Überblick: Die Hostingkosten für LLM variieren stark je nach Bereitstellungsmodell und reichen von 1.025 Tsd. pro Million Token für API-Dienste wie OpenAIs GPT-5-nano bis zu 1.500–5.000 Tsd. monatlich für selbstgehostete Infrastruktur. Organisationen mit über 50.000 Anfragen täglich erzielen durch Selbsthosting oft Kosteneinsparungen von 25.000–50.030 Tsd., während kleinere Betriebe von nutzungsbasierter API-Abrechnung profitieren. Der Hardwarebedarf skaliert mit der Modellgröße: Modelle mit 7 Milliarden Parametern benötigen etwa 3,5 GB VRAM mit 4-Bit-Quantisierung, während Modelle mit 70 Milliarden Parametern 35 GB oder Multi-GPU-Systeme erfordern.
Die Ausgaben von Unternehmen für große Sprachmodelle sind explosionsartig gestiegen. Allein die Kosten für Modell-APIs haben sich bis 2025 auf 1,4 Billionen US-Dollar verdoppelt, und die meisten Unternehmen planen, ihre KI-Budgets in diesem Jahr weiter zu erhöhen.
Aber eines ist klar: Nicht jede Organisation sollte gleich bezahlen. Die Wirtschaftlichkeit des LLM-Hostings hängt vollständig von Umfang, Nutzungsmustern und technischen Anforderungen ab. API-Dienste bieten enormen Komfort, doch durch Selbsthosting lassen sich die Kosten bei ausreichendem Umfang um 501.000 US-Dollar oder mehr senken.
Dieser Leitfaden schlüsselt die tatsächlichen Kosten aller wichtigen Hosting-Optionen auf, von kommerziellen APIs bis hin zu vollständig selbstverwalteter Infrastruktur.
API-basierte LLM-Kosten: Abrechnung pro Token
Kommerzielle API-Dienste funktionieren nach dem Pay-per-Use-Modell und berechnen die Kosten anhand der verarbeiteten Input- und Output-Tokens. Laut der Preisdokumentation von OpenAI (Stand 2026) variieren die Kosten je nach Modell erheblich.
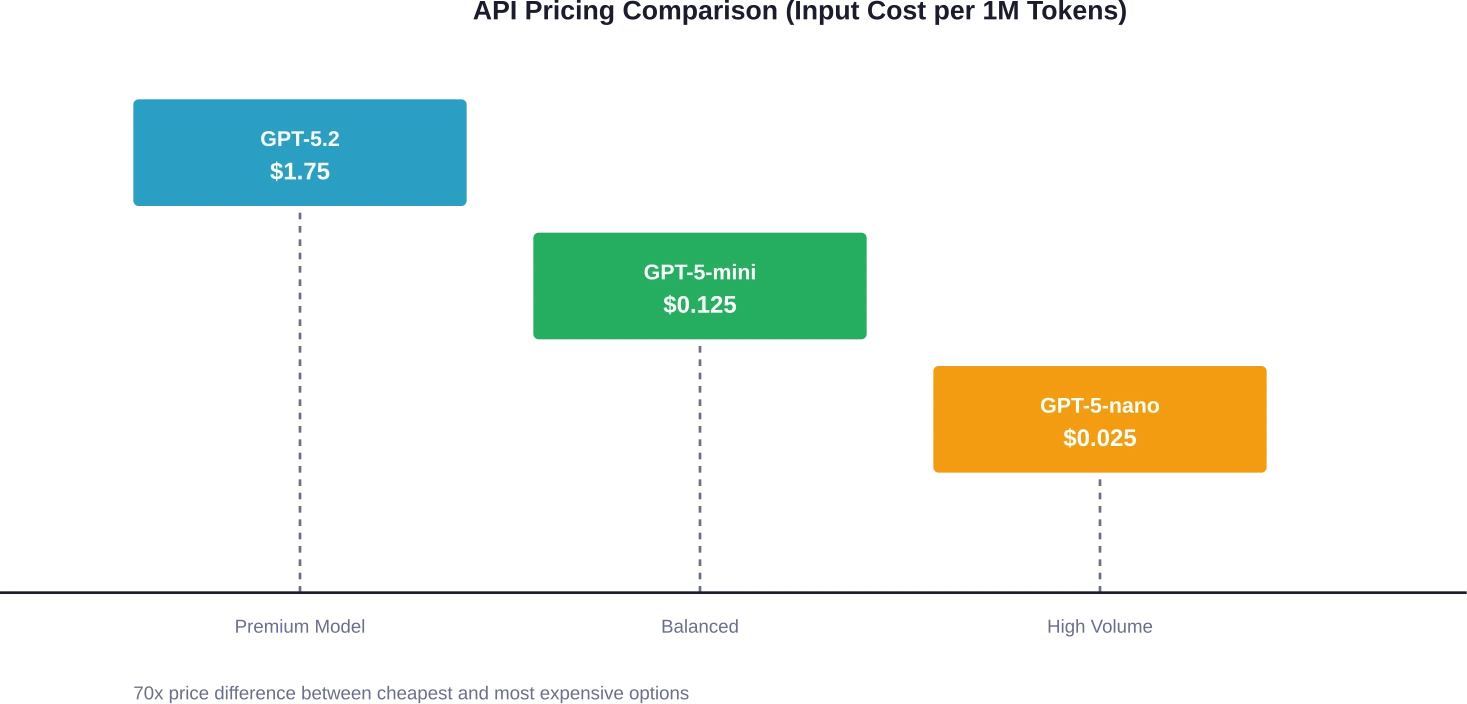
GPT-5.2 benötigt 1,75 TP4T pro Million Eingabe-Token und 14,00 TP4T pro Million Ausgabe-Token. Es handelt sich um das Flaggschiffmodell, das für komplexe Denk- und Programmieraufgaben entwickelt wurde. Zum Vergleich: GPT-5-mini kostet nur 0,125 TP4T pro Million Eingabe-Token und 1,00 TP4T pro Million Ausgabe-Token – also 14-mal weniger bei den Eingaben und Ausgaben.
Der neueste Zuwachs, GPT-5-nano, senkte die Preise nochmals auf $0,025 pro Million Input-Token und $0,20 pro Million Output-Token. Für Teams, die viele einfache Aufgaben mit hohem Volumen ausführen, bedeutet dies eine Kostenreduzierung von 80% im Vergleich zu GPT-5-mini.
Einsparungen bei zwischengespeicherten Eingaben
OpenAI hat ein Preismodell für zwischengespeicherte Eingaben eingeführt, das für wiederholte Inhalte lediglich 10% des Standardpreises berechnet. Zwischengespeicherte Eingaben von GPT-5.2 kosten $0,175 pro Million Token anstatt $1,75. Für Anwendungen mit konsistenten Systemaufforderungen oder Referenzdokumenten ist diese Optimierung relevant.
Die Batch-API senkt die Kosten um 50% für nicht-Echtzeit-Workloads, die asynchron innerhalb von 24 Stunden verarbeitet werden.
Anthropic und Google Preise
Die Preisgestaltung von Googles Vertex AI für Gemini-3-Modelle (Stand: Februar 2026) weist ähnliche tokenbasierte Strukturen auf. Für Anfragen mit weniger als 200.000 Eingabe-Tokens gelten Standardpreise, während für größere Kontexte und zwischengespeicherte Eingaben separate Gebühren anfallen.
Diese kommerziellen Dienste berechnen Gebühren nur für erfolgreiche Anfragen, die den Antwortcode 200 zurückgeben. Fehlgeschlagene Anfragen sind kostenlos, wodurch Fehlerkosten vermieden werden.
Kosten für Cloud-Plattform-Hosting
AWS SageMaker, Google Vertex AI und Azure Foundry bieten verwaltetes LLM-Hosting mit mehr Kontrolle als reine API-Dienste. Diese Plattformen berechnen Rechenressourcen anstelle von Tokens.
AWS SageMaker Preisstruktur
Laut AWS-Dokumentation (Stand: Februar 2026) berechnet SageMaker Gebühren für Instanzstunden, Speicherplatz und Datentransfer. Das AWS Free Tier umfasst 250 Stunden ml.t3.medium-Instanzen für die ersten zwei Monate sowie 4.000 kostenlose API-Anfragen pro Monat.
Bei Produktionsworkloads skaliert der Instanzpreis mit der GPU-Leistung. Organisationen, die Inferenz auf ml.g5.xlarge-Instanzen (NVIDIA A10G GPUs) ausführen, zahlen je nach Region und Vertragslaufzeit unterschiedliche Preise.
AWS-Reservierungsinstanzen bieten im Vergleich zur On-Demand-Preisgestaltung erhebliche Einsparungen. Einjährige Reservierungsverträge können die Kosten für vorhersehbare Workloads deutlich reduzieren.
Google Vertex KI-Wirtschaftswissenschaften
Die Preisdokumentation von Googles Vertex AI zeigt, dass die Gebühren auf Rechenstunden, Modellbereitstellungszeit und Vorhersageanfragen basieren. Für Modelle, deren Bereitstellung fehlschlägt, fallen keine Gebühren an, und Trainingsfehler (außer bei Abbrüchen durch den Nutzer) werden nicht berechnet.
Dieses verbrauchsbasierte Modell schützt davor, für fehlgeschlagene Operationen bezahlen zu müssen, was beim Experimentieren mit Modellkonfigurationen wichtig ist.
Kosten der selbstgehosteten LLM-Infrastruktur
Durch Self-Hosting werden die Kosten von variablen Nutzungsgebühren auf feste Infrastrukturinvestitionen verlagert. Für Organisationen mit über 50.000 Anfragen pro Tag ist dies oft wirtschaftlich sinnvoll.
Die Hardwareanforderungen hängen ausschließlich von der Modellgröße ab. Als Faustregel gilt: etwa 0,5 GB VRAM pro Milliarde Parameter bei 4-Bit-Quantisierung. Volle Präzision (FP16) verdoppelt diesen Bedarf.
| Modellgröße | Parameter | VRAM (4-Bit) | VRAM (FP16) | Typische Hardware |
|---|---|---|---|---|
| Klein | 7B-13B | 3,5–6,5 GB | 14-26 GB | Einzeln A100/H100 |
| Medium | 30B-40B | 15-20 GB | 60-80 GB | A100 80 GB |
| Anwendungsfälle | 70 Milliarden+ | 35 GB+ | 140 GB+ | Multi-GPU-Konfiguration |
Passt das Modell nicht in den VRAM, greift das System auf die CPU-Verarbeitung zurück, die 10- bis 100-mal langsamer ist. Das ist für den Produktiveinsatz nicht praktikabel.
Monatliche Infrastrukturkosten nach Stufe
Eine Studie der Carnegie Mellon University, die die Wirtschaftlichkeit des LLM-Einsatzes vor Ort analysiert, zeigt deutliche Kostenunterschiede auf:
| Stufe | Modellgröße | Hardwarekonfiguration | Monatliche Kostenspanne | Am besten geeignet für |
|---|---|---|---|---|
| Eintrag | 7B-13B | 1x A100/H100 | $1,500-$5,000 | Prototypen, interne Werkzeuge |
| Mitte | 30B-70B | 4-8 GPU-Cluster | $8,000-$20,000 | Produktionsanwendungen, mittlerer Umfang |
| Unternehmen | 70 Milliarden+ | Cluster mit 8+ GPUs | $20,000-$50,000+ | Großserienproduktion |
Diese Zahlen beinhalten die Hardware-Amortisation, den Stromverbrauch, die Kühlung und die grundlegende Wartung. Die auf arxiv.org veröffentlichte Studie zur Kosten-Nutzen-Analyse gibt an, dass die GPU-Stundenkosten für A800 80G-Karten unter gängigen Annahmen etwa $0,79/Stunde betragen und im Allgemeinen im Bereich von $0,51 bis $0,99/Stunde liegen.
Einsparungen bei reservierten AWS EC2-Instanzen
Eine detaillierte Kostenaufstellung des LLM-Hostings von LinkedIn zeigt, dass reservierte AWS EC2-Instanzen im Vergleich zur On-Demand-Preisgestaltung erhebliche Einsparungen bieten. Für g5.xlarge-Instanzen (geeignet für 8-Bit-Parametermodelle) können einjährige Reservierungsverträge die monatlichen Kosten von ca. 1.400.530 USD auf deutlich niedrigere Beträge senken.
Die günstigste Option für 8B-Modelle war Deep Infra mit $5,40/Monat, während AWS SageMaker mit $529,92/Monat am teuersten war. Die durchschnittlichen Kosten liegen bei etwa $237/Monat.

Kennen Sie Ihre LLM-Hostingkosten?
Die Bereitstellung von LLM-Lösungen erfordert Entscheidungen hinsichtlich Latenz, Skalierbarkeit, Sicherheit und Budget. AI Superior Wir helfen Ihnen bei der Auswahl des passenden Hosting-Modells (Cloud, Edge oder Hybrid), schätzen den Ressourcenbedarf ein und berechnen die laufenden Kosten in Abhängigkeit von Traffic und Performance. Unsere Bewertung berücksichtigt Speicher, Monitoring, Skalierung und laufende Wartung. So erhalten Sie eine zuverlässige Prognose Ihrer Hosting-Kosten.
Sind Sie bereit, Ihr Budget für die LLM-Hostelnutzung zu planen?
Sprechen Sie mit einer KI, die überlegen ist gegenüber:
- Wählen Sie die richtige Hosting-Architektur
- Schätzung der Ressourcen- und Betriebskosten
- Sie erhalten eine übersichtliche Aufschlüsselung der Hostingkosten.
👉 Fordern Sie eine Anfrage an LLM-Hostingkosten Schätzung von AI Superior.
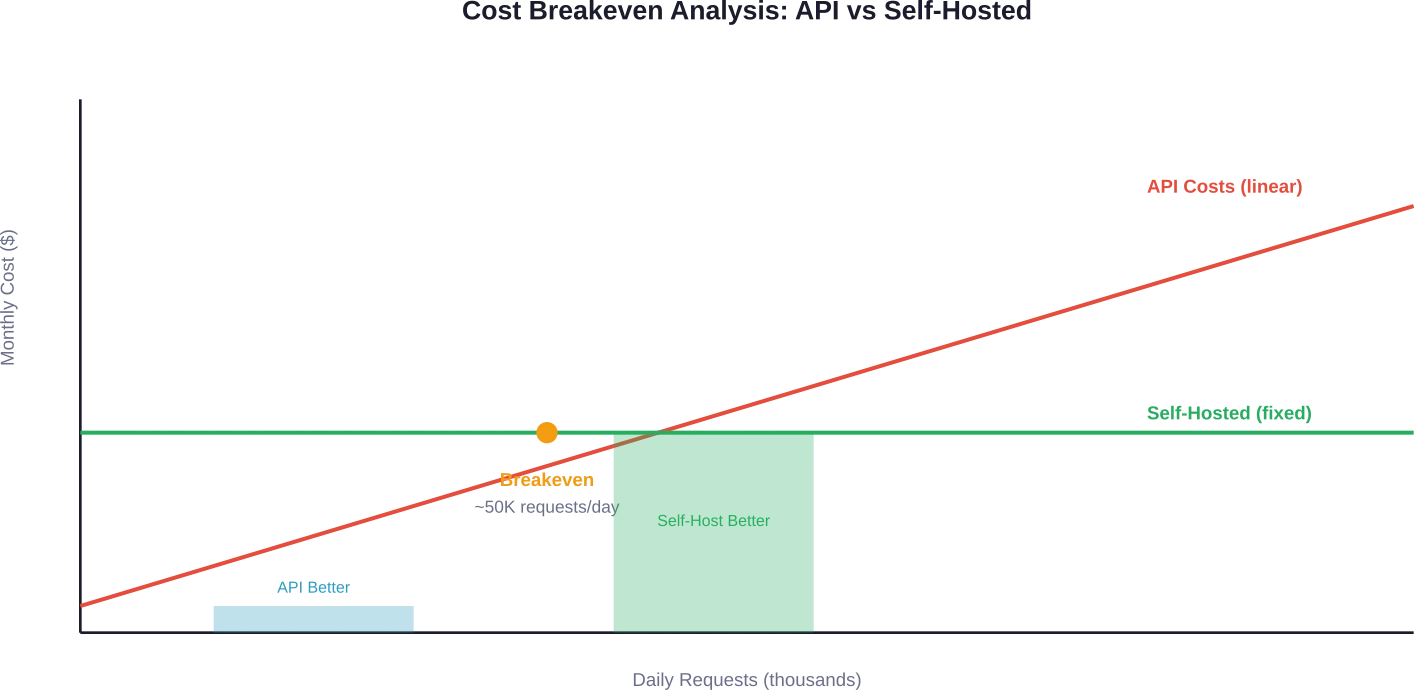
Gewinnschwelle erreichen: Wann sich Selbsthosting lohnt
Der Break-Even-Punkt hängt vom Anfragevolumen ab. Diskussionen in der Community und Kostenanalysen deuten übereinstimmend darauf hin, dass ab 50.000 Anfragen pro Tag das Selbsthosting wirtschaftlich attraktiv wird.
Der Grund dafür ist folgender: Die API-Kosten skalieren linear mit der Nutzung. Die fixen Infrastrukturkosten bleiben unabhängig vom Anfragevolumen (innerhalb der Kapazitätsgrenzen) konstant.
Eine Organisation, die täglich 50.000 Anfragen mit jeweils 500 Eingabe- und Ausgabetoken mithilfe von GPT-5-mini verarbeitet, würde monatlich allein für API-Aufrufe etwa $3.125 ausgeben. Dabei sind Anwendungsinfrastruktur, Caching-Schichten und Monitoring noch nicht berücksichtigt.
Ein selbstgehostetes 7B-Modell auf Einsteigerhardware (1.500–1.500 TP4T/Monat) bewältigt ähnliche Datenmengen und bietet gleichzeitig vollständige Datenkontrolle. Die Wirtschaftlichkeit verbessert sich deutlich bei über 100.000 Anfragen pro Tag.
Versteckte Kosten, über die niemand spricht
Der angegebene Preis ist nur ein Teil der Wahrheit. Sowohl API-basierte als auch selbstgehostete Ansätze bergen versteckte Kosten, die die Gesamtbetriebskosten beeinflussen.
Versteckte Kosten von API-Diensten
Ratenbegrenzungen erzwingen Architekturentscheidungen. Beim Erreichen von Durchsatzgrenzen benötigen Anwendungen Warteschlangensysteme, Wiederholungslogik und Ausweichmechanismen. Das bedeutet Entwicklungszeit und Infrastrukturkosten.
Bei Anwendungen mit hohem Datenaufkommen summieren sich die Gebühren für den Datentransfer. Während die Tokenverarbeitung selbst $X kostet, fallen für die Übertragung großer Datensätze zu und von API-Anbietern separate Gebühren an.
Die Abhängigkeit von einem bestimmten Anbieter verursacht Wechselkosten. Anwendungen, die auf spezifischen API-Antwortformaten, Tool-Integrationen oder Techniken der schnellen Entwicklung basieren, können nicht ohne Weiteres zu einem anderen Anbieter wechseln.
Versteckte Kosten bei Selbsthosting
Der DevOps-Aufwand ist relevant. Jemand muss sich um Modellaktualisierungen, Sicherheitspatches, Überwachung und die Reaktion auf Sicherheitsvorfälle kümmern. Laut dem Enterprise AI Report 2025 von Kong nennen 441.030 Unternehmen Datenschutz und Datensicherheit als größte Hürden – Self-Hosting erfordert dedizierte Ressourcen, um diese Bedenken angemessen zu adressieren.
Strom- und Kühlkosten übersteigen die reinen Rechenkosten. Rechenzentren berichten, dass der tatsächliche Stromverbrauch das 1,5- bis 2-Fache der Nennleistungsaufnahme der GPU beträgt, wenn Ineffizienzen bei Kühlung und Stromversorgung berücksichtigt werden.
Skalierung erfolgt nicht automatisch. Zusätzliche Kapazität erfordert Vorlaufzeiten für die Hardwarebeschaffung, Berücksichtigung des Rackplatzes und Planung der Netzwerkinfrastruktur. API-Dienste skalieren hingegen sofort.
Optimierungsstrategien, die tatsächlich funktionieren
Unabhängig von der Wahl des Hosting-Anbieters gibt es mehrere Techniken, die die LLM-Kosten konstant senken, ohne die Leistung zu beeinträchtigen.
Modellauswahl und Quantisierung
Kleinere Modelle schneiden bei domänenspezifischen Aufgaben oft besser ab als erwartet. Laut einer Studie von Together AI kann ein 27-Bit-Open-Source-Modell, das für spezialisierte Aufgaben feinabgestimmt wurde, Claude Sonnet 4 um 60% übertreffen und dabei 10- bis 100-mal kostengünstiger sein.
Die 4-Bit-Quantisierung halbiert den Speicherbedarf bei minimalen Qualitätseinbußen für die meisten Anwendungen. Dieses Verfahren ermöglicht die Ausführung größerer Modelle auf derselben Hardware oder die Nutzung desselben Modells auf kostengünstigerer Hardware.
Stapelverarbeitung
Die Batch-API von OpenAI spart durch asynchrone Verarbeitung über 24 Stunden 50% an Ein- und Ausgaben. Die Dokumentation der Batch-API von Together AI zeigt ähnliche Einsparungen – Aufgaben, die keine Echtzeit-Antworten erfordern, sollten immer Batch-Endpunkte verwenden.
Untersuchungen von AWS zur SageMaker-Optimierung zeigen, dass die Bündelung von Inferenzanfragen die GPU-Auslastung drastisch verbessert und die Kosten pro Vorhersage reduziert.
Zwischenspeicherung und Anforderungsdeduplizierung
Systemabfragen, Referenzdokumente und wiederholte Abfragen verursachen unnötige Kosten. Durch die Implementierung eines Abfrage-Cachings auf Anwendungsebene wird die redundante Tokenverarbeitung vermieden.
Bei selbstgehosteten Bereitstellungen kann eine Middleware zur Anforderungsdeduplizierung identische Anfragen abfangen, bevor sie das Modell erreichen, und stattdessen zwischengespeicherte Antworten liefern.
Verkehrsprognose und automatische Skalierung
Microsofts Forschung zur Effizienz des LLM-Dienstes (SageServe) erzielte durch vorausschauende automatische Skalierung Einsparungen von bis zu 251 TP3T an GPU-Stunden und ein potenzielles monatliches Kosteneinsparungspotenzial von bis zu 1 TP4T2,5 Millionen. Das System analysiert historische Anfragemuster und passt die Kapazität proaktiv an.
Dadurch wird die Verschwendung von GPU-Stunden aufgrund ineffizienter automatischer Skalierung im Vergleich zu reaktiven Skalierungsansätzen um bis zu 80% reduziert.
Regionale Kostenunterschiede
Die Hostingkosten für LLM variieren erheblich je nach geografischer Region. AWS, Google Cloud und Azure wenden alle regionale Preismodelle an, die die lokalen Infrastrukturkosten, Energiepreise und Marktbedingungen widerspiegeln.
Reale Produktionsdaten, die 10 Millionen Anfragen in verschiedenen Regionen analysieren, zeigen regionale Kostenunterschiede. Bei API-Diensten werden diese Unterschiede üblicherweise nicht berücksichtigt. Bei selbstgehosteter Infrastruktur hingegen hat die Wahl der richtigen Region erhebliche Auswirkungen auf die monatlichen Kosten.
Bei API-Diensten werden diese Unterschiede üblicherweise abstrahiert. Bei selbstgehosteter Infrastruktur hingegen hat die Wahl der richtigen Region erhebliche Auswirkungen auf die monatlichen Kosten.
Kostentrends 2026
Mehrere Faktoren drücken die Hostingkosten von LLM in diesem Jahr.
Verbesserungen der algorithmischen Effizienz sind wichtiger als Hardware-Fortschritte. Laut einer Studie von MIT FutureTech zur algorithmischen Effizienz haben Verbesserungen der Speicherkomplexität bei großen Problemen (n=1 Milliarde) die DRAM-Verbesserungen in 20% der analysierten Fälle übertroffen.
Neue Modellarchitekturen wie Mixture-of-Experts (MoE) erzeugen unterschiedliche Kostenprofile. Untersuchungen zur MoE-Steuer zeigen, dass diese Modelle spezifische Ineffizienzen aufweisen – Lastungleichgewicht während des Vorbefüllens und erhöhte Speichertransfers während der Dekodierung. Optimierte MoE-Implementierungen können jedoch ein besseres Kosten-Nutzen-Verhältnis als dichte Modelle bieten.
AWS kündigte 2023 neue Container für die Inferenz großer Modelle an, die die Latenz für Llama-2-70B-Workloads um 331 TP3T reduzierten. Aktualisierte Versionen verbessern die Effizienz kontinuierlich. Bei Llama-2-70B-Workloads mit 16 gleichzeitigen Prozessen konnte die Latenz mit TensorRT-LLM-Containern um 281 TP3T gesenkt und der Durchsatz um 441 TP3T erhöht werden.
Häufig gestellte Fragen
Wie lässt sich im Jahr 2026 am günstigsten ein LLM-Programm veranstalten?
Für geringes Nutzungsaufkommen (unter 10.000 Anfragen täglich) bietet OpenAIs GPT-5-nano mit 0,025 TP4T pro Million Eingabe-Token den günstigsten Einstieg ohne zusätzlichen Infrastrukturaufwand. Für hohes Produktionsaufkommen (über 50.000 Anfragen täglich) ist das Selbsthosting von Modellen mit 7 bis 13 Milliarden Parametern auf Einsteiger-Hardware (1.500–5.000 TP4T pro Monat) in der Regel kostengünstiger als die Nutzung einer vergleichbaren API.
Wie viel VRAM benötige ich, um ein 70-B-Parametermodell auszuführen?
Ein 70B-Parametermodell benötigt ca. 35 GB VRAM mit 4-Bit-Quantisierung oder 140 GB mit voller FP16-Präzision. Dies entspricht typischerweise entweder einer A100 80GB-GPU (knappes Limit mit Quantisierung) oder einem Multi-GPU-System für einen flüssigen Betrieb. Bei unzureichendem VRAM greift das Modell auf die CPU-Verarbeitung zurück, die jedoch 10- bis 100-mal langsamer ist.
Lohnt sich der Einsatz von AWS Reserved Instances für das LLM-Hosting?
Reservierte Instanzen sind sinnvoll für vorhersehbare, kontinuierliche Workloads, die rund um die Uhr laufen. Einjährige Reservierungsverträge für AWS EC2 bieten im Vergleich zur On-Demand-Preisgestaltung für GPU-Instanzen erhebliche Einsparungen. Allerdings ist die Kapazität durch den Vertrag festgeschrieben – Unternehmen mit schwankendem Nutzungsverhalten zahlen in Zeiten geringer Nachfrage möglicherweise zu viel.
Können sich kleine Organisationen selbstgehostete LLM-Studiengänge leisten?
Die Kosten für Self-Hosting im Einstiegssegment beginnen bei etwa 1.500 bis 5.000 INR monatlich für Modelle mit 7 bis 13 Milliarden Parametern. Organisationen, die täglich mehr als 50.000 Anfragen verarbeiten, erreichen in dieser Größenordnung oft die Gewinnschwelle im Vergleich zu den API-Kosten. Unterhalb dieser Schwelle sind API-Dienste in der Regel günstiger, wenn man den Aufwand für DevOps, Wartung und Management berücksichtigt.
Worin besteht der tatsächliche Kostenunterschied zwischen GPT-5.2 und GPT-5-mini?
Laut OpenAIs Preisprognose für 2026 kostet GPT-5.2 1,75 TTP pro Million Eingabe-Token und 14,00 TTP pro Million Ausgabe-Token, während GPT-5-mini 0,125 TTP pro Eingabe und 1,00 TTP pro Ausgabe kostet – ein Unterschied um das 14-Fache sowohl bei den Eingabe- als auch bei den Ausgabekosten. Für eine typische Anwendung, die täglich 1 Million Token verarbeitet (500.000 Eingabe, 500.000 Ausgabe), belaufen sich die monatlichen Kosten für GPT-5.2 auf etwa 7.875 TTP, im Vergleich zu 562,50 TTP für GPT-5-mini.
Spart Caching tatsächlich Geld bei den LLM-Kosten?
Ja, tatsächlich drastisch. OpenAI berechnet für wiederholte Inhalte lediglich 10% der Standardgebühren für zwischengespeicherte Eingaben. Für Anwendungen mit konsistenten Systemaufforderungen oder Referenzdokumenten bedeutet dies, dass zwischengespeicherte Eingaben von GPT-5.2 nur noch $0,175 pro Million Token statt $1,75 kosten. Anwendungen mit 50% zwischenspeicherbaren Inhalten können die API-Kosten um etwa 45% senken.
Woran erkenne ich, wann ich von API auf selbstgehostet umsteigen sollte?
Berechnen Sie die aktuellen monatlichen API-Kosten und das prognostizierte Wachstum. Vergleichen Sie diese mit den Kosten einer Einsteiger-Selbsthosting-Infrastruktur (1.500–5.000 INR/Monat) zuzüglich DevOps-Aufwand (typischerweise 0,25–0,5 FTE Entwicklungszeit). Übersteigen die API-Kosten 5.000 INR monatlich und ist die Nutzung vorhersehbar, ist Selbsthosting in der Regel wirtschaftlich sinnvoll. Datenschutzbestimmungen, Compliance-Anforderungen und Anpassungswünsche spielen neben den reinen Kosten ebenfalls eine Rolle bei der Entscheidung.
Schlussbetrachtung
Die Hostingkosten für LLM sind nicht pauschal. Die richtige Wahl hängt vom Anfragevolumen, den Leistungsanforderungen, der Datensensibilität und den technischen Möglichkeiten ab.
API-Dienste eignen sich hervorragend für einen schnellen Einstieg, die Bewältigung variabler Arbeitslasten und die Vermeidung von Infrastrukturverwaltung. Sie sind fast immer günstiger bei weniger als 50.000 Anfragen pro Tag.
Selbsthosting ist im großen Maßstab wirtschaftlich sinnvoll, insbesondere wenn Datenschutz wichtig ist oder domänenspezifische Feinabstimmungen bessere Ergebnisse liefern als allgemeine Modelle. Es erfordert jedoch DevOps-Engagement und anfängliche Investitionen in die Infrastruktur.
Der beste Ansatz? Zunächst APIs einsetzen, um die Produkt-Markt-Passung zu validieren. Anschließend sollte man Self-Hosting evaluieren, sobald sich die Nutzungsmuster stabilisiert haben und die Kosten die Infrastrukturinvestition rechtfertigen. Viele Unternehmen nutzen Hybridlösungen: APIs für Experimente und zur Überbrückung von Kapazitätsengpässen, selbstgehostete Infrastruktur für die wichtigsten Produktions-Workloads.
Welcher Weg auch immer den aktuellen Bedürfnissen am besten entspricht, planen Sie flexibel. Die Wirtschaftlichkeit und die Möglichkeiten der LLM-Hosting-Anbieter entwickeln sich weiterhin rasant.