Kurzzusammenfassung: LLM-Analysetools mit Kostenoptimierungsfunktionen unterstützen Unternehmen bei der Überwachung des Tokenverbrauchs, der Nachverfolgung von Ausgabenmustern und der Reduzierung von KI-Infrastrukturkosten durch intelligentes Caching, Modellauswahl und automatisierte Ressourcenzuweisung. Führende Plattformen kombinieren Echtzeit-Kostenverfolgung mit Leistungsüberwachung, um kostenintensive Workflows zu identifizieren und zu optimieren, ohne die Antwortqualität zu beeinträchtigen. Effektives Kostenmanagement erfordert sitzungsbasiertes Tracking, zeitnahe Optimierung und strategische Modellauswahl basierend auf der Aufgabenkomplexität.
Organisationen, die große Sprachmodelle einsetzen, stehen vor einer grundlegenden Herausforderung: Die Kosten können schnell außer Kontrolle geraten, bevor es jemand bemerkt. Tokenbasierte Preisgestaltung führt dazu, dass sich jeder API-Aufruf summiert, und ohne geeignete Analysen können Chatbots oder Dokumentenanalysetools die Budgets in alarmierendem Tempo aufbrauchen.
Die explosionsartige Zunahme der Nutzung von LLM hat einen dringenden Bedarf an spezialisierten Analyseplattformen geschaffen. Diese Tools erfassen nicht nur Ausgaben, sondern identifizieren aktiv Optimierungspotenziale, automatisieren Kostensenkungsstrategien und bieten die notwendige Transparenz für fundierte Entscheidungen hinsichtlich Modellauswahl und Infrastruktur.
Aber eines ist klar: Nicht alle Analyseplattformen sind gleich. Manche konzentrieren sich ausschließlich auf die Beobachtbarkeit, andere priorisieren die Kostenverfolgung, und die besten kombinieren beides mit praktischen Optimierungsfunktionen. Zu verstehen, welche Funktionen für Ihren Anwendungsfall am wichtigsten sind, entscheidet darüber, ob Sie Kosten effektiv managen oder unnötig Geld ausgeben.
LLM-Kostenstrukturen und Preismodelle verstehen
Tokenbasierte Preisgestaltung dominiert den LLM-Markt. Laut der offiziellen Preisgestaltung von Anthropic kostet Claude Opus 4.6 $5 pro Million Input-Token und $25 pro Million Output-Token. Diese Preisasymmetrie ist relevant – Output-Token kosten fünfmal so viel wie Input-Token.
Die allgemeine Regel lautet: Längere Eingabeaufforderungen und längere generierte Antworten bedeuten eine höhere Anzahl an Tokens und höhere Kosten.
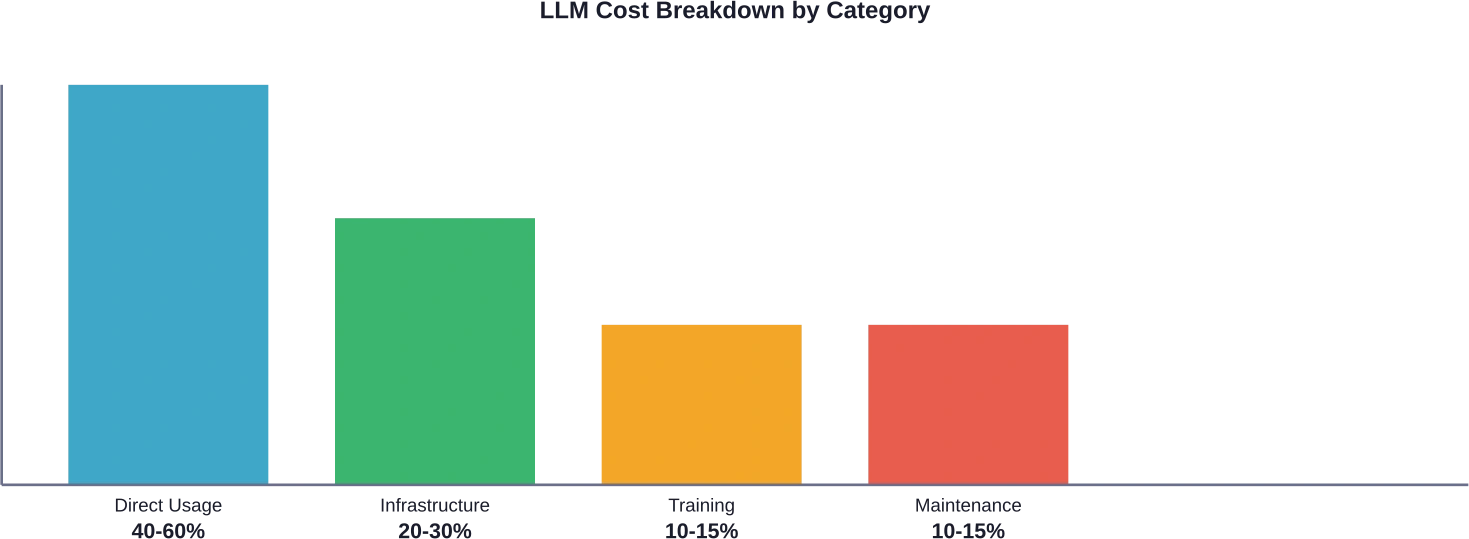
Mal ehrlich: Die meisten Unternehmen unterschätzen ihre tatsächlichen LLM-Kosten. Branchenanalysen zufolge können die direkten Nutzungsgebühren 40 bis 601 Tsd. Billionen der gesamten LLM-Ausgaben ausmachen, Infrastruktur und Integration 20 bis 301 Tsd. Billionen, und Schulung und Optimierung den Rest.
Die versteckten Kostenmultiplikatoren
Laut AWS-Dokumentation kann Prompt-Caching die Latenz von Inferenzantworten um bis zu 851 TP3T und die Kosten für Eingabetoken um bis zu 901 TP3T für unterstützte Modelle auf Amazon Bedrock reduzieren. Ohne Analysen zur Identifizierung von cachefähigen Mustern entgehen Unternehmen diese Einsparungen jedoch vollständig.
Laut AWS-Fallstudien variierte die Verarbeitungsdauer von Anfragen zwischen 6,76 und 32,24 Sekunden. Die Unterschiede sind hauptsächlich auf die verschiedenen Anforderungen an die Ausgabetoken zurückzuführen. Schnelle Antworten unter 10 Sekunden beziehen sich typischerweise auf einfache Abfragen, während komplexe Analyseaufgaben mehr als 30 Sekunden in Anspruch nehmen.
Die Größe des Kontextfensters wirkt sich ebenfalls auf die Kosten aus. Claude Opus 4.6 bietet in der Betaversion ein Kontextfenster mit 1 Million Token – leistungsstark, aber teuer, wenn Unternehmen regelmäßig unnötig große Kontexte senden.
Kernfunktionen von LLM-Analyseplattformen
Effektive LLM-Analyseplattformen bieten drei grundlegende Funktionen: umfassende Kostenverfolgung, Leistungsüberwachung und umsetzbare Optimierungserkenntnisse. Jede Komponente erfüllt einen spezifischen Zweck bei der Verwaltung von KI-Workloads.
Sitzungsbasierte Kostenverfolgung
Sitzungen gruppieren zusammengehörige Anfragen, um die tatsächlichen Kosten der Benutzerinteraktionen aufzuzeigen. Anstatt einzelner API-Aufrufe sehen Teams vollständige Workflows. Laut Kostennachverfolgungsbeispielen kosten Support-Chats durchschnittlich etwa $0,12 mit 5 API-Aufrufen, Dokumentenanalyse-Workflows etwa $0,45 mit 12 API-Aufrufen und Schnellabfragen etwa $0,02 mit einem einzelnen Aufruf.
Diese Detailtiefe ist entscheidend. Unternehmen können so die kostentreibenden Interaktionstypen identifizieren und ihre Prozesse entsprechend optimieren. Die Alternative – jeden API-Aufruf isoliert zu betrachten – verschleiert die tatsächliche Wirtschaftlichkeit von KI-Funktionen.
Echtzeit-Nutzungsüberwachung
Die Analyse des Tokenverbrauchs deckt Optimierungspotenziale auf. Analyseplattformen verfolgen das Verhältnis von eingegebenen zu ausgegebenen Token, identifizieren kostenintensive Aufforderungen und erkennen ungewöhnliche Nutzungsspitzen, bevor diese sich auf das Budget auswirken.
Aber Moment mal. Echtzeitüberwachung ist nur dann hilfreich, wenn sie auch Maßnahmen auslöst. Die besten Plattformen integrieren automatisierte Benachrichtigungen und Budgetgrenzen, um Kostenexplosionen zu verhindern.
Vergleich der Modellleistung
Verschiedene Modelle eignen sich hervorragend für unterschiedliche Aufgaben. Analysetools ermöglichen A/B-Tests verschiedener Modelle, um für jeden Anwendungsfall das optimale Verhältnis zwischen Kosten und Qualität zu finden.
Laut einer Studie des MIT-IBM Watson AI Lab liegt die bestmögliche Genauigkeit aufgrund von zufälligem Startrauschen bei einem durchschnittlichen relativen Fehler von 4%. Ein Fehler von bis zu 20% ist jedoch für die Entscheidungsfindung weiterhin sinnvoll. Unternehmen müssen akzeptable Leistungsschwellenwerte definieren, bevor sie die Kosten optimieren.
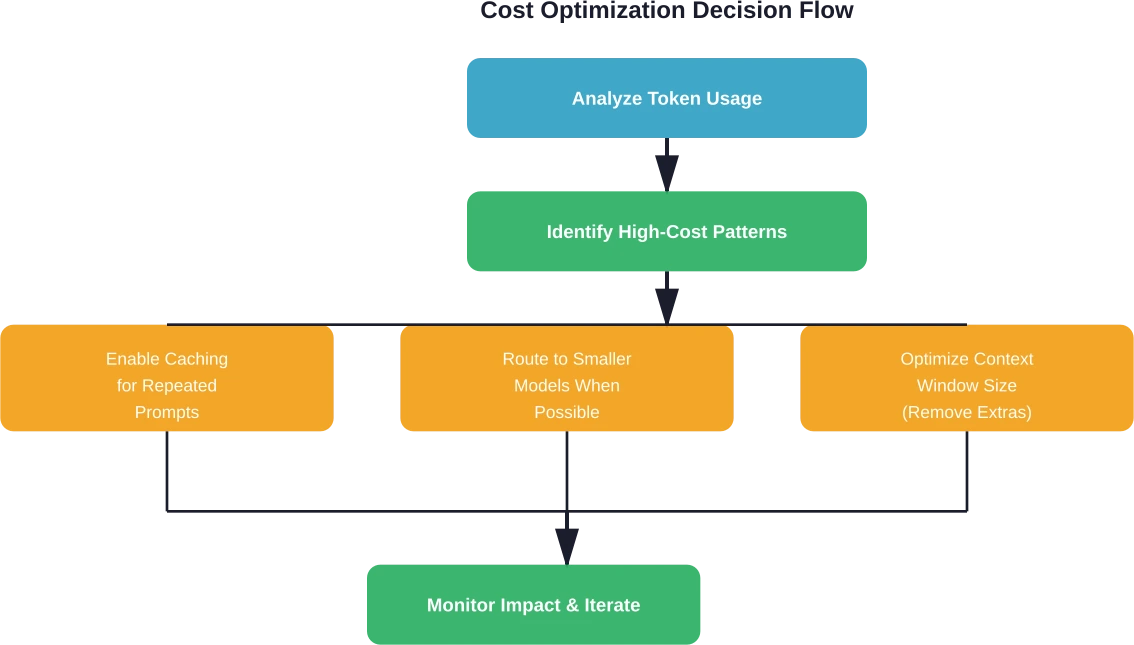
Kostenoptimierungsstrategien, ermöglicht durch Analysetools
Analyseplattformen erfassen nicht nur Kosten – sie ermöglichen gezielte Optimierungsstrategien, die die Ausgaben direkt reduzieren, ohne die Funktionalität einzuschränken.
Intelligentes Prompt-Caching
Das Prompt-Caching speichert häufig verwendete Prompt-Segmente und verwendet sie für mehrere Anfragen wieder. Dadurch werden die Latenzzeiten deutlich verbessert. AWS dokumentiert Antwortzeitreduzierungen von bis zu 851 Tsd. 3 Tsd. für zwischengespeicherte Abfragen. Ohne Analysen zur Identifizierung von Cache-fähigen Mustern entgehen Unternehmen diese Einsparungen jedoch vollständig.
Zwei Caching-Ansätze dominieren: Systemweites Caching speichert häufige Prompt-Präfixe, während Request-Response-Caching vollständige Anfrage-Antwort-Paare zur Wiederverwendung speichert. Analysetools ermitteln anhand von Wiederholungshäufigkeit und Tokenlänge, welche Prompts am meisten vom Caching profitieren.
Strategische Modellauswahl
Eine Kosten-Nutzen-Analyse der On-Premise-Implementierung von LLM durch Carnegie Mellon zeigt, dass die Benchmark-Werte führender kommerzieller Modelle innerhalb von 20% die Unternehmenspraxis widerspiegeln, bei der moderate Leistungsunterschiede zur Kostenreduzierung akzeptabel sind.
Analyseplattformen zeigen Möglichkeiten auf, Anfragen an kostengünstigere Modelle weiterzuleiten, sofern die Qualitätsanforderungen dies zulassen. Einfache Klassifizierungsaufgaben erfordern keine Spitzenmodelle – kleinere, preiswertere Alternativen sind ausreichend.
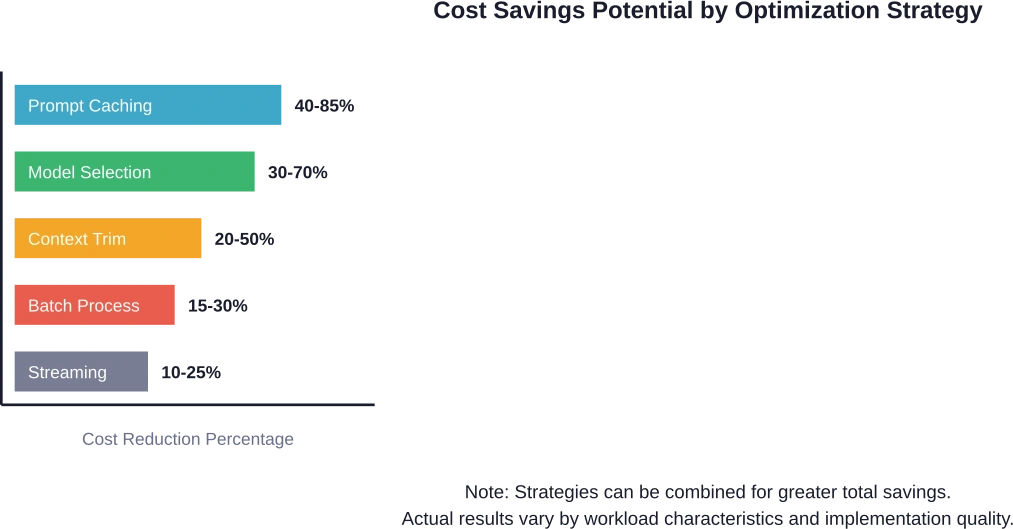
| Strategie | Kostenreduzierung | Implementierungskomplexität | Qualitätsauswirkung
|
|---|---|---|---|
| Schnelles Caching | 40-85% | Niedrig | Keiner |
| Modellauswahl | 30-70% | Medium | Aufgabenabhängig |
| Kontextoptimierung | 20-50% | Medium | Keine bis minimale |
| Stapelverarbeitung | 15-30% | Hoch | Fügt Latenz hinzu |
| Antwortstreaming | 10-25% | Niedrig | Keiner |
Kontextfensteroptimierung
Viele Anwendungen senden unnötig große Kontextinformationen mit jeder Anfrage. Analysen zeigen die durchschnittliche Größe der Kontextinformationen und identifizieren Möglichkeiten, irrelevante Informationen zu entfernen.
Kürzere Kontexte bedeuten weniger Eingabetoken und eine schnellere Verarbeitung. Fallstudien aus der Industrie belegen signifikante Kostensenkungen durch systematische Kontextoptimierung.
Automatisierte Qualitätsschwellenwerte
Die OpenAI-Forschung zu selbstlernenden Agenten empfiehlt, Optimierungszyklen fortzusetzen, bis Qualitätsschwellenwerte von >80% positivem Feedback erreicht sind oder neue Iterationen nur noch minimale Verbesserungen zeigen. Analyseplattformen erfassen diese Metriken und signalisieren, wann weitere Optimierungen abnehmende Erträge bringen.

Senken Sie Ihre LLM-Kosten mit dem richtigen Ingenieurpartner
Viele Unternehmen setzen LLM-Analysetools ein, um Nutzung, Token-Verbrauch und Modellperformance zu überwachen. Die größten Kosteneinsparungen ergeben sich jedoch in der Regel durch die Optimierung der Modellerstellung und -integration. Hier setzt die Optimierung an. AI Superior Oftmals ist das Team involviert. Es arbeitet an der technischen Ebene hinter LLM-Systemen – es entwirft kundenspezifische Modelle, bereitet Trainingsdaten auf, optimiert Architekturen und integriert LLMs in bestehende Arbeitsabläufe, damit Unternehmen Leistung und Betriebskosten effektiver kontrollieren können.
Wenn Sie die Ausgaben für LLM bis 2026 reduzieren möchten, lohnt es sich, die Trainings-, Bereitstellungs- und Überwachungsmethoden Ihrer Modelle zu überprüfen. Ein technisches Audit oder eine Architekturprüfung kann oft unnötige Inferenzkosten, ineffiziente Pipelines oder schlecht optimierte Modelle aufdecken.
Sprich mit AI Superior Wenn Sie Ihre aktuelle LLM-Struktur evaluieren und praktische Wege zur Senkung der langfristigen Betriebskosten identifizieren möchten.
Vergleich führender LLM-Analyseplattformen
Die Landschaft der Analyseplattformen umfasst spezialisierte Observability-Tools, native Lösungen von Cloud-Anbietern und Open-Source-Alternativen. Jede Kategorie bietet spezifische Vorteile.
Cloud-Anbieter-native Lösungen
AWS, Google Cloud und Azure bieten integrierte Analysen innerhalb ihrer umfassenderen KI-Plattformen. Die Nutzung und Kosten von Amazon Bedrock werden über AWS Billing and Cost Management-Berichte und die AWS Cost Explorer-APIs überwacht, wodurch ein programmatischer Zugriff auf unternehmensweite Ausgabendaten ermöglicht wird.
Googles Conversational Insights bietet zwei Preisstufen – Standard und Enterprise – mit Kosten, die je nach Interaktionstyp variieren. Chat-Konversationen werden pro Nachricht abgerechnet, Sprachkonversationen pro Minute. Die Enterprise-Stufe umfasst zusätzlich hochwertige KI-Funktionen mit Unterstützung für bis zu 50 benutzerdefinierte Auswertungen pro Konversation.
Native Lösungen lassen sich nahtlos in bestehende Cloud-Infrastrukturen integrieren, verfügen aber möglicherweise nicht über die erweiterten Optimierungsfunktionen spezialisierter Plattformen.
Spezialisierte Observability-Plattformen
Spezielle LLM-Observability-Plattformen konzentrieren sich ausschließlich auf die Überwachung und Optimierung von KI-Workloads. Diese Tools bieten in der Regel tiefergehende Analysen, ausgefeiltere Optimierungsfunktionen und herstellerunabhängige Unterstützung für verschiedene LLM-Anbieter.
Zu den wichtigsten Funktionen gehören die Nachverfolgung von Anfragen in verteilten Systemen, Latenzanalysen, Fehlerratenüberwachung und Kostenzuordnung nach Funktionen oder Teams. Die besten Plattformen liefern umsetzbare Erkenntnisse anstelle von reinen Kennzahlen.
Open-Source-Alternativen
Open-Source-Analysetools sind für Organisationen mit spezifischen Anforderungen oder Budgetbeschränkungen attraktiv. Diese Lösungen bieten Transparenz und Anpassungsmöglichkeiten, erfordern jedoch höhere technische Investitionen für Implementierung und Wartung.
Bei der gemeinschaftsorientierten Entwicklung entwickeln sich Funktionen auf Basis realer Benutzerbedürfnisse, allerdings hinken Support und Dokumentation im Unternehmensbereich kommerziellen Alternativen möglicherweise hinterher.
| Plattformtyp | Am besten geeignet für | Hauptvorteil | Hauptbeschränkung
|
|---|---|---|---|
| Cloud Native | Einzel-Cloud-Bereitstellungen | Tiefe Integration | Lieferantenbindung |
| Spezialwerkzeuge | Multi-Modell-Umgebungen | Erweiterte Optimierung | Zusätzliche Kosten |
| Open Source | Kundenspezifische Anforderungen | Transparenz und Kontrolle | Instandhaltungsaufwand |
Bewährte Verfahren zur Implementierung von Kostenanalysen
Der effektive Einsatz von Analysetools erfordert sorgfältige Planung und realistische Erwartungen hinsichtlich der Optimierungszeiträume.
Festlegung von Basiskennzahlen
Organisationen können nur optimieren, was sie messen. Beginnen Sie damit, den gesamten Token-Verbrauch, die durchschnittlichen Kosten pro Nutzerinteraktion und die Verteilung der Ausgaben auf verschiedene Funktionen oder Anwendungsfälle zu erfassen.
Die Basismessung sollte mindestens zwei Wochen dauern, um repräsentative Nutzungsmuster zu erfassen. Saisonale Schwankungen oder Nutzungsspitzen beeinflussen die Durchschnittswerte, daher liefern längere Messzeiträume zuverlässigere Daten.
Realistische Optimierungsziele setzen
Forschungsergebnisse des MIT-IBM Watson AI Lab betonen, dass Rechenbudget und Zielgenauigkeit des Modells vor Beginn der Optimierung festgelegt werden müssen. Teams sollten definieren, ob ein durchschnittlicher relativer Fehler von 4% oder ein Fehler von 20% ihren Entscheidungsanforderungen genügt.
Aggressive Kostensenkungsziele beeinträchtigen mitunter die Funktionalität. Ziel ist nicht die Minimierung der Ausgaben, sondern die optimale Ausgabenplanung für die erforderlichen Qualitätsstandards.
Umsetzung schrittweiser Einführungen
Optimieren Sie nicht alles gleichzeitig. Testen Sie Caching-Strategien zunächst an stark frequentierten Endpunkten, messen Sie die Auswirkungen und weiten Sie sie dann auf andere Bereiche aus.
Durch schrittweise Einführung lassen sich Variablen isolieren und Kostensenkungen leichter bestimmten Änderungen zuordnen. Zudem wird das Risiko minimiert – falls die Optimierung die Benutzerfreundlichkeit beeinträchtigt, bleiben die Auswirkungen gering.
Kontinuierliche Überwachung und Iteration
Kostenoptimierung ist kein einmaliges Projekt. Nutzungsmuster entwickeln sich weiter, neue Modelle mit unterschiedlichen Preisen kommen auf den Markt und die Anwendungsanforderungen ändern sich.
Planen Sie vierteljährliche Überprüfungen der Analysedaten ein, um neue Muster zu erkennen. Automatisierung reduziert den manuellen Aufwand – Plattformen, die Optimierungspotenziale automatisch aufzeigen, sparen viel Zeit.
Fortgeschrittene Optimierungstechniken
Über die grundlegende Kostenverfolgung hinaus ermöglichen fortgeschrittene Techniken zusätzliche Einsparungen bei komplexen Implementierungen.
Multi-Agenten-Modell-Routing
Forschungen zur Optimierung natürlicher Sprache mithilfe von LLM-gestützten Agenten zeigen, dass die Kombination verschiedener Modelle zu Leistungssteigerungen führt. Ein Framework erreichte eine Genauigkeit von 88,11 TP3T auf dem NLP4LP-Datensatz und 82,31 TP3T auf Optibench, wodurch die Fehlerraten durch die Zusammenarbeit mehrerer Agenten gegenüber früheren Ergebnissen um 581 TP3T bzw. 521 TP3T reduziert wurden.
Analyseplattformen können intelligentes Routing implementieren, das Anfragen an das kosteneffektivste Modell weiterleitet, das die jeweilige Aufgabe bewältigen kann. Einfache Abfragen werden an schnelle, kostengünstige Modelle weitergeleitet. Komplexe Analyseaufgaben werden an leistungsfähigere – und teurere – Alternativen übertragen.
Optimierung der Aufmerksamkeit für gruppierte Abfragen
Für Organisationen, die selbstgehostete Modelle betreiben, hat die Konfiguration des Aufmerksamkeitsmechanismus erhebliche Auswirkungen auf die Kosten. Untersuchungen zur kostenoptimalen gruppierten Abfrageaufmerksamkeit für die Modellierung langer Kontexte zeigen, dass in Szenarien mit langen Kontexten die Verwendung weniger Aufmerksamkeitsköpfe bei gleichzeitiger Skalierung der Modellgröße sowohl den Speicherverbrauch als auch die FLOPs im Vergleich zur GQA-Konfiguration von Llama-3 um mehr als 50% reduziert, ohne die Modellleistung zu beeinträchtigen.
Dies ist insbesondere bei kundenspezifischen Implementierungen relevant, bei denen die Infrastrukturkosten einen erheblichen Anteil der Gesamtkosten ausmachen.
Automatisierte Umschulungsschleifen
Die OpenAI-Forschung zu selbstlernenden Agenten stellt wiederholbare Trainingsschleifen vor, die Grenzfälle erfassen und Fehler ohne ständiges menschliches Eingreifen korrigieren. Systeme, die minderwertige Ausgaben identifizieren und sich anhand von Feedback automatisch neu trainieren, reduzieren sowohl die Fehlerraten als auch den Token-Verbrauch durch die erneute Generierung fehlerhafter Antworten.
Analyseplattformen, die Kennzahlen zur Ausgabequalität erfassen, ermöglichen diese automatisierten Verbesserungszyklen und führen so im Laufe der Zeit zu kumulativen Kostenvorteilen.
Bewertung des ROI von Investitionen in Analytik
Analyseplattformen verursachen zusätzliche Kosten – Abonnements, Integrationsaufwand, laufende Wartung. Unternehmen benötigen Rahmenbedingungen, um zu bewerten, ob Investitionen einen positiven Ertrag bringen.
Berechnung der Gewinnschwelle
Studien zur Kosten-Nutzen-Analyse von On-Premise-LLM-Implementierungen untersuchen, wann Unternehmen im Vergleich zu kommerziellen Diensten die Gewinnschwelle erreichen. Dieselbe Methodik gilt für Analysetools: Berechnung der monatlichen LLM-Ausgaben, Schätzung der erzielbaren Kostensenkung durch Optimierungsfunktionen und Vergleich mit den Abonnementkosten der Plattform.
Wenn beispielsweise die monatlichen LLM-Kosten $50.000 erreichen und Analysen durch Caching und Modellauswahl eine Reduzierung um 30% ermöglichen, entspricht dies einer monatlichen Einsparung von $15.000. Eine Analyseplattform mit monatlichen Kosten von $2.000 amortisiert sich sofort und erzielt einen monatlichen Nettogewinn von $13.000.
Quantifizierung von Effizienzgewinnen im Betrieb
Kostensenkung ist nur ein Teil der Wertgleichung. Analyseplattformen reduzieren den Zeitaufwand für Entwickler bei der manuellen Untersuchung von Leistungsproblemen, dem Debuggen aufwändiger Abfragen und der Erstellung von Nutzungsberichten.
Branchenberichten zufolge konnten Teams ihre Produktivität deutlich steigern, indem sie mithilfe geeigneter Analysen Engpässe bei der Fehlersuche beseitigten. Die dadurch eingesparte Zeit führt direkt zu geringeren Arbeitskosten oder einer höheren Entwicklungsgeschwindigkeit.
Berücksichtigung des Risikominderungswerts
Budgetwarnungen und Anomalieerkennung verhindern Kostenkatastrophen. Organisationen ohne angemessene Überwachung bemerken Kostenexplosionen erst Tage oder Wochen später – wenn die Rechnungen eintreffen.
Der Wert, eine unerwartete Rechnung in Höhe von 100.000 USD ($100.000) zu vermeiden, rechtfertigt erhebliche Investitionen in Analytik. Die Vorteile der Risikominderung sind schwieriger zu quantifizieren, wirken sich aber wesentlich auf die Gesamtbetriebskosten aus.
Lokale vs. Cloud-basierte Analytik
Organisationen, die selbstgehostete LLMs einsetzen, stehen vor anderen Analyseanforderungen als solche, die ausschließlich kommerzielle APIs verwenden.
Vorteile der Cloud-Analyse
Cloudbasierte Analyseplattformen erfordern minimalen Einrichtungsaufwand, skalieren automatisch und erhalten kontinuierliche Funktionsupdates ohne manuelle Eingriffe. Sie eignen sich gut für Organisationen, die kommerzielle LLM-Dienste nutzen, bei denen die API-basierte Nachverfolgung ausreichende Transparenz bietet.
Die Integration beinhaltet typischerweise das Hinzufügen von SDK-Aufrufen oder das Weiterleiten von Anfragen über Gateway-Dienste – für die meisten Entwicklungsteams unkompliziert.
Überlegungen zur Bereitstellung vor Ort
Selbstgehostete Analyselösungen eignen sich für Organisationen mit strengen Anforderungen an die Datenverwaltung oder solche, die proprietäre Modelle intern betreiben. Laut einer Studie der Stanford University zum Thema „Intelligenz pro Watt“ können lokale LLMs 88,71 TP3T an Chat- und Logikaufgaben mit nur einer Gesprächsrunde präzise beantworten, wodurch sich Self-Hosting für viele Anwendungsfälle als praktikabel erweist.
On-Premise-Implementierungen sind jedoch komplexer. Unternehmen benötigen die Infrastruktur für die Analyseplattform selbst, müssen Aktualisierungen manuell durchführen und benötigen spezialisiertes Fachwissen für die Systemwartung.
Hybride Ansätze
Viele Organisationen setzen auf Hybridstrategien: Cloud-Analysen für die kommerzielle Nutzung von LLM werden mit On-Premise-Monitoring für selbstgehostete Modelle kombiniert. Dies schafft ein Gleichgewicht zwischen Komfort und Kontrolle und gewährleistet gleichzeitig umfassende Transparenz über den gesamten KI-Stack.
Zukunftstrends in der LLM-Kostenanalyse
Die Landschaft der Analytik entwickelt sich weiterhin rasant, da Unternehmen immer ausgefeiltere Fähigkeiten fordern.
Vorausschauende Kostenmodellierung
Plattformen der nächsten Generation prognostizieren zukünftige Kosten auf Basis von Nutzungstrends, Anwendungsänderungen und Preisanpassungen. Proaktive Warnmeldungen informieren Teams über bevorstehende Kostenspitzen, anstatt Probleme erst im Nachhinein zu melden.
Maschinelles Lernen, das auf der Grundlage historischer Nutzungsmuster trainiert wurde, kann die monatlichen Ausgaben mit zunehmender Genauigkeit prognostizieren und so eine bessere Budgetplanung ermöglichen.
Automatisierte Optimierungsagenten
Die Forschung zur automatisierten Optimierung von LLM-basierten Agenten (ARTEMIS) demonstriert Systeme, die kontinuierlich mit Konfigurationsänderungen experimentieren, die Auswirkungen messen und Verbesserungen automatisch ohne menschliches Eingreifen implementieren.
Diese selbstoptimierenden Systeme könnten das Kostenmanagement revolutionieren, indem sie manuelle Optimierungsarbeiten vollständig überflüssig machen. Erste Implementierungen zeigen vielversprechende Ergebnisse, befinden sich aber noch im experimentellen Stadium.
Anbieterübergreifende einheitliche Analysen
Unternehmen nutzen zunehmend mehrere LLM-Anbieter – OpenAI für bestimmte Aufgaben, Anthropic für andere und Open-Source-Modelle für spezifische Anwendungsfälle. Die einheitliche Datenanalyse über alle Anbieter hinweg bleibt eine Herausforderung.
Zukünftige Plattformen werden eine nahtlose Verfolgung mehrerer Anbieter ermöglichen und so einen echten, direkten Kostenvergleich sowie ein intelligentes Routing über verschiedene Anbieter hinweg auf Basis von Echtzeit-Preis- und Leistungsdaten gewährleisten.
Häufige Herausforderungen bei der Implementierung
Organisationen stoßen bei der Einführung von Analyseplattformen auf vorhersehbare Hindernisse. Die Antizipation dieser Herausforderungen beschleunigt die erfolgreiche Implementierung.
Unvollständige Nutzungszuordnung
Um nachzuverfolgen, welches Team, welche Funktion oder welcher Nutzer welche Kosten verursacht hat, ist eine entsprechende Instrumentierung in den gesamten Anwendungen erforderlich. Viele Organisationen erfassen zwar zunächst die Gesamtnutzung, aber es fehlt ihnen an einer detaillierten Zuordnung.
Lösung: Von Anfang an einheitliche Tagging-Standards implementieren. Jeder LLM-Anfrage Metadaten hinzufügen, die die Quellanwendung, den Benutzertyp und die Funktionskategorie identifizieren.
Wachsamkeitsmüdigkeit
Überempfindliche Kostenwarnungen verleiten Teams dazu, Benachrichtigungen zu ignorieren. Wenn jede noch so kleine Nutzungsspitze Alarm auslöst, werden wichtige Warnungen zusammen mit irrelevanten Informationen übersehen.
Lösung: Alarmschwellenwerte sollten auf statistischer Signifikanz statt auf absoluten Änderungen basieren. Ein Kostenanstieg gemäß 10% könnte eine Untersuchung rechtfertigen, wenn er über mehrere Tage anhält, nicht aber, wenn er nur eine Stunde andauert.
Optimierungsanalyse-Paralyse
Manche Teams verbringen mehr Zeit mit der Analyse von Optimierungsmöglichkeiten als mit deren Umsetzung. Die detaillierte Untersuchung jeder potenziellen Verbesserung erweist sich als kontraproduktiv.
Lösung: Wenden Sie die 80/20-Regel an. Konzentrieren Sie sich zunächst auf die Optimierungen mit der größten Wirkung – typischerweise Caching für wiederkehrende Arbeitslasten und Modellauswahl für Endpunkte mit hohem Datenaufkommen. Kleinere Optimierungen können warten.
Häufig gestellte Fragen
In welchem Umfang können Unternehmen die LLM-Kosten realistischerweise durch den Einsatz von Analysetools senken?
Die Kostenreduzierung variiert erheblich je nach anfänglicher Effizienz und Workload-Charakteristik. Organisationen mit wiederkehrenden Abfragen und ohne bestehendes Caching können allein durch Prompt-Caching Einsparungen von 50 bis 701 Tsd. erzielen. Unternehmen, die bereits grundlegende Optimierungen implementiert haben, verzeichnen typischerweise zusätzliche Einsparungen von 20 bis 401 Tsd. durch strategische Modellauswahl und Kontextoptimierung. Entscheidend ist, die Ressourcenverschwendung in Ihrer spezifischen Implementierung zu identifizieren – Analyseplattformen sind hervorragend geeignet, diese Optimierungspotenziale aufzudecken.
Sind Analyseplattformen mit allen LLM-Anbietern kompatibel?
Die meisten spezialisierten Analyseplattformen unterstützen große kommerzielle Anbieter wie OpenAI, Anthropic, Google und AWS Bedrock über Standard-API-Integrationen. Cloud-native Lösungen funktionieren in der Regel nur innerhalb ihrer jeweiligen Ökosysteme – AWS-Tools für Bedrock, Google-Tools für Vertex AI. Bei selbstgehosteten Modellen oder kleineren Anbietern hängt die Kompatibilität davon ab, ob die Plattform benutzerdefinierte Integrationsmöglichkeiten bietet oder spezielle Instrumentierung erfordert.
Wie sieht der typische Implementierungszeitraum für LLM-Analysen aus?
Die grundlegende Integration von Analysetools dauert bei Cloud-basierten Plattformen mit Standard-SDKs 1–2 Wochen. Dies umfasst Einrichtung, grundlegende Tagging-Implementierung und die erste Dashboard-Konfiguration. Eine umfassende Implementierung mit Session-Tracking, benutzerdefinierter Attributionsmodellierung und Optimierungsautomatisierung benötigt je nach Anwendungskomplexität 4–8 Wochen. Organisationen mit verteilten Systemen oder kundenspezifischen LLM-Implementierungen sollten für die vollständige Einführung inklusive Tests und Optimierung 2–3 Monate einplanen.
Sollten kleine Teams in dedizierte Analyseplattformen investieren?
Teams, deren monatliche Ausgaben für LLM unter 10.000 bis 15.000 liegen, können die Kosten oft mit den Standardtools des Cloud-Anbieters und manueller Überwachung ausreichend kontrollieren. Der Aufwand und die Kosten dedizierter Plattformen können in diesem Umfang die Vorteile überwiegen. Sobald die monatlichen LLM-Kosten 10.000 bis 15.000 übersteigen, erzielen spezialisierte Analysen in der Regel einen positiven ROI durch automatisierte Optimierung und detaillierte Transparenz. Berechnen Sie Ihr Einsparpotenzial: Wenn realistische Kostensenkungen die Abonnementkosten der Plattform um das Dreifache oder mehr übersteigen, ist eine Investition sinnvoll.
Wie handhaben Analysetools Ratenbegrenzung und Quotenmanagement?
Moderne Plattformen beinhalten benutzerdefinierte Ratenbegrenzungsfunktionen, die verhindern, dass Anwendungen die konfigurierten Nutzungsschwellenwerte überschreiten. Diese Systeme fangen Anfragen ab, bevor sie LLM-Anbieter erreichen, und weisen überschüssigen Datenverkehr gemäß definierten Richtlinien zurück oder reihen ihn in eine Warteschlange ein. Die Ratenbegrenzung verhindert sowohl Kostenüberschreitungen als auch die Erschöpfung des API-Kontingents der Anbieter. Einige Plattformen implementieren eine intelligente Warteschlangenverwaltung, die Anfragen mit hohem Wert in Zeiten begrenzter Kapazität priorisiert.
Können Analyseplattformen neben den Kosten auch die Latenz reduzieren?
Ja – viele Kostenoptimierungen verbessern gleichzeitig die Antwortzeiten. Caching erzielt die deutlichsten Latenzverbesserungen und reduziert die Antwortzeit zwischengespeicherter Abfragen laut AWS-Studien um bis zu 851 TP3T. Kleinere, schnellere Modelle, die für geeignete Aufgaben ausgewählt werden, reagieren oft schneller als überqualifizierte Frontier-Modelle und sind dabei kostengünstiger. Kontextoptimierung senkt sowohl die Kosten der Tokenverarbeitung als auch die Zeit, die für die Verarbeitung unnötig großer Eingaben benötigt wird. Die besten Analyseplattformen decken Optimierungspotenziale auf, bei denen Kosten- und Leistungsverbesserungen zusammenfallen.
Welche Kennzahlen sind für das Kostenmanagement im LLM-Bereich am wichtigsten?
Vier Kennzahlen bilden die Grundlage für ein effektives Kostenmanagement: Die monatlichen Gesamtausgaben erfassen die Auswirkungen auf das Gesamtbudget; die Kosten pro Nutzerinteraktion zeigen die Wirtschaftlichkeit verschiedener Funktionen; das Verhältnis von Eingabe- zu Ausgabetoken identifiziert kostenintensive Antwortmuster; und die Cache-Trefferrate misst, wie effektiv Caching redundante Verarbeitung reduziert. Zusammen ermöglichen diese Kennzahlen Teams, sowohl die Gesamtkosten als auch spezifische Optimierungspotenziale zu verstehen. Fortgeschrittene Teams ergänzen dies um die Genauigkeit der Modellauswahl – sie verfolgen, wie oft kostengünstigere Modelle die Qualitätsstandards einhalten.
Schlussfolgerung
LLM-Analysetools mit leistungsstarken Kostenoptimierungsfunktionen haben sich von nützlichen Überwachungslösungen zu einer unverzichtbaren Infrastruktur für jedes Unternehmen entwickelt, das KI in großem Umfang einsetzt. Die Kombination aus Echtzeit-Kostenverfolgung, Leistungsüberwachung und automatisierten Optimierungsfunktionen ermöglicht einen sofortigen ROI für Teams, die erhebliche Summen in Sprachmodell-APIs investieren.
Die kurze Antwort? Unternehmen können die LLM-Kosten durch systematische Optimierung mithilfe geeigneter Analysen um 20-70% senken – ohne Einbußen bei Antwortqualität oder Funktionalität. Doch Erfolg erfordert mehr als die Installation eines Dashboards. Effektives Kostenmanagement setzt klare Basiskennzahlen, realistische Optimierungsziele, eine schrittweise Implementierung und kontinuierliche Überwachung voraus.
Forschungsergebnisse des MIT, der Carnegie Mellon University und führender KI-Unternehmen belegen übereinstimmend, dass die Kombination aus strategischer Modellauswahl, intelligentem Caching, Kontextoptimierung und automatisiertem Routing kumulative Vorteile bietet. Teams, die Kostenoptimierung als kontinuierliche Disziplin und nicht als einmaliges Projekt betrachten, erzielen nachhaltige Reduzierungen und bleiben gleichzeitig flexibel genug, um neue Modelle und Funktionen zu integrieren.
Die Landschaft der Analyseplattformen bietet Lösungen für jedes Einsatzszenario – von Cloud-nativen Tools, die in führende Anbieter integriert sind, über spezialisierte Observability-Plattformen für Multi-Vendor-Umgebungen bis hin zu Open-Source-Alternativen für individuelle Anforderungen. Die Wahl der richtigen Plattform hängt von der Einsatzarchitektur, dem Budget und dem Optimierungsbedarf ab.
Beginnen Sie mit der Ermittlung der aktuellen Basiskosten und Nutzungsmuster. Identifizieren Sie die wirkungsvollsten Optimierungspotenziale speziell für Ihre Arbeitslast. Wählen Sie Analysetools, die umsetzbare Erkenntnisse liefern, anstatt Teams mit Rohdaten zu überfordern. Implementieren Sie Optimierungen schrittweise, messen Sie die Ergebnisse und optimieren Sie diese datenbasiert statt auf Annahmen beruhend.
Die erfolgreichsten Organisationen im Bereich LLM-Kostenmanagement weisen eine Gemeinsamkeit auf: Sie setzen umfassende Instrumente ein, analysieren kontinuierlich und optimieren systematisch. Da Sprachmodelle immer leistungsfähiger und verbreiteter werden, trennt diese Disziplin nachhaltige KI-Implementierungen von kostspieligen Experimenten, die nie den Produktionsmaßstab erreichen.
Bereit, Ihre LLM-Kosten zu optimieren? Beginnen Sie mit der Messung – was man nicht erfasst, kann man nicht verbessern. Wählen Sie eine Analyseplattform, die zu Ihrer Infrastruktur passt, implementieren Sie grundlegendes Tracking und lassen Sie die Daten aufzeigen, wo Ihre spezifische Implementierung Ressourcen verschwendet. Die Erkenntnisse werden Sie überraschen, und die Einsparungen werden den Aufwand rechtfertigen.