Kurzzusammenfassung: Die schnellsten LLM-Inferenz-APIs im Jahr 2026 stammen von Anbietern wie Groq, SiliconFlow und Hugging Face mit Latenzen unter 2 Sekunden und einem Durchsatz von über 100 Tokens pro Sekunde. Die Preise variieren stark – von DeepSeeks $0,28 pro Million Eingabe-Tokens bis zu OpenAIs GPT-5.2 Pro mit $21,00. Für eine kosteneffiziente Inferenz müssen Geschwindigkeit, Preis und Modellleistung für Ihre spezifische Arbeitslast optimal aufeinander abgestimmt werden.
Geschwindigkeit ist entscheidend beim Einsatz großer Sprachmodelle in großem Umfang. Die schnellste Inferenz-API ist jedoch nicht immer die günstigste – und die günstigste ist nicht immer schnell genug.
Anfang 2026 hat sich der Markt für LLM-Inferenz in verschiedene Segmente aufgespalten. Premium-Anbieter wie OpenAI verlangen Höchstpreise für hochmoderne Modelle. Gleichzeitig unterbieten aggressive Newcomer wie DeepSeek etablierte Anbieter um mindestens 901.000 US-Dollar.
Dieser Leitfaden liefert detaillierte Informationen zu den tatsächlichen Zahlen. Preise pro Million Token, tatsächliche Latenzmessungen, Durchsatz-Benchmarks und die versteckten Kosten, die auf Preisseiten nicht angegeben werden.
LLM-Inferenzgeschwindigkeitsmetriken verstehen
Bevor man die Anbieter vergleicht, sollte man verstehen, was “schnell” im Kontext von LLM-APIs tatsächlich bedeutet.
Drei Kennzahlen sind am wichtigsten:
- Latenz Die Latenz misst die Zeit bis zum ersten Token – wie schnell das Modell nach Eingang Ihrer Anfrage reagiert. Laut den Metriken des Inferenzanbieters von Hugging Face erreichen leistungsstarke Modelle eine Latenz von unter 1,5 Sekunden. Groq wird in Benchmarks von Drittanbietern und in Groqs eigenen Benchmark-Berichten regelmäßig als extrem schnell genannt (Token/Sek.).
- Durchsatz Hugging Face erfasst die pro Sekunde generierten Token, sobald das Modell reagiert. Daten von Hugging Face zeigen, dass führende Anbieter für Modelle wie Qwen3.5-35B-A3B 127 Token/Sekunde oder mehr erreichen.
- Kontextfenster Bestimmt, wie viel Text das Modell in einer einzelnen Anfrage verarbeiten kann. Moderne Modelle unterstützen 128.000 bis 262.000 Tokens, wobei längere Kontexte sowohl die Latenz als auch die Kosten erhöhen können.
- Aber die Geschwindigkeit hängt stark von den Eigenschaften der Arbeitslast ab. Kurze Abfragen mit kurzen Antworten werden schneller ausgeführt als komplexe Aufgaben mit langem Kontext. Stapelverarbeitung tauscht sofortige Antwortzeiten gegen einen höheren Durchsatz und geringere Kosten.
Schnellste LLM-Inferenzanbieter nach Latenz
Wenn es vor allem auf reine Geschwindigkeit ankommt, übertreffen einige wenige Anbieter die Konkurrenz konstant.
Groq: Speziell für Geschwindigkeit entwickelt
Groq verwendet eine speziell für die LLM-Inferenz entwickelte Hardware für die Sprachverarbeitungseinheit (LPU). Diskussionen in der Community und Groqs eigene Benchmarks bestätigen die “extrem hohe” Inferenzgeschwindigkeit mit konstant marktführenden Token-pro-Sekunde-Werten.
Das Unternehmen veröffentlichte neue Benchmarks für Llama 3.3 70B, die eine branchenführende Inferenzleistung belegen. Für Anwendungen, bei denen Reaktionszeiten im Subsekundenbereich entscheidend sind – Chatbots, Echtzeitassistenten, interaktive Tools – bietet die Architektur von Groq messbare Vorteile.
Die Preise werden nicht für alle Modelle öffentlich angegeben, daher müssen Entwickler die offizielle Dokumentation von Groq konsultieren, um die aktuellen Preise zu erfahren.
SiliconFlow: Geschwindigkeit trifft auf Erschwinglichkeit
SiliconFlow erzielte in aktuellen Benchmark-Tests bis zu 2,3-mal schnellere Inferenzgeschwindigkeiten und eine um 321T3T geringere Latenz im Vergleich zu führenden KI-Cloud-Plattformen bei gleichbleibender Genauigkeit. Die Plattform bietet sowohl serverlose Pay-per-Use- als auch reservierte GPU-Optionen.
Diese Kombination aus Geschwindigkeit und Kostenkontrolle macht SiliconFlow besonders attraktiv für Produktionsumgebungen, in denen beide Kennzahlen wichtig sind. Die Plattform unterstützt verschiedene Open-Source-Modelle mit transparenter Preisgestaltung und flexiblen Infrastrukturoptionen.
Anbieter von Rückschlüssen auf das Umarmen von Gesichtern
Hugging Face aggregiert mehrere Inferenzanbieter über eine einheitliche API und verfolgt die Leistung verschiedener Modell-Anbieter-Kombinationen. Die Schnittstelle ermöglicht es Entwicklern, Anfragen automatisch an den schnellsten oder kostengünstigsten Anbieter für jedes Modell weiterzuleiten. Da der Router OpenAI-kompatible Aufrufe unterstützt, ist die Migration für Nutzer bestehender Integrationen unkompliziert.

Erstellen Sie LLM-Anwendungen, die für schnelle Inferenz optimiert sind.
Schnelle LLM-Reaktionen hängen von der richtigen Architektur, dem richtigen Modellaufbau und der richtigen Infrastruktur ab. AI Superior Das Unternehmen entwickelt KI-Software und NLP-Systeme, die große Sprachmodelle in reale Anwendungen wie Chatbots, Automatisierungstools und Datenanalyseplattformen integrieren. Das Team entwirft Modellpipelines, Backend-Dienste und Bereitstellungsumgebungen, um den zuverlässigen Betrieb von LLM-Funktionen in Produktionssystemen zu gewährleisten.
Ein Produkt entwickeln, das LLM-APIs nutzt?
Sprechen Sie mit einer KI, die überlegen ist gegenüber:
- Entwicklung und Erstellung von LLM-basierten Anwendungen
- Entwicklung von NLP-Systemen und KI-Software
- Sprachmodelle innerhalb bestehender Plattformen einsetzen
👉 Fordern Sie eine KI-Beratung an mit AI Superior um Ihr Projekt zu besprechen.
Preisgestaltung für LLM-Studiengänge: Marktüberblick 2026
Die Preisstrukturen der Anbieter variieren stark. Einige verlangen Premiumpreise für proprietäre Modelle. Andere konkurrieren aggressiv über die Preise von Open-Source-Modellen.
So sieht der Markt Anfang 2026 aus:
Premium-Stufe: OpenAI und Anthropic
OpenAI hat GPT-5.2 Pro im Februar 2026 zu einem Preis von $21,00 pro Million Eingabe-Token und $168,00 pro Million Ausgabe-Token auf den Markt gebracht. Das Standardmodell von GPT-5.2 kostet $8,00 Eingabe- bzw. $32,00 Ausgabe-Token pro Million Token.
Die Claude-Modelle von Anthropic bewegen sich preislich im selben Premiumsegment. Diese Anbieter rechtfertigen die höheren Kosten mit modernster Technologie, Zuverlässigkeit und umfangreichen Sicherheitstests.
Mittlere Preisklasse: Google Gemini und andere
Googles Gemini-Modelle bieten wettbewerbsfähige Preise für leistungsstarke Geräte. Im breiteren mittleren Preissegment finden sich Anbieter wie Mistral AI, die ein gutes Verhältnis von Leistung zu erschwinglicheren Preisen als Premium-Anbieter bieten.
Budgetstufe: DeepSeek Disruption
DeepSeek hat die Konkurrenz mit seinen V3.2-Exp-“Denkmodellen” aggressiv unterboten, die zu Preisen von nur $0,28 pro Million Input-Token (Cache-Miss) und $0,42 pro Million Output-Token angeboten werden. Dies entspricht einem Preisnachlass von über 90% im Vergleich zu Premium-Anbietern.
Die Grok-Produktreihe von xAI richtet sich ebenfalls an kostenbewusste Entwickler. Grok 4 Fast und Grok 4.1 Fast kosten jeweils 1 TP4T0,20 Input bzw. 1 TP4T0,50 Output pro Million Token.
| Anbieter | Modellbeispiel | Eingabe ($/M-Token) | Ausgabe ($/M-Token) | Leistungsstufe |
|---|---|---|---|---|
| OpenAI | GPT-5.2 Pro | $21.00 | $168.00 | Prämie |
| OpenAI | GPT-5.2 | $8.00 | $32.00 | Prämie |
| xAI | Grok 4 | $3.00 | $15.00 | Mittlere Preisklasse |
| xAI | Grok 4 Fast | $0.20 | $0.50 | Budget |
| DeepSeek | V3.2-Exp | $0.28 | $0.42 | Budget |
| Novita (HF) | Qwen3.5-35B-A3B | $0.25 | $2.00 | Budget |
Versteckte Kosten jenseits der Token-Preisgestaltung
Der Preis pro Million Token allein sagt nur einen Teil der Kostengeschichte aus.
Mehrere versteckte Faktoren beeinflussen die tatsächlichen Ausgaben erheblich:
Kontext-Caching und -Wiederverwendung
Manche Anbieter bieten Rabatte für zwischengespeicherte Kontextdaten, die über mehrere Anfragen hinweg wiederverwendet werden. Der Tarif von DeepSeek ($0,28) gilt für Anfragen, bei denen der Cache nicht gefunden wird; bei Anfragen, bei denen der Cache erfolgreich ist, ist er niedriger. Wenn Ihre Anwendung wiederholt ähnliche Kontextdaten verarbeitet, kann Caching die Kosten erheblich senken.
Batch- vs. Echtzeit-Preisgestaltung
OpenAI und Google bieten APIs für die Stapelverarbeitung zu vergünstigten Preisen an – teilweise mit 501 TP3T Rabatt auf Echtzeittarife. Laut Diskussionen in der Hugging Face-Community gibt es für die serverlosen Endpunkte von Hugging Face kein direktes Äquivalent zur Batch-API von OpenAI mit speziellen Preisnachlässen.
Batch-Inferenz eignet sich für nicht zeitkritische Arbeitslasten wie Datenverarbeitung, Inhaltsgenerierung und Analyseaufgaben. Der Nachteil besteht in einer verzögerten Fertigstellung, die jedoch mit geringeren Kosten verbunden ist.
Output-Token-Ökonomie
Ausgabetoken kosten typischerweise 4- bis 8-mal so viel wie Eingabetoken. Ein Modell, das ausführliche Antworten generiert, verbraucht das Budget schneller als eines, das prägnant antwortet.
Zur Kostenoptimierung verhindert die Begrenzung der maximalen Ausgabelänge einen unkontrollierten Tokenverbrauch. Zu niedrige Grenzwerte können dazu führen, dass Antworten vor der vollständigen Übermittlung abgeschnitten werden. Daher muss bei der Konfiguration ein Gleichgewicht zwischen Vollständigkeit und Kostenkontrolle gefunden werden.
Infrastruktur- und Skalierungskosten
Serverlose APIs berechnen die Gebühren pro Token ohne zusätzlichen Infrastrukturaufwand. Modelle mit reservierter Kapazität – wie die reservierten GPU-Optionen von SiliconFlow – erfordern zwar Vorabinvestitionen, bieten aber bei großem Umfang eine bessere Kosten-Nutzen-Rechnung pro Token.
Untersuchungen zum Einsatz heterogener GPUs zeigen, dass die Kosteneffizienz je nach Workload-Charakteristika erheblich variiert. Analysen des LLM-Betriebs auf heterogenen GPUs zufolge verbessert die Zuordnung von Anfragetypen zur passenden Hardware die Ressourcennutzung und senkt die effektiven Kosten.
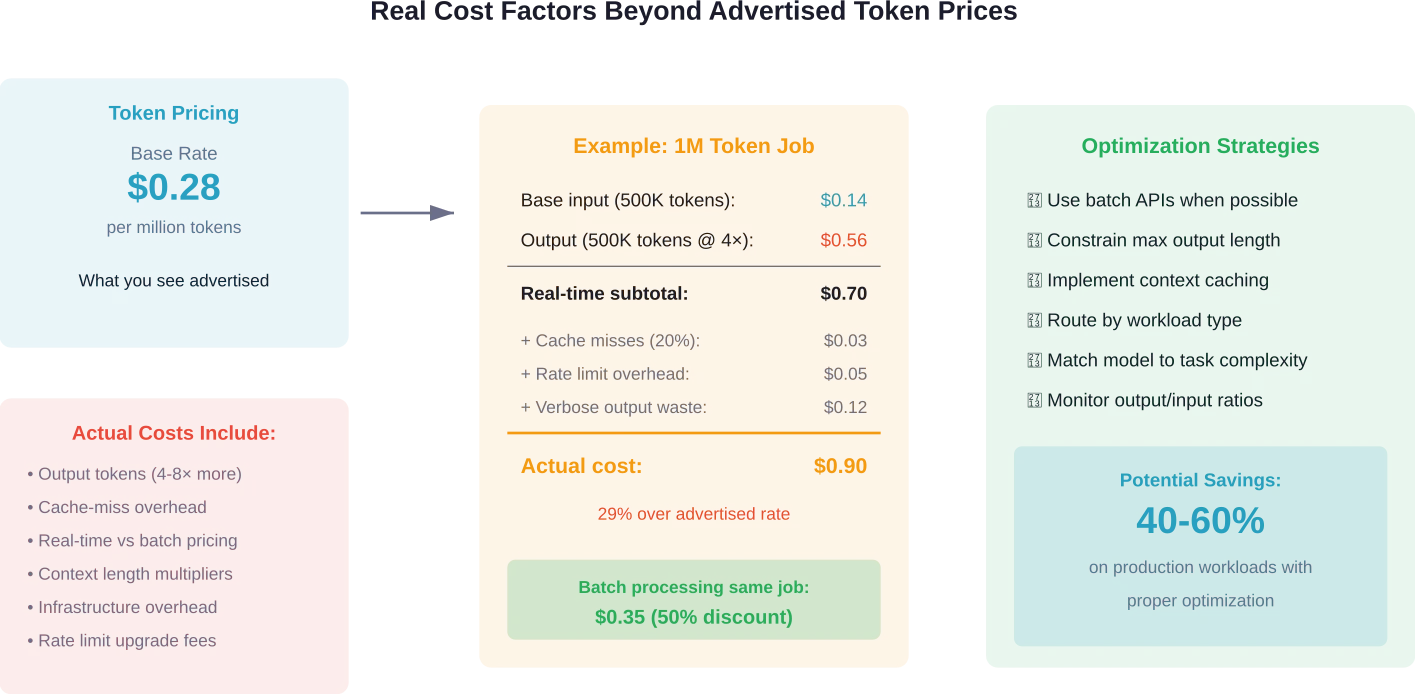
Geschwindigkeits-Kosten-Verhältnis: Den optimalen Punkt finden
Der optimale Anbieter hängt vollständig von den Arbeitslastanforderungen ab.
Bei latenzkritischen Anwendungen – wie kundenorientierten Chatbots, Echtzeit-Codierungsassistenten und interaktiven Demos – rechtfertigt die Geschwindigkeit einen höheren Preis. Eine Reaktionsverzögerung von zwei Sekunden schreckt Nutzer ab, unabhängig von möglichen Kosteneinsparungen.
Bei der Verarbeitung großer Datenmengen – wie Inhaltsklassifizierung, Datenextraktion und Analysepipelines – sind die Kosten pro Million Token ausschlaggebend. DeepSeeks Preisgestaltung ($0,28) bei akzeptabler (wenn auch nicht führender) Performance ist wirtschaftlich sinnvoll.
Forschungen zum LLM-Shepherding legen nahe, dass hybride Ansätze beide Metriken optimieren können. Der Einsatz kleinerer, schnellerer Modelle für die initiale Verarbeitung und die Weiterleitung komplexer Anfragen an größere Modelle senkt die durchschnittlichen Kosten bei gleichbleibender Qualität. Laut der Studie verbessern selbst kleine Hinweise größerer Modelle (10-30% der vollständigen Antwort) die Genauigkeit kleinerer Modelle erheblich.
Überlegungen zur Modellgröße
Die Modellgröße hat direkten Einfluss auf Geschwindigkeit und Kosten.
Laut den Empfehlungen von Hugging Face zur Auswahl von Open-Source-LLMs benötigt ein Modell mit 7–8 Milliarden Parametern 14–16 GB VRAM bei FP16-Genauigkeit oder 6–8 GB bei 4-Bit-Quantisierung. Als Cloud-Option stehen AWS g5.xlarge-Instanzen zur Verfügung.
Kleinere Modelle mit 1-3 Milliarden Parametern laufen auf 4-6 GB VRAM (2 GB quantisiert) und bewältigen grundlegende Aufgaben – Textklassifizierung, Autovervollständigung, einfacher Chat – auf einfacher Hardware wie RTX 3060 oder Laptop-GPUs.
Größere Modelle liefern bessere Schlussfolgerungen, benötigen aber mehr Rechenressourcen. Laut einer Effizienzstudie sind für die FP16-Inferenz eines LLaMA-2-70B-Modells mindestens zwei NVIDIA A100 GPUs (jeweils mit 80 GB VRAM) erforderlich.
Führende Anbieter mit optimalem Kosten-Nutzen-Verhältnis für schnelle Inferenz
Anhand von Leistungskennzahlen und Preisdaten bieten mehrere Anbieter ein überzeugendes Verhältnis von Geschwindigkeit zu Kosten:
SiliconFlow
SiliconFlow vereint hohe Geschwindigkeit (2,3-mal schneller als einige führende Plattformen) mit flexibler Preisgestaltung. Die Plattform unterstützt sowohl Serverless- als auch reservierte Kapazität und ermöglicht so eine Kostenoptimierung basierend auf den Nutzungsmustern.
Der Service bietet eine All-in-One-KI-Cloud mit branchenführendem Preis-Leistungs-Verhältnis und richtet sich sowohl an Entwickler als auch an Unternehmen.
Anbieter von Rückschlüssen auf das Umarmen von Gesichtern
Der einheitliche Router von Hugging Face bündelt die Verbindungen mehrerer Anbieter und ermöglicht so die automatische Weiterleitung zur schnellsten oder günstigsten Option für jedes Modell. Laut deren Kennzahlen:
- Novita bietet Qwen3.5-Modelle mit $0.25-$0.60 Eingangsspannung und einer Latenz von unter 1,1 Sekunden an.
- Together AI bietet vergleichbare Modelle mit etwas höherer Latenz, aber ähnlicher Preisgestaltung.
- Für jedes beliebte Modell konkurrieren mehrere Anbieter, was die Effizienz steigert.
Der Router unterstützt OpenAI-kompatible API-Aufrufe und vereinfacht so die Migration von anderen Anbietern. Entwickler können Routing-Präferenzen – ”:fastest”, “:cheapest” – festlegen, um verschiedene Ziele zu optimieren.
Mistral KI
Mistral AI bietet starke Leistung zu Preisen im mittleren Segment. Das Unternehmen konzentriert sich auf effiziente Modellarchitekturen, die die Inferenzkosten senken, ohne die Leistungsfähigkeit zu beeinträchtigen.
Die Mistral-Modelle erreichen wettbewerbsfähige Qualitätsstandards bei gleichzeitig angemessenen Kosten pro Token, wodurch sie für Produktionsumgebungen, die mehrere Einschränkungen berücksichtigen müssen, attraktiv sind.
DeepSeek
Bei Arbeitslasten, bei denen die Kosten die Entscheidungsfindung dominieren, stellt die aggressive Preisgestaltung von DeepSeek ($0,28 Input / $0,40 Output) die derzeitige Marktuntergrenze für leistungsfähige Modelle dar.
Die Leistung bleibt hinter Premiumanbietern zurück, ist aber für viele Anwendungen ausreichend. Die Kostenersparnis – bis zu 901 TP3T im Vergleich zu Topmodellen – ermöglicht Anwendungsfälle, für die ein Premiumpreis nicht gerechtfertigt wäre.
Feuerwerks-KI
Fireworks AI ist auf optimierte Inferenz für Open-Source-Modelle spezialisiert. Die Plattform konzentriert sich auf produktionsreife Zuverlässigkeit bei gleichzeitig vorhersehbarer Preisgestaltung und Leistung.
Der Dienst bietet eine speziell auf LLM abgestimmte Infrastruktur mit Funktionen, die für Entwickler konzipiert sind, die Anwendungen erstellen, anstatt mit Modellen zu experimentieren.
Überlegungen zum Leistungsvergleich
Veröffentlichte Benchmarks spiegeln nicht immer die Leistung in der realen Welt wider.
Mehrere Faktoren führen zu Diskrepanzen zwischen den beworbenen Kennzahlen und der tatsächlichen Produktionserfahrung:
Die Auslastung beeinflusst die Latenz. Anbieter unter hoher Auslastung verlangsamen ihre Reaktionszeiten. Tageszeit, geografische Region und aktuelle Nachfrage beeinflussen die tatsächlichen Reaktionszeiten.
Die Merkmale der Anfrage spielen eine entscheidende Rolle. Kurze Anfragen mit kurzen Ergebnissen werden schneller bearbeitet als Aufgaben mit längerem Kontext. Untersuchungen zum Energie-Leistungs-Verhältnis bei der Inferenz in LLM-Systemen zeigen, dass die Inferenz je nach Anfrage und Ausführungsphase erhebliche Unterschiede aufweist.
Die Latenz beim Kaltstart kann die erste Anfrage in serverlosen Architekturen beeinträchtigen.
Ratenbegrenzungen schränken den Durchsatz ein. Selbst schnelle APIs drosseln Anfragen ab einem bestimmten Volumen, sodass für Anwendungen mit hohem Datenaufkommen höherwertige Abonnements oder reservierte Kapazität erforderlich sind.
Optionen für die Infrastrukturbereitstellung
Neben verwalteten APIs haben Infrastrukturentscheidungen einen erheblichen Einfluss auf Kosten und Leistung.
Serverlose APIs
Serverlose Lösungen wie die von Hugging Face, OpenAI und anderen Anbietern berechnen die Kosten pro Token und erfordern keine Infrastrukturverwaltung. Dieses Modell eignet sich gut für variable Arbeitslasten, Prototyping und Anwendungen mit unvorhersehbarer Nachfrage.
Der Nachteil besteht in höheren Kosten pro Token im Vergleich zu einer dedizierten Infrastruktur in großem Umfang.
Reservierte Kapazität
Reservierte GPU-Instanzen oder dedizierte Endpunkte bieten garantierte Ressourcen zu niedrigeren Tokenpreisen. Anbieter wie SiliconFlow bieten diese Option neben Serverless-Preismodellen an.
Die Reservierung von Kapazität ist wirtschaftlich sinnvoll, sobald die Nutzung konstante Schwellenwerte erreicht, bei denen die Bereitstellungskosten unter die Kosten vergleichbarer Serverless-Ausgaben sinken.
Selbstgehostete Inferenz
Die Durchführung von Inferenzprozessen auf eigener oder gemieteter Infrastruktur bietet maximale Kontrolle und potenziell niedrigste Kosten bei sehr hohen Datenmengen.
Die Forschung zur Implementierung von LLMs auf Edge-Geräten verdeutlicht Einschränkungen: Ein Modell mit 7–8 Milliarden Parametern erfordert erhebliche Speicher- und Rechenressourcen. Charakterisierungsstudien mobiler SoCs zeigen, dass selbst bei heterogenen Verarbeitungseinheiten die Speicherbandbreite den Durchsatz begrenzt. Einige Konfigurationen erreichen lediglich 40–45 GB/s pro Einheit, bevor mehrere Prozessoren benötigt werden, um die verfügbare Bandbreite auszuschöpfen.
Self-Hosting erfordert Fachkenntnisse in den Bereichen Modellbereitstellung, Optimierung, Überwachung und Skalierung – ein Aufwand, der durch serverlose APIs entfällt.
Den richtigen Anbieter für Ihre Arbeitslast auswählen
Bei den Entscheidungskriterien sollten die Merkmale der Arbeitsbelastung Vorrang vor abstrakten Vergleichen haben.
Stellen Sie diese Fragen:
- Welches Nutzungsmuster gibt es? Bei konstant hohem Arbeitsaufkommen empfiehlt sich reservierte Kapazität oder Self-Hosting. Variable, unvorhersehbare Nachfrage eignet sich für serverlose APIs.
- Wie latenzempfindlich ist die Anwendung? Echtzeit-Benutzerinteraktionen erfordern Reaktionszeiten im Subsekundenbereich. Hintergrundverarbeitung toleriert Latenzzeiten von mehreren Sekunden, um Kosten zu sparen.
- Welche Modellfunktionen werden tatsächlich benötigt? Viele Anwendungen überdimensionieren die Modellkapazität. Kleinere, schnellere Modelle bewältigen einfache Aufgaben zu geringeren Kosten.
- Funktioniert die Stapelverarbeitung? Nicht dringende Arbeitslasten profitieren von 50%-Stapelrabatten, sofern die Anbieter diese anbieten.
- Wie hoch ist das Verhältnis von Output zu Input? Anwendungen, die lange Antworten generieren, verursachen hohe Kosten für Ausgabetoken. Die Begrenzung der Ausführlichkeit reduziert die Kosten erheblich.
- Profitiert die Arbeitslast von Kontext-Caching? Die wiederholte Verarbeitung ähnlicher Kontexte mit Unterstützung durch Caching senkt die Kosten pro Anfrage.
Häufig gestellte Fragen
Was ist die günstigste LLM-Inferenz-API im Jahr 2026?
DeepSeek bietet mit $0,28 pro Million Input-Token und $0,40 pro Million Output-Token für seine V3.2-Exp-Modelle (Stand: Anfang 2026) die niedrigsten Preise. xAIs Grok 4 Fast ist mit $0,20 Input-Token und $0,50 Output-Token vergleichbar bepreist. Die Gesamtkosten hängen jedoch von der Ausführlichkeit der Ausgabe, der Effizienz des Caching und der Verfügbarkeit von Batch-Verarbeitung ab. Die günstigste Option variiert je nach Arbeitslast.
Welcher Anbieter bietet die schnellste LLM-Inferenzgeschwindigkeit?
Groq gilt durchgehend als schnellster Anbieter für Inferenz und nutzt dafür speziell entwickelte LPU-Hardware, die für LLM-Workloads optimiert ist. Benchmarks von Drittanbietern und Diskussionen in der Community bestätigen Groqs branchenführende Leistung in Bezug auf Token pro Sekunde. Laut Hugging Face-Metriken zählen Novita (mit Qwen-Modellen und einer Latenz von 0,66–1,09 Sekunden) und SiliconFlow (2,3-mal schneller als einige führende Plattformen) zu den schnelleren Alternativen. Die tatsächliche Geschwindigkeit hängt von der Modellgröße, der Kontextlänge und der aktuellen Auslastung ab.
Wie viel kostet es, 1 Milliarde Token über eine LLM-API zu verarbeiten?
Die Kosten für 1 Milliarde Token variieren stark je nach Anbieter und Input-/Output-Mix. Bei DeepSeeks Konditionen ($0,28 Input / $0,40 Output) kosten 1 Milliarde Token $280 für reine Input- oder $400 für reine Output-Token. Bei OpenAIs GPT-5.2 Pro-Konditionen ($21 Input / $168 Output) kostet dasselbe Volumen $21.000 Input- oder $168.000 Output-Token. Eine typische Arbeitslast mit 60% Input und 40% Output würde bei DeepSeek etwa $328 kosten, bei GPT-5.2 Pro hingegen $79.800 – ein Unterschied um das 240-Fache.
Sparen Batch-Verarbeitungs-APIs tatsächlich Geld?
Ja, sofern verfügbar. OpenAI und Google bieten Batch-APIs mit etwa 501 TP3T Preisnachlässen im Vergleich zur Echtzeitverarbeitung an. Der Nachteil ist die längere Bearbeitungszeit – Batch-Jobs können Stunden statt Sekunden dauern. Laut Diskussionen in der Hugging Face-Community bieten viele serverlose Endpunkte von Hugging Face keine speziellen Batch-Rabatte an, dedizierte Inferenz-Endpunkte hingegen schon. Batch-Verarbeitung ist sinnvoll für Datenverarbeitung, Content-Generierung und Analyseaufgaben, bei denen keine sofortigen Ergebnisse erforderlich sind.
Soll ich serverlose oder reservierte GPU-Kapazität nutzen?
Es hängt von den Nutzungsmustern und dem Datenvolumen ab. Serverlose APIs eignen sich gut für schwankende Nachfrage, Prototyping und geringe bis mittlere Datenmengen, bei denen der Komfort die Kosten pro Token überwiegt. Reservierte Kapazität wird kosteneffektiv, wenn die kontinuierliche Nutzung den Break-Even-Punkt erreicht und die Kosten für die Bereitstellung unter die Kosten vergleichbarer Serverless-Ausgaben sinken. SiliconFlow bietet beide Optionen und ermöglicht so eine Optimierung basierend auf den Nutzungsmustern. Berechnen Sie Ihr tatsächliches, nachhaltiges Token-Volumen und vergleichen Sie es mit den Preisen für reservierte Kapazität, um die Gewinnschwelle zu ermitteln.
Wie beeinflusst die Modellgröße die Geschwindigkeit und die Kosten der Inferenz?
Größere Modelle benötigen mehr Rechenressourcen, was sowohl die Latenz als auch die Infrastrukturkosten erhöht. Laut der Dokumentation von Hugging Face benötigt ein 1-3-B-Modell lediglich 2-4 GB VRAM und ermöglicht schnelle Inferenz auf Standardhardware, geeignet für einfache Aufgaben. Ein 7-8-B-Modell benötigt je nach Quantisierung 6-16 GB VRAM und bewältigt komplexere Workloads. Ein 70-B-Modell erfordert mehr als 140 GB VRAM (mehrere High-End-GPUs) und verarbeitet Anfragen langsamer. Kleinere Modelle optimieren Geschwindigkeit und Kosten; größere Modelle verbessern die Leistungsfähigkeit und die Qualität der Schlussfolgerungen. Passen Sie die Modellgröße an die tatsächlichen Aufgabenanforderungen an, anstatt standardmäßig das größte verfügbare Modell zu verwenden.
Kann ich die Kosten durch Optimierung der Eingabeaufforderungslänge senken?
Absolut. Kürzere Eingabeaufforderungen verbrauchen weniger Eingabe-Tokens und senken so die Kosten. Noch wichtiger ist, dass die Begrenzung der maximalen Ausgabelänge teure, ausführliche Antworten verhindert. Da Ausgabe-Tokens 4- bis 8-mal so viel kosten wie Eingabe-Tokens, verbraucht ein Modell, das unnötig lange Antworten generiert, schnell das Budget. Gemäß bewährten Methoden sollten Sie die Parameter für `max_tokens` an Ihren Anwendungsfall anpassen – ein zu niedriger Wert kürzt die Antworten, während ein zu hoher Wert zu unnötiger Ausführlichkeit führt. Überwachen Sie die tatsächlichen Ausgabelängen und passen Sie die Grenzwerte entsprechend an. Kontext-Caching für wiederholte Eingabeaufforderungselemente reduziert die Kosten zusätzlich, sofern dies vom Anbieter unterstützt wird.
Fazit: Geschwindigkeit und Kosten im Gleichgewicht halten
Die schnellste LLM-Inferenz-API ist nicht für jede Arbeitslast die beste Wahl – und die billigste API ist nicht immer die kosteneffektivste, wenn es auf Qualität und Geschwindigkeit ankommt.
Im Jahr 2026 bietet der Markt echte Wahlmöglichkeiten. Premium-Anbieter wie OpenAI liefern Spitzentechnologie zu Premiumpreisen. Aggressive Herausforderer wie DeepSeek unterbieten die etablierten Anbieter um 901.030 US-Dollar oder mehr. Spezialisierte Infrastrukturanbieter wie Groq und SiliconFlow optimieren auf Geschwindigkeit oder Kosteneffizienz.
Der optimale Anbieter hängt ganz von Ihren spezifischen Anforderungen ab: Empfindlichkeit gegenüber Latenz, Anforderungen an die Ausgabequalität, Nutzungsvolumen, Ausführlichkeit der Ausgabe, Caching-Möglichkeiten und ob die Stapelverarbeitung für Ihren Anwendungsfall geeignet ist.
Beginnen Sie mit der Analyse Ihrer Workload-Charakteristika. Messen Sie das tatsächliche Token-Volumen, das Input/Output-Verhältnis und die Latenzanforderungen. Ordnen Sie diese Anforderungen anschließend Anbietern zu, die Ihre spezifischen Einschränkungen optimal erfüllen.
Gehen Sie nicht davon aus, dass die teuerste Option die besten Ergebnisse liefert – oder dass die günstigste Option zu viele Qualitätseinbußen mit sich bringt. Testen Sie mehrere Anbieter mit repräsentativen Arbeitslasten, bevor Sie eine großflächige Implementierung vornehmen.
Der Markt für LLM-Inferenz bleibt auch 2026 hart umkämpft, wobei sich Preise und Leistung rasant verbessern. Beobachten Sie neue Marktteilnehmer und führen Sie regelmäßig Benchmarking durch, um sicherzustellen, dass Sie im sich wandelnden Marktumfeld den optimalen Nutzen erzielen.
Sind Sie bereit, Ihre LLM-Inferenzkosten zu optimieren? Vergleichen Sie Ihre spezifische Arbeitslast mit verschiedenen Anbietern anhand der Preisdaten und Leistungskennzahlen in diesem Leitfaden, um das beste Verhältnis von Geschwindigkeit zu Kosten für Ihre Anwendung zu ermitteln.