarios.
Incluso la plataforma más intuitiva requiere cierto aprendizaje. Las organizaciones que consideran la capacitación como opcional registran sistemáticamente una menor adopción y peores resultados que aquellas que invierten en formación estructurada.
Desarrollar programas de capacitación adaptados a los diferentes roles de usuario. Los ejecutivos necesitan contexto estratégico y capacidades de alto nivel. Los analistas de negocio requieren práctica con flujos de trabajo específicos. El personal de TI necesita comprender la arquitectura y los procedimientos operativos.
La formación justo a tiempo, impartida cuando los usuarios están listos para aplicar las nuevas habilidades, suele resultar más eficaz que las sesiones de formación genéricas que se realizan meses antes de su uso real.
Establecer la gobernanza desde el principio
La democratización de la ciencia de datos genera nuevos riesgos en torno a la calidad de los datos, la validez de los modelos y la toma de decisiones. Los marcos de gobernanza proporcionan salvaguardias sin frenar la innovación.
Defina políticas claras para el acceso a los datos, el desarrollo de modelos, las aprobaciones de implementación y el monitoreo continuo. Establezca procesos de revisión que equilibren el rigor con la rapidez. Cree estándares de documentación que faciliten la reproducibilidad y el mantenimiento del trabajo.
Las organizaciones que implementan la gobernanza de forma reactiva, después de que surgen los problemas, se enfrentan a conversaciones más difíciles y cambios más disruptivos que aquellas que establecen marcos de manera proactiva.
Medición del éxito y el retorno de la inversión.
Las inversiones en ciencia de datos deben generar un valor empresarial cuantificable. Definir y monitorizar las métricas adecuadas garantiza la rendición de cuentas y orienta la mejora continua.
Métricas de resultados empresariales
Las medidas más importantes están directamente relacionadas con los objetivos comerciales. Si el objetivo era reducir la pérdida de clientes, se debe realizar un seguimiento de las tasas de abandono antes y después de la implementación. Para la optimización del inventario, se deben medir los costos de almacenamiento y la frecuencia de roturas de stock. El crecimiento de los ingresos, la reducción de costos y la satisfacción del cliente son los resultados que más importan.
La atribución de causas puede ser compleja. Los resultados empresariales rara vez tienen una sola causa. Establezca parámetros de referencia antes de la implementación, controle los factores externos siempre que sea posible y sea honesto sobre la incertidumbre en las estimaciones de impacto.
Métricas operativas
Las mejoras de procesos representan otra categoría de valor. ¿Cuánto tiempo ahorra el equipo de análisis con la preparación automatizada de datos? ¿Cuántos modelos más se implementan por trimestre? ¿Cuánto más rápido obtienen los usuarios de negocio respuestas a sus preguntas analíticas?
Estas mejoras en la eficiencia pueden no aparecer directamente en los estados financieros, pero liberan recursos para trabajos de mayor valor y aceleran los ciclos de toma de decisiones.
Métricas de adopción
La tecnología que permanece sin usar no aporta valor. Es fundamental monitorizar los usuarios activos, el volumen de consultas, los modelos en producción y otros indicadores de utilización. Una baja adopción indica deficiencias en la formación, problemas de usabilidad o una falta de adecuación a las necesidades reales.
Realice encuestas periódicas a los usuarios sobre su satisfacción, los problemas que encuentran y las nuevas funciones que solicitan. Los comentarios cualitativos suelen revelar oportunidades de mejora que las métricas cuantitativas no detectan.
Desafíos comunes en la implementación
Comprender los obstáculos típicos ayuda a las organizaciones a planificar estrategias de mitigación en lugar de verse sorprendidas por problemas prevenibles.
Calidad y accesibilidad de los datos
Las organizaciones subestiman sistemáticamente los desafíos relacionados con la preparación de datos. Sistemas heredados con formatos inconsistentes. Valores faltantes y errores de entrada de datos. Definiciones poco claras y transformaciones no documentadas. Fuentes de datos aisladas con esquemas incompatibles.
Las plataformas de ciencia de datos no pueden corregir datos fundamentalmente defectuosos. Asigne tiempo y recursos para la mejora de la calidad de los datos como parte de la planificación de la implementación. Establezca métricas y criterios de responsabilidad para la calidad de los datos. Considere iniciativas de gestión de datos maestros si los problemas son generalizados.
Brechas de habilidades
Incluso las plataformas de bajo código requieren pensamiento analítico y conocimiento del dominio. Las organizaciones suelen descubrir que democratizar el acceso a las herramientas no crea automáticamente una cultura de toma de decisiones basada en datos.
Abordar las carencias de competencias mediante formación, contratación o alianzas. Considerar la posibilidad de integrar a expertos en ciencia de datos en las unidades de negocio para que proporcionen orientación y apoyo. Crear comunidades de práctica donde los usuarios compartan conocimientos y mejores prácticas.
Complejidad de integración
Lo que parecía sencillo durante la fase de prueba de concepto suele complicarse en producción. Los requisitos de seguridad restringen el acceso a la red. Las políticas de gobernanza de datos exigen flujos de trabajo de aprobación. Las aplicaciones existentes carecen de API. El rendimiento se degrada a escala de producción.
Involucre a los equipos de TI y seguridad desde las primeras etapas de la planificación. Asigne el tiempo suficiente para el trabajo de integración. Realice pruebas a escala real antes de la puesta en marcha. Tenga planes de contingencia para posibles obstáculos técnicos inesperados.
Direcciones futuras
Diversos avances que se vislumbran en el horizonte darán forma a las soluciones de ciencia de datos en los próximos años.
Mayor automatización
La automatización se extenderá a tareas que actualmente requieren juicio humano. AutoML evoluciona hacia AutoDS: ciencia de datos automatizada que abarca todo el ciclo de vida, desde la definición del problema hasta la implementación y el monitoreo. Las organizaciones especificarán los objetivos y las restricciones comerciales, y los sistemas propondrán enfoques analíticos, los ejecutarán y medirán los resultados.
Esto no elimina la participación humana, sino que desplaza el enfoque hacia las decisiones estratégicas, la interpretación y la gobernanza, en lugar de la ejecución técnica.
Mejor explicabilidad
La presión regulatoria y las preocupaciones éticas impulsan la demanda de modelos más interpretables. Las predicciones opacas resultan cada vez menos aceptables en ámbitos de alto riesgo como la sanidad, las finanzas y la justicia penal.
La investigación continúa perfeccionando las técnicas de explicación que funcionan con modelos complejos. Las explicaciones contrafactuales muestran qué cambios serían necesarios para obtener una predicción diferente. Las funciones de influencia identifican qué ejemplos de entrenamiento afectaron más a una predicción específica. Los mecanismos de atención revelan en qué entradas se centra el modelo.
Las plataformas incorporarán estas técnicas de forma nativa, convirtiendo la explicabilidad en una característica estándar en lugar de un complemento especializado.
Aprendizaje distribuido y federado
Las normativas de privacidad y los requisitos de soberanía de datos complican la agregación centralizada de datos. El aprendizaje federado entrena modelos en conjuntos de datos distribuidos sin necesidad de mover los datos subyacentes.
Las organizaciones sanitarias pueden colaborar en el desarrollo de modelos sin compartir historiales clínicos. Las instituciones financieras pueden mejorar la detección de fraudes mediante inteligencia colectiva, manteniendo aislados los datos de las transacciones. Los fabricantes pueden comparar su rendimiento con el de la competencia sin revelar información confidencial.
Este cambio arquitectónico requiere nuevas herramientas, pero aborda barreras fundamentales para el análisis colaborativo en ámbitos sensibles a la privacidad.
Preguntas frecuentes
¿Cuál es la diferencia entre las plataformas de ciencia de datos y las herramientas de inteligencia empresarial?
Las herramientas de inteligencia empresarial se centran principalmente en la elaboración de informes y la visualización de datos históricos. Las plataformas de ciencia de datos, por su parte, hacen hincapié en el modelado predictivo, el aprendizaje automático y el análisis avanzado. Si bien las soluciones modernas difuminan cada vez más estas fronteras, las herramientas de BI generalmente se orientan al análisis descriptivo, mientras que las plataformas de ciencia de datos permiten capacidades predictivas y prescriptivas.
¿Cuánto cuesta implementar soluciones de ciencia de datos?
Los costos varían enormemente según la plataforma elegida, la escala de implementación y las necesidades de la organización. Los servicios gestionados en la nube suelen cobrar en función del uso: horas de computación, datos procesados, llamadas a la API. Las licencias empresariales oscilan entre decenas de miles y millones de dólares anuales. Las soluciones de código abierto requieren costos de infraestructura y personal, en lugar de tarifas de licencia. Consulte los sitios web oficiales de los proveedores para conocer los precios actuales, ya que los modelos cambian con frecuencia.
¿Necesitamos contratar científicos de datos para usar estas plataformas?
Depende de la plataforma y de tus objetivos. Las plataformas de análisis aumentado de bajo código permiten a los usuarios empresariales realizar numerosos análisis sin necesidad de conocimientos de programación. Las herramientas de AutoML reducen la experiencia especializada necesaria para el desarrollo de modelos. Sin embargo, los proyectos complejos, las soluciones personalizadas y las implementaciones en producción suelen beneficiarse de la experiencia de profesionales de la ciencia de datos. Muchas organizaciones utilizan un enfoque híbrido: capacitan a los usuarios empresariales para las tareas rutinarias y mantienen personal especializado para proyectos avanzados.
¿Cuánto tiempo se tarda en ver resultados de las inversiones en ciencia de datos?
El cronograma varía según el alcance del proyecto y la preparación de la organización. Los casos de uso sencillos con datos claros y accesibles pueden mostrar resultados en semanas. Las implementaciones complejas que involucran múltiples sistemas, desarrollo a medida o cambios organizacionales significativos pueden requerir de 6 a 12 meses antes de generar un valor sustancial. Comenzar con proyectos piloto más pequeños ayuda a demostrar el valor con mayor rapidez y genera impulso para iniciativas de mayor envergadura.
¿Qué sectores se benefician más de las soluciones de ciencia de datos?
Prácticamente todos los sectores encuentran valor en la ciencia de datos, pero algunos experimentan un impacto particularmente significativo. El sector de servicios financieros utiliza análisis avanzados para la evaluación de riesgos, la detección de fraudes y el comercio algorítmico. El sector sanitario aplica modelos predictivos a la atención al paciente, la eficiencia operativa y el descubrimiento de fármacos. El comercio minorista aprovecha la ciencia de datos para la personalización, la previsión de la demanda y la optimización de la cadena de suministro. La industria manufacturera emplea el mantenimiento predictivo y el control de calidad. Las telecomunicaciones utilizan la predicción de la deserción de clientes y la optimización de la red.
¿Cómo garantizamos que nuestras iniciativas de ciencia de datos cumplan con las regulaciones?
El cumplimiento normativo exige prestar atención al manejo de datos, la gobernanza de modelos y la documentación. Utilice plataformas con funciones de cumplimiento integradas para su sector: HIPAA para el sector sanitario, SOC 2 para los servicios financieros y GDPR para las operaciones europeas. Implemente marcos de gobernanza de datos que registren el origen de los datos, apliquen controles de acceso y mantengan registros de auditoría. Documente los procesos de desarrollo, validación y monitorización de modelos. Involucre a los equipos legales y de cumplimiento normativo desde las primeras etapas de la planificación del proyecto. Considere plataformas de gobernanza especializadas si los requisitos normativos son extensos.
¿Pueden las soluciones de ciencia de datos funcionar con nuestros sistemas actuales?
La mayoría de las plataformas modernas ofrecen amplias capacidades de integración mediante conectores predefinidos, API y herramientas de importación/exportación de datos. Verifique si la plataforma que está considerando ofrece soporte nativo para sus bases de datos, almacenes de datos, aplicaciones empresariales y formatos de archivo específicos. La complejidad de la integración varía considerablemente: las soluciones en la nube suelen conectarse más fácilmente a otros servicios en la nube, mientras que las implementaciones locales pueden requerir middleware personalizado. Evalúe los requisitos de integración durante la selección de la plataforma, en lugar de descubrir problemas de compatibilidad una vez que se haya tomado la decisión.
Conclusión: Desarrollo de capacidades basadas en datos
Las soluciones de ciencia de datos han evolucionado desde tecnologías experimentales hasta convertirse en infraestructura empresarial esencial. Organizaciones de todos los sectores dependen ahora de estas plataformas para competir eficazmente, operar con eficiencia y ofrecer un mejor servicio a sus clientes.
Las implementaciones más exitosas comparten características comunes. Parten de objetivos empresariales claros, en lugar de utilizar la tecnología como un fin en sí misma. Adaptan la sofisticación de la solución a las capacidades y la madurez de la organización. Invierten en calidad de datos, capacitación de usuarios y marcos de gobernanza, además del despliegue tecnológico. Miden los resultados con rigor y realizan ajustes en función de la evidencia.
Ninguna plataforma resuelve todos los problemas ni se adapta a todas las organizaciones. La mejor solución depende de las necesidades, limitaciones y objetivos específicos. Las plataformas de análisis aumentado democratizan el acceso a la información, pero no sustituyen la experiencia analítica especializada. El aprendizaje automático acelera el desarrollo de modelos, pero requiere datos de calidad y problemas bien definidos. Los sistemas en tiempo real permiten la acción inmediata, pero introducen complejidad operativa. Las soluciones especializadas para cada sector abordan los requisitos específicos de cada dominio, pero pueden resultar más caras que las plataformas generales.
El panorama de la ciencia de datos sigue evolucionando rápidamente. Surgen nuevas capacidades. El rendimiento mejora. Los precios varían. Las organizaciones que establecen criterios de evaluación claros, realizan pruebas exhaustivas y mantienen flexibilidad en la elección de tecnologías se posicionan para adaptarse al avance del sector.
¿Listo para transformar la forma en que su organización utiliza los datos? Comience por identificar un caso de uso de alto valor con datos accesibles y métricas de éxito claras. Evalúe las plataformas que se ajusten a su entorno técnico y nivel de conocimientos. Realice pruebas prácticas con datos reales. A partir de ahí, desarrolle la solución.
La ventaja competitiva recae cada vez más en las organizaciones que transforman los datos en acciones de forma más rápida y eficaz que sus competidores. Las soluciones de ciencia de datos proporcionan las herramientas, pero el éxito exige un compromiso con el cambio organizacional, el aprendizaje continuo y la toma de decisiones basada en la evidencia.