Resumen rápido: Las canalizaciones de datos de IA combinan el aprendizaje automático con la ingeniería de datos para automatizar el mapeo de esquemas, el procesamiento y las comprobaciones de calidad, transformando información bruta y no estructurada en conjuntos de datos listos para la IA con una mínima intervención manual. A diferencia de los ETL tradicionales, iteran continuamente a través de las etapas de ingesta, transformación, ingeniería de características, entrenamiento y monitorización. Los marcos declarativos modernos demuestran mejoras en la eficiencia del desarrollo de 50%, mejoras en la escalabilidad de 500× y reducciones en los costes de computación de hasta 80%.
Todos los proyectos ambiciosos de IA se topan con el mismo obstáculo: montañas de datos desordenados almacenados en sistemas desconectados, muy lejos del formato limpio y estructurado que exigen los modelos.
Las herramientas ETL tradicionales se bloquean con registros no estructurados, imágenes y campos de texto libre. Requieren que un gran número de ingenieros mapeen los esquemas manualmente cada vez que cambia una fuente. Y cuando los clústeres de GPU permanecen inactivos con una utilización de entre 10 y 151 TP3T esperando el siguiente lote, los presupuestos de computación se agotan.
Ese es el problema que resuelven las canalizaciones de datos de IA. No solo mueven datos, sino que aprenden de ellos, se adaptan automáticamente a los cambios de esquema y mantienen la infraestructura de entrenamiento saturada.
¿Qué hace que las canalizaciones de datos de IA sean diferentes?
Los flujos de datos tradicionales siguen una ruta lineal: se extraen los datos brutos, se transforman mediante reglas fijas y se cargan en un almacén de datos. El flujo de trabajo es predecible. Se ejecuta una vez y listo.
Los flujos de datos de IA operan en ciclos continuos: ingesta → preparación → diseño de características → entrenamiento de modelos → predicción → monitorización → reentrenamiento. Cada etapa retroalimenta información valiosa al flujo anterior.
Pero aquí está la clave: también manejan lo que las herramientas ETL tradicionales no pueden: datos no estructurados a gran escala. Documentos, imágenes, audio, comentarios de clientes en texto libre: formatos que representan la mayor parte de la información empresarial, pero que las herramientas convencionales no procesan.
| Dimensión | Canalización de datos tradicional | Canalización de datos de IA |
|---|---|---|
| Propósito principal | Informes e inteligencia empresarial | Entrenamiento, inferencia y predicción de modelos |
| Producción | Paneles de control, informes, métricas agregadas | Modelos entrenados, predicciones, almacenes de características |
| Flujo de trabajo | Lineal: Extraer → Transformar → Cargar | Iterativo: Ingerir → Preparar → Entrenar → Predecir → Monitorear → Reentrenar |
| Manejo de esquemas | Mapeo manual, interrupciones por desviación del esquema | Mapeo automático impulsado por aprendizaje automático, se adapta a los cambios. |
| Tipos de datos | Principalmente estructuradas (bases de datos, CSV) | Estructurado + no estructurado (texto, imágenes, registros) |
| Gobernancia | Control de acceso a nivel de almacén | Linaje de extremo a extremo, control de versiones del modelo, registros de auditoría. |
En realidad, la capa de automatización es lo que los diferencia. Los modelos de aprendizaje automático integrados en el propio proceso detectan cambios de esquema, sugieren transformaciones y señalan anomalías antes de que afecten a los modelos posteriores.
Las cinco etapas clave de los flujos de datos de IA modernos
Ingestión: Conectando todo
Los datos provienen de todas partes: API, bases de datos, flujos de eventos, depósitos S3, almacenes locales. La ingesta los reúne todos en un entorno unificado.
Los conectores modernos gestionan el procesamiento por lotes y en tiempo real simultáneamente. Un marco declarativo podría especificar las fuentes una sola vez y, a continuación, paralelizar automáticamente la ingesta en cientos de particiones.
Apache Spark se utiliza ampliamente para la ingesta distribuida en los flujos de datos empresariales. Sin embargo, las plataformas propietarias cada vez más abstraen la complejidad de Spark mediante una sintaxis declarativa similar a SQL.
Transformación: Limpieza y Estructuración
Los datos sin procesar llegan con duplicados, valores nulos, formato inconsistente y marcas de tiempo faltantes. La lógica de transformación elimina los registros duplicados, imputa los valores faltantes, normaliza las marcas de tiempo y convierte los tipos de datos.
Los procesos ETL tradicionales requieren que los ingenieros escriban y mantengan manualmente los scripts de transformación. Las plataformas basadas en IA utilizan modelos de detección de anomalías para marcar automáticamente los registros sospechosos y sugerir reglas de corrección.
Las investigaciones realizadas en estudios académicos sobre gestión de datos demuestran que la validación impulsada por IA reduce los registros duplicados en 75% y mejora la precisión de los datos en 18%.
Ingeniería de características: Creación de entradas para el modelo
Los modelos no consumen columnas sin procesar; necesitan características diseñadas. Codificación categórica, escalado, segmentación, retardo, agregación a lo largo de periodos de tiempo: todo un preprocesamiento que transforma los atributos sin procesar en señales predictivas.
Las herramientas automatizadas de ingeniería de características prueban miles de transformaciones candidatas, las clasifican según su poder predictivo y gestionan las versiones del conjunto final de características junto con los puntos de control del modelo.
Esta etapa es iterativa. Los modelos fallan, los ingenieros añaden nuevas funcionalidades y los procesos se reentrenan. Los ciclos de retroalimentación intensivos comprimen semanas de experimentación en días.
Formación y validación
Los datos preparados se dividen en conjuntos de entrenamiento y validación, normalmente en una proporción de 80/20. El subconjunto de entrenamiento enseña al modelo los patrones; el subconjunto de validación comprueba si esos patrones se generalizan.
Aquí se realiza el ajuste de hiperparámetros: tasas de aprendizaje, tamaños de lote, coeficientes de regularización. Herramientas de búsqueda automatizadas como MLFlow o plataformas AutoML propietarias prueban cientos de configuraciones en paralelo.
Las pruebas comparativas realizadas en implementaciones a escala de producción muestran tiempos de entrenamiento de extremo a extremo de aproximadamente 60 horas para modelos completos. El ajuste fino de modelos base preentrenados reduce ese tiempo a 8 horas y 47 minutos, con un tiempo de ejecución promedio de 1 minuto y 45 segundos por ejecución.
Implementación y monitoreo
Los modelos entrenados se integran en entornos de inferencia: API REST, tareas de puntuación por lotes y dispositivos periféricos integrados. El monitoreo realiza un seguimiento de la latencia de predicción, el rendimiento, las tasas de error y la desviación de datos.
Cuando cambian las distribuciones de entrada (cambios estacionales, lanzamientos de nuevos productos, actualizaciones de esquemas), el rendimiento se degrada. Las alertas automatizadas activan flujos de trabajo de reentrenamiento antes de que los usuarios noten una disminución en la precisión.
Las capas de gobernanza garantizan el control de acceso, los registros de auditoría y las políticas de cumplimiento desde la ingesta hasta la salida del modelo. La gobernanza centralizada evita que los equipos tengan que reinventar la lógica de seguridad en cada proceso.
Cómo la IA transforma el rendimiento de los flujos de datos
Eliminando la falta de recursos de la GPU
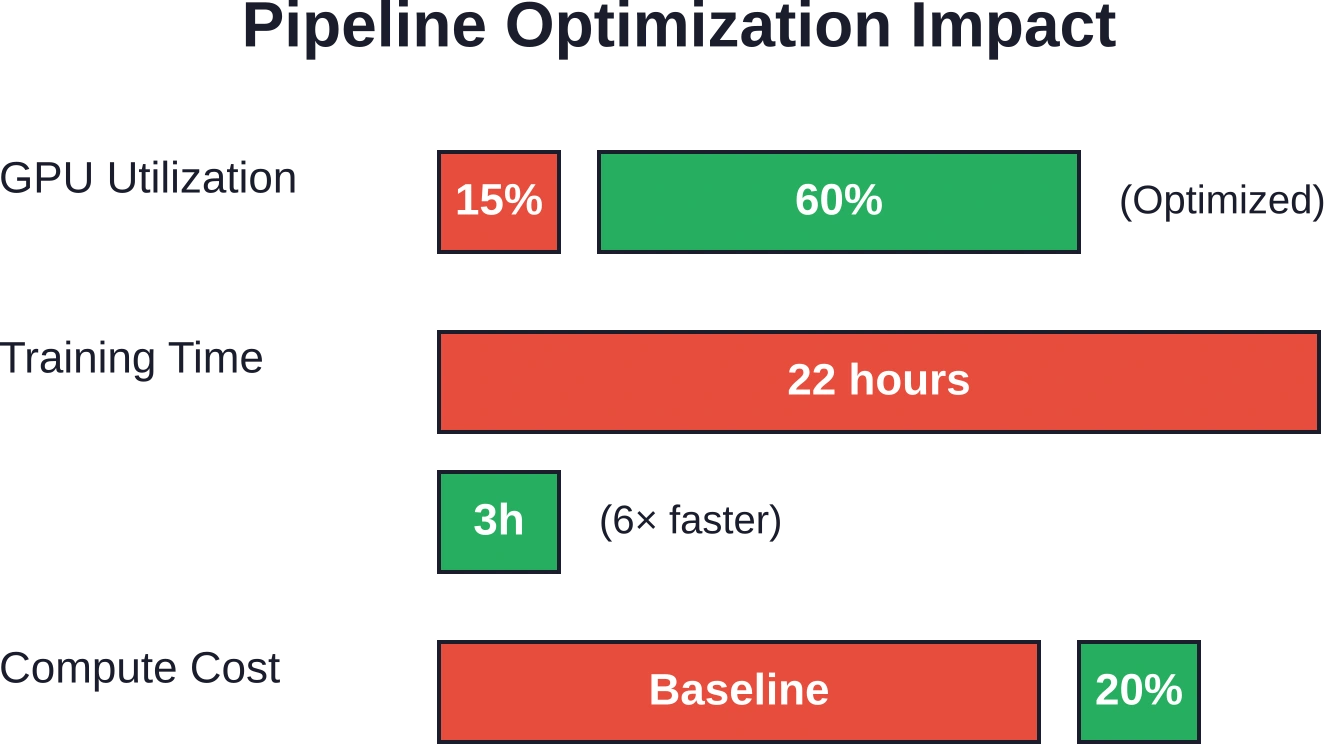
Las GPU de alto rendimiento permanecen inactivas cuando la carga de datos no puede seguir el ritmo del procesamiento. En las canalizaciones de aprendizaje profundo industriales estándar, los investigadores observaron que las GPU se mantenían con una utilización de entre 10 y 15% mientras esperaban lotes.
Las canalizaciones de datos optimizadas mediante cargadores distribuidos como Petastorm lograron una utilización de GPU de 60% y proporcionaron una aceleración general de 6×. El tiempo de entrenamiento de extremo a extremo se redujo de 22 horas a 3 horas. La reducción de los costos de cómputo alcanzó los 80% al eliminar los ciclos desperdiciados.
El cuello de botella no era el modelo, sino la E/S. Si se soluciona el problema de la canalización, la inversión en hardware dará sus frutos.
Marcos declarativos para la escalabilidad
El código de canalización imperativo —scripts de Python que encadenan trabajos de Spark— se vuelve imposible de mantener a gran escala. La depuración requiere leer miles de líneas. La colaboración se estanca cuando la lógica está dispersa en distintos repositorios.
Los marcos de trabajo declarativos permiten a los ingenieros especificar *qué* transformaciones aplicar, no *cómo* ejecutarlas. La plataforma optimiza automáticamente los planes de ejecución.
Los estudios de caso empresariales que utilizan pipelines declarativos reportan una eficiencia de desarrollo 50% superior, esfuerzos de colaboración comprimidos de semanas a días, mejoras de escalabilidad 500× y ganancias de rendimiento 10× en comparación con las implementaciones imperativas.
Las evaluaciones académicas confirmaron un aumento de rendimiento de 5,7 veces con respecto al código que no utiliza el marco de trabajo y una utilización de la CPU de 99% durante el procesamiento distribuido.
Autocuración y evolución de esquemas
Los sistemas de producción se enfrentan a cambios constantes. Las API ascendentes añaden campos, cambian el nombre de las columnas o modifican los tipos de datos sin previo aviso. Los flujos de trabajo tradicionales fallan y requieren correcciones manuales.
La evolución del esquema guiada por IA detecta automáticamente las discrepancias, infiere las asignaciones correctas a partir de patrones históricos y aplica transformaciones sobre la marcha. Los agentes de IA explicables muestran recomendaciones —”Columna `user_id` renombrada a `userId`; asignación automática aplicada”— para que los ingenieros puedan auditar los cambios sin tener que revisar los registros.
Las capas de mejora de la calidad de los datos en tiempo real validan los registros durante la ingesta, detectan valores atípicos y envían los datos sospechosos a tablas de cuarentena para su revisión. Los modelos continúan entrenándose con subconjuntos limpios mientras los ingenieros investigan las anomalías de forma asíncrona.

Prepare las canalizaciones de datos de IA para el desarrollo de modelos reales.
Los proyectos de IA dependen de algo más que un modelo. Los datos deben recopilarse, estructurarse, prepararse y vincularse con la forma en que el sistema se utilizará realmente. IA superior Trabaja con inteligencia artificial y estrategia de datos, desarrollo de software de IA, aprendizaje automático, inteligencia empresarial e integración de IA. En el caso de los flujos de datos de IA, esto puede incluir la preparación de datos para modelos de aprendizaje automático, la creación de aplicaciones basadas en datos, el soporte de flujos de trabajo analíticos y la garantía de que los sistemas de IA puedan trabajar con las fuentes de datos empresariales existentes.
El trabajo de AI Superior puede abarcar:
- Requisitos de datos de planificación para proyectos de IA
- Preparación de datos empresariales para modelos de aprendizaje automático
- Desarrollo de software de IA conectado a fuentes de datos existentes
- Soporte para flujos de trabajo de análisis e inteligencia empresarial.
- Integración de sistemas de IA en los procesos empresariales actuales
👉Ponte en contacto con AI Superior. para analizar cómo se pueden preparar sus datos para modelos de IA, herramientas de análisis o software de IA personalizado.
Desafíos comunes y cómo superarlos
Desafío: Degradación de la calidad de los datos
El rendimiento del modelo disminuye sin cambios en el código. Los paneles de control posteriores muestran una precisión cada vez menor. Causa principal: las fuentes de datos anteriores introdujeron valores nulos, duplicados o inconsistencias de formato hace semanas.
Solución: Controles de calidad continuos durante la ingesta. Los modelos de perfil estadístico analizan las distribuciones de referencia (media, varianza, cardinalidad) y alertan cuando los nuevos lotes se desvían más allá de los umbrales establecidos. Mediante la validación basada en IA, se pueden lograr mejoras automatizadas en la precisión de los datos de 181 TP3T y reducciones de duplicados de 751 TP3T.
Desafío: Infraestructura fragmentada
Los sistemas heredados almacenan datos en silos: bases de datos locales, almacenes en la nube, lagos de datos y aplicaciones SaaS. Mover datos entre entornos requiere scripts personalizados, VPN y coordinación manual.
Solución: Plataformas de ingesta unificadas con conectores preconfigurados para más de 100 fuentes. La configuración declarativa consolida la autenticación, la limitación de velocidad y la lógica de sincronización incremental. Los equipos definen las fuentes una sola vez; la plataforma se encarga del resto.
Desafío: Escalar sin mantener el sistema colapsa
El código de la canalización imperativa crece hasta alcanzar miles de líneas. Cada nueva funcionalidad añade bifurcaciones condicionales. La depuración lleva días. Los nuevos miembros del equipo no pueden integrarse fácilmente.
Solución: Adopte marcos de trabajo declarativos. Especifique las transformaciones como archivos de configuración o consultas tipo SQL. El motor de ejecución optimiza automáticamente el paralelismo, los reintentos y la asignación de recursos. Los equipos empresariales reportan reducciones en el código base de 40% y una reducción del tiempo de resolución de problemas de semanas a días.
Mejores prácticas de arquitectura para sistemas de producción
Almacenamiento y procesamiento separados
Las arquitecturas estrechamente acopladas obligan a escalar el almacenamiento y la computación simultáneamente. El sobredimensionamiento supone un desperdicio de presupuesto; el subdimensionamiento limita la ejecución de las tareas.
Los diseños nativos de la nube desacoplan ambos procesos. Almacenan los datos en almacenamiento de objetos (S3, GCS, Azure Blob). Inician clústeres de computación efímeros (Spark, Dask, Ray) solo cuando se ejecutan trabajos. Los apagan después.
Versión Todo
El código, los datos, los modelos y las configuraciones cambian con el tiempo. Sin control de versiones, reproducir un resultado de hace tres meses se convierte en una tarea ardua.
Las plataformas MLOps modernas integran Git para el código, DVC para los conjuntos de datos y registros de modelos para los artefactos entrenados. Cada ejecución de entrenamiento se vincula con instantáneas exactas de los datos de entrada y las configuraciones de hiperparámetros. Las reversiones se realizan con un solo comando.
Implementar el linaje de extremo a extremo
Los reguladores y auditores preguntan: "¿Cómo llegó el modelo a esta predicción?" Los ingenieros preguntan: "¿Qué tabla anterior causó este error?"“
El registro de linaje documenta cada transformación: tabla de origen → característica intermedia → entrada del modelo → predicción. Los metadatos almacenan marcas de tiempo, versiones de esquema y acciones del usuario. Las interfaces de consulta permiten a los equipos rastrear el origen de cualquier resultado.
Construya la observabilidad desde el primer día.
Los procesos fallan silenciosamente. Las tareas se completan correctamente, pero generan basura. Las alertas se activan demasiado tarde.
Instrumentación en cada etapa: recuento de filas de ingesta, tasas de error de transformación, cambios en la distribución de características, latencia de predicción del modelo. Los paneles de control muestran anomalías en tiempo real. Los equipos de guardia detectan problemas antes de que los usuarios los reporten.
Casos de uso en diversos sectores.
Detección de fraude en tiempo real (servicios financieros)
Las transacciones se procesan en milisegundos. Los modelos evalúan cada transacción en función del riesgo de fraude, bloqueando la actividad sospechosa antes de su liquidación.
Las canalizaciones ingieren flujos de eventos (Kafka, Kinesis), los combinan con las características del perfil del cliente e invocan puntos finales de inferencia de baja latencia. El monitoreo realiza un seguimiento de las tasas de falsos positivos y adapta los umbrales dinámicamente.
Mantenimiento predictivo (fabricación)
Los sensores de los equipos de la fábrica emiten datos de telemetría: temperatura, vibración y presión. Los modelos predicen las fallas días antes de que ocurran, lo que permite programar el mantenimiento durante los periodos de inactividad planificados.
Los sistemas de procesamiento agregan datos de series temporales en ventanas móviles (por hora, por día), diseñan características de retardo y reentrenan los modelos semanalmente a medida que surgen nuevos patrones de fallas.
Recomendaciones personalizadas (comercio electrónico)
Los historiales de clics y compras de los usuarios alimentan los modelos de filtrado colaborativo. Las recomendaciones se actualizan prácticamente en tiempo real a medida que cambian las preferencias.
Las canalizaciones por lotes reconstruyen las incrustaciones de elementos cada noche. Las canalizaciones de transmisión actualizan los perfiles de usuario en cada interacción. Las arquitecturas híbridas equilibran la actualidad y el costo computacional.
Sistema de apoyo a la toma de decisiones clínicas (Atención sanitaria)
Los registros médicos electrónicos contienen resultados de laboratorio estructurados, notas médicas no estructuradas, imágenes médicas e historiales de prescripciones. Los modelos sintetizan señales de diversas modalidades para identificar a los pacientes en riesgo.
Los sistemas gestionan la ingesta multimodal, aplican el procesamiento del lenguaje natural (PLN) para extraer entidades de las notas, normalizan las unidades de laboratorio y aplican un control de acceso que cumple con la normativa HIPAA en todo momento.
Características clave de la plataforma a evaluar
Al evaluar las plataformas de procesamiento de datos, priorice estas capacidades:
- Conectores prefabricados: Bases de datos, aplicaciones SaaS, almacenamiento en la nube, fuentes de transmisión
- Inferencia de esquemas: Detección y mapeo automáticos de tipos de datos
- Bibliotecas de transformación: SQL, Python, constructores visuales de DAG
- Orquestación: Planificación, dependencias, reintentos, rellenos de datos
- Monitorización y alertas: Métricas de calidad de datos, paneles de control del estado del pipeline
- Gobernancia: Control de acceso, registros de auditoría, seguimiento de linaje
- Escalabilidad: Motores de ejecución distribuida (Spark, Dask, Ray)
- Integración: Registros de modelos, almacenes de características, seguimiento de experimentos
Las plataformas propietarias simplifican la complejidad, pero generan dependencia del proveedor. Las herramientas de código abierto (Airflow, Prefect, Dagster) ofrecen flexibilidad, pero requieren una mayor carga operativa.

Estrategia de adopción: empezar poco a poco, escalar rápidamente.
No intentes una revisión completa de todo el sistema empresarial el primer día. Empieza con un caso de uso de alto impacto —detección de fraude, predicción de abandono de clientes, previsión de la demanda— donde las partes interesadas ya experimentan problemas.
Cree el flujo de extremo a extremo: ingesta desde una fuente crítica, transformaciones mínimas, un modelo, un destino de implementación. Demuestre su valor rápidamente. Luego, expanda.
Documenta las lecciones aprendidas. Estandariza los patrones que funcionan. Comparte los logros entre los equipos. A medida que aumenta la adopción, centraliza los componentes compartidos (módulos de autenticación, paneles de monitoreo, políticas de gobernanza) en plantillas reutilizables.
Invierta en capacitación. Los ingenieros de pipeline necesitan tanto habilidades de ingeniería de datos (SQL, sistemas distribuidos) como fundamentos de aprendizaje automático (sesgo, sobreajuste, métricas de evaluación). El trabajo en parejas interdisciplinario acelera la transferencia de conocimientos.
El camino a seguir: Sistemas de IA en 2026 y más allá
Los frameworks declarativos se están convirtiendo en un requisito indispensable. Los equipos que aún escriben scripts imperativos de Spark tendrán dificultades para competir en velocidad.
Las herramientas automatizadas de ingeniería de características convertirán en algo común lo que hoy requiere un profundo conocimiento del dominio. Los modelos propondrán características candidatas; los ingenieros las seleccionarán y aprobarán.
La gobernanza y la explicabilidad pasarán de ser aspectos secundarios a requisitos fundamentales. La presión regulatoria —como la Ley de IA de la UE y las leyes de privacidad estatales— obliga a las organizaciones a demostrar que sus modelos son justos, transparentes y auditables. Los sistemas que integran la gobernanza desde el inicio se adaptarán más rápidamente que aquellos que incorporan el cumplimiento normativo posteriormente.
El despliegue en el borde se acelerará. A medida que los modelos se miniaturizan (cuantización, destilación) y el hardware de borde mejora, la inferencia se acerca a las fuentes de datos. Los flujos de trabajo deberán coordinar el entrenamiento en la nube y el despliegue en miles de puntos finales distribuidos.
Pero el principio fundamental se mantiene: la IA es tan buena como los datos que la alimentan. Los sistemas que automatizan la ingesta, la transformación y los controles de calidad permiten a los equipos centrarse en lo que las máquinas no pueden hacer: formular mejores preguntas.
Preguntas frecuentes
¿Qué es un pipeline de datos de IA?
Una canalización de datos de IA es un flujo de trabajo automatizado que ingiere datos brutos de múltiples fuentes, los transforma en formatos estructurados y limpios, diseña características para modelos de aprendizaje automático, entrena y valida dichos modelos, los implementa para la inferencia y supervisa continuamente su rendimiento. A diferencia de los procesos ETL tradicionales, las canalizaciones de IA iteran mediante ciclos de retroalimentación, reentrenando los modelos a medida que los datos varían y adaptando los esquemas automáticamente mediante aprendizaje automático integrado.
¿En qué se diferencian los flujos de datos de IA de los procesos ETL tradicionales?
El ETL tradicional sigue una secuencia lineal de extracción, transformación y carga para la generación de informes e inteligencia empresarial. Las canalizaciones de datos de IA operan en bucles continuos, manejando datos estructurados y no estructurados (texto, imágenes, registros), utilizando aprendizaje automático para mapear esquemas automáticamente y retroalimentando la información de monitorización para activar el reentrenamiento. Priorizan el entrenamiento del modelo y los resultados de la inferencia sobre los paneles estáticos.
¿Qué mejoras de rendimiento pueden ofrecer los sistemas basados en IA?
Las pruebas de rendimiento en producción muestran que las canalizaciones optimizadas para IA alcanzan una utilización de GPU de 60% (frente a la línea base de 10–15%), ofrecen una aceleración general de 6 veces, reducen el tiempo de entrenamiento de 22 horas a 3 horas y disminuyen los costos de computación en 80%. Los marcos declarativos demuestran ganancias de eficiencia de desarrollo de 50%, mejoras de escalabilidad de 500× y aumentos de rendimiento de 10× en comparación con las implementaciones imperativas.
¿Qué herramientas se utilizan habitualmente para los flujos de datos de IA?
Entre las herramientas de código abierto más populares se encuentran Apache Spark (procesamiento distribuido), Apache Airflow y Prefect (orquestación), MLFlow (seguimiento de experimentos) y DVC (control de versiones de datos). Plataformas propietarias como Databricks, Snowflake y servicios ETL especializados en IA ofrecen entornos gestionados con conectores, gobernanza y monitorización integrados. La elección de la herramienta depende de la experiencia del equipo, la escala y la tolerancia a la sobrecarga operativa.
¿Cuáles son los mayores desafíos a la hora de construir sistemas de procesamiento de datos para IA?
Entre los obstáculos comunes se incluyen la degradación de la calidad de los datos (cambios en el origen que introducen valores nulos o duplicados), la fragmentación de la infraestructura (datos aislados en sistemas incompatibles), la desviación del esquema (cambios en la API que interrumpen los flujos de trabajo) y el colapso de la mantenibilidad a medida que crece el código imperativo. Las soluciones implican controles de calidad continuos, plataformas de ingesta unificadas, evolución del esquema basada en aprendizaje automático y la adopción de marcos declarativos que separan la lógica de la ejecución.
¿Qué importancia tiene la gobernanza en los flujos de datos de IA?
La gobernanza es fundamental para el cumplimiento normativo, las auditorías y la confianza. El seguimiento integral del linaje registra cada transformación, desde el origen hasta la predicción, lo que permite a los equipos detectar errores y a los reguladores verificar la imparcialidad. El control de acceso, los permisos basados en roles y los registros de auditoría automatizados previenen la exposición no autorizada de datos. Las organizaciones que integran la gobernanza en sus procesos desde el primer día se adaptan más rápidamente a la evolución de las leyes de privacidad y las regulaciones de IA.
¿Pueden los sistemas de IA procesar datos no estructurados?
Sí, el manejo de datos no estructurados (documentos, imágenes, audio, texto libre) es una de sus principales ventajas sobre los métodos ETL tradicionales. Las canalizaciones de IA utilizan modelos de PLN para extraer entidades del texto, modelos de visión artificial para clasificar imágenes e incrustaciones para convertir entradas no estructuradas en características numéricas que los modelos pueden procesar. Esta capacidad permite aprovechar la mayor parte de los datos empresariales que las herramientas convencionales ignoran.
Conclusión: Construir sistemas que aprendan
Los modelos de IA acaparan los titulares. Pero son los procesos los que determinan si esos modelos llegan alguna vez a producción.
Las organizaciones que triunfen en 2026 no serán necesariamente las que tengan los equipos de ciencia de datos más grandes. Serán las que automatizaron los procesos básicos (ingesta, transformación, monitorización) para que los ingenieros dediquen su tiempo a resolver problemas de negocio en lugar de depurar scripts ETL.
Empiece con un caso de uso de alto impacto. Demuestre el valor del mapeo de esquemas automatizado, las comprobaciones de calidad en tiempo real y el reentrenamiento continuo. Luego, aplique estos patrones a todos los equipos.
La ventaja competitiva no reside en la arquitectura del modelo, sino en la infraestructura de procesamiento que mantiene los modelos actualizados, fiables y funcionando correctamente. Si se construye esa infraestructura, la IA deja de ser un proyecto científico para convertirse en un motor de negocio.