Kurzzusammenfassung: Die Inferenzkosten von LLM sind seit 2021 jährlich um das Zehnfache gesunken. Die Leistung auf GPT-4-Niveau kostet nun $0,40 pro Million Token, verglichen mit $30 pro Million Input-Token und $60 pro Million Output-Token im März 2023. Allerdings können Inferenzmodelle intern 100-mal mehr Token verbrauchen als sie ausgeben. Dies führt zu einem Kostenparadoxon: Niedrigere Preise pro Token führen zu höheren Gesamtkosten. Das Verständnis der tatsächlichen Infrastrukturkosten, Optimierungstechniken und der Wahl zwischen API-Diensten und selbstgehosteten Bereitstellungen ist für eine nachhaltige KI-Ökonomie unerlässlich.
Die Ökonomie der künstlichen Intelligenz hat eine Phase erreicht, die der herkömmlichen Logik widerspricht. Während Schlagzeilen sinkende Token-Preise feiern, entdecken KI-Unternehmen eine unangenehme Wahrheit: Ihre Kosten steigen stetig.
Was im November 2021 noch 1,4 Billionen Tsd. pro Million Token kostete, kostet heute nur noch 0,06–0,40 Tsd. pro Million Token bei vergleichbarer GPT-4-Leistung – eine Reduzierung um das 150- bis 1000-Fache, je nach Modell. Dennoch berichten viele Startups, die auf großen Sprachmodellen aufbauen, von Infrastrukturkosten, die 40–601 Billionen Tsd. ihrer Einnahmen verschlingen.
Der Übeltäter? Eine grundlegende Veränderung in der Art und Weise, wie moderne KI-Modelle Antworten generieren – und ein Token-Verbrauchsmuster, das niemand vorhergesehen hat.
Der dramatische Rückgang der Preise für LLM-Schlussfolgerungen
Die Kosten für LLM-Inferenz sind schneller gesunken als bei fast allen anderen IT-Produkten in der Geschichte. Laut Studien, die Preistrends analysieren, variiert die Kostensenkungsrate je nach Leistungsziel erheblich und reicht vom Neunfachen bis zum Neunhundertfachen pro Jahr.
Die Rückgangsrate variiert je nach Aufgabe erheblich. Bei einigen Benchmarks sanken die Preise jährlich um das Neunfache. Bei anderen erreichte der Rückgang sogar das Neunhundertfache pro Jahr – wobei diese extremen Rückgänge hauptsächlich im Jahr 2024 auftraten und möglicherweise nicht anhalten.
So sieht das in der Praxis aus: Als GPT-3 im November 2021 öffentlich zugänglich wurde, war es das einzige Modell mit einem MMLU-Wert von 42. Die Kosten? $60 pro Million Token. Bis März 2026 werden mehrere Modelle diesen Wert mit $0,06 pro Million Token oder weniger unterbieten.
Googles Gemini Flash-Lite 3.1 ist mit $0,25 pro Million Input-Token und $1,50 pro Million Output-Token führend im Budget-Segment. Open-Source-Modelle von Anbietern wie Together.ai sind sogar noch günstiger – Llama 3.2 3B kostet beispielsweise $0,06 pro Million Input-Token.
Warum die Preise so schnell gefallen sind
Mehrere Faktoren tragen zu diesen Kostensenkungen bei. Dank verbesserter Trainingsmethoden werden die Modelle kleiner, ohne an Leistung einzubüßen. Ein Modell mit 13 Milliarden Parametern erreicht nun einen MMLU-Score von 95% von GPT-3 mit einem deutlich geringeren Speicherbedarf.
Die Hardwarekosten pro Recheneinheit sinken weiter. Die Preise für Cloud H100 haben sich nach dem Rückgang von den Höchstständen im Jahr 2023 bei $2,85–$3,50 pro Stunde stabilisiert. Laut einer Studie von arXiv belaufen sich die Basiskosten pro A800 80G-Karte auf etwa $0,79/Stunde und liegen üblicherweise zwischen $0,51 und $0,99/Stunde.
Optimierungstechniken wie Quantisierung, kontinuierliches Batching und PagedAttention haben die Durchsatzleistung deutlich gesteigert. Systeme im MLPerf Inference v5.1 Benchmark erzielten eine Verbesserung von bis zu 50% gegenüber dem besten System der Version 5.0 sechs Monate zuvor (September 2025).
Aber es gibt einen Haken.
Das Token-Konsum-Paradoxon
Niedrigere Preise pro Token erzählen nur die halbe Wahrheit. Die andere Hälfte betrifft den tatsächlichen Tokenverbrauch moderner Modelle.
Traditionelle Sprachmodelle generieren Antworten linear. Man stellt eine Frage und erhält eine Antwort. Der Tokenverbrauch entspricht in etwa der Ausgabelänge. Eine 200 Wörter lange Antwort benötigt ungefähr 250–300 Token.
Argumentationsmodelle funktionieren anders. Sie durchdenken Probleme intern, bevor sie ein Ergebnis liefern. Dieser interne Denkprozess verbraucht Token – und zwar viele.
Beispiele aus der Praxis verdeutlichen das Ausmaß dieser Veränderung. Eine einfache Frage kann intern 10.000 Argumentationsbausteine verwenden, liefert aber nur eine Antwort mit 200 Bausteinen. Das sind 50-mal mehr Bausteine, als die sichtbare Ausgabe vermuten lässt.
In von Nutzern dokumentierten Extremfällen verbrauchten einige Schlussfolgerungsmodelle über 600 Tokens, um lediglich zwei Wörter als Ausgabe zu generieren. Eine einfache Abfrage, die mit einem Standardmodell 50 Tokens benötigen würde, kann bei aktiviertem aggressivem Reasoning auf über 30.000 Tokens anwachsen.
Die geschäftlichen Auswirkungen
Dies führt zu dem, was manche das “LLM-Kostenparadoxon” nennen. Der Preis pro Token sank um das Zehnfache, der Tokenverbrauch stieg jedoch für bestimmte Anwendungsfälle um das Hundertfache. Die Rechnung ist für KI-Unternehmen ungünstig.
Startups, deren Preismodelle auf traditioneller Token-Ökonomie basieren, sehen sich mit sinkenden Margen konfrontiert. Ein Kunde, der monatlich $20 zahlt, kann bei rechenintensiven Aufgaben Inferenzkosten in Höhe von $18–25 verursachen. Die Stückkostenrechnung ist schlichtweg nicht praktikabel.
Einige Anbieter reagierten darauf, indem sie die Anzahl der Logik-Tokens begrenzten und so die internen Denkprozesse eines Modells einschränkten. Andere führten gestaffelte Preise ein, bei denen rechenintensive Anfragen teurer sind. Diese Lösungen führen jedoch zu Reibungsverlusten und erhöht die Komplexität.
Die wahren Infrastrukturkosten verstehen
Neben der API-Preisgestaltung müssen Teams, die selbstgehostete Bereitstellungen in Betracht ziehen, die gesamte Kostenstruktur verstehen. Die Zahlen zeigen, wann Selbsthosting wirtschaftlich sinnvoll ist – und wann nicht.
Ökonomie der GPU-Infrastruktur
Gemäß den im Juni 2025 veröffentlichten Benchmarking-Richtlinien von NVIDIA müssen bei der Berechnung der tatsächlichen Inferenzkosten Hardwarebeschaffung, Stromverbrauch, Kühlung, Netzwerkbandbreite und Betriebskosten berücksichtigt werden.
Cloud-H100-Instanzen kosten je nach Anbieter und Vertragslaufzeit zwischen 2,85 und 3,50 TP4T pro Stunde. Selbstgehostete H100-Instanzen erfordern Investitionskosten und laufende Kosten. Die Gewinnschwelle hängt von der Auslastung ab.
Untersuchungen zeigen, dass selbstgehostete Infrastruktur rentabel wird, wenn die GPU-Auslastung nachhaltig 50% übersteigt. Unterhalb dieser Schwelle sind API-Dienste in der Regel wirtschaftlicher.
| Kostenkomponente | Cloud-Anbieter | Selbstgehostet |
|---|---|---|
| GPU-Kosten | $2,85-3,50/Stunde | $30.000-40.000 (H100) |
| Leistung (pro GPU) | Inklusive | $0,40-0,60/Stunde |
| Kühlung | Inklusive | $0,15-0,25/Stunde |
| Netzwerk | $0.08-0.12/GB Ausgang | Fester monatlicher Betrag |
| Operationen | Minimal | 1-2 Vollzeit-Ingenieure |
| Gewinnschwelle | — | 50%+ Nutzung |
Die Nutzungsgleichung
Die Auslastung ist entscheidend. Eine GPU mit einer Auslastung von 30% verursacht pro Inferenz 3,3-mal höhere Kosten als eine mit 100%. Um eine hohe Auslastung zu erreichen, sind jedoch ein konstantes Arbeitslastvolumen und ausgefeilte Batching-Strategien erforderlich.
Die Stapelverarbeitung kann die Kosten pro Ausgabetoken im Vergleich zur Einzelanfrageverarbeitung um bis zu 301 TP3T senken. Techniken wie Continuous Batching, bei dem die Inferenz-Engine Anfragen dynamisch kombiniert, sobald diese eintreffen, maximieren den Durchsatz.
Effizienzsteigerungen durch Quantisierung, Mixture-of-Experts-Architekturen und Datenbereinigung können die Wirtschaftlichkeit um das 2- bis 5-Fache verbessern, ohne die Qualität zu beeinträchtigen. Laut Informationen von Together.ai bietet die MoE-Architektur von DeepSeek kosteneffizient eine Leistung auf GPT-4-Niveau.
Kostenstruktur über verschiedene Modellgrößen hinweg
Die Modellgröße beeinflusst die Inferenzkosten direkt, aber der Zusammenhang ist nicht linear. Kleinere Modelle bedeuten nicht immer proportional niedrigere Kosten, und größere Modelle bieten mitunter ein besseres Preis-Leistungs-Verhältnis bei komplexen Aufgaben.
Kleine Modelle (3B-7B-Parameter)
Modelle dieser Kategorie zeichnen sich durch ihre Kosteneffizienz bei einfachen Aufgaben aus. Llama 3.2 3B kostet etwa $0,06 pro Million Token. Diese Modelle eignen sich gut für Klassifizierung, einfache Fragebeantwortung und die Extraktion strukturierter Daten.
Der Kompromiss liegt in der Leistungsfähigkeit. Kleine Modelle haben Schwierigkeiten mit komplexen Schlussfolgerungen, differenziertem Sprachverständnis und Aufgaben, die umfassendes Weltwissen erfordern. Für viele Produktionsanwendungen ist das akzeptabel.
Mittlere Modelle (13B-70B-Parameter)
Dieser Bereich stellt für viele Anwendungen den optimalen Bereich dar. Ein 13-Bit-Modell, das einen MMLU-Wert von 95% von GPT-3 erreicht, könnte $0,25 pro Million Token kosten – mehr als winzige Modelle, aber mit deutlich besseren Schlussfolgerungsfähigkeiten.
Modelle der 70B-Klasse wie Llama 3.1 70B bieten eine nahezu Spitzenleistung mit Kosten von etwa $0,80 pro Million Token. Für Anwendungen, die eine fundierte Analyse erfordern, aber keine absolut fortschrittlichen Funktionen benötigen, bieten diese Modelle eine hervorragende Wirtschaftlichkeit.
Große Modelle (über 175 Milliarden Parameter)
Spitzenmodelle wie GPT-4, Claude und Gemini Ultra kosten je nach Modell und Anbieter $2-15 pro Million Token. Sie zeichnen sich durch ihre Fähigkeit zu komplexem Denken, kreativen Aufgaben und Problemen aus, die tiefgreifendes Fachwissen erfordern.
Die höheren Kosten pro Token werden dann wirtschaftlich, wenn das Modell Aufgaben in weniger Iterationen erledigt, genauere Antworten liefert oder Anwendungsfälle ermöglicht, die kleinere Modelle einfach nicht bewältigen können.

Benötigen Sie Hilfe bei der Konzeption und Implementierung eines LLM-Systems?
Wenn Sie planen, ein großes Sprachmodell in der Produktion einzusetzen, ist es hilfreich, mit einem Team zusammenzuarbeiten, das täglich KI-Systeme entwickelt und implementiert. AI Superior Das Unternehmen entwickelt maßgeschneiderte KI-Anwendungen auf Basis von maschinellem Lernen und LLM-Modellen – von der ersten Machbarkeitsanalyse bis hin zu Implementierung und Integration. Das Team aus Data Scientists und Ingenieuren arbeitet an der Modellentwicklung, NLP-Systemen, Datenpipelines und der produktiven Implementierung. Darüber hinaus unterstützt es bei der Bewertung, ob ein Anwendungsfall tatsächlich ein LLM erfordert und wie das System für einen effizienten Betrieb strukturiert werden kann.
Sind Sie bereit, Ihr LLM-Studium zu planen?
Sprechen Sie mit einer KI, die überlegen ist gegenüber:
- Bewerten Sie Ihren LLM-Anwendungsfall und die technischen Anforderungen
- Entwicklung und Bau kundenspezifischer KI- oder NLP-Systeme
- Modelle bereitstellen und in bestehende Software integrieren
👉 Fordern Sie eine KI-Beratung an mit AI Superior um Ihr LLM-Projekt zu besprechen.
API-Dienste vs. Selbstgehostete Wirtschaftlichkeit
Die Wahl zwischen API-Diensten und selbstgehosteter Infrastruktur hängt von Umfang, Nutzungsmustern und technischen Möglichkeiten ab. Keine der beiden Optionen ist allgemein überlegen.
Wenn API-Dienste gewinnen
API-Dienste von OpenAI, Anthropic, Google und Anbietern wie Together.ai bieten in vielen Anwendungsfällen überzeugende wirtschaftliche Vorteile. Dank des Wegfalls der Infrastrukturverwaltung können sich Teams auf die Anwendungslogik anstatt auf die GPU-Orchestrierung konzentrieren.
Die Kosten steigen linear mit der Nutzung. Monate mit geringer Nutzung verursachen proportional geringere Kosten als Monate mit hoher Nutzung. Es fallen keine Investitionskosten an, es gibt keine ungenutzten Kapazitäten in Zeiten geringer Nachfrage und keinen Betriebsaufwand für die modellbasierte Infrastruktur.
Bei Anwendungen mit schwankendem Datenverkehr, saisonaler Nachfrage oder unvorhersehbaren Wachstumskurven bieten APIs in der Regel eine bessere Wirtschaftlichkeit, es sei denn, der nachhaltige Durchsatz überschreitet einen relativ hohen Schwellenwert.
Wann Selbsthosting sinnvoll ist
Selbsthosting wird wirtschaftlich rentabel, wenn die GPU-Auslastung nachhaltig 50% übersteigt. Laut Benchmark-Daten erfordert dies ein konstantes Arbeitslastvolumen – etwa 10 Millionen Token täglich für ein einzelnes GPU-Setup.
Neben rein wirtschaftlichen Gründen hosten manche Organisationen ihre Systeme selbst, um Datenschutzbestimmungen einzuhalten, individuelle Anpassungen zu ermöglichen oder bestimmte Latenzanforderungen zu erfüllen. Anwendungen im Finanzdienstleistungssektor, im Gesundheitswesen und im öffentlichen Sektor können Daten oft nicht an APIs von Drittanbietern senden, selbst wenn dies Kostenvorteile mit sich bringt.
Open-Source-Inferenz-Engines wie vLLM ermöglichen leistungsstarke, selbstgehostete Bereitstellungen. vLLMs PagedAttention- und Continuous-Batching-Verfahren maximieren die GPU-Auslastung und machen Self-Hosting dadurch wirtschaftlich wettbewerbsfähiger.
| Faktor | Bevorzugt APIs | Bevorzugt Selbsthosting |
|---|---|---|
| Volumen | <10 Mio. Token/Tag | >50 Millionen Token pro Tag |
| Verkehrsmuster | Variabel/spikig | Beständig/vorhersehbar |
| Latenzanforderungen | Flexibel | Extrem niedriger Energieverbrauch erforderlich |
| Datensensitivität | Standard | Hochsensibel |
| Anpassung | Standardmodelle OK | Benötige Sondermodelle |
| Technische Kapazität | Begrenzte ML-Operationen | Starkes ML-Operations-Team |
Optimierungstechniken, die die Wirtschaftswissenschaften verändern
Verschiedene Techniken können die Inferenzkosten um das 2- bis 10-Fache senken, ohne die Qualität zu beeinträchtigen. Diese Optimierungen funktionieren sowohl bei Verwendung von APIs als auch beim Selbsthosting.
Quantisierung
Die Quantisierung reduziert die Modellgenauigkeit von 16-Bit- oder 32-Bit-Gleitkommazahlen auf 8-Bit- oder sogar 4-Bit-Ganzzahlen. Dadurch wird der Speicherbedarf verringert und die Inferenz beschleunigt.
Moderne Quantisierungsmethoden erhalten die Qualität bemerkenswert gut. Studien zum FP8-Training zeigen, dass die meisten Variablen im LLM-Training und in der Inferenz in Formaten mit niedriger Präzision verwendet werden können, ohne dass die Genauigkeit beeinträchtigt wird. Anbieter wie Together.ai bieten quantisierte Modelle zu reduzierten Preisen an und garantieren dabei die Beibehaltung der Qualität.
Schnelle Optimierung
Die Länge der Eingabeaufforderung hat direkten Einfluss auf die Kosten. Eine Eingabeaufforderung mit 5.000 Token, die 1.000 Mal verarbeitet wird, kostet genauso viel wie 5 Millionen Token für die Schlussfolgerung. Durch die Optimierung der Eingabeaufforderungen hin zu Kürze bei gleichbleibender Effektivität lassen sich die Kosten sofort senken.
Forschungsergebnisse zeigen, dass die Optimierung von Eingabeaufforderungen die Genauigkeit bei Aufgaben verbessern und gleichzeitig den Tokenverbrauch reduzieren kann. Gut strukturierte Eingabeaufforderungen führen Modelle effizienter und verringern so die Anzahl der benötigten Logik-Token, um zu korrekten Antworten zu gelangen.
Antwort-Caching
Viele Anwendungen stellen wiederholt ähnliche oder identische Anfragen. Durch das Zwischenspeichern von Antworten auf häufige Anfragen werden redundante Ableitungskosten vollständig eliminiert.
Intelligente Caching-Strategien berücksichtigen die Ähnlichkeit der Anfragen, nicht nur exakte Übereinstimmungen. Semantisches Caching vergleicht die Bedeutung von Anfragen und liefert zwischengespeicherte Antworten für ausreichend ähnliche Anfragen, selbst wenn sich die Formulierung unterscheidet.
Modellrouting
Nicht jede Anfrage erfordert das leistungsstärkste Modell. Indem einfache Anfragen an kleine, schnelle Modelle und komplexe Anfragen an größere Modelle weitergeleitet werden, wird das Kosten-Nutzen-Verhältnis optimiert.
Dies erfordert eine vorgelagerte Logik zur Klassifizierung der Anfragekomplexität, doch die Wirtschaftlichkeit rechtfertigt die Investition oft. Die Weiterleitung von 701.030 Token an ein Token-Modell mit 1.040.000 Token und 301.030 Token an ein Token-Modell mit 1.040.000 Token ergibt durchschnittliche Kosten von 1.040.000 Token – deutlich niedriger als die Verwendung des teuren Modells für den gesamten Datenverkehr.
Anbieterlandschaft im Jahr 2026
Der Markt für Inferenzdienstleister hat sich erheblich weiterentwickelt. Mittlerweile bedienen verschiedene Anbieterkategorien unterschiedliche Bedürfnisse.
Frontier Model APIs
OpenAI, Anthropic und Google bieten modernste Funktionen zu Premiumpreisen. Modelle der GPT-4-Klasse kosten je nach Modellvariante zwischen $2 und 15 pro Million Token. Diese Anbieter investieren stark in Sicherheit, Zuverlässigkeit und innovative Technologien.
Die 2025 veröffentlichten Modelle o3 und o4-mini von OpenAI stellen Fortschritte in der Schlussfolgerungsfähigkeit dar. Laut OpenAI-Bewertungen macht o3 bei schwierigen realen Aufgaben weniger schwerwiegende Fehler als o1 und erzielt insbesondere in Programmier- und Unternehmensberatungsanwendungen hervorragende Ergebnisse.
Open-Source-Modellplattformen
Anbieter wie Together.ai, Fireworks und Replicate bieten Open-Source-Modelle zu deutlich niedrigeren Preisen an. DeepSeek-Modelle von Together.ai ermöglichen Kosteneinsparungen von 70 bis 901 TP3T gegenüber proprietären Alternativen und bieten gleichzeitig Spitzenleistung.
Diese Plattformen kombinieren gängige Open-Source-Modelle mit proprietärer Serverinfrastruktur. Das Ergebnis: hervorragende Leistung zu deutlich niedrigeren Preisen, allerdings mitunter bei weniger umfassenden Sicherheitsfiltern und Inhaltsmoderation.
KI-Dienste von Cloud-Anbietern
AWS, Azure und Google Cloud bieten sowohl eigene als auch Drittanbietermodelle über einheitliche APIs an. Die Preise variieren, aber Cloud-Anbieter erheben in der Regel eine Gewinnspanne gegenüber dem direkten API-Zugriff und bieten dafür Funktionen für Unternehmen wie SLAs, Compliance-Zertifizierungen und die Integration in bestehende Cloud-Infrastrukturen.
Spezialisierte Inferenzanbieter
Unternehmen wie Groq konzentrieren sich speziell auf die Optimierung von Inferenzprozessen. Groq setzt dabei auf die Optimierung von Inferenzprozessen durch kundenspezifische Siliziumchips für geringe Latenzzeiten.
zukünftige Kostenentwicklung
Wie entwickeln sich die Inferenzkosten von hier aus? Mehrere Trends prägen die Erwartungen.
Die für den Zeitraum 2021–2025 prognostizierten jährlichen Kostensenkungsraten um das Zehnfache werden sich voraussichtlich nicht im gleichen Tempo fortsetzen. Die offensichtlichsten Optimierungsmöglichkeiten sind ausgeschöpft. Hardwareverbesserungen schreiten zwar weiter voran, jedoch in einem deutlich geringeren Tempo. Innovationen in der Modellarchitektur sind weiterhin zu beobachten, jedoch seltener als im dynamischen Zeitraum von 2022 bis 2024.
Eine realistischere Erwartung geht von jährlichen Reduzierungen um das 3- bis 5-Fache bis 2027 aus, die sich anschließend auf das 1,5- bis 2-Fache jährlich verringern. Dies stellt zwar immer noch eine deutliche Verbesserung dar, jedoch nicht mehr das außergewöhnliche Tempo der letzten Jahre.
Die Herausforderung des Tokenverbrauchs im Zusammenhang mit Schlussfolgerungen wird architektonische Innovationen vorantreiben. Modelle, die starke Schlussfolgerungen bei geringerem Token-Overhead ermöglichen, werden Marktanteile gewinnen. Es ist mit weiterer Forschung an effizienten Schlussfolgerungsmechanismen zu rechnen.
Der Wettbewerb bleibt hart. DeepSeeks Markteintritt hat die Preisgestaltung im gesamten Markt durcheinandergebracht und etablierte Anbieter gezwungen, ihre Preise zu senken oder sich auf andere Weise zu differenzieren. Weitere Umwälzungen sind wahrscheinlich von unerwarteten Seiten zu erwarten – von Startups mit neuartigen Architekturen oder regionalen Anbietern mit anderen Wirtschaftsstrukturen.
Aufbau einer nachhaltigen KI-Ökonomie
Organisationen, die auf LLMs aufbauen, benötigen Strategien, die unabhängig von spezifischen Preisschwankungen funktionieren. Mehrere Prinzipien ermöglichen nachhaltiges Wirtschaften.
- Erstens: Architektur für flexible Modelle. Vermeiden Sie fest codierte Abhängigkeiten von bestimmten Anbietern oder Modellen. Abstrakte Inferenz sollte hinter Schnittstellen implementiert werden, die den Austausch von Anbietern bei sich ändernden wirtschaftlichen Bedingungen ermöglichen.
- Zweitens: Erfassen Sie alle relevanten Daten. Messen Sie den Tokenverbrauch, die Kosten pro Anfrage und die Kosten pro Geschäftsergebnis. Viele Organisationen stellen fest, dass 201 Tsd. Anwendungsfälle 801 Tsd. Kosten verursachen – und einige kostenintensive Anwendungsfälle nur minimalen Nutzen bringen.
- Drittens: Investieren Sie in Optimierung. Die zuvor besprochenen Techniken – Quantisierung, Caching, Routing und Prompt-Optimierung – wirken sich mit der Zeit kumulative Effekte aus. Eine Verdopplung der Kosten erscheint zunächst gering, bis man erkennt, dass dies eine monatliche Kostenreduzierung von 501 TP3T bedeutet.
- Viertens: Passen Sie die Modellleistung an die Aufgabenanforderungen an. Der Einsatz von Spitzenmodellen für jede Aufgabe ist ineffizient. Die Entwicklung einer Klassifizierungslogik, die Anfragen korrekt weiterleitet, zahlt sich aus.
- Planen Sie abschließend die Transparenz des Tokenverbrauchs ein. Das Problem der Token-Berechnung trifft Teams oft unvorbereitet, wenn sie den internen Tokenverbrauch nicht überwachen. Anbieter stellen zunehmend Telemetriedaten zur Verfügung, die die versteckte Token-Nutzung aufzeigen – nutzen Sie diese.
Häufig gestellte Fragen
Wie hoch sind die LLM-Inferenzkosten pro Anfrage?
Die Kosten für LLM-Inferenz variieren stark in Abhängigkeit von der Modellgröße und der Komplexität der Anfrage. Einfache Anfragen an kleine Modelle (3–7 Milliarden Parameter) kosten Bruchteile eines Cents – etwa $0,01–0,05 pro 1.000 Anfragen. Mittlere Modelle (13–70 Milliarden Parameter) kosten $0,10–0,80 pro 1.000 Anfragen. Große Grenzmodelle (über 175 Milliarden Parameter) kosten $2–15 pro 1.000 Anfragen. Allerdings können Reasoning-Modelle 50- bis 100-mal mehr Token verbrauchen, als die Ausgabelänge vermuten lässt, was die tatsächlichen Kosten erheblich erhöht.
Ist Selbsthosting günstiger als die Nutzung von API-Diensten?
Selbsthosting ist günstiger als APIs, wenn die GPU-Auslastung konstant etwa 501 TP3T übersteigt. Dies erfordert typischerweise die Verarbeitung von mehr als 10 Millionen Token pro GPU und Tag. Unterhalb dieser Schwelle sind APIs in der Regel wirtschaftlicher, da Investitionskosten vermieden und keine ungenutzten Kapazitäten bezahlt werden. Selbsthosting erfordert zudem Expertise im Bereich Machine Learning und einen erheblichen Aufwand für das Infrastrukturmanagement.
Warum sind Schlussfolgerungsmodelle so teuer?
Schlussfolgerungsmodelle erzeugen vor der Ausgabe einer Antwort umfangreiche interne “Denk”-Token. Eine Antwort mit 200 sichtbaren Token kann während der Schlussfolgerung insgesamt 10.000 bis 30.000 Token verbrauchen. Dieser interne Tokenverbrauch wird zwar abgerechnet, bleibt aber in der Ausgabe unsichtbar. Dadurch entstehen Situationen, in denen der Preis pro Token niedrig erscheint, die Gesamtkosten jedoch hoch sind. Manche Schlussfolgerungsanfragen verbrauchen über 600 Token, um eine Zwei-Wort-Antwort zu generieren.
Wie kann ich die Inferenzkosten von LLM reduzieren?
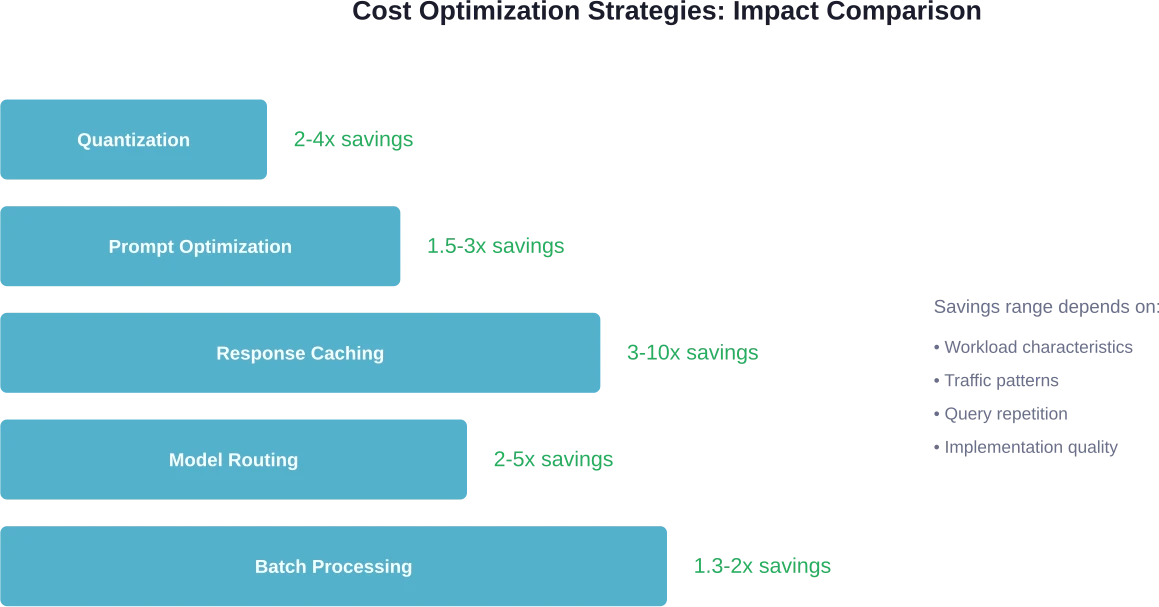
Fünf primäre Strategien reduzieren die Inferenzkosten: Quantisierung (2- bis 4-fache Kostenersparnis), Antwort-Caching für wiederholte Anfragen (3- bis 10-fache Kostenersparnis), Optimierung der Abfrageergebnisse zur Reduzierung des Tokenverbrauchs (1,5- bis 3-fache Kostenersparnis), Modell-Routing zur Verwendung kleinerer Modelle für einfache Aufgaben (2- bis 5-fache Kostenersparnis) und Batch-Verarbeitung für durchsatzorientierte Workloads (1,3- bis 2-fache Kostenersparnis). Diese Techniken verstärken sich gegenseitig, wenn sie effektiv kombiniert werden.
Was kostet derzeit eine Leistung auf GPT-4-Niveau?
Ab März 2026 kostet die Erreichung der Leistungsfähigkeit von GPT-4 mit vergleichbaren Alternativen wie DeepSeek V3 oder Modellen der Mittelklasse großer Anbieter etwa $0,40–0,80 pro Million Token. OpenAIs GPT-4 kostet je nach Variante $2–15 pro Million Token. Dies entspricht einer massiven Deflation gegenüber Ende 2022, als eine gleichwertige Leistung noch über $20 pro Million Token kostete.
Wie vergleichen sich die Kosten für Cloud-GPUs bei verschiedenen Anbietern?
Die Preise für Cloud-H100-GPUs haben sich Anfang 2026 bei den großen Anbietern bei 2,85–3,50 £ pro Stunde stabilisiert. Regionale Cloud-Anbieter bieten mitunter niedrigere Preise (2,20–2,60 £ pro Stunde) mit reduzierten SLAs an. A800-Karten, die in bestimmten Regionen verbreitet sind, kosten aufgrund der Infrastrukturkosten etwa 0,79 £ pro Stunde. Multi-GPU-Konfigurationen bieten typischerweise Mengenrabatte von 10–201 £ pro Stunde.
Werden die Kosten für LLM-Studiengänge weiter sinken?
Die Inferenzkosten werden voraussichtlich weiter sinken, jedoch langsamer als die jährlichen Reduzierungen um den Faktor 10 im Zeitraum 2021–2025. Realistisch betrachtet, sind jährliche Reduzierungen um den Faktor 3–5 bis 2027 zu erwarten, die sich anschließend auf den Faktor 1,5–2 abschwächen, da Optimierungsmöglichkeiten immer seltener werden. Hardwareverbesserungen und architektonische Innovationen werden die Kostensenkung weiter vorantreiben, doch das außergewöhnliche Tempo der letzten Jahre dürfte nicht unbegrenzt anhalten.
Strategische Erkenntnisse für KI-gestützte Anwendungen
Das Verständnis der Ökonomie von LLM-Inferenzsystemen ist heute wichtiger denn je. Die Differenz zwischen naiver Implementierung und optimiertem Einsatz kann Kostenunterschiede um das 5- bis 10-Fache ausmachen – genug, um zu entscheiden, ob sich die Stückkosten überhaupt lohnen.
Die Tokenpreisgestaltung liefert nur einen Teil der Wahrheit. Der gesamte Tokenverbrauch, einschließlich der Token für versteckte Berechnungen, bestimmt die tatsächlichen Kosten. Die Überwachung und Kontrolle dieses Verbrauchs ist für einen nachhaltigen Betrieb unerlässlich.
Die Wahl zwischen API-Diensten und Selbsthosting hängt von Umfang, Nutzungsmustern und den Möglichkeiten Ihres Unternehmens ab. Keine der beiden Optionen ist generell überlegen. Analysieren Sie Ihre spezifische Situation, anstatt blind Branchentrends zu folgen.
Optimierungstechniken wirken synergistisch. Quantisierung, Caching, Prompt Engineering und Modellrouting können gemeinsam die Kosten im Vergleich zu Standardimplementierungen um das Zehnfache oder mehr senken. Investitionen in diese Optimierungen zahlen sich nachhaltig aus.
Der Markt entwickelt sich weiterhin rasant. Regelmäßig entstehen neue Anbieter, Modelle und Preisstrukturen. Der Aufbau flexibler Architekturen, die sich an veränderte wirtschaftliche Gegebenheiten anpassen können, schützt sowohl vor Kosteninflation als auch vor verpassten Chancen durch bessere Alternativen.
Mal ehrlich: Die Kosten für LLM-Inferenz sind drastisch gesunken, aber das heißt nicht, dass KI-Infrastruktur billig ist. Es bedeutet, dass sich die Wirtschaftlichkeit von “unerschwinglich teuer” zu “mit sorgfältiger Optimierung tragbar” verschoben hat. Teams, die diese wirtschaftlichen Zusammenhänge verstehen und ihre Architektur entsprechend gestalten, werden nachhaltige KI-Unternehmen aufbauen. Wer Inferenz als Ware betrachtet, ohne die zugrunde liegenden Kostentreiber zu verstehen, wird Schwierigkeiten haben.
Bereit, Ihre LLM-Inferenzkosten zu optimieren? Beginnen Sie mit der Analyse Ihres aktuellen Tokenverbrauchs, einschließlich aller versteckten Reasoning-Token. Identifizieren Sie Ihre kostenintensivsten Anwendungsfälle und prüfen Sie, ob Modellrouting oder Prompt-Optimierung die Kosten senken könnten. Vergleichen Sie Ihr aktuelles Volumen mit der Gewinnschwelle für Self-Hosting, um festzustellen, ob sich der Besitz einer eigenen Infrastruktur lohnt. Die gewonnenen Erkenntnisse wirken sich direkt auf Ihr Geschäftsergebnis aus.