Kurzzusammenfassung: Asynchroner Code kann die LLM-Kosten bei korrekter Implementierung drastisch senken, jedoch können häufige Fehler wie das vorzeitige Auslösen von Anfragen die Einsparungen zunichtemachen. Strategische asynchrone Muster in Kombination mit Techniken wie Prompt-Caching, Batch-Verarbeitung und kontrollierter Parallelität können die Kosten um 60–901 Tsd. Billionen senken, ohne die Leistung zu beeinträchtigen. Die Preisgestaltung des o3-Modells von OpenAI sank bis Juni 2025 um 801 Tsd. Billionen auf 1 Tsd. 4 Billionen pro Million Token, wodurch eine korrekte asynchrone Implementierung noch kosteneffizienter wird.
Die Kosten für LLM können schneller außer Kontrolle geraten, als die meisten Teams erwarten. Was mit einigen Validierungsskripten oder agentenbasierten Workflows beginnt, entwickelt sich schnell zu Tausenden von API-Aufrufen, die die Budgets in alarmierendem Tempo aufbrauchen.
Aber das Problem ist: Asynchrone Programmierung verspricht, alles schneller und effizienter zu machen. Doch bei falscher Implementierung kann sie tatsächlich... Zunahme Ihre Kosten, während gleichzeitig der Eindruck von Optimierung erweckt wird.
Die Ursache? Subtile Muster im asynchronen Code, die alle Anfragen im Voraus ausführen, selbst wenn nachgelagerte Prozesse frühzeitig beendet werden oder nur Teilergebnisse benötigen. Laut Diskussionen in den OpenAI-Entwicklerforen stoßen Entwickler, die von synchronen auf asynchrone Implementierungen umsteigen, trotz schnellerer Ausführungszeiten häufig auf unerwartete Kostenspitzen.
Die versteckte Kostenfalle im asynchronen LLM-Code
Asynchroner Code erscheint für LLM-Anwendungen als die naheliegende Wahl. Mehrere Anfragen gleichzeitig senden, Ergebnisse direkt nach Eingang verarbeiten und fortfahren. Schnellere Ausführung, zufriedenere Nutzer.
Doch in den gängigsten asynchronen Mustern lauert eine Falle.
Wenn asynchrone Funktionen alle ihre API-Aufrufe im Voraus erstellen – indem sie diese in Tasks oder Promises einbetten, bevor die Verarbeitungslogik ausgeführt wird –, erreicht jede einzelne Anfrage die Server des LLM-Anbieters. Selbst wenn Ihre Validierungslogik nach dem ersten Fehler stoppt. Selbst wenn der Benutzer den Vorgang mittendrin abbricht. Selbst wenn Sie nur drei Ergebnisse benötigen, aber fünfzig in die Warteschlange gestellt haben.
Die Anfragen wurden bereits abgeschickt. Die Token werden bereits verarbeitet. Die Rechnung steigt bereits.
Wie das Auslösen von Vorabanfragen funktioniert
Betrachten wir ein Validierungsskript, das LLM-Antworten anhand von Qualitätskriterien prüft. Eine einfache asynchrone Implementierung könnte folgendermaßen aussehen:
| async def validate_responses(prompts): tasks = [call_llm_api(prompt) for prompt in prompts] für Aufgabe in Aufgaben: Ergebnis = Aufgabe erwarten falls nicht meets_criteria(result): return False Rückgabewert: True |
Haben Sie das Problem entdeckt? Die List Comprehension in Zeile 2 erzeugt sofort alle API-Aufrufe. Noch bevor die Schleife startet. Bevor irgendeine Validierung stattfindet.
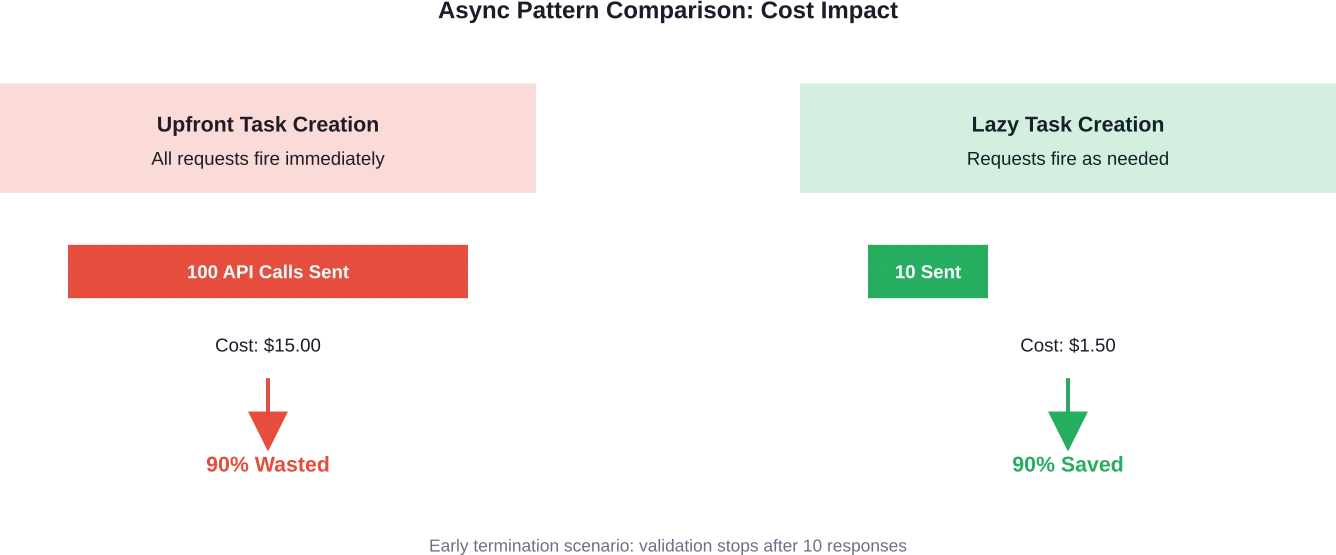
Wenn das erste Ergebnis die Validierung nicht besteht, gibt die Funktion False zurück – aber es sind bereits 49 andere API-Aufrufe im Gange, die bereits Token verbrauchen und Kosten verursachen.
Reale Kostenauswirkungen
Ein Entwicklerteam stieß auf dieses Problem, als ihr LLM-Validierungsskript zwar schnell lief, aber unerwartet hohe Rechnungen generierte. Obwohl sie scheinbar effizienten asynchronen Code implementiert hatten, verarbeiteten sie zehnmal mehr Token als nötig.
Die Lösung? Fünf Codezeilen, die die Erstellung und das Warten auf Aufgaben umstrukturierten. Anstatt alle Aufgaben im Voraus zu erstellen, wurde die Aufgabenerstellung in die Schleife verlagert, wodurch ein frühzeitiger Abbruch ermöglicht und unnötige API-Aufrufe vermieden werden konnten.
Ergebnis: Kostenreduzierung beim 90% bei praktisch keinem Einbruch der Geschwindigkeit oder Funktionalität.
Kontrollierte Parallelität: Die Semaphorlösung
Die Behebung des Problems mit der vorab ausgelösten Anfrage ist der erste Schritt. Es gibt aber noch ein anderes asynchrones Muster, das sich sowohl auf die Kosten als auch auf die Leistung auswirkt: unkontrollierte Parallelität.
Wenn Anwendungen Hunderte oder Tausende von LLM-Anfragen gleichzeitig senden, entstehen mehrere Probleme:
- Ratenbegrenzung, die Wiederholungsversuche und Verzögerungen auslöst
- Unregelmäßige Latenzzeiten, da die Infrastruktur des Anbieters mit Lastspitzen zu kämpfen hat
- Fehlgeschlagene Anfragen, die erneut bearbeitet werden müssen, verdoppeln die Kosten
- Speicherdruck durch die Verwaltung zu vieler gleichzeitiger Verbindungen
Die Lösung beinhaltet asyncio-Semaphore – einen Mechanismus zur Steuerung der Parallelität, der die Anzahl gleichzeitig ausgeführter Anfragen begrenzt.
Implementierung der semaphorbasierten Ratenbegrenzung
Laut Diskussionen in der OpenAI-Community erzielen Entwickler, die die Parallelitätskontrolle mithilfe eines asyncio-Semaphors mit einem Limit von 5 gleichzeitigen Aufrufen implementieren, eine konstantere Performance. Dies reduziert zwar nicht direkt den Tokenverbrauch, verhindert aber die Kaskade von Fehlern und Wiederholungsversuchen, die die Kosten in die Höhe treiben.
| import asyncio async def controlled_llm_call(semaphore, prompt): asynchron mit Semaphor: return await call_llm_api(prompt) async def process_batch(prompts): semaphore = asyncio.Semaphore(5) tasks = [controlled_llm_call(semaphore, p) for p in prompts] return await asyncio.gather(*tasks) |
Dieses Muster stellt sicher, dass nur fünf Anfragen gleichzeitig ausgeführt werden, wodurch die Überschreitung der Ratenbegrenzung reduziert und die Latenz stabilisiert wird.
Aber Moment mal – das Problem der vorgezogenen Aufgabenausführung besteht weiterhin. Die Aufgabenliste wird erstellt, bevor die eigentliche Verarbeitung stattfindet. Zur Kostenoptimierung empfiehlt sich die Kombination von kontrollierter Parallelverarbeitung mit verzögerter Aufgabenerstellung.
Prompt-Caching: Das Geheimnis der Kostenreduzierung bei 60%
Kommen wir nun zu einer anderen Art der Optimierung – einer, die unabhängig von Ihrer asynchronen Implementierung funktioniert.
Prompt-Caching nutzt die Tatsache, dass viele LLM-Anwendungen denselben Kontext wiederholt senden. Forschungsarbeiten, Dokumentationen, Systemanweisungen, Beispieldatensätze – Inhalte, die über mehrere Anfragen hinweg konstant bleiben.
Wenn Caching aktiviert ist, verarbeitet und speichert der LLM-Anbieter diese wiederholten Inhalte. Nachfolgende Anfragen, die die zwischengespeicherten Inhalte wiederverwenden, zahlen nur für die neuen Token, nicht für die gesamte Eingabeaufforderung.
Wie Prompt-Caching funktioniert
Die meisten großen LLM-Anbieter bieten mittlerweile ein beschleunigtes Caching mit ähnlichen Mechanismen an:
- Markieren Sie bestimmte Teile Ihrer Eingabeaufforderung als zwischenspeicherbar.
- Zuerst werden die Anfragen verarbeitet und die Inhalte zwischengespeichert.
- Nachfolgende Anfragen innerhalb eines Zeitfensters verwenden den Cache wieder.
- Sie zahlen reduzierte Preise für zwischengespeicherte Token.
Der Cache (Prompt-Caching) bleibt in der Regel 5 bis 10 Minuten lang gültig, wenn keine Aktivität stattfindet. Wird der Inhalt innerhalb dieses Zeitraums wiederverwendet, ergeben sich erhebliche Einsparungen.
Mal ehrlich: Wenn man eine Forschungsarbeit mit 30.000 Tokens hat und zehn verschiedene Fragen dazu stellen möchte, verändert Caching die Ökonomie komplett.
Ohne Caching verarbeitet das LLM alle 30.000 Tokens pro Frage – insgesamt also 300.000 Tokens. Mit Caching zahlen Sie den vollen Preis für die erste Anfrage und anschließend reduzierte Gebühren für den zwischengespeicherten Anteil bei den folgenden neun Anfragen.
| Szenario | Insgesamt verarbeitete Token | Kostenreduzierung
|
|---|---|---|
| Kein Caching (10 Anfragen) | 300.000 Token | Ausgangswert |
| Mit Caching (10 Abfragen) | ~120.000 Token | Einsparungen beim 60% |
| Mit Caching (50 Abfragen) | ~180.000 Token | Einsparungen beim 88% |
Kombination von Caching mit asynchronen Mustern
Hier wird es interessant. Wenn man eine korrekte asynchrone Implementierung mit Prompt-Caching kombiniert, vervielfachen sich die Kosteneinsparungen.
Asynchroner Code bündelt ähnliche Anfragen zeitlich – genau das, was Caching für eine effektive Funktion benötigt. Anfragen, die innerhalb des Gültigkeitszeitraums des Caches eintreffen, profitieren alle vom gleichen zwischengespeicherten Inhalt.
Wenn Ihre asynchrone Implementierung jedoch unnötige Anfragen auslöst, verbrauchen diese zusätzlichen Aufrufe Ihr Budget für zwischengespeicherte Inhalte, ohne einen Mehrwert zu liefern. Die durch das 60%-Caching erzielten Einsparungen werden durch die zehnfache Anzahl unnötiger Anfragen zunichtegemacht.
Wenn beides stimmt, verändern sich die wirtschaftlichen Gegebenheiten grundlegend.
Batch-API: Zeitersparnis durch massive Kosteneinsparungen
Die Batch-API von OpenAI stellt eine weitere Strategie zur Kostenreduzierung durch asynchrone Verarbeitung dar. Wie in der OpenAI-Entwickler-Community diskutiert, verlagern Entwickler etwa 4.200 synchrone Aufrufe auf die Batch-API, um das 24-Stunden-Verarbeitungsfenster und die damit verbundenen Kosteneinsparungen zu nutzen.
Der Kompromiss ist einfach: Man akzeptiert längere Bearbeitungszeiten im Austausch für deutlich reduzierte Kosten.
Wann Stapelverarbeitung sinnvoll ist
Batch-APIs eignen sich am besten für:
- Datenverarbeitung und -analyse
- Content-Generierungs-Pipelines
- Evaluierungs- und Testabläufe
- Jede Arbeitsbelastung, bei der sofortige Ergebnisse nicht entscheidend sind.
Das asynchrone Muster ist hier anders. Anstatt gleichzeitige Anfragen zu verarbeiten, übermittelt die Anwendung einen Batch-Job und prüft dessen Abschluss. Der LLM-Anbieter optimiert die Verarbeitung im Hintergrund, indem er Anfragen häufig an weniger ausgelastete Infrastruktur weiterleitet oder sie außerhalb der Spitzenzeiten verarbeitet.
| # Batch API asynchrones Muster async def submit_batch_job(requests): batch = await client.batches.create( input_file=upload_batch_file(requests), endpoint=”/v1/chat/completions” ) return batch.id async def poll_batch_status(batch_id): solange wahr: batch = await client.batches.retrieve(batch_id) if batch.status == “completed”: return await retrieve_batch_results(batch_id) await asyncio.sleep(60) |
Die Kosteneinsparungen ergeben sich aus der Fähigkeit des Anbieters, die Ressourcennutzung zu optimieren. Wenn Sie keine sofortigen Antworten benötigen, kann er Ihre Anfragen effizienter bearbeiten.

Senken Sie die LLM-Kosten durch die richtige Architektur
Die Kosten für LLM werden häufig durch ineffiziente Nutzungsmuster, große Eingabeaufforderungen und schlecht strukturierte Inferenzpipelines verursacht. Die Zusammenarbeit mit einem erfahrenen KI-Entwicklungsteam wie AI Superior Das Unternehmen kann dabei helfen, die tatsächlichen Kostenquellen zu identifizieren. Es entwickelt kundenspezifische KI-Systeme und LLM-basierte Anwendungen, darunter NLP-Tools, Chatbots und Datenanalyseplattformen. Die Ingenieure entwerfen Modellpipelines, optimieren die Infrastruktur und strukturieren die Bereitstellung so, dass die Systeme ohne unnötige Rechenkosten skalieren.
Möchten Sie die Kosten für Ihr LLM-Studium senken?
Sprechen Sie mit einer KI, die überlegen ist gegenüber:
- Entwurf von LLM-Pipelines und Backend-Architektur
- Entwicklung von NLP-Systemen und KI-gestützten Anwendungen
- Modelle in bestehende Software einbinden und integrieren
👉 Fordern Sie eine KI-Beratung an mit AI Superior um Ihr LLM-Projekt zu besprechen.
Aktuelle Preislandschaft für LLM-Studiengänge im Jahr 2026
Um Kostenoptimierung zu verstehen, muss man die aktuellen Preise kennen. OpenAI kündigte für Juni 2025 deutliche Preissenkungen für sein o3-Modell an – eine Senkung um 801 TP3T gegenüber den vorherigen Preisen.
Die neue o3-Preisstruktur:
- Eingabe-Token: $2 pro 1 Million Token
- Ausgabetoken: $8 pro 1 Million Token
Laut Untersuchungen zu Mixture-of-Experts-Architekturen berechnete GPT-4.5 $150 für die Generierung von 1 Million Token, was für viele Anwendungen unerschwinglich war. Die drastische Preissenkung bei neueren Modellen verändert die Kosten-Nutzen-Rechnung für Optimierungstechniken.
Allerdings können selbst bei niedrigeren Kosten pro Token ineffiziente asynchrone Muster im großen Maßstab immer noch erhebliche Kosten verursachen. Eine Million unnötiger API-Aufrufe zu $2 pro Million eingegebener Token bedeuten immer noch verschwendete $2.000.
Erweiterte asynchrone Muster für die LLM-Kostenkontrolle
Über die Grundlagen hinaus bieten verschiedene fortgeschrittene asynchrone Muster zusätzliche Möglichkeiten zur Kostenoptimierung.
Asynchrones KV-Cache-Prefetching
Untersuchungen zur Beschleunigung des Inferenzdurchsatzes von LLMs durch asynchrones KV-Cache-Prefetching zeigen signifikante Leistungssteigerungen. Auf NVIDIA H20-GPUs erreicht diese Methode eine bis zu 1,97-fache Beschleunigung der End-to-End-Inferenz bei gängigen Open-Source-LLMs.
Bei dieser Technik geht es zwar primär um die Reduzierung der Latenz und weniger um direkte Kosteneinsparungen, aber eine schnellere Inferenz bedeutet einen höheren Durchsatz pro GPU – wodurch die Infrastrukturkosten pro Anfrage sinken.
Asynchrones RLHF-Training
Für Organisationen, die benutzerdefinierte Modelle trainieren, bietet asynchrones RLHF (Reinforcement Learning from Human Feedback) Vorteile hinsichtlich der Recheneffizienz. Studien belegen, dass asynchrone RLHF-Ansätze Modelle etwa 40¹³T schneller trainieren können als herkömmliche synchrone Methoden.
Die Kosteneinsparungen ergeben sich aus kürzeren Trainingszeiten und einer effizienteren GPU-Auslastung. Asynchrone Trainingsframeworks wie AsyncFlow erzielen im großen Maßstab eine 1,76- bis 1,82-fache Steigerung des Durchsatzes gegenüber herkömmlichen Implementierungen.
Streaming-Antworten mit vorzeitigem Abbruch
Streaming-API-Antworten ermöglichen ein weiteres Kostenoptimierungsmuster: die vorzeitige Beendigung basierend auf der Antwortqualität.
Anstatt auf die vollständige Antwort zu warten, können Anwendungen die gestreamten Token in Echtzeit auswerten und die Anfrage abbrechen, falls die Ausgabe die Qualitätskriterien nicht erfüllt. Dadurch wird die Verschwendung von Token für Antworten vermieden, die ohnehin verworfen werden.
| async def stream_with_quality_check(prompt): stream = await client.chat.completions.create( model=”gpt-4″, messages=[{“role”: “user”, “content”: prompt}], stream=True ) akkumuliert = “” async for chunk in stream: accumulated += chunk.choices[0].delta.content or “” if should_terminate_early(accumulated): await stream.aclose() return None aufgelaufene Rendite |
Entscheidend ist die Definition geeigneter Qualitätskontrollen, die schnell genug ablaufen, um einen Mehrwert zu bieten – die Überprüfung auf verbotene Inhalte, themenfremde Antworten oder Formatverstöße.
Messung und Überwachung der Kosteneffizienz asynchroner Prozesse
Optimierung ohne Messung ist reine Spekulation. Effektive Kostenkontrolle erfordert die Erfassung der richtigen Kennzahlen.
Wichtige zu überwachende Kennzahlen
| Metrisch | Was es offenbart | Ziel
|
|---|---|---|
| Tokens pro Anfrage | Schnelle Effizienz und kurze Reaktionszeiten | Minimieren ohne Qualitätsverlust |
| Cache-Trefferrate | Wie häufig zwischengespeicherte Inhalte wiederverwendet werden | Über 70% für wiederkehrende Arbeitslasten |
| Fehlerrate der Anfragen | Kosten für Wiederholungsversuche aufgrund von Fehlern und Drosselung | Unterhalb von 2% |
| Vorzeitige Beendigungsrate | Wie oft werden Anfragen vor Abschluss abgebrochen? | Vergleich mit den Kosteneinsparungen |
| Anzahl gleichzeitiger Anfragen | Belastung der Providerinfrastruktur | Semaphorgrenzen anpassen |
| Kosten pro erfolgreichem Ergebnis | Tatsächliche Kosten einschließlich Fehlschläge und Wiederholungsversuche | Primäres Optimierungsziel |
Implementierung der Kostenverfolgung
Die meisten LLM-Anbieter bieten Nutzungs-Dashboards an, diese zeigen jedoch in der Regel aggregierte Daten. Für eine detaillierte Optimierung sollten Sie die Erfassung von Anfragen auf Anfrageebene in Ihrer Anwendung implementieren.
Laut Diskussionen in der Community über die API-Nutzung lassen sich durch die nach Einzelposten gruppierte Anzeige der Gebühren wichtige Muster erkennen. Einige Entwickler entdeckten unerklärliche Schwankungen im Token-Verbrauch, die erst durch detailliertes Tracking sichtbar wurden.
Umschließen Sie Ihre API-Aufrufe mit Instrumentierung, die protokolliert:
- Zeitstempel und Latenz der Anfrage
- Anzahl der Eingabe- und Ausgabetoken
- Cache-Treffer-/Fehlstatus
- Fehlertypen und Wiederholungsversuche
- Tatsächliche Kosten basierend auf der aktuellen Preisgestaltung
Mithilfe dieser Daten lassen sich Kostenanomalien erkennen, bevor sie zu Budgetproblemen werden.
Umsetzung in der Praxis: Ein schrittweiser Ansatz
Okay, wie setzt man diese Kostenoptimierungen nun konkret in einer realen Anwendung um?
Beginnen Sie mit einer Überprüfung der aktuellen asynchronen Muster. Achten Sie auf folgende Warnsignale:
- List Comprehensions erstellen alle Aufgaben vor allen await-Anweisungen.
- asyncio.gather()-Aufrufe ohne Beschränkungen der Parallelität
- Keine Konfiguration für promptes Caching trotz sich wiederholender Inhalte
- Synchrone Batch-Jobs, die auf Batch-APIs migriert werden könnten
- Fehlende Fehlerbehandlung, die teure Wiederholungsversuche verursacht
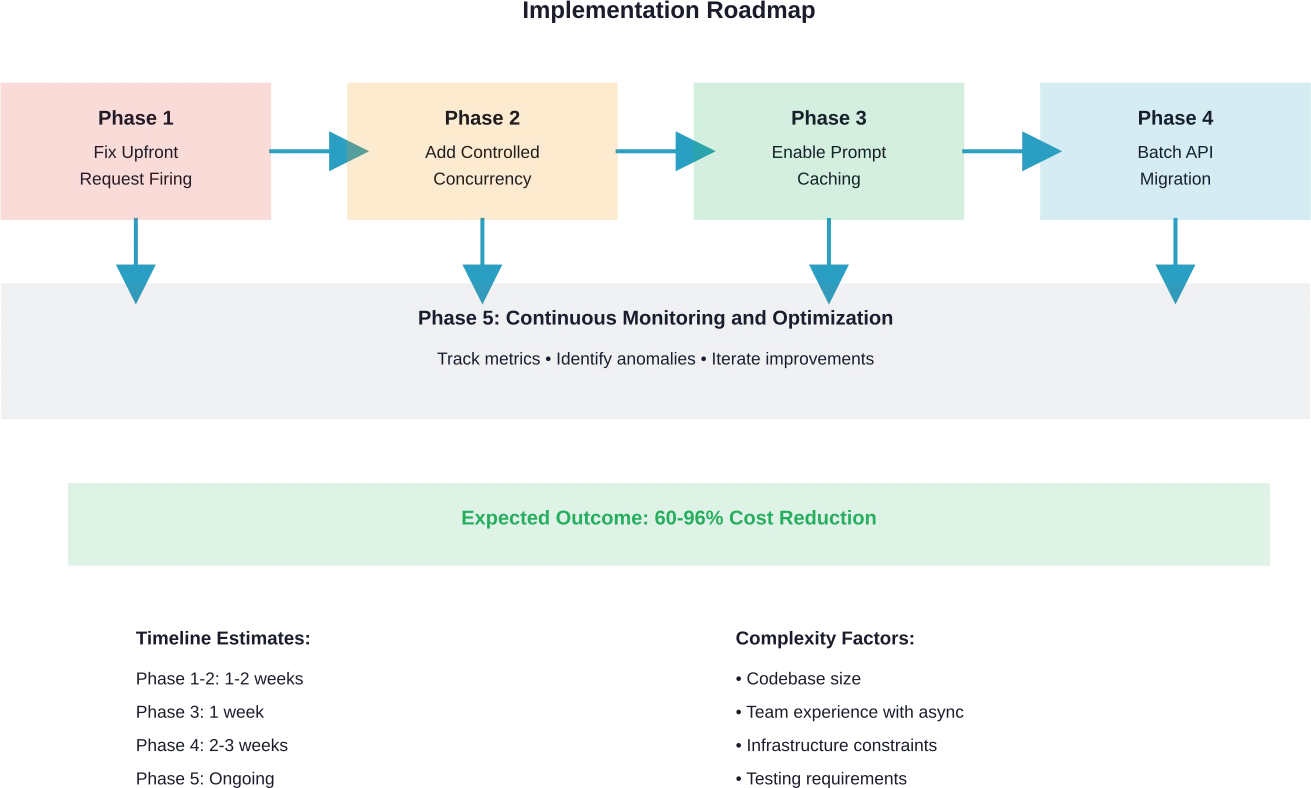
Phase 1: Behebung des Problems mit der Auslösung der Vorabanfrage
Identifizieren Sie Funktionen, die alle Aufgaben vor Beginn der Verarbeitung erstellen. Refactoring zur verzögerten Aufgabenerstellung:
| # Vorher: Alle Aufgaben wurden im Voraus erstellt async def process_items(items): tasks = [process_item(item) for item in items] für Aufgabe in Aufgaben: Ergebnis = Aufgabe erwarten if not validate(result): return False # Nachher: Aufgaben nach Bedarf erstellt async def process_items(items): für Artikel in Artikeln: Ergebnis = await process_item(item) if not validate(result): return False |
Durch diese eine Änderung können 50-90% unnötige Anfragen in Workflows mit vorzeitiger Beendigungslogik eliminiert werden.
Phase 2: Kontrollierte Parallelität hinzufügen
Implementieren Sie Semaphore, um Probleme mit Ratenbegrenzungen zu vermeiden:
| Klasse LLMClient: def __init__(self, max_concurrent=5): self.semaphore = asyncio.Semaphore(max_concurrent) self.client = OpenAI() async def call(self, prompt): async with self.semaphore: return await self.client.chat.completions.create( model=”gpt-4″, messages=[{“role”: “user”, “content”: prompt}] ) |
Phase 3: Aktivierung des Prompt-Cachings
Strukturieren Sie die Eingabeaufforderungen, um die Cache-Wiederverwendung zu maximieren. Platzieren Sie statische Inhalte am Anfang und kennzeichnen Sie diese gemäß der API Ihres Anbieters als cachefähig.
Phase 4: Geeignete Arbeitslasten in die Stapelverarbeitung verlagern
Prüfen Sie, welche Arbeitsabläufe verzögerte Antworten tolerieren können. Datenverarbeitung, Inhaltsgenerierung und Auswertungspipelines sind hierfür ideale Kandidaten.
Phase 5: Überwachung implementieren
Ergänzen Sie die Kostenverfolgung, um die Auswirkungen von Optimierungen zu messen und neue Möglichkeiten zu identifizieren.
Häufige Fehler und wie man sie vermeidet
Selbst bei besten Absichten kann die asynchrone Kostenoptimierung schiefgehen. Hier sind die häufigsten Fallstricke.
Überoptimierung auf Kosten der Latenz
Eine zu aggressive Reduzierung der Parallelität behebt zwar Probleme mit der Ratenbegrenzung, erhöht aber die Gesamtausführungszeit drastisch. Ein Semaphorlimit von 1 könnte die Drosselung zwar verhindern, führt aber auch dazu, dass alle Anfragen serialisiert werden.
Ermitteln Sie den optimalen Punkt durch Tests. Beginnen Sie mit konservativen Grenzwerten und erhöhen Sie diese schrittweise, während Sie die Fehlerraten überwachen.
Verwirrung um Cache-Invalidierung
Schnelles Caching funktioniert einwandfrei, solange die zwischengespeicherten Inhalte aktuell bleiben. Anwendungen, die Referenzdokumente oder Systemanweisungen aktualisieren, benötigen Strategien zur Cache-Invalidierung.
Die meisten Anbieter regeln dies automatisch über eine zeitbasierte Ablaufzeit, aber beachten Sie den Zeitraum. Wenn sich wichtige Inhalte ändern, kann eine Wartezeit von 10 Minuten bis zum Ablauf des Caches inakzeptabel sein.
Kosten für fehlgeschlagene Anfragen ignorieren
Viele asynchrone Implementierungen konzentrieren sich auf erfolgreiche Anfragen und ignorieren dabei die Kosten von Fehlern. Fehler aufgrund von Ratenbegrenzungen, Timeouts und Validierungsfehlern führen häufig zu Wiederholungsversuchen, die die Kosten vervielfachen.
Fehlgeschlagene Anfragen werden separat verfolgt und ein exponentieller Backoff mit maximalen Wiederholungslimits implementiert.
Vorzeitige Migration der Batch-API
Die Verlagerung von Arbeitslasten auf Stapelverarbeitung, bevor deren Latenzanforderungen geklärt sind, führt zu Problemen mit der Benutzerfreundlichkeit. Nicht alle “nicht kritischen” Arbeitslasten tolerieren Verzögerungen von 24 Stunden.
Beginnen Sie mit wirklich asynchronen Arbeitslasten, wie z. B. der Verarbeitung von Datensätzen über Nacht, bevor Sie irgendetwas mit Benutzerinteraktionen anfassen.
Häufig gestellte Fragen
Wie stark lassen sich die LLM-Kosten durch asynchrone Optimierung realistisch senken?
Die Kostenreduzierung hängt stark von den aktuellen Implementierungsmustern ab. Anwendungen mit vorab ausgelösten Anfragen und einer Logik zur frühzeitigen Beendigung können Einsparungen von 60 bis 901 TP3T erzielen. Anwendungen, die bereits effiziente asynchrone Muster nutzen, können allein durch Caching und Batchverarbeitung Einsparungen von 20 bis 401 TP3T erreichen. Entscheidend ist es, unnötige Anfragen im aktuellen Workflow zu identifizieren.
Funktioniert Prompt-Caching mit allen LLM-Anbietern?
Die meisten großen Anbieter bieten mittlerweile schnelles Caching oder ähnliche Funktionen an, die Implementierungsdetails variieren jedoch. Die genauen Anforderungen hinsichtlich minimaler Cache-Größen, Cache-Dauer und Preisstrukturen finden Sie in der Anbieterdokumentation. Einige Anbieter cachen automatisch, während andere eine explizite Konfiguration erfordern.
Welches Limit für gleichzeitige Operationen sollte ich bei Semaphoren verwenden?
Beginnen Sie mit 5–10 gleichzeitigen Anfragen und überwachen Sie die Fehler aufgrund von Ratenbegrenzungen. Bei anhaltender Drosselung reduzieren Sie das Limit. Sind die Fehlerraten niedrig und die Latenz akzeptabel, erhöhen Sie es schrittweise. Das optimale Limit hängt von den Ratenbegrenzungen Ihres Anbieters, der Größe der Anfragen und den Latenzanforderungen Ihrer Anwendung ab. Laut Community-Diskussionen funktionieren Limits zwischen 5 und 10 für die meisten Anwendungen gut.
Kann ich Streaming-Antworten mit Prompt-Caching kombinieren?
Ja, Streaming und Caching ergänzen sich. Zwischengespeicherte Eingabeaufforderungsinhalte reduzieren die Anzahl der zu verarbeitenden Tokens, während Streaming einen frühzeitigen Zugriff auf Ergebnisse ermöglicht und eine vorzeitige Beendigung erlaubt. Diese Kombination bietet sowohl Kosten- als auch Latenzvorteile.
Wie kann ich messen, ob Optimierungen tatsächlich Kosten sparen?
Implementieren Sie eine Kostenverfolgung auf Anfrageebene, die Token-Zähler protokolliert und die Kosten anhand der aktuellen Preise berechnet. Vergleichen Sie die Kosten vor und nach Optimierungsmaßnahmen über vergleichbare Workload-Zeiträume. Laut Empfehlungen der Community zeigt die nach Einzelposten gruppierte Nutzung in den Dashboards der Anbieter detaillierte Kostenmuster, die in aggregierten Ansichten nicht sichtbar sind.
Sollte ich zuerst die Kosten oder die Latenz optimieren?
Dies hängt von den Anwendungsanforderungen ab. Benutzerorientierte Funktionen priorisieren typischerweise geringe Latenzzeiten bei gleichzeitig akzeptablen Kosten. Hintergrundprozesse können höhere Latenzzeiten tolerieren, um Kosten zu sparen. Beginnen Sie damit, unnötige Anfragen zu eliminieren, die unabhängig von ihrer Geschwindigkeit keinen Mehrwert bieten. Wägen Sie anschließend Kosten und Latenzzeiten anhand spezifischer Anwendungsfälle ab.
Was passiert mit laufenden Anfragen, wenn meine Anwendung abstürzt?
Asynchrone Anfragen an LLM-Anbieter werden auch nach Beendigung Ihrer Anwendung weiterverarbeitet. Der Anbieter berechnet weiterhin die Kosten für abgeschlossene Anfragen. Implementieren Sie geeignete Shutdown-Handler, die ausstehende Anfragen abbrechen und asynchrone Ereignisschleifen sauber schließen, um zu verhindern, dass verwaiste Anfragen Gebühren verursachen, ohne Ergebnisse zu liefern.
Schlussbetrachtung: Wie Sie asynchrone Prozesse budgetschonend nutzen können
Asynchrone Programmierung ist nicht per se gut oder schlecht für die LLM-Kosten – es ist ein Werkzeug, das eine sorgfältige Implementierung erfordert.
Die Muster, die die Codeausführung beschleunigen, können auch die Kosten schneller in die Höhe treiben, wenn unnötige Anfragen gestellt werden. Korrekt implementiert ermöglicht asynchroner Code jedoch Kostenoptimierungsstrategien, die synchroner Code schlichtweg nicht bieten kann.
Beginnen Sie mit einer ehrlichen Überprüfung Ihrer aktuellen asynchronen Verarbeitungsmuster. Achten Sie auf die Erstellung von Aufgaben im Voraus, unkontrollierte Parallelverarbeitung und verpasste Caching-Möglichkeiten. Beheben Sie zuerst die größten Probleme – in der Regel die frühzeitige Ausführung von Anfragen in Workflows mit vorzeitigem Abbruch.
Dann folgen weitere Optimierungen: Prompt-Caching für wiederkehrende Inhalte, Stapelverarbeitung für nicht dringende Arbeitslasten, Streaming mit Qualitätsprüfungen für Echtzeitfunktionen.
Und ganz entscheidend: Messen Sie alles. Verfolgen Sie Tokens, Kosten, Latenz und Fehlerraten auf Anfrageebene. Die Daten decken Optimierungspotenziale auf, die bei einer reinen Codeanalyse nicht erkennbar sind.
Die Kostenlandschaft für LLM entwickelt sich stetig weiter. Die Preissenkung von OpenAI für o3-Modelle im Rahmen des 80%-Programms im Juni 2025 hat die Wirtschaftlichkeit deutlich verändert. Doch selbst bei niedrigeren Kosten pro Token ist Effizienz im großen Maßstab entscheidend.
Bereit, Ihre LLM-Kosten zu senken? Beginnen Sie noch heute mit der Überprüfung Ihrer asynchronen Implementierungsmuster. Die fünfzeiligen Korrekturen, die unnötige Anfragen eliminieren, erzielen oft die größte Wirkung bei minimalem Aufwand.