Resumen rápido: El análisis exploratorio de datos (AED) es el proceso de investigar conjuntos de datos mediante visualización y métodos estadísticos para descubrir patrones, detectar anomalías y probar supuestos antes de la modelización formal. Implica examinar las distribuciones de datos, las relaciones entre variables e identificar valores atípicos para comprender la estructura y la calidad de los datos. El AED constituye un primer paso crucial en cualquier proyecto de ciencia de datos, ya que permite a los equipos tomar decisiones informadas sobre qué técnicas analíticas aplicar.
Los datos no revelan sus secretos de inmediato. Los conjuntos de datos sin procesar suelen ocultar patrones, valores atípicos y relaciones bajo capas de números y texto. Ahí es donde entra en juego el Análisis Exploratorio de Datos: un enfoque sistemático para comprender el contenido real de los datos antes de comenzar con la modelización o las predicciones.
Según Statistics Online de la Universidad Estatal de Pensilvania, el análisis exploratorio de datos (AED) puede describirse como la generación de hipótesis basada en datos. En lugar de partir de suposiciones, los analistas permiten que los datos guíen su comprensión mediante un examen minucioso de las estructuras que podrían indicar relaciones más profundas entre casos o variables.
Esta guía completa abarca desde la inspección básica de conjuntos de datos hasta técnicas multivariantes avanzadas. Ya sea que se trate de trabajar con datos reales complejos o de prepararse para proyectos de aprendizaje automático, dominar las técnicas de análisis exploratorio de datos (EDA) garantiza que el trabajo analítico comience con bases sólidas.
¿Qué es el análisis exploratorio de datos?
El análisis exploratorio de datos representa un enfoque para analizar conjuntos de datos que prioriza la comprensión sobre el modelado inmediato. El objetivo no es probar hipótesis de inmediato, sino generarlas examinando lo que los datos revelan mediante la visualización y el resumen estadístico.
En esencia, el análisis exploratorio de datos (AED) se centra en dos aspectos fundamentales: la síntesis numérica y la visualización de datos. Estas técnicas complementarias trabajan juntas para revelar patrones que, de otro modo, podrían permanecer ocultos en hojas de cálculo o bases de datos.
La EPA describe el EDA como un método de análisis que identifica patrones generales en los datos, incluyendo valores atípicos y características que podrían resultar inesperadas. Esta investigación inicial sienta las bases para todo el trabajo analítico posterior.
El propósito detrás de EDA
¿Por qué dedicar tiempo a explorar antes de analizar? Porque las suposiciones sobre los datos a menudo resultan erróneas. Una variable que se supone que sigue una distribución normal puede presentar una asimetría pronunciada. Las relaciones esperadas entre las características pueden no existir, mientras que surgen correlaciones inesperadas.
El análisis exploratorio de datos (AED) evita el desperdicio de esfuerzos en técnicas analíticas inapropiadas. Descubrir que un conjunto de datos contiene valores faltantes significativos o valores atípicos extremos modifica los métodos que producirán resultados válidos. Encontrar colinealidad entre variables predictoras influye en los enfoques de modelado de regresión.
Esta fase exploratoria también permite desarrollar la intuición sobre el dominio del conjunto de datos. Comprender los rangos de valores típicos, los patrones estacionales o las distribuciones de categorías ayuda a contextualizar los hallazgos posteriores y a detectar errores de modelado que producen resultados inverosímiles.
Componentes básicos de la EDA
Según fuentes académicas de Penn State, un análisis exploratorio de datos (AED) eficaz combina varios elementos clave que trabajan juntos para lograr una comprensión integral de los datos.
Recopilación de datos y evaluación de la calidad
Antes de comenzar el análisis, es fundamental comprender el origen de los datos. Según la guía para principiantes de Georgia Tech, la primera fase del análisis exploratorio de datos (EDA) verifica la estructura del conjunto de datos: número de filas y columnas, fuentes de archivos y rangos de tiempo que abarca.
En esta etapa, algunas señales de alerta incluyen conjuntos de datos inusualmente pequeños o enormes, fuentes mixtas sin etiquetas adecuadas o una cobertura temporal poco clara. Registrar instantáneas de los datos con recuentos, rutas de origen y fechas de recopilación garantiza la reproducibilidad desde el principio.
A continuación, se realiza una comprobación de coherencia del esquema, examinando los tipos de datos, los problemas de análisis y los niveles de categoría. Si se encuentran identificadores almacenados como números de coma flotante o fechas representadas como cadenas de texto, se detectarán problemas que deberán corregirse antes de poder realizar un análisis significativo.
Patrones de datos faltantes
Los datos faltantes rara vez aparecen de forma aleatoria. El análisis de los porcentajes de datos faltantes por columna y por fila revela si la ausencia sigue patrones vinculados a subgrupos o condiciones específicas.
Los patrones de datos faltantes no aleatorios o los bloques de "todo o nada", donde registros completos carecen de información, sugieren problemas sistemáticos de recopilación de datos en lugar de lagunas aleatorias. Comprender estos patrones influye en las estrategias de imputación o en si ciertas variables siguen siendo utilizables.
Tipos de análisis exploratorio de datos
Las técnicas de análisis exploratorio de datos (EDA, por sus siglas en inglés) se dividen en categorías según la cantidad de variables que se examinan simultáneamente y si predominan los métodos gráficos o cuantitativos.
Análisis univariado
La exploración univariada examina una variable a la vez, estableciendo una comprensión básica de las características individuales antes de investigar las relaciones.
Para las variables numéricas, esto implica calcular medidas de tendencia central (media, mediana, moda) y dispersión (desviación estándar, varianza, rango). Los histogramas revelan la forma de la distribución: si los datos siguen patrones normales, asimétricos, bimodales o uniformes.
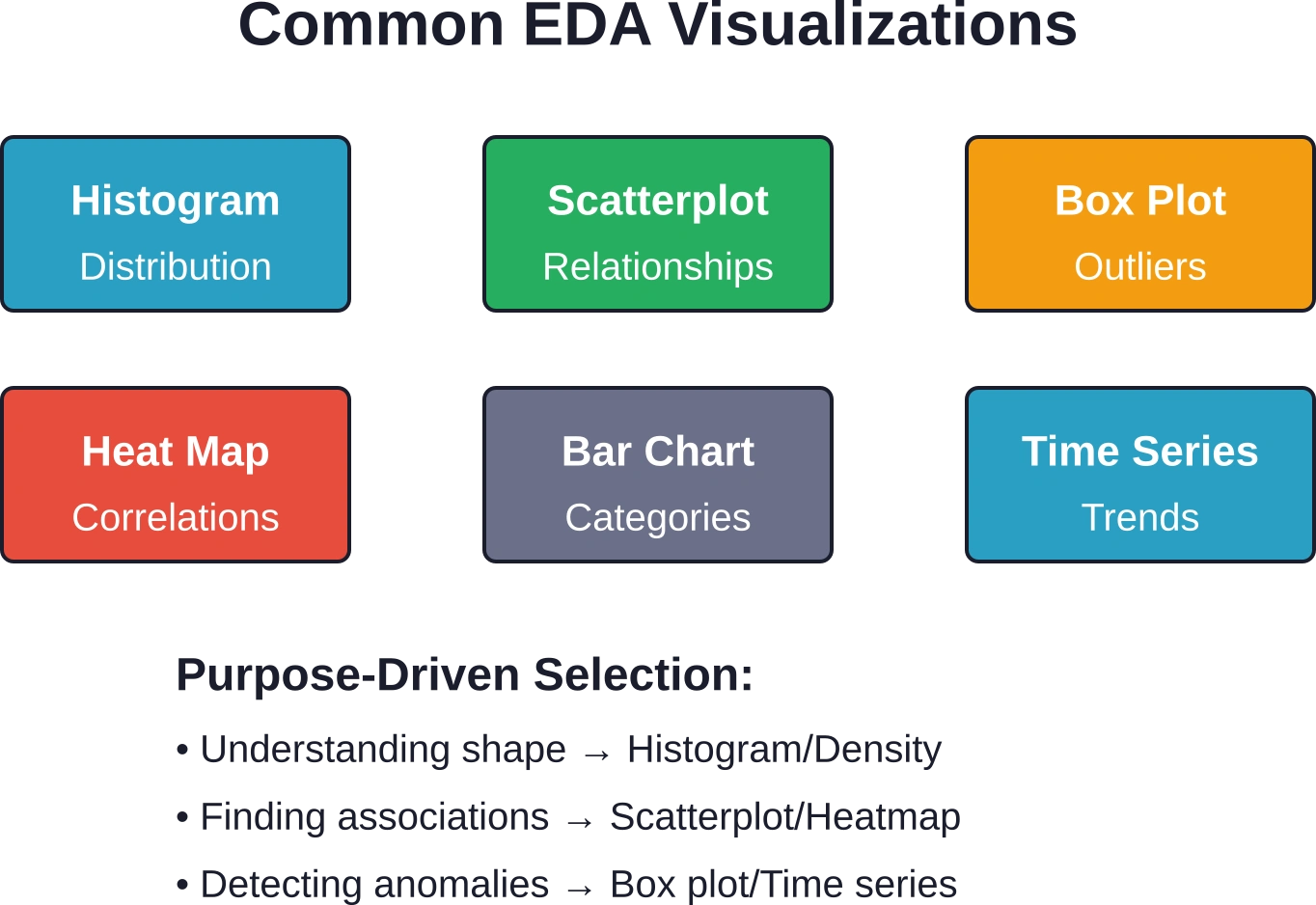
Según la descripción general de la EPA, los histogramas resumen las distribuciones al colocar las observaciones en intervalos y contar las ocurrencias en cada uno. El eje Y puede representar el número de observaciones, el porcentaje del total, la fracción del total (probabilidad) o la densidad.
Las variables categóricas requieren tablas de frecuencia y gráficos de barras que muestren cómo se distribuyen las observaciones entre las categorías. Identificar las categorías dominantes frente a las raras permite tomar decisiones posteriores sobre la agrupación o el tratamiento especial de los datos.
Análisis bivariado
Las técnicas bivariadas exploran las relaciones entre dos variables. Los diagramas de dispersión visualizan las asociaciones entre variables continuas, revelando relaciones lineales, curvas, agrupaciones o la ausencia de un patrón aparente.
El análisis de correlación cuantifica la fuerza de las relaciones lineales. Sin embargo, la correlación no implica causalidad, y centrarse únicamente en los coeficientes de correlación impide detectar las relaciones no lineales visibles en los gráficos.
Las tablas de contingencia examinan las asociaciones entre variables categóricas, mientras que los diagramas de caja agrupados por categorías comparan las distribuciones entre subgrupos; por ejemplo, examinando las distribuciones de ingresos por separado para diferentes niveles educativos.
Análisis multivariado
Los problemas del mundo real implican múltiples variables que interactúan simultáneamente. Las técnicas de análisis exploratorio de datos multivariado manejan tres o más variables, revelando patrones complejos invisibles en las comparaciones por pares.
Las matrices de diagramas de dispersión muestran todas las relaciones por pares en una cuadrícula, lo que proporciona una visión completa de las estructuras de correlación. La codificación por colores de los puntos según una variable categórica añade una tercera dimensión a los diagramas de dispersión estándar.
Los mapas de calor visualizan matrices de correlación, lo que facilita la identificación de grupos de variables relacionadas. El análisis de componentes principales (aunque más avanzado) reduce la dimensionalidad conservando la varianza, lo que ayuda a identificar qué combinaciones de variables generan la mayor variación.
Técnicas y herramientas esenciales de EDA
Un trabajo exploratorio eficaz requiere la combinación adecuada de métodos estadísticos y enfoques de visualización.
Técnicas de resumen estadístico
La estadística descriptiva constituye la base cuantitativa del análisis exploratorio de datos (AED). Más allá de las medias y medianas básicas, el análisis de los cuartiles revela cómo se distribuyen los datos a lo largo de su rango. El resumen de cinco números (mínimo, primer cuartil, mediana, tercer cuartil y máximo) proporciona una visión completa de la forma de la distribución.
Según los ejemplos de Penn State, un conjunto de datos de muestra que contiene 10 objetos con 4 atributos (ID, sexo, educación, ingresos) podría mostrar ingresos que van desde un mínimo de $0 hasta un máximo de $100,000. Estos límites establecen la escala de la variable y ayudan a identificar si los valores se encuentran dentro de los rangos esperados.
La asimetría y la curtosis cuantifican la asimetría de la distribución y la densidad de las colas. Una asimetría positiva indica una cola derecha larga, mientras que una curtosis negativa sugiere colas más ligeras que las de una distribución normal.
Métodos de visualización
Los gráficos revelan patrones que los resúmenes estadísticos por sí solos podrían pasar por alto. Los diferentes tipos de gráficos cumplen funciones distintas en el proceso exploratorio.
Los histogramas y los gráficos de densidad muestran las formas de distribución. Los diagramas de caja representan de forma eficiente las medianas, los cuartiles y los valores atípicos, facilitando la comparación entre grupos. Los diagramas de violín combinan la información de los diagramas de caja con la estimación de la densidad del núcleo.
Los diagramas de dispersión siguen siendo fundamentales para examinar las relaciones entre variables continuas. Añadir líneas de tendencia ayuda a evaluar si los modelos lineales se ajustan bien a los datos.
Los gráficos de barras comparan categorías, mientras que los gráficos de series temporales revelan patrones temporales: tendencias, estacionalidad y períodos anómalos.
Entornos de software y programación
Según los materiales del curso de Penn State, el software R ofrece varias características atractivas para el análisis exploratorio de datos (EDA). Python, con bibliotecas como Pandas, Matplotlib y Seaborn, proporciona capacidades igualmente potentes.
Ambos entornos permiten realizar análisis reproducibles mediante scripts, lo que permite a los analistas documentar cada paso de transformación y visualización. Esta reproducibilidad resulta fundamental cuando se actualizan los conjuntos de datos o cuando los colegas necesitan verificar los resultados.
Los cuadernos Jupyter y R Markdown combinan código, visualizaciones y explicaciones narrativas en documentos coherentes que comunican los hallazgos exploratorios a las partes interesadas que no leen el código fuente.
Proceso EDA paso a paso
Si bien el trabajo exploratorio implica creatividad, seguir un enfoque estructurado garantiza una cobertura integral sin pasar por alto cuestiones críticas.
Fase 1: Inspección inicial de datos
Comience cargando el conjunto de datos y examinando sus propiedades básicas. ¿Cuántas filas y columnas tiene? ¿Qué tipos de datos aparecen en cada columna? ¿Hay errores de análisis o problemas de codificación evidentes?
Imprime las primeras y las últimas filas para verificar que los datos se cargaron correctamente. Comprueba si hay registros duplicados que puedan inflar los resultados del análisis. Confirma que las columnas de identificadores contengan valores únicos.
Esta inspección inicial detecta problemas técnicos (archivos dañados, delimitadores incorrectos, errores de codificación) antes de invertir tiempo en un análisis más profundo.
Fase 2: Limpieza y preparación de datos
Según las directrices de ciencias de la información de Cornell, la documentación de recopilación y limpieza de datos debe registrar cada paso de la transformación. Esto puede incluir el manejo de valores faltantes, la corrección de tipos de datos, la estandarización de etiquetas de categoría o la eliminación de registros no válidos.
Las estrategias para el manejo de valores faltantes dependen de los patrones de datos faltantes. La ausencia de datos completamente aleatoria podría justificar una simple eliminación o imputación por la media. Los patrones sistemáticos requieren enfoques más sofisticados o la aceptación de tamaños de muestra reducidos.
Los valores atípicos requieren un análisis cuidadoso. Algunos representan valores extremos legítimos que contienen información importante. Otros reflejan errores de medición o de introducción de datos que conviene eliminar o corregir.
Fase 3: Exploración univariada
Analice cada variable individualmente. Para las características numéricas, calcule las estadísticas descriptivas y cree gráficos de distribución. Observe la tendencia central, la dispersión y las características de forma.
Para las variables categóricas, genere tablas de frecuencia. Identifique si las categorías están aproximadamente equilibradas o si existe un desequilibrio grave, una situación que afecta a muchos algoritmos de aprendizaje automático.
Documente los hallazgos inesperados. Una variable supuestamente continua que contiene solo unos pocos valores discretos, o una variable categórica con cientos de niveles únicos, indica posibles problemas de calidad de los datos o dificultades en el modelado.
Fase 4: Exploración bivariada y multivariada
Investiga las relaciones entre variables, especialmente entre posibles predictores y variables objetivo. Las matrices de correlación ofrecen una visión general rápida de las relaciones lineales entre características numéricas.
Crea diagramas de dispersión para pares de variables prometedores. Agrega líneas de suavizado para evaluar si las relaciones parecen lineales o requieren transformación.
Para problemas de clasificación, examine cómo difieren las distribuciones de los predictores entre las clases objetivo. Una fuerte separación sugiere características predictivas útiles, mientras que una superposición completa indica predictores débiles.
Fase 5: Generación de hipótesis
Basándose en los patrones observados, formule hipótesis sobre qué factores influyen en la variación de los datos. Estas hipótesis guiarán los esfuerzos de modelización posteriores.
Quizás ciertos segmentos de clientes muestren comportamientos de compra muy diferentes. Tal vez los patrones estacionales dominen la variación temporal. La fase de análisis exploratorio de datos (AED) revela estas ideas, que luego se prueban y cuantifican mediante modelos formales.
| Fase EDA | Actividades clave | Resultados comunes | Duración típica |
|---|---|---|---|
| Inspección inicial | Cargar datos, comprobar estructura, verificar carga | Instantánea de datos, recuentos de dimensiones | 10-15% de tiempo de EDA |
| Limpieza | Gestionar valores faltantes, corregir tipos, eliminar duplicados | Conjunto de datos limpio, registro de transformación | 25-35% de tiempo de EDA |
| Univariado | Análisis de variables individuales, distribuciones | Estadísticas descriptivas, histogramas | 20-25% de tiempo de EDA |
| Multivariado | Relaciones, correlaciones, patrones | Diagramas de dispersión, matrices de correlación | 25-30% de tiempo de EDA |
| Documentación | Registrar los hallazgos, generar hipótesis. | Informe EDA, panel de visualización | 10-15% de tiempo de EDA |

Haga que el análisis exploratorio de datos sea útil con IA superior
El análisis exploratorio de datos suele ser el primer paso antes de que una empresa pueda decidir qué tipo de proyecto de IA o análisis de datos le conviene. IA superior AI Superior puede brindar soporte en esta etapa mediante consultoría en IA, estrategia de datos e IA, inteligencia empresarial, análisis de datos, aprendizaje automático y análisis predictivo. Su trabajo ayuda a las empresas a revisar los datos disponibles, comprender patrones, identificar deficiencias y determinar si los datos están listos para un modelado más profundo o el desarrollo de software de IA. Esto resulta útil para equipos que han recopilado datos empresariales pero no están seguros de lo que estos pueden revelar. En lugar de lanzarse directamente a la creación de modelos, AI Superior puede ayudar a conectar la exploración de datos con casos de uso prácticos, informes más claros y el desarrollo futuro de la IA.
Para trabajos de análisis de datos, AI Superior puede ayudar con:
- Revisión de los datos comerciales disponibles
- Encontrar patrones, lagunas y señales útiles
- Preparación de datos para análisis o aprendizaje automático.
- Desarrollo de herramientas de inteligencia empresarial y análisis
- Definición de casos de uso prácticos de IA a partir de los resultados de los datos.
👉Contacta con IA Superior para analizar cómo el análisis exploratorio de datos puede respaldar su próximo proyecto de análisis, inteligencia empresarial o inteligencia artificial.
Identificación de patrones y anomalías
Uno de los objetivos principales del análisis exploratorio de datos (EDA) consiste en detectar patrones que sugieran relaciones que merezcan ser investigadas y anomalías que puedan indicar problemas o casos límite interesantes.
Reconocimiento de patrones
Los patrones se manifiestan de diversas formas. Los patrones temporales incluyen tendencias (aumentos o disminuciones a largo plazo), estacionalidad (fluctuaciones periódicas regulares) y ciclos (patrones repetidos irregulares).
Los patrones de agrupamiento surgen cuando las observaciones se agrupan de forma natural en segmentos distintos. Los clientes pueden agruparse según su comportamiento de compra, los pacientes según combinaciones de síntomas o las regiones geográficas según sus características ambientales.
Los patrones de asociación revelan que ciertas características tienden a aparecer juntas. En el análisis de cestas de compra, los productos que se compran juntos con frecuencia muestran fuertes asociaciones incluso sin vínculos causales.
Detección de valores atípicos
Los valores atípicos merecen especial atención durante la exploración. Podrían representar problemas de calidad de los datos que requieren corrección, o casos extremos genuinos que contienen información valiosa sobre escenarios poco frecuentes pero importantes.
Los métodos estadísticos, como la regla del rango intercuartil (RIC), identifican los valores atípicos como aquellos puntos que se encuentran a más de 1,5 veces el RIC fuera de los cuartiles. Las puntuaciones Z señalan las observaciones que se desvían varias desviaciones estándar de la media, aunque esto presupone distribuciones aproximadamente normales.
La inspección visual mediante diagramas de caja o diagramas de dispersión suele ser más informativa que las reglas puramente estadísticas. El contexto determina si los valores atípicos deben eliminarse, transformarse o analizarse por separado.
Correlación versus causalidad
El análisis exploratorio de datos (AED) suele revelar correlaciones: variables que se mueven juntas. Pero la correlación no implica causalidad. Dos variables pueden correlacionarse porque una causa a la otra, porque ambas responden a una causa común o simplemente por coincidencia.
Las ventas de helados se correlacionan con las muertes por ahogamiento, no porque el helado cause ahogamientos, sino porque ambos aumentan durante el verano. Distinguir la correlación de la causalidad requiere conocimientos específicos del tema y, a menudo, diseños experimentales o cuasiexperimentales que van más allá del alcance del análisis exploratorio de datos (AED).
Dicho esto, identificar correlaciones fuertes durante la exploración dirige la atención hacia relaciones que merecen ser investigadas mediante métodos de inferencia causal.
Ejemplos reales de EDA
Ejemplos concretos ilustran cómo se aplican las técnicas de análisis exploratorio de datos (EDA) a conjuntos de datos y problemas reales.
Ejemplo de análisis de regresión
Según los materiales del curso STAT 508 de Penn State, considere un modelo de regresión que examine cómo se relaciona el salario con los años de experiencia. El modelo ajustado obtuvo un valor de R cuadrado de 93,7%, con un R cuadrado ajustado de 91,6% y un R cuadrado predicho de 85,94%.
La ecuación de regresión arrojó un coeficiente constante de 24,8 y un coeficiente de pendiente de 15,2 para los años de experiencia, con un valor F de 44,78 y un valor p de 0,007. Estos resultados sugieren que los años de experiencia son un fuerte predictor del salario en este conjunto de datos, explicando la mayor parte de la variación salarial.
Durante el análisis exploratorio de datos (AED) para este tipo de problema, los diagramas de dispersión revelarían primero si una relación lineal parece plausible. Los gráficos de residuos comprobarían si existen patrones que sugieran el incumplimiento de supuestos, como la no linealidad, la heterocedasticidad o la presencia de valores atípicos influyentes.
Ejemplo de ANOVA
Los materiales de Penn State incluyen ejemplos de análisis ANOVA unidireccionales que examinan las diferencias entre grupos, demostrando cómo interpretar los valores F y los valores p para evaluar si las variables categóricas predicen significativamente los resultados.
El elevado valor p (0,184) sugiere que no existen pruebas suficientes de diferencias de género en este conjunto de datos. Un análisis exploratorio de datos previo a este análisis incluiría diagramas de caja que comparen las distribuciones entre las categorías de género y verifiquen supuestos como la homogeneidad de la varianza.

Errores comunes de EDA que se deben evitar
Incluso los analistas experimentados a veces caen en trampas durante el trabajo exploratorio que conducen a conclusiones erróneas o a un esfuerzo desperdiciado.
Omitir la validación de datos
Saltar directamente a la visualización sin validar la calidad de los datos resulta tentador, pero peligroso. Si introduces datos erróneos, obtendrás resultados erróneos: gráficos atractivos con datos corruptos pueden generar conclusiones engañosas.
Siempre verifique que los datos se hayan cargado correctamente, que los tipos sean coherentes y que los rangos de valores se encuentren dentro de límites plausibles. Una persona con 250 años o una temperatura de 500 grados Celsius indican problemas que requieren investigación.
Dependencia excesiva de las estadísticas resumidas automatizadas
Las estadísticas descriptivas proporcionan información valiosa, pero no detectan patrones importantes. El famoso ejemplo del cuarteto de Anscombe demuestra que cuatro conjuntos de datos con medias, varianzas y correlaciones idénticas presentan un aspecto completamente diferente al representarse gráficamente.
Visualiza siempre los datos en lugar de fiarte únicamente de las cifras resumidas. Los gráficos revelan asimetría, multimodalidad, valores atípicos y relaciones no lineales que las estadísticas pasan por alto.
Ignorar el conocimiento del dominio
Los patrones estadísticos desvinculados del conocimiento del dominio en cuestión suelen ser engañosos. Una anomalía aparente podría representar un comportamiento normal en ese contexto específico, mientras que patrones que parecen típicos podrían indicar problemas graves.
Consultar con expertos en la materia durante el análisis exploratorio de datos ayuda a interpretar correctamente los resultados y a centrar la atención en patrones realmente importantes en lugar de en artefactos estadísticos.
Sesgo de confirmación
Buscar patrones que confirmen creencias preexistentes e ignorar la evidencia contradictoria socava el trabajo exploratorio. El objetivo del análisis exploratorio de datos (AED) es descubrir lo que los datos realmente muestran, no validar suposiciones.
La exploración sistemática, siguiendo pasos estructurados, ayuda a contrarrestar el sesgo de confirmación. Documente los hallazgos inesperados, incluso cuando contradigan las expectativas; podrían resultar muy valiosos.
Consideraciones avanzadas sobre EDA
Más allá de las técnicas fundamentales, existen varios temas avanzados que merecen atención para proyectos analíticos complejos.
Manejo de datos de alta dimensión
Los conjuntos de datos con cientos o miles de variables suponen un reto para los enfoques tradicionales de análisis exploratorio de datos (EDA). Crear diagramas de dispersión para cada par de variables resulta poco práctico, y las matrices de correlación se vuelven demasiado grandes para interpretarlas visualmente.
Las técnicas de reducción de dimensionalidad, como el análisis de componentes principales, ayudan a identificar combinaciones lineales de características que capturan la mayor parte de la variación. Esto permite la visualización y exploración en espacios de menor dimensión, conservando la mayor parte de la información.
Las puntuaciones de importancia de las características obtenidas a partir de modelos basados en árboles ofrecen otro enfoque, clasificando las variables según su poder predictivo y permitiendo a los analistas centrarse en el subconjunto más relevante.
Consideraciones especiales sobre series temporales
Los datos temporales requieren técnicas especializadas de análisis exploratorio de datos (EDA). Los gráficos de autocorrelación revelan si las observaciones se correlacionan con sus propios valores pasados, un aspecto clave para los modelos de pronóstico.
La descomposición separa las series temporales en componentes de tendencia, estacionales y residuales, lo que permite aclarar qué patrones predominan y sugerir enfoques de modelado apropiados.
La detección de puntos de cambio identifica los momentos en que cambian los procesos subyacentes de generación de datos, lo cual es fundamental para comprender si los patrones históricos siguen siendo relevantes para las predicciones futuras.
Exploración de datos espaciales
Los conjuntos de datos geográficos se benefician del uso de mapas como técnica de análisis exploratorio de datos (AED). Los mapas coropléticos revelan patrones espaciales —agrupaciones, gradientes o puntos críticos aislados— que las tablas y los gráficos estándar no detectan en absoluto.
Las medidas de autocorrelación espacial cuantifican si las ubicaciones cercanas muestran valores similares, lo que permite comprobar si la proximidad geográfica influye en el fenómeno estudiado.
Comunicación de los resultados del análisis exploratorio de datos (AED)
La exploración genera conocimientos, pero esos conocimientos solo crean valor cuando se comunican eficazmente a las partes interesadas y a los miembros del equipo.
Creación de informes EDA
Los informes exhaustivos de análisis exploratorio de datos (AED) documentan el proceso exploratorio y sus hallazgos. Estos informes deben incluir descripciones de las fuentes de datos, los pasos de transformación realizados, visualizaciones de los patrones clave y un resumen de las conclusiones e hipótesis generadas.
Según las directrices de Cornell, los informes deben indicar claramente los objetivos desde el principio, documentar exhaustivamente la recopilación y la limpieza de datos, calcular las estadísticas descriptivas pertinentes y mostrar gráficos aplicables a los objetivos establecidos.
La reproducibilidad es de suma importancia. Otros deberían poder seguir los pasos documentados y llegar a las mismas conclusiones, verificando así que los hallazgos no se deban a errores o decisiones tomadas sin documentación.
Mejores prácticas de visualización
Las visualizaciones EDA eficaces priorizan la claridad sobre la estética. Cada elemento del gráfico debe tener un propósito: transmitir información en lugar de simplemente tener un aspecto impresionante.
Etiquete claramente los ejes con sus unidades. Incluya títulos informativos que describan lo que muestra el gráfico. Elija escalas apropiadas que no distorsionen las relaciones ni oculten variaciones importantes.
Para presentaciones dirigidas a público no técnico, las visualizaciones más sencillas suelen ser más efectivas que los gráficos multidimensionales complejos. Un gráfico de barras claro comunica con mayor eficacia que una visualización sofisticada que requiere una explicación extensa.
Análisis exploratorio de datos (AED) en el flujo de trabajo más amplio de la ciencia de datos.
El trabajo exploratorio no se realiza de forma aislada, sino que está conectado con los esfuerzos previos de recopilación de datos y las fases posteriores de modelado.
Análisis exploratorio de datos y recopilación de datos
Los hallazgos obtenidos mediante la exploración suelen revelar mejoras en la recopilación de datos. La falta de información crucial para responder preguntas clave podría justificar la recopilación de datos adicionales. Los problemas de calidad detectados podrían indicar la necesidad de realizar cambios en los flujos de datos.
Este ciclo de retroalimentación entre la exploración y la recopilación mejora iterativamente los conjuntos de datos con el tiempo, lo que hace que el trabajo analítico futuro sea más productivo.
EDA e ingeniería de características
Los patrones descubiertos durante la exploración sirven de base para la ingeniería de características: se crean nuevas variables a partir de las existentes para capturar mejor las relaciones de interés.
Observar relaciones no lineales podría sugerir términos polinómicos o de interacción. Notar que el impacto de una variable difiere entre subgrupos podría motivar la creación de características separadas para cada subgrupo.
Análisis exploratorio de datos y selección de modelos
Los hallazgos exploratorios orientan las decisiones de modelado. Las relaciones lineales entre predictores y objetivos sugieren que la regresión lineal podría ser adecuada. Los patrones no lineales indican la necesidad de utilizar términos polinómicos, splines o métodos no paramétricos.
Descubrir interacciones entre características durante las señales de EDA sugiere que los modelos capaces de capturar interacciones, como los métodos basados en árboles, podrían superar a los modelos aditivos.
La identificación de valores atípicos permite tomar decisiones sobre enfoques de modelado robustos frente a la eliminación de valores extremos. Comprender los patrones de datos faltantes orienta la elección de estrategias de imputación.
| Características de los datos | Indicador EDA | Enfoque de modelado sugerido |
|---|---|---|
| Relaciones lineales | Diagramas de dispersión de línea recta | Regresión lineal, modelos lineales generalizados (GLM) |
| Patrones no lineales | Relaciones curvas en gráficos | Términos polinómicos, splines, modelos de árbol |
| valores atípicos fuertes | Bigotes de diagrama de caja extremos | Regresión robusta, eliminación de valores atípicos |
| Alta colinealidad | Matriz de correlación >0,9 | Regresión de cresta, PCA, selección de características |
| Interacciones complejas | Cambios en la relación por subgrupo | Modelos de árbol, términos de interacción |
| Dominante categórico | Variables mayoritariamente categóricas | Regresión logística, Naive Bayes |
Herramientas y tecnologías para EDA
Seleccionar las herramientas adecuadas acelera el trabajo exploratorio y permite un análisis más sofisticado.
Lenguajes de programación
Python y R dominan el trabajo de análisis exploratorio de datos (EDA) en la ciencia de datos. La biblioteca Pandas de Python proporciona potentes capacidades de manipulación de datos, mientras que Matplotlib, Seaborn y Plotly se encargan de las necesidades de visualización.
R destaca en computación estadística gracias a sus funciones integradas para la mayoría de las tareas comunes de análisis exploratorio de datos (EDA). El paquete ggplot2 crea gráficos de alta calidad para publicaciones siguiendo una gramática gráfica rigurosa.
Ambos lenguajes admiten entornos de cuaderno (Jupyter para Python, R Markdown para R) que combinan código, resultados y texto explicativo en documentos coherentes.
Software EDA especializado
Tableau y Power BI ofrecen interfaces intuitivas para la visualización de datos, lo que facilita el acceso a gráficos complejos incluso para usuarios con menos conocimientos técnicos. Estas herramientas destacan por sus paneles interactivos, que permiten a los interesados explorar los datos sin necesidad de escribir código.
Pero sacrifican la reproducibilidad y la personalización en comparación con los enfoques basados en programación. Los cambios en los gráficos requieren clics manuales en lugar de volver a ejecutar scripts documentados.
Bibliotecas de código abierto
Bibliotecas como pandas-profiling y sweetviz automatizan muchas tareas de análisis exploratorio de datos (EDA), generando informes completos con un solo comando. Estas herramientas resultan útiles para una evaluación inicial rápida, pero no deben reemplazar una exploración manual minuciosa.
Los informes automatizados a veces pasan por alto patrones específicos del dominio o señalan hallazgos erróneos. Funcionan mejor como complemento —no como sustituto— del trabajo exploratorio deliberado guiado por preguntas de investigación.
Preguntas frecuentes
¿Cuál es la diferencia entre el análisis exploratorio de datos (EDA) y el análisis confirmatorio de datos?
El análisis exploratorio de datos (AED) genera hipótesis mediante la exploración de datos sin ideas preconcebidas, centrándose en el descubrimiento de patrones y la formulación de preguntas. El análisis confirmatorio pone a prueba hipótesis específicas utilizando estadística inferencial, determinando si los patrones observados reflejan fenómenos reales o el azar. El AED se aplica primero, identificando qué merece ser probado formalmente, mientras que el análisis confirmatorio se realiza posteriormente con pruebas estadísticas rigurosas.
¿Cuánto tiempo debería durar la fase de análisis exploratorio de datos (EDA) en un proyecto de ciencia de datos?
La experiencia del sector sugiere dedicar entre 20 y 301 TP3T del tiempo total del proyecto al análisis exploratorio de datos (AED), aunque esto varía según la complejidad y la familiaridad con los datos. Para conjuntos de datos o dominios nuevos, una exploración más exhaustiva resulta beneficiosa. Con fuentes de datos conocidas, una exploración más rápida es suficiente. La clave reside en equilibrar la exhaustividad con los plazos del proyecto: un AED insuficiente conlleva errores de modelado, mientras que una exploración excesiva retrasa la obtención de valor.
¿Se puede automatizar completamente el análisis exploratorio de datos (EDA)?
Las herramientas automatizadas de análisis exploratorio de datos (EDA) generan rápidamente informes resumidos útiles y visualizaciones estándar, pero la automatización completa sigue siendo problemática. Una exploración eficaz requiere conocimiento del dominio para interpretar patrones, criterio para discernir qué hallazgos son relevantes y creatividad para investigar observaciones inesperadas. La automatización gestiona bien las tareas rutinarias, lo que permite a los analistas centrarse en la interpretación y la generación de hipótesis, tareas que requieren la perspicacia humana.
¿Cuál es la técnica EDA más importante que hay que dominar primero?
Los fundamentos de la visualización ofrecen el mayor retorno de la inversión en aprendizaje. Comprender cómo crear e interpretar histogramas, diagramas de caja y diagramas de dispersión permite descubrir los patrones más importantes. Estas visualizaciones básicas revelan distribuciones, valores atípicos y relaciones que las estadísticas descriptivas por sí solas no muestran. Domine los gráficos sencillos antes de pasar a técnicas multivariantes complejas o métodos estadísticos especializados.
¿Cómo se gestionan los datos faltantes durante el análisis exploratorio de datos (EDA)?
Primero, cuantifique los datos faltantes: qué porcentaje de cada variable y cuántos registros completos quedan. Segundo, investigue los patrones: ¿los datos faltantes se correlacionan con otras variables o parecen aleatorios? Tercero, decida una estrategia: la eliminación funciona cuando los datos faltantes son verdaderamente aleatorios y la muestra restante es adecuada; la imputación (media, mediana o basada en modelos) es apropiada para pequeñas brechas aleatorias; las técnicas especializadas como la imputación múltiple manejan patrones complejos. Documente todas las decisiones y evalúe la sensibilidad.
¿Deberían eliminarse los valores atípicos durante el análisis exploratorio de datos?
No automáticamente. Primero, determine si los valores atípicos representan errores (mediciones incorrectas, errores de entrada de datos) o valores extremos legítimos. Elimine o corrija los errores, pero conserve los valores atípicos genuinos a menos que sean irrelevantes para las preguntas de investigación. Para el modelado, considere métodos robustos que reduzcan el peso de los valores atípicos en lugar de eliminar la información. Al eliminar valores atípicos, documente qué observaciones se excluyeron y por qué, garantizando así la transparencia y la reproducibilidad.
¿En qué se diferencia el análisis exploratorio de datos (EDA) para el aprendizaje automático de la estadística tradicional?
El análisis exploratorio de datos (AED) estadístico tradicional se centra en verificar supuestos para pruebas específicas: normalidad, homocedasticidad e independencia. El AED en aprendizaje automático se enfoca más en las relaciones entre características, patrones predictivos y problemas de calidad de datos que afectan el rendimiento del modelo. La exploración en aprendizaje automático también examina las distribuciones de los conjuntos de entrenamiento y prueba para garantizar la representatividad, mientras que los enfoques tradicionales se preocupan menos por la predicción en datos nuevos. Ambos requieren comprender las distribuciones y las relaciones, pero las prioridades difieren según los objetivos analíticos.
Conclusión
El análisis exploratorio de datos constituye la base esencial para cualquier trabajo serio con datos. Omitir o realizar la exploración de forma apresurada conlleva esfuerzos de modelado erróneos, la pérdida de información valiosa y el desperdicio de recursos al perseguir patrones inexistentes o pasar por alto los que sí existen.
Las técnicas aquí descritas —desde comprobaciones básicas de distribución hasta métodos multivariados avanzados— proporcionan un conjunto completo de herramientas para comprender los conjuntos de datos antes de iniciar el análisis formal. Sin embargo, las herramientas por sí solas no garantizan una buena exploración. Un análisis exploratorio de datos (AED) eficaz requiere curiosidad por lo que revelan los datos, escepticismo ante los patrones aparentes y disposición para seguir los hallazgos inesperados adondequiera que conduzcan.
Según los materiales académicos de Penn State, el análisis exploratorio de datos (AED) proporciona indicaciones iniciales sobre diversas técnicas de aprendizaje al examinar observaciones complejas en busca de estructuras que indiquen relaciones más profundas. Esta generación de hipótesis basada en datos transforma cifras brutas en información útil que impulsa decisiones empresariales, descubrimientos científicos e innovaciones tecnológicas.
Para comenzar tu próximo proyecto de datos, dedica el tiempo necesario a una exploración exhaustiva. Documenta tus hallazgos. Visualiza los datos antes de modelar. Cuestiona las suposiciones. Los conocimientos adquiridos durante un análisis exploratorio de datos (AED) cuidadoso te guiarán para tomar mejores decisiones a lo largo del proceso analítico y, en última instancia, te brindarán resultados más valiosos y confiables.
¿Listo para aplicar estas técnicas? Empiece con un conjunto de datos que le interese, siga sistemáticamente las fases estructuradas y descubra lo que sus datos han estado tratando de decirle todo este tiempo.