Kurzzusammenfassung: Benchmarks für LLM-Dienste messen die Inferenzleistung anhand von Durchsatz, Latenz und Kosteneffizienz. Benchmarking-Tools wie MLPerf, vLLM und GuideLLM unterstützen Unternehmen bei der Bewertung von Bereitstellungsoptionen. Selbstgehostete kleine Modelle (7–14 Milliarden Parameter) sind dabei 95–991 Tsd. Euro günstiger als kommerzielle APIs und bieten in vielen Anwendungsfällen eine vergleichbare Leistung.
Hohe Implementierungskosten für Sprachmodelle können über Erfolg oder Misserfolg eines KI-Projekts entscheiden. Laut AWS und anderen Branchenberichten verbraucht die Inferenz in Produktionsumgebungen mehr als 901 Tsd. Terabytes an Gesamtenergie für Sprachmodelle. Dies stellt einen enormen Betriebsaufwand dar, der sorgfältig kalkuliert werden muss.
Bei der Leistungsbewertung von LLM-Systemen geht es nicht mehr nur um Geschwindigkeit. Kosteneffizienz ist für Unternehmen, die KI-Anwendungen skalieren, zum Hauptkriterium geworden. Es geht nicht mehr darum, ob ein Modell Anfragen bearbeiten kann, sondern ob es dies profitabel tun kann.
Das Problem ist jedoch: Den meisten Teams fehlt ein systematischer Ansatz, um Leistung und Kosten gleichzeitig zu messen. Sie optimieren nur eine Kennzahl und sehen zu, wie die Ausgaben außer Kontrolle geraten.
LLM-Leistungsbenchmarks verstehen
Leistungsbenchmarks messen das Verhalten von LLMs unter bestimmten Bedingungen. Im Gegensatz zu Ranglisten für Modellqualität, die die Schlussfolgerungsfähigkeit bewerten, konzentrieren sich Leistungsbenchmarks auf operative Kennzahlen: Durchsatz, Latenz, Ressourcennutzung und letztendlich die Kosten pro Inferenz.
Die MLCommons MLPerf Inference Benchmark-Suite gilt als Branchenstandard für die Messung der Leistung von ML- und KI-Workloads. Mit der Version 5.1 von MLPerf Inference wurde Llama3.1-8B als Benchmark-Modell eingeführt, das eine Kontextlänge von 128.000 Token bietet und damit realen Unternehmensanforderungen entspricht.
Aber Moment mal – worauf kommt es beim Benchmarking eigentlich an?
Wichtige Leistungskennzahlen
Der Durchsatz misst die Anzahl der pro Sekunde verarbeiteten Anfragen. Ein höherer Durchsatz bedeutet, dass mit derselben Hardware mehr Nutzer bedient werden können. GuideLLM berechnet umfassende Perzentile, darunter das 0,1., 1., 5., 10., 25., 75., 90., 95. und 99. Perzentil für den Durchsatz und weitere Kennzahlen.
Latenz misst die Antwortzeit. MLPerf definiert spezifische Latenzbeschränkungen für verschiedene Szenarien. In Szenarien mit einem einzelnen Datenstrom wird die Latenz im 90. Perzentil gemessen, während in Server-Szenarien Antwortzeiten im Subsekundenbereich für interaktive Anwendungen angestrebt werden.
Die Zeit bis zum ersten Token (TTFT) ist entscheidend für die Nutzererfahrung. Konkret bedeutet das: Nutzer merken, wenn Antworten länger als 200–300 ms auf sich warten lassen. Diese Kennzahl beeinflusst direkt die wahrgenommene Reaktionsfähigkeit der Anwendung.
Der Durchsatz der Tokengenerierung unterscheidet sich vom Anfragedurchsatz. Er misst die Anzahl der pro Sekunde erzeugten Token und korreliert direkt mit der für den Benutzer sichtbaren Ausgabegeschwindigkeit. Jüngste Forschungsergebnisse zum Inferenzmodell für logisches Denken zeigen signifikante Speicherschwankungen während der Tokengenerierung, die diese Metrik beeinflussen.
Standard-Benchmark-Szenarien
MLPerf definiert vier primäre Szenarien. Jedes simuliert unterschiedliche Anwendungsmuster mit spezifischen Lastcharakteristika.
| Szenario | Abfragegenerierung | Latenzbeschränkung | Leistungskennzahl |
|---|---|---|---|
| Einzelstrom | Sequenzielle Anfragen | 90. Perzentil | 90%-ile Latenz |
| Mehrfachstrom | Chargen mit festem Intervall | 99. Perzentil | Maximale Ströme |
| Server | Poisson-Verteilung | 99. Perzentil | Anfragen pro Sekunde |
| Offline | Alle Anfragen gleichzeitig | Keiner | Gesamtdurchsatz |
Server-Szenarien simulieren Produktionslasten der API mit Poisson-verteilten Anfragen. Dieses Muster spiegelt realistisches Benutzerverhalten wider, bei dem Anfragen zufällig und nicht in festen Intervallen eintreffen.
Messung der LLM-Inferenzkosten
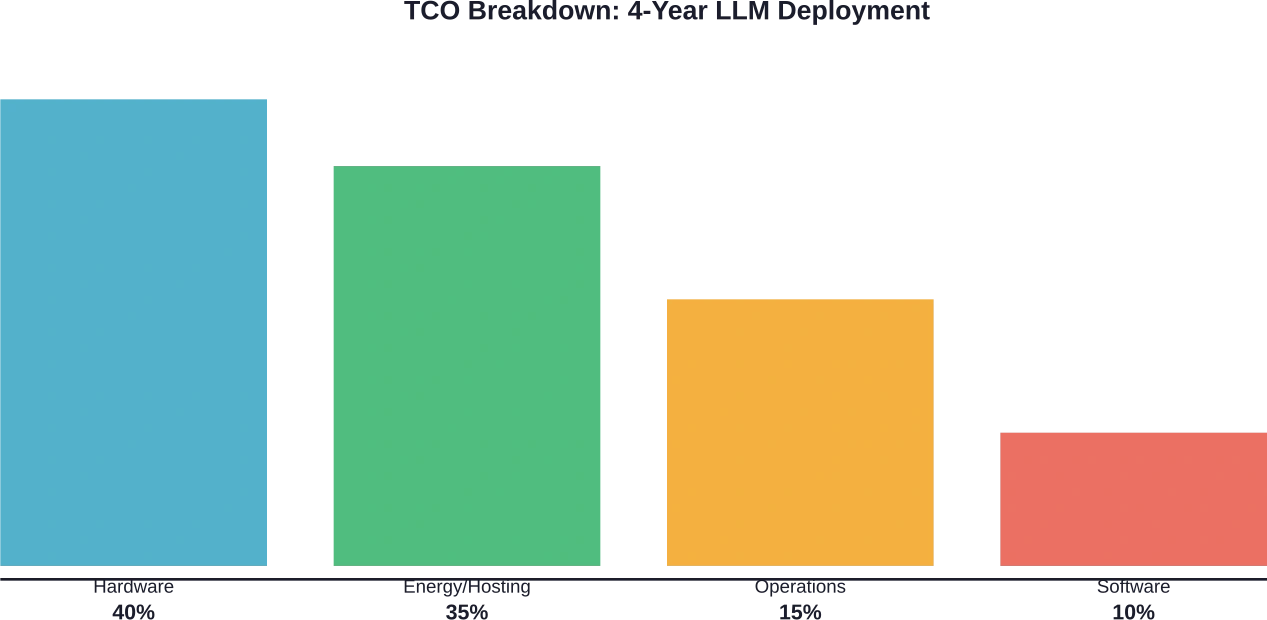
Für eine Kostenanalyse müssen sowohl direkte als auch indirekte Kosten berücksichtigt werden. Hardware-Abschreibung, Energieverbrauch, Hostinggebühren und Betriebskosten tragen alle zu den Gesamtbetriebskosten bei.
Gemäß dem ökonomischen Rahmenwerk für Inferenz des WiNGPT-Teams sollte LLM-Inferenz als rechenintensive intelligente Produktion betrachtet werden. Die A800 80G GPU hat beispielsweise stündliche Basiskosten von etwa $0,79, die unter üblichen Betriebsannahmen typischerweise zwischen $0,51 und $0,99 liegen.
Komponenten der Gesamtbetriebskosten
Die Hardwarekosten beginnen mit der Anschaffung. Serverkonfigurationen mit 8 GPUs können je nach GPU-Modell 1.400.320.000 € oder mehr kosten. Die Abschreibung erfolgt bei Unternehmenseinsätzen typischerweise über einen Zeitraum von vier Jahren.
Die Kosten für die Infrastrukturbereitstellung umfassen Hostinggebühren, Stromverbrauch, Kühlung und Rackplatz. Diese Betriebskosten summieren sich im Laufe der Zeit. Bei Cloud-Bereitstellungen variieren die Instanzpreise erheblich je nach GPU-Typ und Region.
Softwarelizenzierung und -wartung verursachen laufende Kosten. Open-Source-Frameworks wie vLLM eliminieren Lizenzgebühren, kommerzielle Lösungen hingegen berechnen Gebühren pro Bereitstellung oder pro verarbeitetem Token.
Kostenvergleich: Selbstgehostet vs. API
Die Kostenverhältnisse offenbaren deutliche Unterschiede zwischen den Bereitstellungsansätzen. Eine von Fin AI veröffentlichte Studie zeigt, dass kleinere Modelle im Vergleich zu kommerziellen APIs erhebliche Einsparungen ermöglichen.
| Modell | Parameter | Kosten vs. GPT-4.1 | Kosten vs. GPT-4.1 Mini | Kosten vs. Sonett 3.7 |
|---|---|---|---|---|
| Gemma 3 4B | 4B | 0.04 | 0.20 | 0.01 |
| DeepSeek Llama 8B | 8B | 0.05 | 0.27 | 0.01 |
| Qwen 3 14B | 14B | 0.05 | 0.27 | 0.01 |
| Gemma 3 27B | 27B | 0.34 | 1.71 | 0.08 |
| DeepSeek Llama 70B | 70B | 1.70 | 8.49 | 1.10 |
| Qwen 3 235B | 235B | 2.17 | 10.83 | 1.40 |
Kleinere Modelle mit weniger als 14 Milliarden Parametern sind deutlich günstiger als Modelle der GPT-4-Klasse. Untersuchungen zeigen, dass die Kosten im Vergleich zu GPT-4.1 nur 0,04- bis 0,05-mal so hoch sind. Das ist ein entscheidender Vorteil für Anwendungen mit hohem Datenvolumen, bei denen die Qualitätsanforderungen den Einsatz kleinerer Modelle zulassen.
Die Salesforce-Entwicklungsabteilung dokumentierte jährliche Einsparungen von über 1,4 Billionen US-Dollar durch den Ersatz von Live-LLM-Abhängigkeiten durch einen simulierten Dienst für Entwicklungs- und Benchmarking-Workflows. Dadurch wurde der Tokenverbrauch für Tests außerhalb der Produktionsumgebung eliminiert, während die Validierungskapazität bei 16.000 Anfragen pro Minute und einer Spitzenkapazität von über 24.000 Anfragen pro Minute erhalten blieb.
Benchmarking-Tools und -Frameworks
Mehrere Frameworks unterstützen systematische Benchmarks für LLM-Dienstleistungen. Jedes bietet unterschiedliche Möglichkeiten zur Messung von Leistung und Kosteneffizienz.
vLLM Benchmarking Suite
Das vLLM-Projekt bietet integrierte Benchmarking-Tools zur Messung von Durchsatz und Latenz. Das Framework unterstützt verschiedene Datensätze, darunter ShareGPT, BurstGPT und synthetische Zufallsdaten, die von Modell-Tokenisierern generiert werden.
Zu den wichtigsten Parametern des vLLM-Benchmarks gehören die maximale Anzahl gleichzeitiger Anfragen, die Anfrageraten und die Datensatzauswahl. Eine maximale Anzahl gleichzeitiger Anfragen von 10 bedeutet, dass der Server bis zu 10 Anfragen gleichzeitig verarbeitet und weitere Anfragen in eine Warteschlange stellt, bis Kapazität frei wird.
Die Benchmarks der vLLM-ascend-Version 0.7.3 demonstrierten die Leistungsfähigkeit der Modelle Qwen2.5-7B-Instruct und Qwen2.5-VL-7B-Instruct bei QPS-Raten von 1, 4, 16 und unendlich (unbegrenzt). Für die Tests wurden 200 zufällig ausgewählte Eingabeaufforderungen aus den Datensätzen ShareGPT und Vision Arena mit festgelegten Zufallszahlen verwendet, um die Reproduzierbarkeit zu gewährleisten.
GuideLLM für Produktions-Benchmarking
GuideLLM aus dem vLLM-Projekt ist auf die Auswertung von Inferenzdaten in realen Umgebungen spezialisiert. Es simuliert verschiedene Verkehrsmuster durch konfigurierbare Lastprofile.
Ratenbasierte Lasttests unterstützen konstante Anfrageraten. Ein Test mit 10 Anfragen pro Sekunde über 20 Sekunden mit synthetischen Daten von 128 Eingabeaufforderungs- und 256 Ausgabetoken liefert Basiswerte für den Durchsatz. Das Tool berechnet umfassende Perzentilverteilungen, einschließlich des 0,1., 1., 5., 10., 25., 50., 75., 90., 95., 99. und 99,9. Perzentils für jede Metrik.
Lastmuster sind wichtig, da unterschiedliche Anwendungen unterschiedliche Datenverkehrsmuster erzeugen. Burst-Tests zeigen das Systemverhalten bei plötzlichen Lastspitzen, während Dauerlasttests die Leistung im stationären Zustand messen.
MLPerf-Inferenz-Benchmarks
MLPerf Inference gilt als maßgeblicher Industriestandard. Die Benchmark-Suite deckt Rechenzentrums- und mobile Szenarien mit standardisierten Arbeitslasten in den Bereichen Bild-, Sprach- und Datenverarbeitung ab.
Für Rechenzentrumsszenarien misst MLPerf die Anzahl der Anfragen pro Sekunde unter Berücksichtigung spezifischer Latenzbeschränkungen. Benchmarks für Serverszenarien verwenden Poisson-verteilte Anfragemuster mit Latenzzielen im 99. Perzentil. Offline-Szenarien maximieren den Durchsatz ohne Latenzbeschränkungen.
Mit der Version 5.1 von MLPerf Inference wurde Llama3.1-8B mit Unterstützung für Kontexte mit 128.000 Token eingeführt. Dieser Benchmark spiegelt die modernen Anforderungen von Unternehmen an das Verstehen und Generieren langer Kontexte wider.
Abwägung von Kosten und Leistung der GPU
Die Hardwareauswahl hat einen erheblichen Einfluss auf Leistung und Kosteneffizienz. Untersuchungen zur Kosteneffizienz von LLM-Diensten auf heterogenen GPUs zeigen, dass unterschiedliche GPU-Typen mit unterschiedlichen Workload-Charakteristika harmonieren.
| GPU-Typ | Spitzen-FP16-FLOPS | Speicherbandbreite | Speichergrenze | Preis pro Stunde |
|---|---|---|---|---|
| A6000 | 91 TFLOPS | 768 GB/s | 48 GB | $0.83 |
| A40 | 150 TFLOPS | 696 GB/s | 48 GB | $0.55 |
| L40 | 181 TFLOPS | 864 GB/s | 48 GB | $1.15 |
Für LLM-Inferenz ist die Speicherbandbreite oft wichtiger als die Rechenleistung. Die Token-Generierung ist speicherintensiv, da die Modellgewichte wiederholt aus dem GPU-Speicher geladen werden. Die A6000 verfügt über eine Speicherbandbreite von 768 GB/s, die niedriger ist als die der L40 (864 GB/s) und deutlich niedriger als die der H100 oder A100 (2–3 TB/s).
Heterogene GPU-Bereitstellungen optimieren die Kosteneffizienz, indem sie die GPU-Leistung an die Anforderungseigenschaften anpassen. Rechenintensive Anfragen werden an GPUs mit hoher FLOPS weitergeleitet, während speicherintensive Anfragen Optionen mit hoher Bandbreite bevorzugen. Dieser Ansatz verbessert die Ressourcennutzung über verschiedene Anfragemuster hinweg.
Modellgröße und Hardwareanforderungen
Die Anzahl der Parameter bestimmt direkt den minimalen Speicherbedarf. FP16-Genauigkeit erfordert etwa 2 Byte pro Parameter, während die 4-Bit-Quantisierung dies auf etwa 0,5 Byte pro Parameter reduziert.

Die Leistung und die Kosten der Cloud-GPU-Optionen variieren erheblich. AWS g4dn.xlarge-Instanzen unterstützen einfache Workloads mit GPUs der Consumer-Klasse. AWS g5.xlarge bietet eine bessere Leistung für 7-8B-Modelle. Größere Modelle erfordern Multi-GPU-Konfigurationen oder spezielle Instanzen mit hohem Arbeitsspeicher.
Optimierung der Kosteneffizienz
Kostenoptimierung erfordert die gleichzeitige Berücksichtigung mehrerer Faktoren. Der Kompromiss zwischen Leistung, Qualität und Kosten erfordert systematische Messung und Iteration.
Auswirkungen der Quantisierung
Die 4-Bit-Quantisierung reduziert den Speicherbedarf und erhöht den Durchsatz bei minimalem Qualitätsverlust. Die meisten Anwendungen tolerieren die Quantisierung ohne spürbare Leistungseinbußen. Im Vergleich zur FP16-Genauigkeit reduziert die 4-Bit-Quantisierung den Speicherbedarf um etwa 751 T³T bei gleichbleibend hohem Durchsatz.
Die 8-Bit-Quantisierung bietet einen guten Mittelweg: Sie ermöglicht eine bessere Qualitätserhaltung bei gleichzeitig moderater Speichereinsparung. Für qualitätssensible Anwendungen ist 8-Bit daher eine sicherere Wahl als die aggressive 4-Bit-Quantisierung.
Anpassung der Chargengröße
Größere Batchgrößen verbessern die GPU-Auslastung und den Durchsatz. Die gleichzeitige Verarbeitung von 32 Anfragen erzielt eine höhere Hardwareeffizienz als die sequentielle Verarbeitung. Allerdings erhöht eine größere Batchgröße die Latenz für einzelne Anfragen.
Dynamisches Batching optimiert diesen Kompromiss, indem es Anfragen, die innerhalb eines Zeitfensters eintreffen, gruppiert. Bei sporadisch eintreffenden Anfragen sorgen kleinere effektive Batchgrößen für geringe Latenz. Während Lastspitzen maximiert automatisches Batching den Durchsatz.
Strategien für das Anfrage-Routing
Intelligentes Routing von Anfragen an heterogene GPU-Typen verbessert die Kosteneffizienz. Kurze Anfragen mit kleinen Batchgrößen werden an rechenoptimierte GPUs weitergeleitet. Anfragen mit langem Kontext erfordern einen erheblichen Speicherzugriff auf bandbreitenoptimierte Hardware.
Die Lastverteilung über mehrere Replikate hinweg verhindert Hotspots und verbessert die Gesamtauslastung. Round-Robin-Routing eignet sich für homogene Arbeitslasten, aber anforderungsbasiertes Routing liefert bessere Ergebnisse bei heterogenen Anforderungsmustern.
Erstellung eines TCO-Rechners
Eine genaue Kostenschätzung erfordert die systematische Erfassung aller Kostenkomponenten. Unternehmen benötigen Einblick in die tatsächlichen Kosten pro Anfrage, um fundierte Implementierungsentscheidungen treffen zu können.
Die Hardwarekosten unterteilen sich in Anschaffung und Abschreibung. Ein Server mit 8 GPUs zum Preis von 1.400.320.000 Tsd. bei einer Abschreibungsdauer von 4 Jahren kostet jährlich 1.400.800.000 Tsd. oder etwa 1.400.9,13 Tsd. pro Stunde bei einem 24/7-Betrieb.
Zu den Betriebskosten zählen Hostinggebühren, Stromverbrauch und Wartung. Cloud-Bereitstellungen vereinfachen diese Berechnung – die stündlichen Instanzkosten decken den Großteil der Betriebskosten ab. Selbstgehostete Bereitstellungen erfordern eine separate Erfassung der Infrastrukturkosten, des Stromverbrauchs (üblicherweise 0,10–0,15 TLP pro kWh) und des Verwaltungsaufwands.
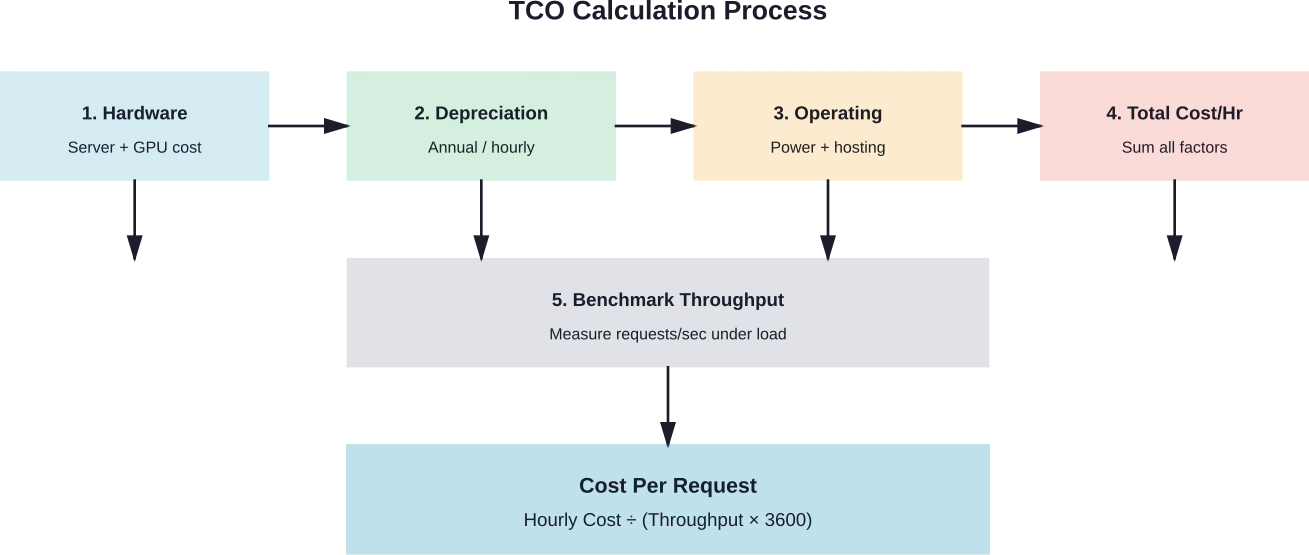
Die Formel für die Kosten pro Anfrage kombiniert die Kosten pro Stunde mit dem gemessenen Durchsatz:
Kosten pro Anfrage = Stundenkosten ÷ (Anfragen pro Sekunde × 3.600)
Bei einer Bereitstellung mit Kosten von $10 pro Stunde, die 50 Anfragen pro Sekunde bearbeitet, betragen die Kosten pro Anfrage $0,0000556 oder ungefähr $0,056 pro 1.000 Anfragen.

Senken Sie die Kosten für die LLM-Schulung durch intelligentere Modellentwicklung
Benchmark-Studien konzentrieren sich häufig auf Token, GPUs und Infrastrukturkosten. Die tatsächlichen Kostenunterschiede ergeben sich jedoch meist aus der Gestaltung und Implementierung des Modells. AI Superior arbeitet auf der Engineering-Ebene – erstellt kundenspezifische LLMs, optimiert Trainingspipelines und strukturiert Bereitstellungen, damit Modelle in der Produktion effizient laufen.
Wenn Ihre Benchmarks hohe Serverkosten aufweisen, liegt das Problem möglicherweise an der Architektur oder der Inferenzkonfiguration. Sprechen Sie mit AI Superior Ihr LLM-System zu überprüfen und praktische Wege zur Senkung der Servicekosten zu ermitteln.
Praktischer Benchmarking-Workflow
Systematisches Benchmarking folgt einem wiederholbaren Prozess. Der Einsatz repräsentativer Arbeitslasten stellt sicher, dass die Messungen die Produktionsbedingungen widerspiegeln.
Auswahl des Datensatzes
ShareGPT bietet realistische Gesprächsmuster mit unterschiedlich langen Eingabeaufforderungen und Antwortanforderungen. Der Datensatz enthält tatsächliche Nutzerinteraktionen und eignet sich daher hervorragend für produktionsnahe Tests. Durch die zufällige Auswahl von 200 bis 500 Eingabeaufforderungen mit einem festen Zufallswert werden reproduzierbare Ergebnisse gewährleistet.
Synthetische Datensätze ermöglichen kontrollierte Tests spezifischer Szenarien. Die zufällige Token-Generierung erzeugt Eingabeaufforderungen mit vordefinierten Längenverteilungen. Dieser Ansatz testet Grenzfälle wie die maximale Kontextlänge oder ungewöhnliche Token-Muster.
Konfiguration des Lademusters
Tests mit konstanter Datenrate messen die Leistung im stationären Zustand. Ein Testlauf mit 10 Anfragen pro Sekunde (QPS) über 60 Sekunden ermittelt die Basiswerte für Durchsatz und Latenz. Durch schrittweise Erhöhung der Datenrate lässt sich die maximal tragbare Last vor einer Verschlechterung der Latenz bestimmen.
Burst-Tests zeigen das Verhalten bei plötzlichen Lastspitzen. Ein Anstieg der Anfragen pro Sekunde (QPS) von 1 auf 100 QPS innerhalb von 10 Sekunden und die Messung der Erholungszeit belegen die Systemstabilität. Produktionssysteme weisen häufig Lastspitzen während der Spitzenzeiten auf.
Analyse der Ergebnisse
Perzentilverteilungen decken Ausreißer auf, die durch Durchschnittswerte verschleiert werden. Während eine Latenz im 50. Perzentil akzeptabel sein mag, zeigen Werte im 99. Perzentil die schlechteste Benutzererfahrung. GuideLLM berechnet automatisch Perzentile von 0,1% bis 99,9% für eine umfassende Analyse.
Ein sinkender Durchsatz unter Dauerlast deutet auf Ressourcenkonflikte hin. Ein stabiler Durchsatz über die gesamte Testdauer belegt die korrekte Skalierung. Ein rückläufiger Durchsatz lässt auf Speicherlecks, thermische Drosselung oder andere systembedingte Probleme schließen.
Energie- und Leistungsbetrachtungen
Der Energieverbrauch wirkt sich unmittelbar auf die Betriebskosten und die ökologische Nachhaltigkeit aus. Untersuchungen von TokenPowerBench unterstreichen, dass der Energieverbrauch für Inferenzprozesse die Trainingskosten bei Produktionssystemen, die täglich Milliarden von Anfragen bearbeiten, um das Zehnfache oder mehr übersteigt.
Die Benchmark-Daten von ML.ENERGY zeigen, dass Energie zu einem kritischen Ressourcenengpass geworden ist. Der Aufbau einer ausreichenden Strominfrastruktur für GPU-Flotten ist in vielen Regionen teurer und zeitaufwändiger als die Hardwarebeschaffung.
Die Leistungsmessung während Benchmarks ermöglicht Kostentransparenz. Der typische Stromverbrauch von GPUs liegt zwischen 250 W für effizienzoptimierte Karten und 700 W für Hochleistungsbeschleuniger. Bei 1 T²⁴T⁰,12 pro kWh kostet eine 400-W-GPU allein für Strom etwa 1 T²⁴T⁰,048 pro Stunde.
Die Multiplikation der Stromkosten mit der Anzahl der GPUs und die Hinzurechnung des Systembetriebs ergeben die gesamten Energiekosten. Für einen Server mit 8 GPUs, der 3.200 W zuzüglich Betriebskosten verbraucht, liegen die Energiekosten je nach lokalen Stromtarifen und Kühlleistung bei etwa $0,40–0,50 pro Stunde.
Häufig gestellte Fragen
Welche Modellgröße ist für den Produktionseinsatz am kosteneffektivsten?
Modelle mit 7 bis 14 Milliarden Parametern bieten eine hohe Kosteneffizienz für Unternehmensanwendungen. Untersuchungen von FinAI zeigen, dass diese Modelle im Vergleich zu Modellen der GPT-4-Klasse nur etwa 0,05-mal so viel kosten und dabei eine akzeptable Qualität für Aufgaben wie Kundensupport, Inhaltsklassifizierung und Extraktion strukturierter Daten gewährleisten. Kleinere Modelle mit 1 bis 3 Milliarden Parametern eignen sich für einfache Klassifizierungsaufgaben, während Modelle mit über 70 Milliarden Parametern Anwendungen vorbehalten sein sollten, die maximale Schlussfolgerungsfähigkeit erfordern.
Wie wirkt sich die Losgröße auf die Servierkosten von LLM aus?
Größere Batchgrößen verbessern die GPU-Auslastung und senken die Kosten pro Anfrage durch die gleichzeitige Verarbeitung mehrerer Anfragen. Eine Verdopplung der Batchgröße von 8 auf 16 erhöht den Durchsatz typischerweise um 40–60¹³Tp/s, ohne dass die Hardwarekosten proportional steigen. Allerdings erhöht eine größere Batchgröße die Latenz für einzelne Anfragen. Dynamische Batching-Strategien gleichen diesen Zielkonflikt aus, indem sie die Batchgröße an die aktuelle Last anpassen und so den Durchsatz während der Spitzenzeiten maximieren und gleichzeitig die Latenz in Zeiten geringer Auslastung niedrig halten.
Sollten Organisationen LLMs selbst hosten oder kommerzielle APIs nutzen?
Das Selbsthosting kleinerer Modelle kann bei hohem Nutzungsaufkommen kosteneffektiv sein, wobei die Gewinnschwelle je nach Modellgröße und Hardwarekonfiguration variiert. Unterhalb dieser Schwelle bleibt die Preisgestaltung kommerzieller APIs unter Berücksichtigung des Betriebsaufwands wettbewerbsfähig. Selbstgehostete Bereitstellungen können je nach Modellgröße und Bereitstellungskonfiguration erhebliche Kosteneinsparungen im Vergleich zu kommerziellen APIs ermöglichen. Unternehmen sollten zudem den Bedarf an technischem Know-how berücksichtigen, da Selbsthosting Infrastrukturmanagement, Überwachung und Leistungsoptimierung erfordert, die von kommerziellen APIs automatisch übernommen werden.
Welche Benchmarking-Tools eignen sich am besten zur Messung der LLM-Servierleistung?
GuideLLM eignet sich hervorragend für praxisnahe Produktions-Benchmarks mit konfigurierbaren Lastmustern und umfassenden Metriken. Die vLLM-Benchmark-Suite bietet eine optimale Integration für Teams, die vLLM bereits für den Serverbetrieb nutzen. MLPerf Inference liefert standardisierte Benchmarks für den Vergleich verschiedener Hardware- und Softwarekonfigurationen. Die verschiedenen Benchmark-Tools dienen unterschiedlichen Zwecken: MLPerf für standardisierte Vergleiche, GuideLLM für praxisnahe Produktionsszenarien und vLLM-Tools für Framework-integrierte Tests.
Wie viel VRAM wird für verschiedene Modellgrößen benötigt?
Die FP16-Genauigkeit erfordert etwa 2 Byte pro Parameter: 7B-Modelle benötigen 14–16 GB, 13B-Modelle 26–28 GB und 70B-Modelle 140 GB. Die 4-Bit-Quantisierung reduziert den Speicherbedarf um 751 TP3T: 7B-Modelle laufen mit 6–8 GB, 13B-Modelle mit 10–12 GB und 70B-Modelle mit 35–40 GB. Hinzu kommen 20–301 TP3T Overhead für den KV-Cache und den Aktivierungsspeicher. Ein 7B-Modell mit 4-Bit-Quantisierung läuft problemlos auf Consumer-GPUs mit 8 GB VRAM, während 70B-Modelle professionelle GPUs mit mindestens 40 GB VRAM oder Multi-GPU-Konfigurationen benötigen.
Was verursacht die Variabilität der Latenz bei LLM-Inferenz?
Begrenzte Speicherbandbreite ist der Hauptgrund für die Latenz. Die Token-Generierung lädt wiederholt Modellgewichte aus dem GPU-Speicher, wodurch die Inferenz speicher- statt rechenintensiv wird. Anfragen in Warteschlangen führen bei hoher Last zu variablen Wartezeiten. Die Größe des KV-Caches wächst mit der Kontextlänge, was den Speicherdruck erhöht und nachfolgende Token verlangsamt. Untersuchungen zur Inferenz von Modellen für logisches Denken zeigen signifikante Speicherschwankungen, die die Leistung beeinträchtigen. Die Überwachung der Latenz im 99. Perzentil macht diese Schwankungen besser sichtbar als durchschnittliche Metriken.
Wie verbessern heterogene GPU-Bereitstellungen die Kosteneffizienz?
Unterschiedliche GPU-Typen eignen sich hervorragend für verschiedene Arbeitslasten. GPUs mit hoher Bandbreite wie die A6000 (768 GB/s) optimieren die speicherintensive Token-Generierung, während GPUs mit hoher Rechenleistung wie die A40 (150 TFLOPS) rechenintensive Operationen optimal bewältigen. Forschungsergebnisse, die auf der ICML 2025 veröffentlicht wurden, zeigen, dass die Weiterleitung von Anfragen basierend auf Rechen- und Speicherbedarf die Auslastung heterogener GPU-Flotten verbessert. Heterogene GPU-Bereitstellungen können die Kosteneffizienz im Vergleich zu homogenen Ansätzen deutlich steigern, indem die Anfragecharakteristika den passenden GPU-Typen zugeordnet werden, anstatt einzelne GPU-Typen übermäßig zu dimensionieren.
Schlussfolgerung
Benchmarks für LLM-Dienste liefern wichtige Einblicke in das Leistungs- und Kostenverhältnis, das die Einsatzfähigkeit bestimmt. Unternehmen, die Durchsatz, Latenz und Gesamtbetriebskosten systematisch messen, treffen fundierte Entscheidungen über Selbsthosting versus kommerzielle APIs, Modellgrößenwahl und Hardwarebereitstellung.
Die Daten zeigen klare Muster. Kleinere Modelle mit 7 bis 14 Bit Parametern ermöglichen Kosteneinsparungen von 95 bis 991 TP3T im Vergleich zu führenden kommerziellen Modellen und bieten gleichzeitig eine für viele Unternehmensanwendungen akzeptable Qualität. Die Wirtschaftlichkeit des Selbsthostings hängt vom täglichen Tokenvolumen, den Hardwarekosten und dem unternehmensspezifischen Betriebsaufwand ab. Die 4-Bit-Quantisierung reduziert den Speicherbedarf um 751 TP3T bei minimalen Qualitätseinbußen.
Doch das Entscheidende ist Folgendes: Benchmarking ist keine einmalige Angelegenheit. Die Leistungsmerkmale ändern sich mit Modellaktualisierungen, Verbesserungen der Bereitstellungsframeworks und sich wandelnden Arbeitslastmustern. Unternehmen, die kontinuierliche Benchmarking-Workflows etablieren, sichern sich Kosteneffizienz bei der Skalierung ihrer KI-Implementierungen.
Beginnen Sie mit repräsentativen Arbeitslasten aus dem Produktionsbetrieb. Messen Sie umfassend Durchsatz, Latenz-Perzentile und Ressourcenauslastung. Berechnen Sie die tatsächlichen Gesamtbetriebskosten (TCO) inklusive Hardwareabschreibung, Energieverbrauch und Betriebskosten. Testen Sie verschiedene Bereitstellungskonfigurationen, um das optimale Kosten-Nutzen-Verhältnis für spezifische Anwendungsfälle zu ermitteln.
Die Tools sind vorhanden – MLPerf, vLLM, GuideLLM und andere bieten leistungsstarke Benchmarking-Funktionen. Die Methoden sind durch Praxiserfahrung und akademische Forschung erprobt. Nun gilt es, diese Frameworks systematisch auf die individuellen Anforderungen und Rahmenbedingungen jeder Organisation anzuwenden. Führen Sie sorgfältige Benchmarks durch, optimieren Sie kontinuierlich und erleben Sie, wie die Kosten für LLM-Dienstleistungen auch bei großem Umfang nachhaltig sinken.