Kurzzusammenfassung: Die Preise für LLM-APIs variieren 2026 je nach Anbieter erheblich. Sie reichen von DeepSeeks budgetfreundlichem Angebot von $0,28 pro Million Token bis hin zu OpenAIs GPT-5.2 Pro mit $21 pro Million Input-Token. Durch das Verständnis tokenbasierter Preismodelle, versteckter Kosten wie Caching und Einbettungen sowie Optimierungsstrategien lassen sich die Ausgaben um 30–90% senken, ohne die Leistung zu beeinträchtigen.
Der Markt für große Sprachmodell-APIs ist explosionsartig gewachsen. Über 300 Modelle konkurrieren mittlerweile um die Aufmerksamkeit der Entwickler, jedes mit völlig unterschiedlichen Preisstrukturen.
Die Wahl des falschen Anbieters kann zu monatlichen Mehrausgaben in Höhe von Tausenden führen. Einige Quellen deuten darauf hin, dass Unternehmen für LLM-APIs zu viel bezahlen, wobei die genauen Überzahlungsprozentsätze je nach Anwendungsfall variieren, einfach weil sie ihre Modellauswahl und Nutzungsmuster nicht optimiert haben.
Dieser Vergleich schlüsselt die aktuelle Preisgestaltung der wichtigsten Anbieter auf, deckt versteckte Kosten auf, die Teams unvorbereitet treffen, und zeigt genau, wohin Ihr Geld fließt, wenn Sie eine LLM-API aufrufen.
LLM-API-Preismodelle verstehen
Die meisten LLM-APIs berechnen die Kosten pro Token. Aber was bedeutet das konkret für Ihr Budget?
Ein Token entspricht etwa vier Textzeichen. Das Wort “understanding” enthält ungefähr drei Tokens. Ihre API-Aufrufe werden separat für Eingabe-Tokens (was Sie senden) und Ausgabe-Tokens (was das Modell generiert) abgerechnet.
Ausgabetoken kosten typischerweise 3- bis 6-mal so viel wie Eingabetoken. Diese Asymmetrie ist relevant, wenn lange Antworten generiert werden.
Die drei Hauptpreisstufen
Die Anbieter strukturieren ihre Preisgestaltung anhand von drei Verbrauchsmodellen:
- Auf Abruf (Standard): Bezahlung pro Token ohne Verpflichtungen. Höchste Kosten pro Token, aber maximale Flexibilität. Ideal für Prototypen oder unvorhersehbare Arbeitslasten.
- Stapelverarbeitung: Stellen Sie Anfragen, die asynchron innerhalb von 24 Stunden verarbeitet werden. Amazon Bedrock und OpenAI bieten beide Rabatte von 50% für Batch-Anfragen im Vergleich zu On-Demand-Preisen. Ideal für nicht dringende Aufgaben wie Datenanalyse oder Content-Erstellung.
- Bereitgestellter Durchsatz: Sichern Sie sich dedizierte Kapazität mit garantierten Reaktionszeiten. Abrechnung stündlich oder monatlich. Ideal für die Verarbeitung konstant hoher Datenmengen und den Bedarf an vorhersehbarer Latenz.
OpenAI hat in seiner neuesten Preisstruktur zusätzliche Stufen eingeführt. Die “Flex”-Stufe bietet moderate Rabatte, während die “Priority”-Stufe eine schnellere Bearbeitung während der Spitzenzeiten garantiert.
Aufschlüsselung der Preise der wichtigsten Anbieter
Lassen wir das Marketing beiseite und schauen wir uns die tatsächlichen Zahlen von den offiziellen Preisseiten an.
OpenAI API-Preise (2026)
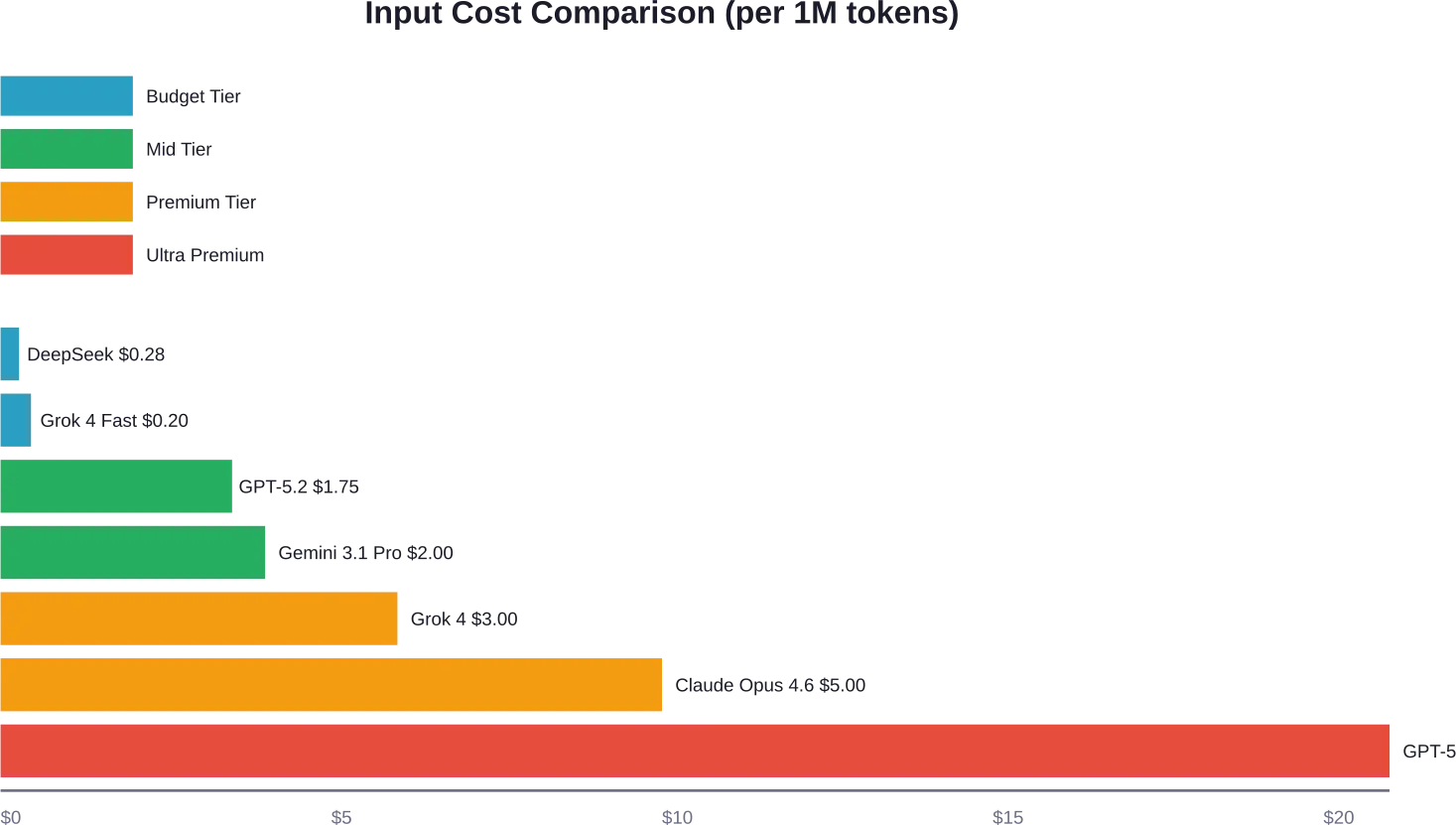
Das Produktangebot von OpenAI wurde deutlich erweitert. Laut der offiziellen Preisseite von OpenAI berechnen sie folgende Preise pro Million Token:
| Modell | Inputkosten | Zwischengespeicherte Eingabe | Produktionskosten |
|---|---|---|---|
| GPT-5.2 Pro | $21.00 | N / A | $168.00 |
| GPT-5.2 | $1.75 | $0.175 | $14.00 |
| GPT-5 Mini | $0.25 | $0.025 | $2.00 |
| GPT-5 Nano | $0.025 | $0.0025 | $0.20 |
| GPT-4.1 | $1.00 | N / A | $4.00 |
| GPT-4o | $1.25 | N / A | $5.00 |
Das Flaggschiff GPT-5.2 ist für komplexe Schlussfolgerungen und agentenbasierte Arbeitsabläufe konzipiert. GPT-5 Nano bietet den günstigsten Einstieg in das aktuelle OpenAI-Portfolio und eignet sich für einfache Klassifizierungs- oder Extraktionsaufgaben.
Ihre Batch-API halbiert diese Preise. Die Batch-Preisgestaltung von GPT-5.2 kostet $0,875 Input und $7,00 Output pro Million Token, was einer Ermäßigung von 50% gegenüber dem Standardpreis entspricht.
Anthropic Claude Preisgestaltung
Die Claude-Modelle von Anthropic verwenden eine andere Architektur mit ausgeprägten Kontext-Caching-Funktionen. Aus der offiziellen Dokumentation:
| Modell | Basiseingabe | Cache-Treffer | Ausgabe |
|---|---|---|---|
| Claude Opus 4.6 | $5.00 | $0.50 | $25.00 |
| Claude Opus 4.5 | $5.00 | $0.50 | $25.00 |
| Claude Opus 4.1 | $15.00 | $1.50 | $75.00 |
Claudes Caching-System bietet einen Rabatt von 90% bei der Wiederverwendung von Kontext. Wenn Sie einen Chatbot entwickeln, der wiederholt auf dieselbe Wissensdatenbank zugreift, bedeuten Cache-Treffer von $0,50 pro Million Token im Vergleich zu $5,00 für neue Eingaben enorme Einsparungen.
Anthropic bietet außerdem Stapelverarbeitung zu 50%-Preisen unter den Standardtarifen an und entspricht damit der Rabattstruktur von OpenAI.
Google Vertex AI (Gemini-Modelle)
Googles Vertex AI-Plattform hostet neben der Gemini-Produktfamilie auch Modelle von Drittanbietern. Die Preise auf der offiziellen Vertex AI-Seite lauten wie folgt:
| Modell | Eingabe ≤200K Token | Eingang >200K | Ausgabe |
|---|---|---|---|
| Gemini 3.1 Pro Vorschau | $2.00 | $4.00 | $12.00 |
| Gemini 3.1 Blitz | Preisgestaltung der niedrigeren Stufe | Siehe offizielle Dokumente | Siehe offizielle Dokumente |
Google verwendet Preisschwellen für längere Anfragen. Anfragen mit mehr als 200.000 Tokens werden für alle Tokens dieser Anfrage höher berechnet. Gemini 2.5 Pro beinhaltet täglich 10.000 kostenlose, integrierte Web-Suchanfragen (Grounded Prompts) und berechnet anschließend $35 pro 1.000 weiteren integrierten Web-Suchanfragen.
Die Kosten für die Web-Erdung im Unternehmen betragen $45 pro 1.000 erzeugten Suchanfragen. Diese sucherweiternden Funktionen summieren sich schnell, wenn die Nutzung nicht überwacht wird.
Amazon Bedrock Multi-Modell-Plattform
AWS Bedrock aggregiert Modelle verschiedener Anbieter unter einheitlicher Abrechnung. Laut der Preisaktualisierung vom Februar 2026:
- Claude 3.5 Sonnet beginnt bei $3 Input / $15 Output pro Million Token
- Gemma 3 4B kostet $0,04 Input / $0,08 Output
- Gemma 3 12B läuft mit $0.09 Eingang / $0.18 Ausgang
Bedrock bietet Batch-Inferenz mit 50% zu On-Demand-Preisen an. Das bereitgestellte Durchsatzmodell berechnet die Kosten pro Modellstunde anstatt pro Token, wobei bei Vertragslaufzeiten Rabatte für 1- oder 6-Monats-Verträge gewährt werden.
Amazon bietet seine Nova-Modelle ebenfalls zu wettbewerbsfähigen Preisen an, wobei die genauen Preise je nach Region variieren.
Budget-Optionen: DeepSeek und xAI
Das chinesische Unternehmen DeepSeek hat den Markt mit aggressiven Preisen für seine V3.2-Exp-Modelle aufgemischt. Laut verfügbaren Preisdaten werden die V3.2-Exp-Modelle von DeepSeek mit $0,60 pro Million Input-Token (Cache-Fehler) bzw. $0,40 pro Reasoning-Output-Token gehandelt.
xAI hat Grok 4 mit einem Input von $3 und einem Output von $15 pro Million Token auf den Markt gebracht. Die schnellere Variante Grok 4.1 Fast kostet $0,20 Input und $0,50 Output und richtet sich an Entwickler, denen Geschwindigkeit wichtiger ist als maximale Leistungsfähigkeit.
Versteckte Kosten, die Ihre Rechnung in die Höhe treiben
Die reinen Token-Kosten sorgen für Schlagzeilen. Doch diverse weniger offensichtliche Gebühren können Ihre tatsächlichen Ausgaben verdoppeln.
Eingabeaufforderungs-Caching und Kontextfenster
Große Kontextfenster klingen verlockend, bis man merkt, dass man jedes Mal für jedes Token bezahlen muss. OpenAI und Anthropic bieten beide ein schnelles Caching, um die Kosten wiederholter Kontextnutzung zu reduzieren.
Laut OpenAI-Dokumentation sind zwischengespeicherte Eingabetoken um 90% günstiger als Standardeingaben. Bei GPT-5.2 betragen die Kosten zwischengespeicherter Token $0,175, während nicht zwischengespeicherte Token $1,75 kosten.
Der Haken? Cache-Schreibvorgänge kosten Geld. Die Preisgestaltung von Anthropic zeigt, dass die Kosten für Cache-Schreibvorgänge je nach Dauer variieren: 5-minütige Cache-Schreibvorgänge kosten $6,25 pro Million Token und 1-stündige Schreibvorgänge $10 pro Million Token für Claude Opus 4.6.
Wenn der Kontext nicht häufig genug wiederverwendet wird, sind die Kosten für das Caching höher als die Einsparungen.
Einbettungen und Vektorsuche
Der Aufbau eines RAG-Systems (Retrieval-Augmented Generation) erfordert die Generierung von Einbettungen. Diese Kosten fallen separat von den Kosten für die Hauptinferenz an.
Amazon Titan Text Embeddings V2 kostet laut AWS-Dokumentation $0,00002 pro 1.000 Eingabe-Tokens. Das klingt günstig, bis man Millionen von Dokumenten einbetten muss.
Zusätzlich fallen Kosten für die Vektorspeicherung an. Googles Vertex AI RAG Engine beinhaltet Gebühren für die Datenerfassung, das LLM-Parsing zur Segmentierung und Vektorsuchoperationen, die über die Kosten der Modellinferenz hinausgehen.
Erdung und Werkzeugnutzung
Google berechnet $35 pro 1.000 Suchanfragen (Websuche) auf Gemini nach Verbrauch des kostenlosen Tageskontingents. Die Websuche mit Claude kostet laut offizieller Preisdokumentation von Anthropic für Vertex AI $10 pro 1.000 Suchanfragen.
Diese Funktionen verbessern die Genauigkeit von Echtzeitinformationen erheblich. Bei großzügiger Nutzung erhöhen sie jedoch auch die üblichen Kosten um 10-15%.
Ratenbegrenzungen und Drosselung
Kostenlose und eingeschränkte Nutzungsstufen unterliegen strengen Ratenbegrenzungen. Das Stufensystem von OpenAI sieht vor, dass Nutzer der Stufe 1 500 Anfragen pro Minute mit 500.000 Token pro Minute auf GPT-5.2 erhalten. Nutzer der Stufe 5 haben Zugriff auf 40 Millionen Token pro Minute.
Das Erreichen von Ratenlimits führt zu fehlgeschlagenen Anfragen und Wiederholungsversuchen, was sowohl Token als auch Entwicklerzeit verschwendet. Ein Upgrade auf einen höheren Tarif erfordert zwar einen Mindestbetrag pro Monat, beseitigt aber Engpässe.

Entwickeln Sie die richtige LLM-Architektur mit überlegener KI
Die Wahl zwischen verschiedenen LLM-APIs hängt nicht nur von der Token-Preisgestaltung ab. Leistungsanforderungen, promptes Design, Systemarchitektur und Skalierungsstrategie beeinflussen die Gesamtkosten einer Anwendung.
AI Superior unterstützt Unternehmen bei der Entwicklung produktionsreifer LLM-Systeme und bei der Auswahl der am besten geeigneten Architektur für ihren Anwendungsfall.
Ihr Team kann Ihnen helfen bei:
- die richtigen LLM-Anbieter auswählen
- Entwurf skalierbarer LLM-Architekturen
- Optimierung von Eingabeaufforderungen und Token-Nutzung
- Integration von LLMs in bestehende Systeme
Wenn Sie ein LLM-basiertes Produkt planen, AI Superior kann bei der Gestaltung der technischen Architektur und der Implementierung der Lösung helfen.
Kostenanalyse in der Praxis: Beispiel Chatbot
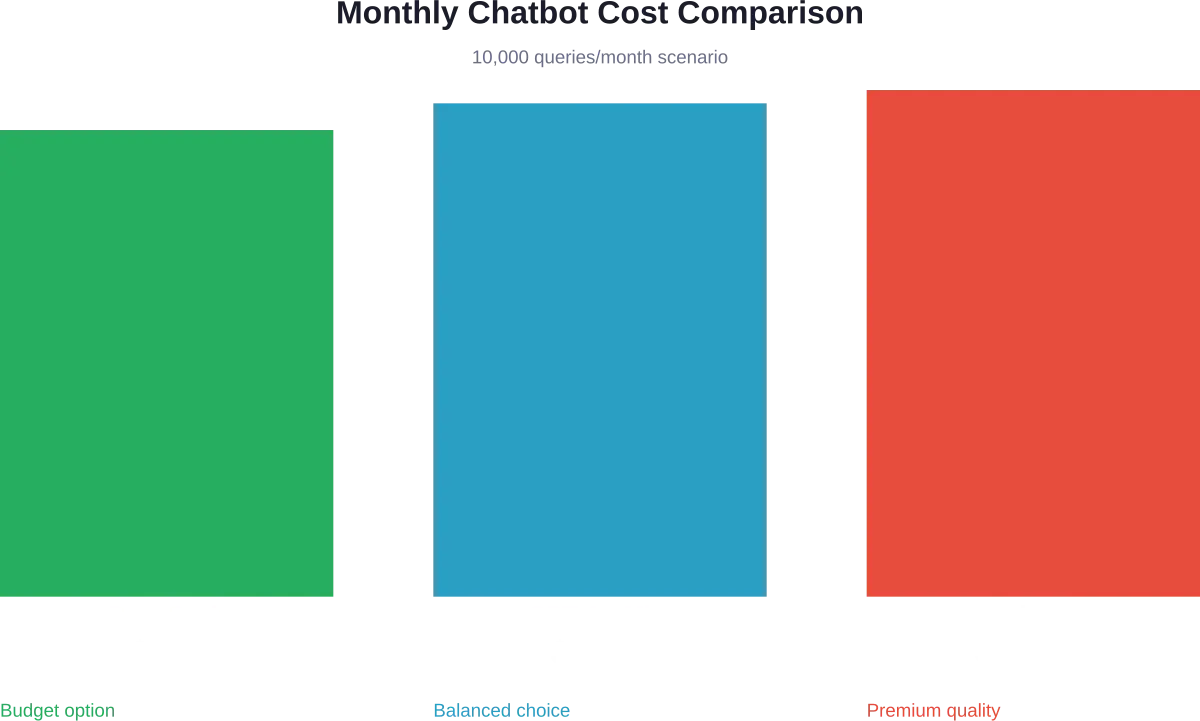
Lassen Sie uns die tatsächlichen Kosten für einen Kundenservice-Chatbot modellieren, der monatlich 10.000 Anfragen bearbeitet.
Annahmen basierend auf typischen Callcenter-Mustern aus der AWS-Dokumentation:
- 5 Millionen Tokens für die Wissensdatenbank (einmalig + Aktualisierungen)
- 50.000 Einbettungen für die semantische Suche
- Durchschnittlich 100 Tokens pro Benutzeranfrage
- Durchschnittlich 100 Tokens pro Antwort
- Insgesamt: 2 Millionen Token monatlich (1 Million Input, 1 Million Output)
OpenAI GPT-4.1 Mini
- Eingabe: 1 Mio. Token × $0,20 = $200
- Ausgabe: 1 Mio. Token × $0,80 = $800
- Einbettungen: 50K × $0,00002 = $1
- Monatliche Summe: ~$1.001
Claude Opus 4.6 mit Caching
- Wissensdatenbank im Cache: 90% Cache-Treffer
- Zwischengespeicherte Eingabe: 900K × $0,50 = $450
- Frischer Eingang: 100K × $5.00 = $500
- Ausgabe: 1M × $25,00 = $25.000
- Monatliche Gesamtsumme: ~$25.950
Moment mal, das ist 26-mal teurer! Aber der Punkt ist: Claude Opus liefert bei komplexen Schlussfolgerungsaufgaben eine deutlich höhere Qualität. Der höhere Preis ist für unternehmenskritische Anwendungen gerechtfertigt, bei denen Genauigkeit wichtiger ist als die Kosten.
DeepSeek V3.2 Budget-Option
- Eingabe: 1M × $0,28 = $280
- Ausgabe: 1M × $0,40 = $400
- Einbettungen: $1
- Monatliche Summe: ~$681
DeepSeek bietet die günstigste Option, weist jedoch eine weniger bewährte Zuverlässigkeit für Unternehmensanwendungen auf. Leistungsvergleiche zeigen, dass es in Standardtests innerhalb von 20% mit führenden kommerziellen Modellen schneidet und sich somit für kostensensible Anwendungen eignet.
Kostenoptimierungsstrategien, die tatsächlich funktionieren
Teams, die die Kosten für LLM-Projekte effektiv managen, folgen mehreren bewährten Mustern.
Intelligente, prompte Weiterleitung
Nicht jede Anfrage erfordert Ihr leistungsstärkstes Modell. Leiten Sie einfache Fragen an kleinere Modelle weiter und komplexe Schlussfolgerungen an die wichtigsten Optionen.
Laut AWS-Dokumentation kann intelligentes Prompt-Routing die Kosten um bis zu 301 TP3T senken, ohne die Genauigkeit zu beeinträchtigen. Implementieren Sie eine Klassifizierungslogik, die Anfragen anhand ihrer Komplexität den passenden Modellen zuordnet.
Amazon Bedrock unterstützt dies durch seine intelligente Prompt-Routing-Funktion, die automatisch die optimalen Modelle pro Anfrage auswählt.
Aggressives Prompt-Caching
Strukturieren Sie Ihre Eingabeaufforderungen so, dass der Cache optimal genutzt wird. Platzieren Sie stabile Kontextinformationen (Systemanweisungen, Auszüge aus der Wissensdatenbank) am Anfang, wo sie zwischengespeichert werden können.
Das Caching-System von Anthropic bietet eine Kostenreduzierung von bis zu 90% für zwischengespeicherte Token im Vergleich zur Standardpreisgestaltung. Für Anwendungen, die auf einen konsistenten Kontext zugreifen, kann diese Optimierung die Ausgaben halbieren.
Stapelverarbeitung für nicht dringende Aufgaben
Sowohl OpenAI als auch Amazon Bedrock bieten Rabatte gemäß § 50% für Batch-API-Anfragen. Alle Anfragen, die innerhalb von 24 Stunden bearbeitet werden können, sollten über Batch-Endpunkte abgewickelt werden.
Inhaltsgenerierung, Datenanalyse und die Erstellung von Trainingsdaten lassen sich problemlos im Batch-Verfahren verarbeiten. Unternehmen können durch Batch-Verarbeitung erhebliche Kosteneinsparungen erzielen, da diese in der Regel mit 50%-Rabatten im Vergleich zur Einzelabrechnung verbunden ist.
Ausgabetokenverwaltung
Ausgabetoken kosten das 4- bis 6-Fache der Eingabetoken. Die Antwortlänge sollte über den Parameter „max_tokens“ streng kontrolliert und die Entwicklungsabteilung umgehend informiert werden.
Die Anforderung von 500-Token-Antworten, obwohl 200 Token ausreichen, führt zu unnötigen Kosten bei jedem Aufruf. Setzen Sie konservative Ausgabelimits und erweitern Sie diese nur für Anfragen, die tatsächlich längere Antworten erfordern.
Modellauswahl nach Aufgabentyp
Modellfunktionen den Anforderungen anpassen:
- Einfache Klassifizierung/Extraktion: Verwenden Sie Nano-/Mini-Modelle (GPT-5 Nano mit $0.025 Eingang, $0.20 Ausgang)
- Allgemeine Chatbot-Antworten: Modelle der mittleren Preisklasse (Varianten GPT-4.1 Mini, Claude Sonnet)
- Komplexes Denken/Kodieren: Flaggschiffmodelle (GPT-5.2, Claude Opus)
- Massenverarbeitung: Verwenden Sie stets Batch-APIs, um Einsparungen von 50% zu erzielen.
Eine Kosten-Nutzen-Analyse legt nahe, dass Unternehmen je nach Nutzungsintensität und Leistungsanforderungen, die wiederum von Nutzungsvolumen und Infrastrukturkosten abhängen, einen Break-Even-Punkt bei der Bereitstellung von On-Premise-LLM erreichen können. Für die meisten Teams bietet die Optimierung der Cloud-API-Nutzung jedoch einen besseren ROI als das Selbsthosting.
Überwachungs- und Kostenmanagement-Tools
Was man nicht misst, kann man nicht optimieren. Verschiedene Ansätze helfen dabei, die Ausgaben für ein LLM-Studium zu verfolgen:
Anbietereigene Dashboards
OpenAI, Anthropic und Google bieten alle Nutzungs-Dashboards an, die den Token-Verbrauch nach Modell, Projekt und Zeitraum anzeigen. Diese funktionieren zwar, ermöglichen aber keinen anbieterübergreifenden Vergleich.
Die Usage & Cost API von Anthropic ermöglicht den programmatischen Zugriff auf Verbrauchsdaten mit einer Granularität von einer Minute bis zu einem Tag. Alle Kosten werden in US-Dollar als Dezimalzahlen in Cent angegeben.
Überwachungsplattformen von Drittanbietern
Helicone und ähnliche Dienste aggregieren die Nutzung über mehrere LLM-Anbieter hinweg. Sie verfolgen die Kosten pro Anfrage, identifizieren teure Abfragen und warnen bei Überschreitung von Budgetgrenzen.
Diese Plattformen berechnen üblicherweise 1-21 TP3T LLM-Ausgaben oder monatliche Pauschalgebühren. Sie lohnen sich für Teams, die mehrere Anbieter nutzen oder eine detaillierte Zuordnung nach Benutzer/Projekt benötigen.
Budgetwarnungen einrichten
Die meisten Anbieter unterstützen Ausgabenlimits und Warnmeldungen. Konfigurieren Sie diese vor der Produktionsbereitstellung:
- Legen Sie feste Obergrenzen für Entwicklungs-/Testumgebungen fest
- Konfigurieren Sie Warnmeldungen bei 50%, 75% und 90% Budgetschwellenwerten.
- Implementieren Sie Schutzmechanismen, die Anfragen pausieren, wenn Grenzwerte erreicht werden.
AWS Cost Explorer ermöglicht die Budgetverfolgung für die Nutzung von Bedrock. Google Cloud bietet eine ähnliche Funktionalität für die Ausgaben von Vertex AI.
Neue Trends bei der Preisgestaltung für LLM-Studiengänge
Das Wettbewerbsumfeld entwickelt sich weiterhin rasant.
Abwärtswettlauf bei Rohstoffaufgaben
Die Preise für einfache Textgenerierung und -klassifizierung sind seit 2023 um 80-90% gesunken. Modelle wie GPT-5 Nano ($0,025 Input) und DeepSeek ($0,28 Input) treiben die Preise für einfache Aufgaben in Richtung Null.
Diese Kommerzialisierung bedeutet, dass die Differenzierung eher auf spezialisierten Fähigkeiten – logischem Denken, multimodalem Verständnis, Werkzeugnutzung – als auf der grundlegenden Textgenerierung beruht.
Premiumpreise für Reasoning-Modelle
Für fortgeschrittene logische Schlussfolgerungen gilt der gegenteilige Trend. GPT-5.2 Pro mit $21-Eingang / $168-Ausgang erzielt deutlich höhere Preise als Standardmodelle.
Diese “langsamen Denkmodelle” benötigen mehr Rechenzeit für logisches Denken, bevor sie reagieren, was höhere Preise für komplexe Probleme rechtfertigt, bei denen Genauigkeit wichtiger ist als Geschwindigkeit.
Kontextfensterökonomie
Für Anfragen mit langem Kontext berechnen die Anbieter höhere Gebühren. Googles Token-Grenze von über 200.000 führt zu höheren Preisen für alle Token in dieser Anfrage.
Mit der Erweiterung der Kontextfenster (OpenAIs GPT-5.2 unterstützt 400.000 Token) dürfte eine gestaffelte Preisgestaltung basierend auf der Kontextnutzung zum Standard werden. Effizientes Kontextmanagement durch Zusammenfassung und Caching wird an Bedeutung gewinnen.
Preisgestaltung für Spezialmodelle
Domänenspezifische Modelle (Medizin, Recht, Finanzen) erzielen aufgrund spezialisierter Schulungen Premiumpreise. Es ist mit einer weiteren Expansion von Nischenmodellen zu rechnen, deren Preise das Zwei- bis Dreifache vergleichbarer allgemeiner Modelle betragen werden.
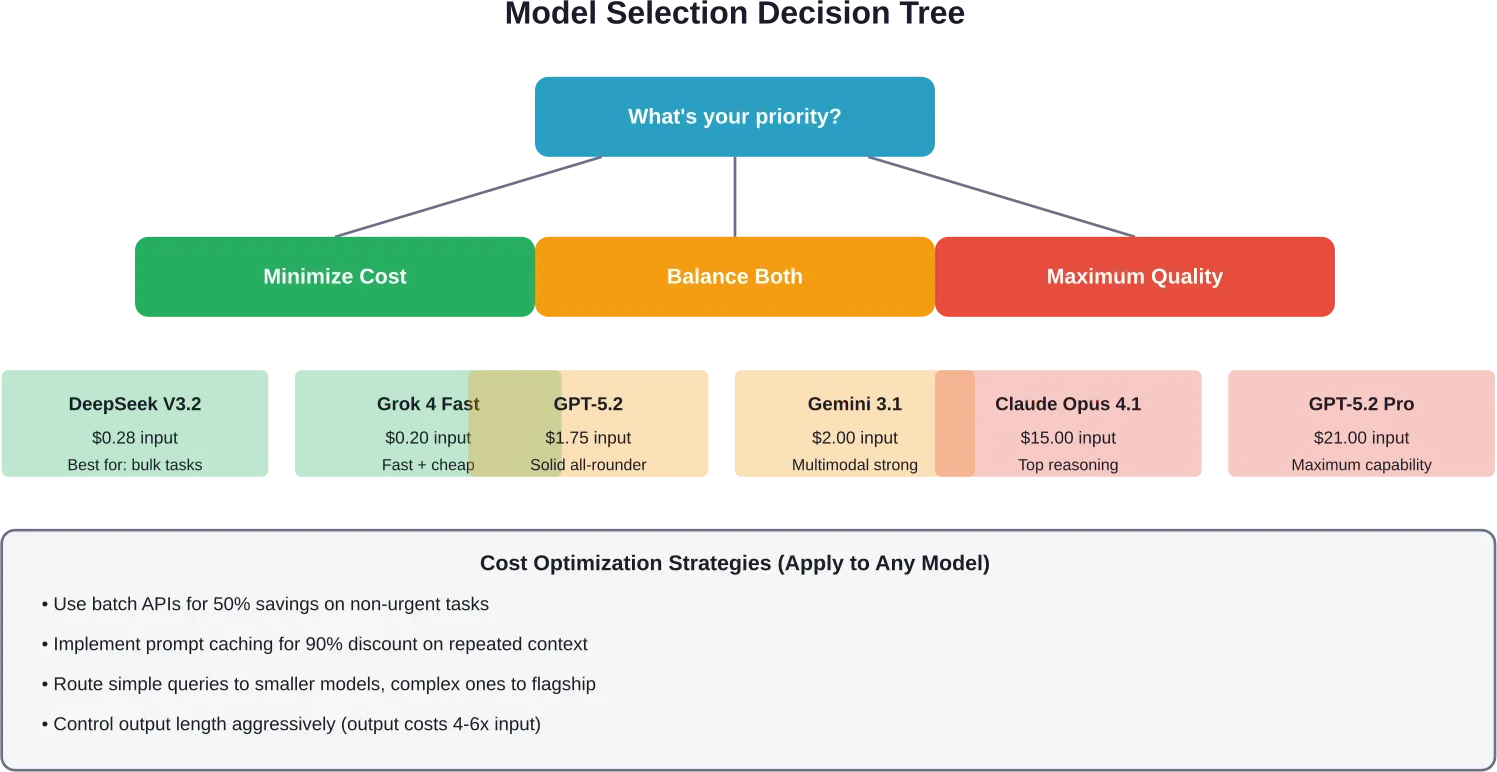
Welchen Anbieter sollten Sie wählen?
Es gibt keine allgemeingültige Antwort, aber hier ist ein Entscheidungsrahmen basierend auf Prioritäten:
Für knappe Budgets
DeepSeek V3.2 bietet die niedrigsten Kosten pro Token bei gleichzeitig angemessener Qualität. Grok 4 Fast ist eine weitere kostengünstige Option mit besserer Supportinfrastruktur.
Kombinieren Sie Budgetmodelle für einfache Aufgaben mit dem strategischen Einsatz von Premiummodellen für kritische Anfragen. Leiten Sie 80% Traffic an günstige Modelle und 20% an teure Modelle weiter.
Für maximale Qualität
OpenAIs GPT-5.2 Pro und Claude Opus 4.1 stellen derzeit die Qualitätsobergrenze dar. Rechnen Sie mit einem 10- bis 30-fach höheren Preis als bei Alternativen der Mittelklasse.
Nur dann gerechtfertigt, wenn die Genauigkeit einen direkten Einfluss auf den Umsatz oder das Risiko hat (Rechtsanalysen, medizinische Anwendungen, kritische Infrastrukturen).
Für eine ausgewogene Leistung
GPT-5.2 ($1.75-Eingang) und Claude Opus 4.6 ($5.00-Eingang) bieten für die meisten Produktionsanwendungen die optimale Lösung: Hohe Leistung ohne extreme Kosten.
Googles Gemini 3.1 Pro mit $2.00-Eingang bietet wettbewerbsfähige Preise bei gleichzeitig hervorragenden multimodalen Fähigkeiten.
Für Google Cloud-Nutzer
Vertex AI bietet einheitlichen Zugriff auf Gemini sowie auf Drittanbietermodelle. Das integrierte Ökosystem vereinfacht die Bereitstellung, wenn Sie bereits eine GCP-Infrastruktur nutzen.
Nutzen Sie die täglich 10.000 kostenlosen, praxisorientierten Suchvorschläge von Gemini 2.5 Pro für suchbasierte Anwendungen.
Für AWS-Umgebungen
Bedrock bietet die größte Modellauswahl mit einheitlicher Abrechnung. Eine gute Wahl für Unternehmen, die AWS als Standard nutzen und über eine einzige Schnittstelle auf Anthropic, Meta und andere Anbieter zugreifen möchten.
Häufig gestellte Fragen
Welches ist das günstigste LLM-API im Jahr 2026?
DeepSeek V3.2 bietet derzeit die niedrigsten Token-Preise mit ca. $0,28 pro Million Input-Token und $0,40 pro Ausgabe. Grok 4 Fast von xAI kostet $0,20 pro Input und $0,50 pro Ausgabe. Für OpenAI-Nutzer kostet GPT-5 Nano $0,025 pro Million Input und $0,20 pro Ausgabe.
Wie viel kostet GPT-5 im Vergleich zu GPT-4?
Laut OpenAIs offizieller Preisgestaltung kostet GPT-5.2 $1,75 Input und $14,00 Output pro Million Token. Der ältere GPT-4 hingegen benötigt $30,00 Input und $60,00 Output. GPT-5.2 ist deutlich günstiger (94% Einsparung beim Input, 77% Einsparung beim Output) und bietet gleichzeitig eine bessere Performance.
Sind Batch-APIs wirklich 50% günstiger?
Ja. Sowohl OpenAI als auch Amazon Bedrock bieten Rabatte von 50% für die Stapelverarbeitung mit einer Bearbeitungszeit von 24 Stunden. Die Stapelverarbeitungspreise von OpenAI zeigen, dass GPT-5.2 im Vergleich zum Standard ($1,75 / $14,00) auf $0,875 Input / $7,00 Output sinkt. Für alle nicht dringenden Workloads sollten Stapelverarbeitungs-Endpunkte verwendet werden.
Was sind die Kosten für Prompt-Caching?
OpenAI berechnet 10% Standard-Eingabekosten für zwischengespeicherte Token. Bei GPT-5.2 betragen die Kosten für zwischengespeicherte Eingaben $0,175 gegenüber $1,75 regulär. Anthropic bietet Rabatte von 90% auf Cache-Treffer, berechnet jedoch Gebühren für Cache-Schreibvorgänge. Bei Claude Opus 4.6 kosten Cache-Schreibvorgänge je nach Dauer $6,25–$10,00 pro Million Token, während Cache-Treffer $0,50 gegenüber $5,00 Basis-Eingabekosten betragen.
Wie berechne ich den Tokenverbrauch für meine Anwendung?
Verwenden Sie anbieterspezifische Tokenisierungstools. OpenAI bietet die tiktoken-Bibliothek an. Ein Token entspricht in der Regel etwa vier Zeichen oder 0,75 Wörtern. Ein Dokument mit 1.000 Wörtern enthält ungefähr 1.333 Tokens. Testen Sie Ihre tatsächlichen Eingabeaufforderungen und Antworten mit Tokenisierungstools, um genaue Token-Zählungen zu erhalten, bevor Sie die Kosten schätzen.
Ist Claude teurer als GPT?
Das hängt von den verglichenen Modellen ab. Claude Opus 4.6 ($5.00 Eingabe) ist teurer als GPT-5.2 ($1.75 Eingabe), aber günstiger als GPT-5.2 Pro ($21.00 Eingabe). Die Ausgabekosten weisen größere Unterschiede auf – Claude Opus berechnet $25.00 Ausgabekosten, GPT-5.2 hingegen nur $14.00. Die hohen Caching-Rabatte von Claude (90% Rabatt) können die Kosten für Anwendungen mit hoher Kontextwiederverwendung jedoch senken.
Welches ist das kostengünstigste Modell für Chatbots?
Für allgemeine Kundenservice-Chatbots bieten GPT-4.1 Mini ($0.20 Eingabe / $0.80 Ausgabe) oder GPT-5 Mini ($0.25 Eingabe / $2.00 Ausgabe) das beste Verhältnis von Qualität und Kosten. Für einfachere FAQ-Bots eignet sich GPT-5 Nano ($0.025 Eingabe / $0.20 Ausgabe) gut. Implementieren Sie intelligentes Routing, um Nano-/Mini-Modelle für einfache Anfragen zu verwenden und erst bei komplexeren Anfragen auf die Flaggschiffmodelle aufzurüsten.
Ihre Entscheidung für die LLM-API
Der Preis sollte nicht Ihr einziges Entscheidungskriterium sein. Modellqualität, Latenz, Kontextfenstergröße und das Integrationsökosystem spielen ebenfalls eine Rolle.
Das Verständnis von Kostenstrukturen hilft Ihnen jedoch, die häufige Falle zu vermeiden, für Funktionen zu viel auszugeben, die Sie nicht benötigen. Die meisten Anwendungen erzielen mit Mittelklassemodellen einen Mehrwert von 90% zum Preis von 20% der Topmodelle.
Beginnen Sie mit diesen Schritten:
Erstellen Sie zunächst ein Profil Ihrer tatsächlichen Nutzungsmuster. Erfassen Sie die Anzahl der Tokens, die Länge der Antworten und die Komplexität der Abfragen für Ihren spezifischen Anwendungsfall. Reale Daten sind aussagekräftiger als Annahmen.
Zweitens sollten Sie mehrere Anbieter anhand Ihrer tatsächlichen Arbeitslast testen. Leistungsbenchmarks lassen sich nicht immer auf Ihre Domäne übertragen. Führen Sie A/B-Tests durch, um sowohl Qualität als auch Kosten zu messen.
Drittens: Implementieren Sie Kostenkontrollen vor der Skalierung. Richten Sie Budgetwarnungen ein, aktivieren Sie Caching und leiten Sie Anfragen intelligent weiter. Diese Optimierungen führen zu größeren Einsparungen als ein Anbieterwechsel.
Die Preislandschaft im Bereich der LLM-Systeme wird sich ständig verändern. Monatlich kommen neue Modelle auf den Markt, die Preise schwanken und die Leistungsfähigkeit verbessert sich kontinuierlich. Die grundlegenden Prinzipien bleiben jedoch unverändert.
Verstehen Sie die tokenbasierte Preisgestaltung. Überwachen Sie die tatsächliche Nutzung. Passen Sie die Modellfunktionen an die Aufgabenanforderungen an. Optimieren Sie die Cache-Wiederverwendung. Nutzen Sie nach Möglichkeit die Stapelverarbeitung.
Unternehmen, die Kostenoptimierungsmaßnahmen umsetzen, können durch eine optimierte Modellauswahl und Nutzungsmuster potenziell erhebliche Einsparungen erzielen – im Vergleich zu Unternehmen, die einfach einen Anbieter auswählen und APIs zum vollen Listenpreis nutzen. Das ist der entscheidende Unterschied zwischen einer nachhaltigen KI-Einführung und kostenintensiven Experimenten, die schnell wieder abgebrochen werden.
Bereit, Ihre LLM-Ausgaben zu optimieren? Beginnen Sie mit einer Überprüfung Ihres aktuellen Verbrauchs und der Implementierung eines intelligenten Prompt-Routings. Die Einsparungen summieren sich schnell.