Kurzzusammenfassung: Die Implementierung von Open-Source-LLM kostet die meisten Organisationen jährlich zwischen 125.000 und über 820.000 US-Dollar und übersteigt damit die API-Preise für typische Workloads deutlich. Zwar sind die Modellgewichte kostenlos, doch Infrastruktur, Entwicklerpersonal, Betriebskosten und Wartung verursachen erhebliche versteckte Ausgaben, die kommerzielle LLM-Dienste bis zum Erreichen bestimmter Gewinnschwellen kosteneffizienter machen.
Das Angebot klingt verlockend: Laden Sie ein Open-Source-Sprachmodell herunter, implementieren Sie es auf Ihrer Infrastruktur und verabschieden Sie sich für immer von API-Rechnungen.
Aber hier ist der Haken: Dieses “kostenlose” Modell kostet Sie je nach Umfang Ihres Unternehmens zwischen 1.250.000 und über 1.200.0 ...
Open-Source-LLMs verlagern die Kosten von transparenten API-Gebühren zu versteckten Betriebskosten. Laut einer im Rahmen einer Kosten-Nutzen-Analyse präsentierten Studie stehen Unternehmen vor einer wichtigen Entscheidung: Entweder sie abonnieren kommerzielle LLM-Dienste von Anbietern wie OpenAI, Anthropic und Google oder sie implementieren Modelle auf ihrer eigenen Infrastruktur. Die Analyse zeigt, dass die meisten Annahmen über Kosteneinsparungen grundlegend fehlerhaft sind.
Diese Analyse untersucht die realen wirtschaftlichen Auswirkungen des Einsatzes von Open-Source-LLM-Programmen im Jahr 2026, gestützt auf Daten aus Produktionsimplementierungen und akademischen Kosten-Nutzen-Analysen.
Der Mythos des Gratismodells: Wofür Sie tatsächlich bezahlen
Die Gewichte der Open-Source-Modelle können kostenlos heruntergeladen werden. Alles andere ist kostenpflichtig.
Wenn Unternehmen die Kosten eines Downloads von 1 TP4T0 mit der API-Preisgestaltung vergleichen, die pro Token abrechnet, scheint die Rechnung auf der Hand zu liegen. Dieser Vergleich ist jedoch irreführend. Die heruntergeladenen Modellgewichte entsprechen etwa 2 bis 51 TP3T0 der gesamten Bereitstellungskosten.
Die restlichen 95-98% stammen von:
- Hardwareinfrastruktur (GPUs, Server, Netzwerk)
- Ingenieurtalente (ML-Ingenieure, MLOps-Spezialisten, Infrastrukturteams)
- Betrieblicher Aufwand (Überwachung, Skalierung, Zuverlässigkeit)
- Wartung und Aktualisierungen (Sicherheitspatches, Modellneutraining, Leistungsoptimierung)
- Integrationsarbeiten (Anbindung von Modellen an bestehende Systeme)
Untersuchungen zu On-Premise-Implementierungen ergaben, dass Unternehmen bestimmte Nutzungsschwellenwerte erreichen müssen, bevor selbstgehostete Modelle mit kommerziellen Diensten wettbewerbsfähig werden. Für die meisten typischen Workloads wird diese Schwelle nie erreicht.
Infrastrukturkosten: Die GPU-Realität
Die Ausführung von LLMs erfordert erhebliche Rechenressourcen. Nicht die eines Laptops. Es bedarf einer GPU-Infrastruktur im industriellen Maßstab.
Hardwareanforderungen je nach Modellgröße
Ein Modell mit 7 Milliarden Parametern kann mit hohen Inferenzgeschwindigkeiten auf einer einzelnen NVIDIA L4 (24 GB) oder sogar auf einer Consumer-Grafikkarte vom Typ RTX 4090/5090 ausgeführt werden und benötigt dabei deutlich weniger Strom als ein A100. Die 13-Milliarden-Parameter-Modelle benötigen mehrere GPUs. Modelle im Bereich von 70 Milliarden Parametern und mehr erfordern ganze GPU-Cluster.
Und das sind keine Billig-Grafikkarten. Laut Marktpreisen kostet eine einzelne NVIDIA A100 80GB GPU etwa 10.000 bis 15.000 Tsd. 4 Tsd. Die neuere H100 kostet etwa 25.000 bis 40.000 Tsd. 4 Tsd. 4 Tsd. pro Stück. Die meisten Unternehmen benötigen mehrere Einheiten für produktive Anwendungen.
| Modellgröße | Mindesten GPU-Speicher | Typische Hardware | Ungefähre Kosten
|
|---|---|---|---|
| 7B-Parameter | 16-24 GB | 1x A100 40GB | $10,000-$15,000 |
| 13B-Parameter | 32-48 GB | 1x A100 80GB oder 2x A100 40GB | $20,000-$30,000 |
| 70B-Parameter | 140-280 GB | 4x A100 80GB oder 2x H100 | $50,000-$80,000 |
| 175B+ Parameter | 350 GB+ | 8x A100 80GB oder GPU-Cluster | $100,000+ |
Cloud vs. On-Premise: Abwägungen
Unternehmen stehen vor zwei Infrastrukturwegen: dem Aufbau eigener Rechenzentren oder der Anmietung von Cloud-GPU-Instanzen.
On-Premise-Infrastruktur erfordert hohe Vorabinvestitionen. Die Budgets reichen von 1.450.000 INR für minimale Implementierungen bis über 1.450.000 INR für Cluster im Produktionsmaßstab. Doch die Investitionskosten sind nur der Anfang. Strom, Kühlung, Stellfläche und Wartung verursachen jährliche Mehrkosten von 20.000 bis 401.300 INR.
Cloud-GPU-Instanzen eliminieren zwar die Vorabkosten, verursachen aber laufende Betriebskosten. Cloud-GPU-Instanzen von Anbietern wie AWS kosten etwa 1.400 bis 1.400 US-Dollar pro Stunde für Konfigurationen mit 8 GPUs, was monatlichen Kosten von 1.400 bis 1.400 US-Dollar im Dauerbetrieb entspricht. Google Cloud und Azure bieten ähnliche Preisstrukturen.
Neuere Innovationen wie Quantisierungstechniken ermöglichen es, einige Modelle auf handelsüblicher Hardware auszuführen. Laut der Dokumentation von Hugging Face zu SmallThinker-Modellen können Modelle mit Q4_0-Quantisierung auf herkömmlichen Prozessoren über 20 Token pro Sekunde verarbeiten. Aufgrund von Kompromissen zwischen Leistung und Genauigkeit eignet sich dieser Ansatz jedoch nur für bestimmte Anwendungsfälle.
Die Personalkosten: Die benötigten Ingenieurteams
Die Infrastruktur ist greifbar. Die Personalkosten hingegen sind der Bereich, in dem die Budgets wirklich stark belastet werden.
Die Bereitstellung und Wartung von Open-Source-LLMs ist kein Projekt für eine einzelne Person. Für den Produktiveinsatz sind spezialisierte Entwicklerteams erforderlich, deren Gehälter die Infrastrukturkosten um ein Vielfaches übersteigen.
Anforderungen an das Kernteam
- Ingenieure für maschinelles Lernen: Entwickeln Sie Inferenzpipelines, optimieren Sie die Modellleistung und implementieren Sie Techniken wie Quantisierung und Batching. Gehaltsspanne: 150.000–250.000 INR jährlich. Die meisten Unternehmen benötigen mindestens zwei Mitarbeiter, um eine umfassende Abdeckung und Expertise zu gewährleisten.
- MLOps-Ingenieure: Verwaltung der Bereitstellungsinfrastruktur, Betreuung von Kubernetes-Clustern, Wartung von Docker-Containern, Konfiguration von GPU-Kontingenten und Implementierung von Inferenz-Stacks wie vLLM oder NVIDIA Triton. Gehaltsspanne: 140.000–230.000 INR jährlich. Entscheidend für die Skalierung über die Proof-of-Concept-Phase hinaus.
- Softwareintegrationsingenieure: Laut Diskussionen in der Community fließen rund 601 Tsd. 300 Tsd. Ingenieursleistungen in KI-Projekten in den sogenannten “Klebstoff” – die Verbindung von Modellen mit Datenbanken, Authentifizierungssystemen und Benutzeroberflächen. Gehaltsspanne: 1 Tsd. 400 Tsd. 130.000 bis 1 Tsd. 400 Tsd. 200.000 jährlich.
- DevOps-/Infrastruktur-Ingenieure: Serverwartung, Netzwerkadministration, Sicherstellung der Einhaltung von Sicherheitsstandards und Notfallwiederherstellung. Gehaltsspanne: 120.000–190.000 INR jährlich.
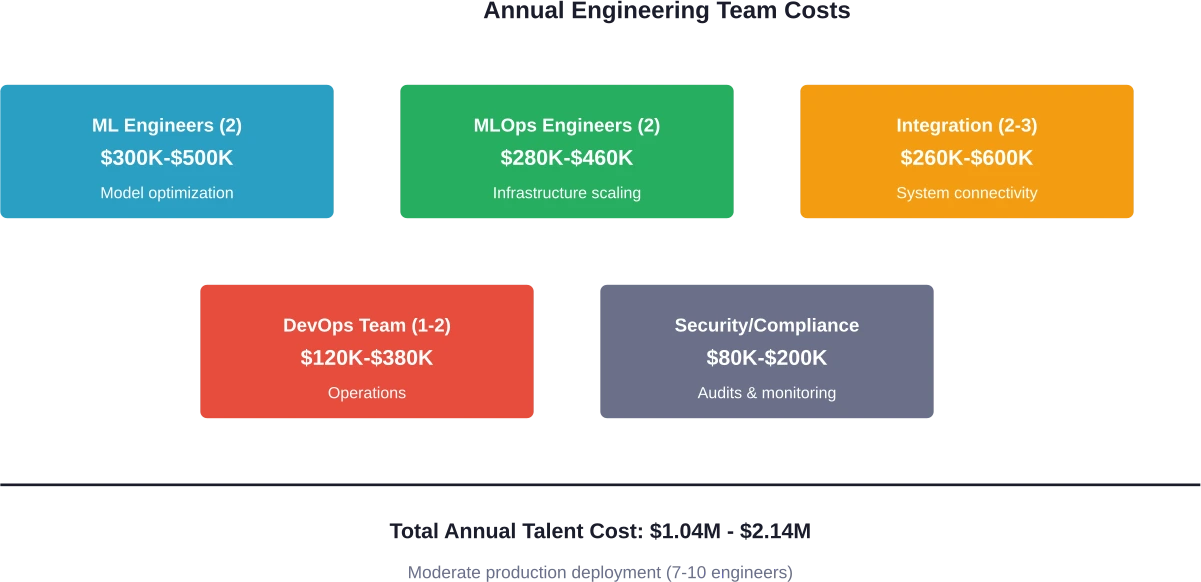
Für minimale interne Implementierungen werden mindestens 3–4 Ingenieure benötigt. Kundenorientierte Funktionen erfordern 7–10. Implementierungen im Unternehmensmaßstab benötigen 15 oder mehr spezialisierte Mitarbeiter.
Gemäß der aktuellen API-Preisgestaltung von 2026 kosten GPT-4-Modelle (und ihre Nachfolger wie GPT-5) etwa $0,0025–$0,01 pro 1.000 eingegebenen Token. Ein ML-Ingenieur kostet jährlich $200.000. Dieser Ingenieur muss Ihnen API-Aufrufe im Wert von 6,6 Milliarden Token einsparen, nur um allein seine Gehaltskosten zu decken.
Betriebskosten: Der monatliche Abfluss
Infrastruktur und Gehälter sind planbare Kostenfaktoren. Bei den Betriebskosten hingegen stößt das Budget auf die Realität.
Überwachung und Beobachtbarkeit
Produktionsfähige LLMs erfordern umfassendes Monitoring: Latenzmessung, Durchsatzmetriken, Fehlerraten, GPU-Auslastung, Speicherverbrauch und Erkennung von Qualitätsbeeinträchtigungen. Tools wie Prometheus, Grafana und spezialisierte ML-Observability-Plattformen verursachen monatliche Kosten von 1,4 TP4T2.000 bis 1,4 TP4T10.000.
Datenspeicherung und -übertragung
Die Modellgewichte für ein Modell mit 70 Milliarden Parametern belegen über 140 GB Speicherplatz. Trainingsdaten, Feinabstimmungsdatensätze und Inferenzprotokolle fügen weitere Terabytes hinzu. Cloud-Speicher kostet monatlich 10,02–10,05 Pence pro GB. Hinzu kommen Gebühren für den Datentransfer – die Gebühren für ausgehende Daten großer Cloud-Anbieter liegen bei 10,08–10,12 Pence pro GB.
Skalierung und Lastverteilung
Für den Produktivbetrieb ist eine automatische Skalierung erforderlich, um variable Lasten zu bewältigen. Untersuchungen zum mehrstufigen LLM-Serving (MIST-Simulatorstudie) zeigen, dass optimierte Bereitstellungen durch sorgfältige Architekturentscheidungen eine bis zu 2,8-fache Steigerung des Token-pro-Dollar-Verhältnisses erzielen können. Die Implementierung dieser Optimierungen erfordert jedoch eine ausgefeilte Infrastruktur.
Load Balancer, Container-Orchestrierung und Redundanzsysteme verursachen monatlich zusätzliche Kosten von $5.000 bis $25.000 für mittelgroße Implementierungen.
Sicherheit und Compliance
Selbstgehostete Modelle erfordern Sicherheitsaudits, Compliance-Zertifizierungen und Schwachstellenmanagement. In regulierten Branchen steigen diese Kosten erheblich. HIPAA-Compliance-Audits kosten für bestehende Infrastrukturen typischerweise 20.000 bis 50.000 Euro jährlich, während die SOC-2-Typ-II-Zertifizierung inklusive Auditgebühren zwischen 30.000 und 60.000 Euro kostet.
Einsatzszenarien: Reale Kostenaufschlüsselungen
Abstrakte Zahlen sind bedeutungslos. Hier sind die Kosten realer Einsatzszenarien im Jahr 2026.
Szenario 1: Minimales internes Werkzeug
Anwendungsfall: Interner Chatbot für Mitarbeiterfragen, 100–500 Mitarbeiter, geringes Nutzungsaufkommen
Aufstellen:
- Einzelparametermodell mit 7B Parametern (Llama 3 oder Mistral)
- 1x A100 40GB GPU (Cloud-gehostet)
- 2 ML-Ingenieure (Teilzeit)
- Grundlegende Überwachung und Infrastruktur
Jährliche Kosten:
- GPU-Infrastruktur: $15,000-$20,000
- Ingenieurtalent (teilweise): $80,000-$120,000
- Überwachung und Tools: $10,000-$15,000
- Speicher und Netzwerk: $5,000-$10,000
- Sicherheit und Compliance: $15,000-$25,000
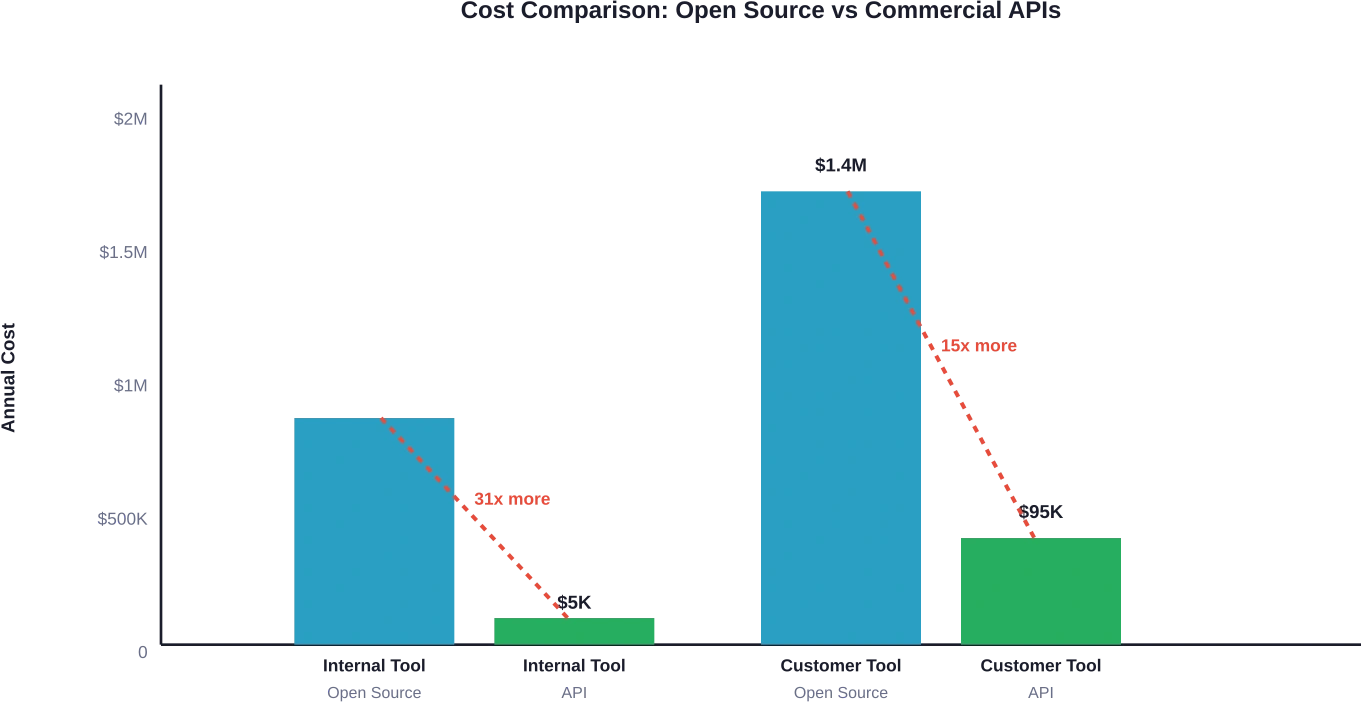
Gesamt: $125.000-$190.000 jährlich
Zum Vergleich: Die Nutzung über kommerzielle APIs wäre bei vergleichbaren Token-Volumina deutlich günstiger – typischerweise $3.000 bis $15.000 pro Jahr. Der Break-even-Punkt wird nie erreicht.
Szenario 2: Kundenorientiertes Merkmal
Anwendungsfall: Chatbot oder Content-Generierung für über 10.000 monatlich aktive Nutzer, moderate Nutzung
Aufstellen:
- 13B-70B-Parametermodell mit Feinabstimmung
- 4x A100 80GB GPUs mit automatischer Skalierung
- 7-10 Mitglieder des Ingenieurteams
- Überwachung und Zuverlässigkeit in Produktionsqualität
- 24/7-Rufbereitschaft
Jährliche Kosten:
- GPU-Infrastruktur: $120,000-$200,000
- Ingenieurteam: $700,000-$1,400,000
- Überwachung und Beobachtbarkeit: $30,000-$60,000
- Speicher, Netzwerk, CDN: $25,000-$50,000
- Sicherheit, Compliance, Audits: $50,000-$80,000
- Bereitschaftsdienst und Reaktion auf Zwischenfälle: $25,000-$30,000
Gesamt: $950.000-$1.820.000 jährlich
Vergleichbare kommerzielle API: geschätzte jährliche Kosten von $40.000 bis $150.000 bei ähnlichen Nutzungsmustern, abhängig vom gewählten Modell. Selbsthosting ist erst ab einem monatlichen Token-Volumen von über 500 Millionen bis 1 Milliarde Token wirtschaftlich sinnvoll.
Szenario 3: Enterprise Core Product
Anwendungsfall: LLM als primäre Produktplattform, Millionen von Nutzern, hohe Verfügbarkeitsanforderungen
Aufstellen:
- Mehrere Modelle mit über 70 Milliarden Parametern und A/B-Tests
- GPU-Cluster (16-32 Einheiten) über mehrere Regionen
- 15-25 Ingenieurspezialisten
- Infrastruktur auf Unternehmensebene mit Redundanz
- Spezielle Sicherheits- und Compliance-Teams
Jährliche Kosten:
- GPU-Infrastruktur: $1,500,000-$3,000,000
- Ingenieurteams: $2,500,000-$5,000,000
- Überwachung und Analyse: $200,000-$400,000
- Speicher und Netzwerk: $300,000-$600,000
- Sicherheit und Compliance: $400,000-$800,000
- Ausbildung und Forschung & Entwicklung: $500,000-$1,000,000
Gesamt: $5.400.000-$10.800.000 jährlich
Diese Skala stellt die Schwelle dar, ab der Self-Hosting potenziell kostenwettbewerbsfähig mit kommerziellen APIs für Nutzungsmuster im Bereich von 500 Millionen bis über 1 Milliarde Token pro Monat wird.
Wann Open Source sich finanziell tatsächlich lohnt
Der Einsatz von Open-Source-Software ist nicht grundsätzlich falsch. Bestimmte Szenarien rechtfertigen die Investition.
Break-Even-Schwellenwertanalyse
Untersuchungen zur Wirtschaftlichkeit von On-Premise-Bereitstellungen identifizieren kritische Break-Even-Punkte, an denen selbstgehostete Modelle mit kommerziellen Diensten preislich konkurrenzfähig werden.
Der Schwellenwert hängt vom Tokenvolumen ab. Für typische Unternehmens-Workloads gilt:
- Unter 100 Millionen Token pro Monat: Kommerzielle APIs gewinnen eindeutig.
- 100 bis 500 Millionen Token monatlich: Die Kosten gleichen sich an, aber APIs bleiben oft günstiger, wenn der Entwicklungsaufwand berücksichtigt wird.
- 500 Millionen bis 1 Milliarde Token monatlich: Gewinnschwelle, ab der sich Selbsthosting für die Kosten lohnen kann
- Monatlich über 1 Milliarde Token: Selbsthosting bietet klare Kostenvorteile
Das reine Tokenvolumen ist jedoch nicht der einzige Faktor.
Nichtfinanzielle Treiber
- Datenschutz und Datensouveränität: Regulierte Branchen, die sensible Daten verarbeiten (Gesundheitswesen, Finanzwesen, Behörden), unterliegen Compliance-Anforderungen, die die Nutzung externer APIs untersagen. Selbsthosting ist daher unabhängig von den Kosten obligatorisch.
- Latenzanforderungen: Anwendungen, die Antwortzeiten unter 100 ms erfordern, vertragen keine Netzwerkzugriffe auf externe APIs. Laut einer Analyse von Hugging Face zum Vergleich von Edge- und Cloud-Inferenz beeinflussen Netzwerkdistanz und -auslastung die p95-Latenz erheblich. Für latenzkritische Anwendungen ist eine lokale Bereitstellung daher unerlässlich.
- Anpassungstiefe: Hochgradig individualisierte Modelle mit umfangreichem Feintuning, domänenspezifischem Training und spezialisierten Architekturen rechtfertigen Investitionen in Eigenregie. Ein bemerkenswertes Beispiel ist das DeepSeek R1-Modell, das laut Berichten über Veränderungen in der Rechenlandschaft für das Nachtraining weniger als 1.400.300.000 Ressourcen benötigte.
- Strategische Unabhängigkeit: Organisationen, die KI-basierte Produkte entwickeln, priorisieren möglicherweise die Unabhängigkeit von Anbietern und die Kontrolle darüber gegenüber einer kurzfristigen Kostenoptimierung.
| Entscheidungsfaktor | Bevorzuge Open Source, wenn | Bevorzugt kommerzielle APIs, wenn
|
|---|---|---|
| Tokenvolumen | Über 500 Millionen monatlich | Unter 500 Mio. monatlich |
| Latenzanforderung | Unter 100 ms p95 | 200 ms+ akzeptabel |
| Datensensitivität | Regulierte/klassifizierte Daten | Nicht sensible Arbeitslasten |
| Anpassungsbedarf | Umfangreiche Feinabstimmung | Standardfunktionen |
| Teamkompetenz | Bestehende ML-/Infrastrukturteams | Begrenzte technische Ressourcen |
| Kapitalverfügbarkeit | Kann $500K+ im Voraus investieren | Bevorzugte Betriebskosten |
Versteckte Kosten, die Projekte zum Scheitern bringen
Neben den offensichtlichen Ausgaben gibt es zahlreiche versteckte Kosten, die die Implementierung von Open-Source-Software verhindern.
Modellaktualisierungen und Drift
Modelle verschlechtern sich mit der Zeit. Datenverteilungen verändern sich. Nutzererwartungen entwickeln sich weiter. Kommerzielle APIs verwalten Aktualisierungen automatisch. Selbstgehostete Bereitstellungen erfordern manuelle Eingriffe.
Das erneute Trainieren oder Aktualisieren von Modellen erfordert zusätzliche GPU-Zeit, Entwicklungsaufwand und Testzyklen. Planen Sie jährlich $50.000 bis $200.000 für die laufende Modellpflege ein.
Opportunitätskosten
Die Entwicklungsteams, die die LLM-Infrastruktur aufbauen, entwickeln keine Produktfunktionen. Die Opportunitätskosten, die entstehen, wenn sieben Entwickler sechs Monate lang an der Bereitstellungsinfrastruktur arbeiten, belaufen sich auf $350.000 bis $700.000 an Gehaltskosten zuzüglich des entgangenen Werts der nicht entwickelten Funktionen.
Fehlgeschlagene Experimente
Nicht jede Implementierung ist erfolgreich. Das Testen mehrerer Modelle, Architekturen und Optimierungsstrategien ist ressourcenintensiv. Fehlgeschlagene Machbarkeitsstudien verursachen Kosten in Höhe von jeweils 100.000 bis 25.000 Tsd. 4 Tsd. an Entwicklungszeit und Infrastruktur.
Technische Schulden
Übereilte Implementierungen führen zu technischen Schulden, die sich mit der Zeit immer weiter anhäufen. Schlecht konzipierte Inferenzpipelines, unzureichendes Monitoring und fehleranfällige Integrationen erfordern kostspielige Refaktorierungen. Die Beseitigung technischer Schulden kostet 3- bis 5-mal so viel wie eine von Anfang an korrekte Entwicklung.
Optimierungsstrategien, die tatsächlich funktionieren
Organisationen, die sich für das Selbsthosting entschieden haben, können Strategien zur Kostenreduzierung einsetzen.
Quantisierung und Kompression
Die Modellquantisierung reduziert den Speicherbedarf und erhöht die Inferenzgeschwindigkeit. Studien zeigen, dass die Q4_0-Quantisierung es Modellen ermöglicht, auf handelsüblicher Hardware mehr als 20 Token pro Sekunde zu verarbeiten. Diese Technik senkt die Infrastrukturkosten um 50–751 TP3T bei minimalen Genauigkeitseinbußen für viele Aufgaben.
Frameworks zur Inferenzoptimierung
Spezialisierte Inferenzserver wie vLLM, NVIDIA Triton und Text Generation Inference verbessern den Durchsatz erheblich. Diese Frameworks können die Anzahl der verarbeiteten Token pro Sekunde im Vergleich zu einfachen Implementierungen um das 2- bis 5-Fache steigern.
Die Leistungssteigerungen führen direkt zu Kosteneinsparungen – weniger GPUs für den gleichen Durchsatz.
Hybride Ansätze
Intelligente Unternehmen entscheiden sich nicht für “ausschließlich Open Source” oder “ausschließlich APIs”. Hybridstrategien nutzen kommerzielle APIs für variable Arbeitslasten und Spitzenlasten, während gleichzeitig eine selbstgehostete Infrastruktur für die Grundlast beibehalten wird.
Dieser Ansatz optimiert die Kosten: APIs bewältigen Lastspitzen ohne Überdimensionierung der Infrastruktur, während selbstgehostete Modelle vorhersehbare Arbeitslasten kosteneffektiv verarbeiten.
Kleinere Spezialmodelle
Größere Modelle sind nicht immer besser. Die SmallThinker-Familie beweist, dass kleinere, speziell entwickelte Modelle größere, universelle LLMs bei bestimmten Aufgaben übertreffen können. Ein gut optimiertes 7B-Modell verursacht geringere Betriebskosten als ein 70B-Modell und bietet potenziell eine bessere Leistung in der jeweiligen Aufgabe.

Das Berechnungsmodell für die Gesamtbetriebskosten
Organisationen benötigen einen systematischen Ansatz zur Berechnung der Gesamtbetriebskosten, bevor sie Implementierungsentscheidungen treffen.
- Schritt 1: Schätzen Sie das Tokenvolumen. Berechnen Sie den voraussichtlichen monatlichen Tokenverbrauch anhand der Nutzeranzahl, der Nutzungsmuster und der Funktionsanforderungen. Berücksichtigen Sie dabei sowohl eingehende als auch ausgehende Token.
- Schritt 2: Berechnen Sie die Basiskosten der kommerziellen API. Multiplizieren Sie das Tokenvolumen mit dem Preis der kommerziellen API. Berücksichtigen Sie unterschiedliche Modellstufen, falls mehrere Modellgrößen verwendet werden.
- Schritt 3: Anforderungen an die Infrastruktur. Bestimmen Sie die Anzahl und Spezifikationen der GPUs anhand der Modellgröße, der Latenzanforderungen und des Redundanzbedarfs. Berücksichtigen Sie dabei Netzwerk, Speicher und Rechenleistung.
- Schritt 4: Schätzen Sie den Entwicklungsaufwand. Ermitteln Sie die benötigten Vollzeitäquivalente (FTEs) für ML-Entwicklung, MLOps, Integration, Infrastruktur und Sicherheit. Berücksichtigen Sie sowohl die Erstentwicklung als auch die laufende Wartung.
- Schritt 5: Berücksichtigen Sie den operativen Aufwand. Dazu gehören Kosten für Überwachung, Sicherheit, Compliance, Datenspeicherung, Bandbreite und Reaktion auf Sicherheitsvorfälle.
- Schritt 6: Berücksichtigen Sie versteckte Kosten. Beziehen Sie Opportunitätskosten, gescheiterte Experimente, technische Schulden und Modellwartungszyklen mit ein.
- Schritt 7: Ermitteln Sie den Break-Even-Punkt. Bestimmen Sie das Token-Volumen, bei dem die Gesamtkosten für das Selbsthosting den Kosten für eine kommerzielle API entsprechen. Die meisten Unternehmen ermitteln diese Schwelle bei 500 Millionen bis 1 Milliarde Token pro Monat.

Senken Sie die Kosten für die Einführung von Open-Source-LLM-Lösungen, bevor sie skalieren.
Open-Source-LLMs wirken auf den ersten Blick kostengünstig, doch die Bereitstellungskosten steigen oft schnell an, sobald Infrastruktur, Überwachung, Skalierung und Integration hinzukommen. AI Superior arbeitet an der technischen Seite von LLM-Systemen – entwirft Modellarchitekturen, richtet die Infrastruktur ein und integriert Modelle in bestehende Umgebungen, damit sie im Produktivbetrieb effizient laufen.
Wenn Sie 2026 Open-Source-LLMs einsetzen, ist es hilfreich, die Architektur und die Bereitstellungspipeline frühzeitig zu überprüfen. Kontaktieren Sie uns. AI Superior um Ihre Bereitstellungskonfiguration zu bewerten und festzustellen, wo Infrastruktur- und Inferenzkosten reduziert werden können.
Die Realität von 2026
Die Kosten für die Implementierung von Open-Source-LLM sinken, jedoch nicht so dramatisch, wie sich die Leistungsfähigkeit der Modelle verbessert.
Die GPU-Preise bleiben aufgrund der anhaltenden Nachfrage hartnäckig hoch. Die Gehälter von KI-Spezialisten steigen weiter – insbesondere ML-Ingenieure mit LLM-Abschluss sind sehr gefragt und erzielen attraktive Gehaltszuwächse.
Gleichzeitig sinken die Preise für kommerzielle APIs. Laut einer Analyse von Hugging Face zu den Trends im Rechenzentrumsmarkt sind die Preise für kommerzielle APIs gegenüber den Prognosen von 2024 deutlich gefallen. Claude und Gemini weisen ähnliche Entwicklungen auf. Die Wirtschaftlichkeit spricht zunehmend für APIs in den meisten Anwendungsfällen.
Sehen Sie, Open Source wird in bestimmten Nischen dominieren: regulierte Branchen, latenzkritische Anwendungen, Organisationen, die monatlich Milliarden von Token verarbeiten, und Unternehmen, die differenzierte KI-basierte Produkte entwickeln. Für alle anderen? Da sind APIs finanziell sinnvoller.
Das “kostenlose” Open-Source-Modell kostet mindestens 125.000 Tsd. 400 und wahrscheinlich mehr als 500.000 Tsd. 400 für alles, was auch nur annähernd produktionsreif ist. Das ist keine Kritik an Open Source – es ist einfach Mathematik.
Häufig gestellte Fragen
Wie hoch ist das realistische Mindestbudget für die Einführung eines Open-Source-LLM-Systems?
Für den minimalen Einsatz interner Tools werden jährlich 125.000 bis 190.000 TP4T benötigt. Diese Summe deckt die grundlegende GPU-Infrastruktur, einen Teil der Entwicklungsressourcen, Überwachung und den laufenden Betrieb ab. Beträge unterhalb dieser Schwelle deuten auf ein unterfinanziertes Projekt mit hoher Wahrscheinlichkeit zum Scheitern hin.
Ab welcher Anzahl an Tokens pro Monat ist Self-Hosting kosteneffektiv?
Studien deuten darauf hin, dass 500 Millionen bis 1 Milliarde Token pro Monat die Gewinnschwelle darstellen, ab der die Kosten für das Selbsthosting nahezu mit denen kommerzieller APIs gleichziehen. Bei weniger als 500 Millionen Token pro Monat sind APIs fast immer günstiger, sofern Entwicklungs- und Betriebskosten angemessen berücksichtigt werden.
Können kleinere Modelle die Bereitstellungskosten deutlich senken?
Ja. Ein gut optimiertes 7B-Parametermodell ist im Betrieb kostengünstiger (85-90%) als ein 70B-Modell. In Kombination mit aufgabenspezifischer Feinabstimmung erreichen kleinere Modelle oft die gleiche oder sogar eine höhere Leistung als größere Modelle für bestimmte Anwendungen, wodurch der Infrastrukturaufwand erheblich reduziert wird.
Was sind die größten versteckten Kosten bei der Implementierung von Open-Source-LLM-Lösungen?
Die Kosten für technisches Fachpersonal machen typischerweise einen erheblichen Teil der gesamten Implementierungskosten aus – den größten versteckten Kostenfaktor bei den meisten Unternehmensimplementierungen. ML-Ingenieure, MLOps-Spezialisten und Integrationsentwickler verdienen jährlich zwischen 140.000 und 250.000 Euro. Für eine mittelgroße Implementierung werden 7 bis 10 Spezialisten benötigt, was allein an jährlichen Personalkosten 1 bis 2 Millionen Euro verursacht.
Sparen Quantisierungstechniken tatsächlich Geld, ohne die Qualität zu beeinträchtigen?
Quantisierungstechniken wie Q4_0 können die Infrastrukturkosten um 50–751 TP3T senken, bei minimalem Genauigkeitsverlust für viele Aufgaben. Studien zeigen, dass quantisierte Modelle auf handelsüblicher Hardware über 20 Token pro Sekunde erreichen. Die Auswirkungen auf die Genauigkeit variieren jedoch je nach Aufgabe – gründliche Tests sind daher vor dem Produktiveinsatz unerlässlich.
Sollten Startups Open-Source-LLMs oder kommerzielle APIs verwenden?
Die meisten Startups sollten mit kommerziellen APIs beginnen. Die Flexibilität, die planbaren Kosten und der fehlende operative Aufwand ermöglichen schnellere Iterationen und eine raschere Produktentwicklung. Selbsthosting ist nur dann sinnvoll, wenn es um massive Skalierung, die Verarbeitung regulierter Daten oder den Aufbau hochdifferenzierter KI-Funktionen geht, die für den Wettbewerbsvorteil entscheidend sind.
Wie viel kostet die Feinabstimmung eines Open-Source-Modells?
Die Kosten für die Feinabstimmung variieren stark je nach Modellgröße und Datensatz. Die minimale Feinabstimmung eines 7-B-Modells kostet 1.400.500 bis 1.400.000 INR, inklusive GPU-Zeit und Entwicklungsaufwand. Die umfassende Feinabstimmung von 70-B-Modellen mit großen Datensätzen kann 1.400.000 bis 300.000 INR übersteigen. Bemerkenswerte Beispiele erzielten beeindruckende Ergebnisse mit reduziertem Investitionsaufwand – kleinere Modelle zeigten vergleichbare Leistung zu einem Bruchteil der Kosten.
Fazit: Rechnen Sie nach, bevor Sie sich festlegen.
Die Implementierung von Open-Source-LLM ist nicht kostenlos. Es handelt sich um eine erhebliche Investition in Entwicklung und Infrastruktur, die sich nur in bestimmten Größenordnungen und für bestimmte Anwendungsfälle finanziell lohnt.
Kommerzielle APIs sind für die meisten Anwendungen, die monatlich weniger als 500 Millionen Token verarbeiten, die wirtschaftlich sinnvolle Wahl. Sie sind definitiv kostengünstiger für interne Tools, Mitarbeiteranwendungen und kundenorientierte Funktionen mittleren Umfangs.
Self-Hosting rechtfertigt die Investition bei der Verarbeitung massiver Token-Volumina (über 1 Milliarde pro Monat), der Handhabung regulierter oder sensibler Daten, die eine Bereitstellung vor Ort erfordern, der Erfüllung extremer Latenzanforderungen oder dem Aufbau hochgradig individualisierter Modelle, die für die Produktdifferenzierung von zentraler Bedeutung sind.
Berechnen Sie Ihre Gesamtbetriebskosten ehrlich. Berücksichtigen Sie Infrastruktur, Entwicklungsaufwand, Betriebskosten, versteckte Kosten und Opportunitätskosten. Vergleichen Sie diese Summe mit den Preisen kommerzieller APIs für eine vergleichbare Nutzung. Die Zahlen täuschen selten.
Und falls die Zahlen für Ihr konkretes Szenario weiterhin für Self-Hosting sprechen? Planen Sie das Doppelte Ihrer ursprünglichen Schätzung ein. Produktionsbereitstellungen kosten immer mehr als geplant.
Sie möchten Ihre LLM-Implementierungskosten präzise berechnen? Beginnen Sie mit Prognosen zum Tokenvolumen und ermitteln Sie anschließend den Infrastruktur- und Personalbedarf. Die Break-Even-Analyse zeigt Ihnen, ob Open-Source- oder kommerzielle APIs für die spezifischen Bedürfnisse Ihres Unternehmens wirtschaftlich sinnvoll sind.