Wichtigste Punkte: Die Kosten für die Feinabstimmung von LLM liegen typischerweise zwischen $300 und über $12.000, abhängig von Modellgröße, Verfahren und Infrastruktur. Kleine Modelle (2–3 Milliarden Parameter) kosten mit LoRA $300–$700, während größere Modelle mit 7 Milliarden Parametern mit LoRA $1.000–$3.000 oder für eine vollständige Feinabstimmung bis zu $12.000 kosten. Zu den versteckten Kosten zählen Datenaufbereitung, Speicherung, Rechenaufwand und laufende Wartung, die die ursprünglichen Schätzungen verdoppeln können.
Die Kosten fallen anders aus, wenn es um die Feinabstimmung großer Sprachmodelle geht. Was als vielversprechendes KI-Projekt beginnt, entwickelt sich schnell zu einer Budgetfrage, die Finanzchefs nervös macht.
Die Kosten für die Feinabstimmung beschränken sich nicht nur auf die GPU-Stunden. Zu den tatsächlichen Ausgaben zählen Datenaufbereitung, Speicherung, fehlgeschlagene Experimente und der Infrastrukturaufwand, der Teams oft überrascht. Diskussionen in der Community zeigen, dass einfache Feinabstimmungsaufgaben zwischen $3.000 und $10.000 kosten – und das noch ohne Berücksichtigung der versteckten Kosten.
Hier erfahren Sie, was diese Kosten tatsächlich verursacht und wie Sie sie in einem überschaubaren Rahmen halten können.
Aufschlüsselung der tatsächlichen Feinabstimmungskosten
Die Modellgröße ist wichtiger, als die meisten Teams annehmen. Die Anzahl der Parameter beeinflusst direkt den Rechenaufwand und letztendlich die Rechnung.
Basierend auf den verfügbaren Daten ergeben sich folgende Kosten für die verschiedenen Modellgrößen:
| Modellgröße | Feinabstimmungsmethode | Typischer Kostenbereich | Trainingszeit |
|---|---|---|---|
| Phi-2 (2,7B-Parameter) | LoRA | $300 – $700 | Mehrere Stunden |
| Mistral 7B | LoRA | $1.000 – $3.000 | 6-12 Stunden |
| Mistral 7B | Vollständige Feinabstimmung | Bis zu $12.000 | 24-48 Stunden |
| Lama 2 7B | LoRA | $1,200 – $3,500 | 8-16 Stunden |
Die gewählte Technik ist ebenso wichtig wie die Modellgröße. Low-Rank Adaptation (LoRA) senkt die Kosten drastisch, indem nur eine kleine Teilmenge der Parameter anstatt des gesamten Modells aktualisiert wird. LoRA-Methoden erzielten laut Benchmarks auf Finanzdatensätzen eine durchschnittliche Genauigkeitssteigerung von 361 TP3T gegenüber Basismodellen und hielten die Kosten dabei überschaubar.
Doch diese Zahlen erzählen nur einen Teil der Geschichte.

Erhalten Sie von AI Superior eine detaillierte Kostenaufstellung für die LLM-Feinabstimmung.
Die Kosten für die Feinabstimmung von LLM variieren je nach Datensatzgröße, Modellwahl, Infrastruktur und Evaluierungsanforderungen. AI Superior Hilft Organisationen bei der Beurteilung, ob eine Feinabstimmung erforderlich ist oder ob schnellere technische oder auf Datenabfrage basierende Lösungen kostengünstiger sind.
Ihr Ansatz umfasst Folgendes:
- Strategie zur Datenbewertung und -aufbereitung
- Modellauswahl und Einrichtung der Trainingspipeline
- Leistungsbewertung und Benchmarking
- Bereitstellungs- und Überwachungseinrichtung
Wenn Sie eine Feinabstimmung Ihres LLM-Studiums in Erwägung ziehen, konsultieren Sie AI Superior für eine Kosten-Nutzen-Analyse, die auf Ihre erwartete Kapitalrendite abgestimmt ist.
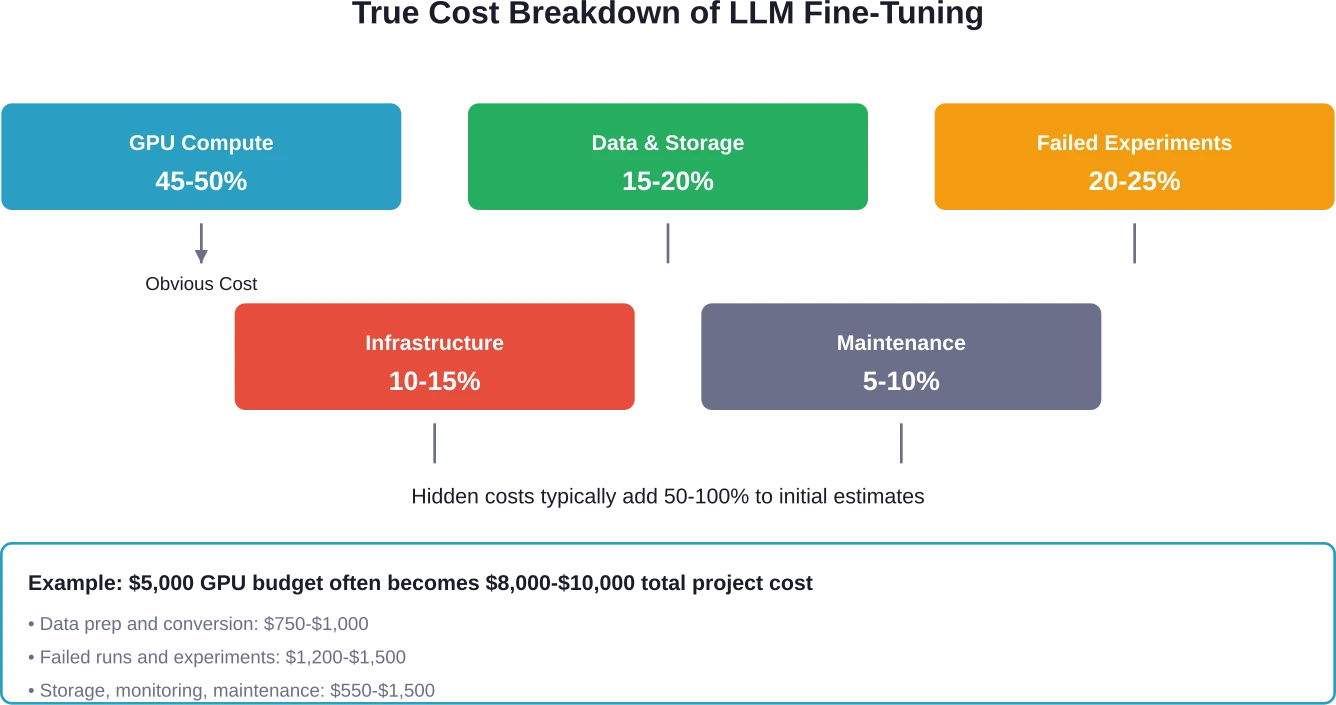
Die versteckten Kosten, vor denen Sie niemand warnt
Der angegebene Preis für GPU-Zeit deckt vielleicht nur die Hälfte der tatsächlichen Kosten ab. Der Rest taucht an Stellen auf, die Teams ursprünglich nicht eingeplant haben.
Datenaufbereitung und -speicherung
Rohdaten eignen sich nicht für die Feinabstimmung. Die Konvertierung von Datensätzen in das richtige Format – typischerweise JSONL für die meisten Plattformen – erfordert Entwicklungszeit. Community-Mitglieder, die mit 400.000 Trainings- und 2.000 Testbeispielen arbeiten, berichten von einem erheblichen Aufwand bei der Vorverarbeitung.
Die Speicherkosten summieren sich schnell. Trainingsdatensätze, Validierungsdatensätze, Modell-Checkpoints und diverse experimentelle Versionen benötigen Speicherplatz. AWS und Cloud-Anbieter berechnen diesen separat, und die Kosten steigen über Monate hinweg.
Fehlgeschlagene Experimente und Iterationen
Der erste Feinabstimmungsdurchlauf liefert selten produktionsreife Ergebnisse. Teams optimieren daher iterativ Hyperparameter, Datenqualität und Trainingsansätze. Jede Iteration ist mit Kosten verbunden.
Untersuchungen zur Dateneffizienz zeigen, dass komplexitätsbewusstes Feintuning mit nur 11% Originaldaten die gleiche Genauigkeit erreichte und andere Methoden im Durchschnitt um 4,7% übertraf. Die Ermittlung des optimalen Ansatzes erfordert jedoch Experimente – und Fehlschläge sind genauso kostspielig wie erfolgreiche.
Infrastrukturaufwand
Selbsthosting verursacht neben den Rechenkosten weitere Ausgaben. Multi-GPU-Cluster, Netzwerk, Überwachung und Wartung benötigen Ressourcen. Einfache GPU-Knoten kosten ab 1.400 US-Dollar pro Monat, und eine Unterauslastung bedeutet Geldverschwendung für ungenutzte Hardware.
OpenAI Fine-Tuning: API-basierte Preisgestaltung
OpenAI bietet Feinabstimmung als Managed Service an und berechnet die Kosten pro Token anstatt für die Infrastruktur. Das Abrechnungsmodell unterscheidet sich deutlich von selbstgehosteten Ansätzen.
Die Trainingskosten berechnen sich aus der Anzahl der Tokens multipliziert mit der Anzahl der Epochen. Bei GPT-3.5-Turbo kosten typische Trainingsdatensätze mit etwa 90.000–100.000 Tokens mehrere hundert Dollar für ein vollständiges Feintuning. Validierungsdatensätze verursachen zusätzliche Token-Gebühren.
Hier wird es jedoch knifflig. Die API schätzt den maximal möglichen Tokenverbrauch im Voraus, einschließlich Bild-Token und dem Overhead von Funktionsaufrufen. Bilder können pro Epoche bis zu 1.105 Token für Standardauflösung oder 36.835 Token für hochauflösende Eingaben verbrauchen – Kosten, die Entwickler überraschen, die das Kleingedruckte nicht lesen.
Reinforcement Fine-Tuning (RFT) für Reasoning-Modelle verwendet ein völlig anderes Abrechnungsmodell. Anstelle einer tokenbasierten Preisgestaltung berechnet RFT die Kosten anhand der für die eigentliche maschinelle Lernarbeit aufgewendeten Zeit. Die Abrechnung hängt von den Einstellungen für den `compute_multiplier`, der Validierungshäufigkeit und der Auswahl des Grader-Modells ab.
AWS und Cloud-Plattformkosten
Amazon Bedrock und SageMaker bieten verwaltetes Feintuning mit nutzungsbasierter Abrechnung. Die Kosten variieren je nach Anbieter, Modalität und Instanztyp.
Die Preise von SageMaker hängen von der gewählten Instanz ab. Die häufig für das Feinabstimmen von 7-B-Modellen verwendete Instanz ml.g5.12xlarge hat einen Rechenaufwand von ca. 1T4T7–1T4T8 pro Stunde. Ein typischer Feinabstimmungsauftrag, der 8–12 Stunden dauert, verursacht allein an Rechenkosten Kosten von 1T4T60–1T4T100.
Die Preise für Amazon Bedrock variieren je nach Modell erheblich. Titan-Modelle, Claude-Varianten und Llama-Modelle haben jeweils unterschiedliche Preislisten. Die Feinabstimmung von Einbettungsmodellen ist in der Regel günstiger als die Feinabstimmung von generativen Modellen.
Die Speicherung auf AWS verursacht zusätzliche Kosten. S3-Speicher für Datensätze, Modellartefakte und Checkpoints sowie EBS-Volumes für Instanzen verursachen Gebühren. Bei einem Projekt mit 1.000 Benutzern, die täglich 10 Anfragen mit 2.000 Eingabe- und 1.000 Ausgabetoken durchführen, können die Kosten für Speicherung und Datentransfer die Rechenkosten im Laufe der Zeit übersteigen.
Die Entscheidung zwischen Selbsthosting und Cloud
Selbsthosting erscheint zunächst teuer, kann aber bei größerem Umfang günstiger sein. Cloud-Lösungen wirken anfangs günstig, die Kosten steigen jedoch mit der Zeit.
| Faktor | Selbstgehostet | Cloud/API |
|---|---|---|
| Anfangsinvestition | Hoch ($5.000-$15.000) | Keiner |
| Monatliche Betriebskosten | Nur Strom (~$100-$300) | $500-$5,000+ |
| Skalierbarkeit | Durch die Hardware begrenzt | Im Wesentlichen unbegrenzt |
| Wartungsaufwand | Hoch (internes Team) | Keiner |
| Datenschutz | Volle Kontrolle | Abhängig vom Anbieter |
| Gewinnschwelle | 3-6 Monate | N / A |
Eine RTX 4090 kostet einmalig 1.600 Tsd. 4 Tsd. 1.600 Tsd. 4 Tsd. 2.500 Tsd. 4 Tsd. 4 Tsd. 4 Tsd. 2 ...3 Tsd. 4.
Die Cloud ist jedoch sinnvoll für Experimente und variable Arbeitslasten. Bei Bedarf einen Feinabstimmungsprozess zu starten, ist deutlich besser, als ungenutzte Hardware zu betreiben.
Kostensenkungsstrategien, die tatsächlich funktionieren
Die Senkung der Kosten für die Feinabstimmung bedeutet nicht, dass man auf Ergebnisse verzichten muss. Mehrere bewährte Techniken reduzieren die Ausgaben erheblich.
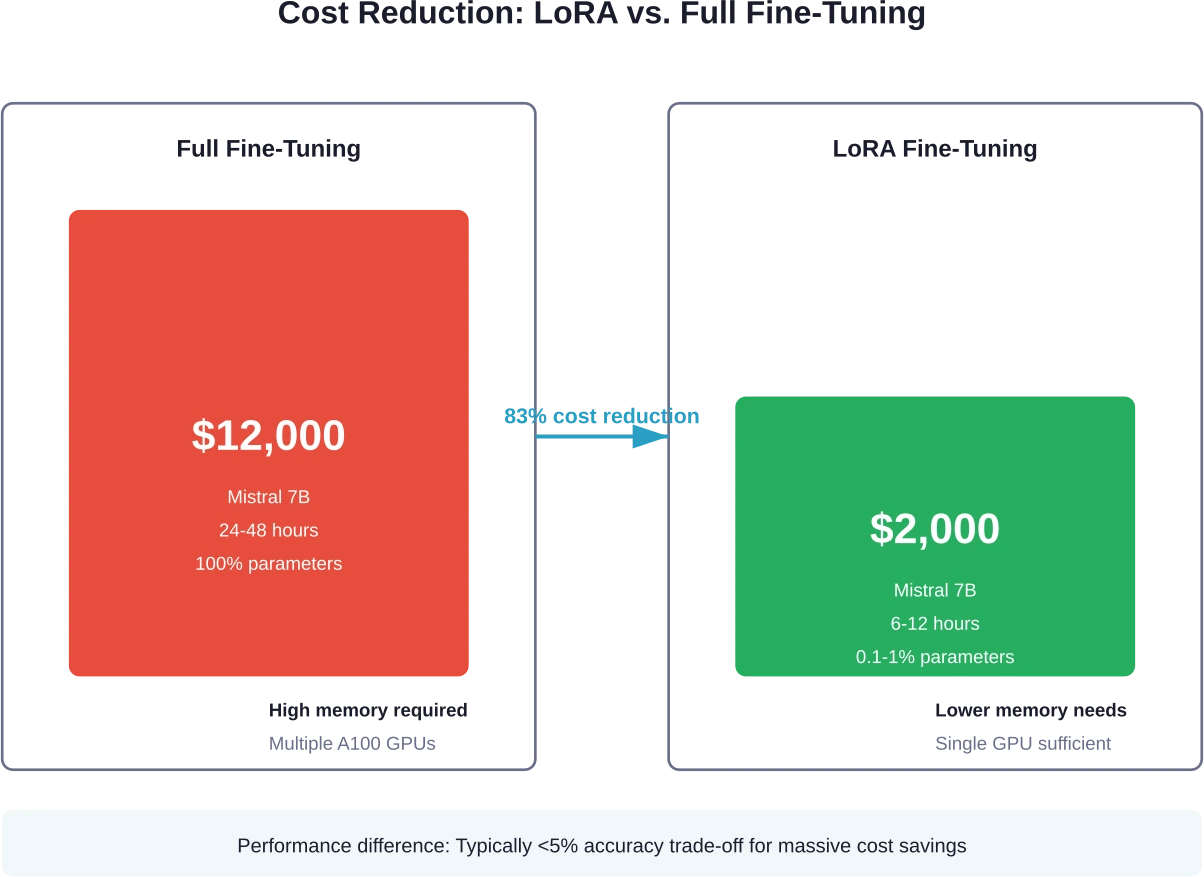
Verwenden Sie LoRA anstelle der vollständigen Feinabstimmung.
LoRA erzielt vergleichbare Ergebnisse, indem lediglich 0,1–1% Modellparameter aktualisiert werden. Die Reduzierung der trainierbaren Parameter führt direkt zu einem geringeren Rechenaufwand und kürzeren Trainingszeiten.
LoRA-Methoden sind etwa 4- bis 10-mal günstiger als eine vollständige Feinabstimmung desselben Modells. Mistral 7B benötigt mit LoRA $1.000 bis $3.000 Iterationen, im Vergleich zu $12.000 Iterationen bei vollständiger Feinabstimmung – gleiches Modell, aber deutlich unterschiedliche Kosten.
Nutzen Sie die Rechenleistung außerhalb der Spitzenzeiten
Einige Anbieter bieten Spot-Instanzen oder Preise außerhalb der Spitzenzeiten an. Diskussionen in der Community deuten auf Interesse an kostengünstigeren Feinabstimmungsoptionen hin, wobei einige auf mögliche Kostensenkungen für 70% durch verschiedene Optimierungsansätze hinweisen.
Datenqualität vor Datenmenge priorisieren
Mehr Trainingsdaten bedeuten nicht immer bessere Ergebnisse. Untersuchungen zum komplexitätsbewussten Feintuning zeigen, dass eine gezielte Datenauswahl mit 111.300 Originaldaten die gleiche Genauigkeit erzielt.
Die Auswahl hochwertiger Beispiele reduziert die Anzahl der benötigten Token und die Trainingszeit. Anstatt dem Modell 1 Million Token zuzuführen, erzielen 100.000 sorgfältig ausgewählte Token oft die gleichen Ergebnisse – zu einem Bruchteil der Kosten.
Intelligente Hyperparameter-Auswahl
Aggressive Lernraten und weniger Epochen verkürzen die Trainingszeit, ohne die Leistung zwangsläufig zu beeinträchtigen. Die optimale Balance zu finden erfordert etwas Experimentieren, aber die Einsparungen summieren sich schnell.
Die Validierungshäufigkeit ist ebenfalls wichtig. Eine Reduzierung der Validierungshäufigkeit (z. B. alle 100 Schritte statt alle 10 Schritte) senkt die Validierungskosten proportional. Bei der Feinabstimmung des Reinforcement Learnings reduziert die Wahl effizienter Grader-Modelle und die Vermeidung übermäßiger Validierungsläufe die Kosten direkt.
Wann sich Feinabstimmung finanziell lohnt
Nicht jeder Anwendungsfall rechtfertigt die Kosten für Feinabstimmungen. Die Wirtschaftlichkeit muss gegeben sein.
Feinabstimmung ist sinnvoll, wenn:
- Domänenspezifische Genauigkeit ist wichtiger als die Kosten. Medizinische, juristische oder finanzielle Anwendungen, bei denen Fehler reale Konsequenzen haben, rechtfertigen die Investition.
- Hohes Datenvolumen verteuert API-Aufrufe. Bei Anwendungen mit hohem Durchsatz, die monatlich Millionen von Token verarbeiten, ist eine Feinabstimmung oft kostengünstiger als wiederholte API-Aufrufe.
- Datenschutz erfordert lokale Kontrolle. Für sensible Daten, die die Infrastrukturgrenzen nicht verlassen dürfen, sind selbstgehostete, feinabgestimmte Modelle erforderlich.
- Spezielle Formate oder Ausgaben sind erforderlich. Wenn alleiniges Auffordern nicht zur gewünschten Ergebnisstruktur oder Verhaltenskonsistenz führen kann.
Feinabstimmung ist nicht sinnvoll, wenn:
- Schnelles Engineering erzielt ähnliche Ergebnisse. Kontextfenster unterstützen jetzt 200.000 bis 1 Million Tokens. Viele Aufgaben funktionieren einwandfrei mit umfassenden Systemabfragen.
- Modelle ändern sich schneller als Bereitstellungszyklen. Alle vier bis sechs Monate kommen bessere Modelle auf den Markt. Die Feinabstimmung des Mistral 4B wird überflüssig, wenn Wochen später der Qwen oder der Llama 3 erscheinen.
- Das Volumen rechtfertigt die Vorlaufkosten nicht. Bei Anwendungen mit geringem Datenverkehr, die monatlich 100.000 TP/4T an API-Gebühren zahlen, sind die Kosten für die Feinabstimmung in Höhe von 5.000 TP/4T nicht zu rechtfertigen.
Die Berechnung läuft auf eine Break-Even-Analyse hinaus. Kostet die Feinabstimmung 1.400.8000 Tsd. und spart sie monatlich 1.400.500 Tsd. an API-Gebühren, so amortisiert sich die Investition in 16 Monaten. Das ist für stabile, langfristige Anwendungen angemessen. Für experimentelle Projekte oder sich schnell entwickelnde Anwendungsfälle ist es jedoch ungeeignet.
Die Ökonomie der Feinabstimmung der Verstärkung
Das Reinforcement Learning Fine-Tuning führt zu einer anderen Kostendynamik. Im Gegensatz zum überwachten Fine-Tuning, das über Token abgerechnet wird, berechnet RFT die Rechenzeit, die für das eigentliche Training aufgewendet wird.
Die Abrechnung der RFT-API von OpenAI basiert auf der Trainingsdauer, nicht auf der Datensatzgröße. Zu den Kostentreibern gehören:
- Multiplikatoreinstellungen berechnen, die die Trainingsgeschwindigkeit steuern
- Validierungshäufigkeit und Auswahl des Gradermodells
- Episodenlänge und Komplexität der Aufgabe
Die Optimierung der RFT-Kosten bedeutet, das kleinste Grader-Modell auszuwählen, das die Qualitätsanforderungen erfüllt, übermäßige Validierungsläufe zu vermeiden und den benutzerdefinierten Auswertungscode effizient zu halten.
Untersuchungen zur Dateneffizienz beim Reinforcement Learning zeigen, dass gezielte Online-Datenauswahl und Rollout-Replay die Trainingszeit um 231 TP³T bis 621 TP³T reduzieren und gleichzeitig die Leistung erhalten. Dies führt direkt zu Kosteneinsparungen, die proportional zur Zeitersparnis sind.
Überwachung und Verwaltung laufender Kosten
Feinabstimmung ist keine einmalige Ausgabe. Modelle driften ab, Daten ändern sich, und ein erneutes Training wird notwendig.
Die Erfassung der Kosten pro Kunde oder Projekt ermöglicht eine transparente Kostenverteilung. Für Teams, die mehrere Kunden über ein einziges Konto betreuen, bietet die Abfrage von Auftragsdetails per API und die Kostenberechnung anhand trainierter Token und des Modelltyps eine ungefähre Kostenverfolgung.
Durch die Festlegung von festen Limits werden unkontrollierte Kosten vermieden. OpenAI und Cloud-Anbieter unterstützen Kostenobergrenzen, die Trainingsprozesse stoppen, sobald bestimmte Schwellenwerte erreicht sind. Dies schützt davor, dass falsch konfigurierte Prozesse Tausende von Dollar an GPU-Zeit verbrauchen.
Die Überwachung über das Dashboard ist wichtig. Durch die Beobachtung des Trainingsfortschritts können leistungsschwache Aufgaben pausiert oder abgebrochen werden, bevor weitere Ressourcen verschwendet werden. Die meisten Plattformen zeigen Echtzeit-Kennzahlen und die aufgelaufenen Kosten an.
Häufig gestellte Fragen
Wie viel kostet die Feinabstimmung eines 7B-Parametermodells?
Das Feinabstimmen eines 7-B-Modells wie Mistral oder Llama kostet typischerweise 1.000 bis 3.000 PKR (1004 Tsd. bis 1004 Tsd.) mit LoRa-Techniken oder bis zu 12.000 PKR (1004 Tsd. bis 1004 Tsd.) für eine vollständige Feinabstimmung. Die genauen Kosten hängen von der Datensatzgröße, der Trainingsdauer und der gewählten Infrastruktur (Cloud vs. Eigenhosting) ab.
Ist LoRA genauso effektiv wie eine vollständige Feinabstimmung?
LoRA erzielt für die meisten Anwendungen eine vergleichbare Leistung wie die vollständige Feinabstimmung, mit einem Genauigkeitsunterschied von typischerweise weniger als 5%. LoRA aktualisiert lediglich 0,1–1% Parameter und liefert dabei ähnliche Ergebnisse zu 4- bis 10-mal geringeren Kosten und deutlich kürzeren Trainingszeiten.
Welche versteckten Kosten birgt die Feinabstimmung von LLM?
Zu den versteckten Kosten zählen Datenaufbereitung und -konvertierung (10–151 Tsd. Billionen Pfund Budget), fehlgeschlagene Experimente und Iterationen (20–251 Tsd. Billionen Pfund), Speicherung von Datensätzen und Prüfpunkten (5–101 Tsd. Billionen Pfund), Infrastrukturaufwand für selbstgehostete Systeme (10–151 Tsd. Billionen Pfund) sowie laufende Wartung und Nachschulung (5–101 Tsd. Billionen Pfund). Diese Kosten können die anfänglichen GPU-Kostenschätzungen verdoppeln.
Wann sollte ich die API-Feinabstimmung und wann das Selbsthosting verwenden?
Die API-Feinabstimmung ist sinnvoll für variable Arbeitslasten, Experimente und Teams ohne ML-Infrastruktur. Selbsthosting ist kosteneffektiv für konsistente, hochvolumige Arbeitslasten, da sich eine einmalige Hardwareinvestition ($5.000–$15.000) im Vergleich zu laufenden Cloud-Kosten innerhalb von 3–6 Monaten amortisiert.
Wie kann ich die Kosten für die Feinabstimmung des 70% reduzieren?
Nutzen Sie LoRA anstelle von vollständigem Feintuning, greifen Sie auf Spot-Instanzen oder günstigere Tarife außerhalb der Spitzenzeiten zurück, optimieren Sie die Datenqualität, um die Datensatzgröße um 80–901 Tsd. Byte zu reduzieren, verringern Sie die Validierungshäufigkeit und wählen Sie effiziente Hyperparameter, die die Trainingszeit verkürzen. Durch die Kombination dieser Strategien lassen sich die Kosten um 701 Tsd. Byte oder mehr senken.
Ist eine Feinabstimmung bei großen Kontextfenstern sinnvoll?
Große Kontextfenster (200.000–1 Million Tokens) reduzieren in vielen Fällen den Bedarf an Feinabstimmung. Wenn umfassende Eingabeaufforderungen zufriedenstellende Ergebnisse liefern, sind sie oft kostengünstiger als eine Feinabstimmung. Eine Feinabstimmung ist jedoch weiterhin sinnvoll für konsistentes Verhalten, spezifische Ausgabeformate oder wenn wiederholte API-Aufrufe die Kosten der Feinabstimmung übersteigen.
Wie oft müssen feinabgestimmte Modelle neu trainiert werden?
Die Häufigkeit des Nachtrainierens hängt von Datenabweichungen und dem Lebenszyklus des Modells ab. Produktionsmodelle müssen typischerweise alle 3–6 Monate aktualisiert werden, wenn sich die zugrunde liegenden Daten ändern oder bessere Basismodelle veröffentlicht werden. Anwendungen mit hohem Risiko erfordern möglicherweise ein monatliches Nachtrainieren, während in stabilen Bereichen jährliche Zyklen möglich sind.
Die Investitionsentscheidung treffen
Feinabstimmungen kosten Geld. Die Entscheidung, fortzufahren, sollte nicht leichtfertig getroffen werden.
Prüfen Sie zunächst, ob eine Feinabstimmung erforderlich ist. Testen Sie zunächst umfangreiche Eingabeaufforderungen mit dem Basismodell. Viele Teams stellen fest, dass 90% für ihren Anwendungsfall ohne Feinabstimmung funktioniert.
Berechnen Sie die Gesamtbetriebskosten – nicht nur die GPU-Stunden. Berücksichtigen Sie Datenaufbereitung, Budget für Experimente, Speicherung und Wartung. Addieren Sie 50–1001 TP3T zu den ersten Schätzungen für versteckte Kosten.
Vergleichen Sie dies mit den API-Kosten beim erwarteten Volumen. Bei aktuellen Ausgaben von 1.400.200 pro Monat und Optimierungskosten von 1.400.8000 liegt der Break-Even-Punkt bei 40 Monaten. Diese Rechnung ist für die meisten Projekte nicht aufgegangen.
Berücksichtigen Sie die Langlebigkeit des Modells. Die Feinabstimmung eines Modells, das in vier Monaten veraltet sein wird, ist Ressourcenverschwendung. Schnell fortschreitende Modellfamilien machen die Feinabstimmung weniger attraktiv als es zunächst scheint.
Doch wenn Fachwissen, Datenschutz oder die Wirtschaftlichkeit des Volumens es rechtfertigen, liefert die Feinabstimmung einen Mehrwert, den generische Modelle nicht bieten können. Entscheidend ist, die Zahlen ehrlich zu prüfen, bevor Budgets freigegeben werden.
Die Teams, die mit LLM-Feinabstimmung erfolgreich sind, betrachten sie als Investitionsentscheidung, nicht als technische Wahl. Sie messen die Kosten, setzen klare Leistungsziele und kennen ihren Break-Even-Punkt, bevor die erste GPU in Betrieb geht.
Sie möchten Ihre KI-Entwicklungskosten optimieren? Beginnen Sie mit einer genauen Messung Ihrer aktuellen API-Ausgaben und der Prognose des Volumenwachstums. Diese Basisdaten zeigen, ob eine Feinabstimmung in Ihrer spezifischen Situation wirtschaftlich sinnvoll ist.