Ich verstehe das. OpenClaw ist überall in aller Munde und die Idee eines KI-Assistenten, der rund um die Uhr verfügbar ist und tatsächlich Aufgaben auf Ihrem Computer erledigen kann, fasziniert Sie. Doch dann lesen Sie, wie Leute Hunderte von Dollar für API-Guthaben ausgeben, und plötzlich schlägt die Begeisterung in Kostenangst um.
Aber das Besondere ist: OpenClaw ist unter der MIT-Lizenz veröffentlicht und vollständig Open Source. Laut dem offiziellen GitHub-Repository openclaw/openclaw mit über 100.000 Sternen läuft dieser KI-Assistent auf “jedem Betriebssystem und jeder Plattform”. Und ja, das schließt auch die Nutzung ohne jegliche Kosten ein.
Die eigentliche Frage ist nicht, ob man OpenClaw kostenlos nutzen kann. Vielmehr geht es darum, wie man es einrichtet, um die horrenden API-Gebühren zu vermeiden, über die sich alle in den Community-Diskussionen beschweren.
Das Kostenproblem verstehen
Bevor wir uns mit Lösungen befassen, sprechen wir darüber, warum Menschen überhaupt Geld dafür ausgeben. OpenClaw ist im Grunde ein KI-Agent, der sich mit Messaging-Plattformen wie Slack, WhatsApp oder Telegram verbindet und Aufgaben in Ihrem Namen ausführt. Der Haken dabei: Er benötigt ein Sprachmodell, um seine Funktionsweise zu steuern.
Die meisten Tutorials verweisen auf Claude, GPT-4 oder andere kommerzielle APIs. Und die sind nicht gerade günstig. Ein Nutzer fragte in einer GitHub-Diskussion vom Februar 2026 nach dem “derzeit besten bezahlbaren LLM” und verdeutlichte damit, dass dies ein großes Problem für die OpenClaw-Community darstellt.
Es gibt jedoch drei legitime Wege zu einem Betrieb ohne Kosten:
- Ausführen vollständig lokaler Modelle auf Ihrer eigenen Hardware
- Nutzung kostenloser Cloud-GPU-Ressourcen
- Strategische Nutzung kostenloser API-Stufen
Lassen Sie uns die einzelnen Ansätze genauer betrachten.
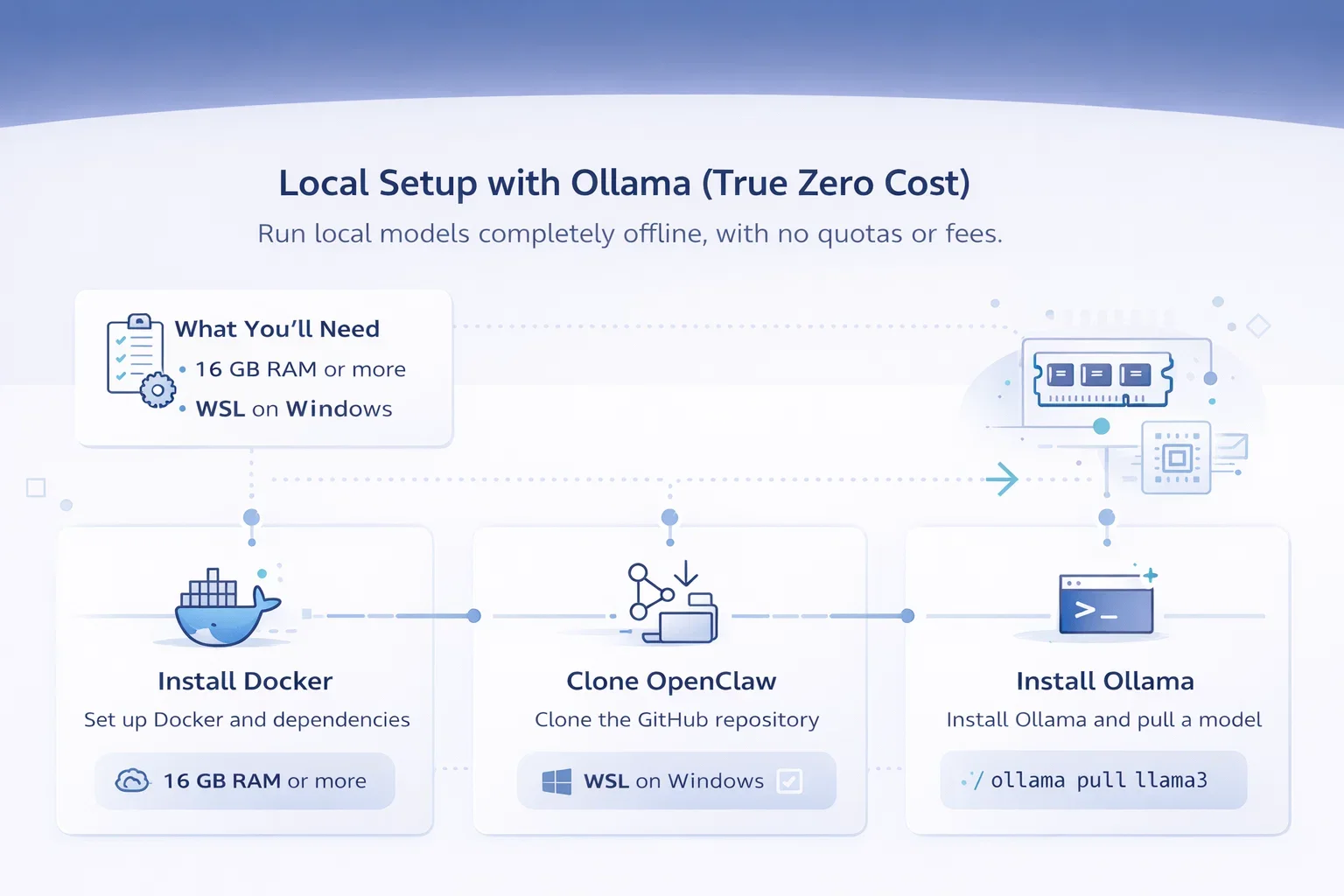
Methode 1: Lokale Einrichtung mit Ollama (Echte Nullkosten)
Das ist mein persönlicher Favorit, denn sobald es konfiguriert ist, ist man völlig unabhängig. Keine Kontingente, keine Ratenbegrenzungen, keine unerwarteten Kosten. Laut dem Digitalknk-Leitfaden “OpenClaw ohne Geld-, Kontingent- oder Nervenverlust betreiben”, der auf GitHub 92 Sterne erhalten hat, sind lokale Modelle die nachhaltigste Langzeitlösung.
Was Sie benötigen
Mal ehrlich: Man braucht keinen Gaming-PC mit mehreren Grafikkarten. Ein ordentlicher Computer mit 16 GB RAM kommt mit kleineren Modellen problemlos zurecht. Ein Nutzer auf Reddit berichtete, OpenClaw erfolgreich auf einem Intel NUC mit 16 GB RAM installiert zu haben, hatte aber anfänglich einige Konfigurationsprobleme.
Windows-Nutzer benötigen WSL (Windows-Subsystem für Linux). Mac- und Linux-Nutzer können diesen Schritt überspringen.
Schritt-für-Schritt-Installation
Docker und Abhängigkeiten installieren
OpenClaw läuft in Docker-Containern, um plattformübergreifende Konsistenz zu gewährleisten. Windows-Nutzer installieren Docker Desktop und aktivieren die WSL2-Integration. Mit der Flutter-basierten App von Mithun_Gowda_B können Sie das OpenClaw AI Gateway direkt auf Ihrem Smartphone ausführen – ohne Root-Zugriff und mit nur einem Fingertipp.
OpenClaw klonen
Besuche das offizielle GitHub-Repository openclaw/openclaw und klone es auf deinen lokalen Rechner. Die Installation ist eigentlich unkompliziert, aber wie ein Reddit-Nutzer anmerkte: “So einfach ist es dann doch nicht, haha. Bei der Installation auf einem VPS liegt das Problem bei localhost, und du musst die IP-Adresse binden.”
Beachten Sie dies, wenn Sie einen Fernzugriff planen.
Ollama installieren
Ollama ist Ihr lokaler Modellbauer. Laden Sie ihn von ollama.ai herunter und installieren Sie ihn entsprechend Ihrem Betriebssystem. Wählen Sie dann ein Modell aus, das zu Ihrer Hardware passt:
- Für 8 GB RAM: Versuchen Sie llama3.2 oder mistral.
- Bei 16 GB RAM: Das Llama3 8B funktioniert hervorragend.
- Für 32 GB+ RAM: Sie können llama3 70B oder mixtral ausführen.
Der Befehl sieht folgendermaßen aus: ollama pull llama3
OpenClaw-Verbindung konfigurieren
Sie müssen OpenClaw nun auf Ihre lokale Ollama-Instanz anstatt auf eine Cloud-API verweisen. Bearbeiten Sie dazu Ihre OpenClaw-Konfigurationsdatei und verwenden Sie den lokalen Endpunkt (typischerweise http://localhost:11434 für Ollama).
Hier scheitern die meisten Anfänger. Wie in einer GitHub-Diskussion erwähnt, ist die korrekte Bindung an localhost wichtig, wenn man das Ganze auf einem VPS ausführt oder Fernzugriff benötigt.
Leistungserwartungen
Lokale Modelle erreichen zwar nicht die Logik von GPT-4 oder die Programmierfähigkeiten von Claude, sind aber für alltägliche Aufgaben erstaunlich leistungsfähig. Und das ist der entscheidende Punkt: Sie können sie rund um die Uhr ausführen, ohne sich Gedanken über Token-Zähler oder Ratenbegrenzungen machen zu müssen.
Ein Mitglied der Community teilte mit: “Ich betreibe ein System, das mich buchstäblich $0/Monat kostet, rund um die Uhr läuft und praktisch unbegrenzt Tokens hat.”
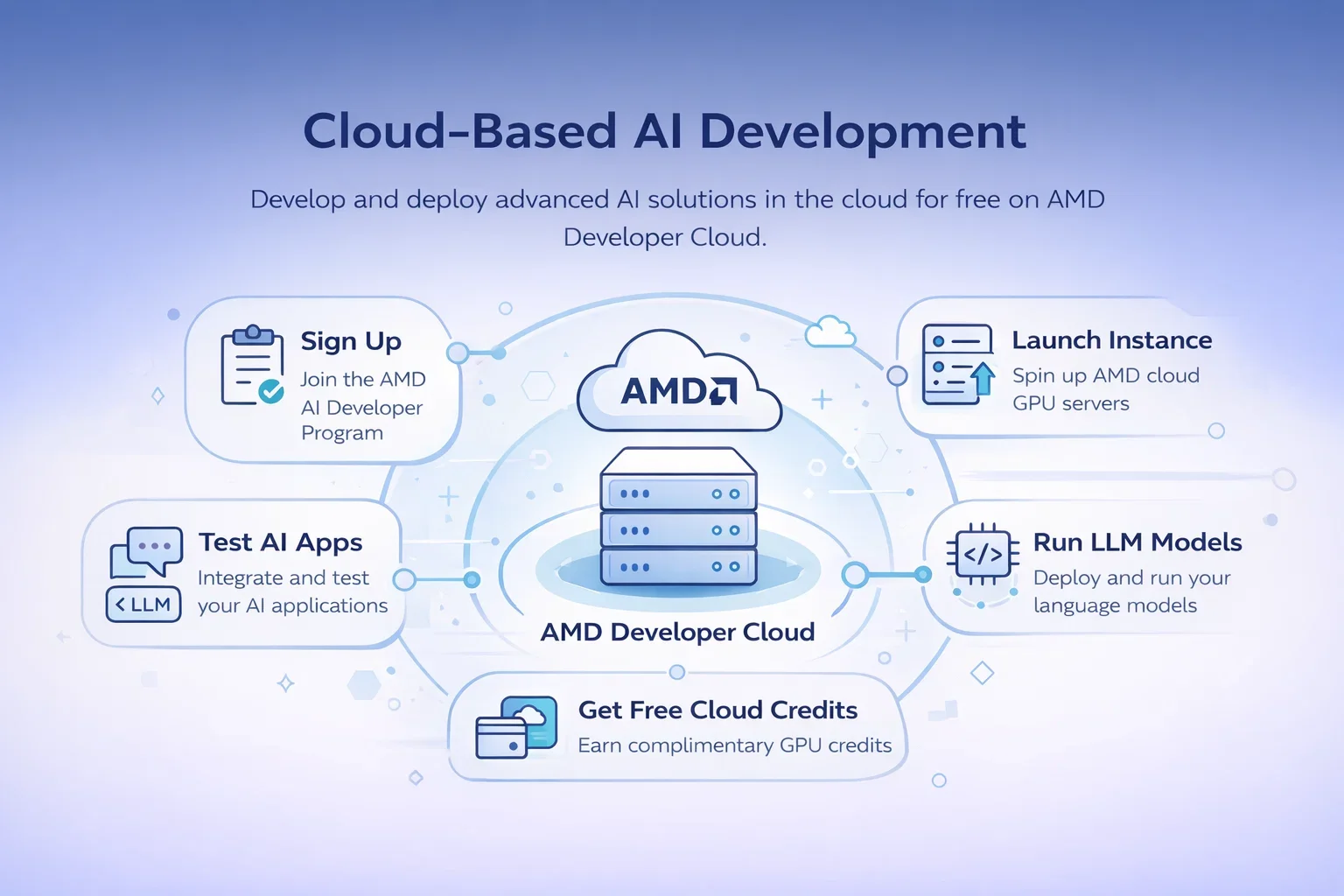
Methode 2: AMD Developer Cloud (Beste kostenlose Cloud-Option)
Hier wird es interessant. Laut mehreren GitHub-Anleitungen zu “OpenClaw mit vLLM kostenlos in der AMD Developer Cloud” kann man über das AMD AI Developer Program kostenlos auf Hardware der Enterprise-Klasse zugreifen.
Wir sprechen hier von AMD Instinct MI300X GPUs mit 192 GB Speicher. Das reicht aus, um Modelle zu betreiben, für die man normalerweise Tausende von Dollar an Consumer-GPUs bräuchte.
Zugriff auf die AMD Developer Cloud erhalten
Melden Sie sich für das AMD AI Developer Program an. Dort erhalten Entwickler, die KI-Workloads testen, kostenlose Cloud-Guthaben. Ein Leitfaden vom Februar 2026 zeigt, wie man OpenClaw kostenlos auf dieser Infrastruktur bereitstellt.“
Aber Moment mal – es gibt einen Haken. Es handelt sich hierbei um Aktionsguthaben, nicht um eine dauerhafte Gratisversion. Wenn Sie OpenClaw jedoch nur testen oder für private Projekte nutzen, sollte das Guthaben eine ganze Weile reichen.
vLLM wird auf AMD Cloud ausgeführt
vLLM ist ein optimierter Inferenzserver, mit dem Sie große Sprachmodelle effizient ausführen können. Der Einrichtungsprozess umfasst Folgendes:
- Starten Sie eine AMD-Cloud-Instanz
- Installieren Sie vLLM und Ihr ausgewähltes Modell.
- Konfigurieren Sie OpenClaw so, dass es auf Ihren vLLM-Endpunkt verweist.
- Verbinden Sie Ihre Messaging-Plattformen
Laut dem secure-openclaw-Repository von ComposioHQ (1,5k Sterne) lässt sich OpenClaw mit WhatsApp, Telegram, Signal oder iMessage integrieren, um ein umfassendes persönliches Assistentenerlebnis zu erhalten.
Methode 3: GitHub Codespaces-Strategie
GitHub bietet über Codespaces kostenlose Rechenstunden an – 60 Stunden pro Monat im kostenlosen Kontingent. Eine kreative Einrichtungsanleitung erwähnte die “Bereitstellung von OpenClaw in unter 5 Minuten im kostenlosen AWS-Kontingent”, aber GitHub Codespaces bietet eine einfachere Alternative.
60 Stunden sind natürlich keine 24/7-Verfügbarkeit. Wenn Sie Ihren KI-Assistenten aber hauptsächlich während der Arbeitszeit nutzen, reicht das erstaunlich lange. Schalten Sie ihn einfach ab, wenn Sie schlafen oder am Wochenende, und Sie haben eine solide kostenlose Lösung.
Der hybride Ansatz
So machen es einige erfahrene Benutzer: Leichte Aufgaben werden lokal mit Ollama ausgeführt, aber für komplexe Codierungs- oder logische Schlussfolgerungsaufgaben wird OpenClaw über eine kostenlose API aufgerufen.
OpenRouter, das in Reddit-Diskussionen erwähnt wurde, bietet kostenloses Guthaben, das monatlich zurückgesetzt wird. Ein Nutzer merkte an: “OpenRouter kostet über 10 € für 1000 Anfragen pro Tag mit den kostenlosen Vorlagen.” Diese 10 € sind Guthaben, keine Gebühren – nutzen Sie es klug, und es fallen keine Kosten an.
Sicherheitsaspekte, die Sie nicht ignorieren dürfen
Mal ehrlich: OpenClaw hat vollen Computerzugriff. Das ist zwar leistungsstark, aber bei Fehlkonfiguration auch potenziell gefährlich.
Ein vielbeachteter Reddit-Thread befasste sich speziell mit dem Thema “Sicherheitshärtungsleitfaden” und warnte: “Da ich sehe, dass so viele neue Leute Clawdbot installieren, empfehle ich dringend, es gegen Prompt-Injection-Angriffe zu immunisieren.”
Es gibt Erkennungsskripte (wie knostic/openclaw-detect mit 56 Sternen), die speziell für die “MDM-Bereitstellung zur Identifizierung von OpenClaw-Installationen auf verwalteten Geräten” entwickelt wurden. Das zeigt, dass Unternehmen sich Sorgen um die Sicherheitsrisiken machen.
Wesentliche Sicherheitsmaßnahmen
| Sicherheitsmaßnahme | Warum es wichtig ist | Wie man es umsetzt |
| Schlüsselmanagement | OpenClaw benötigt API-Schlüssel und Zugangsdaten. | Verwenden Sie 1Password oder einen ähnlichen Anbieter mit einem dedizierten Tresor. |
| Netzwerkbindung | Verhindert externen Zugriff auf Ihre Instanz | Bindet nur an localhost, es sei denn, VPN ist konfiguriert. |
| Firewall-Regeln | Beschränkt den Zugriff von OpenClaw | Verwenden Sie ufw oder Tailscale für sicheren Fernzugriff. |
| Sofortiger Injektionsschutz | Verhindert schädliche Befehle von externen Quellen | Eingabevalidierung und Befehlsbeschränkungen konfigurieren |
Ein sicherheitsbewusster Nutzer teilte mit: “Ich verwende 1Password für meine Schlüsselverwaltung. Der einzige Schlüssel, den OpenClaw besitzt, ist derjenige, mit dem man über einen dedizierten Tresor und ein Dienstkonto auf 1Password zugreifen kann.”
Das ist intelligente Architektur.
Häufige Einrichtungsprobleme und Lösungen
Basierend auf Diskussionen in der Community und der großartigen OpenClaw-Ressourcensammlung (221 Sterne auf GitHub) sind hier die Probleme, die Neulinge häufig plagen:
“Es wurde installiert, führt aber nichts aus.”
Ein frustrierter Reddit-Nutzer schrieb: “Ich habe Clawdbot fünfmal auf meinem 16-GB-Intel-NUC mit Ubuntu installiert, aber es hat kein einziges Mal funktioniert. Ich kann zwar mit ihm sprechen, aber er kann nichts kompilieren.”
Dies deutet in der Regel auf Berechtigungsprobleme oder eine fehlerhafte Modellverbindung hin. Überprüfen Sie Ihre Konfigurationsdatei und stellen Sie sicher, dass OpenClaw Ihren LLM-Endpunkt erreichen kann.
Verwirrung um den Speicherort der WSL-Datei
Windows-Nutzer finden ihre OpenClaw-Dateien oft nicht. Ein hilfreicher Kommentator merkte dazu an: “Die Dateien für devices/pending.json befinden sich unter \\wsl$\Ubuntu\home\user\.openclaw\devices – bei mir liegen sie im Linux-Subsystem.”
Die Verwirrung um das “kostenlose” Thema
Viele “kostenlose” Anleitungen setzen dennoch kostenpflichtige Dienste voraus. Ein skeptischer Nutzer fragte dazu: “Also … ein Bot, der $0 kostet … vorausgesetzt, man hat Abonnements für Google AI Pro und GitHub Copilot? Wie kann das $0 sein?”
Ein berechtigter Einwand. Wirklich kostenlos bedeutet, dass keinerlei Abonnements anfallen – nur lokale Modelle oder tatsächlich kostenlose Cloud-Guthaben.
Plattformvergleich: Was funktioniert wirklich?
| Plattform | Echter Gratis-Tarif | Monatliche Verfügbarkeit | Leistung | Am besten geeignet für |
| Lokaler Ollama | Ja (nur Hardwarekosten) | 24/7 | Gut geeignet für alltägliche Aufgaben | Datenschutzbewusste Nutzer |
| AMD Developer Cloud | Gutschriften (zeitlich begrenzt) | Rund um die Uhr verfügbar, solange der Vorrat reicht | Hervorragend geeignet für große Modelle | Testen und Entwickeln |
| GitHub Codespaces | 60 Stunden/Monat | Teilzeit | Hängt von der Modellwahl ab | Nutzung der Arbeitszeit |
| OpenRouter Gratisversion | Monatliche Gutschriften werden zurückgesetzt | Bis die Guthaben aufgebraucht sind | Variiert je nach Modell | Hybride Ansätze |
Anwendungsfälle aus der Praxis, die nicht das Budget sprengen
Laut Diskussionen im OpenClaw-Blog-Repository nutzen Leute kostenlose OpenClaw-Setups für Folgendes:
- Automatisierte Code-Reviews: Lassen Sie Ihre Commits vor dem Push prüfen.
- Nachrichtenzusammenfassung: Slack-Kanäle oder E-Mail-Threads zusammenfassen
- Geplante Erinnerungen: Die sichere Openclaw-Gabel erwähnt diese Funktion ausdrücklich.
- Unterstützung bei der Recherche: Informationen sammeln und Zusammenfassungen erstellen
- Aufgabenautomatisierung: Dateiorganisation, Datenverarbeitung, Berichtserstellung
Entscheidend ist die Auswahl von Aufgaben, die zu den Fähigkeiten Ihres Modells passen. Erwarten Sie nicht, dass ein lokales 7B-Modell produktionsreifen Code schreibt, aber es kann definitiv bei der Generierung von Boilerplate-Code oder Dokumentation hilfreich sein.
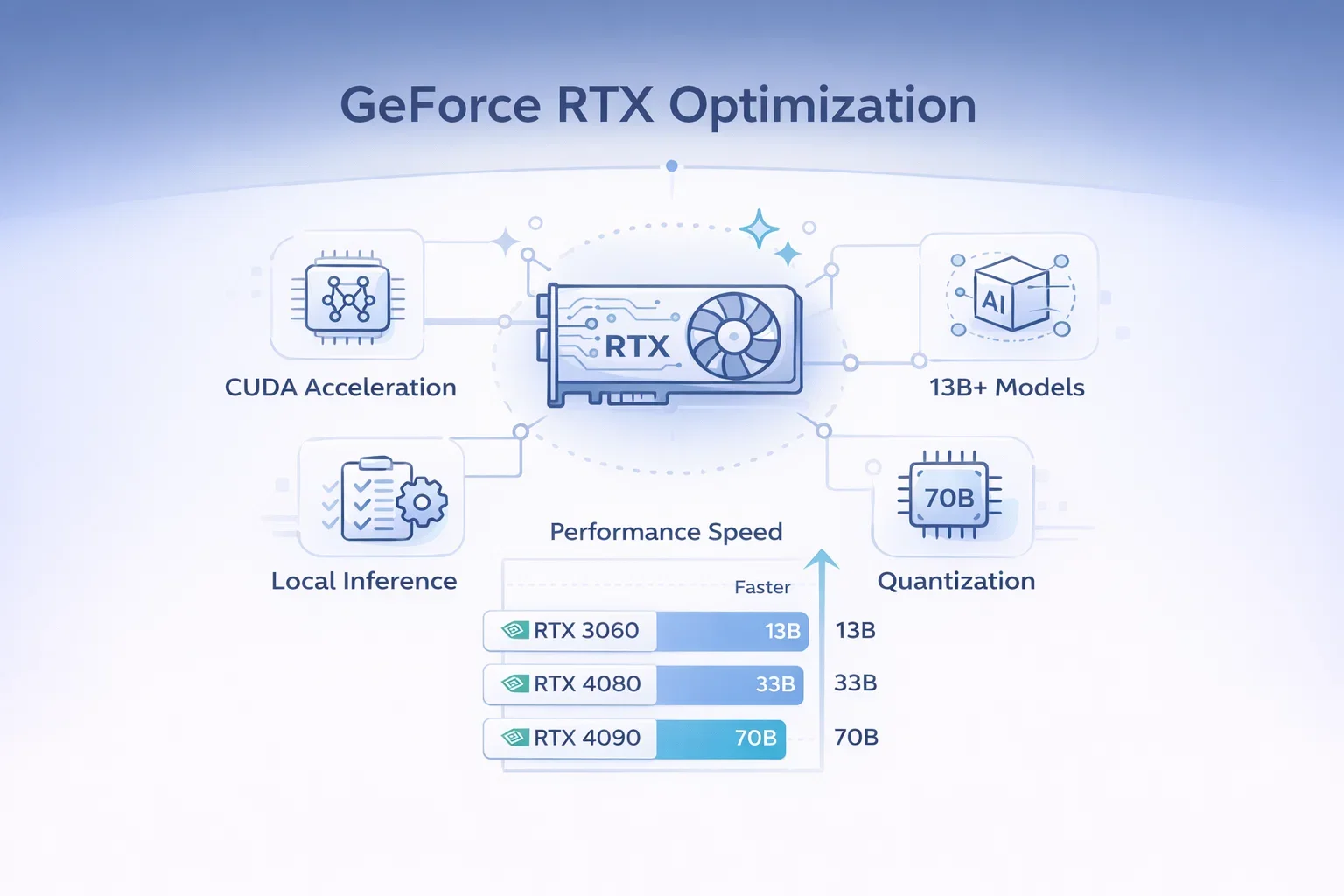
GeForce RTX-Optimierung
Eine beliebte Anleitung beschreibt, wie man OpenClaw kostenlos auf einer GeForce RTX mit lokaler Inferenzoptimierung ausführt. Besitzer einer NVIDIA-GPU können die CUDA-Beschleunigung für deutlich schnellere lokale Inferenz nutzen.
Für eine komfortable Performance mit 13B-Modellen wird eine RTX 3060 oder höher empfohlen. Eine RTX 4090 kann 70B-Modelle mit Quantisierung verarbeiten.
[ABBILDUNG: Leistungsvergleichsdiagramm, das die Inferenzgeschwindigkeiten verschiedener GPUs zeigt]
Alternative Projekte, die eine Überlegung wert sind
Das OpenClaw-Ökosystem hat mehrere Alternativen hervorgebracht. Laut dem Dokument “moltbot-vs-openclaw-complete-comparison” handelt es sich bei Moltbot im Wesentlichen um einen umbenannten Fork mit anderem Branding. ClawdBot war der ursprüngliche Name vor dem Rebranding zu OpenClaw.
ComposioHQs secure-openclaw (258 Forks, 1,5k Sterne) konzentriert sich speziell auf die Integration von Messaging-Plattformen mit “persistentem Speicher, geplanten Erinnerungen und Integrationen mit über 500 Apps”.”
Für Setups mit extrem niedrigem Budget hat ein Reddit-Thread mit dem Titel “OpenClaw / ClawdBot / MoltBot mit kleinem Budget (oder kostenlos) ausführen” verschiedene kostengünstige Ansätze zusammengestellt, die sich für Community-Mitglieder bewährt haben.
Schlussbetrachtung: Lohnt sich ein Nullkostenmodell wirklich?
Hier ist meine ehrliche Meinung nach der Durchsicht dutzender Einrichtungsanleitungen und Community-Diskussionen: Ja, man kann OpenClaw im Jahr 2026 definitiv kostenlos nutzen. Es gibt jedoch einen Kompromiss zwischen Kosten und Komfort.
Lokale Modelle mit Ollama bieten Ihnen echte Unabhängigkeit und keine monatlichen Kosten, allerdings müssen Sie im Vergleich zu Frontier-Modellen Abstriche bei der Leistung machen. AMD Developer Cloud-Guthaben bieten eine hervorragende Leistung, solange sie verfügbar sind, stellen aber keine dauerhafte Lösung dar. Kostenlose API-Tarife funktionieren, bis Sie Ihr Kontingent überschreiten.
Der optimale Ansatz? Beginnen Sie mit Ollama lokal für Routineaufgaben und nutzen Sie anschließend gezielt kostenlose Cloud-Ressourcen für anspruchsvolle Workloads. Ein erfahrener Nutzer merkte in einem ausführlichen Reddit-Leitfaden an: “Der Schlüssel liegt darin, die kostenlosen Kontingente optimal zu nutzen und diese dann effizient zu verwalten.”
Und sehen Sie – selbst wenn Sie sich später für den API-Zugriff entscheiden, bedeutet das Verständnis dieser kostenlosen Methoden, dass Sie die kostenpflichtigen Ressourcen effizienter nutzen werden. Sie wissen genau, wann Sie Cloud-Leistung benötigen und wann eine lokale Lösung ausreicht.
Das OpenClaw-Repository (openclaw/openclaw) wird mit seiner Community, die über 200.000 Sterne zählt, aktiv weiterentwickelt. Regelmäßig erscheinen neue Optimierungsanleitungen, Sicherheitsverbesserungen und Installationstools. Bis Sie dies lesen, könnte die Einrichtung sogar noch einfacher sein.
Bereit, Ihren eigenen KI-Assistenten rund um die Uhr ohne monatliche Gebühren zu entwickeln? Beginnen Sie mit der lokalen Ollama-Einrichtung, experimentieren Sie mit den Möglichkeiten Ihrer Hardware und nutzen Sie die Ressourcen der awesome-openclaw-Community, um von anderen zu lernen, die dasselbe tun.
Ihr persönlicher KI-Agent wartet auf Sie – und das völlig kostenlos.
Häufig gestellte Fragen
Ist OpenClaw wirklich komplett kostenlos?
Ja, die Software selbst ist unter der MIT-Lizenz lizenziert und kostenlos. Zum Ausführen benötigen Sie jedoch entweder eigene Hardware (lokale Installation) oder Cloud-Ressourcen. Um monatliche Kosten zu vermeiden, können Sie kostenlose Alternativen wie Ollama (lokal), AMD Developer Cloud-Guthaben oder den kostenlosen Tarif von GitHub Codespaces nutzen.
Kann ich OpenClaw auf einem Raspberry Pi ausführen?
Technisch gesehen ja, wie in den Community-Anleitungen zu “OpenClaw auf Raspberry Pi: Aufbau eines lokalen KI-Automatisierungssystems mit LM Studio” beschrieben. Die Leistung ist jedoch begrenzt. Ein Raspberry Pi 4 mit 8 GB RAM kann zwar sehr kleine Modelle ausführen, aber mit langsamen Reaktionszeiten ist zu rechnen. Es handelt sich eher um ein Hobbyprojekt als um eine praktische Lösung.
Welche Hardware-Mindestanforderungen gelten für die lokale Einrichtung?
Für grundlegende Funktionen reichen 8 GB RAM und eine moderne CPU aus. Für komfortables Arbeiten sind mindestens 16 GB RAM erforderlich. Mit einer Grafikkarte mit mindestens 8 GB VRAM erzielen Sie eine deutlich bessere Leistung. Viele Nutzer verwenden OpenClaw erfolgreich auf Intel NUCs oder Mac Minis.
Wie kann ich Sicherheitsrisiken vermeiden?
Laut Sicherheitsdiskussionen in der OpenClaw-Community sind folgende Maßnahmen wichtig: die Verwendung dedizierter Anmeldeinformationsspeicher (wie 1Password), die Bindung an localhost (außer bei Verwendung eines VPNs), die Implementierung von Firewall-Regeln und die Absicherung gegen Prompt-Injection-Angriffe. Gewähren Sie OpenClaw niemals direkten Zugriff auf sensible Anmeldeinformationen.
Warum erwähnen manche Anleitungen kostenpflichtige Dienste, wenn OpenClaw kostenlos ist?
OpenClaw selbst ist kostenlos, benötigt aber ein Sprachmodell, um zu funktionieren. Viele Tutorials verwenden standardmäßig kommerzielle APIs wie Claude oder GPT-4, da diese einfacher zu konfigurieren sind. Sie können aber durchaus auch kostenlose lokale Modelle oder kostenlose Cloud-Ressourcen nutzen – dies erfordert lediglich etwas mehr Aufwand bei der Einrichtung.
Worin besteht der Unterschied zwischen ClawdBot, Moltbot und OpenClaw?
Es handelt sich im Wesentlichen um dasselbe Projekt mit unterschiedlichen Namen. Ursprünglich hieß es ClawdBot, dann Moltbot und jetzt OpenClaw. Die Kernfunktionalität bleibt gleich: Es ist ein KI-Agent mit vollem Computerzugriff, der auf Ihrer eigenen Infrastruktur läuft.
Kann ich OpenClaw kostenlos für kommerzielle Zwecke nutzen?
Die MIT-Lizenz erlaubt die kommerzielle Nutzung der OpenClaw-Software selbst. Prüfen Sie jedoch die Lizenz des von Ihnen verwendeten Sprachmodells. Die meisten Open-Source-Modelle erlauben die kommerzielle Nutzung, einige (wie Llama) unterliegen jedoch Beschränkungen, die auf der Anzahl der Nutzer basieren. Überprüfen Sie daher immer die Lizenz des jeweiligen Modells.