Resumen rápido: Los desafíos del big data incluyen la explosión del volumen de datos, problemas de calidad, complejidad de la integración, riesgos de seguridad, escasez de personal cualificado, cuellos de botella en la escalabilidad y deficiencias en la gobernanza. Las soluciones abarcan infraestructura en la nube, herramientas de calidad automatizadas, plataformas de datos unificadas, marcos de cifrado, programas de formación y políticas de gobernanza que permiten a las organizaciones transformar los datos brutos en información útil para la toma de decisiones.
Los datos están por todas partes. Cada clic, transacción, lectura de sensor y publicación en redes sociales genera más. Por ejemplo, solo Walmart recopila más de 2,5 petabytes de datos por hora provenientes de las transacciones de sus clientes; es decir, 2,5 millones de gigabytes por hora. Para ponerlo en perspectiva, la Biblioteca del Congreso contenía 235 terabytes de información en 2011, y un exabyte equivale aproximadamente a 4.255.319 veces esa cantidad.
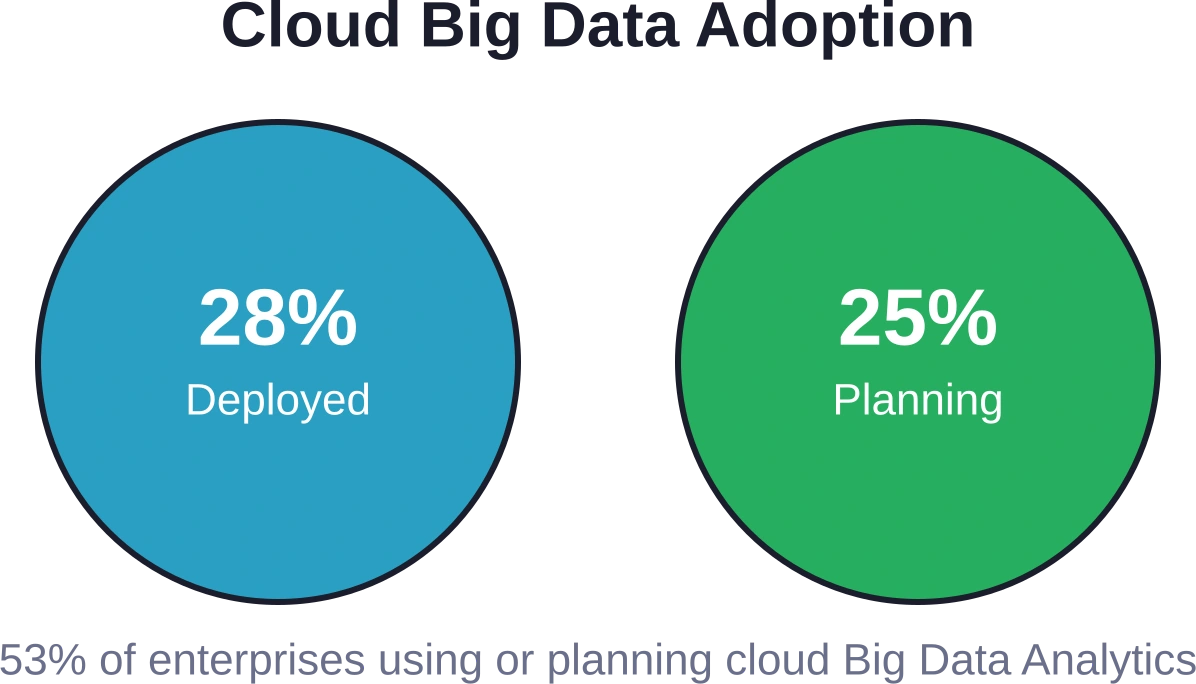
Pero aquí está el problema: tener grandes cantidades de datos no se traduce automáticamente en valor para el negocio. Las organizaciones se enfrentan a un sinfín de obstáculos al intentar recopilar, almacenar, procesar y analizar grandes volúmenes de datos. Según Statista, 751.000 millones de empresas en todo el mundo utilizan datos para impulsar la innovación, y 501.000 millones afirman que los datos les ayudan a competir en el mercado. Sin embargo, muchas tienen dificultades para cerrar la brecha entre los datos brutos y la información útil para la toma de decisiones.
Esta guía analiza los desafíos más apremiantes del big data y las soluciones que realmente funcionan. Seamos realistas: algunos de estos problemas no tienen soluciones milagrosas. Pero las estrategias que se presentan a continuación, respaldadas por investigaciones del NIST, el IEEE y estudios de casos empresariales, ofrecen caminos probados hacia el futuro.
Desafío #1: Explosión del volumen de datos
La magnitud de la generación de datos ha superado la capacidad de la infraestructura tradicional. Actualmente, las empresas manejan petabytes o exabytes de información, creciendo a un ritmo mayor del que sus sistemas pueden soportar.
Los costos de almacenamiento pueden alcanzar millones anualmente. El rendimiento de las consultas se degrada a medida que los conjuntos de datos se expanden. La infraestructura se convierte en un cuello de botella para las iniciativas de análisis y aprendizaje automático. Cuando el volumen de datos se duplica cada pocos años, las soluciones de ayer se convierten en las limitaciones de mañana.
Por qué importa el volumen
En 2010, comprar una unidad de disco capaz de almacenar toda la música del mundo costaba 1.044.600 dólares, según el NIST. El almacenamiento se ha abaratado, pero la generación de datos se ha acelerado aún más. Las organizaciones generan datos estructurados a partir de transacciones, datos no estructurados a partir de documentos y medios, y datos semiestructurados a partir de registros y sensores, todo simultáneamente.
Los sectores de la salud, los servicios financieros y las telecomunicaciones se enfrentan a desafíos de volumen particularmente acuciantes. Estos sectores operan con tasas de adopción de tecnologías de big data e IA que oscilan entre el 90% y el 100%, generando conjuntos de datos masivos que deben conservarse para el cumplimiento normativo, el análisis y el entrenamiento de modelos.
Soluciones para la gestión de volúmenes
- Las arquitecturas de almacenamiento en la nube proporcionan capacidad elástica que se adapta a la demanda. Servicios como Amazon S3, Google Cloud Storage y Azure Blob Storage eliminan la necesidad de aprovisionar hardware con años de antelación.
- La compresión de datos reduce las necesidades de almacenamiento entre 50 y 801 TP3T, según el tipo de datos. Los formatos columnares como Parquet y ORC logran altos índices de compresión a la vez que permiten un rendimiento de consulta rápido para cargas de trabajo analíticas.
- La gestión automatizada del ciclo de vida traslada los datos poco utilizados a niveles de almacenamiento más económicos. Los datos a los que se accede con poca frecuencia pueden pasar del almacenamiento SSD de acceso frecuente a niveles de archivo a una fracción del coste, lo que permite ahorrar presupuesto para los conjuntos de datos a los que se accede con frecuencia.
- Las estrategias de estratificación de datos clasifican la información según los patrones de acceso. Los datos de acceso frecuente se almacenan en memorias rápidas, los datos de acceso moderado se trasladan a niveles de almacenamiento equilibrados y los datos de acceso poco frecuente se archivan en almacenamiento de objetos de bajo coste. Este enfoque optimiza tanto el rendimiento como el coste.
Desafío #2: Problemas de calidad de los datos
Si introduces datos erróneos, obtendrás resultados erróneos. La mala calidad de los datos perjudica todos los procesos posteriores: el análisis, la elaboración de informes, el aprendizaje automático y la toma de decisiones se ven afectados cuando los datos de origen contienen errores, duplicados o inconsistencias.
Los problemas de calidad de los datos surgen de múltiples fuentes: errores de entrada manual, fallos de integración del sistema, formatos inconsistentes entre departamentos, valores faltantes y registros obsoletos. Cuando las organizaciones combinan datos de docenas de sistemas, los problemas de calidad se multiplican.
El verdadero coste de los datos erróneos
Los datos erróneos conducen a malas decisiones. Las campañas de marketing se dirigen a los clientes equivocados. Los modelos de la cadena de suministro realizan predicciones erróneas. Los informes financieros contienen imprecisiones. Los modelos de aprendizaje automático entrenados con datos defectuosos producen resultados poco fiables.
Las organizaciones malgastan tiempo y recursos limpiando datos de forma reactiva en lugar de prevenir proactivamente los problemas de calidad. Los equipos dedican más tiempo a depurar problemas de datos que a generar información valiosa.
Soluciones para la calidad de los datos
- Las reglas de validación automatizadas detectan errores en el momento de la ingesta. La validación del esquema, las comprobaciones de formato, las restricciones de rango y las reglas de integridad referencial rechazan los datos erróneos antes de que contaminen los sistemas posteriores.
- Las herramientas de análisis de datos examinan conjuntos de datos para identificar patrones, anomalías y problemas de calidad. El análisis de datos revela valores faltantes, valores atípicos, duplicados e inconsistencias que pasarían desapercibidos en una revisión manual.
- La gestión de datos maestros (MDM) crea una fuente única de información fidedigna para entidades críticas como clientes, productos y ubicaciones. Los sistemas MDM resuelven conflictos, eliminan registros duplicados y mantienen registros maestros.
- El monitoreo de la calidad de los datos realiza un seguimiento de las métricas a lo largo del tiempo. Los paneles automatizados muestran puntuaciones de integridad, precisión, coherencia y puntualidad, alertando a los equipos cuando la calidad se degrada.
| Dimensión de calidad de los datos | Problemas comunes | Enfoque de solución |
|---|---|---|
| Exactitud | Valores incorrectos, errores tipográficos, registros obsoletos | Reglas de validación, verificación externa, auditorías periódicas |
| Lo completo | Campos faltantes, valores nulos, registros parciales | Aplicación obligatoria de procedimientos, imputación, correcciones del sistema fuente |
| Consistencia | Datos contradictorios entre sistemas, variaciones de formato | Estandarización, MDM, modelos de datos canónicos |
| Oportunidad | Datos obsoletos, actualizaciones retrasadas, retraso en el procesamiento por lotes. | Canalizaciones en tiempo real, CDC, programas de actualización automatizados |
| Unicidad | Registros duplicados, entradas redundantes | Algoritmos de deduplicación, coincidencia difusa, resolución de entidades |
Desafío #3: Complejidad de la integración de datos
Las organizaciones modernas gestionan decenas o cientos de sistemas: plataformas CRM, sistemas ERP, herramientas de automatización de marketing, dispositivos IoT, API de terceros, bases de datos heredadas y aplicaciones en la nube. Cada uno utiliza su propio lenguaje de datos.
Integrar fuentes de datos dispares es un proceso lento, propenso a errores y costoso. Los diferentes esquemas, formatos, frecuencias de actualización y métodos de acceso hacen que la integración sea un desafío constante. Un estudio de caso empresarial demostró que la eficiencia del desarrollo mejoró en 50% y el tamaño del código base se redujo en 40% tras la implementación de un marco de trabajo unificado para la canalización de datos.
Por qué la integración es importante
Las preguntas de negocio rara vez se resuelven en un solo sistema. Para comprender el valor del cliente a lo largo de su vida útil, es necesario integrar datos de CRM, registros de transacciones, tickets de soporte e interacciones de marketing. La optimización de la cadena de suministro requiere datos de inventario, información de proveedores, registros de envíos y pronósticos de demanda.
Sin integración, las organizaciones operan con información parcial. Los datos aislados generan informes contradictorios, duplicación de esfuerzos y puntos ciegos.
Soluciones para la integración
- Las plataformas de datos unificadas proporcionan un centro neurálgico para la ingesta, la transformación y el acceso a los datos. Las plataformas de datos modernas admiten la ingesta por lotes y en tiempo real, la evolución de esquemas y múltiples motores de consulta.
- Las herramientas de automatización ETL/ELT gestionan los procesos de extracción, transformación y carga. Los servicios nativos de la nube como AWS Glue, Azure Data Factory y Google Dataflow reducen la necesidad de programación personalizada.
- La captura de cambios de datos (CDC) solo procesa los registros modificados, en lugar de escanear las tablas completas. La CDC reduce la latencia y la carga de la infraestructura, al tiempo que mantiene sincronizados los sistemas posteriores.
- Las capas de gestión de API estandarizan el acceso a diversos sistemas. Las pasarelas de API proporcionan interfaces consistentes, autenticación, limitación de velocidad y monitorización en todas las fuentes de datos.
- La virtualización de datos crea vistas lógicas sin necesidad de mover físicamente los datos. Permite realizar consultas federadas entre sistemas, minimizando al mismo tiempo los costes de replicación y almacenamiento de datos.
Desafío #4: Escalabilidad y cuellos de botella en el rendimiento
Los sistemas que funcionan bien con gigabytes de datos colapsan con petabytes. El rendimiento de las consultas se degrada. Los procesos se agotan. Los análisis en tiempo real se convierten en tareas por lotes que se ejecutan durante la noche.
Los problemas de escalabilidad surgen a medida que aumenta el volumen de datos, la concurrencia de usuarios y la complejidad de las consultas. Lo que funcionaba con 100 usuarios deja de funcionar con 10 000. Los informes que se ejecutaban en segundos ahora tardan horas.
La trampa del rendimiento
Las organizaciones suelen abordar la escalabilidad de forma reactiva, añadiendo más hardware al problema u optimizando las consultas caso por caso. Estos enfoques ofrecen un alivio temporal, pero no resuelven las limitaciones arquitectónicas subyacentes.
Según estudios sobre marcos de trabajo distribuidos para big data, el 70% de las instalaciones de Hadoop no alcanzarán sus objetivos de ahorro de costes y generación de ingresos debido a una combinación de falta de personal cualificado. La tecnología adecuada es importante, pero el diseño también lo es.
Soluciones para la escalabilidad
- Los marcos de procesamiento distribuido como Apache Spark y Apache Flink paralelizan los cálculos en clústeres. Estos marcos manejan conjuntos de datos a escala de petabytes distribuyendo el trabajo entre cientos o miles de nodos.
- Los formatos de almacenamiento columnar optimizan las consultas analíticas. Los formatos Parquet, ORC y similares almacenan los datos por columna en lugar de por fila, lo que permite un filtrado y una agregación eficientes en grandes conjuntos de datos.
- Las estrategias de particionamiento dividen las tablas grandes en fragmentos manejables. El particionamiento basado en fechas, por ejemplo, permite que las consultas examinen solo las particiones relevantes en lugar de tablas completas.
- El almacenamiento en caché y las vistas materializadas precalculan las consultas costosas. Las agregaciones y uniones a las que se accede con frecuencia se almacenan en caché en la memoria o como vistas materializadas, lo que permite obtener resultados en milisegundos en lugar de minutos.
- La optimización de consultas reescribe las consultas ineficientes. Los motores de consulta modernos aplican la optimización de predicados, la reordenación de uniones y la optimización basada en costos para minimizar los datos escaneados y los cálculos necesarios.
Un estudio de caso empresarial documentado en arXiv Research demostró que el rendimiento mejoró 500 veces en escalabilidad y 10 veces en rendimiento tras la implementación de un marco de trabajo de canalización de datos declarativo. Experimentos académicos mostraron un rendimiento 5,7 veces superior en comparación con enfoques sin marco de trabajo, con una utilización de CPU de 99%.
Desafío #5: Seguridad y privacidad de los datos
El big data implica un gran riesgo. Cuantos más datos recopilen las organizaciones, mayor será el objetivo de los ciberataques. Las filtraciones de datos exponen información de los clientes, conllevan sanciones regulatorias y dañan la reputación.
Las filtraciones de datos sanitarios cuestan, de media, 10,93 millones de dólares. Las multas del RGPD pueden alcanzar los 41 billones de dólares de ingresos anuales. La seguridad no es opcional, es un imperativo empresarial.
Amenazas de seguridad en macrodatos
Los perímetros de seguridad tradicionales se han disuelto. Los datos se mueven entre sistemas locales, plataformas en la nube, redes de socios y dispositivos móviles. Cada punto final y cada transferencia de datos crea vulnerabilidades potenciales.
Las amenazas internas plantean desafíos particulares. Los empleados con acceso legítimo pueden extraer datos confidenciales. Los permisos excesivamente amplios otorgan a los usuarios acceso a información que no necesitan. Los registros de auditoría suelen estar incompletos o se ignoran.
Soluciones para la seguridad y la privacidad
- El cifrado protege los datos tanto en reposo como en tránsito. Los estándares de cifrado modernos, como AES-256, protegen los datos almacenados, mientras que TLS protege los datos que se transmiten a través de las redes. Las claves de cifrado deben rotarse periódicamente y almacenarse por separado de los datos cifrados.
- El control de acceso y la autenticación aplican el principio de mínimo privilegio. El control de acceso basado en roles (RBAC) otorga permisos según la función del puesto. La autenticación multifactor (MFA) previene el robo de credenciales. El acceso justo a tiempo proporciona permisos temporales que caducan automáticamente.
- El enmascaramiento y la anonimización de datos protegen la información confidencial en entornos que no son de producción. El enmascaramiento reemplaza los valores reales con datos falsos realistas. La anonimización elimina la información de identificación personal (IIP) sin comprometer su utilidad analítica.
- El registro y la monitorización de auditorías permiten rastrear quién accede a qué datos y cuándo. Los sistemas de gestión de información y eventos de seguridad (SIEM) agregan registros, detectan anomalías y alertan a los equipos de seguridad sobre actividades sospechosas.
- Las herramientas de prevención de pérdida de datos (DLP) supervisan el movimiento de datos y bloquean las transferencias no autorizadas. Las políticas de DLP impiden que los datos confidenciales salgan de los sistemas autorizados a través de correo electrónico, transferencia de archivos o medios extraíbles.
Desafío #6: Escasez de profesionales cualificados
La tecnología es solo una parte de la ecuación. Las organizaciones necesitan personas que comprendan la arquitectura de datos, los sistemas distribuidos, el modelado estadístico y el análisis específico del dominio. Estas personas son escasas.
La demanda de ingenieros de datos, científicos de datos e ingenieros de aprendizaje automático supera con creces la oferta. La competencia por el talento es feroz. Los salarios suben, pero los puestos permanecen vacantes durante meses.
La brecha de habilidades
El análisis de grandes volúmenes de datos requiere una combinación de habilidades que rara vez se encuentran en una sola persona. Los ingenieros que construyen sistemas escalables pueden carecer de conocimientos estadísticos. Los científicos de datos expertos en modelado pueden tener dificultades con la implementación en producción. Los expertos en el dominio comprenden el negocio, pero no la tecnología.
La formación requiere tiempo. Las tecnologías evolucionan rápidamente. Lo que los desarrolladores aprendieron hace dos años puede que ya esté obsoleto. El aprendizaje continuo no es opcional, es la única manera de mantenerse al día.
Soluciones para la escasez de mano de obra cualificada
- Los programas de capacitación y perfeccionamiento desarrollan el talento interno. Las organizaciones que invierten en educación crean trayectorias profesionales y reducen la rotación de personal. Los cursos en línea, las certificaciones y los proyectos prácticos desarrollan habilidades prácticas.
- La contratación especializada se centra en perfiles con habilidades específicas. En lugar de buscar profesionales multidisciplinares, se crean equipos con fortalezas complementarias: ingenieros de datos, analistas, científicos y expertos en la materia que trabajan juntos.
- Los servicios gestionados y la consultoría cubren temporalmente las necesidades. Los proveedores de servicios en la nube ofrecen servicios gestionados de big data que se encargan de la complejidad de la infraestructura. Las empresas de consultoría aportan su experiencia en el diseño de la arquitectura y la implementación inicial.
- Las herramientas de bajo código y sin código democratizan el trabajo con datos. Las plataformas modernas permiten a los analistas de negocio crear paneles de control, generar informes y realizar análisis básicos sin necesidad de escribir código. Esto libera talento especializado para que se centre en problemas complejos.
- El intercambio de conocimientos y la documentación preservan el conocimiento institucional. Las arquitecturas, los manuales de procedimientos y las mejores prácticas bien documentadas ayudan a los nuevos miembros del equipo a integrarse más rápidamente y a reducir la dependencia de personas específicas.
Desafío #7: Falta de gobernanza de datos
Sin gobernanza, reina el caos de datos. Múltiples versiones de una misma métrica generan informes contradictorios. Los datos confidenciales proliferan sin controles. El cumplimiento normativo se vuelve imposible de verificar.
La gobernanza de datos establece políticas, procesos y responsabilidades para la gestión de datos. Define quién es propietario de qué datos, cómo se mide la calidad de los datos, quién puede acceder a qué y cómo se garantiza el cumplimiento.
Por qué la gobernanza es importante
La gobernanza no se trata de burocracia, sino de lograr que los datos sean fiables y utilizables. Cuando los usuarios empresariales no encuentran los datos que necesitan o no confían en los que encuentran, las inversiones en infraestructura de big data no generan ningún valor.
Las normativas como el RGPD, la CCPA, la HIPAA y la SOX exigen controles de gobernanza. Las organizaciones que no puedan demostrar su cumplimiento se enfrentan a multas, demandas y restricciones operativas.
Soluciones para la gobernanza de datos
- Los catálogos de datos crean inventarios consultables de los conjuntos de datos disponibles. Los catálogos modernos incluyen metadatos, procedencia, puntuaciones de calidad y estadísticas de uso. Los usuarios pueden encontrar datos relevantes sin necesidad de enviar correos electrónicos a sus colegas ni adivinar.
- Los programas de administración de datos asignan la propiedad y la responsabilidad. Los administradores de datos definen estándares, resuelven problemas de calidad y aprueban las solicitudes de acceso a sus dominios. Una propiedad clara previene la tragedia de los bienes comunes.
- La automatización de políticas garantiza la aplicación coherente de las reglas. En lugar de depender de procesos manuales, los sistemas automatizados aplican etiquetas de clasificación, cifrado, políticas de retención y controles de acceso basados en los atributos de los datos.
- El seguimiento del linaje muestra los orígenes y las transformaciones de los datos. El linaje ayuda a depurar problemas de calidad, evaluar el impacto de los cambios y cumplir con los requisitos de auditoría al documentar con precisión cómo los informes y los modelos obtienen sus datos de entrada.
- Los marcos de cumplimiento estructuran los esfuerzos de gobernanza. Marcos como DAMA-DMBOK y DCAM proporcionan modelos para programas de gobernanza, lo que ayuda a las organizaciones a desarrollar capacidades de forma sistemática en lugar de hacerlo de manera improvisada.
| Componente de gobernanza | Objetivo | Herramientas clave |
|---|---|---|
| Catálogo de datos | Inventario y descubrimiento | Alation, Collibra, Azure Purview, Catálogo de datos de AWS Glue |
| Calidad de los datos | Seguimiento y mejora | Grandes expectativas, Talend Data Quality, Informatica DQ |
| Control de acceso | Seguridad y cumplimiento | Apache Ranger, AWS IAM, Azure RBAC |
| Linaje | Trazabilidad y análisis de impacto | Herramientas de linaje en Alation, Collibra, Manta |
| Gestión de políticas | Aplicación automatizada | Immuta, BigID, OneTrust |

Resuelva problemas de Big Data con IA superior
Los proyectos de big data a menudo se ralentizan porque los datos están dispersos, son inconsistentes, difíciles de interpretar o están desconectados de las decisiones empresariales reales. IA superior Podemos brindar soporte a las empresas mediante consultoría en IA, estrategia de datos e IA, inteligencia empresarial, análisis de datos, aprendizaje automático, análisis predictivo y desarrollo de software de IA a medida. Para los desafíos de big data, podemos ayudar con el descubrimiento de casos de uso, la preparación de datos, los flujos de trabajo analíticos, el desarrollo de modelos y la transformación de conjuntos de datos complejos en herramientas prácticas.
El soporte de AI Superior puede incluir:
- Revisión de casos de uso de big data y objetivos comerciales
- Preparación de datos para análisis o aprendizaje automático.
- Desarrollo de soluciones de análisis predictivo e inteligencia empresarial
- Desarrollo de herramientas de IA personalizadas en torno a los datos empresariales.
- Integración de los resultados analíticos en los flujos de trabajo existentes.
Contacta con IA Superior para analizar cómo sus desafíos relacionados con el big data pueden transformarse en soluciones prácticas de IA o análisis de datos.
Historias de éxito reales
Una cosa es la teoría, otra muy distinta la implementación. A continuación, se muestran los logros de algunas organizaciones al afrontar estos desafíos de frente.
Un estudio de caso empresarial documentado en arXiv Research mostró resultados notables al implementar un marco de trabajo de canalización de datos declarativa. La eficiencia del desarrollo mejoró en 50%. Los esfuerzos de colaboración y resolución de problemas se redujeron de semanas a días. Lo más destacable es que el rendimiento mejoró 500 veces en escalabilidad y 10 veces en rendimiento.
El código fuente se redujo en 40%, lo que disminuyó la carga de mantenimiento y facilitó la comprensión del sistema. Estas no son mejoras incrementales, sino cambios fundamentales en sus capacidades.
Los experimentos académicos demostraron patrones similares. Un estudio logró un rendimiento 5,7 veces superior al de las implementaciones sin marco de trabajo, manteniendo una utilización de CPU de 99%. La elección adecuada de la arquitectura y las herramientas es fundamental.
Implementación en la nube frente a implementación local
¿Dónde debería residir la infraestructura de big data? La respuesta depende de los requisitos específicos, pero la tendencia es clara: la adopción de la nube sigue acelerándose.
Las plataformas en la nube ofrecen escalabilidad elástica, servicios gestionados y precios basados en el consumo. Las organizaciones pueden aprovisionar recursos informáticos masivos para las cargas de trabajo máximas y reducirlos durante los períodos de menor actividad. Los servicios gestionados se encargan de la complejidad de la infraestructura, las actualizaciones y las reparaciones.
Sin embargo, las implementaciones locales conservan ventajas en escenarios específicos. Las aplicaciones sensibles a la latencia, los datos altamente regulados y las inversiones en infraestructura existente pueden favorecer las arquitecturas locales o híbridas.
Los enfoques híbridos combinan ambos mundos. Las organizaciones mantienen los datos confidenciales en sus instalaciones, al tiempo que aprovechan los recursos de la nube para obtener capacidad adicional y realizar análisis. La replicación de datos, la conectividad segura y las herramientas de gestión unificadas permiten un funcionamiento híbrido sin interrupciones.
Preguntas frecuentes
¿Cuál es el mayor desafío en el ámbito del big data?
La explosión del volumen de datos se considera el desafío fundamental. Las organizaciones generan y recopilan datos a un ritmo mayor del que la infraestructura tradicional puede almacenarlos, procesarlos o analizarlos. Este desafío conlleva un aumento de los costos de almacenamiento, una disminución del rendimiento de las consultas y cuellos de botella en la infraestructura. Para resolver los problemas de volumen, a menudo se requieren arquitecturas en la nube, marcos de procesamiento distribuido y estrategias de compresión.
¿Cómo se resuelven los problemas de calidad de datos en el big data?
Las reglas de validación automatizadas detectan errores durante la ingesta de datos, evitando que los datos erróneos contaminen los sistemas posteriores. Las herramientas de análisis de datos estudian los conjuntos de datos para identificar anomalías y problemas de calidad. La gestión de datos maestros crea fuentes únicas de información fidedigna para las entidades críticas. El monitoreo de la calidad de los datos realiza un seguimiento de las métricas a lo largo del tiempo y alerta a los equipos cuando la calidad se degrada. La combinación de estos enfoques previene los problemas de calidad en lugar de solucionarlos de forma reactiva.
¿Por qué es tan difícil la seguridad de los macrodatos?
Los desafíos de seguridad de los macrodatos se derivan de su escala, distribución y complejidad. Los datos se mueven entre sistemas locales, plataformas en la nube y redes de socios, lo que genera numerosas vulnerabilidades potenciales. El enorme volumen dificulta la monitorización integral. Los múltiples puntos de acceso y usuarios legítimos complican el control de acceso. Las filtraciones de datos sanitarios cuestan, en promedio, 10,93 millones de dólares, mientras que las multas del RGPD pueden alcanzar los 41 billones de dólares de ingresos anuales, lo que hace que los fallos de seguridad sean extremadamente costosos.
¿Qué habilidades se necesitan para los puestos relacionados con el análisis de grandes datos?
Los profesionales de big data necesitan habilidades técnicas en sistemas distribuidos, lenguajes de programación como Python y SQL, y frameworks como Apache Spark. Los ingenieros de datos se centran en la creación de pipelines e infraestructura. Los científicos de datos requieren estadística, aprendizaje automático y experiencia en el sector. Ambos roles se benefician del conocimiento de plataformas en la nube, modelado de datos y diseño de sistemas. El aprendizaje continuo es esencial, ya que las tecnologías evolucionan rápidamente.
¿Cuánto cuesta la infraestructura de big data?
Los costos varían enormemente según la escala y la arquitectura. Las empresas gastaron 1.040.595.700 millones en infraestructura de computación y almacenamiento en 2024 (según Datamation). Las plataformas en la nube ofrecen precios basados en el consumo que se ajustan al uso. La compresión de datos reduce las necesidades de almacenamiento entre 50 y 801.300 millones, lo que reduce directamente los costos. Los servicios gestionados reducen los gastos operativos, pero cobran precios elevados. La infraestructura local requiere una inversión de capital inicial, pero ofrece menores costos por unidad a gran escala.
¿Es mejor la nube o las instalaciones locales para el análisis de grandes volúmenes de datos?
Las plataformas en la nube dominan las nuevas implementaciones. La nube ofrece escalabilidad elástica, servicios gestionados y precios basados en el consumo. Las implementaciones locales son adecuadas para aplicaciones sensibles a la latencia, datos altamente regulados y organizaciones con inversiones en infraestructura ya existentes. Los enfoques híbridos combinan ambos, manteniendo los datos confidenciales en las instalaciones y aprovechando los recursos de la nube para gestionar picos de capacidad.
¿Qué es la gobernanza de datos y por qué es importante?
La gobernanza de datos establece políticas, procesos y responsabilidades para la gestión de datos. Define la propiedad de los datos, los estándares de calidad, los controles de acceso y los procedimientos de cumplimiento. Sin gobernanza, las organizaciones se enfrentan a informes contradictorios, una proliferación incontrolada de datos sensibles y deficiencias en el cumplimiento normativo. La gobernanza garantiza la fiabilidad y la utilidad de los datos mediante catálogos de datos, programas de administración, automatización de políticas, seguimiento del linaje y marcos de cumplimiento.
Conclusión
Los desafíos que plantea el big data son reales, pero también lo son las soluciones. El volumen de datos sigue creciendo exponencialmente; los 2,5 petabytes por hora de Walmart son un claro ejemplo. Sin embargo, la infraestructura en la nube, las estrategias de compresión y los marcos de procesamiento distribuido ofrecen soluciones probadas para gestionar este crecimiento.
La calidad de los datos, la complejidad de la integración, los cuellos de botella en la escalabilidad, los riesgos de seguridad, la escasez de personal cualificado y las deficiencias en la gobernanza representan obstáculos. Sin embargo, las organizaciones que abordan sistemáticamente estos desafíos logran resultados extraordinarios: mejoras en la escalabilidad de 500 veces, aumentos en la eficiencia del desarrollo de 50% y un incremento de 10 veces en el rendimiento.
La clave reside en pasar de la resolución reactiva de problemas a una arquitectura proactiva. La validación de calidad automatizada supera la limpieza manual. Las plataformas de datos unificadas eliminan la complejidad de la integración. El cifrado y los controles de acceso previenen las brechas de seguridad en lugar de responder a ellas. Los programas de capacitación desarrollan capacidades internas en lugar de reclutar personal constantemente.
Ese potencial existe en todos los sectores. La cuestión no es si el big data aporta valor, sino si las organizaciones afrontarán los retos necesarios para aprovecharlo.
Empieza con un desafío. Identifica el principal problema del entorno actual. Implementa una solución. Mide los resultados. Genera impulso. La transformación de los macrodatos no ocurre de la noche a la mañana, pero el progreso sistemático se acumula con el tiempo.
¿Listo para afrontar tu mayor desafío en el ámbito del big data? Evalúa tu situación actual, prioriza las soluciones y comienza la implementación hoy mismo.