Kurzzusammenfassung: Die Verarbeitung natürlicher Sprache (NLP) nutzt regelbasierte und statistische Methoden für spezifische Sprachaufgaben zu geringeren Kosten, während große Sprachmodelle (LLMs) neuronale Netze sind, die mit riesigen Datensätzen trainiert werden und sich hervorragend für generative Aufgaben eignen, aber deutlich mehr kosten. Die Kombination beider Ansätze – NLP für Klassifizierung und Routing, LLMs für komplexes Schließen – kann die Inferenzkosten um 40–901 Tsd. µT senken und gleichzeitig die Qualität erhalten.
Alle lieben große Modelle, bis die Rechnung kommt. Was während der Testphase nach Centbeträgen pro Anfrage aussieht, summiert sich in der Produktion auf Tausende pro Monat.
Die Realität sieht so aus: Die meisten KI-Workloads benötigen nicht für jede einzelne Anfrage GPT-basierte Schlussfolgerungen. Ohne eine geeignete Kostenarchitektur trifft jedoch jede Anfrage trotzdem auf das teuerste Modell.
Aber das Entscheidende ist: NLP und LLMs sind keine konkurrierenden Technologien. Sie ergänzen sich und bieten in strategischer Kombination sowohl Leistung als auch Kosteneffizienz. Zu verstehen, wann welcher Ansatz am besten eingesetzt wird, dient nicht nur der Kostenersparnis, sondern auch dem Aufbau nachhaltiger und skalierbarer KI-Systeme.
Den Kostenunterschied zwischen NLP und LLMs verstehen
Traditionelle Verfahren der natürlichen Sprachverarbeitung und große Sprachmodelle basieren auf grundlegend unterschiedlichen ökonomischen Prinzipien. Diese Unterscheidung ist wichtig, da sie sich direkt auf die Produktionskosten auswirkt.
NLP-Systeme verursachen typischerweise anfängliche Entwicklungskosten – für die Erstellung von Regelsätzen, das Training kleinerer, spezialisierter Modelle und die Entwicklung von Klassifizierungspipelines. Nach der Implementierung sind die Kosten für die Inferenz minimal. Die Verarbeitung von Texten mittels regulärer Ausdrücke, Named Entity Recognition oder kleiner Klassifizierungsmodelle erfordert nur einen vernachlässigbaren Rechenaufwand.
LLMs kehren dieses Modell komplett um. Die Entwicklungskosten sind geringer, da die Basismodelle vortrainiert sind. Die Inferenzkosten werden jedoch zum dominierenden Kostenfaktor. Jedes verarbeitete Token – sowohl Eingabe als auch Ausgabe – hat seinen Preis.
Die Realität der Token-Ökonomie
Tokenbasierte Preisgestaltung bedeutet, dass die Kosten linear mit der Nutzung steigen. Laut Daten von Anbietern von Hugging Face Inference variieren die aktuellen Marktpreise für vergleichbare Modelle erheblich:
| Modell | Anbieter | Eingabe (pro 1 Mio. Token) | Ausgabe (pro 1 Million Token) | Kontextfenster |
|---|---|---|---|---|
| GPT-5 Mini | OpenAI | $0.25 | $2.00 | ~400k |
| Qwen3.5-35B-A3B | Novita | $0.25 | $2.00 | 262,144 |
| Qwen3.5-27B | Novita | $0.30 | $2.40 | 262,144 |
| Qwen3.5-397B-A17B | Zusammen | $0.60 | $3.60 | 262,144 |
Ausgabetoken kosten durchweg 8- bis 10-mal so viel wie Eingabetoken. Diese Asymmetrie bestraft ausführliche Antworten. Ein Chatbot, der 500-Wort-Antworten generiert, verbraucht das Budget exponentiell schneller als ein für prägnante Ausgaben optimierter Bot.
Mal ehrlich: Die $0,25 pro Million Input-Token klingen günstig, bis das Produktionsvolumen erreicht ist. Verarbeitet man monatlich 100 Millionen Token – für eine mittelgroße Anwendung problemlos machbar –, sind das schon $25.000 allein für die Input-Token. Kommen dann noch die Output-Token hinzu, vervielfachen sich die tatsächlichen Ausgaben.
Infrastrukturkosten jenseits von API-Aufrufen
Die Preisgestaltung von Cloud-GPUs bringt eine weitere Ebene ins Spiel. Laut einer Analyse von Hugging Face zur Wirtschaftlichkeit von Cloud-Computing dominieren bei Selbsthosting-Modellen die Infrastrukturkosten.
Die Kapitalinvestition für GPU-Kapazität stellt die größte Hürde dar. Die physische Infrastruktur ist weniger wichtig als die anfänglichen Hardwarekosten. Für Organisationen, die ihre Inferenzprozesse selbst durchführen, verschiebt sich dadurch das Kostenmodell von einer nutzungsbasierten Abrechnung hin zu einer Planung mit fester Kapazität.
Aber Moment mal. Cloud-Instanzen werden weiterhin stündlich abgerechnet. Basierend auf der Modellgröße und den in Branchenquellen dokumentierten Hardware-Bereitstellungsmustern ergeben sich folgende praktische Einschränkungen:
| Modellgröße | VRAM (FP16) | VRAM (4-Bit) | Cloud-Instanztyp | Typische Anwendungsfälle |
|---|---|---|---|---|
| 1-3B | 4-6 GB | ca. 2 GB | AWS g4dn.xlarge | Grundlegender Chat, Kategorisierung, Autovervollständigung |
| 7-8B | 14-16 GB | ca. 6-8 GB | AWS g5.xlarge | Allgemeine Schlussfolgerung |
Herkömmliche NLP-Komponenten laufen problemlos auf CPU-Instanzen. Es ist keine spezielle Hardware erforderlich. Der Kostenunterschied wird bei großem Umfang deutlich.
Wo traditionelles NLP Kostenvorteile bietet
Bestimmte Sprachverarbeitungsaufgaben profitieren nicht von den LLM-Funktionen. Für diese Arbeitslasten liefern traditionelle NLP-Methoden gleichwertige oder sogar bessere Ergebnisse zu einem Bruchteil der Kosten.
Klassifizierungs- und Routingaufgaben
Absichtsklassifizierung, Stimmungsanalyse, Themenkategorisierung – diese Probleme sind gelöst. Kleine, spezialisierte Modelle, die für spezifische Klassifizierungsaufgaben trainiert wurden, erreichen eine Genauigkeit von über 951 TP3T und verarbeiten dabei Tausende von Anfragen pro Sekunde mit minimaler Hardware.
Ein auf BERT basierender Klassifikator, der für das Kundensupport-Routing optimiert ist, verwendet möglicherweise 110 Millionen Parameter. Im Vergleich dazu benötigt GPT-5 Mini Milliarden von Parametern. Das Klassifikationsmodell führt die Inferenz auf der CPU in wenigen Millisekunden durch. Ein LLM-Aufruf dauert Hunderte von Millisekunden und ist um ein Vielfaches teurer pro Anfrage.
In Community-Diskussionen werden praktische Beispiele hervorgehoben. Laut einer Fallstudie von Lumitech stellte sich bei der Analyse ihrer LLM-Nutzung heraus, dass 80% der Anfragen unkompliziert waren. Jede Anfrage belastete unnötigerweise ihr teuerstes Modell.
Durch die Implementierung einer NLP-Klassifizierungsschicht vorab konnten einfache Aufgaben an ressourcenschonende Modelle weitergeleitet und LLMs für komplexe Schlussfolgerungen reserviert werden. Das Ergebnis: Eine zehnfache Kostenreduktion – von $200 auf $20 pro Monat – ohne Qualitätseinbußen.
Mustererkennung und Entitätsextraktion
Regex-Muster und regelbasierte Extraktionssysteme verursachen praktisch keine Betriebskosten. Bei klar definierten Anforderungen funktionieren die Regeln einwandfrei.
E-Mail-Validierung, Telefonnummernformatierung, Datumsanalyse, Adressnormalisierung – all das benötigt keine neuronalen Netze. Regelbasierte Systeme werden in Mikrosekunden ausgeführt, ohne API-Aufrufe oder Modellinferenz.
Die Erkennung benannter Entitäten folgt ähnlichen ökonomischen Prinzipien. Die statistischen Modelle von SpaCy extrahieren Entitäten mit hoher Genauigkeit in verschiedenen Sprachen. Nach dem Laden in den Speicher erfolgt die Verarbeitung nahezu verzögerungsfrei. Es fallen keine Kosten pro Anfrage an. Token-Zählung ist nicht erforderlich.
Domänenspezifische Sprachaufgaben
Spezialisierte NLP-Modelle, die für eng begrenzte Anwendungsbereiche trainiert wurden, sind oft leistungsfähiger als allgemeine LLMs und kosten dabei weniger.
Die Verarbeitung medizinischer Texte profitiert von BioBERT oder ähnlichen domänenspezifischen Modellen. Die Analyse juristischer Dokumente funktioniert besser mit rechtsspezifischen NLP-Pipelines. Die Stimmungsanalyse im Finanzbereich erzielt mit FinBERT eine höhere Genauigkeit als mit generischen LLMs.
Diese Modelle umfassen 100 bis 400 Millionen Parameter. Selbsthosting wird dadurch wirtschaftlich rentabel. Die Trainingskosten sind einmalige Ausgaben. Die Inferenzkosten sinken bei großem Umfang gegen null.
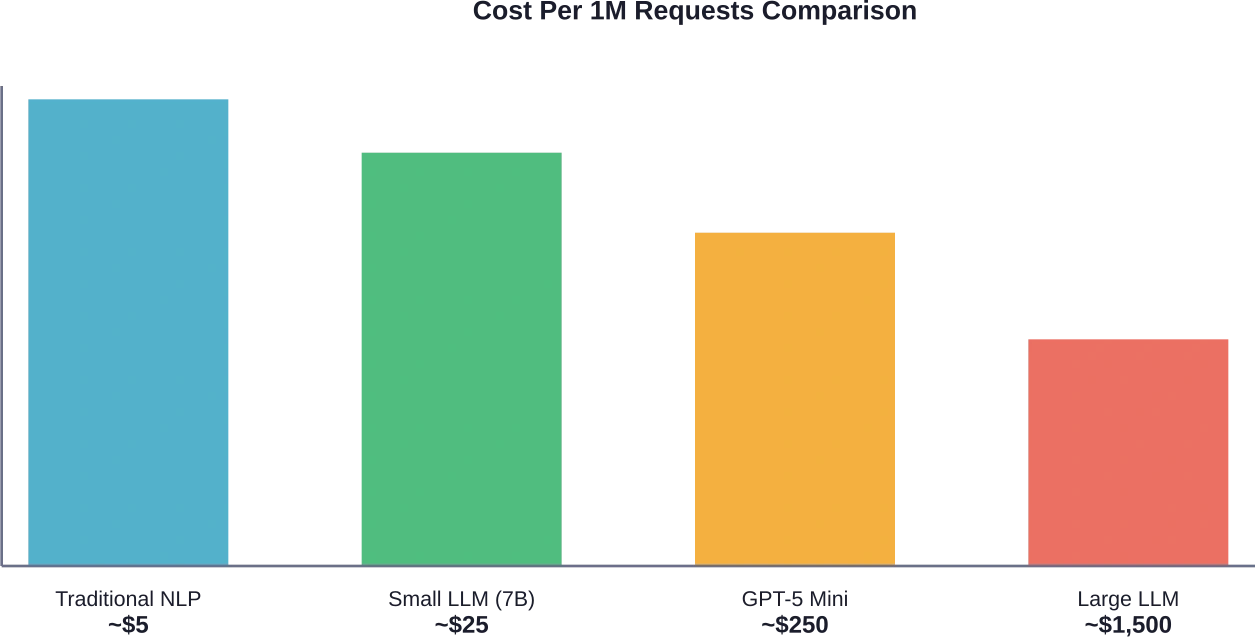
Wann sich die Kosten für einen LLM lohnen
LLMs rechtfertigen ihren Preis durch spezifische Anwendungsfälle. Entscheidend ist, dass die Leistungsfähigkeit den Anforderungen entspricht.
Generative und kreative Aufgaben
Contentgenerierung, kreatives Schreiben, Codesynthese, Zusammenfassung – das ist das Gebiet des LLM. Traditionelle NLP kann keine kohärenten, längeren Texte generieren. Regelbasierte Systeme können keine Marketingtexte verfassen, die natürlich klingen.
Bei generativen Workloads sind LLM-Kosten unvermeidbar. Die Frage verschiebt sich von der Frage, ob LLMs eingesetzt werden sollen, hin zu der Frage, welches Modell das beste Preis-Leistungs-Verhältnis bietet.
OpenAI berichtet, dass GPT-5 Mini beim AIME-Mathematikwettbewerb 91,11 TP3T und bei einem internen Intelligenztest 87,81 TP3T erreicht. Die Leistung ist mit der deutlich größerer Modelle vergleichbar. Mit 1 TP4T0,25 pro Million Eingabe-Token bietet es Spitzenleistung zu einem erschwinglichen Preis.
Komplexes Denken und mehrstufige Probleme
Gedankenketten, mehrstufige Fragebeantwortung, mathematische Problemlösung – kleinere Modelle stoßen hier an ihre Grenzen. Größere LLMs mit Milliarden von Parametern zeigen neuartige Denkfähigkeiten, die höhere Kosten rechtfertigen.
Doch hier wird es interessant. Nicht jede komplexe Aufgabe erfordert das größte Modell. Untersuchungen zur Optimierung der LLM-Nutzung zeigen Methoden, die die Kosten um 40–90¹TP3T senken und gleichzeitig die Qualität um 4–7¹TP3T verbessern.
Die Methodik beinhaltet eine umfassende Evaluierung über verschiedene Modellebenen hinweg. Die Ergebnisse zeigen durchweg, dass eine aufgabengerechte Modellauswahl die Qualität sichert und gleichzeitig die Kosten kontrolliert.
Workflows mit geringem Volumen und hohem Wert
Bei geringem Anfragevolumen und hohem Entscheidungswert sind die LLM-Kosten im Vergleich zu den Auswirkungen auf das Geschäft vernachlässigbar.
Ein juristisches Recherchetool, das täglich 100 Anfragen verarbeitet, profitiert von den Funktionen eines LLM-Systems. Selbst bei Premium-Preisen können die monatlichen Kosten 1,45 bis 200 £ betragen. Der Wert einer präzisen juristischen Analyse übersteigt diese Ausgaben jedoch bei Weitem.
Vergleichen Sie dies mit einem Chatbot, der täglich 100.000 Interaktionen verarbeitet. Gleiches Modell, anderes Volumen, völlig anderes Kostenprofil. Szenarien mit hohem Volumen erfordern Optimierung. Workflows mit niedrigem Volumen können sich Premium-Modelle leisten.
Der hybride Architekturansatz
Die kosteneffektivsten Produktionssysteme kombinieren NLP und LLMs strategisch. Es handelt sich nicht um eine Entweder-oder-Entscheidung.
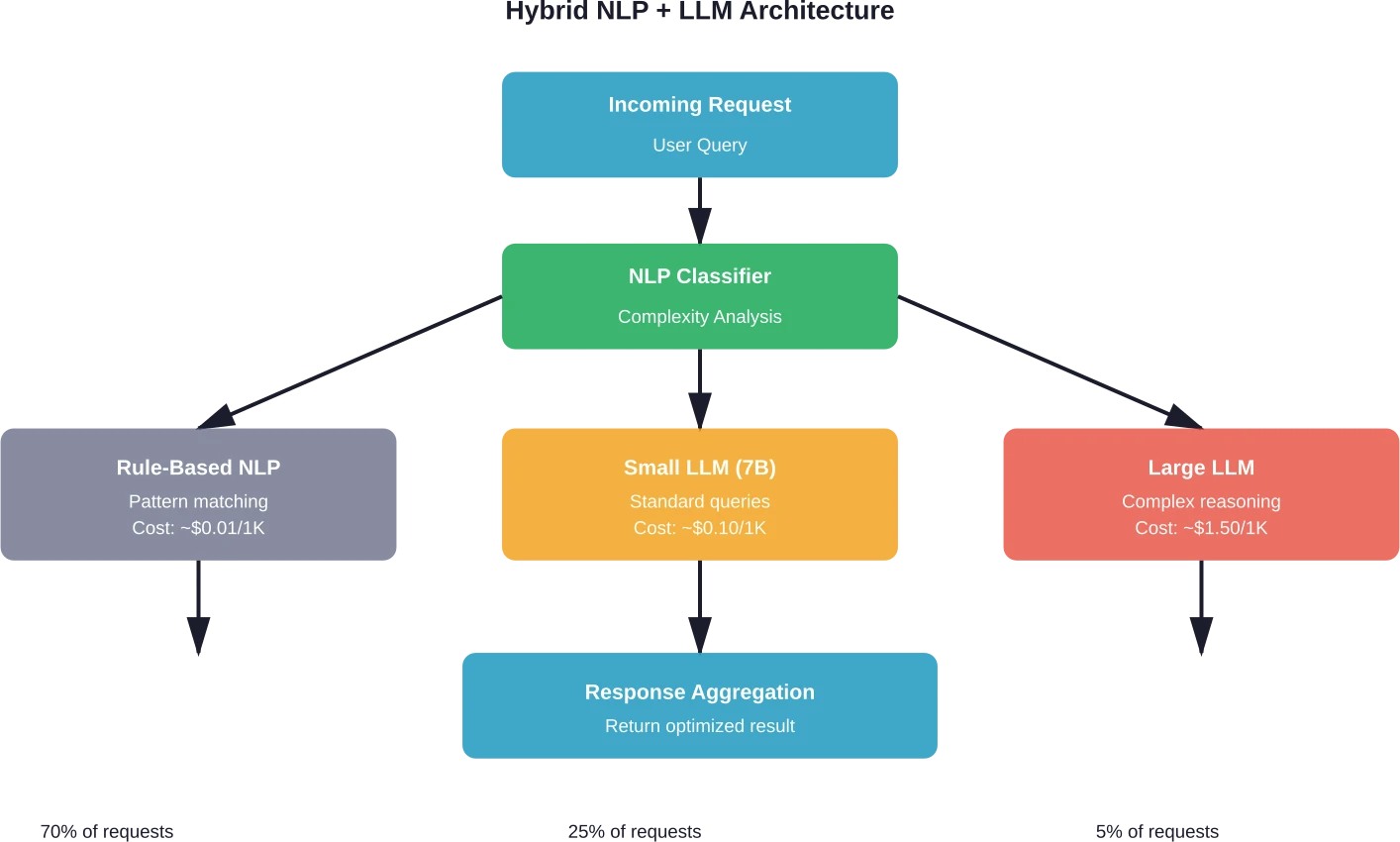
Intelligentes Anfrage-Routing
Klassifizierungsebenen bestimmen die Komplexität, bevor Anfragen an geeignete Modelle weitergeleitet werden. Einfache Aufgaben werden von schnellen und kostengünstigen Modellen bearbeitet. Komplexe Aufgaben werden an leistungsfähige LLMs (Low-Level-Modelle) weitergeleitet.
Die Implementierung erfordert mehrere Komponenten. Zunächst analysiert ein ressourcenschonender Klassifikator die eingehenden Anfragen. Dies kann ein feinabgestimmtes BERT-Modell oder auch eine noch einfachere Heuristik sein, die auf der Länge der Anfrage, den Schlüsselwörtern und der Struktur basiert.
Der Klassifikator teilt Anfragen in verschiedene Stufen ein: einfache Faktenabfragen, unkomplizierte Aufgaben, Anfragen mittlerer Komplexität und Anfragen hoher Komplexität. Jede Stufe ist einem anderen Verarbeitungspfad zugeordnet.
Teams, die intelligentes Routing implementieren, berichten von Kostensenkungen von 30-50% ohne messbare Qualitätseinbußen, wenn Routingstrategien Modelle effektiv an die Aufgabenanforderungen anpassen. Der Schlüssel liegt in einer systematischen Evaluierung, die die Routinglogik validiert und Qualitätsstandards über alle Modellebenen hinweg sicherstellt.
Optimierung von Caching und Antwortzeiten
Semantisches Caching verhindert redundante LLM-Aufrufe. Wenn Benutzer ähnliche Fragen stellen, werden zwischengespeicherte Antworten sofort und ohne zusätzliche Kosten für die Schlussfolgerung bereitgestellt.
Traditionelles Caching gleicht exakte Anfragen ab. Semantisches Caching verwendet Einbettungen, um ähnliche Fragen mit unterschiedlicher Formulierung zu identifizieren. Eine Vektorähnlichkeitssuche ermittelt, ob zwischengespeicherte Antworten neue Anfragen erfüllen.
Einbettungsmodelle sind kostengünstig. Selbst mit dem zusätzlichen Einbettungsschritt reduziert die Bereitstellung zwischengespeicherter Antworten die Kosten im Vergleich zur vollständigen LLM-Inferenz drastisch.
Die Optimierung der Antworten zielt darauf ab, die Anzahl der Ausgabetoken zu reduzieren. Eine zügige Entwicklung, die prägnante Antworten fördert, senkt die Kosten direkt. Da Ausgabetoken das 8- bis 10-fache der Eingabetoken kosten, treiben ausführliche Antworten die Kosten unverhältnismäßig in die Höhe.
Progressive Verbesserung
Beginnen Sie mit dem kleinstmöglichen Modell. Steigen Sie erst bei Bedarf auf größere Modelle um.
Ein Multiagentensystem versucht Aufgaben zunächst mit einem Modell mit 7 Milliarden Parametern. Sinkt der Konfidenzwert unter einen Schwellenwert, wiederholt das System den Vorgang automatisch mit einem leistungsfähigeren Modell. Die meisten Anfragen sind beim ersten Versuch erfolgreich. Nur in schwierigen Fällen entstehen höhere Kosten.
Dieser Ansatz erfordert eine Konfidenzkalibrierung. Modelle müssen ihre eigene Unsicherheit präzise einschätzen. Gut kalibrierte Modelle erkennen, wann ein Versagen wahrscheinlich ist und können automatisch eine Eskalation anfordern.
Kostenoptimierungsstrategien aus der Praxis
Produktionssysteme setzen mehrere Strategien gleichzeitig ein. Keine einzelne Optimierungsmaßnahme löst das Kostenproblem. Erst die Kombination führt zum Erfolg.
Schnelles Engineering für mehr Effizienz
Die Länge der Eingabeaufforderung hat direkten Einfluss auf die Kosten. Jedes Token in der Eingabeaufforderung wird verarbeitet und abgerechnet.
Übermäßiger Kontext, ausführliche Anweisungen, redundante Beispiele – all das treibt die Anzahl der Eingabe-Tokens unnötig in die Höhe. Optimierte Eingabeaufforderungen, die Anforderungen prägnant vermitteln, senken die Kosten, ohne die Qualität zu beeinträchtigen.
Wenige Beispiele demonstrieren das gewünschte Verhalten, verbrauchen aber Token. Durch das Testen verschiedener Beispielanzahlen lassen sich optimale Kompromisse ermitteln. Manchmal erreichen drei Beispiele die gleiche Genauigkeit wie zehn, benötigen aber 70% Token weniger.
Modellanpassung
Größer ist nicht immer besser. Die Auswahl eines aufgabengerechten Modells bringt Leistungsfähigkeit und Kosten in Einklang.
Benchmark-Suites wie MMLU, HumanEval und domänenspezifische Evaluierungen zeigen, welche Modelle für bestimmte Aufgaben geeignet sind. Ein Modell mit 851 TP3T-Punkten kostet möglicherweise nur ein Zehntel eines Modells mit 901 TP3T-Punkten. Der Unterschied von 5 Punkten in der Genauigkeit rechtfertigt unter Umständen nicht den zehnfachen Preis für bestimmte Anwendungen.
Umfangreiche Benchmarks und Analysen zeigen, dass kleinere Modelle bei spezialisierten Aufgaben oft die Leistungsfähigkeit deutlich größerer Modelle erreichen. DeepSeek V3.2-Exp erreicht in öffentlichen Benchmarks die Leistung seines Vorgängers V3.1 und übertrifft ihn teilweise sogar. Gleichzeitig bietet es dank architektonischer Verbesserungen eine höhere Kosteneffizienz.
Stapelverarbeitung und asynchrone Arbeitsabläufe
Echtzeit-Inferenz ist teurer als Stapelverarbeitung. Wenn keine sofortige Verarbeitung erforderlich ist, reduziert die Stapelverarbeitung von Anfragen die Kosten.
Dokumentenzusammenfassung, Inhaltsmoderation, Datenextraktion – diese Arbeitsabläufe sind oft tolerant gegenüber Latenzzeiten. Die Verarbeitung in Stapeln ermöglicht eine bessere Ressourcennutzung und die Aushandlung von Mengenrabatten mit Anbietern.
Asynchrone Workflows entkoppeln die Anfrageübermittlung von der Ergebnisübermittlung. Benutzer übermitteln Aufgaben, arbeiten parallel weiter und erhalten die Ergebnisse nach Abschluss der Verarbeitung. Diese Flexibilität ermöglicht Kostenoptimierungen, die durch Echtzeitbeschränkungen nicht möglich wären.
Vergleich der aktuellen Marktpreise
Die Preise der Anbieter variieren erheblich. Ein Preisvergleich lohnt sich.
Basierend auf Daten von Anfang 2026 konzentriert sich der Wettbewerb bei den Preisen auf mehrere Stufen. Einsteigermodelle wie GPT-5 Mini und Qwen3.5-35B-A3B beginnen bei $0,25 pro Million Input-Token und $2,00 pro Million Output-Token.
Die Preise für Modelle der mittleren Preisklasse liegen zwischen $0,30 und $0,60. Premium-Modelle mit hohem Eingangspegel überschreiten $0,60.
Die Größe des Kontextfensters beeinflusst die Wertberechnung. Modelle mit Kontextfenstern von 256.000 bis 400.000 ermöglichen andere Architekturmuster als solche mit Fenstern von 32.000 bis 128.000. Ein größerer Kontext reduziert die Notwendigkeit mehrerer Anfragen bei der Verarbeitung langer Dokumente.
| Fähigkeitsstufe | Typischer Inputpreis | Typischer Ausgabepreis | Am besten geeignet für |
|---|---|---|---|
| Eingang (7-8B) | $0.10-0.25 / 1M | $0.80-2.00 / 1M | Klassifizierung, einfacher Chat, grundlegende Zusammenfassung |
| Mitte (30-40B) | $0.25-0.60 / 1M | $2.00-3.60 / 1M | Allgemeine Aufgaben, mittelschweres logisches Denken |
| Premium (100 Mrd.+) | $0.60-2.00 / 1M | $3.60-10.00 / 1M | Komplexes Denken, spezialisierte Bereiche |
Latenz und Durchsatz variieren unabhängig vom Preis. Günstigere Modelle sind nicht zwangsläufig langsamer. Die Infrastruktur und Optimierung des Anbieters beeinflussen die Leistung ebenso stark wie die Modellgröße.
Versteckte Kosten, die zu berücksichtigen sind
Die API-Preisgestaltung ist nicht der einzige Kostenfaktor. Entwicklungszeit, Komplexität der Fehlersuche und Wartungsaufwand tragen ebenfalls zu den Gesamtbetriebskosten bei.
Die traditionelle NLP erfordert einen höheren Entwicklungsaufwand im Vorfeld. Der Aufbau von Klassifizierungspipelines, die Optimierung von Modellen und die Pflege von Regelsätzen – all diese Aufgaben erfordern qualifizierte Entwicklerzeit.
LLMs reduzieren den Entwicklungsaufwand. Schnelles Engineering ersetzt das Modelltraining. Iterationszyklen verkürzen sich. Für Teams mit begrenzter ML-Expertise gleicht die Benutzerfreundlichkeit von LLMs die höheren Inferenzkosten aus.
Bei großem Umfang überwiegen jedoch die Inferenzkosten. Ein System, das täglich Millionen von Anfragen verarbeitet, gibt im Laufe eines Jahres mehr für LLM-Token aus als für die anfängliche NLP-Entwicklung. Mit steigendem Volumen kehrt sich das Verhältnis um.
Energie- und Umweltkostenüberlegungen
Die finanziellen Kosten hängen mit dem Energieverbrauch zusammen. Untersuchungen von arxiv.org zu den Energiekosten von LLM-Inferenz-Benchmarks verdeutlichen das Verhältnis zwischen Rechenleistung und Stromverbrauch.
Die Inferenz großer Modelle erfordert erhebliche Energie. Die genauen Zahlen hängen zwar von der Hardware und der Optimierung ab, der Trend ist jedoch eindeutig: Größere Modelle verbrauchen mehr Energie pro Token.
Herkömmliche NLP-Modelle verarbeiten Anfragen mit minimalem Energieaufwand. CPU-basierte Inferenz benötigt deutlich weniger Energie als GPU-beschleunigte LLM-Inferenz.
Organisationen mit Nachhaltigkeitsverpflichtungen stehen unter doppeltem Druck: finanzielle Optimierung und Reduzierung des CO₂-Fußabdrucks. Glücklicherweise lassen sich diese Ziele vereinbaren. Strategien zur Senkung der LLM-Kosten reduzieren in der Regel gleichzeitig den Energieverbrauch.
Effizientes Routing, das einfache Anfragen an schlanke Modelle weiterleitet, senkt Kosten und Emissionen. Die bedarfsgerechte Dimensionierung von Modellen führt neben Kosteneinsparungen auch zu ökologischen Vorteilen.
Aufbau einer kostenbewussten Architektur
Nachhaltige KI-Systeme überwachen und optimieren die Kosten kontinuierlich. Eine einmalige Optimierung reicht nicht aus. Nutzungsmuster ändern sich. Die Preisgestaltung der Modelle ändert sich. Die Anforderungen entwickeln sich weiter.
Kostenüberwachung und -zuordnung
Die Nachverfolgung von Ausgaben nach Funktionen, Nutzergruppen oder Arbeitsabläufen deckt Optimierungspotenziale auf. Aggregierte Kennzahlen verschleiern hingegen, welche Komponenten die Ausgaben verursachen.
Die detaillierte Protokollierung erfasst Metadaten der Anfragen: verwendetes Modell, Tokenanzahl, Latenz, Kosten und Geschäftskontext. Diese Daten ermöglichen Analysen, die kostenintensive Muster identifizieren.
Manche Funktionen können im Verhältnis zum Geschäftswert unverhältnismäßig hohe Kosten verursachen. Eine Nutzungsanalyse könnte aufzeigen, dass 51.030 Nutzer 601.030 des LLM-Budgets durch ineffiziente Interaktionsmuster verbrauchen. Gezielte Optimierung oder Funktionsüberarbeitung kann diese Ausreißer beheben.
Test- und Bewertungsrahmen
Kostenoptimierung erfordert Messungen. Qualitätskennzahlen bestätigen, dass kostengünstigere Alternativen eine akzeptable Leistung erbringen.
Evaluierungsrahmen vergleichen die Modellausgaben verschiedener Stufen. Eine menschliche Bewertung oder eine automatisierte Qualitätsbewertung entscheidet darüber, ob kleinere Modelle für bestimmte Aufgaben eine ausreichende Genauigkeit erreichen.
A/B-Tests im Produktivbetrieb messen die Nutzerzufriedenheit bei verschiedenen Modellauswahlen. Können Nutzer bei bestimmten Suchanfragen keinen Unterschied zwischen den Antworten eines 7B-Modells und eines 70B-Modells feststellen, bietet das teurere Modell keinen Mehrwert.
Kontinuierliche Optimierungsschleifen
Statische Architekturen werden mit der Verbesserung von Modellen und sich ändernden Preisen suboptimal. Regelmäßige Evaluierungen identifizieren bessere Alternativen.
Neue Modelle kommen regelmäßig auf den Markt. Ein im nächsten Monat erscheinendes Modell könnte ein besseres Preis-Leistungs-Verhältnis bieten als die aktuellen Modelle. Kontinuierliche Vergleiche mit Neuerscheinungen gewährleisten, dass die Systeme den bestmöglichen Nutzen bieten.
Preisanpassungen erfolgen ohne Vorankündigung. Die Beobachtung von Preisänderungen bei verschiedenen Anbietern ermöglicht einen opportunistischen Wechsel, wenn Wettbewerber günstigere Konditionen bieten.
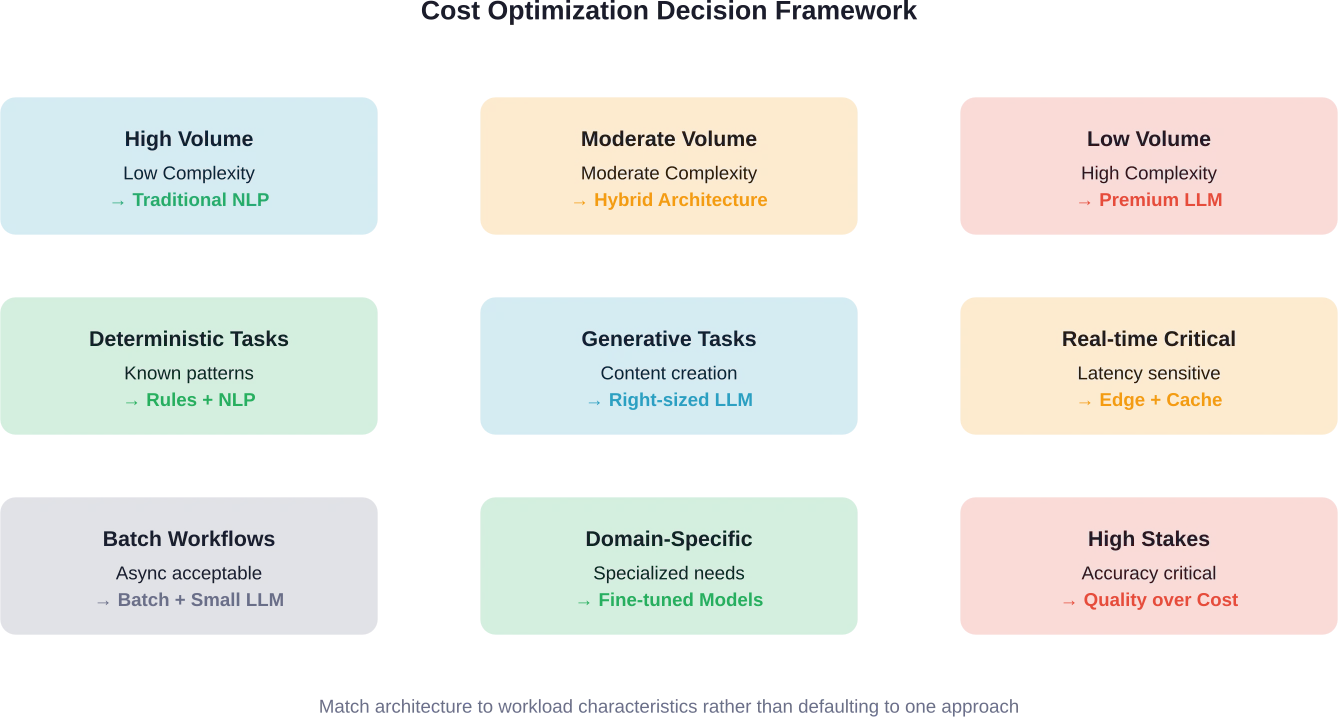
Zukünftige Kostentrends
Die Preisentwicklung ist für die langfristige Planung wichtig. Mehrere Faktoren beeinflussen die zukünftigen Kosten.
Die Effizienz der Modelle verbessert sich stetig. Architektonische Innovationen führen zu einer besseren Leistung pro Parameter. Forschungsergebnisse von arxiv.org zur Effizienz großer Sprachmodelle dokumentieren algorithmische Fortschritte, die den Rechenaufwand reduzieren.
Neu gestaltete Modelle erreichen durch Architekturoptimierung mit weniger Parametern die gleichen Fähigkeiten. Mit zunehmender Reife dieser Techniken sinken die Kosten pro Fähigkeitseinheit.
Der Wettbewerb zwischen den Anbietern übt einen Abwärtsdruck auf die Preise aus. Mit dem Markteintritt weiterer Anbieter beschleunigt sich der Preisverfall. Die Einführung von GPT-5 Mini, Gemini 2.5 Flash und Claude 3.5 Haiku schuf eine neue Klasse leistungsstarker Modelle zu deutlich niedrigeren Preisen als die Vorgängergenerationen.
Die Hardwareverbesserungen schreiten voran. Neue GPU-Architekturen ermöglichen einen höheren Durchsatz bei Inferenzprozessen. Dank der gesteigerten Hardwareeffizienz können Anbieter niedrigere Preise anbieten und gleichzeitig ihre Gewinnmargen halten.
Doch gleichzeitig steigt die Nachfrage. Mit der zunehmenden Integration von LLMs in immer mehr Anwendungen steigen die Gesamtausgaben, selbst wenn die Kosten pro Token sinken. Unternehmen, die ihre Prozesse nicht aktiv optimieren, sehen sich trotz fallender Stückpreise mit steigenden Ausgaben konfrontiert.
Implementierungsfahrplan
Der Übergang von einer teuren reinen LLM-Architektur zu kostenoptimierten Hybridsystemen erfordert Planung.
Phase 1: Messung und Analyse
Instrumentieren Sie bestehende Systeme, um detaillierte Nutzungsmetriken zu erfassen. Ohne Daten ist Optimierung reine Spekulation.
Jede LLM-Anfrage wird mit Metadaten protokolliert: Zeitstempel, Benutzer, Funktion, Eingabeaufforderungstoken, Abschlusstoken, verwendetes Modell, Latenz und Kosten. Diese Daten werden zur Analyse aggregiert.
Identifizieren Sie Muster. Welche Funktionen generieren die meisten Anfragen? Welche Benutzer verbrauchen die meisten Tokens? Welche Aufforderungsmuster treten häufig auf?
Berechnen Sie die Kosten pro Funktion, pro Nutzersegment und pro Geschäftsergebnis. Dadurch wird deutlich, wo Optimierungsmaßnahmen den größten Nutzen bringen.
Phase 2: Schnelle Erfolge
Schnell umsetzbare Maßnahmen ermöglichen sofortige Einsparungen und schaffen gleichzeitig die Grundlage für größere Initiativen.
Implementieren Sie eine Optimierung der Eingabeaufforderung. Entfernen Sie unnötigen Kontext, überflüssige Anweisungen und fassen Sie Beispiele zusammen. Dies erfordert minimalen Entwicklungsaufwand, reduziert aber sofort den Tokenverbrauch.
Fügen Sie semantisches Caching hinzu. Für die meisten Programmiersprachen existieren Bibliotheken, die die Implementierung vereinfachen. Durch Caching lassen sich 20 bis 401 Tsd. Anfragen mit minimalen Codeänderungen einsparen.
Die richtige Größe für offensichtliche Fälle finden. Aufgaben, die derzeit Premium-Modelle verwenden, aber mit Modellen der mittleren Preisklasse gleichwertige Ergebnisse erzielen, bieten klare Optimierungsmöglichkeiten.
Phase 3: Strategische Architektur
Größere Initiativen erfordern zwar mehr Planung, führen aber zu erheblichen und dauerhaften Einsparungen.
Erstellen Sie die Klassifizierungs- und Routing-Schicht. Diese bildet die Grundlage für weitere Optimierungen. Beginnen Sie einfach – klassifizieren Sie Anfragen zunächst in zwei oder drei Stufen.
Setzen Sie aufgabenspezifische NLP-Modelle für deterministische Workloads mit hohem Datenvolumen ein. Diese ersetzen LLM-Aufrufe in bestimmten Anwendungsfällen vollständig.
Implementieren Sie progressive Verbesserung für komplexe Abfragen. Versuchen Sie zunächst kostengünstigere Modelle und eskalieren Sie erst bei Bedarf.
Phase 4: Kontinuierliche Verbesserung
Optimierung ist kein Projekt mit einem Enddatum. Es ist eine fortlaufende Praxis.
Planen Sie vierteljährliche Überprüfungen der Modellleistung und der Preisgestaltung ein. Ständig kommen neue Optionen hinzu. Regelmäßige Evaluierungen gewährleisten, dass sich die Systeme an die sich verändernden Rahmenbedingungen anpassen.
Überwachen Sie Kostenkennzahlen parallel zu Geschäftskennzahlen. Behandeln Sie Kosteneffizienz als wichtigen Leistungsindikator neben Qualität, Latenz und Kundenzufriedenheit.
Experimentieren Sie mit neuen Ansätzen. Planen Sie ein Budget für das Testen alternativer Architekturen, neuer Modelle und verschiedener Anbieter ein. Die optimale Lösung für das nächste Quartal existiert möglicherweise noch nicht.

Reduzieren Sie Ihre KI-Kosten, bevor sie außer Kontrolle geraten.
Die Entscheidung zwischen NLP-Systemen und großen Sprachmodellen kann die langfristigen Ausgaben für KI dramatisch beeinflussen. AI Superior Das Unternehmen arbeitet mit Firmen zusammen, die KI-Systeme für den praktischen Einsatz benötigen. Das Team entwickelt und optimiert Lernmodelle, erstellt aufgabenspezifische Modelle und optimiert KI-gestützte Arbeitsabläufe, damit Unternehmen den Rechenaufwand reduzieren und gleichzeitig die Leistung aufrechterhalten können.
Wenn Sie die KI-Kosten senken statt sie nur zu erhöhen möchten, sprechen Sie mit AI Superior und erhalten Sie praktische Anleitungen zum Aufbau effizienterer KI-Systeme.
Häufige Fallstricke, die es zu vermeiden gilt
Kostenoptimierung kann kontraproduktiv sein, wenn sie unachtsam durchgeführt wird. Mehrere Fehler treten immer wieder auf.
Vorzeitige Optimierung
Frühphasenprojekte profitieren von der durch LLMs ermöglichten schnellen Iteration. Wochenlanges Entwickeln kundenspezifischer NLP-Pipelines vor der Validierung der Produkt-Markt-Passung ist ressourcenverschwendend.
Beginnen Sie mit dem einfachsten Ansatz, der funktioniert. Optimieren Sie erst, wenn der Umfang es erfordert, nicht vorher. Vorzeitige Optimierung lenkt von der Kernproduktentwicklung ab.
Optimierung ohne Messung
Annahmen über die Kostentreiber erweisen sich oft als falsch. Detaillierte Messungen offenbaren überraschende Muster.
Teams optimieren mitunter die falschen Komponenten. Eine Funktion, die teuer erscheint, kann 31 TP3T der Gesamtkosten ausmachen. Gleichzeitig verschlingt ein übersehener Workflow unbemerkt 401 TP3T des Budgets.
Zuerst messen. Dann die wichtigsten Bereiche optimieren. Weniger wichtige Faktoren ignorieren, bis die Hauptprobleme gelöst sind.
Qualität aus Kostengründen opfern
Aggressive Kostensenkungsmaßnahmen, die die Produktqualität mindern, erweisen sich als kontraproduktiv. Schlechte KI-Erfahrungen schädigen das Vertrauen der Nutzer und mindern den Produktwert.
Qualitätsstandards einhalten. Mithilfe von Bewertungsrahmen überprüfen, ob günstigere Alternativen die Anforderungen erfüllen. Falls nicht, ist die teurere Option die richtige Wahl.
Entwicklungsgeschwindigkeit ignorieren
Komplexe Kostenoptimierungsarchitekturen können die Entwicklung verlangsamen. Für Produkte in der Frühphase ist es selten sinnvoll, Agilität gegen marginale Einsparungen einzutauschen.
Den Optimierungsaufwand gegen den Geschäftsnutzen abwägen. Ein System, das 1.000 Anfragen pro Tag verarbeitet, benötigt nicht dieselbe Optimierungsstrenge wie ein System, das 1.000.000 Anfragen verarbeitet.
Häufig gestellte Fragen
Wie viel kann eine hybride NLP + LLM-Architektur realistischerweise einsparen?
Forschungs- und Praxisberichte dokumentieren Kostensenkungen zwischen 401 TP³T und 901 TP³T, abhängig von den Arbeitslastmerkmalen. Systeme mit einem hohen Volumen einfacher Anfragen erzielen die größten Einsparungen. Anwendungen, die von komplexen generativen Aufgaben dominiert werden, weisen geringere, aber dennoch signifikante Einsparungen auf. Entscheidend ist der Anteil der Anfragen, die mit kostengünstigeren NLP-Verfahren bearbeitet werden können, im Vergleich zu solchen, die umfassende LLM-Funktionen erfordern.
Sind kleinere LLMs tatsächlich leistungsfähig genug für den Produktionseinsatz?
Moderne kleine LLMs wie GPT-5 Mini erzielen in Benchmarks überraschend hohe Ergebnisse. OpenAI berichtet von 91,11 TP3T bei AIME-Mathematikaufgaben und 87,81 TP3T bei internen Intelligenzmessungen. Für viele Produktionsaufgaben erreichen oder übertreffen diese Modelle die Qualität großer Modelle der vorherigen Generation und sind dabei 5- bis 10-mal günstiger. Eine aufgabenspezifische Evaluierung ist unerlässlich, da die Leistung je nach Anwendungsfall variiert.
Ab welchem Punkt rechnet sich die Entwicklung eigener NLP-Modelle im Vergleich zur Verwendung von LLMs?
Generell rechtfertigen deterministische Aufgaben mit hohem Anfragevolumen die Entwicklung individueller NLP-Modelle. Wenn eine Aufgabe täglich Tausende von Anfragen erhält und durch Klassifizierung oder Extraktion gelöst werden kann, amortisieren sich die individuellen Modelle innerhalb weniger Wochen. Aufgaben mit niedrigem Anfragevolumen oder hoher Variabilität begünstigen hingegen LLMs trotz höherer Kosten pro Anfrage, da sich der Entwicklungsaufwand nicht auf genügend Anfragen amortisieren lässt.
Wie kann ich feststellen, welche Anfragen teure und welche günstige Modelle erfordern?
Beginnen Sie mit einem einfachen Klassifikator, der die Merkmale von Anfragen analysiert: Länge, Struktur, Schlüsselwörter und Domäne. Leiten Sie die Anfragen anhand dieser Signale an die entsprechenden Modellebenen weiter. Die anfängliche Klassifizierungsgenauigkeit muss nicht perfekt sein – implementieren Sie Feedbackschleifen, die falsch weitergeleitete Anfragen erkennen und die Klassifizierung im Laufe der Zeit verfeinern. Viele Teams berichten, dass einfache Heuristiken als Ausgangspunkt überraschend gut funktionieren.
Welche Kennzahlen sollte ich zur Kostenoptimierung im Bereich LLM überwachen?
Erfassen Sie die Tokenanzahl für Eingabe und Ausgabe separat, da die Preise deutlich variieren. Überwachen Sie die Kosten pro Anfrage, pro Benutzer, pro Funktion und pro Geschäftsergebnis. Verfolgen Sie die Verteilung der Modellauswahl, um Routingmuster zu verstehen. Messen Sie die Cache-Trefferraten, wenn Sie semantisches Caching verwenden. Überwachen Sie Qualitätsmetriken zusammen mit den Kosten, um sicherzustellen, dass die Optimierung die Leistung nicht beeinträchtigt. Richten Sie Warnmeldungen ein, wenn die Kosten die erwarteten Muster überschreiten.
Ist es aus Kostengründen besser, API-Dienste oder Self-Hosting-Modelle zu nutzen?
Die Antwort hängt von Umfang und technischer Leistungsfähigkeit ab. API-Dienste bieten Komfort und eliminieren den Aufwand für die Infrastrukturverwaltung. Bei moderaten Datenmengen ist die Abrechnung pro Token oft wirtschaftlicher als der Betrieb einer GPU-Infrastruktur. Selbsthosting wird erst bei sehr hohen Datenmengen kosteneffektiv, wenn die Kosten pro Anfrage die amortisierten Infrastrukturkosten übersteigen. Analysen von Hugging Face zeigen, dass die Kapitalinvestitionen und nicht die operative Komplexität die größte Hürde für Selbsthosting darstellen.
Wie häufig ändern sich die Preise für LLM-Projekte und sollte ich das bei meiner Planung berücksichtigen?
Preisänderungen der Anbieter erfolgen regelmäßig, manchmal ohne Vorankündigung. Große Releases führen oft neue Preisstufen ein. Abstraktionsschichten, die die Modellauswahl von der Geschäftslogik trennen, ermöglichen den Wechsel von Anbietern oder Modellen ohne umfangreiche Refaktorisierung. Die Unterstützung mehrerer Anbieter ermöglicht ein opportunistisches Routing zu demjenigen, der zum jeweiligen Zeitpunkt das günstigste Angebot für bestimmte Anfragetypen bietet.
Schlussfolgerung
Die Wahl zwischen NLP und LLMs ist nicht binär. Die kosteneffektivsten KI-Systeme für den Produktiveinsatz kombinieren beide Ansätze strategisch.
Traditionelle NLP-Verfahren eignen sich hervorragend für deterministische Aufgaben mit hohem Datenaufkommen. Regelbasierte Systeme und spezialisierte Modelle verarbeiten einfache Anfragen kostengünstig. LLMs bieten Fähigkeiten, die traditionelle Methoden nicht erreichen, allerdings zu deutlich höheren Kosten.
Eine intelligente Architektur leitet Anfragen an die jeweils geeigneten Verarbeitungsebenen weiter. Klassifizierungsebenen identifizieren einfache Aufgaben, die keine aufwendigen Modelle benötigen. Komplexe Schlussfolgerungen werden an leistungsfähige LLMs weitergeleitet. Dieser hybride Ansatz senkt die Kosten um 40–901 TP3T bei gleichbleibender Qualität.
Kostenoptimierung erfordert kontinuierliche Anstrengungen. Messungen decken Muster auf. Evaluierungen bestätigen Alternativen. Regelmäßige Überprüfungen gewährleisten die Weiterentwicklung von Systemen im Zuge von Modellverbesserungen und Preisänderungen.
Beginnen Sie mit der Messung. Analysieren Sie Ihr bestehendes System, um Ausgabenmuster zu verstehen. Identifizieren Sie schnelle Erfolge durch zügige Optimierung und Caching. Entwickeln Sie eine strategische Architektur für langfristige Effizienz. Betrachten Sie Kostenmanagement als fortlaufenden Prozess und nicht als einmaliges Projekt.
Organisationen, die dieses Gleichgewicht beherrschen, werden nachhaltige und wirtschaftlich skalierbare KI-Systeme entwickeln. Diejenigen, die standardmäßig auf teure Modelle setzen, werden mit Budgetbeschränkungen konfrontiert sein, die Innovationen hemmen.
Jetzt sind Sie am Zug: Analysieren Sie Ihre aktuellen Kosten, identifizieren Sie Optimierungspotenziale und setzen Sie systematische Verbesserungen um. Die Werkzeuge und Techniken sind vorhanden. Die Frage ist nur, ob Sie sie auch nutzen werden.