Kurzzusammenfassung: Zu den besten LLM-Analyseplattformen für Kosten- und Qualitätsverfolgung im Jahr 2026 zählen Confident AI für evaluierungsorientiertes Monitoring mit nutzungsbasierter Preisgestaltung, Langfuse für Open-Source-Observability mit Session-Tracking und Datadog LLM Observability für Tracing im Unternehmensmaßstab. MiniMax M2.5 gilt als das kosteneffizienteste Modell mit hoher Analysequalität, während AgServe-Frameworks demonstrieren, wie Session-Aware Serving eine GPT-4o-äquivalente Qualität zu 16,51 TP3T-Kosten erreichen kann.
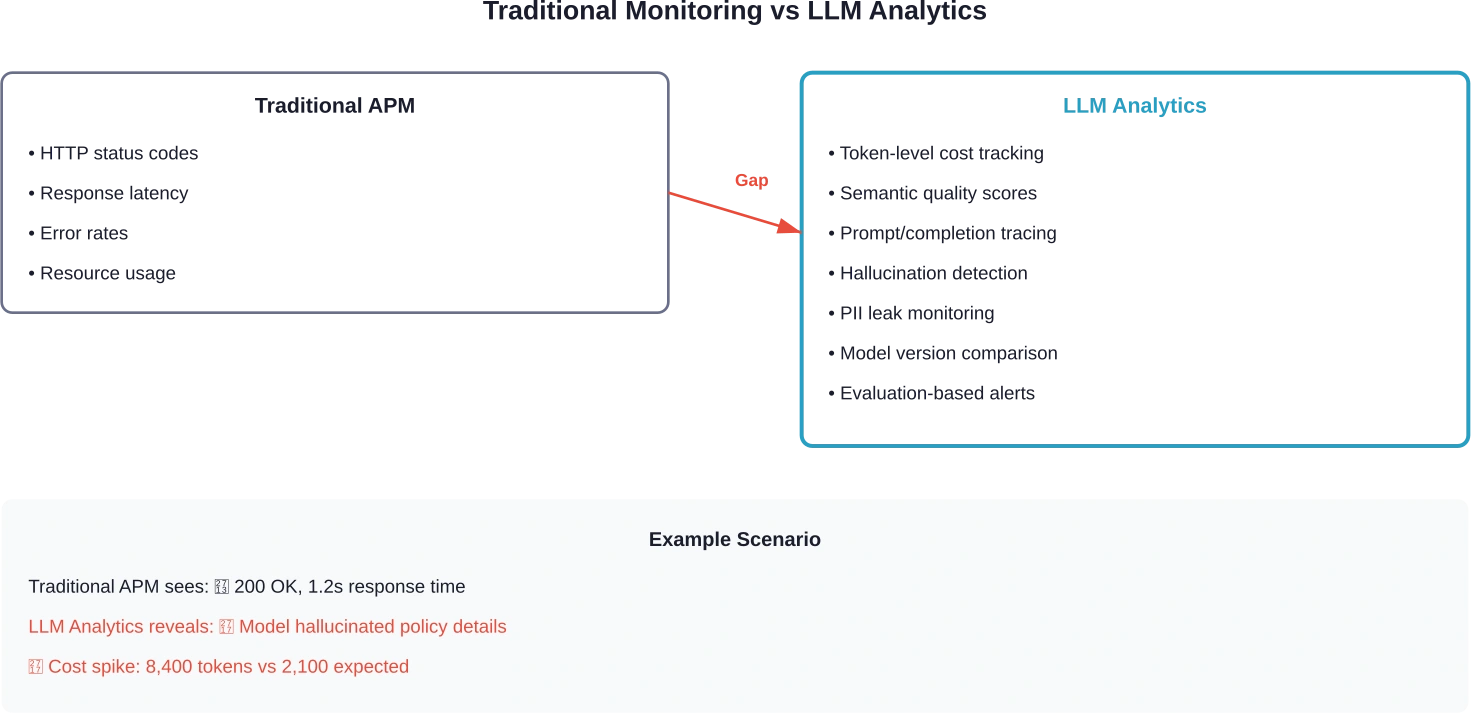
Herkömmliche Überwachungsmethoden decken KI-Fehler nicht auf. Ein APM-Dashboard zeigt zwar möglicherweise eine 200-Antwort in 1,2 Sekunden an, aber es zeigt nicht an, dass das Modell eine Richtlinie falsch interpretiert, sensible Informationen preisgegeben oder mitten im Gespräch vom Thema abgewichen ist.
Genau diese Lücke schließen LLM-Analysetools. Sie verfolgen Eingabeaufforderungen und Abschlüsse, berechnen die Tokenkosten pro Anfrage, erkennen Qualitätsabweichungen zwischen Modellversionen und decken Fehlermuster auf, die Standard-Observability-Plattformen völlig übersehen.
Mit der Skalierung von LLM-basierten Anwendungen vom Prototyp bis zur Produktion können die Tokenkosten schnell explodieren. Eine einzige nicht optimierte Prompt-Chain kann die Ausgaben verzehnfachen. Ohne Echtzeit-Einblick in die Nutzungsmuster entdecken Teams Budgetüberschreitungen oft erst, wenn der Schaden bereits entstanden ist.
Dieser Leitfaden stellt die führenden LLM-Analyseplattformen zur Kosten- und Qualitätsverfolgung vor. Wir erläutern die Unterschiede der einzelnen Tools, vergleichen die Preise der verschiedenen Anbieter und zeigen auf, welche Plattformen sich am besten für spezifische Einsatzszenarien eignen.
Warum Kosten- und Qualitätsverfolgung im LLM-Bereich wichtig sind
Produktionssysteme für KI versagen anders als herkömmliche Software. Ein Webserver liefert entweder Daten oder gibt eine Fehlermeldung aus. Ein LLM hingegen kann perfekt formatiertes JSON zurückgeben, das vollständig erfundene Informationen enthält.
Die Kostenkontrolle stellt eine weitere Herausforderung dar. Tokenbasierte Preisgestaltung bedeutet, dass jede Änderung an einer Anfrage die Wirtschaftlichkeit beeinflusst. Das Hinzufügen von Kontext zur Qualitätsverbesserung kann die Kosten pro Anfrage verdreifachen. Der Wechsel von GPT-4 zu einem kleineren Modell könnte die Kosten um 90% senken, aber die Ausgabegenauigkeit unter akzeptable Schwellenwerte verschlechtern.
Laut Forschungsergebnissen zu Agenten-Serving-Systemen mangelt es bestehenden Modell-Serving-Plattformen an Session-Awareness, was zu unnötigen Kompromissen zwischen Kosten und Qualität führt. Das AgServe-Framework demonstriert, dass Session-Awareness-KV-Cache-Management und qualitätsbasierte Modellkaskadierung eine Antwortqualität erreichen können, die mit GPT-4o vergleichbar ist, und das zu nur 16,5% der Kosten.
Folgendes ermöglicht eine korrekte LLM-Analyse:
- Kostenzuordnung auf Token-Ebene über verschiedene Eingabeaufforderungen, Benutzer, Funktionen und Modellversionen hinweg
- Qualitätsdrift-Erkennung durch automatisierte Bewertungsnoten und menschliche Feedbackschleifen
- Latenzverfolgung das trennt die API-Antwortzeit von der Modellverarbeitungszeit
- Fehlermusteranalyse das häufige Auslöser von Halluzinationen oder Formatierungsfehler aufdeckt
- Sicherheitsüberwachung wegen des Auslaufens personenbezogener Daten, unerlaubter Einschleusungsversuche und Verstößen gegen die Inhaltsrichtlinien
Ohne diese Fähigkeiten agieren die Teams im Blindflug. Sie können keine schnellen technischen Entscheidungen optimieren, den ROI gegenüber den Stakeholdern nicht nachweisen und Qualitätsbeeinträchtigungen nicht erkennen, bevor diese sich auf die Nutzer auswirken.
Was unterscheidet LLM Analytics von der Standard-Observability?
Standardmäßige APM-Tools erfassen Anfragen, Fehler und Latenz. Das ist notwendig, aber für LLM-Anwendungen nicht ausreichend.
Der grundlegende Unterschied: LLM-Analytics muss die semantische Qualität Es geht nicht nur darum, ob der API-Aufruf erfolgreich war, sondern auch um die Ergebnisse. Ein Statuscode 200 sagt beispielsweise nichts darüber aus, ob die Empfehlung des Modells korrekt, relevant oder sicher war.
Drei Funktionen unterscheiden die LLM-spezifische Analytik von der herkömmlichen Überwachung:
Tokenbasierte Kostenberechnung
Jeder API-Aufruf verbraucht Eingabe-Tokens (die Eingabeaufforderung) und Ausgabe-Tokens (die Bestätigung). Die Kosten variieren je nach Modell, Token-Typ und mitunter auch je nach Tageszeit. Für eine korrekte Kostenverfolgung müssen die Nutzungsmetadaten jeder API-Antwort analysiert und dem entsprechenden Kostenstellenbereich zugeordnet werden.
Laut der Dokumentation von Anthropic zum Kostenmanagement liefert der Befehl `/cost` detaillierte Statistiken zur Token-Nutzung, einschließlich Gesamtkosten, API-Dauer, Laufzeit und Codeänderungen. Diese detaillierte Nachverfolgung ermöglicht es Teams, kostenintensive Vorgänge zu identifizieren, bevor sie skaliert werden.
Bewertungsbasierte Qualitätskennzahlen
Die Qualität lässt sich nicht aus HTTP-Statuscodes ableiten. Analyseplattformen lösen dieses Problem, indem sie nach jedem Abschluss automatisierte Auswertungen durchführen. Diese Auswertungen prüfen auf fehlerhafte Ergebnisse, messen die Relevanz anhand der erwarteten Ausgaben, verifizieren die Einhaltung der Formatvorgaben und kennzeichnen potenzielle Sicherheitsverstöße.
Die Forschung von Anthropic zur Agentenbewertung unterstreicht, dass gute Bewertungen Teams helfen, KI-Agenten mit mehr Zuversicht zu entwickeln. Ohne sie verharren Teams in reaktiven Schleifen und erkennen Probleme erst im Produktivbetrieb, wo die Behebung eines Fehlers weitere Fehler verursacht.
Nachverfolgung von Eingabeaufforderungen und Abschlüssen
Standardprotokolle erfassen Endpunkte und Statuscodes. LLM-Tracing zeichnet den gesamten Zyklus von der Eingabeaufforderung bis zur Fertigstellung auf, einschließlich Systemmeldungen, Benutzereingaben, Funktionsaufrufen, Modellparametern und der endgültigen Ausgabe. Dieser Kontext ist unerlässlich für die Fehlersuche bei Qualitätsproblemen und die Optimierung von Eingabeaufforderungen.
Die Leitlinien von OpenAI zur Evaluierung mit Langfuse zeigen, wie die Nachverfolgung der internen Schritte von Agenten-Workflows sowohl Online- als auch Offline-Evaluierungsstrategien ermöglicht, die Teams nutzen, um Agenten zuverlässig in die Produktion zu bringen.
Die besten LLM-Analyseplattformen für 2026
Der Markt für LLM-Analysen hat sich deutlich weiterentwickelt. Plattformen lassen sich nun in drei Kategorien einteilen: evaluierungsorientierte Tools, Open-Source-Observability-Frameworks und Enterprise-Monitoring-Suiten.
Hier ist ein Vergleich der führenden Plattformen:
Zuversichtliche KI
Confident AI stellt die LLM-Qualitätsüberwachung in den Mittelpunkt und konzentriert sich dabei auf Evaluierungen und strukturierte Qualitätsmetriken anstatt auf die Observability im APM-Stil. Es vereint automatisierte Bewertungsscoring, LLM-Tracing, Schwachstellenerkennung und menschliches Feedback auf einer einzigen Plattform.
Das Tool eignet sich hervorragend für Teams, die der Qualitätssicherung Vorrang vor allgemeiner Observability einräumen. Jeder Trace wird automatisch anhand konfigurierbarer Metriken wie Relevanz, Halluzinationsrate und Formatkonformität ausgewertet.
Hauptmerkmale:
- Integrierte Bewertungsbibliothek mit über 20 Qualitätsmetriken
- Unterstützung benutzerdefinierter Evaluatoren für domänenspezifische Qualitätsprüfungen
- Integration von menschlichem Feedback für RLHF-Workflows
- Schwachstellenscan auf sofortige Einschleusung und PII-Leckage
- Versionierung von Datensätzen für Regressionstests
Preise: Die nutzungsbasierte Abrechnung macht es zu einer erschwinglichen Option für Teams mit moderatem Trace-Volumen. Die Kostenprognose sollte während der Einführungsphase erfolgen.
Ideal für: Teams mit Fokus auf Qualitätssicherung und evaluierungsgesteuerte Entwicklungszyklen.
Langfuse
Langfuse bietet Open-Source-LLM-Observability mit vollständiger Ablaufverfolgung bis zum Abschluss, Kostenverfolgung auf Token-Ebene und Qualitätsüberwachung. Die Plattform unterstützt sowohl selbstgehostete als auch Cloud-Bereitstellungsmodelle.
Laut dem OpenAI-Kochbuch zur Bewertung von Agenten mit Langfuse überwacht die Plattform interne Agentenschritte und ermöglicht sowohl Online- als auch Offline-Bewertungsmetriken, die von Teams verwendet werden, um Agenten zuverlässig in die Produktion zu bringen.
Langfuse zeichnet sich durch sitzungsbasiertes Tracking aus, indem es zusammengehörige Traces in Sitzungen gruppiert, um die Analyse von mehrstufigen Gesprächen und agentenbasierten Workflows zu vereinfachen.
Hauptmerkmale:
- Unbegrenzte Trace-Spannen im Pro-Tarif
- Sitzungsbasierte Gesprächsverfolgung
- Echtzeit-Bewertung
- Kostenzuordnung pro Benutzer, Funktion oder Modell
- Open-Source-Kern mit Enterprise-Cloud-Option
Preise: Langfuse Cloud bietet einen Hobby-Tarif (50.000 Einheiten/Monat kostenlos), einen Core-Tarif (1.000 Einheiten/Monat + Nutzung) und einen Pro-Tarif (1.000 Einheiten/Monat + Nutzung). Beide kostenpflichtigen Tarife beinhalten 100.000 Einheiten; die zusätzliche Nutzung kostet ab 1.000 Einheiten/Monat + Nutzung.
Ideal für: Teams, die Wert auf Open-Source-Flexibilität mit optionalem Cloud-Hosting legen, insbesondere für dialogbasierte Anwendungen mit mehreren Gesprächsrunden.
Helikone
Helicone bietet eine ressourcenschonende LLM-Observability mit Fokus auf Kostenoptimierung. Die Plattform fungiert als Proxy-Schicht zwischen Anwendungen und LLM-APIs und erfasst jede Anfrage, ohne dass Codeänderungen erforderlich sind.
Die Proxy-Architektur vereinfacht die Bereitstellung. Ändert man den API-Endpunkt, beginnt Helicone sofort mit der Protokollierung von Anfragen. Diese Einfachheit hat jedoch ihren Preis: weniger Flexibilität bei benutzerdefinierten Auswertungen und keine integrierten Qualitätsmetriken.
Hauptmerkmale:
- Integration ohne Programmieraufwand über API-Proxy
- Token-Nutzungsverfolgung über verschiedene Modelle hinweg
- Kostenüberwachung und Budgetwarnungen
- Latenzanalyse und Caching-Schicht
- Unterstützung für mehr als 10 LLM-Anbieter
Preise: Die kostenlose Version beinhaltet 10.000 Anfragen pro Monat. Die Pro-Version ist ab 1.040.790 £/Monat mit nutzungsbasierter Preisgestaltung erhältlich.
Ideal für: Teams, die einen schnellen Kostenüberblick ohne umfangreiche Auswertungsanforderungen benötigen.
Datadog LLM Observability
Datadog hat seine Enterprise-Monitoring-Plattform um LLM-Anwendungen erweitert. Durch die Integration werden LLM-Traces zusammen mit Infrastrukturmetriken, APM-Daten und Protokollen im selben Dashboard angezeigt.
Diese einheitliche Ansicht hilft Teams, die Leistung von LLM mit dem zugrunde liegenden Systemverhalten in Zusammenhang zu bringen. Langsame Abschlusszeiten könnten mit Datenbanklatenz korrelieren. Kostenspitzen könnten mit bestimmten Feature-Releases übereinstimmen.
Hauptmerkmale:
- Einheitliche Überwachung der gesamten Infrastruktur und der LLM-Schicht
- Echtzeit-Kostenverfolgung und Anomalieerkennung
- Aufschlüsselung der Tokennutzung nach Endpunkt und Benutzer
- Unterstützung benutzerdefinierter Metriken für domänenspezifische KPIs
- Funktionen für Unternehmenssicherheit und Compliance
Preise: Integriert in das bestehende Datadog-Abonnement. Aktuelle, auf die Observability-Anforderungen von LLM zugeschnittene Tarife finden Sie auf der offiziellen Website.
Ideal für: Unternehmensteams, die bereits Datadog nutzen und die LLM-Überwachung in ihren bestehenden Observability-Stack integrieren möchten.
Gewichte & Schrägen Weben
Weave erweitert die Experimentverfolgungsfunktionen von W&B auf LLM-Anwendungen. Es verfolgt Eingabeaufforderungsvorlagen, Modellparameter und Ausgaben über verschiedene Experimente hinweg und erleichtert so den Vergleich von Eingabeaufforderungsvariationen und Modellkonfigurationen.
Die Plattform zeichnet sich durch ihre hervorragende Offline-Evaluierung aus. Teams können Produktionsabläufe erfassen, sie anhand verschiedener Modelle oder Eingabeaufforderungen wiedergeben und Qualitätsunterschiede messen, bevor sie Änderungen implementieren.
Hauptmerkmale:
- Experimentorientierter Workflow zur schnellen Optimierung
- Offline-Auswertung mit Trace-Wiedergabe
- Kostenverfolgung pro Experiment und Modellvariante
- Integration mit den ML-Lebenszyklustools von W&B
- Datensatzverwaltung für Benchmark-Tests
Preise: Kostenloses Kontingent verfügbar. Team- und Enterprise-Tarife mit nutzungsbasierter Preisgestaltung – aktuelle Preise finden Sie auf der offiziellen Website.
Ideal für: ML-Teams, die umfangreiche Prompt-Optimierungsexperimente durchführen und Offline-Evaluierungsfunktionen benötigen.
| Plattform | Kostenverfolgung | Qualitätskennzahlen | Sitzungsbewusstsein | Startpreis
|
|---|---|---|---|---|
| Zuversichtliche KI | Ja | Mehr als 20 integrierte Auswertungen | Basic | Nutzungsbasiert |
| Langfuse | Ja | Kundenspezifische Evaluatoren | Fortschrittlich | Kostenlos / $249/Monat |
| Helikone | Ja | Beschränkt | NEIN | Kostenlos / $79/Monat |
| Datadog LLM | Ja | Benutzerdefinierte Metriken | Basic | Preise für Unternehmen |
| W&B Weave | Ja | Experimentorientiert | Offline-Wiedergabe | Kostenloses Kontingent verfügbar |

LLM-Systeme mit transparenter Kosten- und Qualitätsüberwachung entwickeln
LLM-Anwendungen benötigen Einblick in die Funktionsweise von Modellen im Produktivbetrieb. Die Nachverfolgung von Eingabeaufforderungen, Antworten, Token-Nutzung und Systemverhalten hilft Teams, die Qualität zu sichern und zu verstehen, wie ihre KI-Systeme tatsächlich genutzt werden. AI Superior Das Unternehmen entwickelt KI-Plattformen, auf denen Sprachmodelle in Backend-Systeme, Datenpipelines und Analysetools integriert werden. Die Ingenieure entwickeln KI-Software, die Protokollierung, Auswertung und Überwachung unterstützt, sodass LLM-Anwendungen zuverlässig im Produktivbetrieb verwaltet werden können.
Bereitstellung einer LLM-Anwendung in der Produktion?
Sprechen Sie mit einer KI, die überlegen ist gegenüber:
- Entwicklung von LLM-basierten Anwendungen und NLP-Werkzeugen
- Workflows für Monitoring und Analyse integrieren
- KI-Systeme in bestehende Softwareplattformen integrieren
👉 Kontakt AI Superior um Ihr KI-Entwicklungsprojekt zu besprechen.
Das richtige Modell für kosteneffiziente Analysen auswählen
Die Wahl der Plattform ist wichtig, aber die Modellauswahl bestimmt die tatsächlichen Kosten und die Qualität der Ergebnisse. Aktuelle Vergleichsstudien zeigen signifikante Unterschiede in der Leistungsfähigkeit der Modelle bei analytischen Arbeitslasten.
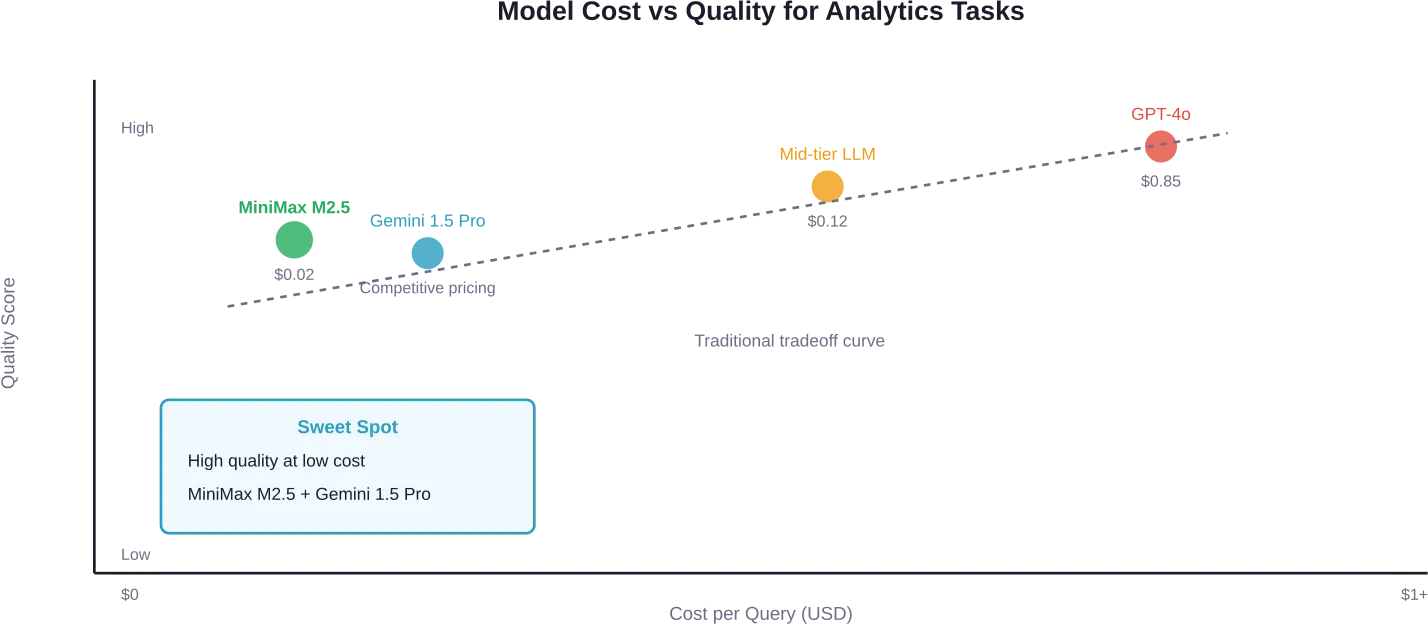
Laut Tests mit realen Google Analytics-Daten lieferte MiniMax M2.5 über mehrere Testläufe hinweg eine ausgezeichnete Qualität, kostete $0.02 pro Abfrage und erreichte eine durchschnittliche Bearbeitungszeit von 70 Sekunden.
Der Benchmark bewertete Modelle anhand mehrerer Dimensionen:
- Qualitätsbewertung: Lieferte das Modell über die Rohdaten hinausgehende, umsetzbare Erkenntnisse?
- Genauigkeitswert: Wie genau wurden die tatsächlichen GA4-Dimensionen und -Metriken verwendet?
- Kosten pro Abfrage: Gesamtkosten der API für die Durchführung der Analyseaufgabe
- Latenz: Zeit von der fristgerechten Einreichung bis zum Abschluss
Für strategische Analysen, die ein tieferes Verständnis erfordern, zeigte Gemini 1.5 Pro eine starke Leistung. Es erkannte sofort fehlerhaftes Attributions-Tracking in Testdaten und leitete zu einer aussagekräftigen Conversion-Analyse über. Zu diesen Preisen können Teams täglich Hunderte von Abfragen zu minimalen Kosten durchführen.
Forschungen zur Auswahl von LLMs für mehrstufige, komplexe Aufgaben bestätigen diese Ergebnisse. Das MixLLM-Framework zeigte, dass die adaptive Modellauswahl im Vergleich zur Verwendung eines einzelnen leistungsstarken kommerziellen LLM die Ergebnisqualität um 1-16% verbessert und gleichzeitig die Inferenzkosten um 18-92% senkt.
Kosten-Qualitäts-Abwägungsrahmen
Forschungen zur Überwindung des Kosten-Nutzen-Kompromisses bei Agentendiensten zeigen, dass sitzungsbasierte Architekturen die traditionelle Kompromisskurve durchbrechen können. AgServe erreicht eine vergleichbare Antwortqualität wie GPT-4o zu 16,5% Kosten durch zwei Innovationen:
- Sitzungsbewusste KV-Cache-Verwaltung: Das Framework nutzt die Entfernung von Elementen basierend auf der geschätzten Ankunftszeit und die Kalibrierung der Positionseinbettung direkt im Cache, um die Wiederverwendungsrate drastisch zu erhöhen. Dadurch werden redundante Berechnungen über mehrere Durchläufe hinweg reduziert.
- Qualitätsbewusste Modellkaskadierung: Anstatt sich für eine gesamte Sitzung auf ein einziges Modell festzulegen, führt AgServe eine Echtzeit-Qualitätsbewertung durch und aktualisiert die Modelle bei Bedarf während der Sitzung. Dadurch kann mit kostengünstigeren Modellen begonnen und erst dann auf höherwertige Modelle umgestiegen werden, wenn die Qualität dies erfordert.
Die Forschung belegt eine 1,8-fache Verbesserung der Qualität im Vergleich zur traditionellen Kosten-Nutzen-Abwägung und beweist damit effektiv, dass die richtige Architekturwahl bessere Ergebnisse bei gleichzeitig niedrigeren Kosten ermöglichen kann.
Wichtige Kennzahlen zur Verfolgung
Effektive LLM-Analysen erfordern die Erfassung der richtigen Kennzahlen. Zu viele Teams konzentrieren sich ausschließlich auf Kosten oder Latenz und ignorieren dabei Qualitätssignale, die die Nutzerzufriedenheit vorhersagen.
Kostenkennzahlen
- Tokenverbrauch pro Anfrage: Messen Sie sowohl Eingabe- als auch Ausgabetoken separat. Die Optimierungsstrategien unterscheiden sich – die Reduzierung von Eingabetoken erfordert eine zügige technische Anpassung, während die Kontrolle von Ausgabetoken bessere Stichprobenparameter oder Formatbeschränkungen erfordert.
- Kosten pro Nutzerinteraktion: Die Gesamtkosten aller API-Aufrufe, die zur Erledigung einer Benutzeraufgabe erforderlich sind, werden ermittelt. Eine einzelne Benutzerfrage kann mehrere Modellaufrufe auslösen (Abruf, Begründung, Formatierung), und die Gesamtkosten sind wichtiger als die Kosten einzelner Aufrufe.
- Kosten pro Funktion oder Endpunkt: Die Zuordnung ermöglicht die ROI-Analyse. Welche Funktionen generieren einen Mehrwert, der ihre LLM-Kosten rechtfertigt? Welche verbrauchen Token ohne proportionalen Nutzernutzen?
Die Dokumentation von Anthropic zum Kostenmanagement hebt die Bedeutung der Verfolgung von Nutzungsmustern mit dem Befehl /stats hervor, der Einblick in die Token-Nutzung, die API-Dauer, die Laufzeit und die Codeänderungen auf Sitzungsebene bietet.
Qualitätskennzahlen
- Halluzinationsrate: Prozentsatz der abgeschlossenen Projekte mit erfundenen Informationen, die nicht durch den bereitgestellten Kontext gestützt werden. Dies erfordert eine automatisierte Faktenprüfung anhand von Quelldokumenten oder Wissensdatenbanken.
- Relevanzbewertung: Wie gut beantwortet die Vervollständigung die eigentliche Benutzeranfrage? Die semantische Ähnlichkeit zwischen Frage und Antwort liefert einen Näherungswert.
- Formatkonformität: Bei strukturierten Ausgaben (JSON, CSV, SQL): Wie hoch ist der Prozentsatz der abgeschlossenen Analysen, die fehlerfrei durchgeführt werden?
- Sicherheitsverstöße: Häufigkeit von Ausgaben, die personenbezogene Daten, anstößige Inhalte oder Reaktionen auf Aufforderungsversuche zur Dateneingabe enthalten.
Untersuchungen zur Bewertung der Qualität von Gedankengängen bei der Codegenerierung ergaben, dass externe Faktoren 53,601 TP3T ausmachen (hauptsächlich unklare Anforderungen und fehlender Kontext), während interne Faktoren 40,101 TP3T ausmachen (vorwiegend Inkonsistenzen zwischen Schlussfolgerungen und Eingabeaufforderungen). Dies deutet darauf hin, dass die Überwachung sowohl der Eingabequalität als auch der Modellierungsmuster für die Einhaltung von Ausgabestandards wichtig ist.
Leistungsmetriken
- Zeit bis zum ersten Token (TTFT): Latenzzeit, bevor das Modell mit der Ausgabe beginnt. Entscheidend für die wahrgenommene Reaktionsfähigkeit in Chat-Oberflächen.
- Token pro Sekunde: Die Übertragungsgeschwindigkeit steigt, sobald das Streaming beginnt. Langsamere Übertragungsgeschwindigkeiten frustrieren Nutzer, die auf lange Wartezeiten warten.
- End-to-End-Latenz: Gesamtzeit von der Benutzeranfrage bis zur vollständigen Antwort, einschließlich Abruf, Vorverarbeitung, Modellinferenz und Nachbearbeitung.
| Metrische Kategorie | Wichtige Indikatoren | Warum es wichtig ist
|
|---|---|---|
| Kosten | Token-Nutzung, Kosten pro Interaktion, Kosten pro Funktion | Kontrolliert die Ausgaben und ermöglicht die ROI-Analyse |
| Qualität | Halluzinationsrate, Relevanzwert, Formatkonformität | Gewährleistet Ausgabegenauigkeit und Benutzerzufriedenheit |
| Leistung | TTFT, Token/Sekunde, End-to-End-Latenz | Gewährleistet ein reaktionsschnelles Benutzererlebnis |
| Sicherheit | Datenlecks, Versuche der sofortigen Dateneinschleusung, Richtlinienverstöße | Verhindert Sicherheitsvorfälle und Compliance-Probleme |
Umsetzungsstrategien
Um aus LLM-Analysen einen Mehrwert zu generieren, reicht die Installation eines Überwachungstools nicht aus. Teams benötigen strukturierte Ansätze für die Instrumentierung, die Gestaltung der Auswertung und die Alarmierung.
Beginnen Sie mit dem Nachzeichnen
Instrumentieren Sie LLM-API-Aufrufe, um vollständige Anfrage- und Antwortdaten zu erfassen.
Mindestens protokollieren:
- Zeitstempel und Anforderungs-ID
- Modellname und Parameter
- Vollständige Eingabeaufforderung (Systemmeldung, Benutzereingabe, Kontext)
- Vollständiger Vervollständigungstext
- Tokenanzahl (Eingabe, Ausgabe, Gesamt)
- Latenzaufschlüsselung (API-Zeit, Verarbeitungszeit)
- Kostenberechnung
Die meisten Analyseplattformen bieten SDKs an, die dies automatisch erledigen. Aber auch eine einfache, benutzerdefinierte Protokollierung in einem strukturierten Format ermöglicht eine nachträgliche Analyse.
Qualitätsstandards definieren
Die Forschung zur Entmystifizierung von Evaluierungen für KI-Systeme betont, dass Evaluierungsstrategien der Systemkomplexität entsprechen sollten. Codebasierte Bewertungsverfahren (Stringvergleich, Binärtests, statische Analyse) eignen sich für deterministische Ausgaben. LLM-basierte Bewertungsverfahren übernehmen die semantische Evaluierung, wenn ein exakter Vergleich nicht möglich ist.
Erstellen Sie einen Benchmark-Datensatz mit repräsentativen Eingabeaufforderungen und erwarteten Ausgaben. Testen Sie neue Modellversionen oder Eingabeaufforderungsvorlagen anhand dieses Datensatzes, bevor Sie sie bereitstellen. Verfolgen Sie Qualitätskennzahlen im Zeitverlauf, um Regressionen frühzeitig zu erkennen.
Gemäß den Richtlinien von OpenAI zur Agentenbewertung mit Langfuse beinhaltet die Offline-Bewertung typischerweise die Verwendung eines Benchmark-Datensatzes mit Eingabeaufforderungs-Ausgabe-Paaren, das Ausführen des Agenten auf diesem Datensatz und den Vergleich der Ausgaben mithilfe zusätzlicher Bewertungsmechanismen.
Kostenwarnungen einrichten
Bei tokenbasierter Preisgestaltung kommt es schnell zu Budgetüberschreitungen.
Konfigurieren Sie Benachrichtigungen für:
- Tägliche Kosten übersteigen den Basiswert um 251 TP3T+
- Einzelanfragen verbrauchen das Zehnfache der üblichen Token.
- Bestimmte Nutzer oder Funktionen, die unverhältnismäßige Kosten verursachen
- Unerwartete Modellversionsänderungen erhöhen die Ausgaben
Warnmeldungen sollten zu Untersuchungen anregen, nicht zu Panik. Kostenspitzen deuten oft eher auf Produkterfolg (verstärkte Nutzung) als auf Probleme hin. Transparenz ermöglicht es jedoch, Wachstum von Ineffizienz zu unterscheiden.
Feedbackschleifen implementieren
Automatisierte Metriken erfassen nicht alles, was Nutzern wichtig ist. Fügen Sie explizite Feedbackmechanismen hinzu:
- Daumen hoch/runter für abgeschlossene Spiele
- Detaillierte Problembeschreibung bei mangelhaften Ergebnissen
- Zufriedenheitsumfragen auf Sitzungsebene
Korrelieren Sie das Nutzerfeedback mit den automatisierten Qualitätsbewertungen. Wenn Menschen Abschlüsse mit hohen Bewertungen durchweg schlecht bewerten, müssen die automatisierten Metriken neu kalibriert werden.
Fortgeschrittene Optimierungstechniken
Sobald die grundlegende Überwachung betriebsbereit ist, können verschiedene fortgeschrittene Techniken das Kosten-Nutzen-Verhältnis deutlich verbessern.
Sitzungsbewusstes Modell Kaskadierung
Untersuchungen zum Agentenservice zeigen, dass die sitzungsbasierte Modellauswahl deutliche Verbesserungen ermöglicht. Anstatt sich für ein einziges Modell für die gesamte Konversation festzulegen, beginnt das System mit einem kostengünstigeren Modell und aktualisiert es während der Sitzung, wenn die Qualität dies erfordert.
Das AgServe-Framework erreicht eine GPT-4o-äquivalente Qualität zu 16,5% der Kosten, indem es Modelle während der Sitzungsdauer dynamisch auf Basis einer Echtzeit-Qualitätsbewertung auswählt und aktualisiert.
Die Umsetzung erfordert:
- Qualitätsbewertung nach jeder Modellantwort
- Schwellenwerte zur Definition akzeptabler Qualitätsniveaus
- Logik zur Eskalation auf leistungsfähigere (teurere) Modelle bei Bedarf
- KV-Cache-Verwaltung zur Wiederverwendung des Kontextes über Modellwechsel hinweg
Schnelle Optimierung auf Basis von Analysen
Analysen zeigen, welche Anfragemuster mit Qualitätsproblemen oder Kostenüberschreitungen korrelieren. Häufige Probleme sind:
- Übermäßige Kontextüberfrachtung: Das Hinzufügen ganzer Dokumente zu den Eingabeaufforderungen, obwohl gezielte Auszüge ausreichen würden, ist problematisch. Analysen, die eine hohe Anzahl an Eingabe-Tokens bei gleichzeitig niedriger Relevanzbewertung zeigen, deuten auf dieses Problem hin.
- Unklare Anweisungen: Allgemeine Anweisungen wie “Analysieren Sie diese Daten” führen zu unstrukturierten und unstrukturierten Ergebnissen. Analysen, die eine geringe Formatkonformität oder eine hohe Varianz in der Ausgabelänge aufzeigen, deuten auf Probleme mit der Verständlichkeit der Anweisungen hin.
- Fehlende Einschränkungen: Wird die Ausgabelänge oder das Ausgabeformat nicht angegeben, führt dies zu unnötig langen Vervollständigungen. Die Token-Nutzungsanalyse deckt dies schnell auf.
Caching-Strategien
Viele LLM-Anwendungen verarbeiten wiederholt ähnliche Kontexte. Analysen, die häufige Prompt-Präfixe identifizieren, ermöglichen gezielte Caching-Strategien.
Semantisches Caching speichert Einbettungen kürzlich gestellter Eingabeaufforderungen. Wenn eine neue Eingabeaufforderung einer zwischengespeicherten semantisch ähnlich ist, wird die zwischengespeicherte Vervollständigung zurückgegeben, anstatt die API aufzurufen. Dies eignet sich gut für FAQ-ähnliche Anwendungen, in denen viele Benutzer ähnliche Fragen stellen.
Das Zwischenspeichern von Eingabeaufforderungspräfixen nutzt die Verarbeitung gemeinsamer Systemmeldungen und Kontextinformationen wieder. Wenn 80% von Eingabeaufforderungen dasselbe 2.000-Token-Präfix verwenden, spart das Zwischenspeichern dieser Berechnung erhebliche Kosten.
Häufige Fehler und wie man sie vermeidet
Selbst Teams mit Überwachungsinfrastruktur begehen vorhersehbare Fehler, die die Effektivität der Analysen beeinträchtigen.
Verfolgung von Eitelkeitskennzahlen
Kennzahlen wie die Gesamtzahl der API-Aufrufe oder die Anzahl der Tokens sind nicht entscheidungsrelevant. Sie steigen mit dem Erfolg des Produkts. Verfolgen Sie stattdessen Kennzahlen, die auf Probleme hinweisen: Kosten pro geliefertem Wert, Qualitätsverlustraten und Ausreißer bei der Latenz.
Statistische Signifikanz ignorieren
Die Ergebnisse von LLM sind stochastisch. Ein einzelner fehlgeschlagener Abschluss deutet nicht auf systemische Probleme hin. Teams reagieren jedoch oft überempfindlich auf vereinzelte Fehler, anstatt Trends zu analysieren.
Um auf das Vorliegen einer qualitativ hochwertigen Regression schließen zu können, sind ausreichend große Stichproben erforderlich. Die Forschung zur LLM-Auswahl für mehrstufige Aufgaben legt den Schwerpunkt auf die Entwicklung von Systemen, die Leistungsschwankungen aufgrund der LLM-Stochastik tolerieren.
Optimierung nur hinsichtlich der Kosten
Kostensenkungen gemäß 50% sind bedeutungslos, wenn die Qualität so stark leidet, dass die Nutzererfahrung beeinträchtigt wird. Ziel ist ein optimales Kosten-Nutzen-Verhältnis, nicht die Minimierung der Kosten.
Die Analyse sollte beide Dimensionen gleichzeitig erfassen. Untersuchungen zum sitzungsbasierten Service zeigen, dass eine geeignete Architektur die Qualität verbessern kann. während Kosten senken, den traditionellen Zielkonflikt überwinden.
Nicht im Produktionsbetrieb getestet
Offline-Evaluierungen mit Benchmark-Datensätzen sind wichtig, das Verhalten in der Praxis weicht jedoch ab. Benutzer formulieren Abfragen anders als von Testentwicklern erwartet. Reale Grenzfälle treten in kuratierten Datensätzen nicht auf.
Führen Sie eine kontinuierliche Produktionsüberwachung durch und nutzen Sie diese, um Offline-Benchmarks zu optimieren. Der Benchmark sollte sich weiterentwickeln, um die tatsächlichen Nutzungsmuster widerzuspiegeln.
Häufig gestellte Fragen
Worin besteht der Unterschied zwischen LLM-Monitoring und LLM-Beobachtbarkeit?
Monitoring erfasst vordefinierte Metriken und alarmiert bei Überschreitung von Schwellenwerten. Observability ermöglicht die Untersuchung des Systemverhaltens durch beliebige Abfragen detaillierter Trace-Daten. Die meisten modernen Plattformen kombinieren beide Ansätze: strukturierte Metriken für Dashboards und Alarme sowie detaillierte Traces zur Behebung spezifischer Probleme.
Wie hoch sind die typischen Kosten für LLM-Analysen?
Die Preismodelle variieren erheblich. Nutzungsbasierte Plattformen berechnen die Kosten anhand des Trace-Volumens. Abonnementplattformen wie Langfuse Pro kosten $249/Monat für unbegrenzte Traces. Enterprise-Suiten wie Datadog integrieren LLM-Monitoring in bestehende Verträge.
Können Analysetools meine LLM-Kosten senken?
Analysen senken die Kosten nicht direkt, ermöglichen aber Optimierungsentscheidungen, die dies bewirken. Untersuchungen zum sitzungsbasierten Service zeigen, dass durch architektonische Verbesserungen Kostensenkungen von über 80% möglich sind.
Welche Qualitätskennzahlen sind für produktive LLM-Anwendungen am wichtigsten?
Halluzinationsrate und Relevanzbewertung sind entscheidend für die faktische Richtigkeit. Die Einhaltung des Formats ist für strukturierte Ausgaben wichtig. Sicherheitskennzahlen (z. B. Datenlecks, Resistenz gegen Prompt-Injection) beugen Sicherheitsvorfällen vor. Die spezifischen Kennzahlen hängen vom Anwendungsfall ab – Kundensupport-Anwendungen priorisieren andere Qualitätsdimensionen als Codegenerierungstools.
Soll ich Open-Source- oder kommerzielle LLM-Analysetools verwenden?
Open-Source-Tools wie Langfuse bieten Flexibilität bei der Bereitstellung und keine Abhängigkeit von einem bestimmten Anbieter, erfordern jedoch ein Infrastrukturmanagement. Kommerzielle Plattformen bieten Managed Hosting, schnellere Funktionsentwicklung und dedizierten Support. Teams mit ausgeprägten Infrastrukturkapazitäten bevorzugen oft Open Source. Teams, die sich auf die Anwendungsentwicklung und weniger auf den Betrieb konzentrieren, wählen in der Regel Managed-Lösungen.
Wie messe ich den ROI von LLM-Analytics-Investitionen?
Verfolgen Sie drei Dimensionen: Kosteneinsparungen durch Optimierung (reduzierter Token-Verbrauch), Qualitätsverbesserungen (bessere Nutzerbewertungen, weniger Supportanfragen) und höhere Entwicklungsgeschwindigkeit (schnelleres Debugging, sicherere Bereitstellungen). Die meisten Teams erzielen bereits innerhalb von 2–3 Monaten allein durch Kostenoptimierung einen positiven ROI, noch bevor die Vorteile hinsichtlich Qualität und Geschwindigkeit berücksichtigt werden.
Was ist die minimale, funktionsfähige Analysekonfiguration für eine neue LLM-Anwendung?
Beginnen Sie mit einer grundlegenden Protokollierung, die jede Eingabeaufforderung, jeden Abschluss, jede Tokenanzahl und die Kosten erfasst. Ergänzen Sie dies um eine einfache, für Ihren Anwendungsbereich relevante Qualitätsmetrik (z. B. Formatkonformität für strukturierte Ausgaben, Relevanzbewertung für Chat-Anwendungen). Richten Sie Kostenwarnungen für Budgetüberschreitungen ein. Diese minimale Konfiguration lässt sich in 1–2 Tagen implementieren und beugt den häufigsten Produktionsproblemen vor.
Schlussfolgerung
Die LLM-Analyse hat sich von einem netten Extra zu einer unverzichtbaren Produktionsfunktion entwickelt. Ohne Einblick in Tokenkosten, Qualitätskennzahlen und Leistungsmerkmale agieren Teams im Blindflug.
Die Plattformlandschaft bietet leistungsstarke Optionen für unterschiedliche Anforderungen. Confident AI ist führend im Bereich der evaluierungsorientierten Qualitätsüberwachung. Langfuse bietet Open-Source-Flexibilität mit robustem Session-Tracking. Helicone ermöglicht schnelle Kostentransparenz durch Proxy-basierte Bereitstellung. Datadog erweitert die Enterprise-Observability auf LLM-Workloads.
Doch die richtigen Werkzeuge allein garantieren keinen Erfolg. Effektive Analysen erfordern die Erfassung der richtigen Kennzahlen, die Entwicklung von Qualitätsstandards, die Implementierung von Feedbackschleifen und die Nutzung der gewonnenen Erkenntnisse zur Optimierung.
Forschungsergebnisse zeigen, dass sitzungsbasierte Architekturen die traditionellen Kosten-Nutzen-Abwägungen überwinden können. AgServe erreicht GPT-40-Qualität bei nur 16,51 TP3T Kosten durch intelligentes KV-Cache-Management und dynamische Modellauswahl. Diese Techniken funktionieren, weil sie die Systemarchitektur optimal an die spezifischen Eigenschaften von LLM-Workloads anpassen.
Die Teams mit den besten Ergebnissen wenden gemeinsame Praktiken an. Sie setzen von Anfang an umfassende Instrumente ein. Sie definieren frühzeitig Qualitätsstandards und verfolgen kontinuierlich Regressionen. Sie optimieren datenbasiert statt intuitiv. Und sie betrachten Analysen als ein Feedbacksystem, das sich im Laufe der Zeit verbessert, nicht als einmalige Implementierung.
Beginnen Sie mit der Implementierung grundlegender Funktionen zur Ablaufverfolgung und Kostenkontrolle. Ergänzen Sie die Liste um Qualitätskennzahlen, die für den Anwendungsfall relevant sind. Richten Sie Warnmeldungen ein, um Probleme zu erkennen, bevor sie sich auf die Benutzer auswirken. Nutzen Sie anschließend die gewonnenen Erkenntnisse, um iterative Verbesserungen bei Eingabeaufforderungen, Modellauswahl und Systemarchitektur voranzutreiben.
Der Unterschied zwischen Teams, die mit produktiven LLM-Anwendungen erfolgreich sind, und solchen, die damit Schwierigkeiten haben, liegt oft in der Datenanalyse. Messungen ermöglichen Optimierung. Optimierung führt zu nachhaltiger Wirtschaftlichkeit. Und nachhaltige Wirtschaftlichkeit ermöglicht die Entwicklung wirklich nützlicher KI-Produkte.