Kurzzusammenfassung: Die Feinabstimmung eines LLM kostet typischerweise zwischen unter 1.400.500 und 1.400.000 INR, abhängig von Modellgröße, Methode und Infrastruktur. Kleinere Modelle (2–8 Milliarden Parameter) mit parametereffizienten Methoden wie LoRA lassen sich auf Cloud-GPUs für unter 1.400.000 INR feinabstimmen, während die vollständige Feinabstimmung größerer Modelle auf Premium-Infrastruktur 1.400.000 INR übersteigen kann. Das Verständnis der Kostentreiber – Rechenressourcen, Trainingsdatenvolumen, Modellarchitektur und gewählte Methode – hilft Teams bei der effektiven Budgetplanung.
Die Kosten für die Feinabstimmung großer Sprachmodelle überraschen die meisten Teams. Das Training von Grund auf kann Millionen kosten – Googles Gemini Ultra erreichte Berichten zufolge 191 Millionen TP4T, während GPT-4 bei etwa 78 Millionen TP4T lag –, doch die Feinabstimmung bestehender Modelle ist eine ganz andere Geschichte.
Das Problem ist jedoch: Die Kosten für die Feinabstimmung variieren enorm. Ein Forschungsteam der Stanford University optimierte Qwen3-8B-Base für unter 104.000 US-Dollar mithilfe von LoRa-Adaptern über den Managed Service von Together AI. Vollständige Feinabstimmungen auf Unternehmensinfrastrukturen kosten hingegen üblicherweise zwischen 3.000 und 10.000 US-Dollar.
Wichtiger als der Preis auf dem Etikett ist es zu verstehen, wohin Ihr Geld fließt.
Was treibt die Kosten für die Feinabstimmung an?
Vier Hauptfaktoren bestimmen die tatsächlichen Kosten der Feinabstimmung.
Recheninfrastruktur
Die Wahl der GPU verursacht die größten Kostenunterschiede. Cloud-Anbieter rechnen stundenweise ab, und die Preise variieren je nach Hardwareklasse erheblich.
Eine NVIDIA A10G – nach heutigen Maßstäben ein Mittelklasse-Modell – kostet auf gängigen Cloud-Plattformen etwa 1,50 bis 2,50 TP4T pro Stunde. Die zuvor erwähnte Feinabstimmung, die weniger als 10 TP4T kostete, lief vier Stunden lang auf einer einzelnen A10G.
Die Skalierung wird jedoch schnell teuer. Premium-GPUs wie A100 oder H100 kosten auf AWS oder Google Cloud 104.000 bis 104.000 TP pro Stunde. Multi-GPU-Setups für größere Modelle vervielfachen diese Kosten linear.
Selbsthosting erfordert eine andere Kostenkalkulation. Eine RTX 4090 kostet einmalig etwa 1.600 £, dafür fallen keine laufenden Stundengebühren an. Laut Diskussionen in der LinkedIn-Community amortisiert sich eine einzelne GPU innerhalb weniger Wochen im Vergleich zu monatlichen Abonnements für Cloud-GPU-Knoten im Wert von 2.500 £ – vorausgesetzt, die Auslastung bleibt konstant hoch.
Modellgröße und Architektur
Die Anzahl der Parameter hat direkten Einfluss auf den Speicherbedarf und die Trainingsdauer.
| Modellgröße | VRAM (Vollständige Feinabstimmung) | VRAM (4-Bit LoRA) | Typischer Kostenbereich |
|---|---|---|---|
| 2-3B-Parameter | 6-8 GB | 2-3 GB | $300-$700 |
| 7-8B-Parameter | 14-16 GB | 6-8 GB | $1,000-$3,000 (LoRA) Bis zu $12.000 (voll) |
| 12-13B-Parameter | 24-28 GB | 10-12 GB | $5,000-$15,000 |
Phi-2 (2,7 Milliarden Parameter) mit LoRA kostet typischerweise $300 bis $700. Mistral 7B-Modelle liegen mit LoRA zwischen $1.000 und $3.000, aber eine vollständige Feinabstimmung kann die Kosten auf $12.000 treiben.
Der Speicherbedarf erklärt dies. Vollständiges Fine-Tuning speichert Gradienten für jeden Parameter. Ein 7-Bit-Modell benötigt allein zum Laden der Gewichte mit 16-Bit-Genauigkeit etwa 28 GB VRAM – noch bevor Gradienten, Optimiererzustände und Aktivierungsspeicher während des Trainings berücksichtigt werden.
Auswahl der Trainingsmethode
Die gewählte Methode zur Feinabstimmung verändert sowohl den Kosten- als auch den Ressourcenbedarf erheblich.
- Vollständige Feinabstimmung Jeder Modellparameter wird aktualisiert. Dieser Ansatz bietet maximale Kontrolle und Anpassungsmöglichkeiten, benötigt aber erheblichen VRAM. Der Speicherverbrauch skaliert linear mit der Modellgröße, wodurch eine vollständige Feinabstimmung von Modellen mit mehr als 13 Milliarden Parametern ohne Multi-GPU-Systeme praktisch nicht möglich ist.
- Parametereffiziente Feinabstimmung (PEFT) Techniken aktualisieren nur eine kleine Teilmenge der Gewichte. LoRA (Low-Rank Adaptation) fügt trainierbare Adaptermodule zwischen Transformerschichten ein, während das Basismodell eingefroren wird. Laut arXiv-Forschung zu ressourceneffizienten Methoden reduziert LoRA den Trainingsspeicherbedarf erheblich und erhält gleichzeitig eine vergleichbare Genauigkeit wie vollständiges Fine-Tuning.
Welche Auswirkungen hat das auf die Praxis? Forscher der Stanford University erzielten beim Feinabstimmen von Qwen3-8B mit LoRA (Rang=32) eine Genauigkeit von 0,78 gegenüber 0,41 beim Basismodell – und das bei Rechenkosten von unter $5. Dieser Leistungszuwachs bei minimalem Aufwand verdeutlicht, warum PEFT-Verfahren in praktischen Anwendungen dominieren.
- Quantisierung Die Kosten werden weiter gesenkt. Laut der Dokumentation von Hugging Face reduzierte das Training mit 4-Bit-Quantisierung mittels bitsandbytes den maximalen Speicherbedarf für das LoRA-Feintuning von FLUX.1-dev von etwa 60 GB auf rund 37 GB. Der Qualitätsverlust blieb dabei vernachlässigbar.

Datensatzgröße und Trainingsdauer
Mehr Trainingsdaten bedeuten nicht immer bessere Ergebnisse, aber definitiv höhere Kosten.
Die Anzahl der Token bestimmt die Rechenzeit. Die Fine-Tuning-API von OpenAI, die auf Basis der Trainingstoken und nicht der tatsächlichen Rechenzeit abrechnet, verdeutlicht diesen Zusammenhang. In Diskussionen der Community wird darauf hingewiesen, dass die Kostenverfolgung die Überwachung der trainierten Token erfordert, da die Abrechnung nicht mehr auf den ursprünglichen Trainingszeitmetriken basiert.
Die Datenqualität ist wichtiger als die Datenmenge. Teams erzielen oft bessere Ergebnisse mit 500 sorgfältig ausgewählten Beispielen als mit 5.000 fehlerhaften Daten. Schlechte Datenqualität verlängert die Trainingsdauer, da das Modell Schwierigkeiten hat, konsistente Muster zu erkennen, was die Kosten erhöht, ohne die Ergebnisse zu verbessern.

Implementieren Sie maßgeschneiderte LLM-Lösungen mit überlegener KI
Die Feinabstimmung eines großen Sprachmodells erfordert den richtigen Datensatz, die passende Trainingsinfrastruktur und einen geeigneten Evaluierungsprozess. In vielen Fällen können auch benutzerdefinierte Modellanpassungen oder abfragebasierte Systeme in Betracht gezogen werden.
AI Superior entwickelt maßgeschneiderte LLM-Lösungen für Unternehmen, die domänenspezifische KI-Fähigkeiten benötigen.
Zu ihren Fachgebieten gehören:
- Datensatzvorbereitung und -annotation
- Modellfeinabstimmung und -bewertung
- RAG- und Hybridarchitekturen
- Produktionseinsatz von LLM-Systemen
Wenn Sie eine maßgeschneiderte LLM-Lösung benötigen, die auf Ihre Daten und Arbeitsabläufe zugeschnitten ist, AI Superior können den Entwicklungsprozess unterstützen.
Versteckte Kosten, die sich summieren
Die Rechnung Ihres Cloud-Anbieters erzählt nicht die ganze Geschichte.
Datenaufbereitungsarbeit
Das Bereinigen, Formatieren und Validieren von Trainingsdaten beansprucht einen erheblichen Zeitaufwand. Inkonsistenzen im Datensatz schränken die Modellleistung direkt ein – Untersuchungen zur Feinabstimmung für die automatisierte Programmreparatur (arXiv:2507.19909) zeigen, dass die Übereinstimmungsrate der menschlichen Annotationen die erreichbare Genauigkeit begrenzt.
Wenn die Annotatoren nur in 70% Fällen übereinstimmen, kann das Modell unabhängig vom Trainingsaufwand nicht zuverlässig eine Genauigkeit von 70% erreichen.
Experimentierkosten
Feinabstimmung gelingt selten beim ersten Versuch. Die Optimierung der Hyperparameter – Lernrate, Batchgröße, Anzahl der Epochen – erfordert mehrere Trainingsläufe.
Planen Sie mindestens 3-5 Iterationen ein. Jeder Testlauf kostet so viel wie ein Produktionstraining.
Validierung und Bewertung
Bei Reinforcement-Fine-Tuning-Verfahren entstehen durch die Validierung während des Trainings zusätzliche Kosten. Die Abrechnungsrichtlinien von OpenAI zu Reinforcement-Fine-Tuning weisen ausdrücklich auf die Validierungshäufigkeit als Kostenfaktor hin – häufigere Validierungen bedeuten höhere Kosten.
Die Auswahl des Grader-Modells ist ebenfalls wichtig. Die Verwendung eines größeren Modells zur Bewertung von Trainings-Checkpoints verursacht höhere Kosten pro Validierungszyklus als die Verwendung kleinerer, schnellerer Grader.
Speicherung und Bereitstellung
Modell-Checkpoints belegen Speicherplatz. Ein Modell mit 7 Milliarden Parametern und 16-Bit-Genauigkeit benötigt pro Checkpoint etwa 14 GB Speicherplatz. Das Speichern von Checkpoints in jeder Epoche über mehrere Experimente hinweg summiert sich.
Die Bereitstellungsinfrastruktur verursacht laufende Kosten. Selbsthosting erfordert die Wartung von GPU-Knoten rund um die Uhr. API-basierte Bereitstellung verlagert die Kosten auf die Abrechnung pro Token für Inferenz.
Kostenanalyse Cloud vs. Selbsthosting
Die Entscheidung zwischen Eigenentwicklung und Zukauf hängt von den Nutzungsmustern und dem Umfang ab.
Preise von Cloud-Anbietern
Die großen Cloud-Plattformen bieten Managed Services für Feinabstimmung und GPU-Rechenleistung an. Managed Services abstrahieren die Infrastrukturkomplexität, verursachen aber zusätzliche Kosten. Laut der Dokumentation der Forschungsrechenressourcen der Stanford University lieferte der Managed Training Service von Together AI das Beispiel für Feinabstimmung unter $5 – deutlich günstiger als eine vergleichbare, selbstverwaltete Infrastruktur.
Die Anmietung von reinen GPUs bietet mehr Kontrolle. AWS g5.xlarge-Instanzen (NVIDIA A10G) sind ab ca. 1,50 TP4T pro Stunde erhältlich. Multi-GPU-Instanzen für größere Modelle skalieren proportional: g5.12xlarge mit 4 A10G-GPUs kostet etwa 6 TP4T pro Stunde.
Ökonomie des Selbsthostings
Consumer-GPUs ermöglichen lokales Feintuning auch für kleinere Modelle. Eine RTX 4060 Ti mit 16 GB bewältigt 7B-Modelle mit LoRa und Quantisierung. Die Anschaffungskosten liegen bei 1.200 bis 1.600 £, dafür fallen keine laufenden Kosten an.
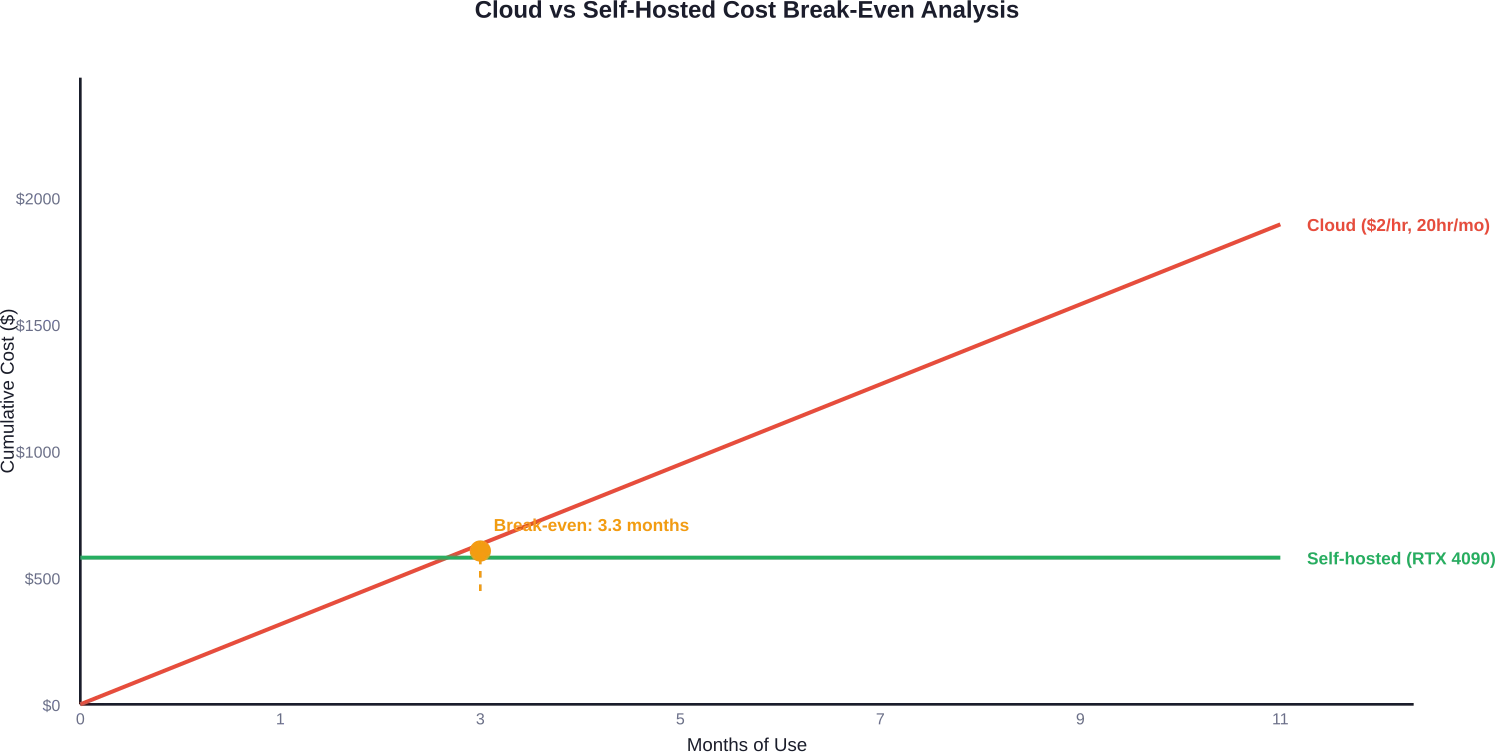
Die Berechnung spricht für Self-Hosting, wenn die Nutzung 15–20 Stunden pro Monat übersteigt. Bei Cloud-Tarifen von $2/Stunde kostet eine monatliche Nutzung von 20 Stunden $480 – das bedeutet, dass sich eine GPU im Wert von $1600 bei regelmäßiger Nutzung in weniger als vier Monaten amortisiert.
Die Cloud bietet jedoch Flexibilität für sporadische Arbeitslasten. Die monatliche Ausführung eines Feinabstimmungsvorgangs über vier Stunden ($8-$10 in der Cloud) rechtfertigt nicht den Besitz einer GPU.
Wann sich Feinabstimmung finanziell lohnt
Nicht jeder Anwendungsfall rechtfertigt eine Investition in die Feinabstimmung.
Berechnen Sie Ihre Ausgangsbasis
Vergleichen Sie die Kosten für die Feinabstimmung mit den API-Alternativen. Benötigt eine Aufgabe monatlich 10 Millionen Inferenz-Token, entsprechen die API-Kosten bei 0,001 TP4T pro 1.000 Token 10.000 TP4T jährlich. Eine einmalige Investition von 2.000 TP4T in die Feinabstimmung, die kostengünstigere Inferenz mit kleineren Modellen ermöglicht, amortisiert sich innerhalb weniger Monate.
Wenn jedoch durch zügiges Engineering mit einem Basismodell akzeptable Ergebnisse erzielt werden, ist die Feinabstimmung eine Ressourcenverschwendung.
Kontextfenster ändern die Berechnung
Moderne Modelle unterstützen Kontextfenster mit 200.000 bis 1 Million Token. Durch das Einfügen von Domänenwissen in Eingabeaufforderungen entfällt für viele Anwendungen der Bedarf an Feinabstimmung. Da alle vier bis sechs Monate neue Basismodelle veröffentlicht werden, entstehen durch die Wartung feinabgestimmter Versionen wiederkehrende Kosten.
In Diskussionen innerhalb der Community wird dieser Wandel deutlich: Teams bevorzugen zunehmend große Kontextfenster mit gut durchdachten Eingabeaufforderungen gegenüber einer individuellen Feinabstimmung, da der Wechsel zu verbesserten Basismodellen kein erneutes Training erfordert.
Feinabstimmung führt zu Siegen für
In bestimmten Szenarien ist eine Feinabstimmung weiterhin sinnvoll:
- Eine einheitliche Ausgabeformatierung, die durch Eingabeaufforderungen nicht zuverlässig erzwungen werden kann.
- Fachspezifisches Domänenwissen, das in den Trainingsdaten des Basismodells nicht vorhanden ist
- Latenzkritische Anwendungen, bei denen kleinere, feinabgestimmte Modelle größere Basismodelle übertreffen.
- Inferenz mit hohem Datenvolumen, bei der die API-Kosten pro Token die einmaligen Schulungsinvestitionen übersteigen.
- Datenschutzbestimmungen verhindern die Nutzung externer APIs
Reduzierung der Feinabstimmungskosten ohne Qualitätseinbußen
Mehrere Strategien reduzieren die Kosten bei gleichzeitiger Aufrechterhaltung der Leistungsfähigkeit.
Fang klein an
Beginnen Sie mit dem kleinsten Modell, das funktionieren könnte. Optimieren Sie ein 3-Billionen-Parameter-Modell, bevor Sie Varianten mit 7 oder 13 Milliarden Parametern ausprobieren. Die Leistung könnte ausreichen – und die Kosten bleiben unter $500.
Laut einer arXiv-Studie zur Feinabstimmung von ressourcenschonenden LLMs für die Finanzstimmungsanalyse (arXiv:2512.00946) werden Modelle mit 7–8 Milliarden Parametern, darunter DeepSeek-LLM 7B, Llama3 8B Instruct und Qwen3 8B, anhand von Finanzdatensätzen mit FinBERT evaluiert. Kleinere Modelle liefern für klar definierte Aufgaben produktionsreife Ergebnisse.
LoRA standardmäßig verwenden
Beginnen Sie jedes Feinabstimmungsprojekt mit LoRA, es sei denn, zwingende Gründe erfordern eine vollständige Feinabstimmung. Die Qualitätserhaltung des 80-95% im Vergleich zur Kostenreduzierung des 70-95% macht LoRA zur naheliegenden Standardwahl.
Durch die Optimierung der Rangparameter lässt sich die Optimierung weiter vorantreiben. Niedrigere LoRA-Ränge (8–16) reduzieren die Kosten im Vergleich zu höheren Rängen (32–64) bei minimalen Einbußen an der Genauigkeit für viele Aufgaben.
Trainingsdauer optimieren
Mehr Epochen garantieren keine besseren Ergebnisse. Überwachen Sie den Validierungsverlust und beenden Sie das Training, sobald keine Verbesserung mehr eintritt. Durch frühzeitiges Stoppen vermeiden Sie unnötigen Rechenaufwand für marginale Verbesserungen.
Die Forschung des MIT-IBM Watson AI Lab zu Skalierungsgesetzen zeigt, dass eine absolute Fehlerrate (ARE) von etwa 4 Prozent die beste erreichbare Genauigkeit ist, die man aufgrund von zufälligem Startrauschen erwarten kann. Dies erfordert eine sorgfältige Zuweisung des Rechenbudgets. Ein Überschreiten dieses Punktes führt jedoch zu abnehmenden Erträgen bei exponentiell höheren Kosten.
Trainingsdaten aggressiv kuratieren
Fünfhundert hochwertige Beispiele sind besser als 5.000 mittelmäßige. Investieren Sie von Anfang an Zeit in die Datenqualität, um die Anzahl der erforderlichen Trainingsiterationen zu reduzieren.
Entfernen Sie Duplikate, beheben Sie Formatierungsfehler und überprüfen Sie die Bezeichnungen. Saubere Daten beschleunigen das Training und erzielen bessere Ergebnisse, wodurch Zeit und Kosten gespart werden.
Erwägen Sie Managed Services
Die Kosten für eine Plattform sind mitunter geringer als der Entwicklungsaufwand. Managed Services übernehmen die Bereitstellung, Überwachung und das Checkpoint-Management der Infrastruktur. Für Teams ohne Expertise im Bereich ML-Infrastruktur bieten Managed-Plattformen wie Together AI oder Hugging Face AutoTrain schnellere Ergebnisse zu geringeren Gesamtkosten.
Häufig gestellte Fragen
Wie viel kostet die Feinabstimmung von GPT-3.5 oder GPT-4?
OpenAI berechnet die Gebühren anhand der Trainings-Token. Das Feinabstimmen von GPT-3.5-Turbo kostet etwa $0,008 pro 1.000 Trainings-Token. Ein Datensatz mit 100.000 Trainings-Token kostet ungefähr $0,80 für das Training. Die Preise für das Feinabstimmen von GPT-4 sind deutlich höher – die aktuellen Preise finden Sie auf der offiziellen Preisseite von OpenAI, da diese regelmäßig aktualisiert werden.
Kann ich LLMs auf einem Laptop feinabstimmen?
Kleinere Modelle (2–3 Milliarden Parameter) laufen auf High-End-Laptops mit mindestens 16 GB Arbeitsspeicher oder dediziertem VRAM unter Verwendung von 4-Bit-Quantisierung und LoRa. Das Training dauert je nach Datensatzgröße Stunden bis Tage. Cloud-GPUs sind in den meisten Fällen praktischer, aber die Feinabstimmung auf einem Laptop ist für Experimente technisch möglich.
Ist Feintuning langfristig günstiger als die Nutzung von API-Aufrufen?
Es hängt vom Inferenzvolumen ab. Berechnen Sie die monatlichen API-Kosten bei aktueller Nutzung und vergleichen Sie diese mit den einmaligen Kosten für die Feinabstimmung zuzüglich der Inferenzkosten mit Ihrem optimierten Modell. Bei Anwendungen mit hohem Volumen (Millionen von Tokens monatlich) amortisiert sich die Feinabstimmung oft innerhalb weniger Monate. Bei geringem Volumen oder für experimentelle Zwecke sind die API-Kosten niedriger.
Wie oft sollte ich mein Modell neu feinabstimmen?
Führen Sie eine erneute Feinabstimmung durch, wenn sich die Basismodelle deutlich verbessern oder die Leistung bei neuen Datenmustern nachlässt. Viele Teams verzichten bei modernen Modellen für große Kontexte ganz auf die erneute Feinabstimmung und aktualisieren stattdessen die Eingabeaufforderungen beim Wechsel zu neueren Basismodellen. Prüfen Sie, ob die Vorteile der Feinabstimmung auch bei größeren Kontextfenstern und verbesserten Basismodellfähigkeiten bestehen bleiben.
Worin besteht der Unterschied zwischen den Kosten für die Feinabstimmung und den Inferenzkosten?
Die Feinabstimmung ist ein einmaliger Aufwand für das Training und die Anpassung des Modells. Die Inferenzkosten fallen hingegen bei jeder Vorhersage des Modells an. Bei selbstgehosteten Modellen werden die Inferenzkosten auf eine feste Infrastruktur verlagert, während API-basierte Modelle pro verarbeitetem Token abrechnen. Berücksichtigen Sie beides bei der Berechnung der Gesamtbetriebskosten.
Benötige ich mehrere GPUs zur Feinabstimmung von LLMs?
Nicht geeignet für Modelle mit weniger als 13 Milliarden Parametern bei Verwendung von LoRa und Quantisierung. Eine einzelne Consumer-GPU (RTX 3060 12 GB oder besser) kann Modelle mit 7–8 Milliarden Parametern mithilfe von PEFT-Verfahren verarbeiten. Für die vollständige Feinabstimmung größerer Modelle oder das Training mit mehr als 13 Milliarden Parametern sind in der Regel Multi-GPU-Systeme erforderlich, es sei denn, eine extreme Quantisierung ist akzeptabel.
Wie kann ich die Kosten für die Feinabstimmung vor Beginn abschätzen?
Bestimmen Sie die Modellgröße, wählen Sie die Trainingsmethode (vollständiges Training vs. LoRa), schätzen Sie die Trainingsdauer anhand der Datensatzgröße und berechnen Sie die benötigten GPU-Stunden. Multiplizieren Sie die GPU-Stunden mit den Tarifen Ihres Cloud-Anbieters. Planen Sie einen Puffer von 30–401 TP3T für Experimente ein. Beginnen Sie mit kleinen Pilotläufen, um die Schätzungen zu validieren, bevor Sie das volle Trainingsbudget festlegen.
Die Feinabstimmungsentscheidung treffen
Die Kosten für die Feinabstimmung variieren um zwei Größenordnungen, je nachdem, welche Entscheidungen im Vorfeld getroffen werden.
Erfolgreiche Teams hinterfragen zunächst, ob eine Feinabstimmung überhaupt notwendig ist. Größere Kontextfenster und bessere Basismodelle lösen Probleme, die noch vor wenigen Monaten eine Feinabstimmung erforderten. Sollte sich eine Feinabstimmung als notwendig erweisen, ermöglichen parametereffiziente Verfahren wie LoRA die Entwicklung kundenspezifischer Modelle zu Budgets unter $100 für die meisten Anwendungsfälle.
Die kostspieligen Fehler weisen gemeinsame Muster auf: Auslassen der Datenqualitätsvalidierung, Auswahl überdimensionierter Modelle und Durchführung eines vollständigen Feintunings, obwohl LoRA ausreichen würde.
Mal ehrlich: Planen Sie Budget für Experimente ein. Der erste Trainingslauf liefert selten produktionsreife Ergebnisse. Rechnen Sie mit 3–5 Iterationen, behalten Sie die Kosten im Blick und optimieren Sie konsequent.
Bereit für die Feinabstimmung im Rahmen Ihres Budgets? Beginnen Sie mit dem kleinstmöglichen Modell, verwenden Sie standardmäßig LoRA und prüfen Sie die Datenqualität, bevor Sie Rechenleistung investieren. Ihre erste erfolgreiche Feinabstimmung ist lehrreicher als jede Anleitung.