Kurzzusammenfassung: Ideen für KI-Projekte reichen von einfachen Chatbots und Bildklassifikatoren bis hin zu komplexen Empfehlungssystemen, Betrugserkennungssystemen und generativen KI-Anwendungen. Der globale KI-Markt, der 2024 einen Wert von 1,4 Billionen US-Dollar erreichte, wird Prognosen zufolge bis 2032 auf 1,4 Billionen US-Dollar anwachsen. Dies führt zu einer beispiellosen Nachfrage nach praktischen KI-Kenntnissen. Die Entwicklung praktischer KI-Projekte – von Stimmungsanalysen bis hin zu medizinischen Diagnosetools – ist nach wie vor der effektivste Weg, maschinelles Lernen, Deep Learning und neuronale Netze zu beherrschen und gleichzeitig ein Portfolio aufzubauen, das die Fähigkeit zur Lösung realer Probleme demonstriert.
Die Landschaft der künstlichen Intelligenz hat sich dramatisch verändert. Tutorials zu lesen reicht nicht mehr aus – Personalverantwortliche und Recruiter wollen sehen, was Sie tatsächlich entwickelt haben.
Mal ehrlich: Der Unterschied zwischen jemandem, der eine Stelle im Bereich KI ergattert, und jemandem, der keine bekommt, liegt oft an den Projektarbeiten im Portfolio. Nicht an theoretischem Wissen. Nicht an Zertifizierungen allein. Sondern an realen, funktionierenden Systemen, die echte Probleme lösen.
Dieser Leitfaden stellt über 50 KI-Projektideen verschiedener Schwierigkeitsgrade vor. Egal, ob Sie Ihr erstes Python-Skript schreiben oder Transformer-Modelle optimieren möchten – Sie finden Projekte, die zu Ihren aktuellen Fähigkeiten passen und Sie weiterbringen.
Warum KI-Projekte im Jahr 2026 wichtiger denn je sind
Die Zahlen sprechen für sich. Laut einer Studie, die das Förderportfolio der National Institutes of Health analysiert, erhalten KI-Projekte im Vergleich zu Projekten ohne KI-Schwerpunkt eine messbare Mehrförderung von 13,41 Billionen US-Dollar. Das ist nicht nur eine akademische Erkenntnis – es spiegelt wider, wie Organisationen branchenübergreifend nachgewiesene KI-Kompetenz bewerten.
Der globale KI-Markt erreichte 2024 ein Volumen von 233,46 Milliarden US-Dollar und wird Prognosen zufolge bis 2032 auf 1.771,62 Milliarden US-Dollar anwachsen, was einer durchschnittlichen jährlichen Wachstumsrate von 29,20 Billionen US-Dollar entspricht. Unternehmen experimentieren nicht mehr nur mit KI – sie setzen sie in großem Umfang ein.
Doch für Entwickler und Studierende ist Folgendes entscheidend: 791.000 KI-Projekte befinden sich noch in der Forschungs- und Entwicklungsphase, während nur 14.710 KI-Projekte den klinischen Einsatz oder die Implementierung erreichen. Diese Lücke birgt großes Potenzial. Unternehmen benötigen Fachkräfte, die Modelle vom Laptop in die Produktion überführen können.
Die Entwicklung von Projekten zwingt einen, sich mit der komplexen Realität der KI-Entwicklung auseinanderzusetzen. Daten sind nie perfekt bereinigt. Modelle konvergieren nicht auf Anhieb. Produktionsumgebungen unterliegen Einschränkungen, die in Jupyter-Notebooks nicht auftreten.
Genau deshalb funktionieren Projekte. Sie konfrontieren einen mit den Problemen, die man später im Berufsleben tatsächlich lösen wird.

Testen Sie KI-Projektideen mit AI Superior
AI Superior Das Unternehmen entwickelt maßgeschneiderte KI-Software, darunter Modelle für maschinelles Lernen, KI-basierte Anwendungen, Web- und Mobil-Apps sowie individuelle Softwareprodukte. Das Team unterstützt Projekte von der Bedarfsanalyse und Datenprüfung bis hin zur Entwicklung von Proof-of-Concepts (PoCs) oder Minimum Viable Products (MVPs), der Integration und der Ergebnisevaluierung.
Benötigen Sie Hilfe beim Aufbau eines KI-Projekts?
AI Superior kann Ihnen helfen bei:
- Bewertung von KI-Projektideen
- Entwicklung kundenspezifischer KI- und ML-Tools
- Konzepte durch PoC- oder MVP-Arbeit testen
- Integration von KI in bestehende Systeme
👉 Kontaktieren Sie AI Superior um Ihr Projekt zu besprechen.
KI-Projektideen für Anfänger: Legen Sie den Grundstein
Es kommt darauf an, mit den Grundlagen zu beginnen. Diese Projekte führen in Kernkonzepte ein – überwachtes Lernen, Klassifizierung, Regression, grundlegende neuronale Netze – ohne dabei zu komplex zu wirken.
1. E-Mail-Spam-Erkennungssystem
Entwickeln Sie einen Klassifikator, der mithilfe von natürlicher Sprachverarbeitung Spam von legitimen E-Mails trennt. Dieses Projekt behandelt die Textvorverarbeitung, die Merkmalsextraktion mit TF-IDF oder Wortvektoren sowie die binäre Klassifizierung mit Algorithmen wie Naive Bayes oder logistischer Regression.
Der Datensatz ist frei verfügbar (SpamAssassin Public Corpus), und das Problem ist klar definiert. Sie lernen, wie Sie mit unausgewogenen Datensätzen umgehen – Spam stellt typischerweise eine Minderheitsklasse dar – und die Leistung anhand von Präzision, Trefferquote und F1-Score anstatt nur der Genauigkeit messen.
2. Handschrifterkennung
Trainieren Sie ein neuronales Netzwerk zur Erkennung von Ziffern aus dem MNIST-Datensatz. Dieses klassische Projekt führt in die Welt der Convolutional Neural Networks (CNNs), die Bildvorverarbeitung und die Grundlagen von Deep-Learning-Frameworks wie TensorFlow oder PyTorch ein.
Obwohl es sich um ein typisches Anfängerprojekt handelt, vermittelt es wichtige Konzepte: wie Faltungsschichten Merkmale extrahieren, wie Pooling-Schichten die Dimensionalität reduzieren und wie man Overfitting durch Dropout und Datenaugmentation verhindern kann.
3. Hauspreisprognosemodell
Prognostizieren Sie Immobilienpreise anhand von Merkmalen wie Wohnfläche, Lage, Anzahl der Schlafzimmer und Alter. Dieses Regressionsprojekt vermittelt Kenntnisse in Feature Engineering, dem Umgang mit kategorialen Variablen und der Bewertung der Modellleistung mithilfe von Kennzahlen wie dem mittleren absoluten Fehler und dem Bestimmtheitsmaß (R²).
Nutzen Sie den Kaggle-Datensatz zu Immobilienpreisen oder sammeln Sie lokale Immobiliendaten. Sie lernen, wie Sie Ausreißer identifizieren und behandeln, Merkmale normalisieren und verschiedene Algorithmen – lineare Regression, Entscheidungsbäume, Random Forests – für dasselbe Problem vergleichen.
4. Filmempfehlungssystem
Entwickeln Sie ein System, das mithilfe von kollaborativem Filtern Filme basierend auf den Nutzerpräferenzen vorschlägt. Beginnen Sie mit einem einfachen Ansatz: Empfehlen Sie Filme, die ähnlichen Nutzern gefallen haben.
Der MovieLens-Datensatz enthält Bewertungen von Tausenden von Nutzern. Dieses Projekt führt in die Matrixfaktorisierung, Ähnlichkeitsmetriken (Kosinusähnlichkeit, Pearson-Korrelation) und das Kaltstartproblem ein – was empfiehlt man neuen Nutzern ohne bisherige Nutzungshistorie?
5. Stimmungsanalyse-Tool
Entwickeln Sie einen Klassifikator, der erkennt, ob Produktrezensionen, Tweets oder Kommentare eine positive, negative oder neutrale Stimmung ausdrücken. Nutzen Sie vortrainierte Modelle wie VADER für einen schnellen Einstieg und trainieren Sie anschließend Ihr eigenes Modell mit domänenspezifischen Daten.
Dieses Projekt vermittelt den Unterschied zwischen regelbasierten Ansätzen und maschinellem Lernen, wie der Kontext die Stimmung beeinflusst (“nicht schlecht” vs. “nicht gut”) und wie man mit Sarkasmus und Negation in Texten umgeht.
6. Wettervorhersagesystem
Mithilfe historischer Daten lassen sich Temperatur, Niederschlag und Wetterbedingungen vorhersagen. Dieses Zeitreihenprojekt führt in Konzepte wie Saisonalität, Trendanalyse und zeitliche Abhängigkeiten ein.
Beginnen Sie mit einfachen gleitenden Durchschnitten und gehen Sie dann zu ARIMA-Modellen oder rekurrenten neuronalen Netzen (RNNs) über. Sie lernen, wie Sie mit fehlenden Daten umgehen, verzögerte Merkmale erstellen und Prognosen anhand von zeitreihenspezifischen Metriken bewerten.
| Projekt | Primärtechnik | Wichtigste Erkenntnisse | Typische Dauer |
|---|---|---|---|
| Spam-Erkennung | Textklassifizierung | Grundlagen der NLP, unausgewogene Daten | 1-2 Wochen |
| Ziffernerkennung | CNN | Grundlagen des Deep Learning | 1-2 Wochen |
| Hauspreisprognose | Regression | Feature-Engineering | 1-2 Wochen |
| Filmempfehlungs-App | Kollaboratives Filtern | Ähnlichkeitsmetriken | 2-3 Wochen |
| Stimmungsanalyse | Textklassifizierung | NLP, vortrainierte Modelle | 1-2 Wochen |
| Wettervorhersage | Zeitreihen | Zeitliche Muster | 2-3 Wochen |
Projektideen für fortgeschrittene KI-Projekte
Sobald die Grundlagen sitzen, kommen bei fortgeschrittenen Projekten zusätzliche Komplexitäten hinzu – mehrere Datenquellen, anspruchsvollere Architekturen, Überlegungen zur Bereitstellung.
7. Erkennung von Kreditkartenbetrug
Identifizierung betrügerischer Transaktionen in stark unausgewogenen Datensätzen, in denen Betrug weniger als 11.300 Fälle ausmacht. Dieses Projekt erfordert Techniken wie SMOTE zur Behandlung von Klassenungleichgewichten, Algorithmen zur Anomalieerkennung und eine sorgfältige Schwellenwertanpassung, um ein Gleichgewicht zwischen falsch positiven und falsch negativen Ergebnissen zu erzielen.
Nutzen Sie den Kaggle-Datensatz zu Kreditkartenbetrug. Sie erfahren, warum Genauigkeit bei unausgewogenen Problemen eine irreführende Kennzahl ist und wie Präzisions-Recall-Kurven die Schwellenwertauswahl in Produktionssystemen steuern.
8. Chatbot mit natürlicher Sprachverarbeitung
Entwickeln Sie einen Dialogagenten, der die Absicht des Nutzers versteht und relevante Antworten liefert. Beginnen Sie mit regelbasierten Mustern und fügen Sie anschließend die Absichtsklassifizierung und Entitätsextraktion mithilfe von Bibliotheken wie spaCy oder Rasa hinzu.
Dieses Projekt führt Dialogmanagement, Kontextverfolgung über Gesprächsrunden hinweg und die Herausforderung der Bearbeitung mehrdeutiger oder themenfremder Anfragen ein. Die Integration einer Wissensdatenbank oder API zur Bereitstellung dynamischer Antworten wird empfohlen.
9. Gesichtserkennungssystem
Gesichter in Bildern oder Videostreams erkennen und identifizieren. Vortrainierte Modelle wie FaceNet verwenden oder eigene Modelle mit CNNs und Triplet-Loss zum Lernen von Gesichtseinbettungen erstellen.
Dieses Projekt vermittelt Transferlernen, One-Shot- und Few-Shot-Learning (Personenerkennung anhand weniger Beispiele) sowie die Einschränkungen der Echtzeitverarbeitung. Sie lernen, mit Variationen in Beleuchtung, Pose und Bildqualität umzugehen.
10. Aktienkursprognosetool
Prognose von Aktienkursen oder Markttrends mithilfe historischer Daten, technischer Indikatoren und gegebenenfalls externer Signale wie der Nachrichtenstimmung. Dieses Projekt verdeutlicht sowohl die Grenzen als auch die Möglichkeiten der KI – Märkte sind bekanntermaßen schwer vorherzusagen.
Nutzen Sie APIs wie Alpha Vantage oder Yahoo Finance für Daten. Experimentieren Sie mit LSTM-Netzwerken für die Sequenzmodellierung und lernen Sie, warum Backtesting mit historischen Daten keine Garantie für zukünftige Ergebnisse bietet.
11. Medizinischer Diagnoseassistent
Entwickeln Sie ein System, das Krankheiten oder Beschwerden anhand von Symptomen, medizinischen Bildern oder Laborergebnissen vorhersagt. Nutzen Sie Datensätze wie den Herzkrankheiten-Datensatz oder Röntgenbilder des Brustkorbs zur Erkennung von Lungenentzündung.
Dieses Projekt wirft ethische Fragen auf – medizinische KI muss der Minimierung falsch negativer Ergebnisse höchste Priorität einräumen – und unterstreicht die Bedeutung der Modellinterpretierbarkeit. Fachkräfte im Gesundheitswesen müssen verstehen, warum ein Modell eine bestimmte Vorhersage getroffen hat.
12. Kundenabwanderungsprognose
Identifizieren Sie Kunden, die voraussichtlich Abonnements kündigen oder einen Dienst nicht mehr nutzen werden. Dieses Klassifizierungsproblem tritt branchenübergreifend auf – Telekommunikation, SaaS, Bankwesen – und hat direkte Auswirkungen auf Unternehmenskennzahlen.
Feature Engineering ist hier entscheidend: Nutzungsmuster, Häufigkeit von Supportanfragen, Zahlungshistorie und Engagement-Kennzahlen liefern wichtige Hinweise. Sie lernen, wie Sie Modellvorhersagen in konkrete Kundenbindungsstrategien umsetzen.
13. Inhaltsbasiertes Bildabrufsystem
Entwickeln Sie ein System, das visuell ähnliche Bilder in einer Datenbank findet. Benutzer laden ein Bild hoch, und Ihr System liefert die ähnlichsten Treffer basierend auf visuellen Merkmalen anstatt auf Text-Tags.
Nutzen Sie vortrainierte CNNs wie ResNet oder VGG als Merkmalsextraktoren und berechnen Sie anschließend die Ähnlichkeit mit der Kosinusdistanz im Einbettungsraum. Dieses Projekt führt Dimensionsreduktionsverfahren wie die Hauptkomponentenanalyse (PCA) und eine effiziente Nächste-Nachbarn-Suche mit Bibliotheken wie FAISS ein.
Fortgeschrittene KI-Projekte für erfahrene Entwickler
Fortgeschrittene Projekte befassen sich mit offenen Problemen, erfordern architektonische Entscheidungen und kombinieren oft mehrere KI-Techniken.
14. Autonomes Navigationssystem
Entwickeln Sie einen Agenten, der mithilfe von Reinforcement Learning durch Umgebungen navigiert. Beginnen Sie mit simulierten Umgebungen wie OpenAI Gym und gehen Sie dann zu komplexeren Szenarien mit Hindernissen, mehreren Agenten oder kontinuierlichen Aktionsräumen über.
Dieses Projekt führt in Q-Learning, Policy Gradients und Actor-Critic-Methoden ein. Sie lernen, den Exploration-Exploitation-Kompromisse zu bewältigen und Belohnungsfunktionen zu entwerfen, die erwünschtes Verhalten ohne unbeabsichtigte Folgen fördern.
15. Neuronales maschinelles Übersetzungssystem
Entwickeln Sie ein Modell, das Texte zwischen Sprachen mithilfe von Sequenz-zu-Sequenz-Architekturen mit Aufmerksamkeitsmechanismen übersetzt. Verwenden Sie parallele Korpora aus Quellen wie Europarl oder dem Tatoeba-Datensatz.
Dieses Projekt vermittelt Encoder-Decoder-Architekturen, Aufmerksamkeitsmechanismen, die es Modellen ermöglichen, sich auf relevante Eingabe-Token zu konzentrieren, und Bewertungsmetriken wie BLEU-Scores. Erwägen Sie das Feinabstimmen vortrainierter Modelle wie mBART oder T5, um mit begrenzten Daten bessere Ergebnisse zu erzielen.
16. Generativer KI-Kunstgenerator
Erstellen Sie originelle Bilder mithilfe generativer adversarieller Netzwerke (GANs) oder Diffusionsmodellen. Trainieren Sie diese in spezifischen Bereichen – Porträts, Landschaften, abstrakte Kunst –, um neuartige Ergebnisse in diesem Stil zu generieren.
Dieses Projekt stellt das adversarielle Training vor, bei dem ein Generator und ein Diskriminator miteinander konkurrieren, Probleme des Modenkollapses, bei denen Generatoren nur eine begrenzte Vielfalt erzeugen, sowie Techniken wie progressives Wachstum für hochauflösende Ausgaben.
17. Echtzeit-Objekterkennung für Videos
Mehrere Objekte in Videostreams mithilfe von Modellen wie YOLO oder Faster R-CNN erkennen und verfolgen. Optimiert für Echtzeitleistung – 25+ Bilder pro Sekunde – auf handelsüblicher Hardware.
Sie müssen Genauigkeit und Geschwindigkeit in Einklang bringen, überlappende Objekte mit nicht-maximaler Unterdrückung verarbeiten und Objekte über mehrere Frames hinweg verfolgen. Erwägen Sie den Einsatz auf Edge-Geräten mithilfe von Modellquantisierung und -beschneidung.
18. Frage-Antwort-System
Entwickeln Sie ein System, das Fragen beantwortet, indem es Informationen aus Dokumenten oder Wissensdatenbanken extrahiert. Verwenden Sie vortrainierte Transformer wie BERT, die auf den Datensätzen SQuAD oder Natural Questions feinabgestimmt wurden.
Dieses Projekt vermittelt Leseverständnismodelle, Strategien zum Abruf von Textpassagen bei der Arbeit mit großen Dokumentensammlungen sowie hybride Ansätze, die Information Retrieval mit Deep Learning kombinieren.
19. Sprachassistent mit Aktivierungsworterkennung
Entwickeln Sie einen sprachgesteuerten Assistenten, der auf ein Aktivierungswort reagiert, Sprache transkribiert, Befehle verarbeitet und antwortet. Kombinieren Sie Spracherkennung (mit Modellen wie Wav2Vec oder Whisper), Absichtsklassifizierung und Text-zu-Sprache-Synthese.
Dieses umfassende Projekt integriert mehrere KI-Komponenten in eine einzige Pipeline. Sie sind verantwortlich für die Echtzeit-Audioverarbeitung, die Unterdrückung von Hintergrundgeräuschen und die Bearbeitung verschiedener Akzente oder Sprechstile.
20. KI-Code-Review-Assistent
Entwickeln Sie ein Tool, das mithilfe von maschinellem Lernen Code auf Fehler, Stilverstöße oder Sicherheitsprobleme analysiert. Trainieren Sie es mit Datensätzen von Codeänderungen in Verbindung mit Kommentaren von Reviewern oder optimieren Sie codespezifische Modelle wie CodeBERT.
Dieses Projekt wendet NLP-Techniken auf einen strukturierten Bereich (Programmiersprachen) an, vermittelt die Analyse abstrakter Syntaxbäume (AST) und demonstriert, wie KI menschliches Fachwissen ergänzen, anstatt es zu ersetzen.
Domänenspezifische KI-Projektideen
Die Spezialisierung auf einen Bereich – Gesundheitswesen, Finanzen, Einzelhandel – differenziert die Portfolios und richtet sich nach den Karrierezielen.
KI-Projekte im Gesundheitswesen
Medizinische Bildklassifizierung (Erkennung von Tumoren in MRT-Scans), Vorhersage von Arzneimittelwechselwirkungen, Prognose von Patientenwiederaufnahmen und Analyse elektronischer Gesundheitsakten – all dies sind Themen, die sich mit realen Herausforderungen im Gesundheitswesen befassen.
Diese Projekte erfordern die Beachtung regulatorischer Standards, des Patientendatenschutzes (HIPAA-Konformität) und der Folgen von Fehlern. Laut einer Analyse der NIH entfallen 50,11 TP3T aller KI-Fördermittel auf Krebs, Altern und psychische Gesundheit, während die Forschung zu gesundheitlichen Ungleichheiten mit nur 5,71 TP3T stark unterrepräsentiert ist – eine Lücke, die sowohl ethische Bedenken als auch Chancen birgt.
Finanzielle KI-Projekte
Algorithmische Handelssysteme, die Vorhersage von Kreditausfällen, die Aufdeckung von Versicherungsbetrug und die Portfoliooptimierung verdeutlichen den geschäftlichen Nutzen von KI. Finanzprojekte weisen oft klare Erfolgskennzahlen auf – Kapitalrendite, Fehlalarmrate, Bearbeitungszeit –, die für Arbeitgeber relevant sind.
Aber sie bringen auch Herausforderungen mit sich: Märkte sind antagonistisch (andere Algorithmen reagieren auf Ihren Algorithmus), Vorschriften schränken ein, welche Daten Sie verwenden können, und Backtesting-Ergebnisse garantieren keine Live-Performance.
Einzelhandels- und E-Commerce-Projekte
Produktempfehlungssysteme, dynamische Preisgestaltung, Bedarfsprognosen, visuelle Suche und die Vorhersage des Kundenlebenszeitwerts lösen Probleme, mit denen Einzelhändler täglich konfrontiert sind.
Diese Projekte arbeiten mit unterschiedlichsten Datentypen – Transaktionsdatensätzen, Produktkatalogen, Kundenverhaltensprotokollen, Bildern – und müssen auf Millionen von Benutzern und Produkten skalierbar sein.
Content- und Medienprojekte
Automatisierte Systeme zur Inhaltskennzeichnung, Videozusammenfassung, Deepfake-Erkennung, Identifizierung von Urheberrechtsverletzungen und Inhaltsmoderation begegnen Herausforderungen in den digitalen Medien.
Die Diskussionen in der Community verdeutlichen sowohl die technischen Herausforderungen (Umgang mit Adversarial Examples, Skalierung auf Millionen von Beiträgen) als auch die ethischen (Voreingenommenheit bei Moderationsentscheidungen, Transparenz bei automatisierten Löschungen).
Ideen für KI-Agenten- und Automatisierungsprojekte
Agentische KI – Systeme, die planen, argumentieren und autonom handeln – stellt einen bedeutenden Trend im Jahr 2026 dar. Das NIST kündigte im Februar 2026 die “AI Agent Standards Initiative” an, um Interoperabilität und Sicherheit bei der zunehmenden Verbreitung dieser Systeme zu gewährleisten.
21. Zusammenfassung von Forschungsarbeiten
Entwickeln Sie einen Agenten, der Artikel aus arXiv extrahiert, die wichtigsten Ergebnisse zusammenfasst und sie thematisch ordnet. Kombinieren Sie PDF-Parsing, extraktiver und abstraktiver Zusammenfassung sowie Topic Modeling.
22. Automatisierter Bewerbungsassistent
Entwickeln Sie ein System, das Stellenanzeigen durchsucht, passende Positionen mit Lebensläufen abgleicht und personalisierte Anschreiben generiert. Dieses Projekt kombiniert Web-Scraping, NLP zur Zuordnung von Qualifikationen zu Stellenbeschreibungen und Textgenerierung.
23. Finanznachrichtenanalysator
Entwickeln Sie einen Agenten, der Finanznachrichten überwacht, Unternehmenserwähnungen und Stimmungsanalysen extrahiert und Nachrichten mit Aktienkursbewegungen korreliert. Integrieren Sie APIs für Nachrichtenquellen, führen Sie eine Named-Entity-Erkennung durch und analysieren Sie Stimmungstrends.
24. Social-Media-Content-Planer
Entwickeln Sie ein Tool, das Social-Media-Beiträge generiert, die Veröffentlichungszeiten anhand von Interaktionsdaten optimiert und Inhalte automatisch veröffentlicht. Kombinieren Sie Textgenerierung, Zeitreihenanalyse von Interaktionsmustern und API-Integration.
25. Extraktor für Besprechungsnotizen und Aktionspunkte
Entwickeln Sie ein System, das Besprechungen transkribiert, Diskussionen zusammenfasst und Aufgaben mit Verantwortlichen und Fristen extrahiert. Nutzen Sie Spracherkennung, Zusammenfassungsmodelle und Techniken zur Informationsextraktion.
Innovative KI-Projektideen für 2026
Diese Projekte erforschen neue Techniken und Trends, die die Entwicklung von KI prägen.
26. Multimodales KI-System
Entwickeln Sie ein System, das Inhalte verschiedener Modalitäten – Text, Bilder, Audio – versteht und generiert. Beispielsweise ein Modell, das ein Produktbild und eine Beschreibung entgegennimmt und daraus ein Werbevideo mit Sprechertext erstellt.
Multimodale Modelle wie CLIP, Flamingo und GPT-4V demonstrieren, wie sich unterschiedliche Datentypen gegenseitig beeinflussen können. Dieses Projekt vermittelt intermodale Aufmerksamkeit, die Abstimmung zwischen Modalitäten und den Umgang mit Eingaben von stark unterschiedlichen Dimensionen.
27. Föderiertes Lernsystem
Implementieren Sie ein System, in dem mehrere Clients ein gemeinsames Modell trainieren, ohne ihre Rohdaten auszutauschen. Dieser datenschutzfreundliche Ansatz ist wichtig für das Gesundheitswesen, den Finanzsektor und alle Bereiche mit sensiblen Daten.
Sie lernen verteilte Optimierung, wie man Modellaktualisierungen aggregiert und Techniken für den Umgang mit nicht-IID-Daten (Clients haben unterschiedliche Datenverteilungen).
28. Few-Shot-Learning-Klassifikator
Entwickeln Sie ein Modell, das anhand weniger Beispiele neue Kategorien lernt – entscheidend bei wenigen gelabelten Daten. Nutzen Sie Meta-Learning-Ansätze wie MAML oder prototypische Netzwerke.
Dieses Projekt stellt Lern-zu-Lernen-Paradigmen vor, bei denen Modelle auf schnelle Anpassung optimiert sind, anstatt auf Leistung bei einer festgelegten Aufgabe.
29. Erklärbares KI-Dashboard
Entwickeln Sie ein System, das nicht nur Vorhersagen trifft, sondern seine Vorgehensweise mithilfe von Techniken wie SHAP-Werten, LIME oder Aufmerksamkeitsvisualisierung erläutert. Wenden Sie es in einem kritischen Bereich wie Kreditanträgen oder medizinischen Diagnosen an.
Gemäß den IEEE-Standards sind Transparenz und Erklärbarkeit grundlegend für ethische KI. Organisationen fordern zunehmend interpretierbare Modelle, insbesondere in regulierten Branchen.
30. Leistungsmonitor für KI-Modelle
Entwickeln Sie ein System, das die Modellleistung im Produktivbetrieb überwacht, Datenabweichungen erkennt und bei Bedarf ein erneutes Training auslöst. Dieses MLOps-Projekt verdeutlicht den Unterschied zwischen Entwicklung und Einsatz.
Modelle verschlechtern sich im Laufe der Zeit, da sich die Datenverteilungen verändern. Überwachungssysteme verfolgen die Vorhersagegenauigkeit, die Merkmalsverteilungen und die tatsächlichen Daten (sofern verfügbar), um zu erkennen, wann Modelle die Realität nicht mehr widerspiegeln.
Werkzeuge und Technologien für KI-Projekte
Die Auswahl des richtigen Technologie-Stacks beschleunigt die Entwicklung und vermittelt branchenübliche Werkzeuge.
Programmiersprachen
Python dominiert die KI-Entwicklung aus gutem Grund – umfangreiche Bibliotheken, lesbare Syntax und starke Community-Unterstützung. R eignet sich für statistische Modellierung und Datenanalyse. Julia gewinnt zunehmend an Bedeutung für numerische Berechnungen und leistungskritische Anwendungen.
Die Ergebnisse von Codegenerierungs-Benchmarks spiegeln rasante Fortschritte wider. Laut einer Analyse der Modellfähigkeiten erreichte die erste Version von Codex eine Genauigkeit von 28,81 TP3T auf HumanEval, während GPT-5 (Version nicht spezifiziert) im Jahr 2025 93,51 TP3T erzielte. Das Kimi-K2-Open-Weights-Modell übertraf es mit 94,51 TP3T.
Frameworks für maschinelles Lernen
TensorFlow und PyTorch sind führend im Bereich Deep Learning. Scikit-learn zeichnet sich durch seine Expertise in traditionellen Algorithmen des maschinellen Lernens aus. JAX bietet leistungsstarke numerische Berechnungen mit automatischer Differenzierung.
Die Wahl des Frameworks ist weniger wichtig als man vielleicht denkt – Arbeitgeber legen mehr Wert auf Problemlösungskompetenz und grundlegende Kenntnisse im Bereich Machine Learning als auf spezifische Bibliothekskenntnisse. Dennoch gewinnt PyTorch in der Forschung zunehmend an Bedeutung, während TensorFlow weiterhin leistungsstarke Tools für den produktiven Einsatz bietet.
Cloud-Plattformen und Computing
Google Cloud, AWS und Azure bieten alle KI/ML-Dienste an – vortrainierte Modelle, verwaltete Trainingsinfrastruktur und Bereitstellungsplattformen. Google Colab bietet kostenlosen GPU-Zugriff für Lern- und Prototyping-Zwecke.
Lokale Entwicklungsumgebungen eignen sich für kleinere Projekte. Größere Modelle und Datensätze erfordern Cloud-Ressourcen. Das Verständnis von Cloud-Plattformen ist für den Produktiveinsatz unerlässlich.
Datenwerkzeuge und Datenbanken
Pandas dient der Bearbeitung tabellarischer Daten. NumPy ermöglicht numerische Operationen. Für die verteilte Verarbeitung großer Datenmengen bieten Spark und Dask Lösungen.
Vektordatenbanken wie Pinecone, Weaviate und ChromaDB sind für Systeme zur Ähnlichkeitssuche und zur Erweiterung der Abruffunktionen unerlässlich geworden.
Bewährte Verfahren für die KI-Projektentwicklung
Erfolgreiche Projekte folgen Mustern, die funktionierende Prototypen von verworfenen Notizbüchern unterscheiden.
Beginnen Sie mit einer klaren Problemstellung
Definiere, wie Erfolg aussieht, bevor du mit dem Programmieren beginnst. Welches konkrete Problem löst das Programm? Welche Kennzahlen sind relevant? Wer würde das Programm nutzen?
Vage Ziele – ”etwas mit neuronalen Netzen entwickeln” – führen zu abgebrochenen Projekten. Spezifische Ziele – ”Kundensupport-Tickets mit einer Genauigkeit von 85% in fünf Kategorien einteilen” – geben die Richtung vor.
Versionskontrolle vom ersten Tag an nutzen
Git ist nicht nur für Softwareentwickler. Verfolgen Sie Ihren Code, Ihre Experimente und Modellversionen. Verwenden Sie Branches für Experimente. Schreiben Sie aussagekräftige Commit-Nachrichten, die erklären, was sich geändert hat und warum.
Tools wie DVC (Data Version Control) erweitern Git, um große Datensätze und Modelldateien zu verarbeiten.
Dokumentieren Sie Ihren Prozess
Führen Sie ein Projekttagebuch, in dem Sie Entscheidungen, Experimente und Ergebnisse festhalten. Zukünftige Arbeitgeber möchten Ihren Denkprozess verstehen und nicht nur das fertige Modell sehen.
Dokumentieren Sie auch Sackgassen. Zu erklären, warum ein Ansatz nicht funktioniert hat, zeugt genauso von Verständnis wie erfolgreiche Umsetzungen.
Fokus auf Datenqualität
Modelle lernen nur die in den Trainingsdaten vorhandenen Muster. „Müll rein, Müll raus“ gilt weiterhin, egal wie ausgefeilt die Architektur ist.
Investieren Sie Zeit in die explorative Datenanalyse. Verstehen Sie Verteilungen, identifizieren Sie Ausreißer und prüfen Sie auf Datenlecks (wenn Testdaten versehentlich in das Training einfließen). Die Datenarbeit ist zwar nicht glamourös, aber sie ist für den Projekterfolg entscheidender als die Wahl der Modellarchitektur.
Fang einfach an, dann iteriere.
Beginnen Sie mit dem einfachsten Ansatz, der funktionieren könnte – logistische Regression vor neuronalen Netzen, kleine Modelle vor großen. Legen Sie eine Basislinie fest und erhöhen Sie die Komplexität nur dann, wenn sich die Ergebnisse dadurch verbessern.
Einfache Modelle lassen sich schneller trainieren, leichter debuggen und erzielen oft überraschend gute Ergebnisse. Komplexe Modelle sind nur dann sinnvoll, wenn einfachere Ansätze versagen.
Berücksichtigen Sie die Bereitstellung von Anfang an
Wie soll das in der Praxis genutzt werden? Ein Notebook, das die manuelle Ausführung von Zellen erfordert, wird nicht bereitgestellt. Projekte sind über eine REST-API, eine Weboberfläche oder ein Kommandozeilentool zugänglich.
Die Bereitstellung legt Einschränkungen offen, die während der Entwicklung unsichtbar sind: Latenzanforderungen, Speichergrenzen, Abhängigkeitskonflikte, Fehlerbehandlung. Das sind keine nachträglichen Überlegungen – sie sind Kernbestandteile von produktiver KI.
Ethische Überlegungen in KI-Projekten
Die Steuerung von KI hat sich zu einem bedeutenden Wirtschaftszweig entwickelt. Laut einer Studie der IEEE Standards Association hat der Markt für KI-Governance ein Volumen von über 1,4 Billionen US-Dollar und wird in den nächsten fünf Jahren voraussichtlich um 35,71 Billionen US-Dollar wachsen.
Organisationen weltweit erkennen an, dass ethische KI keine Option ist – sie ist unerlässlich für Vertrauen, die Einhaltung gesetzlicher Bestimmungen und die langfristige Überlebensfähigkeit.
Voreingenommenheit und Fairness
Modelle übernehmen Verzerrungen aus den Trainingsdaten. Gesichtserkennungssysteme funktionieren für manche Bevölkerungsgruppen besser als für andere. Einstellungsalgorithmen bevorzugen bestimmte Hintergründe. Kreditwürdigkeitsbewertungen verfestigen historische Ungleichheiten.
Testen Sie die Modellleistung in verschiedenen demografischen Gruppen. Verwenden Sie neben der Gesamtgenauigkeit auch Fairness-Metriken. Prüfen Sie, ob Ihre Trainingsdaten die Population repräsentieren, für die Ihr Modell verwendet werden soll.
Datenschutz und Datensicherheit
Personenbezogene Daten erfordern einen sorgfältigen Umgang. Die DSGVO in Europa, der CCPA in Kalifornien und neue Datenschutzbestimmungen weltweit stellen strenge Anforderungen.
Datenerfassung minimieren – nur das Nötigste verwenden. Daten nach Möglichkeit anonymisieren. Aufbewahrungsfristen beachten. Für Projekte im Gesundheitswesen ist die Einhaltung der HIPAA-Richtlinien obligatorisch.
Transparenz und Erklärbarkeit
Entscheidungen mit weitreichenden Folgen – Kreditgenehmigungen, medizinische Diagnosen, Strafverfahren – erfordern eine Begründung. “Der Algorithmus hat es so entschieden” reicht nicht aus, wenn es um Menschenleben geht.
Die Arbeit des IEEE zu ethischen KI-Standards betont Transparenz und Erklärbarkeit als grundlegende Prinzipien. Projekte sollten Interpretierbarkeitsmethoden beinhalten, die den Beteiligten die Vorhersagen erläutern.
Sicherheit und Robustheit
Die im Dezember 2025 veröffentlichten Cybersicherheitsrichtlinien des NIST für KI-Systeme befassen sich mit neu auftretenden Bedrohungen – Adversarial Examples, Model Inversion Attacks und Data Poisoning.
Berücksichtigen Sie die Sicherheit während des gesamten Entwicklungsprozesses. Validieren Sie die Eingaben. Testen Sie die Robustheit gegenüber Angriffen. Implementieren Sie Überwachungsmechanismen, um Angriffe oder Modellbeeinträchtigungen zu erkennen.
| Ethische Bedenken | Projektauswirkungen | Minderungsstrategie |
|---|---|---|
| Voreingenommenheit und Fairness | Ungleiche Leistungen der verschiedenen Gruppen | Vielfältige Trainingsdaten, Fairness-Metriken, Bias-Tests |
| Datenschutz | Unberechtigte Datenoffenlegung | Datenminimierung, Anonymisierung, Compliance-Prüfungen |
| Transparenz | Unerklärliche Entscheidungen | Interpretierbarkeitswerkzeuge, Dokumentation, Prüfprotokolle |
| Sicherheit | Adversarial Attacks, Data Poisoning | Eingangsvalidierung, Robustheitstests, Überwachung |
| Umwelt | Energieverbrauch des Trainings | Effiziente Architekturen, kohlenstoffbewusstes Rechnen |
Aufbau Ihres KI-Portfolios
Projekte demonstrieren Leistungsfähigkeit, aber die Präsentation ist genauso wichtig wie die technische Umsetzung.
Projekte strategisch auswählen
Qualität schlägt Quantität. Drei gut durchgeführte und gut dokumentierte Projekte beeindrucken mehr als zehn halbfertige Notizbücher. Wählen Sie Projekte, die unterschiedliche Fähigkeiten demonstrieren – ein Klassifizierungsproblem, ein generatives Modell, eine durchgängige Anwendung.
Richten Sie Ihre Projekte an Ihren Karrierezielen aus. Streben Sie eine Karriere im Bereich KI im Gesundheitswesen an? Dann konzentrieren Sie sich auf Projekte im Bereich medizinische Bildgebung oder klinische Prognose. Interessieren Sie sich für NLP? Entwickeln Sie Dialogsysteme, Textgenerierungs- oder Informationsextraktionswerkzeuge.
Dokumentieren Sie gründlich
Jedes Projekt benötigt eine klare Dokumentation: Problemstellung, Vorgehensweise, Ergebnisse, gewonnene Erkenntnisse. Visualisierungen wie Lernkurven, Konfusionsmatrizen und Beispielausgaben sollten ebenfalls enthalten sein.
Schreiben Sie für jemanden, der mit dem Problem nicht vertraut ist. Erläutern Sie Ihre architektonischen Entscheidungen. Gehen Sie darauf ein, was nicht funktioniert hat und was Sie als Nächstes versuchen würden. Dies beweist kritisches Denken, nicht nur Programmierkenntnisse.
Projekte barrierefrei gestalten
Veröffentlichen Sie den Code auf GitHub mit ausführlichen README-Dateien. Fügen Sie Installationsanweisungen, Abhängigkeiten und Anwendungsbeispiele hinzu. Stellen Sie für Modelle vortrainierte Gewichte bereit, damit andere sie ohne erneutes Training testen können.
Setzen Sie Projekte nach Möglichkeit ein. Eine Live-Demo – selbst eine einfache Weboberfläche – zeigt Engagement, das über den Studieninhalt hinausgeht. Dienste wie Streamlit, Gradio oder Hugging Face Spaces erleichtern die Umsetzung.
Schreiben Sie über Ihre Arbeit
Blogbeiträge, Artikel oder technische Dokumentationen erhöhen die Wirkung des Projekts. Indem Sie anderen Ihre Arbeit erklären, vertiefen Sie Ihr eigenes Verständnis und bauen eine öffentliche Präsenz auf.
In Diskussionen innerhalb der Community wird immer wieder betont, dass Kandidaten, die ihre Lernprozesse dokumentieren und teilen, bei der Einstellung besonders hervorstechen.
Häufige Fallstricke, die es zu vermeiden gilt
Aus den Fehlern anderer zu lernen beschleunigt den Fortschritt.
Tutorial-Hölle
Das Durcharbeiten von Tutorials mag zwar produktiv erscheinen, vermittelt aber nur begrenzte Fähigkeiten. Wichtig ist die Herausforderung – Fehler beheben, Designentscheidungen treffen, unerwartete Probleme bewältigen.
Nutze Tutorials, um die Grundlagen zu erlernen, und wende die Konzepte anschließend direkt in deinen eigenen Projekten an. Modifiziere den Code aus den Tutorials. Kombiniere Techniken aus verschiedenen Quellen. Probiere aus, Dinge zu zerstören und sie anschließend zu reparieren.
Überkomplizierung früher Projekte
Ehrgeiz ist gut. Der Versuch, als erstes Projekt hochmoderne Forschungssysteme zu entwickeln, führt zu Frustration und schließlich zum Abbruch des Projekts.
Passen Sie die Projektkomplexität Ihrem aktuellen Kenntnisstand an. Erfolg motiviert. Drei Anfängerprojekte erfolgreich abzuschließen, stärkt das Selbstvertrauen mehr als ein fortgeschrittenes Projekt nur teilweise zu beenden.
Ignorieren der Datenqualität
Wer sich ausschließlich auf die Modellarchitektur konzentriert und dabei Datenprobleme vernachlässigt, führt zwangsläufig zu schlechten Ergebnissen. Fehlerhafte Daten lassen sich nicht durch bessere Modelle korrigieren.
Investieren Sie Zeit in die Datenbereinigung, -exploration und -validierung. Machen Sie sich mit den Grenzen Ihrer Daten vertraut. Dokumentieren Sie Annahmen und Entscheidungen zur Datenvorverarbeitung.
Nicht ordnungsgemäß getestet
Eine hohe Genauigkeit im Testdatensatz ist wertlos, wenn dieser keine realen Daten repräsentiert. Datenlecks – bei denen Informationen aus dem Testdatensatz das Training beeinflussen – erzeugen ein falsches Vertrauen.
Verwenden Sie eine geeignete Aufteilung in Trainings- und Testdaten. Testen Sie bei Zeitreihendaten mit zukünftigen Daten, nicht mit zufällig ausgewählten Punkten. Führen Sie Kreuzvalidierung durch, wenn die Datensätze klein sind. Hinterfragen Sie Ergebnisse, die zu gut erscheinen.
Vernachlässigung von Produktionsbelangen
Modelle, die in Notebooks funktionieren, aber im Produktivbetrieb versagen, sind nur bedingt nützlich. Berücksichtigen Sie Latenz, Speicherbedarf, Abhängigkeiten und Fehlerbehandlung von Anfang an.
Tests auf repräsentativer Hardware durchführen. Inferenzzeit messen. Grenzfälle berücksichtigen. Produktionsreifer Code ist Teil des Projekts, keine nachträgliche Überlegung.
Ressourcen für die KI-Projektentwicklung
Hochwertige Ressourcen beschleunigen das Lernen und liefern Inspiration für Projekte.
Datensätze
Kaggle hostet Tausende von Datensätzen aus verschiedenen Bereichen sowie Wettbewerbe mit strukturierten Aufgaben. Das UCI Machine Learning Repository bietet klassische Datensätze für Benchmarking. Hugging Face Datasets ermöglicht den einfachen Zugriff auf NLP- und multimodale Daten.
Regierungsdatenportale – data.gov, NIH-Datensätze, NASA-Datensätze – bieten reale Daten für Projekte zum Wohle der Allgemeinheit.
Vortrainierte Modelle
Hugging Face Model Hub bietet Tausende vortrainierte Modelle für NLP, Computer Vision und Audio. TensorFlow Hub und PyTorch Hub bieten ähnliche Ressourcen.
Transferlernen – also das Lernen mit vortrainierten Modellen und deren Feinabstimmung für spezifische Aufgaben – erzielt bessere Ergebnisse mit weniger Daten und Rechenaufwand als das Training von Grund auf.
Lernplattformen
Die Kurse von Fast.ai legen Wert auf die praktische Anwendung. Coursera und edX bieten Inhalte auf Universitätsniveau. YouTube-Kanäle wie StatQuest erklären Konzepte anschaulich.
Wissenschaftliche Artikel auf arXiv bieten Zugang zu hochaktueller Forschung. Das Lesen dieser Artikel fördert das Verständnis aktueller Techniken und Forschungsrichtungen.
Gemeinschaften
Reddit-Communities wie r/MachineLearning und r/learnmachinelearning bieten Unterstützung und Feedback. Stack Overflow hilft bei der Fehlersuche. Discord-Server und Slack-Communities ermöglichen Diskussionen in Echtzeit.
Die Interaktion mit Gemeinschaften – Fragen stellen, anderen helfen, Projekte teilen – beschleunigt das Lernen durch kollektives Wissen.
KI-Projektideen für verschiedene Ziele
Die Projektauswahl sollte auf spezifische Ziele zugeschnitten sein.
So sichern Sie sich Ihren ersten Job im Bereich KI
Konzentrieren Sie sich auf durchgängige Projekte, die praktische Fähigkeiten demonstrieren: Datenerfassung, Vorverarbeitung, Modelltraining, Evaluierung und Implementierung. Priorisieren Sie Probleme mit klarem Geschäftswert – Kundenabwanderungsprognosen, Empfehlungssysteme, Betrugserkennung.
Fügen Sie mindestens ein Projekt hinzu, das mit realen Problemen umgeht: fehlende Daten, Klassenungleichgewicht, fehlerhafte Beschriftungen.
Für akademische Forschung
Wählen Sie Problemstellungen, die das Fachgebiet voranbringen: neuartige Architekturen, neue Anwendungen bestehender Techniken oder umfassende empirische Vergleiche. Dokumentieren Sie die Methodik sorgfältig. Vergleichen Sie Ihre Ergebnisse mit etablierten Referenzwerten. Erwägen Sie eine Einreichung bei Konferenzen oder in Fachzeitschriften.
Für freiberufliche Tätigkeiten oder Beratungsleistungen
Entwickeln Sie Projekte, die gängige Geschäftsprobleme lösen: automatisierte Datenverarbeitung, prädiktive Analysen, natürliche Sprachverarbeitung für den Kundensupport. Weisen Sie den ROI nach – zeigen Sie, wie Ihre Lösung Zeit oder Geld spart.
Erstellen Sie professionelle Demos und eine verständliche Dokumentation, die auch Kunden ohne technische Vorkenntnisse verstehen können.
Für den Start eines KI-Produkts
Prüfen Sie, ob das Problem relevant ist, bevor Sie komplexe Lösungen entwickeln. Beginnen Sie mit minimalen funktionsfähigen Produkten. Konzentrieren Sie sich auf einen Anwendungsfall, ein Nutzersegment. Holen Sie frühzeitig und regelmäßig Feedback ein.
Viele erfolgreiche KI-Produkte begannen als persönliche Projekte, die ein reales Problem des Entwicklers lösten.
Häufig gestellte Fragen
Welche Programmiersprachen benötige ich für KI-Projekte?
Python ist aufgrund umfangreicher Bibliotheken wie TensorFlow, PyTorch, scikit-learn und pandas weiterhin die dominierende Sprache für KI-Projekte. R eignet sich gut für statistische Analysen und Data-Science-Projekte. Für Produktionssysteme mit hohen Leistungsanforderungen bieten Sprachen wie C++ oder Julia Geschwindigkeitsvorteile. Die meisten Anfänger sollten mit Python beginnen – es bietet die beste Balance zwischen Leistungsfähigkeit, Lernressourcen und Arbeitsmarktnachfrage. JavaScript-Frameworks wie TensorFlow.js ermöglichen bei Bedarf browserbasierte KI-Anwendungen.
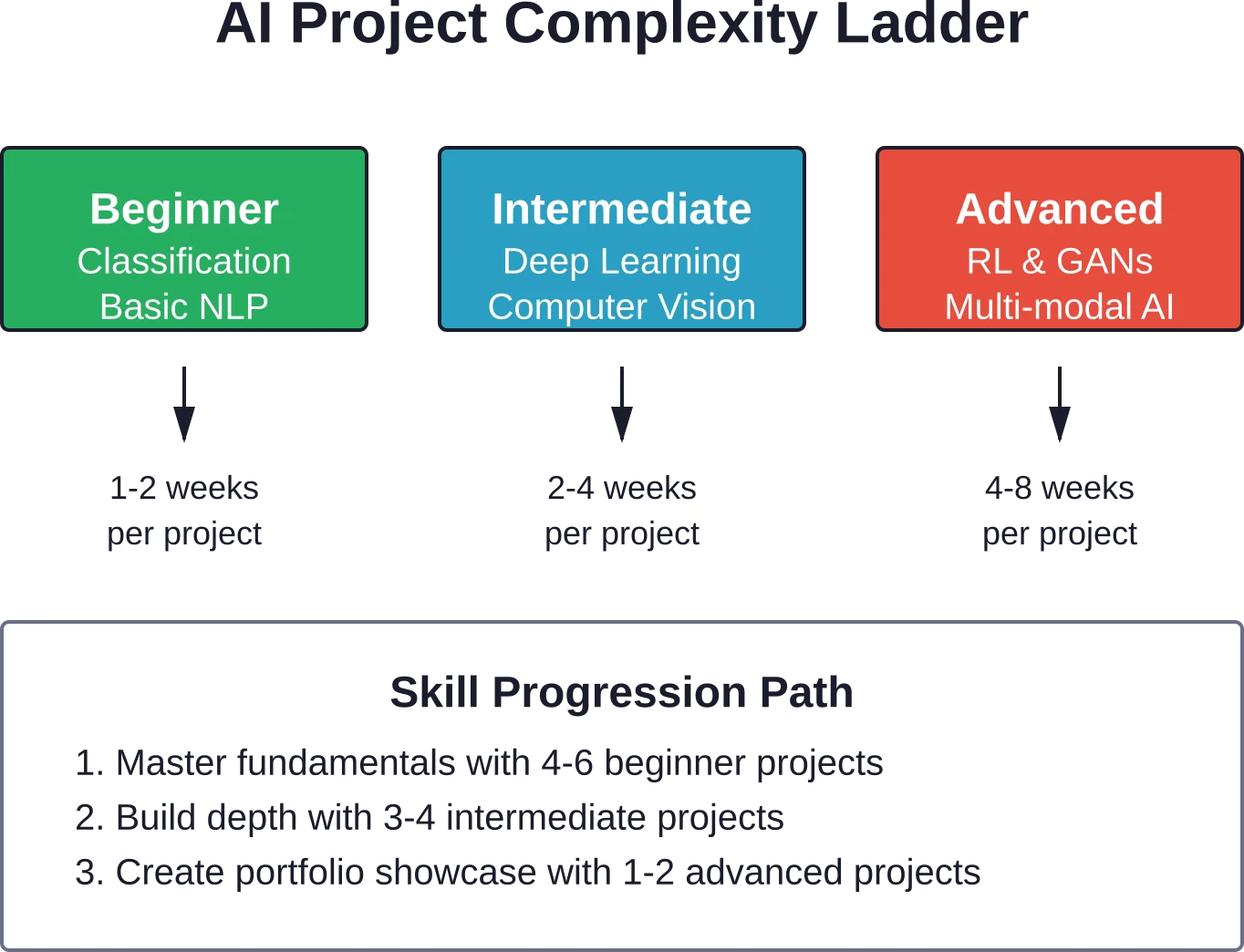
Wie lange dauert die Fertigstellung eines KI-Projekts?
Die Projektdauer variiert je nach Komplexität und Erfahrungsstand. Anfängerprojekte wie Spam-Erkennung oder einfache Bildklassifizierung lassen sich in der Regel in 1–2 Wochen in Teilzeit realisieren. Projekte für Fortgeschrittene, die Deep Learning oder mehrere Datenquellen einbeziehen, benötigen 2–4 Wochen. Anspruchsvolle Projekte wie Reinforcement-Learning-Agenten oder multimodale Systeme können 4–8 Wochen oder länger dauern. Entscheidend ist kontinuierlicher Fortschritt: Tägliches, konzentriertes Arbeiten von einigen Stunden führt zu besseren Ergebnissen als sporadische intensive Arbeitsphasen. Die Unterteilung von Projekten in Meilensteine (Datenerfassung, Basismodell, Optimierung, Implementierung) hilft, den Fortschritt zu verfolgen und die Dynamik aufrechtzuerhalten.
Benötige ich teure Hardware, um KI-Projekte zu entwickeln?
Nicht unbedingt. Viele Projekte für Anfänger und Fortgeschrittene lassen sich auf Standard-Laptops durchführen, insbesondere bei kleinen bis mittleren Datensätzen und vortrainierten Modellen. Kostenlose Ressourcen wie Google Colab ermöglichen den Zugriff auf GPUs für das Training von Deep-Learning-Modellen ohne Hardwareinvestitionen. Cloud-Plattformen (AWS, Google Cloud, Azure) bieten nutzungsbasierte Abrechnung für größere Experimente. Fortgeschrittene Projekte mit riesigen Datensätzen oder dem Training großer Modelle von Grund auf benötigen zwar erhebliche Rechenleistung, doch der Einstieg mit Transfer Learning und kleineren Problemen macht KI auch ohne teure Hardware zugänglich. Lernen findet größtenteils durch Problemlösung und Experimentieren statt, nicht durch reine Rechenleistung.
Wo finde ich Datensätze für KI-Projekte?
Kaggle hostet Tausende von Datensätzen aus verschiedenen Bereichen und für unterschiedliche Kenntnisstände sowie strukturierte Wettbewerbe. Das UCI Machine Learning Repository stellt klassische Benchmark-Datensätze bereit. Hugging Face Datasets bietet einfachen Zugriff auf NLP-Korpora und multimodale Sammlungen. Regierungsportale wie data.gov, NASA-Datensätze und NIH-Datenrepositorien stellen öffentlich zugängliche Daten aus der Praxis bereit. Die Google-Datensatzsuche hilft, Datensätze im gesamten Web zu finden. Wissenschaftliche Publikationen verlinken häufig auf ihre Datensätze. Für domänenspezifische Projekte existieren branchenspezifische Repositorien – Finanzdaten von Alpha Vantage oder FRED, medizinische Bilddaten vom NIH, Satellitenbilder von der NASA. Web Scraping ermöglicht die Erstellung benutzerdefinierter Datensätze, wenn öffentliche Quellen die Anforderungen nicht erfüllen, sofern die Nutzungsbedingungen und robots.txt-Dateien beachtet werden.
Soll ich mich auf ein bestimmtes KI-Spezialgebiet konzentrieren oder ein breites Wissen erwerben?
Beginnen Sie mit einem breiten Ansatz, um herauszufinden, was Ihnen liegt, und spezialisieren Sie sich dann entsprechend Ihren Interessen und Karrierezielen. Vielfältige Einsteigerprojekte – Klassifizierung, Regression, NLP, Computer Vision – ermöglichen Ihnen die Auseinandersetzung mit unterschiedlichen Problemtypen und Techniken. Sobald Sie erkennen, was Ihnen Spaß macht und Ihnen leichtfällt, vertiefen Sie sich in diesem Bereich. Spezialisierungen (Computer Vision, NLP, Reinforcement Learning, generative Modelle) heben Sie auf dem Arbeitsmarkt hervor und ermöglichen Ihnen Expertise. Grundlegende Fähigkeiten – Datenvorverarbeitung, Modellevaluierung, Debugging, Deployment – sind jedoch branchenübergreifend anwendbar. In der Praxis kombinieren Projekte oft mehrere Spezialisierungen. Eine breite Grundlage in Verbindung mit Vertiefung in einem Bereich bietet die beste Kombination aus Flexibilität und Expertise.
Woran erkenne ich, ob mein KI-Projekt gut genug für mein Portfolio ist?
Qualitativ hochwertige Portfolio-Projekte demonstrieren Problemlösungskompetenz, nicht Perfektion. Achten Sie auf: eine klar definierte Problemstellung, einen systematischen Umgang mit Daten und Modellierung, eine geeignete Evaluierungsmethodik, eine offene Auseinandersetzung mit den Grenzen des Projekts und eine saubere Dokumentation. Das Projekt sollte zuverlässig funktionieren, auch wenn die Performance nicht dem neuesten Stand der Technik entspricht. Die vollständige Fertigstellung ist wichtiger als das Erreichen höchster Benchmark-Werte. Eine gute Dokumentation, die Ihren Prozess, Ihre Entscheidungen und Ihre Erkenntnisse erläutert, ist oft wichtiger als technische Raffinesse. Wenn Sie durch das Projekt etwas Wertvolles gelernt haben und erklären können, was Sie entwickelt haben und warum, gehört es in Ihr Portfolio. Eine professionelle Präsentation – eine übersichtliche README-Datei, strukturierter Code, Visualisierungen – lässt Projekte unabhängig von ihrer Komplexität glänzen.
Worin besteht der Unterschied zwischen KI-Projekten zum Lernen und solchen für berufliche Anwendungen?
Lernprojekte konzentrieren sich auf das Verständnis von Konzepten und Techniken – das Absolvieren von Tutorials, die Implementierung von Algorithmen von Grund auf und die Reproduktion von Forschungsergebnissen. Bewerbungsprojekte betonen die praktische Problemlösung und die Einsatzbereitschaft – den Umgang mit realen, unstrukturierten Daten, die Berücksichtigung von Bereitstellungsbeschränkungen, eine umfassende Dokumentation und den Nachweis des Geschäftswerts. Für Portfolios sollten Projekte priorisiert werden, die definierte Probleme vollständig lösen, eine klare Dokumentation und Visualisierungen beinhalten, zuverlässig funktionieren (nicht nur unter idealen Bedingungen), für die angestrebten Positionen relevante Fähigkeiten demonstrieren und eine Steigerung der Komplexität aufzeigen. Lernprojekte lassen sich in Portfolio-Projekte umwandeln, indem sie eine umfassende Dokumentation, die Bereitstellung (auch einfache Web-Oberflächen) und die Diskussion realer Aspekte wie Skalierbarkeit, Latenz und Fehlerbehandlung beinhalten.
Den ersten Schritt wagen
Die Kluft zwischen dem Lesen über KI und dem Entwickeln von KI-Systemen schließt sich nur durch praktisches Handeln. Die Theorie bildet das Fundament, Projekte hingegen schaffen die notwendigen Fähigkeiten.
Fang einfach an. Such dir ein Projekt aus der Anfängerliste aus, das dich interessiert. Arbeite diese Woche daran, eine Basisversion zum Laufen zu bringen. Perfektion ist nicht das Ziel – Hauptsache, es ist fertig.
Die Welt der künstlichen Intelligenz belohnt Entwickler. Modelle verbessern sich durch Iteration. Fähigkeiten entwickeln sich durch Übung. Portfolios wachsen Projekt für Projekt.
Laut staatlichen KI-Strategieinitiativen wetteifern Organisationen weltweit darum, KI-Kompetenzen aufzubauen. Das sich durchsetzende Ökosystem wird globale Standards setzen und wirtschaftliche Vorteile erzielen. Dies eröffnet Entwicklern, die ihre praktischen KI-Kenntnisse in realen Projekten unter Beweis stellen können, neue Chancen.
Die Werkzeuge sind vorhanden. Die Daten sind verfügbar. Das Wissen ist zugänglich. Was Entwickler, die erfolgreiche KI-Projekte realisieren, von denen unterscheidet, die scheitern, sind nicht Talent oder Ressourcen – es ist schlicht der Anfang.
Wähle ein Projekt. Schreibe die erste Codezeile. Behebe den ersten Fehler. Man lernt durchs Tun, nicht durchs Planen.