Überblick: Das Training eines großen Sprachmodells wie GPT-4 kostet zwischen 1,4 Billionen und 1,92 Milliarden US-Dollar, wobei die Recheninfrastruktur 60 bis 701 Billionen US-Dollar der Gesamtkosten ausmacht. Diese Kosten entstehen durch GPU-Cluster, Stromverbrauch, Datenaufbereitung und den Bedarf an Entwicklerpersonal. Durch die Optimierung bestehender Modelle lassen sich die Kosten im Vergleich zum Training von Grund auf um 60 bis 901 Billionen US-Dollar senken.
Große Sprachmodelle haben die künstliche Intelligenz von einem Forschungsgebiet zu einem kommerziellen Kraftpaket gemacht. Doch was die meisten nicht wissen: Die Kosten für die Entwicklung dieser Systeme sind vergleichbar mit den Kosten für den Start von Satelliten ins Weltall.
Laut dem Stanford AI Index Report 2025 beliefen sich die geschätzten Trainingskosten für GPT-4 auf $78–100 Millionen. Gemini Ultra 1.0 trieb diese Summe auf $192 Millionen. Das entspricht einer Steigerung um das 287.000-fache gegenüber den $670, die das Training eines Transformer-Modells im Jahr 2017 kostete.
Die wirtschaftlichen Zusammenhänge dieser Zahlen sind nicht nur von akademischem Interesse. Organisationen, die entscheiden müssen, ob sie eigene Modelle entwickeln oder bestehende lizenzieren, benötigen konkrete Daten. Forschungsteams, die Fördermittel einwerben, brauchen realistische Budgetprognosen. Und Branchenbeobachter, die die KI-Entwicklung verfolgen, benötigen Kontext, um die Marktdynamik zu verstehen.
Diese Aufschlüsselung untersucht, wohin jeder Dollar beim Training von modernen Sprachmodellen fließt, warum die Kosten so dramatisch steigen und welche Strategien die Ausgaben tatsächlich senken, ohne die Leistung zu beeinträchtigen.
Die Anatomie der LLM-Ausbildungskosten
Die Schulungskosten setzen sich nicht aus einer einzigen Position zusammen. Mehrere Ausgabenkategorien summieren sich zu diesen acht- und neunstelligen Gesamtsummen.
Die Recheninfrastruktur macht den größten Teil des Budgets aus. Cloud-Anbieter berechnen den GPU-Zugriff stundenweise, und Trainingsläufe erstrecken sich über Wochen oder Monate. OpenAI gab Berichten zufolge über 100 Millionen US-Dollar für das Training von GPT-4 aus, wobei ein erheblicher Teil auf Cloud-Computing-Kosten entfiel.
Die Hardwarekosten steigen mit der Modellkomplexität. Größere Modelle erfordern leistungsfähigere Beschleuniger – und mehr davon. Der Unterschied zwischen dem Training eines Modells mit 20 Milliarden Parametern und eines mit 120 Milliarden Parametern ist nicht linear. Der Rechenaufwand steigt exponentiell mit der Anzahl der Parameter.
Aber Moment mal. Die Hardwarekosten sind nur ein Teil der Geschichte.
Die versteckten Multiplikatoren
Der Stromverbrauch verursacht laufende Kosten, die in vielen Budgetplanungen unterschätzt werden. Anthropic kündigte im Februar 2026 an, die Strompreissteigerungen für seine Rechenzentren zu übernehmen und unterstrich damit, wie ernst große KI-Labore dieses Thema nehmen. Sie wiesen darauf hin, dass das Training eines einzigen hochmodernen KI-Modells bald Gigawattstunden Strom benötigen wird – ein Zeichen dafür, dass diese Systeme eine erhebliche Infrastrukturbelastung darstellen.
Datenaufbereitung und -speicherung stellen eine weitere Ebene dar. Trainingsdatensätze für Modelle wie GPT-4 enthalten Hunderte von Milliarden Tokens, die aus Büchern, Websites, wissenschaftlichen Artikeln und spezialisierten Korpora stammen. Das Erfassen, Bereinigen, Filtern und Speichern dieser Daten erfordert spezialisierte Teams und eine entsprechende Infrastruktur.
Ingenieurtalente erzielen Spitzengehälter. Forscher im Bereich maschinelles Lernen und Infrastrukturingenieure, die Trainingsläufe auf Tausenden von GPUs orchestrieren können, sind rar. Ihre Gehälter, Boni und Aktienoptionen machen einen erheblichen Teil der gesamten Projektkosten aus.
Experimentelle Iterationen vervielfachen die Kosten der Basislinienberechnung. Die Ermittlung optimaler Hyperparameter – Lernraten, Batchgrößen, Architekturvarianten – erfordert mehrere Trainingsläufe. Jeder fehlgeschlagene Versuch verbraucht GPU-Zeit, ohne das endgültige Modell zu erzeugen.

GPU-Infrastruktur: Der dominierende Kostenfaktor
Grafikprozessoren bilden das Rückgrat des modernen KI-Trainings. Diese spezialisierten Chips zeichnen sich durch ihre hervorragende Leistung bei den parallelen Matrixoperationen aus, die neuronale Netze benötigen.
NVIDIA dominiert den Markt. Ihre H100- und A100-Beschleuniger treiben die meisten groß angelegten Trainingsoperationen an. Cloud-Anbieter berechnen etwa 10.000 bis 25.000 GPUs pro H100-GPU-Stunde. Das Training eines Spitzenmodells kann 10.000 bis 25.000 GPUs erfordern, die mehrere Wochen lang laufen.
Die Rechnung wird schnell brutal. Bei 1T4T3 pro GPU-Stunde kostet der Betrieb von 15.000 GPUs über 30 Tage hinweg 1T4T32,4 Millionen – allein für die Rechenzeit. Speicher, Netzwerk und alle anderen Infrastrukturkomponenten sind dabei noch nicht berücksichtigt.
Der direkte Kauf von Hardware verändert die Kostenstruktur. Zwar sind die anfänglichen Investitionskosten höher, doch die Vermeidung laufender Cloud-Kosten kann die Gesamtausgaben langfristig senken. Organisationen, die mehrere Schulungsdurchgänge oder kontinuierliche Optimierungen planen, finden den Kauf oft wirtschaftlicher als die Miete.
Das Leerlaufproblem
Das Problem ist jedoch: GPUs sind nicht in jedem Moment produktiv, in dem sie eingeschaltet sind. Datenladeengpässe, das Speichern von Checkpoints und Debugging-Pausen erzeugen Leerlaufzeiten, in denen teure Hardware ungenutzt bleibt, aber dennoch Kosten verursacht.
Untersuchungen auf arXiv zu effizienten LLM-Trainingsframeworks ergaben, dass GPUs trotz voller Leistungsaufnahme während des Standard-Pre-Trainings oft nur suboptimal mit 30%- bis 50%-Auslastungsraten arbeiten. Diese Ineffizienz resultiert aus der Interaktion von Transformer-Architekturen mit den Hardware-Kapazitäten.
Es gibt Lösungen. Optimierte Trainingsframeworks können die GPU-Auslastung verbessern, indem sie Datenpipelines optimieren, Berechnungen und Kommunikation überlappen und den Synchronisierungsaufwand minimieren. Diese Verbesserungen beschleunigen nicht nur das Training, sondern reduzieren auch direkt die insgesamt benötigten GPU-Stunden.
| Hardwaretyp | Stündliche Cloud-Kosten | Kaufpreis | Gewinnschwelle |
|---|---|---|---|
| NVIDIA H100 | $2.50-$4.00 | $30,000-$40,000 | 10.000-16.000 Stunden |
| NVIDIA A100 | $1.50-$2.50 | $10,000-$15,000 | 6.000-10.000 Stunden |
| NVIDIA H200 | $3.50-$5.00 | $40,000-$50,000 | 11.000-14.000 Stunden |
Energiekosten: Die wachsende Sorge
Die Stromkosten für die Trainingsläufe sind fast so hoch wie die Hardwarekosten selbst. Frontier-Modelle verbrauchen Gigawattstunden Strom – genug, um Tausende von Haushalten monatelang zu versorgen.
Energieeffizienz hat sich zu einem zentralen Forschungsschwerpunkt entwickelt. Auf arXiv veröffentlichte Arbeiten zur Energieoptimierung in LLM-basierten Anwendungen priorisieren den Energieverbrauch als wichtige Effizienzkennzahl neben traditionellen Leistungsmaßen. Experimente mit NVIDIA RTX 8000-Hardware zeigten, dass optimierte Ansätze eine vergleichbare Genauigkeit wie die Vergleichswerte erreichen und gleichzeitig den Energieverbrauch um 23–501 TP3T senken.
Mal ehrlich: Bei Energiekosten geht es nicht nur um die unmittelbare Stromrechnung. Die Infrastruktur zur Bereitstellung von Gigawattstunden Leistung erfordert Umspannwerke, Kühlsysteme und Notstromaggregate. Rechenzentrumsbetreiber kalkulieren diese Investitionen in ihre Preismodelle ein.
Mit steigendem Schulungsbedarf wird die Strominfrastruktur zu einem Wettbewerbsvorteil. Organisationen mit Zugang zu kostengünstigem und zuverlässigem Strom erzielen erhebliche wirtschaftliche Vorteile im Schulungsbereich.
Training von Grund auf vs. Feinabstimmung
Nicht jedes Projekt erfordert die Entwicklung eines Modells von Grund auf. Die Feinabstimmung vortrainierter Modelle bietet für viele Anwendungen eine kostengünstige Alternative.
Die Kostenstruktur ändert sich dramatisch. Das Feinabstimmen eines Modells wie Llama 2 oder GPT-3.5 auf domänenspezifische Daten kann je nach Datensatzgröße und Rechenaufwand zwischen 1.400.500 und 1.400.000 Tsd. kosten. Das ist 1.000- bis 10.000-mal günstiger als das Training eines vergleichbaren Modells von Grund auf.
Auf arXiv dokumentierte Untersuchungen zu effizienten Strategien zur Verbesserung von LLMs ergaben, dass Feinabstimmungen mit Techniken wie LoRA (Low-Rank Adaptation) auch auf einfacher Hardware möglich sind. In einem Experiment wurde LoRA-Training auf ein vorquantisiertes Modell mit 4 Bit auf einer einzelnen NVIDIA T4 GPU mit 16 GB VRAM angewendet; der Prozess war in 7 Stunden abgeschlossen.
Die Feinabstimmung hat jedoch ihre Grenzen. Vortrainierte Modelle weisen aufgrund ihrer ursprünglichen Trainingsdaten noch immer Verzerrungen und Wissenslücken auf. Durch die Feinabstimmung wird das Modellverhalten zwar an spezifische Aufgaben angepasst, aber das Kernwissen und die Fähigkeiten des Modells bleiben unverändert.
Wann ist ein Training von Grund auf sinnvoll?
Organisationen streben aus verschiedenen Gründen umfassende Schulungen an. Proprietäre Datensätze, die nicht mit externen Modellanbietern geteilt werden dürfen, erfordern interne Schulungen. Spezialisierte Bereiche, in denen bestehende Modelle nur unzureichende Ergebnisse liefern, profitieren von individuell angepassten Architekturen, die von Grund auf mit relevanten Korpora trainiert werden.
Wettbewerbsdifferenzierung ist ein wichtiger Faktor bei manchen Entscheidungen. Unternehmen, die KI-basierte Produkte entwickeln, benötigen Modelle, die Konkurrenten nicht einfach durch Feinabstimmung öffentlich verfügbarer Alternativen nachbilden können.
Die Kontrolle über das Modellverhalten ist wichtig. Das Training von Grund auf ermöglicht die vollständige Transparenz von Datenquellen, Trainingsverfahren und Modelleigenschaften – entscheidend für regulierte Branchen oder sicherheitskritische Anwendungen.


Schätzen Sie Ihre LLM-Ausbildungskosten
Das Training großer Sprachmodelle (LLMs) umfasst Datenaufbereitung, Infrastruktur, Rechenbudgetierung, Experimente und Evaluierung. AI Superior Sie prüfen Ihre Datensätze, Ziele und Leistungsvorgaben, bevor sie den Ressourcen- und Zeitaufwand schätzen. Die Kostenaufstellung umfasst Vorverarbeitung, Trainingszyklen, Feinabstimmung und Validierung. So können Sie Rechenaufwand und Entwicklungsarbeit im Voraus planen.
Sind Sie bereit, Ihre Investition in die LLM-Ausbildung zu berechnen?
Sprechen Sie mit einer KI, die überlegen ist gegenüber:
- Bewerten Sie Ihren Datensatz und Ihre Ziele
- Trainingsstrategie definieren und Bedarf berechnen
- Sie erhalten einen strukturierten Kostenvoranschlag für die LLM-Ausbildung.
👉 Fordern Sie eine Anfrage an Angebot für eine LLM-Ausbildung von AI Superior.
Kostenbeispiele aus der Praxis
Spezifische Modelle liefern konkrete Bezugspunkte zum Verständnis der Ökonomie von Weiterbildungsmaßnahmen.
Laut dem Wall Street Journal und dem Stanford AI Index Report 2025 beliefen sich die geschätzten Trainingskosten für GPT-4 auf 1,78 bis 100 Millionen US-Dollar. Diese Summe umfasst Recheninfrastruktur, Strom, Datenerfassung und technische Ressourcen für den gesamten Trainingszeitraum.
Gemini Ultra 1.0 trieb die Kosten laut Stanford AI Index Report 2025 auf rund 1,4 Billionen US-Dollar in die Höhe. Die gestiegenen Kosten spiegeln einen größeren Umfang, eine längere Trainingsdauer oder umfangreichere Experimente während der Entwicklung wider.
Das Training von GPT-4o dauerte etwa 100 Millionen Runs. Diese Spitzenmodelle aus großen Forschungslaboren weisen ähnliche Kostenstrukturen auf – acht- oder neunstellige Budgets, die hauptsächlich durch GPU-Rechenleistung und Stromverbrauch bestimmt werden.
Kleinere Organisationen stehen vor anderen wirtschaftlichen Herausforderungen. Das Training eines Modells mit 7 Milliarden Parametern kann je nach Hardwareverfügbarkeit und -effizienz zwischen 1,4 T 50.000 und 1,4 T 200.000 kosten. Ein Modell mit 20 Milliarden Parametern könnte zwischen 1,4 T 500.000 und 1,4 T 2 Millionen kosten. Diese Summen sind zwar immer noch beträchtlich, aber für gut finanzierte Startups oder Forschungsteams in großen Unternehmen durchaus realisierbar.
Der Verlauf der Preisinflation
Die Trainingskosten sind exponentiell gestiegen. Der Stanford AI Index Report 2025 dokumentiert einen Anstieg um das 287.000-fache von 2017 bis heute – von $670 für frühe Transformer-Modelle auf neunstellige Beträge für aktuelle Spitzensysteme.
Dieser Trend scheint sich nicht umzukehren. Die Modelle werden immer komplexer hinsichtlich Parameteranzahl, Trainingsdatenvolumen und Architektur. Jede Generation benötigt mehr Rechenleistung als die vorherige.
Allerdings gleichen Effizienzsteigerungen die Skaleneffekte teilweise aus. Bessere Algorithmen, optimierte Hardware und verbesserte Trainingsmethoden ermöglichen eine höhere Leistungsfähigkeit pro investiertem Dollar. Die Kosten pro Einheit Modellleistung sind sogar gesunken, obwohl die absoluten Trainingskosten gestiegen sind.
Strategien zur Senkung der Schulungskosten
Mehrere Ansätze können die Kosten erheblich senken, ohne die Modellqualität proportional zu beeinträchtigen.
Effiziente Trainingsframeworks minimieren den Verbrauch ungenutzter GPU-Zyklen. Techniken wie Gradientenakkumulation, Training mit gemischter Präzision und optimierte Datenladepipelines verbessern die Hardwareauslastung. Analysen von Hochdurchsatz-Trainingssystemen zeigen, dass die Behebung ineffizienter Nutzung von Rechenressourcen während des Transformer-Trainings sowohl die Trainingszeit als auch den Energieverbrauch drastisch reduzieren kann.
Modellkomprimierungstechniken reduzieren den Rechenaufwand. Die Quantisierung stellt Gewichte mit weniger Bits dar, wodurch Speicherbandbreite und Speicherplatzbedarf sinken. Durch das Entfernen weniger wichtiger Verbindungen wird die Modellgröße verringert. Wissensdestillation überträgt Fähigkeiten von großen Modellen effizienter auf kleinere als das Training von Grund auf.
Intelligente Ressourcenzuweisung verhindert Kosten für ungenutzte Hardware. Das automatische Anhalten von GPU-Clustern während der Datenaufbereitungsphasen, die dynamische Anpassung der Infrastruktur an jede Trainingsphase und die Planung von Trainingsläufen außerhalb der Spitzenzeiten der Strompreise tragen alle zu niedrigeren Gesamtkosten bei.
Die Hyperparameteroptimierung reduziert die Anzahl fehlgeschlagener Experimente. Systematische Suchstrategien finden effektive Trainingskonfigurationen schneller als die manuelle Optimierung. Weniger verschwendete Trainingsläufe bedeuten weniger GPU-Stunden, die in Sackgassen investiert werden.
Die Entscheidung zwischen Cloud und On-Premise
Cloud-Infrastruktur bietet Flexibilität und geringe Anfangskosten. Tausende von GPUs können für einen Trainingslauf bereitgestellt und anschließend wieder freigegeben werden. Dieser Ansatz eignet sich gut für Organisationen, die nur gelegentlich Experimente durchführen oder deren langfristiger Rechenbedarf ungewiss ist.
Die Installation eigener Hardware erfordert zwar erhebliche Investitionen, eliminiert aber laufende Mietkosten. Eine Break-Even-Analyse zeigt in der Regel, dass sich der Besitz nach 10.000 bis 16.000 Betriebsstunden bei H100-Chips bzw. nach 6.000 bis 10.000 Betriebsstunden bei A100-Chips amortisiert.
Organisationen, die mehrere große Trainingsläufe, kontinuierliche Feinabstimmungsvorgänge oder langfristige Modellentwicklungspipelines planen, stellen oft fest, dass der Kauf von Hardware trotz höherer Anfangskosten wirtschaftlicher ist.
| Kostenreduzierungsstrategie | Mögliche Einsparungen | Implementierungskomplexität |
|---|---|---|
| Effiziente Trainingsrahmen | 20-40% | Medium |
| Modellquantisierung | 30-50% | Niedrig |
| Intelligente Ressourcenplanung | 15-30% | Medium |
| Feinabstimmung vs. Training von Grund auf | 60-90% | Niedrig (wenn das Basismodell den Anforderungen entspricht) |
| Lokale Hardware (langfristig) | 40-60% | Hoch |
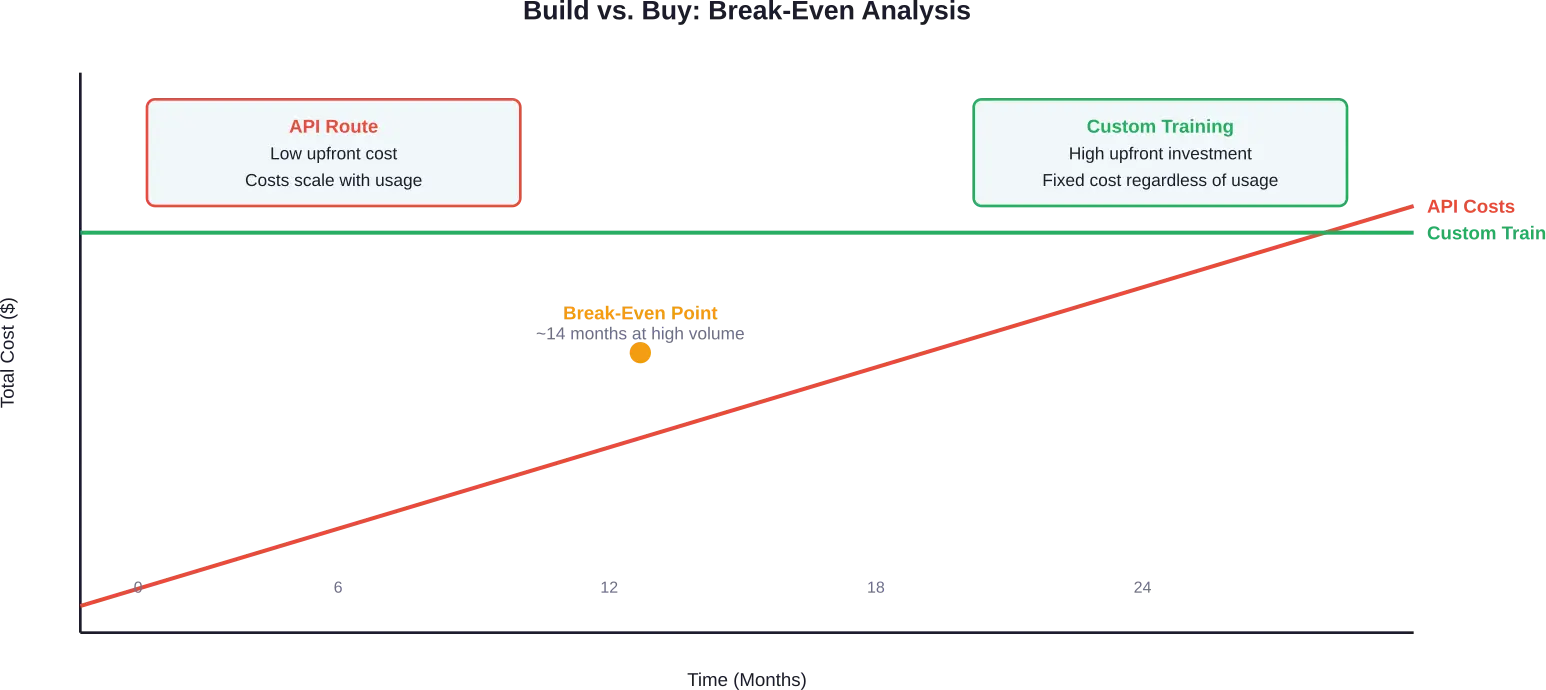
Die Entscheidung zwischen Selberbauen und Kaufen
Viele Organisationen stehen vor einer grundlegenden Frage: ein eigenes Modell entwickeln oder bestehende lizenzieren?
Der API-Zugriff auf Modelle wie GPT-4 beginnt bei einigen Anbietern bei $0,60 pro Million eingegebener Token, wobei die Ausgabepreise je nach Modell variieren. Gemini Flash-Lite bietet laut Preisdaten von 2025 sogar noch günstigere Tarife von $0,075 pro Million eingegebener Token und $0,30 pro Million ausgegebener Token.
Nutzungsbasierte Preisgestaltung erscheint zunächst wirtschaftlich. Die Kosten steigen jedoch linear mit dem Datenverkehr. Anwendungen, die täglich 1,2 Millionen Nachrichten zu je 150 Token verarbeiten, können je nach Preisstufe und Input/Output-Verhältnis monatliche API-Rechnungen von 15.000 bis 60.000 TTP4T verursachen.
Bei hohem Datenaufkommen wird der Betrieb eigener Infrastruktur wirtschaftlicher. Eine Break-Even-Analyse für einen dokumentierten Fall ergab monatliche API-Kosten von $60.000 und einen Trend hin zu über $500.000 jährlich – eine Summe, die erhebliche Vorabinvestitionen in Schulungen rechtfertigt.
Die Entscheidung hängt von Nutzungsmustern, erforderlichen Anpassungen und der Wettbewerbsposition ab. Anwendungen mit vorhersehbar hohem Nutzungsaufkommen, spezialisierten Domänenanforderungen oder dem Bedarf an Modelltransparenz tendieren zu individuellem Training. Projekte mit variabler Nutzung, allgemeinen Funktionen oder engen Entwicklungszeitplänen bevorzugen hingegen den API-Zugriff.
Zukünftige Kostentrends
Die Kosten für Schulungen werden sich mit den Veränderungen der Technologie und der Marktdynamik weiterentwickeln.
Verbesserungen der Hardwareeffizienz senken kontinuierlich die Kosten pro Rechenoperation. Die Architekturgenerationen von NVIDIA weisen durchgängige Leistungssteigerungen pro Watt auf. Der Markteintritt von Wettbewerbern im Bereich der Beschleuniger wird die Optimierung weiter vorantreiben und den Preiswettbewerb verschärfen.
Algorithmische Fortschritte ermöglichen es, mit weniger Rechenaufwand mehr Leistung zu erzielen. Techniken wie Mixture-of-Experts-Architekturen, Mechanismen zur spärlichen Aufmerksamkeitssteuerung und verbesserte Optimierungsalgorithmen reduzieren den Rechenaufwand, der zur Erreichung bestimmter Leistungsziele erforderlich ist.
Die Energiekosten werden voraussichtlich steigen, da die KI-Infrastruktur die Stromnetze stärker belastet. Mit zunehmendem Trainingsbedarf und der steigenden Bedeutung der Strominfrastruktur werden Organisationen mit Zugang zu kostengünstiger erneuerbarer Energie Wettbewerbsvorteile erlangen.
Regulatorischer Druck kann sich auf die Wirtschaftlichkeit von Schulungen auswirken. Regierungen, die sich Sorgen um Energieverbrauch, Datenschutz oder KI-Sicherheit machen, könnten Anforderungen einführen, die die Kosten für die Einhaltung von Vorschriften erhöhen oder bestimmte Praktiken einschränken.
Demokratisierungstendenzen könnten Markteintrittsbarrieren abbauen. Open-Source-Modelle, gemeinsam genutzte Rechenplattformen und eine verbesserte Trainingseffizienz könnten die Entwicklung groß angelegter Modelle auch für mittelständische Unternehmen zugänglich machen, anstatt sie ausschließlich Technologiekonzernen vorzubehalten.
Häufig gestellte Fragen
Wie viel kostet das Training von GPT-4?
Laut dem Wall Street Journal und dem Stanford AI Index Report 2025 belaufen sich die geschätzten Trainingskosten für GPT-4 auf 1,78 bis 100 Millionen US-Dollar. Diese Summe umfasst die GPU-Infrastruktur, den Stromverbrauch, die Datenaufbereitung und die technischen Ressourcen während des mehrmonatigen Trainingszeitraums.
Warum ist die LLM-Ausbildung so teuer?
Die Trainingskosten entstehen hauptsächlich durch die GPU-Recheninfrastruktur, die Ausgaben in Höhe von 60–701 Tsd. Billionen US-Dollar verursacht. Ein Spitzenmodell benötigt unter Umständen 10.000–25.000 High-End-GPUs, die über Wochen oder Monate kontinuierlich laufen. Weitere Kosten entstehen durch den Stromverbrauch (Gigawattstunden), den Aufwand für die Entwickler, die Datenerfassung und -aufbereitung sowie experimentelle Iterationen zur Optimierung der Hyperparameter.
Kann eine Feinabstimmung die Kosten der LLM-Ausbildung senken?
Das Feinabstimmen bestehender Modelle ist typischerweise 60–901 Tsd. weniger wert als das Training von Grund auf. Die Anpassung eines vortrainierten Modells wie Llama 2 oder GPT-3.5 an spezifische Aufgaben kostet etwa 1 Tsd. 5.000–1 Tsd. 50.000, verglichen mit 1 Tsd. 78–192 Millionen für das Training eines Spitzenmodells. Techniken wie LoRa ermöglichen das Feinabstimmen auf einzelnen GPUs und sind innerhalb von Stunden statt Wochen abgeschlossen.
Worin besteht der Unterschied zwischen den Schulungskosten in der Cloud und vor Ort?
Die Cloud-Infrastruktur berechnet $2-4 pro H100-GPU-Stunde ohne Vorabinvestition, jedoch mit laufenden Mietgebühren. Der Kauf der H100-Hardware kostet einmalig $30.000-$40.000 pro Einheit, dafür entfallen die Mietgebühren. Die Gewinnschwelle liegt bei etwa 10.000-16.000 Nutzungsstunden. Organisationen, die mehrere Trainingsdurchgänge planen, finden den Kauf trotz höherer Anfangsinvestitionen oft wirtschaftlicher.
Wie viel Strom verbraucht die Ausbildung eines LLM-Studenten?
Moderne KI-Modelle verbrauchen Gigawattstunden Strom – genug, um Tausende von Haushalten monatelang zu versorgen. Schon bald wird das Training eines einzigen modernen KI-Modells Gigawatt an Leistungskapazität erfordern. Die Stromkosten machen 15 bis 201 Billionen Billionen der gesamten Trainingskosten für große Modelle aus, wobei sowohl die direkten Stromrechnungen als auch die Kosten für die benötigte Infrastruktur die Ausgaben in die Höhe treiben.
Wie lässt sich ein benutzerdefiniertes Sprachmodell am kostengünstigsten trainieren?
Die Feinabstimmung eines bestehenden Open-Source-Modells mithilfe effizienter Techniken wie LoRa bietet den kostengünstigsten Einstieg. Studien belegen, dass ein LoRa-Trainingsexperiment auf einer einzelnen NVIDIA T4 GPU mit 16 GB VRAM – einer Hardware, die auf Plattformen wie Google Colab verfügbar ist – in nur 7 Stunden abgeschlossen werden konnte. Für Anwendungen, bei denen die Feinabstimmung ausreichend ist, reduziert dieser Ansatz die Kosten im Vergleich zum Training von Grund auf um das 1.000- bis 10.000-Fache.
Steigen die Ausbildungskosten immer noch?
Die absoluten Trainingskosten für hochmoderne Modelle steigen mit zunehmender Parameteranzahl und Datensatzgröße weiter an. Der Stanford AI Index Report 2025 dokumentiert einen Anstieg um das 287.000-fache von 2017 bis heute. Gleichzeitig sinken die Kosten pro Modellleistungseinheit aufgrund von Hardwareverbesserungen und algorithmischen Fortschritten. Effizienzgewinne gleichen die Kostensteigerungen teilweise aus, obwohl die Gesamtbudgets für hochmoderne Modelle weiter steigen.
Die Investition verstehen
Die Kosten für eine LLM-Ausbildung spiegeln den hohen Rechenaufwand wider, der für die Entwicklung von Systemen zur Verarbeitung und Generierung menschlicher Sprache in großem Umfang erforderlich ist. Diese acht- und neunstelligen Beträge sind nicht willkürlich – sie repräsentieren Tausende von spezialisierten Prozessoren, die kontinuierlich laufen, Megawatt an Strom verbrauchen und von Teams spezialisierter Ingenieure gesteuert werden, die mit riesigen Datensätzen arbeiten.
Die wirtschaftlichen Rahmenbedingungen werden sich weiterentwickeln. Hardware wird effizienter. Algorithmen werden verbessert. Wettbewerb treibt Innovationen voran. Doch der grundlegende Zielkonflikt bleibt bestehen: Leistungsfähigkeit erfordert Rechenleistung, und Rechenleistung kostet Geld.
Organisationen, die die Entwicklung eigener Modelle erwägen, benötigen realistische Kostenprognosen, keine unrealistischen Schätzungen. Teams, die Finanzmittel einwerben, müssen alle Ausgabenkategorien berücksichtigen, nicht nur die offensichtlichen Kosten für die GPU-Miete. Und Branchenbeobachter, die die KI-Entwicklung verfolgen, sollten verstehen, dass die Trainingskosten ein nützlicher Indikator für die Größe und Leistungsfähigkeit eines Modells sind.
Der weitere Weg hängt von den jeweiligen Anforderungen ab. Anwendungen mit hohem Datenaufkommen und speziellen Anforderungen rechtfertigen oft individuelle Schulungen trotz erheblicher Vorabinvestitionen. Bei Projekten mit geringerem Datenaufkommen oder allgemeinen Anwendungsfällen ist der API-Zugriff wirtschaftlicher. Viele Anwendungsfälle liegen irgendwo dazwischen, wo eine Feinabstimmung das richtige Gleichgewicht zwischen Anpassung und Kosteneffizienz bietet.
Sind Sie bereit, mit der Modellentwicklung fortzufahren? Beginnen Sie mit der Berechnung Ihrer spezifischen Nutzungsmuster, identifizieren Sie, welche Funktionen ein individuelles Training bzw. eine Feinabstimmung erfordern, und führen Sie eine Break-Even-Analyse für Ihren geplanten Einsatzumfang durch. Die Daten zeigen Ihnen, welcher Weg für Ihre Situation am sinnvollsten ist.