Kurzzusammenfassung: Das Training eines LLM von Grund auf kostet zwischen 1,4 Billionen Tsd. 78 und 1,4 Billionen Tsd. für Spitzenmodelle wie GPT-4 und Gemini Ultra 1.0. Diese Kosten werden durch massive GPU-Cluster, Strom, Datenerfassung und qualifizierte Ingenieure verursacht. Kleinere Modelle lassen sich mithilfe von Cloud-Infrastruktur für 1,4 Billionen Tsd. 50.000 bis 1,4 Billionen Tsd. ...
Große Sprachmodelle haben unsere Interaktion mit Technologie grundlegend verändert. Doch was die meisten Menschen nicht wissen: Die Kosten für die Erstellung dieser Modelle sind astronomisch.
Laut dem Stanford AI Index Report 2025 sind die Trainingskosten für fortschrittliche KI-Modelle drastisch gestiegen. Das Training von GPT-4 belief sich auf etwa 1,4 Billionen US-Dollar ($78 bis $100 Millionen US-Dollar). Die Trainingskosten für Gemini Ultra werden dem Stanford AI Index Report 2024 zufolge auf rund 1,4 Billionen US-Dollar ($191 Millionen US-Dollar) geschätzt. Dies entspricht einer Steigerung um das 287.000-Fache gegenüber den Trainingskosten eines Transformer-Modells im Jahr 2017, die lediglich 1,4 Billionen US-Dollar ($670 US-Dollar) betrugen.
Was verursacht also diese enormen Ausgaben? Und noch wichtiger: Was kostet es tatsächlich, wenn man ein eigenes Modell von Grund auf trainiert?
Aufschlüsselung der tatsächlichen Kosten der LLM-Ausbildung
Das Training eines großen Sprachmodells von Grund auf ist nicht nur teuer – es ist ein mehrdimensionales finanzielles Engagement, das Hardware, Energie, Daten und Humankapital umfasst.
Recheninfrastruktur: Der größte Kostenpunkt
Die Rechenkosten dominieren alles andere. Hochleistungs-GPUs wie die NVIDIA H100 können 14.000 US-Dollar pro Stück kosten. Aber das ist erst der Anfang.
Zum besseren Verständnis: Das Training von Spitzenmodellen erfordert Tausende von GPUs, die wochen- oder monatelang kontinuierlich laufen. Untersuchungen von arXiv zur Wirtschaftlichkeit von GPUs ergaben, dass eine A800 80G GPU stündliche Basiskosten von etwa $0,79 verursacht, wobei die typischen Kosten je nach Konfiguration und Cloud-Plattform zwischen $0,51 und $0,99 pro Stunde liegen.
Berichten zufolge investierte OpenAI über 1,4 Billionen US-Dollar in das Training von GPT-4, wobei ein erheblicher Teil auf Cloud-Computing-Kosten entfiel. Das Ausmaß ist kaum vorstellbar.
| Modell | Geschätzte Schulungskosten | Quelle |
|---|---|---|
| GPT-4 | $78M-$100M+ | Wall Street Journal, Stanford AI Index 2025 |
| Gemini Ultra 1.0 | $191M | Stanford AI Index Report 2024 |
| GPT-4o | ~$100M | Branchenschätzungen |
| Transformer (2017) | $670 | Stanford AI Index Report 2025 |
Energieverbrauch und Umweltkosten
Der Dauerbetrieb Tausender GPUs verbraucht enorme Mengen an Strom. Eine im Jahr 2025 bei Springer veröffentlichte Studie zur Energieeffizienz großer Sprachmodelle zeigt, dass die Dynamik des Energieverbrauchs direkt mit der Modellgröße und der Batch-Konfiguration korreliert.
Die Umweltauswirkungen reichen weit über die Trainingsphase hinaus. Mit steigendem Rechenaufwand wachsen auch die Bedenken hinsichtlich Nachhaltigkeit und CO₂-Fußabdruck.
Datenerfassung und -aufbereitung
Ein Aspekt, der zu wenig Beachtung findet: Die menschliche Arbeitsleistung bei der Erstellung von Trainingsdaten wird deutlich unterschätzt. Ein Positionspapier, das im April 2025 auf Hugging Face veröffentlicht wurde, argumentiert, dass die Kosten der Datenproduktion mindestens so hoch sein sollten wie die Rechenkosten des Trainings.
Qualitativ hochwertige Datensätze entstehen nicht aus dem Nichts. Sie erfordern Folgendes:
- Datenerfassungs- und Lizenzgebühren
- Manuelle Reinigung und Annotation
- Einhaltung des Urheberrechts und rechtliche Prüfung
- Laufende Aktualisierungen und Wartung
Der Artikel liefert überzeugende Argumente dafür, dass Trainingsdaten den teuersten – und am meisten unterbezahlten – Teil der LLM-Entwicklung darstellen.
Ingenieurtalent und Betriebskosten
Der Aufbau eines LLM-Studiums erfordert spezialisierte Expertise. Fachkräfte wie Machine-Learning-Ingenieure, Data Scientists, Infrastrukturspezialisten und Forschungswissenschaftler sind nicht billig. Die Gehälter für diese Positionen liegen in großen Technologiezentren typischerweise zwischen 150.000 und über 500.000 US-Dollar jährlich.
Neben den Gehältern fallen auch operative Gemeinkosten an: Projektmanagement, Nachverfolgung von Experimenten, Versionierung von Modellen, Sicherheits- und Compliance-Infrastruktur.
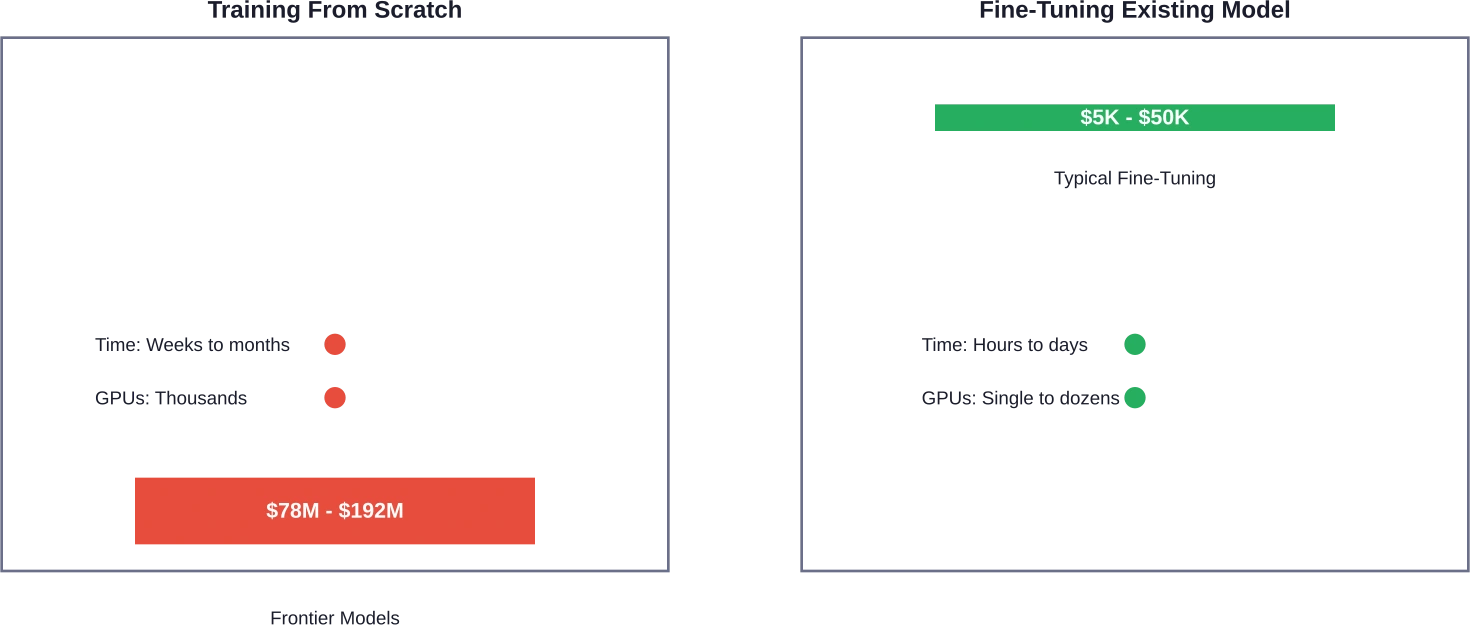
Schulung von Grund auf vs. Feinabstimmung: Ein Kostenvergleich
Nicht jeder muss GPT-5 selbst entwickeln. Die Entscheidung zwischen dem Training von Grund auf und der Feinabstimmung eines bestehenden Modells kann Unternehmen 60 bis 901 Tsd. Billionen ihres KI-Budgets einsparen.
Wann ein Training von Grund auf sinnvoll ist
Eine vollständige Vorbereitung von Grund auf ist in der Regel sinnvoll, wenn:
- Ihre Domäne erfordert grundlegend andere Sprachmuster als allgemeine Modelle.
- Datenschutzbestimmungen verbieten die Verwendung kommerzieller Modelle
- Sie benötigen die vollständige Kontrolle über die Modellarchitektur und das Verhalten.
- Ihre Organisation verfügt über das Budget und die Expertise, um die langfristige Modellentwicklung zu unterstützen.
Die Feinabstimmungsalternative
Beim Feinabstimmungsverfahren wird ein vortrainiertes Modell an spezifische Aufgaben oder Anwendungsbereiche angepasst. Der Kostenunterschied ist erheblich. Während das Training von GPT-4 von Grund auf fast 100 Millionen US-Dollar kostete, könnten die Kosten für die Feinabstimmung für spezialisierte Anwendungen zwischen 5.000 und 50.000 US-Dollar liegen.
Forschungen der Universidad Nacional de Colombia demonstrierten effiziente Feinabstimmungsstrategien mithilfe von LoRA (Low-Rank Adaptation). Ihre Experimente zeigten, dass ein mit 8 Bit quantisiertes Basismodell auf einer einzelnen NVIDIA T4 GPU mit 16 GB VRAM in etwa 7 Stunden feinabgestimmt werden konnte – Hardware, deren Kosten auf gängigen Cloud-Plattformen etwa 10⁴T²⁻⁴ pro Stunde betragen.
Budgetfreundliches Training: Geht das für unter 100.000 Euro?
Die Antwort lautet ja, allerdings mit erheblichen Kompromissen hinsichtlich Modellgröße und Leistungsfähigkeit.
Ein auf arXiv veröffentlichter Artikel mit dem Titel “FLM-101B: Ein offenes LLM-Programm und wie man es mit einem Budget von $100K durchführt” zeigte, dass kleinere LLM-Schulungen mit sorgfältigem Ressourcenmanagement realisierbar sind. Zu den wichtigsten Strategien gehören:
- Verwendung kleinerer Modellarchitekturen (1-20 Milliarden Parameter statt über 175 Milliarden)
- Nutzung von Open-Source-Frameworks und bestehenden Codebasen
- Optimierung der Trainingsläufe durch effiziente Hyperparameter-Auswahl
- Verwendung von Trainings- und Quantisierungstechniken mit gemischter Präzision
Eine Studie des Fraunhofer-Instituts verglich drei Optimierungsverfahren – AdamW, Lion und eine dritte Variante – für das kostengünstige Vortraining von LLMs. Die Experimente nutzten zwei Clusterknoten mit mehreren GPUs und zeigten, dass die Wahl des Optimierungsverfahrens sowohl die Trainingszeit als auch die endgültige Modellleistung signifikant beeinflusst.
Die offene Gewichtsalternative
Die Veröffentlichung von gpt-oss-120b und gpt-oss-20b durch OpenAI im August 2025 revolutionierte die Branche. Diese unter der Apache-2.0-Lizenz veröffentlichten Openweight-Modelle liefern starke Ergebnisse in realen Anwendungen zu deutlich geringeren Kosten als das Training von Grund auf.
Organisationen können diese Modelle jetzt herunterladen und für spezifische Anwendungsfälle feinabstimmen, wodurch die enormen anfänglichen Schulungskosten vollständig umgangen werden.
Cloud vs. On-Premise: Was ist langfristig kostengünstiger?
Forscher der Carnegie Mellon University veröffentlichten eine Kosten-Nutzen-Analyse, die untersuchte, wann sich der Einsatz von LLM vor Ort im Vergleich zu kommerziellen Cloud-Diensten rechnet. Ihre Ergebnisse stellen gängige Annahmen in Frage.
Kosten der Cloud-Infrastruktur
Cloud-Plattformen bieten Flexibilität, verlangen aber hohe Gebühren für GPU-Zeit. Große Anbieter berechnen in der Regel:
- $2-8 pro Stunde für Hochleistungs-GPU-Instanzen
- Gebühren für die Datenübertragung (oft übersehen, aber bei großem Umfang beträchtlich)
- Speicherkosten für Modell-Checkpoints und Trainingsdaten
- API-Aufrufgebühren bei Nutzung von Managed Services
Der Vorteil? Keine anfänglichen Investitionskosten und die Möglichkeit, nach Bedarf zu skalieren.
Investitionen in die Infrastruktur vor Ort
Der Kauf von Hardware erfordert zwar erhebliches Kapital, eliminiert aber laufende Cloud-Kosten. Ein Cluster aus NVIDIA H100-GPUs kostet zwar zunächst 1,4 Billionen bis 1,4 Billionen PKR, diese Investition amortisiert sich jedoch über 3–5 Jahre.
Die Analyse der Carnegie Mellon University ergab, dass Unternehmen mit nachhaltigen, vorhersehbaren KI-Workloads oft schon nach 12 bis 18 Monaten die Gewinnschwelle erreichen, wenn sie sich für eine On-Premise-Lösung anstelle von Cloud-Diensten entscheiden.
Doch es gibt einen Haken: Die Infrastruktur vor Ort erfordert eigenes Personal für Wartung, Kühlsysteme, Stromversorgung und Sicherheit – Kosten, die in vielen Budgetanalysen außer Acht gelassen werden.
Was treibt die Kosten für eine LLM-Ausbildung in die Höhe?
Mehrere Faktoren entscheiden darüber, ob Ihr Trainingsbudget eher bei $50.000 oder bei $50 Millionen liegt.
Modellgröße und Architektur
Der Zusammenhang zwischen Parametern und Kosten ist nicht linear, sondern exponentiell. Eine Verdopplung der Modellgröße führt zu mehr als einer Verdopplung der Trainingskosten, und zwar aus folgenden Gründen:
- Erhöhter Speicherbedarf erzwingt Multi-GPU-Parallelität
- Längere Trainingszeiten, da die Konvergenz mit zunehmender Größe langsamer wird.
- Größere Datenanforderungen für das ordnungsgemäße Training größerer Architekturen
Trainingsdauer und Konvergenz
Trainingsläufe, die nicht konvergieren, verschwenden enorme Ressourcen. Eine effiziente Hyperparameter-Optimierung kann die Lerngeschwindigkeit eines Modells dramatisch beeinflussen. Ein gut optimierter Trainingslauf kann die Zielgenauigkeit in der Hälfte der Zeit eines schlecht konfigurierten Laufs erreichen.
Hier zahlt sich Fachwissen aus. Ingenieure, die Lernratenpläne, Batchgrößenoptimierung und Regularisierungstechniken verstehen, ersparen Unternehmen Millionen an verschwendeter Rechenleistung.
Datenqualität und -quantität
Das Training mit minderwertigen Daten führt zu minderwertigen Modellen – doch die Beschaffung hochwertiger Daten kostet Geld. Manche Organisationen investieren mehr in die Datenaufbereitung als in die Recheninfrastruktur.
Der sich abzeichnende Konsens, der im Positionspapier von Hugging Face zur Ökonomie von Trainingsdaten formuliert wurde, besagt, dass Daten der teuerste Bestandteil der LLM-Entwicklung sein sollten. Derzeit werden sie unterbewertet.
Versteckte Kosten jenseits der Schulung
Hier scheitern viele Budgetprognosen: Die Ausbildungskosten sind nur der Anfang.
Inferenzinfrastruktur
Das WiNGPT-Team stellte ein Rahmenwerk zur “Ökonomie der Inferenz” vor, das die LLM-Inferenz als rechenintensive Produktionsaktivität betrachtet. Ihre Analyse ergab, dass die Inferenzkosten über die gesamte Betriebsdauer des Modells häufig die Trainingskosten übersteigen.
Jede an Ihr Modell gesendete Anfrage verbraucht Rechenressourcen. Im großen Maßstab können die Kosten für die Inferenzinfrastruktur Hunderttausende pro Monat betragen.
Modellaktualisierungen und Nachschulung
Sprache entwickelt sich weiter. Fakten ändern sich. Geschäftsanforderungen verschieben sich. Modelle, die im Jahr 2024 trainiert wurden, sind im Jahr 2026 bereits veraltet.
Regelmäßige Weiterbildungsmaßnahmen oder kontinuierliche Lernprogramme stellen laufende Kosten dar, die viele Organisationen bei der anfänglichen Planung unterschätzen.
Speicherung und Datenverwaltung
Modell-Checkpoints, Trainingsdatensätze, Experimentprotokolle und Versionierungssysteme belegen Speicherplatz. Bei hochmodernen Modellen sprechen wir von Petabytes an Daten. Die Speicherkosten summieren sich unbemerkt, aber beträchtlich.
Überwachung und Wartung
Produktionsfähige ML-Systeme erfordern eine ständige Überwachung auf:
- Leistungsverschlechterung
- Erkennung und Minderung von Verzerrungen
- Sicherheitslücken
- API-Zuverlässigkeit und Verfügbarkeit
Diese Betriebskosten bleiben so lange bestehen, wie das Modell produziert wird.
| Kostenkategorie | Einmalig | Wiederkehrend | Typischer Bereich |
|---|---|---|---|
| Grundausbildung | ✓ | $50K – $192M | |
| Inferenzinfrastruktur | ✓ | $10K – $500K/Monat | |
| Modell-Neutraining | ✓ | 20-50% der anfänglichen Kosten/Jahr | |
| Lagerung | ✓ | $5K – $50K/Monat | |
| Ingenieurteam | ✓ | $500K – $5M/Jahr | |
| Datenerfassung | ✓ | ✓ | $100K – $10M+ |
Strategien zur Senkung der LLM-Ausbildungskosten
Intelligente Unternehmen setzen verschiedene Strategien ein, um die Kosten unter Kontrolle zu halten, ohne die Leistungsfähigkeit des Geschäftsmodells zu beeinträchtigen.
Transferlernen und progressives Training
Statt bei Null anzufangen, sollte man mit einem bestehenden Modell für offene Gewichtsklassen beginnen und es schrittweise anpassen. Dieser Ansatz, der in einer Studie der Universidad Nacional de Colombia dokumentiert ist, reduziert die Trainingszeit um 80–90 % (TP3T).
Effiziente Optimierungstechniken
Die Forschung des Fraunhofer-Instituts, die AdamW, Lion und alternative Optimierer verglich, zeigte, dass die Wahl des Optimierers sowohl die Trainingsgeschwindigkeit als auch den Ressourcenverbrauch maßgeblich beeinflusst. Die Wahl des richtigen Optimierers für Ihren spezifischen Anwendungsfall kann die Trainingskosten um 20 bis 301 TP3T senken.
Quantisierung und Kompression
Das Training mit gemischter Präzision (Kombination von 16-Bit- und 32-Bit-Gleitkommaoperationen) reduziert den Speicherverbrauch und beschleunigt die Berechnung. Die Quantisierung nach dem Training auf 8-Bit- oder sogar 4-Bit-Darstellungen verringert die Modellgröße für den Einsatz ohne gravierende Leistungseinbußen.
Die Experimente der Universidad Nacional de Colombia zeigten ein erfolgreiches LoRA-Training an Modellen, die auf 8 Bit quantisiert wurden, wobei vorquantisierte 4-Bit-Modelle eine akzeptable Leistung auf handelsüblicher Hardware aufwiesen.
Intelligente Ressourcenzuweisung
Durch die effiziente Nutzung und Verwaltung von Rechenressourcen lassen sich Kosten für Leerlaufzeiten vermeiden. Zu den Strategien gehören:
- Spot-Instance-Bieting auf Cloud-Plattformen für nicht kritische Trainingsläufe
- Pipeline-Parallelisierung zur Maximierung der GPU-Auslastung
- Gradientenakkumulation zur Simulation größerer Batchgrößen auf begrenzter Hardware
- Checkpoint-Neustartfunktionen zur Wiederherstellung nach Unterbrechungen
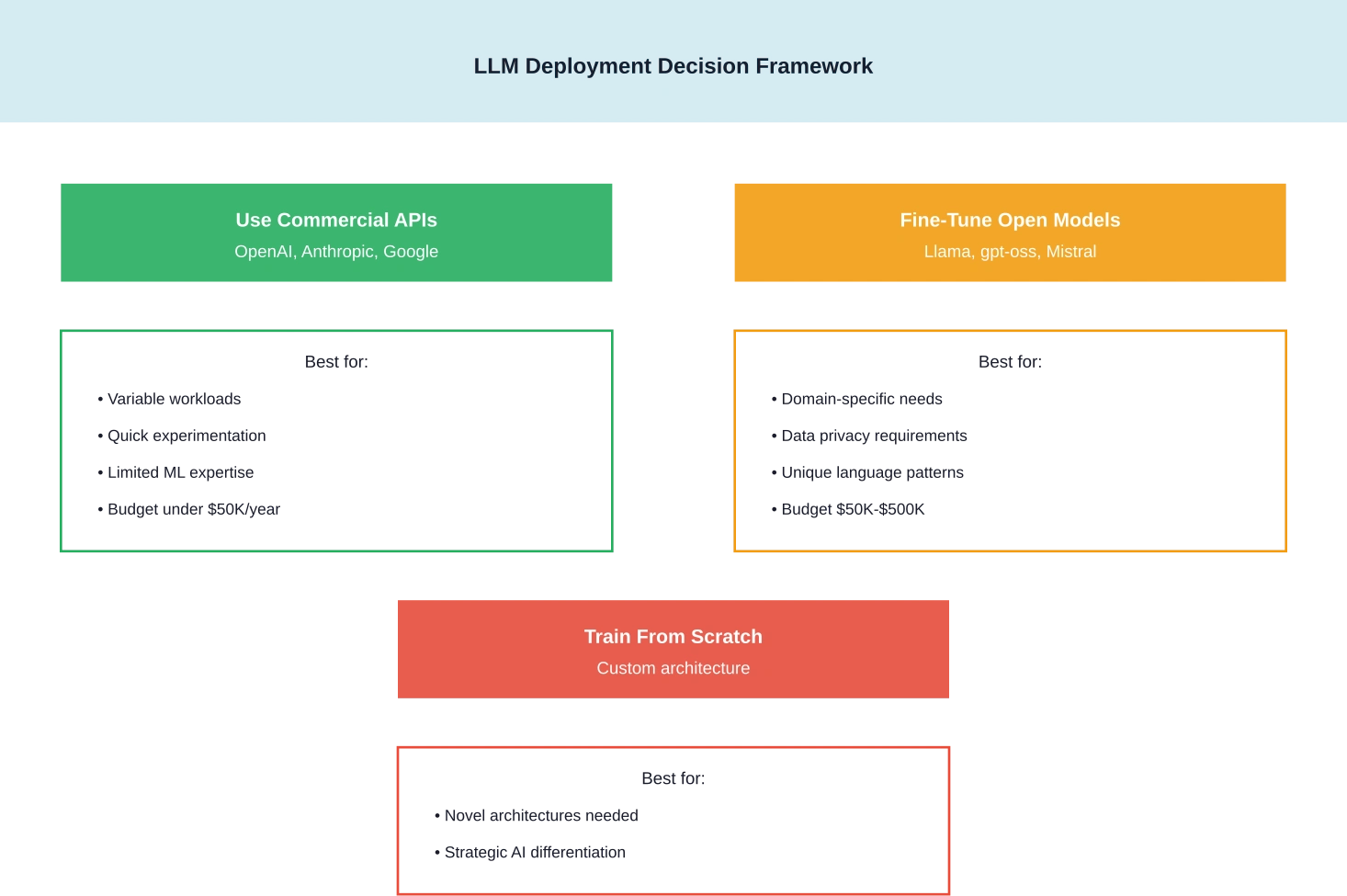
Sollten Sie 2026 Ihren eigenen LLM absolvieren?
Mit der zunehmenden Verbreitung leistungsfähiger Open-Weight-Modelle hat sich der Entscheidungsrahmen dramatisch verändert.
Für die meisten Organisationen lautet die Antwort nein – zumindest nicht von Grund auf. Die gpt-oss-Modelle von OpenAI, die Llama-3-Serie von Meta und andere Open-Wight-Alternativen bieten eine Leistung, deren Nachbildung zig Millionen kosten würde.
Aber Feinabstimmung? Das ist eine andere Geschichte. Organisationen mit einzigartigen Domänenanforderungen, spezifischen Compliance-Anforderungen oder proprietären Daten profitieren oft von der Feinabstimmung bestehender Modelle, anstatt sich ausschließlich auf allgemeine kommerzielle APIs zu verlassen.
Wann Schulungen vor Ort sinnvoll sind
Die Kosten-Nutzen-Analyse der Carnegie Mellon University identifizierte spezifische Szenarien, in denen sich die Implementierung und Schulung von LLM-Programmen vor Ort als wirtschaftlich rentabel erweisen:
- Dauerhafte Arbeitslasten von mehr als 10.000 GPU-Stunden pro Jahr
- Strenge Anforderungen an den Datenspeicherort verbieten die Nutzung der Cloud.
- Langfristige strategische KI-Initiativen mit einer Laufzeit von mehr als 3 Jahren
- Verfügbarkeit von internem ML-Infrastruktur-Know-how
Wenn Cloud-Dienste gewinnen
Für experimentelle Projekte, variable Arbeitslasten oder Organisationen ohne Expertise im Bereich ML-Infrastruktur bieten Cloud-basierte Lösungen und API-Dienste eine bessere Wirtschaftlichkeit. Die Flexibilität, die Ressourcen zu skalieren oder vollständig abzuschalten, eliminiert das Risiko von Fehlinvestitionen.

Reduzieren Sie die Kosten für Ihre LLM-Ausbildung, bevor Sie beginnen
Das Training eines LLM von Grund auf ist nicht nur wegen des Rechenaufwands teuer, sondern auch wegen der Datenaufbereitung, der Wahl der Modellarchitektur und der Trainingsstrategie. AI Superior arbeitet auf dieser technischen Ebene – unterstützt Unternehmen bei der Entwicklung kundenspezifischer LLMs, der Aufbereitung von Trainingsdatensätzen und der Optimierung von Trainingspipelines, damit Modelle von Anfang an effizient erstellt werden.
Wenn Sie die tatsächlichen Kosten einer LLM-Ausbildung im Jahr 2026 abschätzen möchten, ist es hilfreich, die technische Infrastruktur zu überprüfen, bevor Sie hohe IT-Budgets bereitstellen. Kontaktieren Sie uns. AI Superior um Ihre Trainingsarchitektur zu bewerten und festzustellen, wo Kosten reduziert werden können, noch bevor der Trainingsprozess überhaupt beginnt.
Die Zukunft der LLM-Ausbildungsökonomie
Mehrere Trends verändern die Kostenlandschaft.
Die Veröffentlichung von GPT-5.3-Codex durch OpenAI im Februar 2026 (angekündigt am 5. Februar 2026) zeigte eine um 25% höhere Effizienz als der Vorgänger. Mit der Verbesserung der Modellarchitekturen sinkt der Rechenaufwand für eine vergleichbare Leistung.
Auch die Hardwareentwicklung schreitet voran. Die aufeinanderfolgenden GPU-Generationen von NVIDIA bieten deutliche Verbesserungen der Leistung pro Watt und reduzieren so sowohl die Investitions- als auch die Betriebskosten.
Am wichtigsten ist jedoch wohl, dass die Demokratisierung des Zugangs durch offene Gewichtungsmodelle grundlegend verändert, wer an der Entwicklung von Lernmanagementsystemen teilhaben kann. Was 2023 noch 100 Millionen Studierende erforderte, könnte durch den geschickten Einsatz von Transferlernen und effizienten Trainingsmethoden 2026 bereits für 100.000 Studierende erreichbar sein.
Häufig gestellte Fragen
Wie viel kostet es, GPT-4 von Grund auf zu trainieren?
Laut dem Stanford AI Index Report 2024 und einem Bericht des Wall Street Journal belaufen sich die Trainingskosten für GPT-4 auf 1,4 Milliarden US-Dollar ($78 bis $100 Millionen US-Dollar). Darin enthalten sind Recheninfrastruktur, Energiekosten, Datenerfassung und Entwicklungsressourcen während des Trainingszeitraums. Die Trainingskosten für Gemini Ultra werden laut dem Stanford AI Index Report 2024 auf etwa 1,4 Milliarden US-Dollar ($191 Millionen US-Dollar) geschätzt.
Kann man einen LLM für unter 100.000 £ ausbilden?
Ja, allerdings mit erheblichen Einschränkungen hinsichtlich Modellgröße und Leistungsfähigkeit. Die im FLM-101B-Paper dokumentierte Forschung zeigte, dass kleinere Modelle (1–20 Milliarden Parameter) innerhalb eines Budgets von $100.000 durch effiziente Architekturen, optimierte Trainingsverfahren und sorgfältiges Ressourcenmanagement trainiert werden können. Die Feinabstimmung bestehender Openweight-Modelle ist für die meisten Anwendungsfälle deutlich kostengünstiger.
Was ist günstiger: eine LLM-Schulung in der Cloud oder vor Ort?
Das hängt von den Nutzungsmustern ab. Untersuchungen der Carnegie Mellon University ergaben, dass sich die Kosten für eine On-Premise-Lösung in der Regel innerhalb von 12 bis 18 Monaten amortisieren, wenn die jährliche Arbeitslast konstant und vorhersehbar ist und 10.000 GPU-Stunden übersteigt. Cloud-Dienste erweisen sich als kostengünstiger für variable Arbeitslasten, experimentelle Projekte oder Organisationen ohne entsprechende Infrastrukturexpertise.
Wie hoch sind die Kosten für die LLM-Inferenz im Vergleich zum Training?
Untersuchungen des WiNGPT-Teams legen nahe, dass die Kosten für die Inferenz im Laufe der Betriebsdauer eines Modells häufig die Trainingskosten übersteigen. Während das Training eine einmalige Ausgabe darstellt (mit regelmäßigem Nachtraining), läuft die Inferenz kontinuierlich, solange das Modell Nutzern dient. Anwendungen mit hohem Datenverkehr können monatliche Inferenzkosten in Höhe von Hunderttausenden von Euro verursachen.
Ist Feintuning günstiger als eine Ausbildung von Grund auf?
Deutlich günstiger. Feinabstimmung kann 60–901 Tsd. weniger kosten als das Training von Grund auf. Während das Training von Spitzenmodellen wie GPT-4 1 Tsd. 78–100 Millionen kostet, liegen die Kosten für die Feinabstimmung derselben Modelle für spezifische Anwendungen typischerweise zwischen 1 Tsd. 5.000 und 1 Tsd. 50.000. Forschungen der Universidad Nacional de Colombia haben gezeigt, dass eine effektive Feinabstimmung in nur 7 Stunden auf einer einzelnen NVIDIA T4 GPU möglich ist.
Welche GPU eignet sich am besten für eine kostengünstige LLM-Ausbildung?
Für kostengünstige Schulungen bieten NVIDIA T4-GPUs (16 GB VRAM) mit 104 Tsd. 2–4 Tsd. pro Stunde auf Cloud-Plattformen einen guten Einstieg. Für anspruchsvollere Projekte bieten A100- oder H100-GPUs trotz höherer Stundensätze ein besseres Preis-Leistungs-Verhältnis. Die A800 80G verursacht laut arXiv-Recherche zur GPU-Ökonomie Basiskosten von etwa 104 Tsd. 0,79 Tsd. pro Stunde.
Wie verändern Open-Weight-Modelle wie GPT-OSS die Ökonomie?
Die Veröffentlichung von gpt-oss-120b und gpt-oss-20b durch OpenAI im März 2026 unter der Apache-2.0-Lizenz verändert die Kostenstruktur grundlegend. Unternehmen können nun hochmoderne Modelle herunterladen und an ihre spezifischen Bedürfnisse anpassen, ohne die hohen Kosten für das Training von Grund auf. Dies ermöglicht auch Organisationen mit kleineren Budgets den Zugang zu fortschrittlichen Modellen.
Die Trainingsentscheidung treffen
Die Ausbildung eines LLM-Absolventen von Grund auf stellt eine enorme finanzielle Verpflichtung dar, die sich nur für Organisationen mit besonderen Anforderungen, beträchtlichen Budgets und langfristigen strategischen KI-Initiativen lohnt.
In den allermeisten Anwendungsfällen erzielt die Feinabstimmung von Open-Wichtungsmodellen einen Nutzen von 80–901 TP³T bei nur 5–101 TP³T Kosten. Die Vielzahl hochwertiger Open-Wichtungsmodelle von OpenAI, Meta, Mistral und anderen Anbietern hat die individuelle Entwicklung von LLM-Modellen auch für Organisationen zugänglich gemacht, die dies vor drei Jahren noch nicht in Betracht gezogen hätten.
Die eigentliche Frage ist nicht, ob man es sich leisten kann, von Grund auf neu zu trainieren – sondern ob man es sich leisten kann, die Milliarden von Dollar, die bereits in Basismodelle für den offenen Gewichtsbereich investiert wurden, nicht zu nutzen.
Sind Sie bereit, den Einsatz von LLM in Ihrem Unternehmen zu prüfen? Beginnen Sie mit der Bewertung bestehender Open-Weight-Modelle anhand Ihrer spezifischen Anforderungen. Berechnen Sie Ihre voraussichtlichen Inferenzkosten mithilfe von Tools wie den verfügbaren Berechnungswerkzeugen für LLM-Trainingskosten. Und am wichtigsten: Führen Sie zunächst kleine Feinabstimmungsexperimente durch, bevor Sie größere Infrastrukturinvestitionen tätigen.