Kurzzusammenfassung: Predictive Analytics nutzt historische Daten, statistische Modelle und maschinelles Lernen, um zukünftige Ergebnisse branchenübergreifend vorherzusagen. Von der Instandhaltung von Produktionsanlagen bis hin zur Prognose von Kundenabwanderung im Bankwesen helfen prädiktive Modelle Unternehmen, Risiken zu minimieren, Abläufe zu optimieren und datengestützte Entscheidungen zu treffen. Die Implementierung umfasst Datenerfassung, Modelltraining, Validierung und Einsatz – und transformiert reaktive Branchen in proaktive, autonome Systeme.
Produktionslinien fallen nicht planmäßig aus. Kunden kündigen ihre Kündigung nicht an. Lieferketten senden keine Frühwarnungen, bevor sie zusammenbrechen.
Doch in den Daten lassen sich Muster erkennen – versteckte Anzeichen dafür, dass etwas schiefgehen wird. Predictive Analytics findet diese Anzeichen, bevor Probleme auftreten.
Prädiktive Analytik ist ein Teilgebiet der fortgeschrittenen Analytik, das mithilfe historischer Daten in Kombination mit statistischer Modellierung, Data-Mining-Techniken und maschinellem Lernen Vorhersagen über zukünftige Ergebnisse trifft. Unternehmen setzen prädiktive Analytik-Tools ein, um Muster in den Daten zu erkennen und so Risiken und Chancen zu identifizieren.
Der Wandel von reaktiver zu proaktiver Entscheidungsfindung stellt eine grundlegende Transformation dar. Anstatt Geräte erst nach ihrem Ausfall zu reparieren, prognostizieren Unternehmen Ausfälle Wochen im Voraus. Anstatt auf Kundenabwanderung zu reagieren, identifizieren Banken gefährdete Konten, bevor es zu Kundenverlusten kommt.
Wie prädiktive Analysen tatsächlich funktionieren
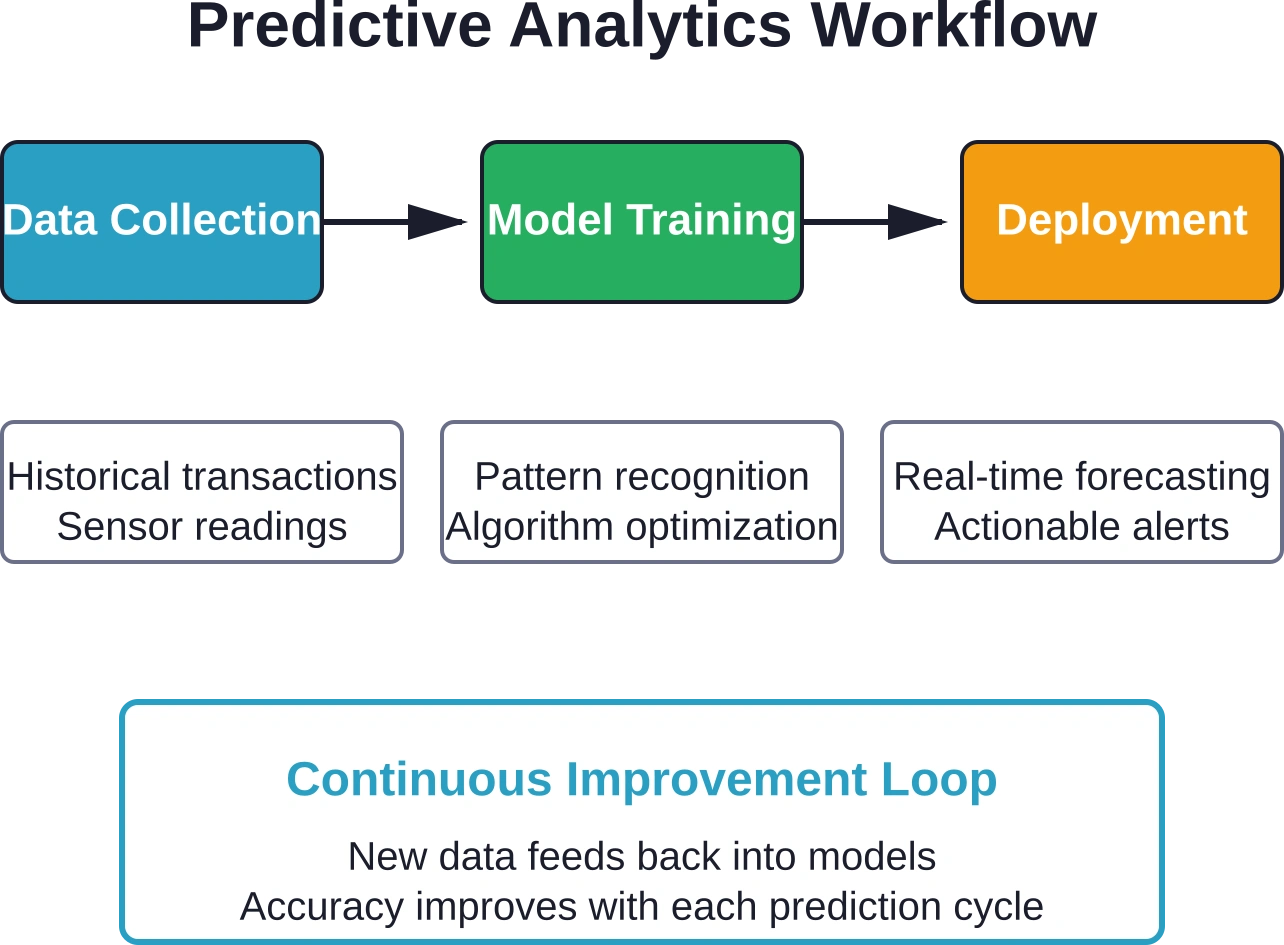
Der Prozess beginnt mit historischen Daten. Und zwar mit einer großen Menge.
Organisationen erfassen Transaktionsdaten, Sensormesswerte, Kundeninteraktionen, Produktionskennzahlen – alle Daten, die vergangene Ereignisse dokumentieren. Diese historische Grundlage dient als Basis für statistische Modelle, die Muster erkennen lernen.
Maschinelle Lernalgorithmen analysieren diese Muster. Sie identifizieren, welche Variablen mit bestimmten Ergebnissen korrelieren: Temperaturspitzen vor Geräteausfällen, Transaktionsmuster vor Kontoschließungen, Lagerbestände vor Lieferengpässen.
Die Modelle erkennen nicht nur Korrelationen, sondern quantifizieren auch Wahrscheinlichkeiten. Eine bestimmte Maschinenkonfiguration birgt ein Ausfallrisiko von 78% innerhalb von zwei Wochen. Ein Konto mit drei Verhaltensindikatoren weist eine Kündigungswahrscheinlichkeit von 82% innerhalb von 90 Tagen auf.
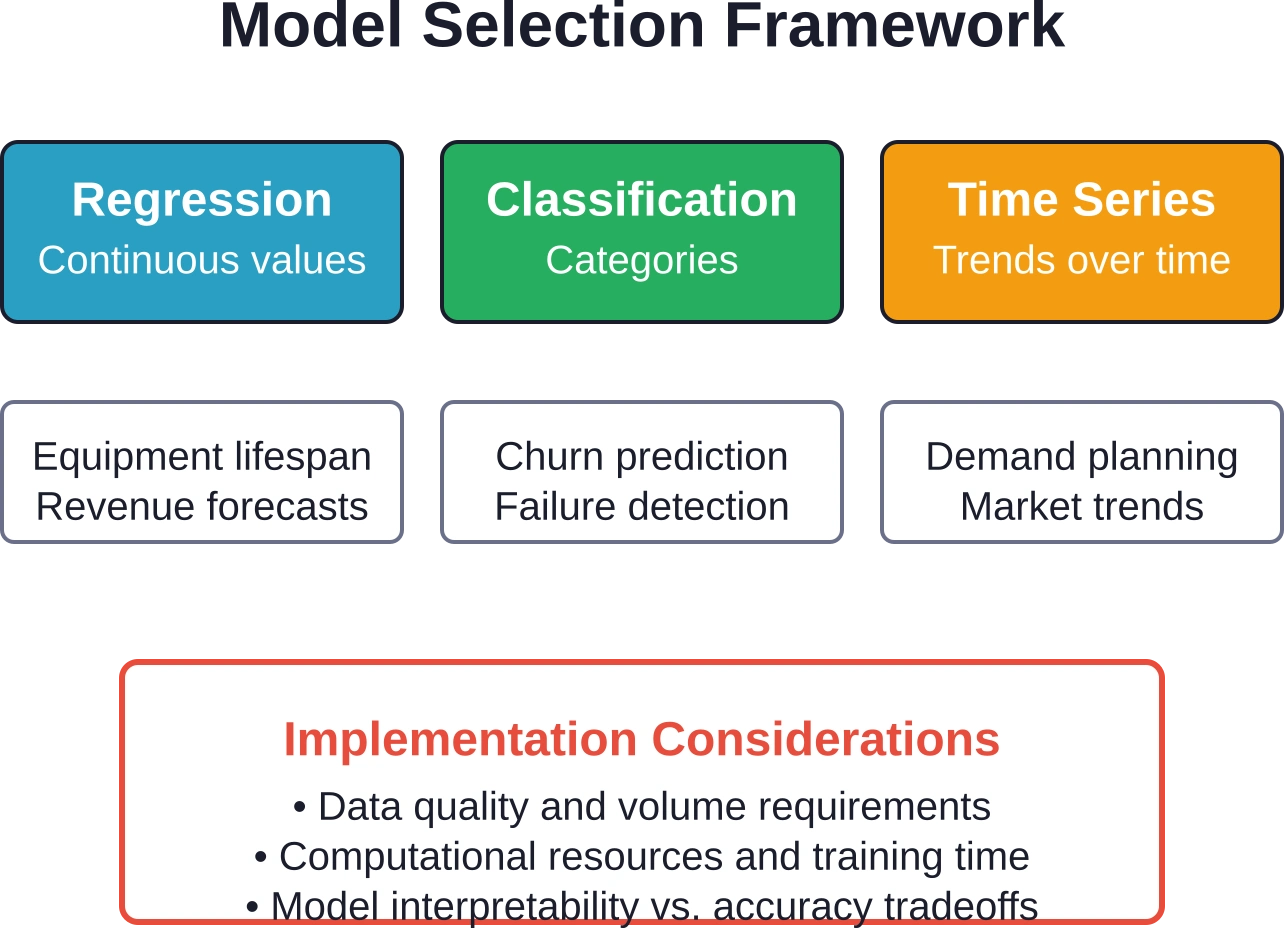
Statistische Modellierungstechniken variieren je nach Anwendungsfall. Regressionsmodelle prognostizieren kontinuierliche Werte wie die Lebensdauer von Anlagen oder den Umsatz. Klassifikationsmodelle prognostizieren kategoriale Ergebnisse wie Bestehen/Nichtbestehen oder Verbleiben/Ausscheiden. Zeitreihenmodelle prognostizieren Trends über bestimmte Zeiträume.
Data-Mining-Techniken extrahieren diese Muster aus riesigen Datensätzen. Neuronale Netze mit mehreren verborgenen Schichten identifizieren nichtlineare Zusammenhänge, die dem Menschen entgehen würden. Entscheidungsbäume bilden verzweigte logische Pfade ab, die zu unterschiedlichen Ergebnissen führen.
Anwendungen für die industrielle vorausschauende Instandhaltung
Produktionsanlagen erzeugen enorme Mengen an Sensordaten. Temperaturmessungen, Vibrationsmessungen, Druckpegel, elektrischer Strom – all dies wird kontinuierlich von den Produktionsanlagen erfasst.
Vorausschauende Wartungsmodelle analysieren diese Sensordaten, um Geräteausfälle vorherzusagen, bevor sie auftreten. Die technische Literatur des IEEE dokumentiert Implementierungen, die die Verfügbarkeit von Produktionsanlagen in Automobilunternehmen durch die Vorhersage des Wartungsbedarfs verbessern.
Industrielle IoT-Anwendungen integrieren heute prädiktive Analysen für die proaktive Wartung. Sensoren in Motoren, Pumpen, Förderbändern und Montagerobotern übermitteln Betriebsdaten in Echtzeit. Maschinelle Lernalgorithmen verarbeiten diese Daten, um Verschleißmuster zu erkennen.
| Wartungsansatz | Strategie | Auswirkungen von Ausfallzeiten | Kosteneffizienz |
|---|---|---|---|
| Reaktiv | Nach dem Ausfall beheben | Hohe Anzahl ungeplanter Stromausfälle | Niedrig – teure Notfallreparaturen |
| Präventiv | Planmäßige Wartung | Mittel – geplante Ausfallzeit | Mittel – einige unnötige Arbeiten |
| Vorhersage | Prognosegesteuerte Intervention | Niedrige, gezielte Wartung | Hoch – optimales Timing |
Die Fertigungsindustrie steht vor komplexen Herausforderungen durch Rohstoffknappheit und Lieferkettenunterbrechungen. Prognosemodelle tragen dazu bei, operative Risiken zu reduzieren, indem sie diese Störungen vorhersagen, bevor sie die Produktion beeinträchtigen.
Automobilhersteller nutzen prädiktive Analysen, um Produktionspläne an geplante Wartungsfenster anzupassen. Anstatt ganze Produktionslinien für Routineprüfungen stillzulegen, erfolgt die Wartung genau dann, wenn Sensoren einen tatsächlichen Bedarf anzeigen.
Anwendungsfälle im Bank- und Finanzdienstleistungssektor
Kundenbindung ist der Schlüssel zur Rentabilität im Finanzdienstleistungssektor. Die Bindung bestehender Kunden ist kostengünstiger als die Neukundengewinnung.
Neuronale Netze verbessern die Vorhersagegenauigkeit für Kundenabwanderung im Bankwesen deutlich. Untersuchungen mit einem Datensatz von 10.000 Einträgen und 14 Merkmalen zeigen, wie maschinelles Lernen prognostiziert, welche Kunden ihre Konten schließen werden.

Die logistische Regression erreichte eine Genauigkeit von 89,61 TP³T bei einer Sensitivität von 96,81 TP³T und einem AUC-Wert von 0,91 für die Diskriminierungsfähigkeit. Naive Bayes erzielte eine Genauigkeit von 86,71 TP³T bei einer Präzision von 92,01 TP³T und einer Sensitivität von 92,21 TP³T sowie einem AUC-Wert von 0,83.
Diese Modelle identifizieren nicht nur gefährdete Kunden, sondern ordnen sie auch nach Wahrscheinlichkeit und schlagen Interventionsstrategien vor. Wertvolle Kundenkonten, bei denen frühe Warnsignale auftreten, lösen personalisierte Kundenbindungsangebote aus, bevor Kunden eine Kündigungsentscheidung treffen.
Banken nutzen mehrschichtige Perzeptron-Architekturen mit unterschiedlichen Neuronenkonfigurationen, die für ihre spezifischen Aufgaben zur Kundenabwanderungsprognose optimiert sind. Diese neuronalen Netze verarbeiten Transaktionsmuster, Kontostandsentwicklungen, Interaktionen mit dem Kundenservice und demografische Faktoren.
Finanzinstitute nutzen prädiktive Analysen zur Betrugserkennung, Kreditrisikobewertung und Portfoliooptimierung. Jede Anwendung basiert auf demselben Grundprinzip: Historische Muster sagen zukünftiges Verhalten voraus.
Prognosen für Lieferkette und Logistik
Lieferketten unterliegen einer Vielzahl von Einflussfaktoren. Nachfrageschwankungen, Transportverzögerungen, Lagerbestände, Zuverlässigkeit der Lieferanten, saisonale Muster – all dies ist miteinander verbunden.
Prädiktive Analysemodelle verarbeiten diese Komplexität, um die Nachfrage vorherzusagen, Lagerbestände zu optimieren und Störungen zu vermeiden. Der Einsatz von Daten und prädiktiver Analytik in der Logistik hilft Unternehmen, von reaktiven, hektischen Maßnahmen zu geplanten Lösungen überzugehen.
Nachfrageprognosemodelle analysieren historische Verkaufsdaten zusammen mit externen Faktoren wie Wetter, Konjunkturindikatoren und Markttrends. Einzelhändler prognostizieren die Produktnachfrage Wochen im Voraus und passen ihre Lagerbestände an, bevor es zu Engpässen oder Überbeständen kommt.
Transport- und Routenoptimierung nutzen Vorhersagemodelle, um Lieferzeiten unter Berücksichtigung von Verkehrsaufkommen, Wetterbedingungen und historischen Verzögerungsdaten zu prognostizieren. Logistikunternehmen senken so ihre Kraftstoffkosten und verbessern die Liefergenauigkeit.
Doch die prädiktive Analytik der Lieferkette geht noch weiter. Modelle identifizieren Lieferantenrisiken durch die Analyse von Lieferkonsistenz, Qualitätskennzahlen und externen Faktoren wie geopolitischer Instabilität oder der Wahrscheinlichkeit von Naturkatastrophen in den Lieferregionen.
Modellarchitektur und technische Implementierung
Die Entwicklung effektiver Vorhersagemodelle erfordert sorgfältige Architekturentscheidungen.
Neuronale Netze bieten eine leistungsstarke Mustererkennung, benötigen jedoch umfangreiche Trainingsdaten und Rechenressourcen. Einfachere Modelle wie die logistische Regression eignen sich gut für binäre Klassifizierungsprobleme mit klaren Merkmalsbeziehungen.
Die Wahl hängt von den Dateneigenschaften und der Komplexität der Vorhersage ab. Lineare Modelle eignen sich für einfache Zusammenhänge. Nichtlineare Modelle erfassen komplexe Wechselwirkungen, bergen aber das Risiko der Überanpassung, wenn die Trainingsdaten begrenzt sind.
Die Datenvorverarbeitung beansprucht einen erheblichen Teil der Implementierungszeit. Rohdaten enthalten Inkonsistenzen, fehlende Werte und Ausreißer. Die Bereinigung und Normalisierung der Daten vor dem Modelltraining hat einen erheblichen Einfluss auf die Vorhersagegenauigkeit.
Feature Engineering wandelt Rohvariablen in aussagekräftige Prädiktoren um. Die Transaktionshäufigkeit wird so zu einem nützlicheren Merkmal als die reinen Transaktionszeitstempel. Die Temperaturänderungsrate sagt Ausfälle oft besser voraus als die absolute Temperatur.
Die Modellvalidierung verhindert Überanpassung. Trainingsdaten vermitteln Muster. Validierungsdaten prüfen, ob sich diese Muster auf neue Fälle übertragen lassen. Testdaten liefern abschließende Leistungskennzahlen für völlig unbekannte Beispiele.
Kreuzvalidierungsverfahren partitionieren Daten auf verschiedene Weise, um sicherzustellen, dass Modelle über verschiedene Teilmengen hinweg konsistent funktionieren. Die K-fache Kreuzvalidierung teilt die Daten in Segmente auf, trainiert mit den meisten Segmenten und testet mit den verbleibenden. Anschließend wird das Segment, das als Testset dient, rotiert.

Anwendung prädiktiver Analysen auf industrielle Arbeitsabläufe
Predictive Analytics kann Industrieunternehmen unterstützen, wenn es mit Planung, Betrieb, Ausrüstung, Produktion, Qualität oder Ressourcenmanagement verknüpft ist. AI Superior Das Unternehmen bietet KI-Beratung, maschinelles Lernen, prädiktive Analysen, Business Intelligence, Computer Vision und die Entwicklung kundenspezifischer KI-Software an. Das Team unterstützt Unternehmen bei der Definition geeigneter Prognoseaufgaben, der Aufbereitung von Geschäfts- und Betriebsdaten, der Modellentwicklung und der Integration der Ergebnisse in bestehende Systeme. Dies ist besonders hilfreich für Unternehmen, die mithilfe von Daten Risiken frühzeitig erkennen, fundierter planen oder vermeidbare Ineffizienzen reduzieren möchten.
Wenden Sie sich an AI Superior für:
- Definition von Anwendungsfällen für prädiktive Analysen
- Gebäudeprognose- und Anomalieerkennungsmodelle
- Unterstützung von vorausschauender Wartung und Qualitätsanalyse
- Erstellung von BI-Tools auf Basis von Betriebsdaten
- Integration prädiktiver Erkenntnisse in Geschäftsprozesse
Wenden Sie sich an AI Superior. um Anwendungsfälle für prädiktive Analysen für Ihre industriellen Daten, Betriebsabläufe oder Planungsprozesse zu erkunden.
Implementierung und kontinuierliche Verbesserung
Trainierte Modelle müssen in operative Systeme integriert werden.
Die Bereitstellungsarchitektur bestimmt, wie Prognosen Entscheidungsträger erreichen. Die Stapelverarbeitung erstellt Prognosen planmäßig – beispielsweise nächtliche Bedarfsprognosen oder wöchentliche Wartungsrisikoberichte. Die Echtzeitverarbeitung bewertet Transaktionen in Echtzeit – etwa zur Betrugserkennung oder für sofortige Qualitätskontrollwarnungen.
API-Endpunkte ermöglichen es mehreren Systemen, Prognosen anzufordern. Ein CRM-System fragt das Abwanderungsmodell ab, wenn der Kundenservice mit einem Konto interagiert. Ein Warenwirtschaftssystem fordert Bedarfsprognosen an, wenn es die Nachbestellung plant.
Die Überwachung eingesetzter Modelle verhindert Genauigkeitseinbußen. Geschäftsbedingungen ändern sich. Muster, die im letzten Jahr galten, sind im nächsten Quartal möglicherweise nicht mehr gültig. Kennzahlen zur Modellleistung verfolgen die Vorhersagegenauigkeit hinsichtlich laufender Ergebnisse.
Regelmäßiges Neutraining aktualisiert Modelle mit aktuellen Daten. Manche Organisationen führen das Neutraining monatlich durch. Andere lösen es aus, sobald die Genauigkeit unter bestimmte Schwellenwerte fällt. Kritische Anwendungen werden möglicherweise kontinuierlich neu trainiert, sobald neue, annotierte Daten eintreffen.
Das Konzept autonomer Daten- und KI-Plattformen stellt die nächste Evolutionsstufe dar. Unternehmen gehen über einfache Prognosen hinaus und entwickeln intelligente Systeme, die auf Basis von Vorhersagen handeln. Systeme passen Lagerbestände automatisch an Bedarfsprognosen an oder planen Wartungsarbeiten anhand von Risikobewertungen der Anlagen.
Branchenspezifische Herausforderungen bei der Implementierung
Jede Branche steht vor spezifischen Herausforderungen im Bereich der prädiktiven Analytik.
Die Fertigung ist mit der Qualität von Sensordaten konfrontiert. Industrielle Umgebungen erzeugen elektrisches Rauschen, extreme Temperaturen und Vibrationen, die die Messwerte verfälschen. Modelle müssen daher zwischen tatsächlichen Degradationssignalen und Umwelteinflüssen unterscheiden.
Finanzdienstleister müssen regulatorische Anforderungen erfüllen. Modellentscheidungen, die sich auf Kreditvergabe oder Versicherungen auswirken, erfordern oft Nachvollziehbarkeit. Komplexe neuronale Netze, die als Blackboxes fungieren, stehen selbst bei überragender Genauigkeit vor Compliance-Herausforderungen.
Prädiktive Modelle im Gesundheitswesen verarbeiten sensible Patientendaten unter strengen Datenschutzbestimmungen. Das Training von Modellen mit geschützten Gesundheitsinformationen erfordert eine sorgfältige Anonymisierung. Der Einsatz muss das Risiko einer Reidentifizierung ausschließen.
Die Prognose im Einzelhandel steht vor der Herausforderung, rasche Trendwechsel und externe Störungen zu bewältigen. Nachfragemuster, die jahrelang Bestand hatten, können sich aufgrund viraler Beiträge in sozialen Medien oder unerwarteter Ereignisse über Nacht verändern.
| Raumfahrtindustrie | Primäre Anwendung | Hauptherausforderung | Erfolgskennzahl |
|---|---|---|---|
| Herstellung | Gerätewartung | Qualität der Sensordaten | Reduzierung von Ausfallzeiten |
| Bankwesen | Abwanderungsprognose | Modellerklärbarkeit | Verbesserung der Kundenbindung |
| Einzelhandel | Nachfragevorhersage | Schnelle Trendänderungen | Bestandsoptimierung |
| Logistik | Routenoptimierung | Echtzeitanpassung | Liefergenauigkeit |
Prognosemodelle im Energiesektor sagen Verbrauchsmuster und Geräteausfälle in der Stromerzeugung und -verteilung voraus. Netzbetreiber nutzen diese Prognosen, um Angebot und Nachfrage auszugleichen, Stromausfälle zu verhindern und gleichzeitig die Nutzung der Energiequellen zu optimieren.
Im Bauwesen werden prädiktive Analysen eingesetzt, um Projektzeitpläne, Kostenüberschreitungen und Sicherheitsvorfälle zu überwachen. Modelle, die anhand historischer Projektdaten trainiert wurden, identifizieren Risikofaktoren, die typischerweise zu Verzögerungen oder Budgetüberschreitungen führen.
Messung des Erfolgs von Vorhersagemodellen
Die Genauigkeit des Modells allein definiert noch keinen Erfolg.
Klassifikationsmodelle verwenden Präzision, Trefferquote und F1-Score. Die Präzision misst, wie viel Prozent der positiven Vorhersagen korrekt sind. Die Trefferquote erfasst, wie viel Prozent der tatsächlich positiven Fälle das Modell erkennt. Der F1-Score berücksichtigt beide Kennzahlen.
Regressionsmodelle basieren auf dem mittleren absoluten Fehler oder dem mittleren quadratischen Fehler. Diese Kennzahlen quantifizieren, wie stark die Vorhersagen im Durchschnitt von den tatsächlichen Werten abweichen.
Doch die geschäftlichen Auswirkungen sind entscheidend. Ein Abwanderungsmodell mit einer Genauigkeit von 90% ist wertlos, wenn das Unternehmen nicht auf die Prognosen reagiert. Ein Wartungsmodell mit einer Genauigkeit von 75% hingegen kann Millionen einsparen, wenn es auch nur wenige kritische Ausfälle verhindert.
Die Rentabilitätsberechnung vergleicht die Kosten der Modellimplementierung mit den betrieblichen Verbesserungen. Reduzierte Ausfallzeiten, geringere Lagerkosten, verbesserte Kundenbindung – all dies wirkt sich finanziell aus.
Der eigentliche Test findet im Produktionsbetrieb statt. Vorhersagen werden validiert, wenn die prognostizierten Ereignisse eintreten oder nicht eintreten. Der kontinuierliche Vergleich von Vorhersage und Realität zeigt, ob die Modelle ihre Genauigkeit auch bei sich ändernden Bedingungen beibehalten.
Zukünftige Entwicklungen in der industriellen prädiktiven Analytik
Die Vorhersagefähigkeiten entwickeln sich mit dem Wachstum der Datenmengen und der Verbesserung der Algorithmen stetig weiter.
Edge Computing bringt prädiktive Modelle direkt zu Industrieanlagen. Anstatt Sensordaten zur Analyse an Cloud-Server zu senden, laufen die Modelle auf lokalen Prozessoren, die in die Maschinen integriert sind. Dies reduziert die Latenz und ermöglicht eine sofortige Reaktion auf vorhergesagte Ausfälle.
Automatisierte Machine-Learning-Plattformen vereinfachen die Modellentwicklung. Systeme testen automatisch verschiedene Algorithmen, optimieren Hyperparameter und wählen den leistungsstärksten Ansatz aus. Data Scientists können sich so auf die geschäftlichen Herausforderungen konzentrieren, anstatt Modelle manuell abzustimmen.
Föderiertes Lernen ermöglicht das Training von Modellen über verteilte Datensätze hinweg, ohne sensible Daten zentral zu speichern. Organisationen arbeiten zusammen, um die Vorhersagegenauigkeit zu verbessern und gleichzeitig den Datenschutz zu wahren.
Erklärbare KI-Techniken machen komplexe Modelle verständlicher. SHAP-Werte und LIME-Analysen zeigen, welche Merkmale bestimmte Vorhersagen beeinflussen, und helfen Unternehmen so, Modellentscheidungen zu verstehen und ihnen zu vertrauen.
Der Übergang von prädiktiver zu präskriptiver Analytik stellt die nächste Herausforderung dar. Modelle prognostizieren nicht nur zukünftige Ereignisse, sondern geben auch Handlungsempfehlungen. Präskriptive Systeme optimieren Entscheidungen unter Berücksichtigung mehrerer Ziele und Einschränkungen.
Erste Schritte mit Predictive Analytics
Organisationen, die ihre Reise in die Welt der prädiktiven Analytik beginnen, sollten schrittweise vorgehen:
- Identifizieren Sie ein konkretes Geschäftsproblem mit klaren Erfolgskennzahlen: Der Versuch, alles gleichzeitig vorherzusagen, führt zwangsläufig zum Scheitern. Betrachten wir einen Anwendungsfall – die Vorhersage von Geräteausfällen in einer kritischen Produktionslinie oder die Prognose von Kundenabwanderung in wertvollen Kundensegmenten.
- Datenverfügbarkeit und -qualität beurteilen: Vorhersagemodelle benötigen historische Beispiele, die das vorhergesagte Ergebnis beinhalten. Wenn Daten zu Geräteausfällen nicht systematisch erfasst wurden, muss für die Erstellung eines Ausfallvorhersagemodells zunächst eine solche Erfassung eingerichtet werden.
- Fangen Sie einfach an: Logistische Regression oder Entscheidungsbäume liefern oft überraschend genaue Ergebnisse bei minimaler Komplexität. Beweisen Sie den Nutzen mit einfachen Modellen, bevor Sie in komplexe neuronale Netzwerkarchitekturen investieren.
- Feedbackschleifen einrichten: Setzen Sie die Modelle zunächst im Schattenmodus ein, um parallel zu den bestehenden Prozessen Vorhersagen zu generieren, ohne diese jedoch zu implementieren. Vergleichen Sie die Vorhersagen mit den tatsächlichen Ergebnissen. Optimieren Sie die Modelle, bevor Sie ihnen Entscheidungsbefugnisse übertragen.
- Organisationsfähigkeiten aufbauen: Für den Erfolg prädiktiver Analysen sind Datenaufbereitung, statistische Expertise, Branchenkenntnisse und Change-Management erforderlich. Niemand verfügt über alle notwendigen Fähigkeiten – daher sollten interdisziplinäre Teams zusammengestellt werden.
Häufig gestellte Fragen
Worin besteht der Unterschied zwischen prädiktiver Analytik und traditioneller Business Intelligence?
Klassische Business Intelligence analysiert historische Daten, um zu verstehen, was passiert ist und warum. Dashboards, Berichte und deskriptive Statistiken beantworten Fragen zur bisherigen Performance. Predictive Analytics nutzt diese historischen Daten, um zukünftige Ergebnisse vorherzusagen. Anstatt die Abwanderungsrate des letzten Quartals zu berichten, ermitteln prädiktive Modelle, welche Bestandskunden voraussichtlich im nächsten Quartal abwandern werden.
Wie viele historische Daten benötige ich, um genaue Vorhersagemodelle zu erstellen?
Der benötigte Datenumfang hängt von der Komplexität der Vorhersage und der Anzahl der Merkmale ab. Einfache Probleme mit wenigen Variablen können bereits mit Hunderten von Beispielen brauchbare Modelle liefern. Komplexe Probleme mit vielen interagierenden Merkmalen erfordern typischerweise Tausende bis Zehntausende von Beispielen. Der Datensatz zur Kundenabwanderung, der eine Genauigkeit von 89,61 TP3T erreichte, enthielt 10.000 Datensätze mit 14 Merkmalen. Generell gilt: Mehr Daten verbessern die Genauigkeit, die Datenqualität ist jedoch wichtiger als die Quantität.
Können kleine Unternehmen prädiktive Analysen ohne Data-Science-Teams implementieren?
Ja, allerdings sollten die Erwartungen den verfügbaren Ressourcen entsprechen. Cloud-Plattformen bieten mittlerweile automatisierte Machine-Learning-Tools, die einen Großteil der technischen Komplexität übernehmen. Kleine Unternehmen können mit diesen Plattformen mit fokussierten Anwendungen wie der Prognose des Kundenlebenszeitwerts oder der Bestandsoptimierung beginnen. Entscheidend ist, mit sauberen Daten und einem klar definierten Geschäftsproblem zu starten. Ziehen Sie für die erste Implementierung die Zusammenarbeit mit Analytics-Beratern in Betracht, während Sie gleichzeitig interne Kompetenzen aufbauen.
Wie oft sollten Vorhersagemodelle mit neuen Daten neu trainiert werden?
Die Häufigkeit der Modellaktualisierung hängt davon ab, wie schnell sich die Muster im zugrunde liegenden Geschäftsumfeld ändern. Nachfragemodelle im Einzelhandel müssen möglicherweise monatlich aktualisiert werden, um saisonale Schwankungen und Trendänderungen zu erfassen. Ausfallmodelle für Industrieanlagen können über mehrere Quartale hinweg präzise bleiben, solange die Betriebsbedingungen stabil sind. Überwachen Sie die Leistungskennzahlen der Modelle kontinuierlich – sobald die Genauigkeit unter akzeptable Schwellenwerte fällt, ist eine Aktualisierung erforderlich. Viele Unternehmen legen vierteljährliche Aktualisierungspläne als Standard fest.
Was passiert, wenn Vorhersagen falsch sind?
Kein Vorhersagemodell erreicht absolute Genauigkeit. Unternehmen müssen Prozesse entwickeln, die Vorhersagefehler berücksichtigen. Falsch-positive Ergebnisse – die Vorhersage eines Ereignisses, das nicht eintritt – können Ressourcen für unnötige Eingriffe verschwenden. Falsch-negative Ergebnisse – das Übersehen von Ereignissen, die tatsächlich eintreten – bedeuten verpasste Gelegenheiten zur Problemvermeidung. Die akzeptable Fehlerrate hängt von den Kosten der jeweiligen Fehlerart ab. Die Vorhersage eines Geräteausfalls, der nicht eintritt, verursacht einen Wartungseinsatz. Das Übersehen eines tatsächlichen Ausfalls führt zum Stillstand einer gesamten Produktionslinie.
Benötige ich Echtzeitprognosen oder reichen Batch-Prognosen aus?
Dies hängt von den Anforderungen an die Entscheidungszeit ab. Betrugserkennung erfordert eine Echtzeitbewertung, da Transaktionen sofort genehmigt oder abgelehnt werden müssen. Die Bedarfsplanung für die Lagerhaltung funktioniert gut mit nächtlicher Stapelverarbeitung, da Kaufentscheidungen über einen längeren Zeitraum getroffen werden. Echtzeitsysteme erhöhen die Komplexität und die Kosten – sie sollten nur dann implementiert werden, wenn die sofortige Umsetzung von Prognosen einen relevanten Geschäftsnutzen generiert.
Wie kann ich das Management davon überzeugen, in prädiktive Analysen zu investieren?
Beginnen Sie mit einem Pilotprojekt, das ein sichtbares, kostspieliges Geschäftsproblem angeht. Berechnen Sie den potenziellen ROI auf Basis konservativer Annahmen. Wenn die Vermeidung von nur drei Geräteausfällen mehr einspart als die Implementierungskosten des Modells, ist der Business Case eindeutig. Nutzen Sie die Ergebnisse des Pilotprojekts, um den Wert nachzuweisen, bevor Sie größere Investitionen beantragen. Konzentrieren Sie sich auf Geschäftsergebnisse statt auf technische Fähigkeiten – dem Management sind Kostensenkungen und Umsatzsteigerungen wichtiger als ausgefeilte Algorithmen.
Wie Sie Prognosen für Ihre Branche nutzbar machen
Predictive Analytics wandelt reaktive in proaktive Organisationen um. Geräte fallen seltener aus, da Wartungen erfolgen, bevor es zu Ausfällen kommt. Kunden bleiben länger, da Probleme behoben werden, bevor Unzufriedenheit zur Abwanderung führt. Lieferketten funktionieren reibungslos, da Störungen vorhergesagt und minimiert werden.
Die Technologie entwickelt sich stetig weiter, doch die Grundprinzipien bleiben unverändert. Saubere historische Daten in Kombination mit geeigneten statistischen Verfahren ermöglichen Prognosen für zukünftige Entwicklungen. Die Genauigkeit der Modelle ist wichtig, der geschäftliche Erfolg jedoch entscheidend.
Branchen, die prädiktive Analysen effektiv einsetzen, erzielen Wettbewerbsvorteile. Sie optimieren Abläufe, die anderen nicht möglich sind. Sie beugen Problemen vor, auf die Wettbewerber lediglich reagieren. Sie treffen datengestützte Entscheidungen, während andere auf Intuition setzen.
Die Frage ist nicht, ob prädiktive Analysen einen Mehrwert bieten – dokumentierte Implementierungen in der Fertigung, im Finanzwesen, im Einzelhandel und in der Logistik belegen dies. Die Frage ist vielmehr, ob Unternehmen in die Dateninfrastruktur, die Analysefähigkeiten und die erforderlichen kulturellen Veränderungen investieren werden, um diesen Mehrwert zu realisieren.
Beginnen Sie fokussiert. Beweisen Sie den Nutzen anhand konkreter Anwendungsfälle. Bauen Sie Ihre Kompetenzen schrittweise aus. Unternehmen, die heute prädiktive Analysen beherrschen, positionieren sich als Branchenführer von morgen.