Résumé rapide : ChatGPT repose sur de grands modèles de langage (LLM) — des réseaux neuronaux de type Transformer entraînés sur de vastes ensembles de données textuelles pour prédire et générer un texte naturel. Ces modèles utilisent des mécanismes d'attention pour comprendre le contexte, puis génèrent des réponses jeton par jeton. Bien qu'extrêmement performants pour la génération de texte, le codage et la conversation, ils présentent des limitations telles que des imprécisions occasionnelles, un manque d'informations en temps réel et une sensibilité à la formulation des invites.
Grâce à ChatGPT, l'intelligence artificielle est passée des cercles technologiques aux conversations quotidiennes. On l'utilise pour rédiger des courriels, déboguer du code, trouver des idées et même rédiger des documents juridiques.
Mais comment ça marche concrètement ? Que se passe-t-il lorsque vous tapez une question et que vous recevez en quelques secondes une réponse cohérente, presque humaine ?
La solution réside dans les grands modèles de langage : des réseaux neuronaux sophistiqués qui ont fondamentalement transformé la façon dont les machines comprennent et génèrent du texte. Ce guide explique en détail l’architecture, le processus d’entraînement et les applications pratiques, sans exagération.
Que sont les grands modèles de langage ?
Les grands modèles de langage sont des systèmes d'IA conçus pour comprendre et générer le langage humain. Essentiellement, ce sont des moteurs de prédiction : à partir d'un texte donné, ils prédisent les mots qui devraient suivre.
Mais cette description simpliste ne rend pas justice à leurs performances. Les LLM modernes comme GPT-5.5 peuvent écrire du code, répondre à des questions, traduire des langues, résumer des documents et tenir des conversations d'un naturel saisissant.
Le terme “ grand ” est important. Ces modèles contiennent des milliards de paramètres — des pondérations ajustables qui déterminent la façon dont le modèle traite l'information. GPT-5.5 représente la dernière génération et offre des capacités de raisonnement améliorées par rapport aux versions précédentes.
La Fondation : Architecture des transformateurs
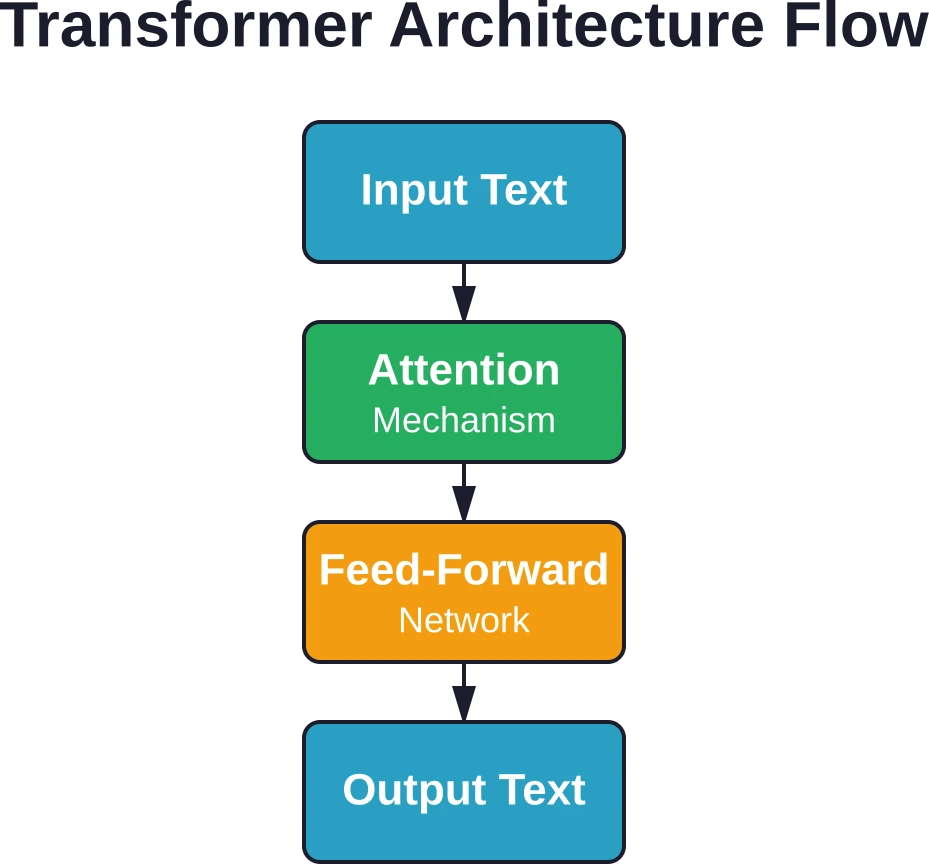
Les grands modèles de langage sont construits sur l'architecture Transformer, introduite dans l'article de recherche fondateur “ L'attention est tout ce dont vous avez besoin ”. Cette architecture a remplacé les anciens modèles de séquences par une approche plus efficace.
Voici ce qui rend les transformeurs si particuliers : ils traitent des séquences de texte entières simultanément, et non mot par mot. Ce traitement parallèle leur permet de gérer des contextes beaucoup plus longs et de s’entraîner bien plus efficacement.
L'architecture Transformer repose sur un mécanisme appelé mécanisme d'attention. Celui-ci permet au modèle de pondérer l'importance des différents mots d'une séquence lors de la génération de prédictions.
Considérons la phrase : “ L’animal n’a pas traversé la rue parce qu’il était trop fatigué. ” Pour comprendre à quoi le pronom “ il ” fait référence, le modèle doit se concentrer sur “ animal ” plutôt que sur “ rue ”. Les mécanismes attentionnels gèrent précisément ce type de raisonnement contextuel.
Comment un texte devient un nombre
Les modèles de langage ne fonctionnent pas avec des mots, mais avec des nombres. Avant tout traitement, le texte est converti en jetons, qui sont ensuite associés à des vecteurs numériques.
La tokenisation consiste à diviser un texte en unités plus petites. Un token peut être un mot entier ou seulement quelques caractères. Le mot “ chatbot ” peut devenir un seul token, tandis que “ unprecedented ” peut être décomposé en “ un ”, “ pre ” et “ cedented ”.”
Chaque jeton est associé à un vecteur de grande dimension — une liste de nombres représentant sa “ signification ” dans un espace mathématique. Les mots ayant des significations similaires se retrouvent avec des vecteurs similaires.
Cette représentation numérique permet au modèle d'effectuer des opérations mathématiques sur le langage, en décelant des schémas et des relations qu'il serait impossible de coder manuellement.

Développer des outils progressifs grâce à une IA supérieure
IA supérieure Cette entreprise conçoit des applications et des logiciels sur mesure basés sur l'IA, utilisant l'apprentissage automatique et des modèles d'IA. Ses services comprennent le développement de logiciels d'IA, le conseil, la R&D, la formation, le traitement automatique du langage naturel (TALN), l'analyse prédictive, la BI et l'analyse de données massives.
Besoin d'un outil d'IA conçu pour votre flux de travail ?
AI Superior peut vous aider avec :
- création d'outils NLP et LLM personnalisés
- Tester les idées de chatbot via une preuve de concept ou un prototype.
- analyse des données textuelles et documentaires
- intégrer les outils d'IA aux systèmes existants
👉 Contactez l'IA supérieure pour discuter de votre projet.
Comment ChatGPT génère du texte
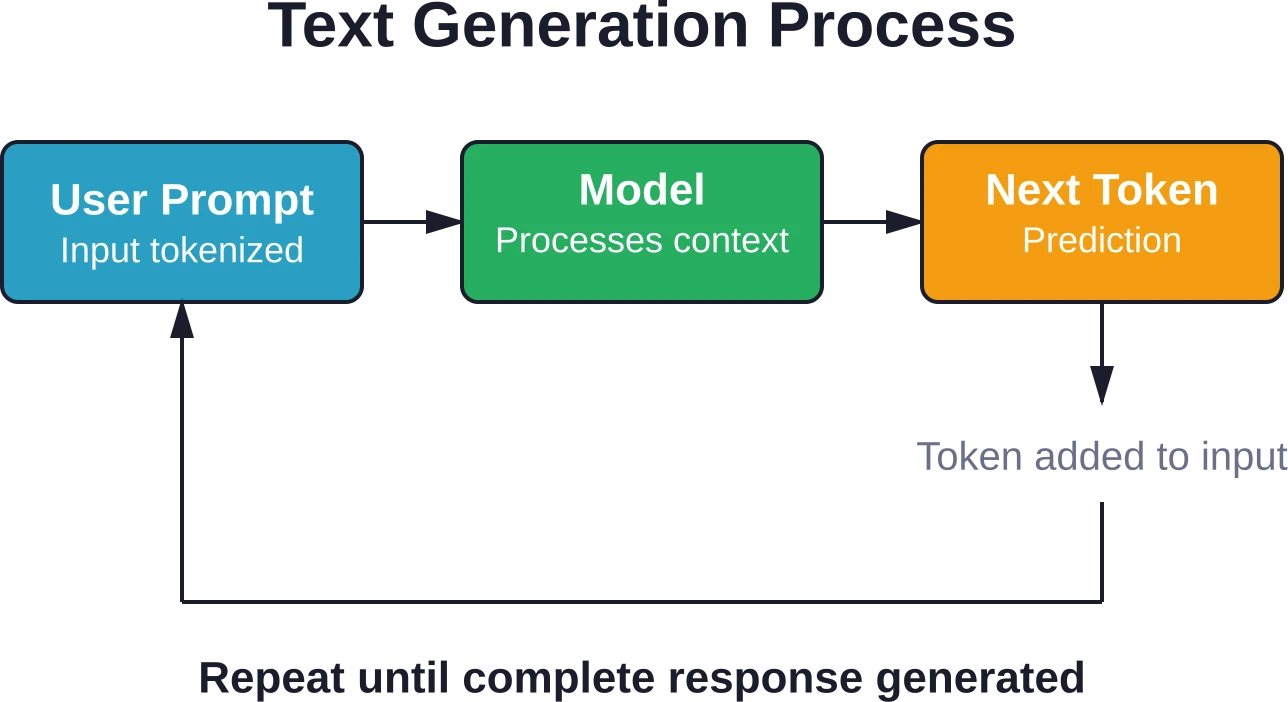
Lorsque vous envoyez une requête à ChatGPT, un processus de prédiction sophistiqué se déclenche. Le modèle ne génère pas la réponse complète d'un seul coup ; il produit un jeton à la fois.
Voici le déroulement : le modèle reçoit votre requête, la traite à travers plusieurs couches de transformation et prédit le jeton suivant le plus probable. Ce jeton prédit est ajouté à l’entrée, et le processus se répète jusqu’à ce que le modèle génère un signal d’arrêt.
Cette approche autorégressive signifie que chaque mot influence le suivant. Si le modèle commet une erreur au début de sa réponse, cette erreur peut s'amplifier à mesure que le modèle construit sa réponse sur ses propres résultats incorrects.
Le rôle de la température et de l'échantillonnage
Le modèle ne choisit pas systématiquement le mot suivant le plus probable. Cela rendrait les réponses prévisibles et répétitives.
Les modèles de langage utilisent plutôt une aléatoire contrôlée. Le paramètre de température détermine le degré d'aléatoire introduit. Une température basse rend le modèle plus déterministe et précis. Une température élevée introduit plus de variété, mais risque d'entraîner une incohérence.
L'API d'OpenAI permet aux développeurs d'ajuster ces paramètres. Pour les tâches exigeant de la précision, comme la génération de code ou l'extraction de données, des températures plus basses sont préférables. L'écriture créative, quant à elle, bénéficie de valeurs légèrement plus élevées.
Entraînement de grands modèles de langage
La création d'un modèle comme ChatGPT implique plusieurs étapes d'entraînement, chacune ayant un objectif distinct.
Préparation à la formation : Apprentissage des structures linguistiques
Le pré-entraînement est la phase durant laquelle le modèle apprend les bases du langage. Pour ce faire, il traite d'énormes ensembles de données : livres, sites web, articles, dépôts de code, etc.
L'objectif de l'entraînement est simple : prédire le mot suivant. En répétant cette opération des milliards de fois sur des textes variés, le modèle apprend la grammaire, les faits grammaticaux, les schémas de raisonnement et même une certaine forme de bon sens.
Cette phase nécessite d'importantes ressources de calcul. Les simulations d'entraînement peuvent durer des semaines, voire des mois, sur des clusters de matériel spécialisé.
Réglage fin : spécialisation du comportement
Les modèles pré-entraînés possèdent des connaissances, mais ne sont pas toujours utiles. Ils peuvent générer des réponses exactes mais inappropriées, ou ne pas suivre correctement les instructions.
Le réglage fin permet de remédier à ce problème. Selon une étude de Stanford HAI, le réglage fin personnalise les modèles de base pour des tâches ou des comportements spécifiques, mais il introduit également des risques pour la sécurité s'il n'est pas soigneusement contrôlé.
Pour ChatGPT, le réglage fin consiste à entraîner le modèle sur des ensembles de données soigneusement sélectionnés de conversations de haute qualité, les commentaires humains guidant le modèle vers des réponses utiles, inoffensives et honnêtes.
Apprentissage par renforcement à partir de retours humains
La dernière étape de l'entraînement utilise l'apprentissage par renforcement. Des évaluateurs humains classent les différentes réponses du modèle à une même consigne. Ces classements permettent d'entraîner un modèle de récompense qui prédit les préférences humaines.
Le modèle de langage est ensuite optimisé pour générer des réponses obtenant un score plus élevé selon ce modèle de récompense. Cette approche permet d'aligner le comportement du modèle sur les valeurs et les attentes humaines.
Ce modèle n'est pas parfait : il apprend à optimiser les préférences des évaluateurs, ce qui ne correspond pas toujours à la solution objectivement optimale. Mais il s'agit actuellement de la technique d'alignement la plus efficace.
L'API OpenAI et GPT-5.5
ChatGPT propose une interface utilisateur, tandis que l'API OpenAI offre aux développeurs un accès programmatique aux modèles sous-jacents. D'après la documentation officielle, l'API utilise des points de terminaison RESTful fonctionnant via des requêtes HTTP standard.
D'après la documentation officielle de l'API OpenAI, l'authentification utilise des clés API via l'authentification HTTP Bearer. Ces clés ne doivent jamais être exposées dans le code côté client ; elles sont exclusivement réservées aux applications côté serveur.
Options du modèle actuel
L'API donne accès à plusieurs modèles aux fonctionnalités et aux prix variés. D'après la documentation officielle d'OpenAI, GPT-5.5 est la dernière famille de modèles, conçue pour les flux de production complexes.
GPT-5.5 excelle dans les tâches de programmation, les flux de travail d'agents complexes, la récupération de contextes longs et les applications destinées aux clients où la qualité des réponses est primordiale. Conformément aux recommandations officielles, il convient de le considérer comme une nouvelle famille de modèles à optimiser, et non comme un remplacement direct des versions précédentes.
La documentation officielle indique que trois variantes de GPT-5.5 sont disponibles pour les utilisateurs de ChatGPT Business : GPT-5.5-Instant, avec une utilisation pratiquement illimitée pour les tâches courantes ; GPT-5.5 Thinking, avec 3 000 requêtes par semaine pour les utilisateurs de ChatGPT Business destinés au raisonnement complexe ; et GPT-5.5 Pro, avec 15 requêtes par mois pour les charges de travail les plus exigeantes.
| Modèle | Idéal pour | Atout majeur |
|---|---|---|
| GPT-5.5 Instant | tâches à volume élevé | Rapidité et disponibilité |
| GPT-5.5 Pensée | raisonnement complexe | Résolution de problèmes en plusieurs étapes |
| GPT-5.5 Pro | Charges de travail premium | Capacité maximale |
Effectuer des appels API
D'après la documentation officielle de l'API, l'API Responses gère les requêtes directes de modèles pour la génération de texte. Le principe de base consiste à créer un client, à spécifier un modèle et à fournir le texte d'entrée.
L'API renvoie des réponses structurées avec le texte généré dans le champ output_text. Les développeurs peuvent ajuster des paramètres tels que la température, le nombre maximal de jetons et les séquences d'arrêt pour contrôler le comportement de génération.
Pour les applications de production, une gestion appropriée des erreurs et une limitation du débit sont essentielles. L'API applique des limites d'utilisation en fonction de votre niveau de compte et peut renvoyer des erreurs de limitation de débit lors des pics de trafic.
Formules d'abonnement ChatGPT
OpenAI propose plusieurs niveaux d'abonnement avec des fonctionnalités et des limites différentes. Les tarifs et les fonctionnalités étant régulièrement mis à jour, il est recommandé de consulter la page officielle des tarifs pour obtenir les informations les plus récentes.
Plans pour les consommateurs
Selon le centre d'aide officiel d'OpenAI, ChatGPT Go est un abonnement à prix abordable offrant un accès étendu aux fonctionnalités les plus populaires. Il inclut un accès illimité à GPT-5.5 Instant, la génération d'images étendue, le téléchargement de fichiers et l'analyse de données avancée.
Selon des sources officielles, ChatGPT Plus est proposé au prix de $20 par mois. Il donne accès à des fonctionnalités avancées telles que Codex et la recherche approfondie pour certains projets, tout au long de la semaine.
ChatGPT Pro se décline en deux niveaux selon la documentation officielle : $100 par mois pour les projets réels avec des limites 5 fois supérieures à celles de Plus (et une utilisation du Codex 10 fois supérieure pendant une durée limitée), et $200 par mois pour les flux de travail intensifs avec des limites 20 fois supérieures à celles de Plus (et une utilisation du Codex 25 fois supérieure pendant une durée limitée).
Entreprise et commerce
ChatGPT Business propose des espaces de travail collaboratifs sécurisés pour les équipes. D'après la documentation officielle, il inclut l'authentification unique SAML, des contrôles d'administration et une prise en charge de la conformité au RGPD et au CCPA.
D'après les pages de tarification officielles, Codex est une offre axée sur le développement, avec une tarification à l'usage et sans frais fixes par poste. Elle inclut l'ingénierie logicielle basée sur l'IA, les revues de code automatisées et des environnements intégrés pour les flux de travail multi-agents.
Les forfaits Entreprise proposent des solutions personnalisées pour les grandes organisations. Les tarifs et les fonctionnalités varient selon les besoins de chaque organisation.

Applications pratiques des grands modèles de langage
Les grands modèles de langage se sont révélés utiles dans des domaines étonnamment divers. Certaines applications fonctionnent mieux que d'autres.
Création et rédaction de contenu
L'assistance à la rédaction est l'un des cas d'utilisation les plus courants. Les titulaires d'un LLM peuvent rédiger des articles, créer des textes marketing, rédiger des courriels et concevoir du contenu pour les réseaux sociaux.
La qualité est variable. Pour un contenu informatif et simple, les masters en droit (LLM) sont performants. Pour un contenu exigeant une expertise pointue, une argumentation nuancée ou une recherche originale, l'intervention humaine demeure essentielle.
De nombreux auteurs font appel à des juristes spécialisés en droit comme partenaires de brainstorming ou pour générer des premières ébauches, plutôt que pour produire le contenu final. Cette approche collaborative donne souvent de meilleurs résultats que le travail réalisé uniquement par des humains ou par une intelligence artificielle.
Génération et débogage de code
C’est en programmation que les titulaires d’un LLM moderne excellent particulièrement. Ils savent écrire des fonctions, corriger les erreurs, traduire entre langages de programmation et expliquer du code complexe.
D'après la documentation officielle, GPT-5.5 excelle particulièrement dans les tâches de programmation. Il gère les projets multi-fichiers, conserve le contexte au sein de vastes bases de code et génère du code de qualité professionnelle dans de nombreux cas de figure.
Cela dit, le code généré par LLM nécessite une vérification. Les modèles peuvent produire un code fonctionnel mais qui respecte les mauvaises pratiques, contient des bogues subtils ou présente des failles de sécurité.
Analyse et extraction des données
Les modèles de langage peuvent traiter du texte non structuré et en extraire des informations structurées. Ils analysent les documents, catégorisent le contenu, extraient les faits clés et formatent les données pour l'analyse.
Pour les applications commerciales, cela permet le traitement automatisé des documents, l'analyse des commentaires des clients et la synthèse d'informations à partir de vastes collections de textes.
Le défi réside dans la fiabilité. Il arrive que les modèles omettent des informations importantes ou introduisent des erreurs. Pour les applications critiques, des étapes de vérification sont indispensables.
Interfaces conversationnelles
Les chatbots et les assistants virtuels alimentés par LLM peuvent gérer le service client, répondre aux questions et guider les utilisateurs à travers des processus complexes.
Ces applications tirent parti de la capacité du modèle à comprendre le contexte, à gérer des formulations variées et à générer des réponses naturelles. La conversation paraît moins robotique qu'avec les systèmes traditionnels basés sur des règles.
Mais des erreurs se produisent. Il arrive que les modèles fournissent des informations erronées, paraissant pourtant convaincantes ; c’est ce qu’on appelle l’hallucination. Les applications qui traitent des décisions importantes nécessitent des mesures de protection.
Ingénierie rapide : Obtenir de meilleurs résultats
La formulation des consignes a un impact considérable sur la qualité du résultat. La conception de consignes efficaces est devenue une compétence essentielle.
Principes fondamentaux
La clarté est essentielle. Des consignes vagues produisent des résultats vagues. Des instructions précises, assorties d'exigences claires, génèrent des résultats plus utiles.
Le contexte est important. Fournir des informations générales, des exemples et des contraintes permet au modèle d'obtenir de meilleures réponses.
Les spécifications de format sont efficaces. Si vous avez besoin d'une sortie JSON, de données CSV ou d'une mise en forme Markdown, le fait de préciser explicitement cette exigence améliore la conformité.
Techniques courantes
L'apprentissage avec peu d'exemples consiste à fournir des exemples avant la requête proprement dite. Montrez au modèle 2 ou 3 exemples de la tâche souhaitée, puis présentez-lui les données d'entrée réelles. Cela améliore considérablement les performances sur des cas spécifiques.
L'utilisation d'un rôle spécifique — en demandant au modèle d'adopter un point de vue particulier — peut améliorer les réponses adaptées au domaine. Des formulations comme “ En tant que développeur Python expérimenté ” ou “ Du point de vue de la conformité légale ” orientent l'approche du modèle.
L'incitation à détailler le raisonnement demande explicitement au modèle d'expliquer sa démarche étape par étape. Cela améliore les performances en matière de raisonnement logique et de résolution de problèmes mathématiques.
| Technique | Quand l'utiliser | Exemple |
|---|---|---|
| Apprentissage avec peu d'exemples | Format de sortie spécifique requis | Fournissez 2 à 3 exemples avant la tâche |
| incitation des rôles | Expertise du domaine requise | “ En tant qu’expert en cybersécurité… ” |
| Chaîne de pensée | tâches de raisonnement complexes | “Expliquez votre raisonnement étape par étape.” |
| Instructions système | contraintes comportementales | Définir le ton, le style et les limites |
Limites et défis
Les grands modèles de langage ne sont pas magiques. Ils présentent des limitations réelles qui affectent les applications pratiques.
Seuil de connaissance et obsolescence
Les modèles apprennent pendant l'entraînement, et non pendant leur utilisation. Les données d'entraînement ont une date limite, après laquelle le modèle n'apprend plus rien.
Pour les questions portant sur des événements récents, des technologies émergentes ou des informations mises à jour, les modèles fournissent des réponses obsolètes ou erronées. Ceci est particulièrement problématique dans les domaines où le facteur temps est crucial.
Certains systèmes pallient ce problème en enrichissant les données de recherche : ils récupèrent des informations actualisées auprès de sources externes et les intègrent à l’invite. Mais cela complexifie la situation et augmente le coût.
Hallucination
Quand les modèles ignorent quelque chose, ils ne disent pas “ Je ne sais pas ”. Ils génèrent des informations qui semblent plausibles, mais qui sont incorrectes.
Cela s'explique par le fait que l'objectif du modèle est de générer un texte cohérent, et non de garantir l'exactitude des faits. Le processus d'apprentissage optimise les schémas linguistiques, et non la vérité.
Les hallucinations sont particulièrement dangereuses dans les applications à forts enjeux. Les avis médicaux, les conseils juridiques et les spécifications techniques doivent être vérifiés.
Limites du raisonnement
Malgré leurs performances impressionnantes, les LLM ne raisonnent pas comme les humains. Ils effectuent une reconnaissance de formes à partir de données d'entraînement plutôt que de construire des modèles logiques.
Cette méthode fonctionne bien pour les schémas courants, mais échoue face à des problèmes inédits exigeant un véritable raisonnement. Les mathématiques, les énigmes logiques et les tâches nécessitant une compréhension approfondie mettent en évidence ces limites.
Les modèles plus récents comme GPT-5.5 Thinking montrent des améliorations dans le raisonnement multi-étapes, mais des limitations fondamentales subsistent.
Biais et équité
Les modèles apprennent à partir de textes trouvés sur Internet, qui contiennent des biais humains. Les données d'entraînement incluent des stéréotypes, des préjugés et des associations problématiques.
Les processus de réglage fin et d'alignement réduisent ces biais, mais ne les éliminent pas. Les modèles peuvent générer des résultats reflétant des biais de genre, raciaux ou culturels présents dans les données d'entraînement.
Les applications qui affectent directement les personnes nécessitent des tests de biais rigoureux et des stratégies d'atténuation adaptées.
Considérations relatives à la sécurité et à la confidentialité
L'utilisation de modèles de langage volumineux introduit des risques en matière de sécurité et de confidentialité qui nécessitent une attention particulière.
Protection des données
Les textes envoyés aux points de terminaison de l'API sont traités sur des serveurs externes. Les informations sensibles (données personnelles, secrets commerciaux, code propriétaire) ne doivent pas y être incluses sans mesures de protection appropriées.
D'après la documentation officielle d'OpenAI, les données de l'API ne sont pas utilisées par défaut pour l'entraînement, mais elles transitent néanmoins par leur infrastructure. Pour les applications hautement sensibles, cela représente un risque inacceptable.
Certaines organisations utilisent des modèles open source auto-hébergés pour garder le contrôle de leurs données. Ce choix implique un compromis entre fonctionnalités et confidentialité.
Injection rapide
Lorsque les LLM alimentent des applications destinées aux utilisateurs, des utilisateurs malveillants peuvent tenter des attaques par injection d'instructions — en créant des entrées qui manipulent le modèle pour qu'il ignore ses instructions.
Par exemple, un chatbot programmé pour “ toujours être utile ” pourrait être amené à générer du contenu nuisible grâce à des messages habilement formulés qui annulent les instructions initiales.
Se prémunir contre l'injection rapide nécessite une validation des entrées, un filtrage des sorties et des protections architecturales qui limitent ce à quoi le modèle peut accéder ou ce qu'il peut faire.
Sécurité des clés API
La documentation de l'API OpenAI souligne que les clés API sont des informations confidentielles qui doivent être protégées. Leur divulgation permet une utilisation non autorisée, pouvant engendrer des coûts importants.
Les clés ne doivent jamais figurer dans le code côté client, les dépôts publics ni les journaux. Elles doivent être stockées dans des variables d'environnement ou des systèmes de gestion de secrets dotés de contrôles d'accès appropriés.
L'avenir des grands modèles de langage
Les capacités des modèles de langage continuent de progresser rapidement. Plusieurs tendances façonnent leur développement.
Modèles multimodaux
Les modèles actuels, comme GPT-5.5, gèrent déjà le texte et les images. Les systèmes futurs intégreront plus profondément l'audio, la vidéo et d'autres modalités.
Cela permet des interactions plus riches : analyse du contenu vidéo, génération d’images à partir de descriptions ou traitement naturel de la parole. Les modèles multimodaux peuvent s’attaquer à des problèmes nécessitant plusieurs types d’entrées et de sorties.
Améliorations de l'efficacité
D'après les enquêtes universitaires, la recherche sur les architectures efficaces vise à réduire les coûts de calcul tout en préservant les performances. Des techniques comme la quantification, l'élagage et les mécanismes d'attention efficaces permettent de concevoir des modèles plus petits et plus rapides.
Cela a son importance pour le déploiement. Les modèles plus petits fonctionnent sur du matériel moins coûteux, réduisent la latence et permettent le traitement sur l'appareil pour les applications sensibles à la confidentialité.
Fenêtres de contexte plus longues
Les premiers modèles ne traitaient que quelques centaines d'éléments de contexte. Les modèles modernes en gèrent des milliers, voire des dizaines de milliers.
Selon les recherches sur l'architecture des transformateurs, l'extension de la longueur du contexte permet de nouvelles applications : le traitement de documents entiers, le maintien de conversations plus longues et le raisonnement simultané sur davantage d'informations.
Des défis techniques subsistent en matière d'efficacité de calcul et de qualité de l'attention sur de très longues séquences, mais les progrès se poursuivent.
Un meilleur raisonnement
Les modèles actuels excellent dans la reconnaissance de formes, mais peinent à appréhender des raisonnements inédits. La recherche explore des architectures et des approches d'entraînement visant à améliorer le raisonnement logique, la résolution de problèmes mathématiques et la planification.
Les approches hybrides combinant réseaux de neurones et systèmes de raisonnement symbolique sont prometteuses. Elles pourraient pallier les limitations tout en préservant la flexibilité des modèles appris.
Questions fréquemment posées
Qu'est-ce qui différencie ChatGPT des chatbots traditionnels ?
Les chatbots traditionnels utilisent des règles et des scripts prédéfinis : ils associent les entrées de l’utilisateur à des réponses prédéfinies. ChatGPT, quant à lui, utilise un vaste modèle de langage qui génère des réponses dynamiques à partir de modèles appris grâce à d’immenses ensembles de données textuelles. Cela lui permet de traiter des questions inattendues, de comprendre le contexte et de tenir une conversation naturelle, au lieu de suivre des arbres de décision rigides.
Puis-je utiliser ChatGPT pour mon entreprise sans problème de confidentialité ?
Cela dépend des données partagées. D'après la documentation officielle, les données API ne sont pas utilisées par défaut pour la formation, mais elles transitent néanmoins par leurs systèmes. Pour les données sensibles (dossiers clients, informations confidentielles, documents confidentiels), il est recommandé d'utiliser des solutions avec des contrôles de sécurité appropriés, de mettre en place un filtrage des données ou d'envisager des alternatives auto-hébergées pour une confidentialité maximale.
Pourquoi ChatGPT fournit-il parfois des informations incorrectes ?
ChatGPT génère des réponses en prédisant des séquences de texte probables, et non en extrayant des faits vérifiés d'une base de données. Lorsqu'il ignore une information, il produit un texte plausible en s'appuyant sur des modèles issus des données d'entraînement. Cette “ hallucination ” est due au fait que le modèle privilégie la génération d'un langage cohérent plutôt que l'exactitude des faits. Il est donc essentiel de toujours vérifier les informations importantes, notamment pour les sujets spécialisés ou urgents.
Combien coûte l'intégration de l'API d'OpenAI dans une application ?
La tarification de l'API repose sur un modèle de paiement au jeton : le coût est calculé en fonction de la quantité de texte traitée et générée. Les coûts varient selon le modèle, les modèles plus performants étant plus chers par jeton. Pour connaître les tarifs actuels, consultez la page de tarification officielle d'OpenAI, car ils évoluent en fonction du volume d'utilisation. La plupart des applications commencent par des tests à petite échelle afin d'estimer les coûts avant un déploiement complet.
Les grands modèles de langage peuvent-ils remplacer les rédacteurs ou les programmeurs humains ?
Pas tout à fait. Les titulaires d'un LLM excellent dans la rédaction d'ébauches, la gestion des tâches routinières et la fourniture de points de départ, mais ils manquent de véritable compréhension, de créativité originale et de discernement. En matière d'écriture, ils produisent un contenu générique qui nécessite une révision humaine pour le style, l'exactitude et la profondeur. En programmation, ils écrivent du code fonctionnel, mais peuvent introduire des bogues, des failles de sécurité ou de mauvaises décisions architecturales. Il faut les considérer comme des assistants précieux plutôt que comme des remplaçants.
Quelle est la différence entre GPT-5.5 Instant et GPT-5.5 Thinking ?
D'après la documentation officielle, GPT-5.5 Instant est optimisé pour la rapidité et gère un nombre quasi illimité de requêtes ; il est conçu pour les tâches répétitives à volume élevé. GPT-5.5 Thinking, quant à lui, se concentre sur le raisonnement complexe et les problèmes à plusieurs étapes, avec une limite de 3 000 requêtes par semaine pour les utilisateurs de ChatGPT Business. Choisissez Instant pour des réponses rapides et un débit élevé ; choisissez Thinking lorsque les problèmes nécessitent une analyse plus approfondie.
Comment empêcher mon chatbot d'être manipulé par les utilisateurs ?
Mettez en œuvre plusieurs mesures de protection : validez et nettoyez toutes les entrées utilisateur, utilisez des instructions système difficiles à contourner, filtrez les sorties pour détecter les réponses inappropriées et concevez le système de manière à ce que le modèle ne puisse pas accéder directement aux fonctions sensibles. Des tests réguliers avec des requêtes malveillantes permettent d’identifier les vulnérabilités. Pour les applications critiques, ajoutez des points de contrôle de validation humaine pour les décisions importantes.
Conclusion
Les grands modèles de langage représentent un changement fondamental dans la façon dont les machines interagissent avec le langage humain. ChatGPT et les systèmes similaires démontrent des capacités qui semblaient impossibles il y a encore quelques années : de la génération de textes longs et cohérents à l’écriture de code fonctionnel, en passant par la participation à des conversations nuancées.
Mais comprendre leurs limites est tout aussi important que reconnaître leurs points forts. Ce sont des systèmes de reconnaissance de formes qui génèrent des textes statistiquement plausibles, et non des machines pensantes dotées d'une véritable compréhension. Ils peuvent avoir des hallucinations, présenter des biais, éprouver des difficultés avec des raisonnements inédits et ne peuvent accéder aux informations au-delà de leur seuil d'apprentissage.
La solution pratique consiste à considérer les logiciels de modélisation juridique comme de puissants outils qui augmentent les capacités humaines plutôt que de les remplacer. Utilisez-les pour la rédaction, le brainstorming, l'automatisation des tâches routinières et le traitement de gros volumes de texte. Mais maintenez l'intervention humaine pour le jugement, la vérification, la créativité et la responsabilisation.
Prêt à intégrer de grands modèles de langage à votre flux de travail ? Commencez par consulter la documentation de l’API OpenAI, expérimentez différentes techniques d’invite et mettez en place des mesures de sécurité adaptées à votre cas d’utilisation. Cette technologie est puissante ; pour l’utiliser efficacement, il est essentiel de comprendre à la fois ses capacités et ses limites.