Kurzzusammenfassung: Strategien zur Kostenoptimierung im Bereich Lifecycle Management (LLM) helfen Unternehmen, Betriebskosten zu senken und gleichzeitig die KI-Leistung aufrechtzuerhalten. Zu den wichtigsten Ansätzen gehören die schnelle Optimierung, das Modellrouting, Caching, Quantisierung und die Infrastrukturoptimierung. Studien zeigen, dass diese Techniken die Kosten durch Methoden wie schnelle Komprimierung, strategische Modellauswahl und effizientes Token-Management um 10 bis 501 Tsd. Billionen US-Dollar senken können.
Die Betriebskosten für den Einsatz großer Sprachmodelle in der Produktion können schnell explodieren. Was als vielversprechender Machbarkeitsnachweis beginnt, wird bei Millionen von API-Aufrufen pro Monat zu einer finanziellen Belastung.
Organisationen, die LLMs einsetzen, stehen vor einer harten Realität: Die Verarbeitungskosten steigen linear mit der Nutzung. Für ein Modell mit etwa 175 Milliarden Parametern würde der benötigte Speicherplatz ca. 350 GB (für FP16) bzw. 700 GB (für FP32) betragen. Das ist nur der Speicherplatz – die eigentlichen Inferenzkosten steigen mit jedem verarbeiteten Token.
Aber das Entscheidende ist: Kostenoptimierung bedeutet nicht, die Leistung zu beeinträchtigen. Strategische Ansätze können die Ausgaben drastisch senken und gleichzeitig die Qualität der Ergebnisse erhalten oder sogar verbessern.
LLM-Preismodelle verstehen
Die meisten cloudbasierten LLM-Dienste berechnen die Gebühren pro Token. Nutzer zahlen separat für Eingabe-Token (die Eingabeaufforderung) und Ausgabe-Token (die generierte Antwort). Dieser Mechanismus der Bezahlung pro Token erzeugt interessante Dynamiken.
Forschungen des MIT-IBM Watson AI Lab (in “A Hitchhiker's Guide to Scaling Law Estimation”, 2024/2025) zeigen, dass ein durchschnittlicher relativer Fehler (ARE) von ca. 4% die bestmögliche Vorhersagegenauigkeit bei der Schätzung von Skalierungsgesetzen darstellt (d. h. bei der Prognose des Verlusts großer Modelle anhand kleinerer Modelle derselben Familie). Dies ist hauptsächlich auf zufälliges Rauschen im Startwert zurückzuführen, das selbst bei identischen Trainingskonfigurationen Unterschiede von bis zu ca. 4% im endgültigen Verlust verursachen kann. Ein ARE von bis zu 20% ist für viele praktische Entscheidungsaufgaben bei der Modellauswahl und Budgetverteilung weiterhin nützlich. Diese Aspekte sind wichtig für die Bewertung des Kosten-Nutzen-Verhältnisses verschiedener Modellfamilien oder -größen.
Zwischengespeicherte Eingabetoken kosten typischerweise etwa 10 Prozent der Kosten normaler Eingabetoken. Diese Preisasymmetrie bietet Möglichkeiten für erhebliche Einsparungen durch strategische Caching-Ansätze.
Die Preisstruktur führt dazu, dass die Generierung von Outputs für die meisten Anbieter teurer ist als die Inputverarbeitung. Diese grundlegende Tatsache treibt verschiedene Optimierungsstrategien voran, die den Tokenverbrauch von teuren Outputs hin zu günstigeren Inputs verlagern.
Techniken zur schnellen Optimierung
Die Optimierung der Eingabeaufforderungen bietet das größte Potenzial zur Kostenreduzierung. Schlecht strukturierte Eingabeaufforderungen verschwenden Token und erzeugen unnötige Ergebnisse.
Komprimieren ohne Kontextverlust
Ausführliche Eingabeaufforderungen verbrauchen viele Eingabefelder. Eine Produktbeschreibungsanfrage könnte beispielsweise lauten: “Erstellen Sie eine aussagekräftige Produktbeschreibung für ein Smartphone. Diese sollte die wichtigsten Merkmale und Spezifikationen wie Bildschirmgröße, Kameraauflösung, Akkulaufzeit und Speicherkapazität enthalten. Versuchen Sie, sie ansprechend und überzeugend zu gestalten.”
Die optimierte Version: “Erstellen Sie eine überzeugende Produktbeschreibung für ein Smartphone mit 6,5-Zoll-Display, 48-MP-Kamera, 5000-mAh-Akku und 256 GB Speicher.”
Gleiches Ziel, weniger Token, präzisere Anleitung. Dieser Ansatz senkt die Inputkosten und verbessert gleichzeitig häufig die Outputqualität durch Genauigkeit.
Strukturieren Sie die Ergebnisse strategisch
Strukturierte Ausgaben minimieren den Tokenverbrauch. Anstatt nach Freitextantworten zu fragen, die analysiert werden müssen, sollten JSON oder spezifische Formate angefordert werden. Diese Technik kommt in Produktionssystemen zum Einsatz, in denen E-Agent-Frameworks strukturierte Ausgaben verwenden, um die Länge der Kandidatenantworten zu minimieren.
Laut der Dokumentation von OpenAI zur Feinabstimmung des Reinforcement Learnings ermöglichen klare Aufgabenspezifikationen mit überprüfbaren Antworten ein effizienteres Modellverhalten. Explizite Bewertungskriterien und codebasierte Bewertungsalgorithmen messen den funktionalen Erfolg und reduzieren gleichzeitig unnötige Ausführlichkeit.
| Eingabeaufforderungstyp | Token-Nutzung | Kostenauswirkungen | Am besten geeignet für
|
|---|---|---|---|
| Ausführlich, unstrukturiert | Hoch | Ausgangswert | Explorationsphase |
| Komprimiert, strukturiert | Medium | 20-30%-Reduzierung | Produktionsbereitstellungen |
| Zwischengespeichert mit Struktur | Niedrig | 40-50% Reduzierung | Wiederkehrende Aufgaben |
Strategische Modellauswahl und Routing
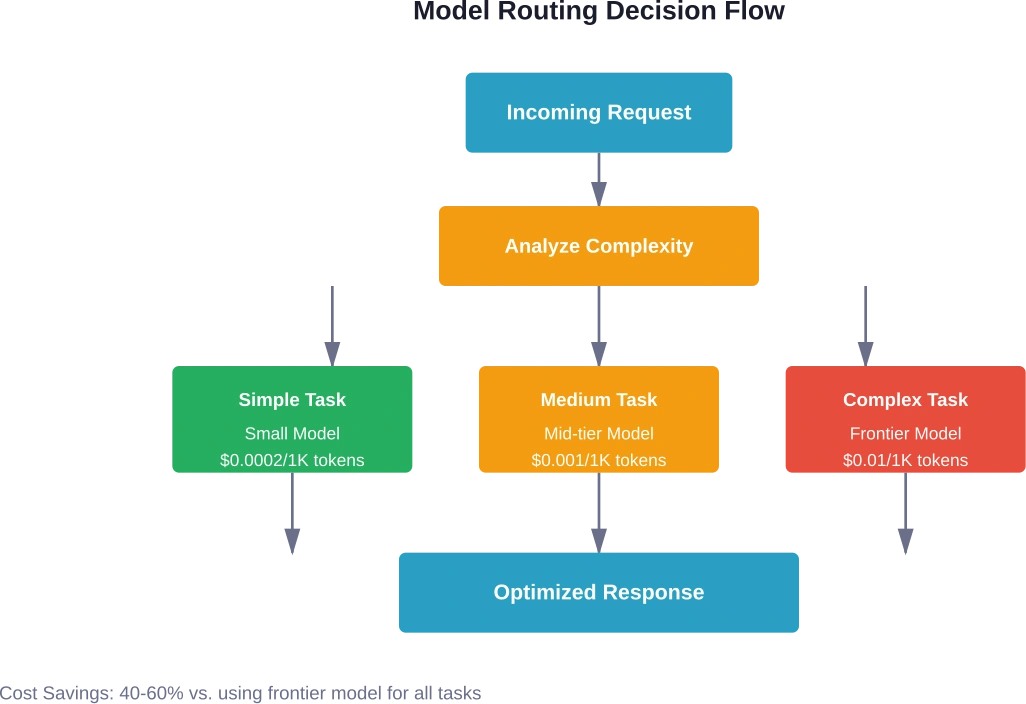
Nicht jede Aufgabe erfordert das leistungsstärkste verfügbare Modell. Modellrouting – die Weiterleitung verschiedener Anfragen an entsprechend dimensionierte Modelle – führt zu erheblichen Einsparungen.
Modellfähigkeit an Aufgabenkomplexität anpassen
Einfache Klassifizierungsaufgaben benötigen keine hochmodernen Modelle. Stimmungsanalyse, einfache Zusammenfassung oder Kategorisierung funktionieren gut mit kleineren, kostengünstigeren Alternativen. Teure Modelle sollten für komplexes Schließen, differenzierte Generierung oder Aufgaben mit spezialisiertem Wissen reserviert werden.
Untersuchungen zur Modelleffizienz zeigen, dass neu gestaltete Architekturen vergleichbare Leistungen in unterschiedlichen Größenordnungen erzielen können. Die Architektur des Modells spielt dabei eine entscheidende Rolle, die weit über die reine Parameteranzahl hinausgeht.
Produktionssysteme melden den Einsatz von OpenAI-, Anthropic- und lokalen Modellen je nach Aufgabenanforderungen bei über 2 Millionen monatlichen API-Aufrufen. Dieser heterogene Ansatz optimiert das Kosten-Nutzen-Verhältnis für verschiedene Anwendungsfälle.
Intelligente Routing-Logik implementieren
Automatisierte Routing-Systeme analysieren eingehende Anfragen und wählen geeignete Modelle aus. KI-gestützte Plattformen optimieren sowohl die LLM-Auswahl als auch die zugrunde liegende Infrastruktur automatisiert und reduzieren so den manuellen Entscheidungsaufwand.
Die Routing-Logik berücksichtigt Faktoren wie Abfragekomplexität, erforderliche Genauigkeit, Latenztoleranz und aktuelle Preise. Dynamisches Routing passt sich ohne manuelles Eingreifen an veränderte Bedingungen an.
Caching-Strategien für wiederkehrende Arbeitslasten
Caching ermöglicht sofortige und drastische Kostensenkungen für Anwendungen mit wiederkehrenden Mustern. Produktionssysteme verzeichnen Cache-Trefferraten von 40 Prozent, wobei einige Implementierungen monatlich rund 14.000 US-Dollar an API-Kosten einsparen.
Semantisches Caching implementieren
Einfaches Caching speichert exakte Übereinstimmungen mit der Eingabeaufforderung. Semantisches Caching geht noch einen Schritt weiter – es erkennt ähnliche Anfragen selbst bei unterschiedlicher Formulierung. “Wie setze ich mein Passwort zurück?” und “Wie funktioniert die Passwortwiederherstellung?” lösen dieselbe zwischengespeicherte Antwort aus.
Dieser Ansatz kommt insbesondere dem Kundensupport, der Dokumentationssuche und FAQ-Systemen zugute, wo Benutzer identische Fragen unterschiedlich formulieren.
Cache-System-Eingabeaufforderungen und Kontext
Systemabfragen, die das Modellverhalten definieren, ändern sich selten. Durch deren Zwischenspeicherung werden redundante Verarbeitungsprozesse reduziert. Kontextinformationen, die in mehreren Anfragen vorkommen – wie Unternehmensinformationen, Produktkataloge oder Styleguides – sollten großzügig zwischengespeichert werden.
Ansätze des Kontext-Engineerings zeigen, dass Subagenten zwar umfangreiche Analysen mit Zehntausenden von Token durchführen können, aber nur komprimierte Zusammenfassungen von 1.000 bis 2.000 Token zurückgeben. Das Zwischenspeichern dieser Ergebnisse verhindert redundante, detaillierte Analysen derselben Informationen.
Frühstopp und Ausgangssteuerung
Modelle erzeugen oft mehr Inhalte als nötig. Frühstoppverfahren erkennen, wann genügend Informationen erzeugt wurden, und stoppen die Generierung.
Die Forschung zu ES-CoT (Early Stopping Chain-of-Thought) zeigt Methoden auf, wie sich die Konvergenz von Antworten erkennen und die Generierung frühzeitig beenden lässt. Wenn aufeinanderfolgende identische Schrittantworten auf Konvergenz hindeuten, wird die Generierung beendet, wodurch die Kosten für die Inferenztoken reduziert werden, während die Genauigkeit vergleichbar bleibt.
Das Verfahren funktioniert, indem das Modell in jedem Denkschritt seine aktuelle Antwort ausgibt. Die Länge aufeinanderfolgender identischer Antworten dient als Konvergenzmaß. Ein starker Anstieg der Länge, der Mindestschwellenwerte überschreitet, führt zum Abbruch des Algorithmus.
Maximale Token-Limits festlegen
Die Ausgabelänge sollte explizit über API-Parameter begrenzt werden. Dies verhindert eine unkontrollierte Generierung von Tokens für unnötige Verarbeitung. Unterschiedliche Aufgaben erfordern unterschiedliche Grenzwerte – passen Sie diese je nach Anwendungsfall an.
Für die Klassifizierung werden 10 Token benötigt. Für die Zusammenfassung möglicherweise 200. Die Generierung von Langtexten könnte 1.000 oder mehr Token rechtfertigen. Standardeinstellungen, die eine unbegrenzte Ausgabe ermöglichen, führen jedoch zu Verschwendung.
Quantisierung und Modellkomprimierung
Die Quantisierung verringert die Genauigkeit der Modellgewichte und senkt dadurch den Speicherbedarf und die Rechenkosten. LLMs verwenden üblicherweise die FP16-Genauigkeit, um den Speicherbedarf im Vergleich zu FP32 zu reduzieren. Eine weitere Quantisierung auf INT8 oder INT4 ermöglicht zusätzliche Einsparungen.
Quantisierung nach dem Training
Die nachträgliche Reduzierung der Modellkosten durch das Entfernen von Gewichten aus dichten Netzwerken wird durch Sparsity-Induktion nach dem Training gesenkt. Untersuchungen zur Sparsity-Induktion demonstrieren Ansätze zur nachträglichen Reduzierung der Modellkosten anhand von Modellen, die mit einzelnen NVIDIA RTX A6000 GPUs (48 GB) getestet wurden.
Native dichte Matrizen weisen eine geringe Dichte auf, wodurch das direkte Entfernen von Gewichten zu Problemen führt. Fortschrittliche Ansätze erzeugen Dichtemuster, die die Modellleistung erhalten und gleichzeitig den Rechenaufwand reduzieren.
Destillation für Spezialaufgaben
Wissensdestillation erzeugt kleinere Modelle, die größere Modelle für spezifische Aufgaben nachbilden. Das Schülermodell lernt aus den Ausgaben des Lehrermodells und erfasst aufgabenrelevantes Verhalten mit weniger Parametern.
Autodistill-Frameworks ermöglichen die Entwicklung spezialisierter Modelle mit deutlich geringeren Inferenzkosten durch Wissensdestillationsansätze.
| Technik | Komplexität | Kostenreduzierung | Qualitätsauswirkung
|
|---|---|---|---|
| Schnelle Optimierung | Niedrig | 20-30% | Verbessert oft |
| Modellrouting | Medium | 40-60% | Minimal |
| Caching | Niedrig | 30-50% | Keiner |
| Vorzeitiger Stopp | Medium | 30-40% | Minimal |
| Quantisierung | Hoch | 50-70% | 5-10%-Abbau |
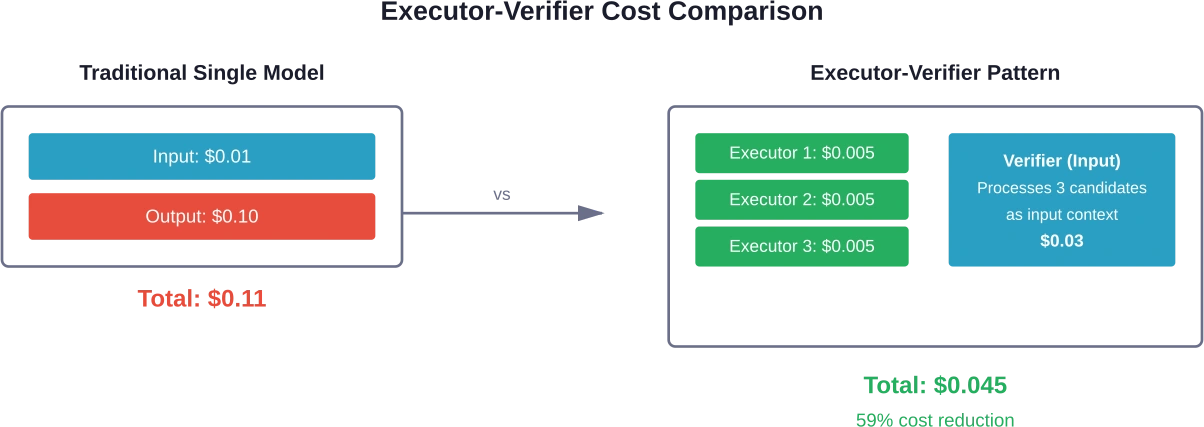
Executor-Verifier-Architekturen
Das Executor-Verifier-Paradigma verlagert den Tokenverbrauch von teuren Ausgaben hin zu günstigeren Eingaben. Mehrere kleine, lokal bereitgestellte Modelle generieren Lösungsvorschläge. Ein leistungsstarkes Cloud-basiertes Modell überprüft, welcher Vorschlag korrekt ist.
E-Agent-Frameworks zeigen, dass dieser Ansatz den Tokenverbrauch im Vergleich zu herkömmlichen Methoden um 10–50 Prozent reduziert. Die Preisasymmetrie zwischen Input- und Output-Token macht die Verifizierung kostengünstiger als die Generierung.
Kleine Ausführungsmodule laufen lokal oder auf kostengünstiger Infrastruktur. Sie generieren parallel mehrere unterschiedliche Kandidaten. Der Verifizierer verarbeitet alle Kandidaten als Eingabekontext – zu niedrigeren Gebühren für Eingabetoken – und wählt die beste Antwort aus oder synthetisiert sie.
Diese Architektur eignet sich besonders für Aufgaben mit klaren Korrektheitskriterien: mathematische Probleme, Codegenerierung, Sachfragen oder die Extraktion strukturierter Daten.
Infrastruktur- und Bereitstellungsoptimierung
Über Optimierungen auf Modellebene hinaus haben Infrastrukturentscheidungen einen erheblichen Einfluss auf die Kosten.
Hardwareauswahl optimieren
Die Wahl der GPU ist entscheidend. NVIDIA TensorRT-LLM bietet Python-APIs zur Definition von LLMs mit modernsten Optimierungen für effiziente Inferenz auf NVIDIA-GPUs. Tests zeigen deutliche Leistungsverbesserungen auf geeigneter Hardware.
Experimente mit einzelnen NVIDIA RTX A6000 GPUs mit 48 GB Speicher zeigen, dass Inferenz für Modelle, die ein sorgfältiges Ressourcenmanagement erfordern, praktikabel ist. Die richtige Dimensionierung der Hardware verhindert eine Überdimensionierung und gewährleistet gleichzeitig eine akzeptable Latenz.
Stapelverarbeitung, wenn möglich
Echtzeitanforderungen führen mitunter zu künstlichen Einschränkungen. Die Stapelverarbeitung mehrerer Anfragen verbessert den Durchsatz und senkt die Kosten pro Anfrage. Aufgaben wie Inhaltsmoderation, Klassifizierung oder Analyse tolerieren oft geringfügige Verzögerungen, die eine Stapelverarbeitung ermöglichen.
Für eine größere Reichweite sollten Sie Self-Hosting in Betracht ziehen.
Bei ausreichendem Volumen wird Self-Hosting wirtschaftlich. Die Preisgestaltung von Cloud-APIs beinhaltet erhebliche Margen. Organisationen, die monatlich Millionen von Anfragen verarbeiten, sollten eine dedizierte Infrastruktur in Betracht ziehen.
Der Break-Even-Punkt hängt von den technischen Möglichkeiten, dem Wartungsaufwand und den Nutzungsmustern ab. Potenzielle Einsparungen bei großem Umfang können eine eingehende Analyse rechtfertigen.
Iterative Verfeinerungssysteme
Parallel-Distill-Refine (PDR)-Systeme erzeugen parallel verschiedene Entwürfe, destillieren diese in abgegrenzte Arbeitsbereiche und verfeinern sie bedingt durch diesen Arbeitsbereich. Dieser Ansatz bietet oft eine bessere Performance als lange Denkketten bei gleichzeitig geringerer Latenz und Kontextgröße.
Sequentielle Verfeinerung verbessert iterativ eine einzelne Lösungskandidatin ohne persistenten Arbeitsbereich. Tests an mathematischen Aufgaben zeigen, dass iterative Pipelines die Single-Pass-Baselines bei gleichem sequentiellen Budget übertreffen. Shallow PDR erzielt die größten Verbesserungen – etwa 10 Prozent bei anspruchsvollen Problemstellungen.
Diese Methoden betrachten Modelle als Verbesserungsoperatoren mit kontinuierlichen Strategien. Sie generieren vier kürzere Antworten und kombinieren deren Stärken zu einer einzigen überlegenen Antwort. Dies ist oft der Generierung einer einzelnen langen Antwort überlegen und benötigt dabei insgesamt weniger Token.
Kontinuierliche Überwachung und Optimierung
Kostenoptimierung ist kein einmaliger Vorgang. Kontinuierliches Monitoring deckt neue Chancen auf und erkennt Rückschritte.
Wichtige Kennzahlen verfolgen
Überwachen Sie Token pro Anfrage, Kosten pro Transaktion, Cache-Trefferraten und die Verteilung der Modellauswahl. Legen Sie Baselines fest und alarmieren Sie bei Anomalien. Nutzungsmuster ändern sich – Optimierungsstrategien sollten sich anpassen.
Feedbackschleifen implementieren
Selbstlernende Agenten-Frameworks implementieren Trainingsschleifen, die Probleme erkennen und die Leistung verbessern. Die Optimierung sollte so lange fortgesetzt werden, bis Qualitätsschwellenwerte erreicht sind – typischerweise >80% an Ausgaben mit positivem Feedback – oder bis abnehmende Erträge auftreten, bei denen neue Iterationen nur noch minimale Verbesserungen zeigen.
Evaluierungsgetriebenes Systemdesign nutzt Evaluierungen als Kernprozess zur Entwicklung produktionsreifer autonomer Systeme. Strukturierte Evaluierungen mit klaren Kennzahlen ermöglichen systematische Verbesserungen ohne Spekulationen.
Regelmäßige Modellbewertung
Ständig kommen neue Modelle mit verbessertem Preis-Leistungs-Verhältnis auf den Markt. Vierteljährliche Evaluierungen gewährleisten, dass die Systeme die neuesten Funktionen nutzen. Das Spitzenmodell von gestern wird morgen zur Alternative im mittleren Preissegment.
Testen Sie neue Versionen anhand bestehender Benchmarks. Der Modellwechsel erfordert nur minimale Codeänderungen, kann aber erhebliche Einsparungen oder Funktionsverbesserungen ermöglichen.
Häufige Fallstricke, die es zu vermeiden gilt
Mehrere Fehler untergraben die Optimierungsbemühungen:
- Überoptimierung allein aus Kostengründen: Qualität ist entscheidend. Eine Kostenreduzierung um 50 Prozent ist wertlos, wenn die Produktqualität so weit sinkt, dass menschliches Eingreifen erforderlich wird. Messen Sie daher stets neben den Kosten auch die Genauigkeit.
- Latenzfolgen außer Acht lassen: Manche Optimierungstechniken nehmen eine geringere Latenz in Kauf, um Kosten zu sparen. Batchverarbeitung und Modellrouting verlängern die Verarbeitungszeit. Es muss sichergestellt werden, dass die Leistung für die jeweiligen Anwendungsfälle akzeptabel bleibt.
- Statische Optimierungsstrategien: Was heute funktioniert, kann morgen schon überholt sein. Preismodelle ändern sich, neue Funktionen entstehen und Nutzungsmuster entwickeln sich weiter. Statische Strategien verlieren allmählich an Wirksamkeit.
- Vorzeitige Optimierung: Beginnen Sie mit grundlegenden Techniken wie der Optimierung von Prompts und dem Caching. Komplexe Ansätze wie die benutzerdefinierte Modelldestillation erfordern erhebliche Investitionen. Stellen Sie sicher, dass das Volumen den Aufwand rechtfertigt.
Beispiele für Kosteneinsparungen in der Praxis
In der Praxis zeigen sich durch diese Strategien erhebliche Einsparungen.
Systeme, die monatlich über 2 Millionen API-Aufrufe in mehreren Anwendungen verarbeiten, weisen Cache-Trefferraten von 40 Prozent auf und sparen dadurch monatlich ca. 1,4 Billionen Euro. Dies stellt eine unkomplizierte Implementierung mit sofortigem ROI dar.
E-Agent-Frameworks, die den Tokenverbrauch um 10–50 Prozent reduzieren, erhalten oder verbessern die Genauigkeit bei wissensintensiven Aufgaben. Tests mit wissensintensiven und logischen Aufgaben belegen die Effektivität des Executor-Verifier-Ansatzes.
Methoden zum vorzeitigen Stoppen reduzieren die Anzahl der Inferenztoken im Durchschnitt um etwa 41 Prozent über fünf Datensätze zum logischen Denken und drei LLMs hinweg, wobei die Genauigkeit vergleichbar bleibt.
Dies sind gemeldete Ergebnisse aus Produktionssystemen, die reale Arbeitslasten verarbeiten.

Verschwenden Sie kein Geld mehr für LLM-Studiengänge – KI ist überlegen
Viele Teams setzen auf große Sprachmodelle und merken erst später, wie schnell die Infrastrukturkosten explodieren können. Der Tokenverbrauch steigt, die Modelle laufen länger als erwartet, und Systeme, die in der Testphase funktionierten, werden im Produktivbetrieb teuer.
AI Superior Wir unterstützen Unternehmen bei der Konzeption und Optimierung von LLM-Systemen, um deren Effizienz auch bei großem Umfang zu gewährleisten. Unsere Teams entwickeln kundenspezifische Modelle, optimieren diese und optimieren KI-Workflows. Dadurch reduzieren wir häufig unnötigen Rechenaufwand und verbessern die Implementierung von Modellen in realen Geschäftsprozessen.
Wenn Ihre LLM-Kosten immer weiter steigen, wenden Sie sich an AI Superior Um Ihre Konfiguration zu überprüfen und Ineffizienzen zu beheben, bevor Ihre nächste Cloud-Rechnung eintrifft.
Häufig gestellte Fragen
Wie lassen sich die Kosten für einen LLM-Abschluss am schnellsten senken?
Schnelle Optimierung und Caching liefern sofortige Ergebnisse bei minimalem Implementierungsaufwand. Beginnen Sie damit, ausführliche Eingabeaufforderungen zu komprimieren, strukturierte Ausgaben anzufordern und ein einfaches Caching für wiederholte Abfragen zu implementieren. Diese Änderungen können die Kosten innerhalb weniger Tage um 20–40 Prozent senken.
Wie viel kann durch modellbasiertes Routing eingespart werden?
Modellrouting spart typischerweise 40–60 Prozent im Vergleich zur Verwendung von Grenzmodellen für alle Aufgaben. Die genauen Einsparungen hängen von der Aufgabenverteilung ab – Umgebungen mit vielen einfachen Klassifizierungs- oder Extraktionsaufgaben erzielen höhere Einsparungen als solche, die hauptsächlich komplexe Schlussfolgerungen erfordern.
Beeinträchtigt die Quantisierung die Modellqualität signifikant?
Moderne Quantisierungstechniken erhalten die Qualität bemerkenswert gut. Die INT8-Quantisierung führt typischerweise zu einem Genauigkeitsverlust von 1–3 Prozent, reduziert aber den Speicherbedarf um etwa 50 Prozent. Die INT4-Quantisierung weist einen Verlust von 5–10 Prozent auf, ermöglicht aber die Ausführung deutlich größerer Modelle auf leistungsschwächerer Hardware.
Wann sollten Organisationen Selbsthosting in Betracht ziehen?
Selbsthosting wird ab etwa 10–50 Millionen Token pro Monat wirtschaftlich, abhängig von den technischen Möglichkeiten und den Preisen der Cloud-API. Organisationen mit Expertise im Bereich Machine Learning und einem konsistenten Nutzungsverhalten erreichen die Gewinnschwelle früher. Berechnen Sie die Gesamtbetriebskosten inklusive Infrastruktur, Wartung und Opportunitätskosten.
Wie häufig sollten Kostenoptimierungsstrategien überprüft werden?
Vierteljährliche Überprüfungen decken wesentliche Änderungen bei Preisen, Modellfunktionen und Nutzungsmustern auf. Die monatliche Überwachung wichtiger Kennzahlen identifiziert Anomalien, die sofortiges Handeln erfordern. Wesentliche Änderungen der Anwendungsfunktionalität machen eine umgehende Optimierung notwendig.
Können sich auch kleinere Unternehmen fortschrittliche Optimierungstechniken leisten?
Absolut. Grundlegende Techniken wie die Optimierung von Schnellzugriffen, Caching und Modellauswahl erfordern nur minimalen technischen Aufwand. Fortgeschrittene Ansätze wie benutzerdefinierte Destillation oder Self-Hosting sind bei höheren Datenmengen sinnvoll, aber die anfänglichen Einsparungen ergeben sich durch einfache Änderungen, die jedes Unternehmen umsetzen kann.
Welcher Zusammenhang besteht zwischen Kostenoptimierung und Latenz?
Manche Techniken verbessern beides – Early Stopping reduziert Kosten und Latenz gleichzeitig. Andere bringen Kompromisse mit sich – Modellrouting verursacht einen geringen Routing-Overhead, Batching verzögert einzelne Anfragen. Es sollten Optimierungsstrategien entwickelt werden, die die Latenzanforderungen für spezifische Anwendungsfälle berücksichtigen.
Fortschritte bei der Kostenoptimierung
Die Kostenoptimierung im LLM-Bereich ist ein fortlaufender Prozess, kein abgeschlossenes Ziel. Beginnen Sie mit wirkungsvollen, unkomplizierten Techniken. Messen Sie die Ergebnisse sorgfältig. Optimieren Sie Ihr Vorgehen anhand der Daten.
Organisationen, die mit produktiven LLM-Implementierungen erfolgreich sind, betrachten Kostenoptimierung als Kernkompetenz. Sie überwachen kontinuierlich, experimentieren systematisch und passen ihre Strategien an veränderte Bedingungen an.
Die Forschung entwickelt Optimierungstechniken stetig weiter. Durch die Berücksichtigung aktueller Entwicklungen wird sichergestellt, dass Implementierungen von den neuesten Innovationen profitieren. Regelmäßig entstehen neue Methoden für Komprimierung, Routing und effiziente Inferenz.
Die Grundprinzipien bleiben jedoch unverändert: Preismodelle verstehen, Ressourcen an Anforderungen anpassen, Verschwendung vermeiden und alles messen. Diese Prinzipien ermöglichen nachhaltige Kostenstrukturen, die mit dem Unternehmenswachstum skalieren.
Beginnen Sie diese Woche mit der Umsetzung ein oder zweier Strategien. Messen Sie die Auswirkungen. Bauen Sie darauf auf. Der kumulative Effekt mehrerer Optimierungen verstärkt sich – eine Verbesserung von 20 Prozent hier, 30 Prozent dort, und plötzlich sinken die Gesamtkosten um 60 Prozent, während sich die Qualität verbessert.
Das ist keine Theorie. Das ist das Ergebnis von Produktionssystemen, wenn Organisationen die Kostenoptimierung systematisch angehen.