Kurzzusammenfassung: Das Training eines großen Sprachmodells kostet je nach Modellgröße, Infrastruktur und Trainingsdauer zwischen 1,4 Billionen und über 1,4 Billionen. Kleinere Modelle mit 20 Milliarden Parametern kosten etwa 1,4 Billionen bis 100.000, während massive Systeme wie GPT-4 oder Gemini über 100 Millionen kosten können. Die größten Kostenfaktoren sind GPU-Rechenzeit, Datenaufbereitung und Cloud-Infrastruktur.
Die Wirtschaftlichkeit des Trainings großer Sprachmodelle ist zu einem entscheidenden Faktor in der KI-Entwicklung geworden. Unternehmen stehen nun vor der wichtigen Entscheidung, ob sie eigene Modelle entwickeln oder kommerzielle Dienste in Anspruch nehmen.
Und die Zahlen? Sie sind erschreckend.
Laut einer Studie von Epoch AI haben sowohl GPT-4 als auch Googles Gemini Hunderte Millionen Dollar für das Training gekostet. Es handelt sich dabei nicht nur um geringfügige Verbesserungen gegenüber früheren Modellen – die finanziellen Hürden sind in den letzten Jahren sprunghaft angestiegen.
Aber das Entscheidende ist: Nicht jede Organisation benötigt ein Frontier-Modell. Das Verständnis der Kostenstruktur hilft dabei, den richtigen Ansatz für spezifische Anwendungsfälle zu bestimmen.
Was treibt die Trainingskosten für große Sprachmodelle an?
Die Schulungskosten lassen sich in mehrere Hauptkategorien unterteilen, die jeweils einen erheblichen Anteil an der Gesamtrechnung ausmachen.
Recheninfrastruktur
Die GPU-Hardware macht den größten Teil der Kosten aus. Modelle mit rund 100 Milliarden Parametern benötigen leistungsstarke GPU-Hardware, wie beispielsweise die A100-GPUs von NVIDIA. Für ein Modell mit 20 Milliarden Parametern benötigt die Infrastruktur typischerweise 8 bis 16 A100-GPUs mit 80 GB Speicher.
Die Rechenkosten allein belaufen sich für ein kleineres Modell auf $50.000–$100.000. Diese Basisberechnung – etwa $22.000 (16 A100 × $2,75/Std. × 500 Stunden) – stellt lediglich den erfolgreichen Trainingslauf dar.
Aber Moment mal.
Fehlgeschlagene Läufe und Experimente können diesen Wert leicht verdoppeln oder verdreifachen. Das Training großer Sprachmodelle ist kein einmaliger Prozess. Hyperparameter-Optimierung, Architekturexperimente und Fehlersuche beanspruchen zusätzliche Rechenzeit.
Zeit und Dauer
Die Trainingsdauer skaliert mit der Modellgröße und -komplexität. Ein Modell mit 20 Milliarden Parametern benötigt etwa 500 bis 1000 Stunden für das Training. Größere Modelle mit über 120 Milliarden Parametern können mehrere tausend GPU-Stunden in Anspruch nehmen.
Die Kosten für die Cloud-Infrastruktur summieren sich stündlich. Jede Optimierung, die die Trainingszeit verkürzt, senkt daher direkt die Kosten. Eine effiziente Hyperparameter-Auswahl, ein optimiertes Datenpipeline-Design und reduzierte GPU-Leerlaufzeiten wirken sich finanziell aus.
Datenaufbereitung und -verwaltung
Hochwertige Trainingsdaten entstehen nicht von selbst. Organisationen investieren erhebliche Summen in die Datenerfassung, -bereinigung, -kennzeichnung und -aufbereitung. Die zunehmende Verknappung öffentlich verfügbarer, qualitativ hochwertiger Daten hat diese Herausforderung noch verschärft.
Auch die Kosten für Datenspeicherung und -übertragung summieren sich. Das Verschieben massiver Datensätze zwischen Speichersystemen und Rechenclustern verursacht Bandbreiten- und Speichergebühren, die in vielen anfänglichen Budgets unterschätzt werden.

Die wahren Kosten einer LLM-Ausbildung verstehen
Das Training eines großen Sprachmodells erfordert weit mehr als nur Rechenressourcen. Datenaufbereitung, Modellentwicklung, Evaluierung und die Infrastruktur für den Einsatz beeinflussen ebenfalls die Gesamtkosten.
AI Superior hilft Organisationen bei der Beurteilung, ob das Trainieren eines Modells von Grund auf gerechtfertigt ist oder ob alternative Ansätze wie die Modellanpassung oder die API-Integration praktikabler sind.
Zu ihren Dienstleistungen gehören:
- Gestaltung der Ausbildungspipeline
- Strategie und Validierung des Datensatzes
- Infrastrukturplanung
- Kosten-Nutzen-Analyse von kundenspezifischen Modellen
Wenn Sie die Entwicklung eines individuellen LLM-Programms in Betracht ziehen, kann eine Machbarkeitsanalyse dazu beitragen, unnötige Schulungskosten zu vermeiden.
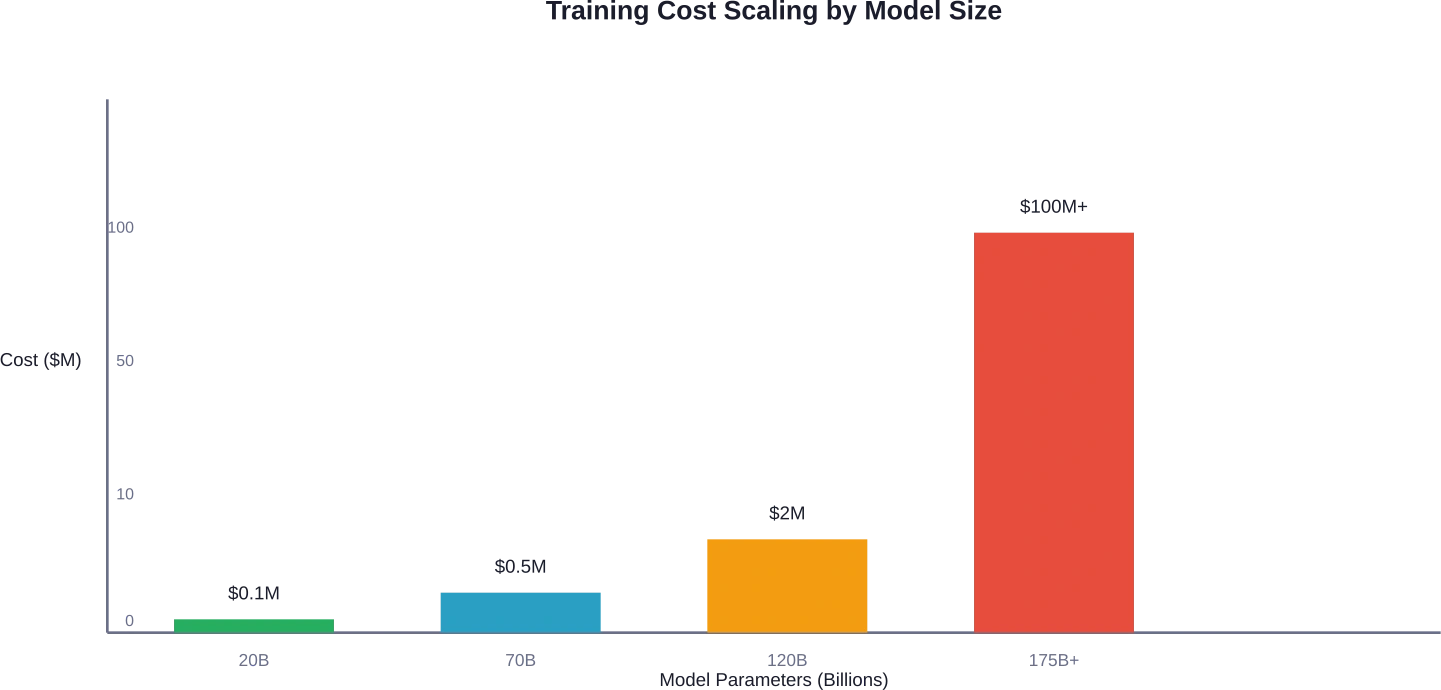
Kostenvergleich in der Praxis: Parameter von 20 Mrd. bis 120 Mrd.
Lassen Sie uns die tatsächlichen Kostenbereiche für verschiedene Modellgrößen aufschlüsseln.
| Modellgröße | GPU-Anforderungen | Grundrechnerkosten | Geschätzte Gesamtkosten |
|---|---|---|---|
| 20B-Parameter | 8-16 A100 80 GB | $22,000-$50,000 | $50,000-$100,000 |
| 70B-Parameter | 32-64 A100 80 GB | $100,000-$250,000 | $200,000-$500,000 |
| 120B+ Parameter | 64-128+ A100 80 GB | $300,000-$800,000 | $500,000-$2,000,000 |
| Frontier-Modelle (175B+) | Mehr als 1000 GPUs | $50M-$200M+ | $100M-$500M+ |
Der Unterschied zwischen kleinen und großen Modellen ist nicht linear, sondern exponentiell. Ein Modell mit 120 Milliarden Parametern kostet etwa 5- bis 20-mal so viel wie ein Modell mit 20 Milliarden Parametern, nicht nur aufgrund der Parameteranzahl, sondern auch wegen der höheren Trainingskomplexität, längerer Konvergenzzeiten und des höheren Infrastrukturaufwands.
Das Frontier-Modell Premium
Systeme wie GPT-4 und Gemini spielen in einer völlig anderen Kostenklasse. Laut Daten von Epoch AI haben die Entwicklungskosten dieser Modelle Hunderte von Millionen Dollar betragen.
Warum solche astronomischen Zahlen?
Zukunftsweisende Modelle benötigen massive GPU-Cluster, die monatelang laufen. Sie beinhalten umfangreiche Experimente, mehrere Trainingsläufe, Sicherheitstests und Ausrichtungsarbeiten. Allein die Infrastruktur – die Tausende von GPUs gleichzeitig verwaltet – erfordert hochentwickelte Orchestrierungssysteme.
Aufschlüsselung der Infrastrukturkosten
Die Infrastrukturkosten beschränken sich nicht nur auf die reine GPU-Miete. Unternehmen müssen den gesamten Technologie-Stack berücksichtigen.
GPU-Hardwareoptionen
NVIDIAs A100-GPUs gelten weiterhin als Standard für das LLM-Training, obwohl neuere Varianten wie die H100 und H200 eine bessere Leistung zu höheren Preisen bieten. Die Wahl hängt von Verfügbarkeit, Budget und Zeitplan ab.
Cloud-Anbieter berechnen unterschiedliche Preise. AWS, Google Cloud und Microsoft Azure haben jeweils eigene Preisstrukturen für GPU-Instanzen. Spezialisierte Anbieter, die sich auf KI-Workloads konzentrieren, bieten mitunter günstigere Konditionen für eine kontinuierliche Nutzung.
Speicher und Netzwerk
Modell-Checkpoints, Trainingsdaten und Protokolle beanspruchen erheblichen Speicherplatz. Ein Modell mit 120 Milliarden Parametern erzeugt Checkpoint-Dateien mit einer Größe von jeweils über 500 GB. Unternehmen speichern daher üblicherweise während des Trainings mehrere Checkpoints zur späteren Wiederherstellung und Analyse.
Die Netzwerkbandbreite spielt ebenfalls eine Rolle. Der Datentransfer zwischen Speicher und Rechenleistung, insbesondere bei verteiltem Training über mehrere Knoten hinweg, kann die monatliche Rechnung um Tausende von Dollar erhöhen.
Hosting und Bereitstellung
Die Trainingskosten sind nur der Anfang. Das Hosting dieser Modelle für die Inferenz verursacht laufende Kosten. Bei Modellen mit rund 100 Milliarden Parametern liegen die Hostingkosten je nach Modellgröße und Nutzungsmuster zwischen 1.400.500.000 und 1.400.000 PKR pro Jahr.
Die häufig zitierten Entwicklungskosten für destillierte Modelle wie DeepSeek-V3 lassen möglicherweise die Kosten für das Training leistungsfähigerer Lehrermodelle, von denen sie abgeleitet wurden, außer Acht. Dies verdeutlicht, wie Buchhaltungsansätze die gesamten Entwicklungsinvestitionen verschleiern können.
Optimierungsstrategien zur Reduzierung der Schulungskosten
Mehrere Techniken können die Schulungskosten drastisch senken, ohne die Modellqualität zu beeinträchtigen.
Quantisierung und gemischte Präzision
FP4-Quantisierungsframeworks für LLMs haben gezeigt, dass sie bei großen Modellen eine mit BF16 und FP8 vergleichbare Genauigkeit bei minimalen Einbußen erreichen können. Diese Technologie reduziert den Speicherbedarf und beschleunigt die Berechnung, wodurch die benötigte GPU-Zeit direkt gesenkt wird.
Das Training mit gemischter Präzision ist mittlerweile Standard. Durch die Verwendung geringerer Präzision für bestimmte Arbeitsgänge und die Beibehaltung höherer Präzision dort, wo es darauf ankommt, wird ein effektives Gleichgewicht zwischen Geschwindigkeit und Genauigkeit geschaffen.
Trainingsmethoden für niedrige Ränge
Die Anwendung von Parametrisierungen niedrigen Rangs auf Transformer-basierte LLMs reduziert den Rechenaufwand und kann in manchen Fällen die Leistung sogar verbessern. Diese Methoden komprimieren den Parameterraum, ohne die Ausdrucksstärke des Modells zu beeinträchtigen.
Effiziente Datenstrategien
Untersuchungen zu Chinchilla-optimalen Skalierungsgesetzen deuten darauf hin, dass ein LLM-Entwickler, der ein 13B-Modell trainiert, das mit einer Inferenznachfrage von 2 Billionen Token rechnet, den gesamten Rechenaufwand potenziell um etwa 1,7×10²² FLOPs (17%) reduzieren könnte, indem er kleinere Modelle länger trainiert.
Die wichtigste Erkenntnis? Längeres Training mit mehr Daten kann die späteren Inferenzkosten senken, wenn das Modell viele Anfragen bearbeiten soll. Die Gesamtbetriebskosten sind wichtiger als die reinen Trainingskosten.

Spot-Instanzen und unterbrechbare VMs
Cloud-Anbieter bieten vergünstigte Spot-Instanzen an, die unterbrochen werden können. Für fehlertolerante Trainingsworkflows mit regelmäßigen Checkpoints senken Spot-Instanzen die Kosten im Vergleich zur On-Demand-Preisgestaltung um 40 bis 701 Tsd. Euro.
Der Nachteil? Das Training könnte sich aufgrund von Unterbrechungen verlängern. Bei einem effizienten Kontrollpunktmanagement rechtfertigen die Einsparungen jedoch in der Regel den höheren Aufwand.
Die Entscheidung zwischen Selberbauen und Kaufen
Organisationen stehen vor einer grundlegenden Entscheidung: Entweder sie entwickeln ihr eigenes Modell oder sie nutzen kommerzielle Dienstleistungen.
Wann kommerzielle Dienstleistungen sinnvoll sind
In den meisten Anwendungsfällen ist die Nutzung kommerzieller LLM-Dienste wirtschaftlicher. APIs von OpenAI, Anthropic und Google ermöglichen den Zugriff auf modernste Modelle ohne Vorabinvestitionen.
Laut Kosten-Nutzen-Analysen benötigen Unternehmen eine signifikante und nachhaltige Nutzung, um die Kosten für kommerzielle Dienstleistungen zu decken. Studien deuten darauf hin, dass Leistungsparitätsschwellen von etwa 201 TP3T führender kommerzieller Modelle sinnvolle Break-Even-Punkte für Infrastrukturinvestitionen darstellen.
Wann Training sinnvoll ist
Individuelle Schulungen werden attraktiv, wenn:
- Domänenspezifische Anforderungen erfordern spezialisierte Trainingsdaten
- Datenschutzbestimmungen verhindern das Senden von Informationen an APIs von Drittanbietern.
- Das erwartete Anfragevolumen übersteigt monatlich Millionen von Anfragen.
- Eine Feinabstimmung kommerzieller Modelle erweist sich für den Anwendungsfall als unzureichend.
Organisationen, die über mehrere Jahre hinweg mit einer intensiven und kontinuierlichen Nutzung rechnen, können mit selbstgehosteten Modellen niedrigere Gesamtbetriebskosten erzielen. Der Break-Even-Punkt hängt von der Modellgröße, dem Anfragevolumen und den erforderlichen Leistungsniveaus ab.
Überlegungen zur Testzeitberechnung
Jüngste Forschungsergebnisse zur Rechenlastverteilung während der Testphase offenbaren eine weitere Kostendimension. Die Kosten für die Inferenz können bei weit verbreiteten Modellen die Trainingskosten übersteigen.
Adaptive Allokationsstrategien, die Rechenleistung dynamisch anhand der Abfrageschwierigkeit zuweisen, verbessern die Effizienz erheblich. Trainingsfreie Schwierigkeitsindikatoren helfen dabei, feste Rechenbudgets auf Testabfragen zu verteilen und so die Anzahl gelöster Instanzen unter Einhaltung der Budgetbeschränkungen zu maximieren.
Forschungen zu effizienten Agenten zeigen, dass ein optimales Framework-Design von enormer Bedeutung ist. Eine Studie fand ein Framework, das die Leistung eines führenden Open-Source-Agenten um 96,71 TP3T beibehielt und gleichzeitig die Betriebskosten von 0,398 auf 0,228 senkte – eine Verbesserung der Durchlaufzeitkosten um 28,41 TP3T.
Rechnungslegungsgrundsätze für KI-Entwicklungskosten
Politikverantwortliche nutzen zunehmend Entwicklungskosten und Rechenleistung als Indikatoren für KI-Fähigkeiten und -Risiken. Jüngste Gesetze führen regulatorische Anforderungen ein, die an bestimmte Kostenschwellenwerte geknüpft sind.
Hier liegt das Problem: Technische Unklarheiten in der Kostenrechnung schaffen Schlupflöcher. Eine zu enge Kostenrechnung kann die tatsächlichen Entwicklungskosten eines Modells verschleiern. Die häufig genannten Entwicklungskosten für vereinfachte Modelle wie DeepSeek-V3 lassen möglicherweise die Kosten für das Training leistungsfähigerer Basismodelle außer Acht, von denen sie abgeleitet wurden.
Organisationen sollten eine umfassende Rechnungslegung einführen, die Folgendes beinhaltet:
- Alle Trainingsläufe, einschließlich fehlgeschlagener Experimente
- Kosten für Datenerfassung, -bereinigung und -aufbereitung
- Infrastrukturaufwand und Netzwerk
- Zeitaufwand für die Architekturentwicklung
- Sicherheitsprüfung und Ausrichtungsarbeiten
- Kosten von Lehrermodellen für Destillationsansätze
| Kostenkategorie | Typischer % von Gesamt | Oft übersehen? |
|---|---|---|
| GPU-Berechnung (erfolgreicher Lauf) | 30-40% | NEIN |
| Fehlgeschlagene Experimente | 15-25% | Ja |
| Datenaufbereitung | 10-15% | Ja |
| Speicher & Netzwerk | 5-10% | Ja |
| Ingenieursarbeit | 20-30% | Manchmal |
| Sicherheit und Ausrichtung | 5-10% | Ja |
Zukünftige Kostentrends
Mehrere Faktoren werden die Ausbildungskosten in den kommenden Jahren beeinflussen.
Die GPU-Hardware entwickelt sich stetig weiter. NVIDIAs Blackwell-Architektur – einschließlich der Varianten B100, B200 und GB200 – verspricht ein besseres Preis-Leistungs-Verhältnis. Die hohe Nachfrage hält die Preise jedoch weiterhin hoch.
Die Datenkosten steigen. Da qualitativ hochwertige öffentliche Daten immer knapper werden, investieren Unternehmen verstärkt in proprietäre Datensätze, die Generierung synthetischer Daten und Datenlizenzvereinbarungen.
Allerdings gleichen algorithmische Verbesserungen und Effizienzsteigerungen beim Training die Hardwarekosten teilweise aus. Die Forschungsgemeinschaft entwickelt kontinuierlich bessere Optimierungsmethoden, Skalierungsgesetze und Architekturentwürfe.
Häufig gestellte Fragen
Wie viel kostet das Training eines Modells mit 70 Milliarden Parametern?
Das Training eines Modells mit 70 Milliarden Parametern kostet typischerweise zwischen $200.000 und $500.000. Dies beinhaltet die grundlegenden Rechenkosten von $100.000-$250.000 für 32-64 A100-GPUs sowie zusätzliche Ausgaben für fehlgeschlagene Läufe, Experimente, Datenaufbereitung und Infrastrukturaufwand.
Können sich kleinere Organisationen das Training großer Sprachmodelle leisten?
Kleinere Organisationen können mithilfe von Cloud-GPU-Ressourcen und Optimierungstechniken Modelle mittlerer Größe (1–20 Milliarden Parameter) für $10.000–$100.000 trainieren. Für die meisten Anwendungen ist die Nutzung kommerzieller API-Dienste oder die Feinabstimmung bestehender Open-Source-Modelle jedoch kostengünstiger als das Training von Grund auf.
Was ist der teuerste Aspekt der LLM-Ausbildung?
Die GPU-Rechenzeit macht bei den meisten Projekten 30–401 Tsd. ...
Wie lange dauert das Training eines großen Sprachmodells?
Die Trainingsdauer variiert stark je nach Modellgröße. Ein Modell mit 20 Milliarden Parametern benötigt etwa 500–1000 GPU-Stunden (ungefähr 3–6 Wochen auf einem Cluster mit 16 GPUs). Größere Modelle mit über 120 Milliarden Parametern können mehrere tausend GPU-Stunden erfordern, wodurch sich das Training auf 2–4 Monate verlängert. Spitzenmodelle mit über 175 Milliarden Parametern trainieren oft mehrere Monate lang auf großen Clustern.
Ist es günstiger, einmalig zu trainieren oder langfristig API-Aufrufe zu nutzen?
Dies hängt vollständig vom Nutzungsvolumen ab. Für Anwendungen mit weniger als 10 Millionen API-Aufrufen pro Monat sind kommerzielle Dienste in der Regel günstiger. Organisationen mit dauerhaft hohem Nutzungsvolumen – insbesondere solche, die spezielle Modelle benötigen oder Datenschutzanforderungen erfüllen müssen – können über mehrere Jahre hinweg durch Selbstschulungen wirtschaftlicher vorgehen.
Worin besteht der Unterschied zwischen Trainingskosten und Inferenzkosten?
Die Trainingskosten sind einmalige Ausgaben für die Modellentwicklung und können zwischen Tausenden und Hunderten von Millionen Dollar liegen. Die Inferenzkosten sind laufende Kosten für den Betrieb des Modells zur Vorhersage, die pro Anfrage oder Token abgerechnet werden. Bei weit verbreiteten Modellen übersteigen die gesamten Inferenzkosten über die Lebensdauer des Modells häufig die Trainingskosten.
Wie kann ich die Kosten für die LLM-Ausbildung reduzieren?
Zu den wichtigsten Strategien zur Kostenreduzierung gehören die Verwendung von Quantisierung (FP4/FP8-Training), die Nutzung von Spot-Instanzen zur Einsparung von 40-70%, die Implementierung effizienter Checkpointing-Verfahren zur Minimierung von Rechenzeitverschwendung, die Optimierung von Datenpipelines zur Reduzierung der Leerlaufzeit der GPU sowie die Berücksichtigung der Modelldestillation aus größeren Lehrermodellen, wenn dies angebracht ist.
Die Investitionsentscheidung treffen
Das Training großer Sprachmodelle ist nach wie vor teuer, aber die Kosten variieren stark. Unternehmen stehen nicht vor der Wahl zwischen modernsten Modellen und gar keinem Training.
Eine realistische Bewertung beginnt mit den Anforderungen des Anwendungsfalls. Welches Leistungsniveau löst das Geschäftsproblem tatsächlich? Benötigt die Anwendung Spitzentechnologie oder würde ein kleineres, spezialisiertes Modell ausreichen?
Für viele Anwendungen liefern Modelle mit 7 bis 20 Milliarden Parametern hervorragende Ergebnisse zu überschaubaren Kosten. Diese Systeme lassen sich für $50.000 bis $200.000 Parameter trainieren und sind somit auch für mittelständische Unternehmen mit spezifischen Anforderungen zugänglich.
Der Wettlauf um die neuesten KI-Modelle – mit über 175 Milliarden Parametern – ist vor allem für Unternehmen sinnvoll, die universelle KI-Plattformen entwickeln. Für alle anderen liegen die besten Ergebnisse oft in kleineren, spezialisierten Modellen, die für bestimmte Aufgaben optimiert sind.
Betrachten Sie die Gesamtbetriebskosten. Schulungen stellen nur den Anfang dar. Berücksichtigen Sie Hosting, Inferenzkosten, laufende Wartung und das benötigte Entwicklerteam zur Systembetreuung.
Die Wirtschaftlichkeit der LLM-Entwicklung entwickelt sich stetig weiter. Hardware wird besser, Algorithmen werden effizienter und neue Trainingsmethoden kommen regelmäßig auf den Markt. Was heute 1.400.500.000 TP kostet, könnte in zwei Jahren nur noch 200.000 TP kosten – oder für denselben Preis die dreifache Leistung erbringen.
Organisationen, die in diesen Bereich einsteigen, sollten klein anfangen, sorgfältig messen und erst bei nachgewiesenem Nutzen skalieren. Die Technologie ist mittlerweile so ausgereift, dass Experimente keine massiven Vorabinvestitionen mehr erfordern. Entwickeln Sie Prototypen mit kleineren Modellen, validieren Sie den Ansatz und entscheiden Sie dann, ob eine Skalierung oder die Nutzung kommerzieller APIs sinnvoller ist.
Die KI-Revolution schreitet rasant voran, doch eine intelligente Implementierung ist wichtiger als reine Skalierung. Das Verständnis dieser Kostenstrukturen hilft Unternehmen, fundierte Entscheidungen zu treffen, anstatt Benchmarks zu verfolgen, die für ihre spezifischen Anwendungen möglicherweise irrelevant sind.