Kurzzusammenfassung: Die Kostenüberwachung von LLM unterstützt Unternehmen dabei, den Tokenverbrauch zu verfolgen, Budgetüberschreitungen zu vermeiden und die Ausgaben für KI-Workloads zu optimieren. Durch die Echtzeit-Transparenz der Modellnutzungsmuster können Teams kostspielige Ineffizienzen erkennen, bevor diese außer Kontrolle geraten. Die richtige Überwachungslösung liefert detaillierte Kostenaufschlüsselungen, Nutzungsanalysen und Governance-Kontrollen, die für den Produktiveinsatz unerlässlich sind.
Große Sprachmodelle haben sich von experimentellen Projekten zu Produktionssystemen entwickelt, die alles von Kundensupport bis hin zur Inhaltsgenerierung unterstützen. Doch hier liegt das Problem: Ohne angemessene Überwachung können die Kosten über Nacht explodieren.
Eine einzige nicht optimierte Eingabeaufforderungskette kann die Kosten um bis zu das Zehnfache erhöhen. Teams entdecken diese Budgetüberschreitungen oft erst nach Abschluss der Abrechnungszyklen, wenn der Schaden bereits angerichtet ist.
Hier geht es nicht nur um Kosteneinsparung. Kostenmonitoring schafft die nötige Transparenz für fundierte Entscheidungen hinsichtlich Modellauswahl, schneller Entwicklung und Infrastruktur. Organisationen, die KI-Workloads in großem Umfang einsetzen, benötigen umfassendes Tracking als unverzichtbare Betriebsanforderung.
Warum die Kostenkontrolle bei LLM-Einsätzen wichtig ist
Tokenbasierte Preisgestaltung bedeutet, dass jeder API-Aufruf Kosten verursacht. Im Gegensatz zu herkömmlicher Software, bei der die Rechenkosten relativ vorhersehbar sind, variieren die Kosten für LLM je nach Nutzungsmuster, Komplexität der Abfrage und Modellauswahl erheblich.
Der Übergang vom Prototyp zur Produktion verstärkt diese Herausforderung. Was bei Tests mit wenigen Anfragen gut funktionierte, ist im großen Maßstab finanziell nicht tragbar. Ohne kontinuierliche Transparenz wird Optimierung zum Ratespiel.
Reale Einsatzszenarien bringen zusätzliche Komplexität mit sich. Mehrere Teams verwenden möglicherweise unterschiedliche Modelle für verschiedene Anwendungen. Manche Workflows beinhalten verkettete Aufrufe, bei denen ein LLM-Output in einen anderen einfließt. RAG-Pipelines rufen Daten aus Vektordatenbanken ab, bevor sie Antworten generieren, was den Rechenaufwand erhöht.
Die Kostenüberwachung löst drei entscheidende Probleme. Erstens beugt sie unerwarteten Rechnungen vor, indem sie Ausgaben in Echtzeit statt rückwirkend erfasst. Zweitens deckt sie Optimierungspotenziale auf, indem sie zeigt, welche Eingabeaufforderungen, Modelle oder Nutzer die meisten Token verbrauchen. Drittens ermöglicht sie die Steuerung durch die Festlegung von Budgets und Warnmeldungen auf Projekt-, Team- oder Organisationsebene.
Wichtige Kennzahlen zur Verfolgung der LLM-Kosten
Effektives Monitoring erfordert die Erfassung der richtigen Kennzahlen. Der Tokenverbrauch bildet die Grundlage – sowohl der Input-Token (die Eingabeaufforderung) als auch der Output-Token (die generierte Antwort). Da verschiedene Modelle unterschiedliche Gebühren pro Token berechnen, geben die reinen Token-Zahlen kein vollständiges Bild.
Die Kosten pro Anfrage bieten eine standardisierte Sichtweise. Diese Kennzahl hilft, die Wirtschaftlichkeit verschiedener Ansätze zu vergleichen. Eine Anfrage, die ein teureres Modell nutzt, aber weniger Token generiert, kann günstiger sein als ein kostengünstigeres Modell mit ausführlicher Ausgabe.
Nutzungsmuster offenbaren wichtige Trends. Spitzenzeiten, Anfragevolumen pro Anwendung und Token-Verbrauch pro Benutzer oder Team zeigen, wo die Ausgaben konzentriert sind. Diese Muster decken oft unerwartete Ineffizienzen auf.
Die Modellauswahl hat direkten Einfluss auf die Kosten. Neuere Modelle sind in der Regel teurer als ältere. Bei Open-Source-Modellen, die lokal eingesetzt werden, fallen Infrastrukturkosten anstelle von Gebühren pro Token an. Die Analyse, welche Modelle welche Workloads verarbeiten, deckt Optimierungspotenziale auf.
Fehlerraten sind wichtiger, als den meisten Teams bewusst ist. Fehlgeschlagene API-Aufrufe verbrauchen weiterhin Tokens – und Budget. Hohe Fehlerraten deuten auf Integrationsprobleme hin, bedeuten aber auch unnötige Ausgaben, die durch eine bessere Fehlerbehandlung vermieden werden könnten.
LLM-Dienstleistungen vor Ort versus kommerziell
Unternehmen stehen vor einer grundlegenden Entscheidung: kommerzielle Dienste abonnieren oder Modelle auf ihrer eigenen Infrastruktur implementieren. Studien, die diesen Zielkonflikt analysieren, zeigen, dass die Wahl neben dem reinen Token-Preis noch weitere Kostenfaktoren umfasst.
Kommerzielle Dienste von Anbietern wie OpenAI, Anthropic und Google bieten eine attraktive Einfachheit. Teams zahlen nur für die genutzten Tokens und müssen sich nicht um Infrastruktur, Modellaktualisierungen oder den laufenden Betrieb kümmern. Dieser Ansatz ist leicht skalierbar, die Kosten steigen jedoch linear mit der Nutzung.
Die Bereitstellung vor Ort erfordert anfängliche Investitionen in die Infrastruktur. Basierend auf Kosten-Nutzen-Analysen müssen Unternehmen die Hardwarebeschaffung, den Stromverbrauch, die Kühlung, die Wartung und den Personalaufwand berücksichtigen. Der Break-Even-Punkt hängt vom Nutzungsvolumen ab – bei hohem Nutzungsvolumen sind On-Premise-Modelle oft vorteilhafter, während bei geringerem Volumen kommerzielle APIs die bessere Wahl sind.
Untersuchungen zur Kosten-Nutzen-Analyse von On-Premise-LLM-Implementierungen legen Kriterien für die Modellauswahl fest, darunter die Leistungsparität führender kommerzieller Modelle innerhalb des 20%-Standards. Dieser Schwellenwert spiegelt die Unternehmensnormen wider, wonach geringfügige Genauigkeitsunterschiede durch Kosteneinsparungen, Sicherheitsvorteile und Integrationsflexibilität kompensiert werden.
Versteckte Kosten in beiden Ansätzen
Kommerzielle Dienste bergen neben dem reinen Preis versteckte Kosten. Ratenbegrenzungen können ein Upgrade auf Premium-Tarife erforderlich machen. Bei der Verarbeitung großer Datenmengen fallen Gebühren für den Datentransfer an. Der Zugriff mehrerer Teammitglieder treibt die Abonnementkosten in die Höhe.
On-Premise-Implementierungen bergen versteckte Kosten. Die Feinabstimmung von Modellen erfordert Data Scientists. Die Infrastruktur muss redundant ausgelegt sein, um Zuverlässigkeit zu gewährleisten. Updates und Patches erfordern kontinuierliche Aufmerksamkeit. Der Aufwand für Sicherheit und Compliance steigt bei selbstgehosteten Lösungen.
Die Überwachung ist unabhängig von der gewählten Bereitstellungsmethode unerlässlich. Kommerzielle APIs müssen überwacht werden, um Kostenexplosionen zu vermeiden. Auch On-Premise-Systeme benötigen Überwachung, um die Ressourcennutzung zu optimieren und Infrastrukturinvestitionen zu rechtfertigen.
Unverzichtbare Werkzeuge und Technologien
Zur Deckung des Bedarfs an Kostenverfolgung im Bereich LLM sind verschiedene Monitoring-Lösungen entstanden. Diese Tools unterscheiden sich hinsichtlich ihrer Funktionen, Komplexität und idealen Anwendungsfälle.
LiteLLM bietet eine einheitliche Schnittstelle für verschiedene LLM-Anbieter. Es standardisiert API-Aufrufe und erfasst Token und Kosten zentral. Teams, die mit mehreren Anbietern arbeiten, profitieren von einer konsolidierten Überwachung, anstatt mehrere Dashboards prüfen zu müssen.
Langfuse bietet Open-Source-Observability speziell für LLM-Anwendungen. Es erfasst Kosten und Qualitätsmetriken und ermöglicht so Einblicke in das Verhältnis von Ausgaben und Ergebnisqualität. Die Plattform unterstützt komplexe Workflows, darunter RAG-Pipelines und mehrstufige Agentenketten.
Datadog LLM Observability erweitert die bestehende Infrastrukturüberwachung auf KI-Workloads. Unternehmen, die Datadog bereits nutzen, können LLM-Tracking hinzufügen, ohne neue Tools einführen zu müssen. Die Integration verknüpft Kostendaten mit umfassenderen Systemleistungskennzahlen.
| Lösungstyp | Am besten geeignet für | Hauptstärke | Rücksichtnahme |
|---|---|---|---|
| Einheitlicher Proxy | Multi-Provider-Setups | Einheitliche Schnittstelle für alle LLMs | Fügt eine Latenzschicht hinzu |
| Open-Source-Plattform | Anpassungsbedarf | Volle Kontrolle und Transparenz | Erfordert Selbsthosting. |
| Unternehmens-Observabilität | Große Organisationen | Lässt sich in bestehende Tools integrieren | Höhere Kostenstruktur |
| Anbieter-Native-API | Nutzung durch einen einzigen Anbieter | Genaueste Daten | Eingeschränkte anbieterübergreifende Sicht |
Anbietereigene Lösungen ermöglichen den programmatischen Zugriff auf API-Nutzungs- und Kostendaten von Organisationen. Dieser Ansatz funktioniert gut bei der Standardisierung auf einen einzigen Anbieter, birgt aber in Umgebungen mit mehreren Anbietern Schwachstellen.

Erstellen Sie LLM-Systeme mit übersichtlicher Nutzungsüberwachung
LLM-basierte Anwendungen benötigen eine angemessene Überwachung und Infrastruktur, um Anfragen, Nutzung und Systemleistung zu verwalten. AI Superior Das Unternehmen entwickelt KI-Plattformen, auf denen große Sprachmodelle mit Backend-Diensten, Datenpipelines und Analysetools integriert werden. Die Ingenieure des Unternehmens entwickeln Systeme, die eine zuverlässige Modellbereitstellung, Protokollierung und Leistungsüberwachung in Produktionsumgebungen unterstützen.
Einführung eines LLM-Systems in der Produktion?
Sprechen Sie mit einer KI, die überlegen ist gegenüber:
- Design der LLM-Infrastruktur und Backend-Dienste
- Erstellen Sie NLP-Anwendungen, die auf Sprachmodellen basieren.
- Integration von Überwachung und Analyse in KI-Systeme
👉 Kontakt AI Superior um Ihr KI-Entwicklungsprojekt zu besprechen.
Implementierung der Echtzeit-Kostenverfolgung
Echtzeitüberwachung ermöglicht sofortige Transparenz anstelle von nachträglicher Analyse. Diese Funktion ermöglicht ein proaktives Kostenmanagement anstelle reaktiver Schadensbegrenzung.
Die Implementierung umfasst typischerweise drei Komponenten. Erstens erfasst die Instrumentierung die Tokenanzahl jedes LLM-Aufrufs. Zweitens aggregiert eine zentrale Datenbank diese Daten mit zugehörigen Metadaten wie Benutzer, Anwendung und Zeitstempel. Drittens visualisieren Dashboards Ausgabenmuster und lösen Warnmeldungen aus, sobald Schwellenwerte überschritten werden.
PostgreSQL-Datenbanken dienen häufig als Speicherschicht für Kostenüberwachungssysteme. Die Datenbank speichert Token-Zähler, Kostenberechnungen und Nutzungsmetadaten. Dieser Ansatz bietet Flexibilität für benutzerdefinierte Abfragen und bewältigt gleichzeitig das Schreibvolumen von Produktionsanwendungen.
Integrierte Dashboards wandeln Rohdaten in wertvolle Erkenntnisse um. Effektive Dashboards zeigen die aktuellen Ausgaben, vergleichen sie mit Budgets, heben die wichtigsten Kunden hervor und decken Trends im Zeitverlauf auf. Die besten Implementierungen ermöglichen es, von der Organisationsebene bis hin zu Details einzelner Anfragen zu navigieren.
Benachrichtigungen und Budgets einrichten
Die Konfiguration von Warnmeldungen beugt Budgetüberraschungen vor. Teams sollten mehrere Warnstufen festlegen – Warnschwellenwerte, die auf erhöhte Ausgaben hinweisen, und kritische Grenzwerte, die ein Eingreifen auslösen.
Die Budgetverteilung funktioniert am besten hierarchisch. Unternehmensweite Budgets legen die Gesamtobergrenzen fest. Abteilungs- oder Projektbudgets ermöglichen eine detaillierte Kontrolle. Obergrenzen pro Benutzer oder Anwendung verhindern unkontrollierte Kosten durch einzelne Probleme.
Benachrichtigungskanäle sind wichtig. E-Mail-Benachrichtigungen eignen sich für nicht dringende Warnungen. Slack- oder Teams-Integrationen verbessern die Teamkommunikation. PagerDuty oder ähnliche Systeme helfen bei kritischen Budgetüberschreitungen, die ein sofortiges Eingreifen erfordern.
Kostenoptimierung durch Monitoring-Einblicke
Kostenüberwachung generiert Daten. Optimierung wandelt diese Daten in Einsparungen um.
Prompt-Engineering erweist sich als zentraler Optimierungshebel. Die Überwachung zeigt, welche Prompts übermäßig viele Token verbrauchen. Kürzere, fokussiertere Prompts reduzieren die Inputkosten. Die Begrenzung der Ausgabelänge verhindert ausführliche Antworten, die Budget verschwenden.
Die Optimierung der Modellauswahl nutzt Kostendaten, um Arbeitslasten den passenden Modellen zuzuordnen. Einfache Aufgaben benötigen nicht die leistungsstärksten (und teuersten) Modelle. Die Überwachung identifiziert Möglichkeiten, Anfragen an kostengünstigere Alternativen weiterzuleiten, ohne die Qualität zu beeinträchtigen.
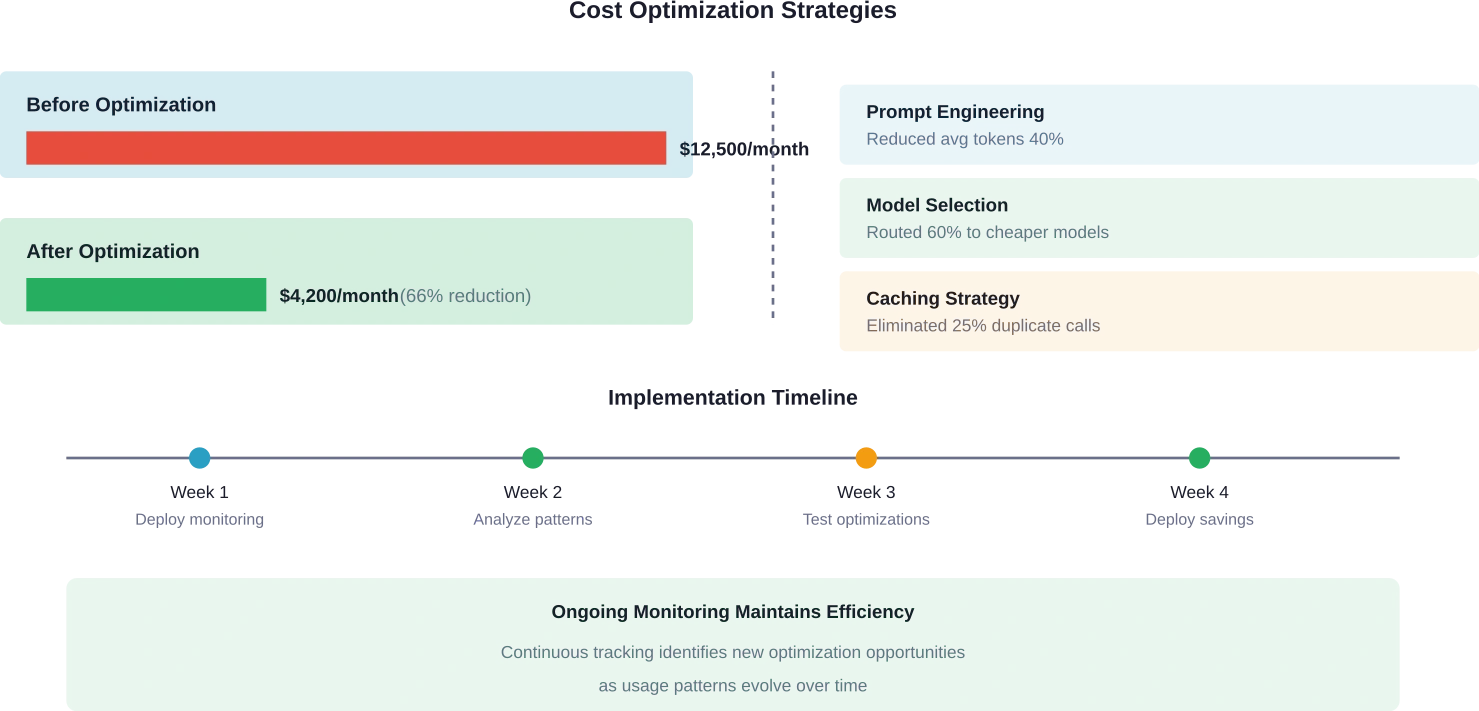
Caching-Strategien vermeiden die doppelte Verarbeitung von Daten. Stellen mehrere Nutzer ähnliche Fragen, verhindert das Zwischenspeichern der ersten Antwort die erneute Generierung identischer Inhalte. Die Überwachung identifiziert häufige Anfragen, die am meisten vom Caching profitieren.
Die Stapelverarbeitung von Anfragen fasst nach Möglichkeit mehrere Operationen zusammen. Manche Workflows führen zahlreiche kleine API-Aufrufe durch, die konsolidiert werden könnten. Die Überwachung der Nutzungsmuster deckt Möglichkeiten zur Stapelverarbeitung auf, wodurch Kosten und Latenz reduziert werden.
Governance- und Nutzungskontrollen
Kostenüberwachung ermöglicht eine Steuerung, die über die reine Kostenverfolgung hinausgeht. Organisationen benötigen Kontrollmechanismen, um Richtlinien durchzusetzen und unautorisierte Ausgaben zu verhindern.
Die rollenbasierte Zugriffskontrolle legt fest, wer welche Modelle verwenden darf. Entwicklungsteams greifen möglicherweise für Testzwecke auf teure Modelle zu, während Produktionsanwendungen kostengünstigere Alternativen nutzen. Die Überwachung gewährleistet die Einhaltung dieser Richtlinien.
Die Begrenzung der Zugriffsrate verhindert, dass Missbrauch oder Fehlkonfigurationen zu Budgetüberschreitungen führen. Benutzer- oder anwendungsspezifische Begrenzungen deckeln den maximalen Tokenverbrauch innerhalb festgelegter Zeiträume. Diese Kontrollmechanismen schützen vor Endlosschleifen und unerwarteten Nutzungsspitzen.
Genehmigungsprozesse erhöhen den Aufwand bei kostenintensiven Vorgängen. Forschungsanwendungen, die neue Anwendungsfälle untersuchen, benötigen möglicherweise eine explizite Genehmigung, bevor sie auf Premium-Modelle zugreifen können. Das Monitoring liefert die Nutzungsdaten, die zur Bewertung dieser Anfragen erforderlich sind.
Compliance- und Prüfungsanforderungen
Viele Branchen unterliegen regulatorischen Anforderungen im Zusammenhang mit dem Einsatz von KI. Finanzinstitute müssen einen verantwortungsvollen Umgang mit KI nachweisen. Organisationen im Gesundheitswesen müssen Datenschutzbestimmungen einhalten.
Die Kostenüberwachung generiert Prüfprotokolle, die aufzeigen, welche Benutzer auf welche Modelle mit welchen Daten zugegriffen haben. Diese Dokumentation unterstützt Compliance-Maßnahmen und ermöglicht gleichzeitig forensische Analysen bei auftretenden Problemen.
Richtlinien zur Datenaufbewahrung legen fest, wie lange Nutzungsdatensätze gespeichert werden. Eine längere Aufbewahrung ermöglicht Trendanalysen, erhöht aber die Speicherkosten. Unternehmen wägen diese Aspekte anhand ihrer spezifischen Compliance-Anforderungen ab.
Integration mit Contact Center Analytics
Kontaktzentren stellen ein typisches Anwendungsgebiet für LLM-basierte Lösungen dar. Studien zur Gewinnung von Erkenntnissen aus LLM-basierten Analysen für Kontaktzentren zeigen, dass Unternehmen Sprachmodelle für Self-Service-Tools, administrative Automatisierung und die Steigerung der Mitarbeiterproduktivität einsetzen.
Diese Implementierungen führen zu einem massiven Tokenverbrauch. Die Überwachung ist daher für einen kosteneffizienten Betrieb unerlässlich. Die Studie beschreibt Systeme, die automatisch Erkenntnisse aus Kundeninteraktionen gewinnen und gleichzeitig die Implementierungskosten kontrollieren.
Zero-Shot-Baselines mit Modellen wie GPT-3.5-Turbo bieten Ausgangspunkte für Contact-Center-Anwendungen. Feinabgestimmte Modelle liefern eine höhere Genauigkeit, erfordern jedoch zusätzliche Infrastruktur und Wartung. Die Kostenüberwachung hilft, diese Vor- und Nachteile abzuwägen, indem sie die finanziellen Auswirkungen jedes Ansatzes verfolgt.
Die Forschung legt den Schwerpunkt auf umfassende Topic-Modeling-Experimente zur Ermittlung optimaler Skalierungsfaktoren. Diese Experimente basieren auf einer detaillierten Kostenverfolgung, um Genauigkeitsverbesserungen gegen erhöhte Ausgaben abzuwägen.
Überlegungen zur Integration des Finanzsektors
Finanzinstitute stehen bei der Integration sprachbasierter Modelle vor besonderen Herausforderungen. Die Forschung zu strategischen Rahmenwerken für die Integration sprachbasierter Modelle im Finanzbereich zeigt auf, wie Organisationen Sprachmodelle für Kreditwürdigkeitsprüfungen, Kundenberatungsdienste und die Automatisierung sprachintensiver Prozesse einsetzen.
Eine erfolgreiche Implementierung erfordert verantwortungsvolle Innovation, die Leistungsfähigkeit und Risikomanagement in Einklang bringt. Kostenüberwachung unterstützt dieses Gleichgewicht, indem sie Einblick in Nutzungsmuster und Ausgabentrends ermöglicht.
Finanzorganisationen wenden in der Regel strengere Governance-Richtlinien an als andere Branchen. Überwachungstools müssen detaillierte Prüfprotokolle, rollenbasierte Zugriffskontrollen und Compliance-Berichte unterstützen. Die Integration in bestehende Risikomanagementsysteme ist unerlässlich.
Die Studie zeigt, dass Finanzinstitute aller Größen zunehmend LLMs einsetzen. Kleinere Organisationen benötigen kosteneffiziente Überwachungslösungen. Größere Institute benötigen hingegen Governance-Lösungen und Skalierbarkeit auf Unternehmensebene.
Die richtige Überwachungslösung auswählen
Die Auswahl eines Überwachungsinstruments hängt von den spezifischen Bedürfnissen der Organisation ab. Mehrere Faktoren beeinflussen diese Entscheidung.
Die Unterstützung mehrerer Anbieter ist wichtig, wenn mehrere LLM-Anbieter eingesetzt werden. Organisationen, die sich auf einen einzigen Anbieter festlegen, priorisieren möglicherweise eine tiefere Integration gegenüber einer umfassenden Kompatibilität.
Die Flexibilität bei der Bereitstellung beeinflusst sowohl Kosten als auch Kontrolle. Cloud-basierte Lösungen minimieren den Betriebsaufwand. Selbstgehostete Optionen bieten mehr Anpassungsmöglichkeiten und Datensouveränität.
Die Integrationsmöglichkeiten bestimmen, wie Überwachungsdaten in bestehende Systeme fließen. Der API-Zugriff ermöglicht die Erstellung benutzerdefinierter Dashboards. Webhooks unterstützen ereignisgesteuerte Automatisierung. Vorkonfigurierte Konnektoren vereinfachen die Integration mit gängigen Tools.
| Besonderheit | Startup-Bedarf | Unternehmensbedarf |
|---|---|---|
| Kostenverfolgung | Grundlegende Token-Zählung | Mehrdimensionale Analyse |
| Governance | Einfache Budgets | Komplexe Genehmigungsprozesse |
| Integration | Eigenständiges Dashboard | Konnektivität von Unternehmenstools |
| Unterstützung | Community-Foren | Engagierte Unterstützung |
| Einsatz | Cloud-basierte Lösungen bevorzugt | Option vor Ort erforderlich |
Die Skalierbarkeitsanforderungen variieren je nach Unternehmensgröße und Wachstumsprognose. Tools, die für Dutzende Anfragen pro Tag gut funktionieren, können bei Tausenden pro Minute an ihre Grenzen stoßen. Die Kenntnis des zu erwartenden Volumens verhindert, dass die Überwachungsinfrastruktur mit dem Wachstum zunimmt.
Die Budgetierung der Monitoring-Lösung selbst stellt eine zusätzliche Herausforderung dar. Zu hohe Ausgaben für Monitoring sind kontraproduktiv. Kosteneffiziente Lösungen sollten nur einen minimalen Anteil der gesamten KI-Ausgaben ausmachen.
Zukunftstrends im Kostenmanagement des LLM
Die Kostenüberwachung entwickelt sich parallel zum gesamten LLM-Ökosystem stetig weiter. Mehrere Trends verändern die Art und Weise, wie Unternehmen das Ausgabenmanagement angehen.
- Die vorausschauende Kostenmodellierung nutzt historische Daten, um zukünftige Ausgaben zu prognostizieren. Algorithmen des maschinellen Lernens erkennen Muster und projizieren Kosten unter verschiedenen Szenarien. Diese Fähigkeit ermöglicht eine proaktive Budgetplanung anstelle reaktiver Anpassungen.
- Die automatisierte Optimierung nutzt Erkenntnisse aus der Überwachung und implementiert Verbesserungen ohne manuelles Eingreifen. Systeme leiten Anfragen automatisch an kostenoptimale Modelle weiter, passen Caching-Parameter an und komprimieren Eingabeaufforderungen bei gleichbleibender Qualität.
- Die anbieterübergreifende Kostenarbitrage überwacht die Preise verschiedener Anbieter und leitet Anfragen an die kostengünstigste Option für jede Arbeitslast weiter. Dieser Ansatz erfordert Kostendaten in Echtzeit und eine ausgefeilte Routing-Logik.
- Die Erfassung des CO₂-Fußabdrucks erweitert die Überwachung über die finanziellen Kosten hinaus auf die Umweltauswirkungen. Angesichts des zunehmenden Drucks auf Unternehmen im Bereich Nachhaltigkeit wird das Verständnis des Energieverbrauchs im Zusammenhang mit KI-Workloads immer wichtiger.
Häufig gestellte Fragen
Um wie viel reduziert die Überwachung der LLM-Kosten typischerweise die Ausgaben?
Organisationen, die umfassendes Monitoring und Optimierung implementieren, können die LLM-Kosten deutlich senken. Die genauen Einsparungen hängen davon ab, wie optimiert die anfängliche Implementierung war. Teams ohne vorheriges Monitoring erzielen oft die größten Einsparungen. Die Vorteile ergeben sich primär aus einer schnellen Entwicklung, der Optimierung der Modellauswahl und der Vermeidung unnötiger Doppelaufrufe.
Sind Monitoring-Tools anbieterübergreifend bei verschiedenen LLM-Anbietern einsetzbar?
Ja, diverse Monitoring-Lösungen unterstützen Umgebungen mit mehreren Anbietern. Tools wie LiteLLM schaffen eine einheitliche Schnittstelle für OpenAI, Anthropic, Google und andere Anbieter. Diese Lösungen standardisieren API-Aufrufe und ermöglichen eine zentrale Kostenverfolgung. Das Monitoring mit nur einem Anbieter liefert zwar in der Regel detailliertere Metriken, birgt aber bei der Verwendung mehrerer Anbieter Risiken.
Worin besteht der Unterschied zwischen Kostenüberwachung und LLM-Beobachtbarkeit?
Die Kostenüberwachung konzentriert sich speziell auf die Nachverfolgung der Token-Nutzung und -Ausgaben. Die LLM-Observability umfasst neben den Kosten ein breiteres Spektrum an Metriken, darunter Qualität, Latenz, Fehlerraten und Nutzerzufriedenheit. Observability-Plattformen bieten einen umfassenden Einblick in den Zustand von LLM-Anwendungen. Die Kostenüberwachung ist ein wichtiger Bestandteil der Observability, aber nicht das vollständige Bild.
Wie unterscheiden sich On-Premise-Bereitstellungen im Umgang mit der Kostenüberwachung?
Bei On-Premise-Bereitstellungen werden die Infrastrukturkosten anstelle der Gebühren pro Token erfasst. Das Monitoring konzentriert sich auf GPU-Auslastung, Stromverbrauch und Durchsatz. Das Ziel verschiebt sich von der Minimierung des Tokenverbrauchs hin zur Maximierung der Hardwareeffizienz. Teams müssen die internen Kosten pro Token auf Basis der Infrastrukturausgaben berechnen, um sie mit kommerziellen Alternativen zu vergleichen.
Sollte jede Organisation Echtzeitüberwachung implementieren oder ist eine Stapelanalyse ausreichend?
Echtzeitüberwachung wird bei großem Umfang oder knappen Budgets unerlässlich. Organisationen, die täglich Tausende von Anfragen verarbeiten, benötigen sofortige Transparenz, um Kostenexplosionen zu vermeiden. Kleinere Implementierungen mit vorhersehbarer Nutzung können auf Batch-Analysen der täglichen oder wöchentlichen Ausgaben zurückgreifen. Der Aufwand und die Komplexität von Echtzeitsystemen lohnen sich nur dann, wenn das Risiko von Budgetüberschreitungen die Investition rechtfertigt.
Wie wirkt sich Caching auf die Genauigkeit der Kostenüberwachung aus?
Caching reduziert die Anzahl der LLM-API-Aufrufe, jedoch muss das Monitoring sowohl zwischengespeicherte als auch nicht zwischengespeicherte Anfragen erfassen. Effektives Monitoring unterscheidet Cache-Treffer von Cache-Fehlern, um die tatsächlichen Kosteneinsparungen zu berechnen. Ohne diese Unterscheidung könnten Teams die tatsächlichen Ausgaben überschätzen. Die Cache-Trefferrate wird neben dem Token-Verbrauch zu einer wichtigen Optimierungsmetrik.
Welche Rolle spielt Monitoring in der Governance des LLM-Programms?
Monitoring bildet die Datengrundlage für Governance-Richtlinien. Die Nutzungsanalyse ermöglicht die Einhaltung von Budgets, die Begrenzung von Datenraten und die Kontrolle von Zugriffen. Prüfprotokolle aus Monitoringsystemen belegen die Einhaltung interner Richtlinien und externer Vorschriften. Governance-Richtlinien ohne Monitoringdaten sind lediglich nicht durchsetzbare Empfehlungen und keine wirksamen Kontrollmechanismen.
Kontrolle über die LLM-Ausgaben
Die Kostenüberwachung wandelt LLM-Implementierungen von unvorhersehbaren Kostenfaktoren in überschaubare, optimierte Systeme um. Die dadurch gewonnene Transparenz ermöglicht fundierte Entscheidungen hinsichtlich Modellauswahl, zügiger Entwicklung und Infrastrukturplanung.
Unternehmen, die KI-Workloads in die Produktion überführen, können es sich nicht leisten, diesen Schritt zu überspringen. Die Tools und Techniken zur Kostenkontrolle, Vermeidung von Kostenüberschreitungen und kontinuierlichen Kostenoptimierung sind bereits vorhanden. Der Implementierungsaufwand amortisiert sich durch die reduzierten Ausgaben innerhalb weniger Wochen.
Beginnen Sie mit der grundlegenden Token-Verfolgung, falls Ihnen ein umfassendes Monitoring zu komplex erscheint. Schon ein einfacher Überblick darüber, welche Anwendungen und Nutzer die meisten Token verbrauchen, deckt Optimierungspotenziale auf. Erweitern Sie das Monitoring mit zunehmender Größe Ihrer Implementierungen hin zu Echtzeit-Monitoring, automatisierten Benachrichtigungen und Governance-Kontrollen.
Den Wettbewerbsvorteil sichern sich Teams, die KI effektiv einsetzen und gleichzeitig die Kosten verantwortungsvoll managen. Monitoring ermöglicht beides – einen zügigen Einsatz ohne unüberlegte Ausgaben. Organisationen, die das Kostenmonitoring beherrschen, können neue LLM-Anwendungen mit Zuversicht erkunden, da sie die finanzielle Kontrolle behalten.