Kurzzusammenfassung: Um die Kosten von LLM-Anwendungen zu überwachen, ist die Echtzeit-Überwachung von Token-Nutzung, Modellauswahl und Anfragemustern erforderlich, um Budgetüberschreitungen zu vermeiden. Führende Tools wie Datadog LLM Observability, Langfuse und Cloud-native Lösungen von AWS Bedrock und OpenAI ermöglichen die Kostenzuordnung, Nutzungsanalysen und Optimierungsempfehlungen. Effektives Monitoring kombiniert Observability-Plattformen mit strategischen Praktiken wie der schnellen Optimierung, der Modellauswahl und dem Caching.
Mit dem Übergang generativer KI-Anwendungen vom Prototyp zum Produktiveinsatz können die Token-Kosten schnell außer Kontrolle geraten. Eine einzige unoptimierte Prompt-Kette kann die Ausgaben verzehnfachen, und ohne Echtzeit-Einblick in die Nutzungsmuster entdecken Teams Budgetüberschreitungen oft erst, wenn die Rechnung eintrifft.
Herkömmliche Cloud-Kostenüberwachung ist für LLM-Anwendungen nicht ausreichend. Tokenbasierte Preismodelle erfordern eine spezielle Überwachung, die nicht nur die Rechenzeit, sondern auch Eingabe- und Ausgabetoken, die Modellauswahl und die Anfragehäufigkeit über verschiedene Anbieter hinweg erfasst.
Dies stellt eine grundlegende Herausforderung dar: Wie können Teams die Kosten für LLM im Blick behalten, ohne die Entwicklungsgeschwindigkeit oder die Anwendungsleistung zu beeinträchtigen?
Warum die Kostenkontrolle beim LLM wichtig ist
Das tokenbasierte Preismodell verändert grundlegend, wie sich die Anwendungskosten skalieren. Im Gegensatz zu traditioneller Infrastruktur, bei der die Kosten mit der Serververfügbarkeit korrelieren, hängen die LLM-Kosten vom Volumen und der Komplexität jeder einzelnen Anfrage ab.
Laut AWS-Dokumentation vom Oktober 2025 („Aufbau eines proaktiven KI-Kostenmanagementsystems für Amazon Bedrock“) stehen Unternehmen vor der Herausforderung, die Kosten tokenbasierter Preisgestaltung zu kontrollieren, da diese bei unzureichender Nutzungsüberwachung zu unerwarteten Rechnungen führen können. Herkömmliche Methoden wie Budgetwarnungen und die Erkennung von Kostenanomalien reagieren oft zu spät.
Das unterscheidet das Kostenmanagement beim LLM-Programm:
- Der Tokenverbrauch variiert stark je nach Länge der Aufforderung und Komplexität der Antwort.
- Die verschiedenen Modelle weisen drastisch unterschiedliche Preise auf (Amazon Nova Micro kostet $0,000035 pro 1.000 Input-Token und $0,00014 pro 1.000 Output-Token im Vergleich zu größeren Modellen mit höheren Preisen).
- Mehrstufige Agenten-Workflows verursachen durch mehrere LLM-Anrufe zusätzliche Kosten.
- Die tatsächlichen Produktionsnutzungsmuster stimmen selten mit den Entwicklungsprognosen überein.
Mal ehrlich: Die meisten Teams bemerken ein Kostenproblem erst, wenn bereits Tausende von Euro an Gebühren angefallen sind. Proaktives Monitoring verhindert genau das.
Tokenökonomie verstehen
Die Token-Preisgestaltung ist nicht einheitlich über verschiedene Modelle oder Anbieter hinweg. Die Wirtschaftlichkeit hängt stark davon ab, welches Basismodell die Anwendung antreibt und wie die Anfragen strukturiert sind.
Die Dokumentation von OpenAI zeigt, dass Audio-Tokens in Benutzernachrichten als 1 Token pro 100 ms Audio gezählt werden, während Assistentennachrichten 1 Token pro 50 ms verwenden. Diese Unterschiede sind bei der Entwicklung multimodaler Anwendungen relevant.
Die Amazon Nova-Modelle veranschaulichen das Preisspektrum deutlich. Wie in den AWS-Unterlagen vom Juni 2025 dokumentiert:
| Modell | Eingabe-Tokens (pro 1.000) | Ausgabetoken (pro 1.000) |
|---|---|---|
| Amazon Nova Micro | $0.000035 | $0.00014 |
| Größere Nova-Varianten | Höhere Raten | proportional skaliert |
Nicht für jede Aufgabe ist immer das größte Modell erforderlich. Die Anpassung der Modellleistung an die Komplexität des Anwendungsfalls wirkt sich direkt auf die Kosten aus.
Anthropic bietet eine Nutzungs- und Kosten-API, die den programmatischen Zugriff auf Ausgabendaten von Organisationen ermöglicht. Dadurch können Teams benutzerdefinierte Dashboards erstellen und die Kostenkontrolle automatisieren.

Implementierung von LLM-Überwachungssystemen
LLM-Anwendungen erfordern eine Überwachung, um Nutzung, Leistung und Betriebsstabilität zu verfolgen.
AI Superior entwickelt Überwachungs- und Management-Tools für KI-Produktionssysteme und unterstützt Unternehmen dabei, LLM-basierte Anwendungen effizienter zu betreiben.
Ihre Entwicklungsarbeit kann Folgendes umfassen:
- Nutzungsverfolgungssysteme
- Analyse von Schnell- und Reaktionszeiten
- Infrastrukturüberwachung
- Werkzeuge zur Optimierung von KI-Systemen
AI Superior unterstützt Teams bei der Überführung von LLM-Anwendungen von Prototypen in stabile Produktionsumgebungen.
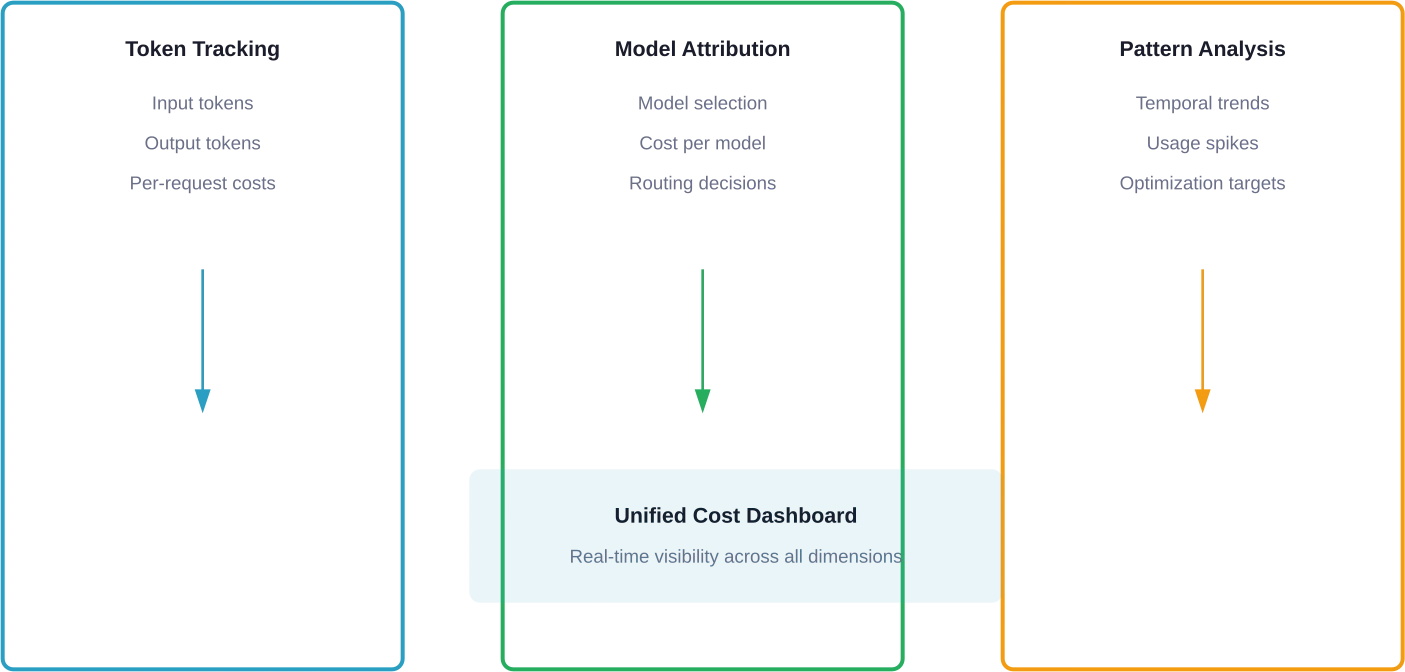
Kernkomponenten der LLM-Kostenüberwachung
Effektive Überwachungssysteme erfassen mehrere Dimensionen gleichzeitig. Die Token-Nutzung allein liefert kein vollständiges Bild.
Token-Nutzungsverfolgung
Jede Anfrage erzeugt sowohl Eingabe- als auch Ausgabetoken. Überwachungssysteme müssen beide Dimensionen erfassen und sie bestimmten Benutzern, Funktionen oder Arbeitsabläufen zuordnen.
Die Anzahl der Eingabe-Token hängt von den gewählten Systemeinstellungen ab. Ausführliche Systemabfragen oder übermäßige Kontextinjektion erhöhen die Kosten pro Anfrage. Die Anzahl der Ausgabe-Token variiert je nach Modellparametern wie Temperatur und der Einstellung „max_tokens“.
Die Apigee-Dokumentation von Google beschreibt die Token-Richtlinien von LLM als entscheidend für die Kostenkontrolle. Dabei werden Nutzungsmetriken der Token verwendet, um Limits durchzusetzen und Echtzeitüberwachung zu ermöglichen. Die Plattform erlaubt die Festlegung von Token-Limits, beispielsweise die Beschränkung von Anfragen auf 1.000 Token pro Minute.
Attribution der Modellauswahl
Anwendungen, die mehrere Modelle verwenden, benötigen eine Kostenzuordnung nach Modelltyp. Eine Routing-Entscheidung, die einfache Anfragen an ein ressourcenintensives Modell weiterleitet, verschwendet Budget.
Modellkaskadierungsstrategien können die Kosten optimieren, indem zunächst kostengünstigere Modelle ausprobiert und erst bei Bedarf auf teurere Modelle umgestiegen wird. Die Überwachung muss erfassen, welches Modell welche Anfrage bearbeitet hat und welche Kostendifferenz damit verbunden war.
Analyse von Anfragemustern
Zeitliche Muster decken Optimierungspotenziale auf. Stapelverarbeitung außerhalb der Spitzenzeiten, Drosselung von Anfragen bei Verkehrsspitzen und die Identifizierung redundanter Anrufe erfordern allesamt historische Musterdaten.
AWS-Tests vom Oktober 2025 zeigten, dass die Workflow-Ausführungszeiten je nach Anforderungen an die Ausgabetoken zwischen 6,76 und 32,24 Sekunden lagen. Das Verständnis dieser Muster ist für die Kapazitätsplanung hilfreich.
Die besten Tools zur Kostenüberwachung für LLM-Absolventen
Mehrere Plattformen haben sich als führend im Bereich der LLM-Observability und des Kostenmanagements etabliert. Jede Plattform bietet je nach Bereitstellungsarchitektur und Anbieter-Ökosystem unterschiedliche Stärken.
Datadog LLM Observability
Die Plattform von Datadog integriert sich mit führenden LLM-Anbietern wie OpenAI, Anthropic und Amazon Bedrock, wie in den AWS-Partnerschaftsunterlagen dokumentiert. Die AWS-Dokumentation vom Juli 2025 („Überwachung von Agenten auf Amazon Bedrock mit Datadog LLM Observability“) beschreibt, wie Datadog Agenten auf Bedrock mit umfassenden Observability-Funktionen überwacht.
Die Plattform erfasst Token-Nutzung, Latenz und Kosten aller LLM-Anrufe in einem zentralen Dashboard. Protokolle dokumentieren mehrstufige Agenten-Workflows und zeigen, wie sich Kosten in komplexen Prozessketten anhäufen.
Zu den wichtigsten Funktionen gehören die Kostenzuordnung in Echtzeit, die Leistungsüberwachung und die Anomalieerkennung. Teams können Budgetwarnungen einrichten und Ausgabentrends im Zeitverlauf visualisieren.
Die Preise variieren je nach Nutzungsvolumen; für groß angelegte Implementierungen sind individuelle Enterprise-Tarife erhältlich.
Langfuse
Langfuse bietet Open-Source-LLM-Observability mit der Option zum Selbsthosting. Die Plattform stellt sitzungsbasierte Ansichten bereit, die zusammengehörige LLM-Anfragen verknüpfen und so das Verständnis von Nutzerabläufen erleichtern.
Die hohe Beobachtbarkeit mehrstufiger Ketten und Agenten-Workflows zeichnet Langfuse aus. Hierarchisches Tracing zeigt Eltern-Kind-Beziehungen zwischen LLM-Aufrufen, während die Kostenverfolgung Ausgaben bestimmten Traces oder Sitzungen zuordnet.
In den Diskussionen der Community wird hervorgehoben, dass die selbstgehostete Option zwar volle Kontrolle bietet, die Cloud-Version jedoch bei $29/Monat beginnt und die Preise über den Basistarif hinaus nutzungsabhängig sind. Eine kostenlose selbstgehostete Option ist ebenfalls verfügbar.
Amazon Bedrock Native Tools
AWS hat das Kostenmanagement direkt in Bedrock integriert. Die Dokumentation vom Oktober 2025 beschreibt ein proaktives KI-Kostenmanagementsystem, das über herkömmliche Budgetwarnungen hinausgeht.
Der Workflow gewährleistet konsistente Ausführungsmuster bei der Verarbeitung von Anfragen mit unterschiedlicher Dauer (6,76 bis 32,24 Sekunden, abhängig von den Anforderungen an das Ausgabetoken). Dank dieser nativen Integration ist für Bedrock-Workloads keine separate Observability-Plattform erforderlich.
Die im Juni 2025 dokumentierten Kostenoptimierungsstrategien betonen die Bedeutung der Modellauswahl als zentralen Hebel. Die Wahl der richtigen Nova-Modellvariante kann die Kosten drastisch senken, ohne die Anwendungsqualität zu beeinträchtigen.
OpenAI-Kostenmanagement-Tools
OpenAI bietet natives Nutzungs-Tracking über das API-Dashboard und programmatischen Zugriff über Nutzungsendpunkte. Die Dokumentation der Echtzeit-API erläutert die Kostenberechnung für verschiedene Modalitäten: Text, Audio und Bilder.
Die Berechnung der Audio-Tokens variiert je nach Nachrichtentyp (1 Token pro 100 ms für Benutzernachrichten, 1 Token pro 50 ms für Assistentennachrichten). Das Verständnis dieser Unterschiede verhindert unerwartete Kosten in sprachgesteuerten Anwendungen.
Die Plattform bietet Budgetlimits und Benachrichtigungsschwellenwerte, die auf Organisations- und Projektebene konfiguriert werden können.
Anthropische Nutzungs- und Kosten-API
Anthropics Ansatz ermöglicht den programmatischen Zugriff auf Nutzungsdaten von Organisationen über eine dedizierte API. Dies ermöglicht die Integration individueller Kostenüberwachungssysteme ohne Abhängigkeit von Drittanbieterplattformen.
Die Dokumentation von Claude Code auf Anthropic zeigt, dass der Befehl `/cost` detaillierte Statistiken zur Token-Nutzung liefert, einschließlich der Gesamtkosten (Beispiel: $0.55), der API-Dauer und der Codeänderungen. Diese detaillierten Daten helfen Entwicklern, die Kostentreiber ihrer Anwendungen genau zu verstehen.
Durch Ratenbegrenzung und Teamausgabenkontrolle können Administratoren die Nutzung auf Organisationsebene begrenzen.
Cloud-native Überwachungslösungen
Die großen Cloud-Anbieter haben die LLM-Kostenüberwachung in ihre umfassenderen Observability-Plattformen integriert.
Azure Monitor
Die Überwachung durch Azure erstreckt sich auch auf Bereitstellungen des Azure OpenAI-Dienstes. Die Plattform verfolgt den Tokenverbrauch, die Anforderungsraten und die Kosten über alle bereitgestellten Modelle hinweg.
Die Integration mit Azure Cost Management bietet eine einheitliche Transparenz sowohl der Infrastruktur- als auch der LLM-Ausgaben und erleichtert so das Verständnis der gesamten Anwendungskosten.
Google Cloud und Apigee
Googles Ansatz nutzt Apigee LLM-Tokenrichtlinien zur Kostenkontrolle. Diese Richtlinien setzen Limits basierend auf Token-Nutzungsmetriken durch und ermöglichen die Echtzeitüberwachung des Tokenverbrauchs.
Die Dokumentation beschreibt die Implementierung von Ratenbegrenzungen, beispielsweise 1.000 Token pro Minute, mithilfe von PromptTokenLimit-Richtlinien. Dadurch werden unkontrollierte Kosten durch unerwartete Traffic-Spitzen vermieden.
Infrastruktur für umarmendes Gesicht
Die im Januar 2026 veröffentlichten Preisinformationen von Hugging Face zeigen ein breites Spektrum von kostenlosen Tarifen bis hin zu Enterprise-Lösungen. Die Abrechnung der Inference Endpoints basiert auf der Rechenzeit multipliziert mit dem Hardwarepreis.
Eine Anfrage, die auf einer GPU 10 Sekunden dauert und $0,00012 pro Sekunde kostet, führt zu einer Gebühr von $0,0012, wie in den Preisrichtlinien von Hugging Face dokumentiert. Das Verständnis dieses Rechenzeitmodells unterscheidet sich von tokenbasierter Preisgestaltung und erfordert andere Überwachungsansätze.
Die Plattform bietet Dashboards zur Rechenleistungsnutzung, doch Diskussionen in der Community vom April 2025 zeigen Unklarheiten bei der Umrechnung der Laufzeit in exakte Kosten. Eine bessere Dokumentation der Umrechnungsformel wäre hilfreich.
| Plattform | Preismodell | Überwachungsfunktionen | Am besten geeignet für |
|---|---|---|---|
| Datadog | Nutzungsbasiert | Einheitliche Beobachtbarkeit, Ablaufverfolgung, Warnmeldungen | Multi-Provider-Umgebungen |
| Langfuse | Kostenloses Self-Hosting, $29+ Cloud | Sitzungsverfolgung, hierarchische Ablaufverfolgung | Open-Source-Präferenz |
| AWS Bedrock | Im Service inbegriffen | Native Integration, Anfragemuster | AWS-native Bereitstellungen |
| OpenAI Native | Inklusive | Nutzungs-Dashboard, API-Zugriff | OpenAI-exklusive Apps |
| Anthropic API | Inklusive | Programmkostendaten | Claude-basierte Anwendungen |
Strategien zur Kostenoptimierung
Monitoring deckt Probleme auf. Optimierung behebt sie. Verschiedene Strategien reduzieren die LLM-Kosten kontinuierlich, ohne die Funktionalität zu beeinträchtigen.
Prompt Engineering
Prägnante Eingabeaufforderungen reduzieren die Anzahl der Eingabetoken. Untersuchungen zeigen, dass fehlerhafter Code im Vergleich zu sauberem Code zu einem deutlich höheren Tokenverbrauch während der Inferenz führt, wobei der Median des Tokenverbrauchs bei sauberem Code 28,13 und bei fehlerhaftem Code 33,30 beträgt.
Durch das Entfernen unnötiger Kontextinformationen, die Verwendung klarer Anweisungen und die effiziente Strukturierung von Eingabeaufforderungen lassen sich die Kosten pro Anfrage senken. Das Testen verschiedener Formulierungen von Eingabeaufforderungen und die Messung der Token-Nutzung ermitteln die effizientesten Ansätze.
Modellauswahl
Aufgabenspezifische Modelle sind oft kostengünstiger als Allzweckmodelle. Die AWS-Dokumentation betont, dass das größte Modell nicht immer für jede Anwendung erforderlich ist.
Ein kaskadierendes Verfahren testet zunächst kostengünstigere Modelle und greift erst dann auf teurere Modelle zurück, wenn die Genauigkeit unter bestimmte Schwellenwerte fällt. Dadurch werden Kosten und Qualität dynamisch in Einklang gebracht.
Bei Untersuchungen zur Kosten-Nutzen-Analyse wird Leistungsparität als Vergleichswert innerhalb von 20% führender kommerzieller Modelle definiert, wobei Unternehmensnormen berücksichtigt werden, dass kleine Genauigkeitslücken durch Kosten-, Sicherheits- und Integrationsvorteile ausgeglichen werden.
Caching-Strategien
Die Zwischenspeicherung von Antworten für wiederholte Anfragen eliminiert redundante LLM-Aufrufe vollständig. Die semantische Zwischenspeicherung geht noch einen Schritt weiter, indem sie ähnliche (nicht nur identische) Anfragen erkennt und zwischengespeicherte Antworten zurückgibt.
Die Dokumentation von OpenAI zur Kostenoptimierung hebt Caching als primäre Strategie hervor. Die Batch-API und die flexible Verarbeitung bieten zusätzliche Mechanismen zur Kostenreduzierung für nicht zeitkritische Workloads.
Strategische Drosselung
Durch die Begrenzung der Datenrate werden Kostenspitzen bei unerwartet hohem Datenverkehr verhindert. Die Token-Richtlinien von Apigee setzen Limits durch, die vor unkontrollierten Ausgaben schützen.
Warteschlangenbasierte Architekturen absorbieren Verkehrsspitzen, ohne die LLM-Nutzung sofort zu skalieren. Dies bringt eine gewisse Latenz in Kauf, bietet aber gleichzeitig planbare Kosten.
Bewährte Implementierungsmethoden
Die Implementierung von Kostenmonitoring erfordert sowohl technische Integration als auch organisatorische Prozesse.
Instrumentierungsansatz
Instrumentieren Sie LLM-Aufrufe auf SDK-Ebene, anstatt Anbieter-Dashboards auszulesen. Die direkte Integration erfasst Anfragemetadaten wie Benutzer-IDs, Feature-Flags und Sitzungskontexte, die eine detaillierte Kostenzuordnung ermöglichen.
Die meisten Observability-Plattformen bieten SDKs oder OpenTelemetry-Integrationen zur automatischen Aufzeichnung von Traces. Manuelle Instrumentierung ermöglicht zwar mehr Kontrolle, erfordert aber einen höheren Entwicklungsaufwand.
Alarmkonfiguration
Richten Sie gestaffelte Warnmeldungen basierend auf absoluten Ausgabenschwellenwerten und prozentualen Steigerungen ein. Eine tägliche Budgetwarnung ($100) erfasst schleichende Kostensteigerungen, während eine stündliche Erhöhungswarnung (200%) plötzliche Spitzenwerte erkennt.
Die AWS-Kostenanomalieerkennung funktioniert zwar für Infrastrukturkosten, reagiert aber bei tokenbasierten Kosten oft zu spät. Echtzeitüberwachung durch spezialisierte LLM-Observability-Plattformen deckt Probleme schneller auf.
Teambildung
Entwickler benötigen Einblick in die Kostenfolgen ihrer Entscheidungen. Die Anzeige von Token-Anzahlen und geschätzten Kosten während der Entwicklung trägt zur Kostenwahrnehmung bei.
Die Dokumentation von Claude Code zeigt, dass der Befehl `/cost` Statistiken auf Sitzungsebene liefert, darunter Gesamtkosten, Dauer und Codeänderungen. Der Aufbau ähnlicher Feedbackschleifen in internen Tools ermöglicht bessere Entscheidungen.
Regelmäßige Prüfungen
Monatliche Kostenanalysen decken Optimierungspotenziale auf und bestätigen die Wirksamkeit der Kontrollmechanismen. Die Erfassung der Kosten pro Nutzer, pro Funktion und pro Transaktion zeigt, wo sich die Ausgaben konzentrieren.
Der Vergleich der tatsächlichen Kosten mit den ursprünglichen Schätzungen deckt Planungslücken auf und verbessert zukünftige Prognosen.
ROI- und Erfolgsmessung
Die Kostenüberwachung selbst kostet Zeit und Ressourcen. Teams benötigen klare Kennzahlen, um die Investition zu rechtfertigen.
Zu den wichtigsten Leistungsindikatoren gehören:
- Kosten pro Anwendungsfunktion oder Benutzersitzung
- Prozentuale Reduzierung des Tokenverbrauchs nach der Optimierung
- Mittlere Zeit zur Erkennung von Kostenanomalien
- Abweichung zwischen geplanten und tatsächlichen Ausgaben
Die Forschung zu effizienten Agenten erreichte 96,7% der Leistung von OWL bei gleichzeitiger Reduzierung der Betriebskosten von $0,398 auf $0,228, was zu einer Verbesserung der Durchlaufzeitkosten um 28,4% führte (aus arXiv: Efficient Agents).
Ziel ist nicht die Kostenminimierung um jeden Preis, sondern die Maximierung des Nutzens pro investiertem Dollar. Manchmal führen höhere Kosten zu einem proportional höheren Nutzen.
Häufige Fallstricke, die es zu vermeiden gilt
Mehrere Fehler untergraben immer wieder die Bemühungen zur Kostenkontrolle.
Überwachung ohne Optimierungsmaßnahmen ist reine Ressourcenverschwendung. Daten ohne Entscheidungen führen nicht zu Kostensenkungen. Schaffen Sie Feedbackschleifen, die Erkenntnisse in schnelle Änderungen, Modellauswahl oder Architekturverbesserungen umsetzen.
Eine zu frühe Überoptimierung in der Entwicklung verlangsamt die Iterationsgeschwindigkeit. Warten Sie mit einer aggressiven Optimierung, bis sich die Nutzungsmuster stabilisiert haben. Eine verfrühte Optimierung auf Basis der Prototypennutzung spiegelt selten die Realität in der Produktion wider.
Auch die Vernachlässigung von Opportunitätskosten ist wichtig. Die Entwicklerzeit, die sie für die Optimierung einer monatlichen Ausgabe von $50 aufwenden, kann mehr kosten als die reine Rechnungszahlung. Konzentrieren Sie Ihre Optimierungsbemühungen daher auf die Bereiche mit den höchsten Ausgaben.
Die Vernachlässigung der Latenz-Kompromisse führt zu neuen Problemen. Aggressives Caching oder die Reduzierung der Modellauswahl mögen zwar die Kosten senken, aber die Antwortzeiten so weit erhöhen, dass die Benutzerfreundlichkeit beeinträchtigt wird. Daher sollten beide Aspekte gemeinsam überwacht werden.
Zukunftstrends im Kostenmanagement des LLM
Die Landschaft der Kostenüberwachung entwickelt sich mit zunehmender Reife der Technologie weiterhin rasant.
Probabilistische Kostenbeschränkungen stellen einen neuen Ansatz dar. Die arXiv-Forschung zu optimierten Modellkaskaden beschreibt C3PO, ein System, das die LLM-Auswahl mithilfe probabilistischer Kostenbeschränkungen für Schlussfolgerungsaufgaben optimiert. Dies geht über einfache Schwellenwerte hinaus und ermöglicht eine anspruchsvolle Optimierung des Kosten-Nutzen-Verhältnisses.
Multi-Provider-Routing auf Basis von Echtzeitpreisen wird gängiger werden. Mit der Angleichung der Modellfunktionen verschärft sich der Preiswettbewerb. Systeme, die Anfragen dynamisch an den günstigsten Anbieter mit ausreichender Qualität weiterleiten, bieten Wettbewerbsvorteile.
Spezialisierte Hardware für Inferenz verbessert kontinuierlich das Preis-Leistungs-Verhältnis. Laut den Preisdokumenten von Hugging Face beginnen die Preise für Intel Sapphire Rapids x1-Instanzen bei $0,033/Stunde (Stand: Datum der Quelle). Kundenspezifische KI-Beschleuniger von Cloud-Anbietern senken die Kosten weiter.
Aber Moment mal. Niedrigere Basispreise beseitigen nicht den Überwachungsbedarf. Sie verlagern den Optimierungsschwerpunkt von den Gesamtausgaben hin zu Effizienzkennzahlen wie den Kosten pro erfolgreich abgeschlossener Aufgabe.
Häufig gestellte Fragen
Wie berechne ich die Kosten einer LLM-API-Anfrage?
Multiplizieren Sie die Anzahl der Eingabe-Token mit dem Eingabe-Token-Preis des Modells und addieren Sie anschließend die Anzahl der Ausgabe-Token, multipliziert mit dem Ausgabe-Token-Preis. Beispiel: Bei Amazon Nova Micro mit $0,000035 pro 1.000 Eingabe-Token und $0,00014 pro 1.000 Ausgabe-Token kostet eine Anfrage mit 500 Eingabe-Token und 1.500 Ausgabe-Token etwa $0,0000175 + $0,00021 = $0,0002275.
Worin besteht der Unterschied zwischen LLM-Monitoring und traditionellem APM?
Die traditionelle Anwendungsleistungsüberwachung konzentriert sich auf Infrastrukturmetriken wie CPU-, Speicher- und Anfragelatenz. LLM-Monitoring ergänzt diese um Tokenverbrauch, Modellauswahl, Promptmuster und Kostenzuordnung speziell für generative KI-Workloads. Viele Plattformen integrieren mittlerweile beide Funktionen.
Kann ich die Kosten über mehrere LLM-Anbieter hinweg überwachen?
Ja. Plattformen wie Datadog LLM Observability unterstützen mehrere Anbieter, darunter OpenAI, Anthropic und Amazon Bedrock, in einem einheitlichen Dashboard. Dies ermöglicht Kostenvergleiche und Routing-Strategien für mehrere Anbieter.
Wie viel kann durch Kostenoptimierung realistischerweise eingespart werden?
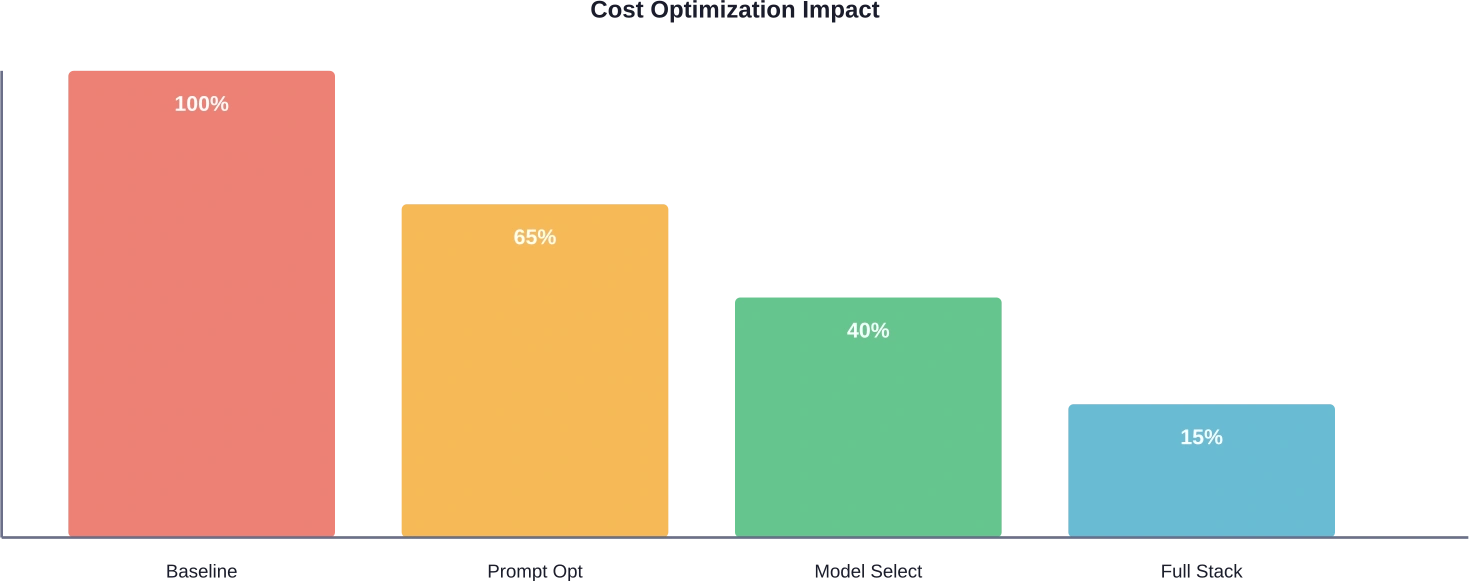
Die Optimierungsergebnisse variieren je nach Anwendung. AWS-Tests ergaben ein Kosteneinsparungspotenzial von bis zu 901 TP3T für den Step Functions Express-Workflow im Vergleich zum Standard-Workflow bei gleicher Arbeitslast. Schnelles Engineering reduziert die Kosten typischerweise um 20–401 TP3T, die Modellauswahl um weitere 30–501 TP3T, und Caching eliminiert redundante Aufrufe vollständig. Die genauen Einsparungen hängen von der Ausgangseffizienz und dem Optimierungsaufwand ab.
Sollte ich die Modelle selbst hosten, um Kosten zu sparen?
Selbsthosting ist ab einem gewissen Umfang sinnvoll. Untersuchungen von ArXiv zur Kosten-Nutzen-Analyse zeigen, dass die Gewinnschwelle vom Nutzungsvolumen, den technischen Möglichkeiten und der Erreichbarkeit einer vergleichbaren Leistung wie bei kommerziellen Modellen abhängt. Für viele Unternehmen bleiben Managed Services kostengünstiger, wenn der Entwicklungsaufwand berücksichtigt wird.
Wie oft sollte ich die Kosten für den LLM-Abschluss überprüfen?
Prüfen Sie während der ersten Bereitstellungsphase täglich die Echtzeit-Dashboards, um Konfigurationsprobleme frühzeitig zu erkennen. Führen Sie während der aktiven Entwicklungsphase wöchentlich und nach Stabilisierung der Nutzung monatlich detaillierte Kostenanalysen durch. Richten Sie automatische Warnmeldungen für Anomalien ein, anstatt sich ausschließlich auf geplante Überprüfungen zu verlassen.
Welche Kennzahlen sind für das Kostenmanagement im LLM-Bereich am wichtigsten?
Erfassen Sie die Kosten pro Nutzersitzung, die Kosten pro erfolgreich abgeschlossener Aufgabe, die Token-Effizienz (Ausgabewert pro Token) und die Kostenabweichung vom Budget. Diese Kennzahlen stellen einen direkten Zusammenhang zwischen Ausgaben und Geschäftsergebnissen her, anstatt Kosten als abstrakte Infrastrukturausgaben zu betrachten.
Weiteres Vorgehen bei der Kostenüberwachung des LLM
Die Verwaltung der Kosten für LLM-Anwendungen erfordert kontinuierliche Transparenz, strategische Optimierung und organisatorische Disziplin. Das tokenbasierte Preismodell unterscheidet sich grundlegend von traditionellen Infrastrukturkosten und erfordert daher spezielle Überwachungsansätze.
Beginnen Sie mit nativen Monitoring-Tools von Anbietern wie OpenAI, Anthropic oder AWS Bedrock. Diese integrierten Funktionen bieten grundlegende Transparenz ohne zusätzliche Plattformkosten. Mit zunehmender Skalierung Ihrer Anwendungen sollten Sie dedizierte Observability-Plattformen wie Datadog oder Langfuse für erweiterte Funktionen wie die Unterstützung mehrerer Anbieter und ausgefeilte Alarmierung in Betracht ziehen.
Der eigentliche Mehrwert entsteht durch die Verknüpfung von Monitoring und Maßnahmen. Kosten werden verfolgt, Optimierungspotenziale durch schnelles Engineering und die Auswahl geeigneter Modelle identifiziert und die Auswirkungen von Änderungen gemessen. Feedbackschleifen helfen Entwicklern, die Kostenfolgen bereits während der Entwicklung zu verstehen, anstatt Probleme erst im Produktivbetrieb zu entdecken.
Kostenoptimierung bedeutet nicht, Ausgaben um jeden Preis zu minimieren. Vielmehr geht es darum, den Nutzen pro investiertem Euro zu maximieren und gleichzeitig Qualitäts- und Leistungsstandards zu gewährleisten. Die richtige Überwachungsgrundlage macht dieses Gleichgewicht möglich.
Sie möchten die LLM-Ausgaben kontrollieren? Beginnen Sie noch heute mit der Ausstattung Ihrer Anwendungen mit grundlegendem Token-Tracking. Kleine Verbesserungen summieren sich schnell, wenn sie konsequent auf alle LLM-Aufrufe angewendet werden.