Resumen rápido: El aprendizaje profundo es un subconjunto especializado del aprendizaje automático que utiliza redes neuronales multicapa para aprender automáticamente patrones complejos a partir de datos sin procesar. El aprendizaje automático es un campo más amplio de la IA que incluye el aprendizaje profundo, además de algoritmos tradicionales que requieren la ingeniería manual de características. La diferencia clave radica en que el aprendizaje automático requiere la ingeniería manual de características y funciona bien con conjuntos de datos pequeños, mientras que el aprendizaje profundo extrae características automáticamente, pero exige grandes cantidades de datos y potencia computacional.
En el ámbito tecnológico, los términos aprendizaje automático y aprendizaje profundo se usan indistintamente. Pero la verdad es que no son lo mismo, y comprender la diferencia es fundamental tanto si se desarrollan sistemas de IA como si simplemente se intenta entender qué impulsa la tecnología moderna.
Ambas se engloban dentro de la inteligencia artificial. Ambas aprenden de los datos. Sin embargo, la forma en que abordan los problemas, gestionan la información y ofrecen resultados difiere fundamentalmente.
Según Stanford HAI, el aprendizaje profundo es un subconjunto del aprendizaje automático que utiliza grandes redes neuronales multicapa para aprender automáticamente patrones complejos a partir de datos. En lugar de que una persona programe manualmente las características que se deben buscar, estos modelos descubren representaciones cada vez más abstractas por sí mismos.
¿Te suena familiar? Eso se debe a que el aprendizaje profundo impulsa el asistente de voz de tu teléfono, el motor de recomendaciones de las plataformas de streaming y los modelos de lenguaje que están transformando nuestra forma de trabajar.
¿Qué es el aprendizaje automático?
El aprendizaje automático es una metodología dentro de la inteligencia artificial donde los sistemas aprenden de los datos sin ser programados explícitamente para cada escenario. En lugar de escribir reglas para cada posible entrada, los desarrolladores entrenan modelos para reconocer patrones y hacer predicciones basadas en ejemplos.
Este enfoque se basa en algoritmos que mejoran con la experiencia. Si se alimenta un modelo de aprendizaje automático con suficientes datos etiquetados (por ejemplo, correos electrónicos marcados como spam o no spam), este aprende a clasificar nuevos correos electrónicos por sí solo.
Pero hay un inconveniente. El aprendizaje automático tradicional requiere ingeniería de características: el proceso mediante el cual los humanos seleccionan y diseñan manualmente las características de los datos que el modelo debe analizar. En el caso del reconocimiento de imágenes, esto podría significar programar el sistema para que busque bordes, esquinas o patrones de color específicos.
Esta intervención humana moldea lo que aprende el modelo. Si se eligen las características incorrectas, el rendimiento se resiente. Si se eligen bien, incluso los algoritmos relativamente sencillos pueden ofrecer resultados sólidos con datos estructurados.
Tipos de aprendizaje automático
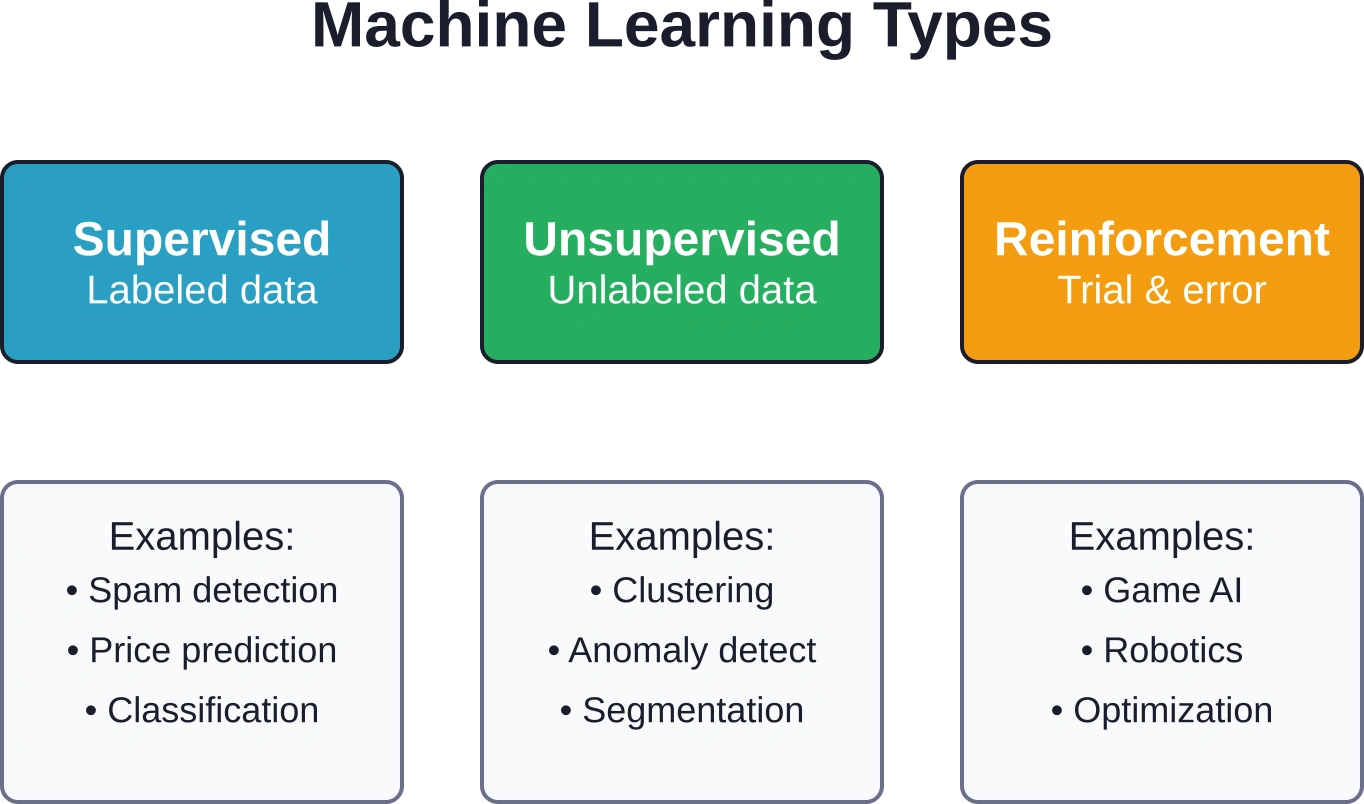
El aprendizaje automático se divide en tres categorías principales según cómo aprende el algoritmo:
- El aprendizaje supervisado se entrena con datos etiquetados donde se conoce la respuesta correcta. El modelo aprende a relacionar las entradas con las salidas, como predecir los precios de las viviendas en función de la superficie, la ubicación y la antigüedad. La mayoría de las aplicaciones empresariales se incluyen en esta categoría.
- El aprendizaje no supervisado trabaja con datos sin etiquetar, encontrando patrones ocultos sin categorías predefinidas. La agrupación de clientes según su comportamiento de compra o la detección de anomalías en el tráfico de red son ejemplos de este enfoque.
- El aprendizaje por refuerzo se basa en el método de ensayo y error, recibiendo recompensas o penalizaciones según las acciones realizadas. La IA aplicada a los juegos y la robótica suelen utilizar este método, aunque es menos común en los entornos empresariales tradicionales.
¿Qué es el aprendizaje profundo?
El aprendizaje profundo lleva el aprendizaje automático un paso más allá mediante el uso de redes neuronales con múltiples capas, de ahí el término "profundo". Estas redes constan de nodos interconectados (neuronas) organizados en capas que procesan datos secuencialmente, y cada capa extrae características cada vez más complejas.
La arquitectura refleja cómo los investigadores entienden que el cerebro humano procesa la información, aunque la analogía biológica tiene sus limitaciones. Lo que importa en la práctica es que los modelos de aprendizaje profundo pueden descubrir automáticamente las representaciones necesarias para la detección de características a partir de datos sin procesar.
No se requiere ingeniería de características manual. Basta con alimentar un sistema de aprendizaje profundo con imágenes sin procesar, y este aprende por sí solo a reconocer bordes en las primeras capas, formas en las capas intermedias y objetos completos en las capas más profundas.
Este aprendizaje automático de características hace que el aprendizaje profundo sea especialmente potente para datos no estructurados: imágenes, audio, texto y vídeo. Tareas que durante décadas habían resultado imposibles para el aprendizaje automático tradicional se volvieron repentinamente manejables.
Explicación de las redes neuronales
En el núcleo del aprendizaje profundo se encuentra la red neuronal. Imagínela como una serie de capas de procesamiento, cada una con múltiples nodos que realizan operaciones matemáticas sobre los datos entrantes.
La información fluye hacia adelante a través de la red. Cada conexión entre nodos tiene un peso que se ajusta durante el entrenamiento. La red aprende modificando estos pesos para minimizar los errores de predicción, un proceso llamado retropropagación.
Las redes neuronales superficiales pueden tener una o dos capas ocultas entre la entrada y la salida. Las redes profundas apilan docenas o incluso cientos de capas, lo que les permite modelar relaciones extremadamente complejas.
La profundidad tiene un precio: la intensidad computacional. Entrenar redes neuronales profundas requiere una potencia de procesamiento considerable, razón por la cual este campo experimentó un auge sin precedentes junto con los avances en la computación mediante GPU.
Diferencias clave entre el aprendizaje automático y el aprendizaje profundo.
Ahora bien, aquí es donde la cosa se pone interesante. Si bien el aprendizaje profundo se engloba dentro del aprendizaje automático, en la práctica existen varias diferencias fundamentales que los distinguen.
Requisitos de datos
Los algoritmos tradicionales de aprendizaje automático pueden funcionar bien con conjuntos de datos pequeños, a veces de tan solo miles de ejemplos. Los métodos estadísticos como los árboles de decisión, los bosques aleatorios o las máquinas de vectores de soporte extraen patrones significativos de datos limitados.
El aprendizaje profundo requiere gran cantidad de datos. Las redes neuronales contienen millones de parámetros que necesitan ajustarse, lo que exige conjuntos de datos masivos para un entrenamiento eficaz. Si se alimenta un modelo de aprendizaje profundo con muy pocos datos, se produce un sobreajuste: memoriza los ejemplos de entrenamiento en lugar de aprender patrones generalizables.
Los informes del sector sugieren que el aprendizaje profundo normalmente necesita entre decenas de miles y millones de ejemplos etiquetados para alcanzar su máximo rendimiento, aunque las técnicas de aprendizaje por transferencia pueden reducir este requisito.
Ingeniería de características
Aquí es donde la carga de trabajo cambia drásticamente. Los profesionales del aprendizaje automático dedican mucho tiempo a la ingeniería de características: seleccionar, transformar y crear las variables de entrada que utilizarán sus modelos.
¿Dispones de datos de clientes? Los desarrolladores podrían crear funciones como "días desde la última compra", "valor medio del pedido" o "frecuencia de compra" antes de que comience el entrenamiento. Este conocimiento del dominio influye en el rendimiento del modelo.
El aprendizaje profundo automatiza este proceso. Las capas de la red neuronal aprenden características de forma jerárquica durante el entrenamiento. Esto reduce el esfuerzo humano, pero también implica una desventaja: menor control sobre lo que el modelo aprende realmente.
Recursos computacionales
¿Ejecutar un modelo de aprendizaje automático en tu portátil? Por supuesto. Muchos algoritmos tradicionales se entrenan rápidamente en hardware estándar, lo que los hace accesibles y prácticos para escenarios con recursos limitados.
Los modelos de aprendizaje profundo son máquinas computacionales. Entrenar redes de última generación requiere hardware especializado (GPU o TPU) y puede llevar días o semanas incluso en sistemas potentes. Los costes operativos aumentan en consecuencia.
La inferencia (mediante un modelo entrenado) también difiere. Los modelos de aprendizaje automático suelen ofrecer predicciones en milisegundos en hardware básico. Los modelos de aprendizaje profundo de gran tamaño pueden requerir infraestructura dedicada para cumplir con los requisitos de latencia en tiempo real.
Interpretabilidad
Los modelos de aprendizaje automático, especialmente los más sencillos como los árboles de decisión o la regresión lineal, ofrecen transparencia. Los desarrolladores pueden rastrear con precisión por qué un modelo realizó una predicción específica, lo cual es fundamental en industrias reguladas o en decisiones de gran importancia.
El aprendizaje profundo funciona como una caja negra. Con millones de pesos distribuidos en docenas de capas, comprender por qué una red neuronal tomó una decisión en particular se vuelve prácticamente imposible. La investigación sobre IA explicable intenta abordar este problema, pero la interpretabilidad sigue siendo un desafío constante.
Una investigación del MIT de diciembre de 2021 puso de manifiesto una preocupación: las redes neuronales entrenadas con conjuntos de datos como CIFAR-10 realizaban predicciones fiables incluso cuando faltaba el 95 % de las imágenes de entrada, siendo el resto incomprensible para los humanos. Esta sobreinterpretación plantea dudas sobre la fiabilidad en aplicaciones críticas.
Compromisos de rendimiento
Para datos estructurados y tabulares (como hojas de cálculo con filas y columnas), el aprendizaje automático tradicional suele ser superior. Los árboles de decisión, el aumento de gradiente y métodos similares a menudo superan a las redes neuronales en estas tareas, con un entrenamiento más rápido y requiriendo menos datos.
El aprendizaje profundo domina el procesamiento de datos no estructurados. El reconocimiento de imágenes, el procesamiento del lenguaje natural y el reconocimiento de voz experimentaron mejoras revolucionarias una vez que el aprendizaje profundo maduró. Las investigaciones indican que el aprendizaje profundo puede lograr una mayor precisión en tareas de procesamiento de imágenes en comparación con el aprendizaje automático tradicional, y algunos estudios muestran diferencias de rendimiento en este rango.
La brecha se amplía a medida que aumenta la complejidad de la tarea. La clasificación simple podría favorecer los enfoques tradicionales. El reconocimiento de patrones complejos en datos de alta dimensión se inclina hacia el aprendizaje profundo.

Elija el enfoque de IA adecuado con IA superior
La cuestión de si elegir aprendizaje profundo o aprendizaje automático no es solo técnica. Afecta a las necesidades de datos, el tiempo de desarrollo, la complejidad del modelo y cómo se utilizará la solución en la práctica. IA superior Ayudamos a las empresas a comparar diferentes enfoques de IA mediante consultoría, aprendizaje automático, aprendizaje profundo, análisis predictivo, procesamiento del lenguaje natural (PLN), visión artificial y desarrollo de software de IA a medida. Antes de la implementación, su equipo puede revisar el caso de uso, los datos disponibles y los resultados esperados. Esto permite a las empresas evitar elegir un modelo más complejo de lo necesario, a la vez que les deja margen para una IA más avanzada cuando el problema lo requiera.
AI Superior puede ayudar a evaluar:
- Ya sea aprendizaje automático o aprendizaje profundo, la tarea es la más adecuada.
- Requisitos de datos para diferentes tipos de modelos
- Casos de uso y opciones de modelos de análisis predictivo
- Aplicaciones de aprendizaje profundo en flujos de trabajo de visión o lenguaje.
- Integración de modelos de IA seleccionados en software personalizado
👉Contacta con IA Superior para analizar qué enfoque de IA se ajusta mejor a los requisitos de su proyecto, datos o producto.
Aplicaciones prácticas y casos de uso
En realidad, elegir entre aprendizaje automático y aprendizaje profundo no se trata de cuál es "mejor", sino de encontrar la herramienta adecuada para el problema.
Cuando el aprendizaje automático brilla
Los problemas con datos estructurados se benefician del aprendizaje automático tradicional. Predecir la deserción de clientes, detectar el fraude con tarjetas de crédito, pronosticar las ventas o recomendar productos basándose en el historial de compras: estos escenarios suelen implicar datos tabulares donde las relaciones son relativamente directas.
Los escenarios con datos limitados también apuntan hacia el aprendizaje automático. ¿Entrenar un modelo con solo unos cientos de ejemplos? El aprendizaje profundo tendrá dificultades. Algoritmos como los bosques aleatorios o el aumento de gradiente pueden extraer patrones significativos de conjuntos de datos más pequeños.
¿Necesitas interpretabilidad? El aprendizaje automático la proporciona. Las instituciones financieras utilizan árboles de decisión para la aprobación de préstamos porque los reguladores exigen explicaciones para las decisiones crediticias. El diagnóstico médico se beneficia de manera similar: los médicos quieren comprender por qué un modelo identificó un riesgo en particular.
Cuando el aprendizaje profundo domina
El reconocimiento de imágenes se transformó una vez que el aprendizaje profundo maduró. El reconocimiento facial, el análisis de imágenes médicas, los sistemas de visión para vehículos autónomos y el control de calidad en la fabricación: las redes neuronales convolucionales revolucionaron estos campos.
El procesamiento del lenguaje natural experimentó avances similares. La traducción automática, el análisis de sentimientos, los chatbots y el resumen de documentos mejoraron drásticamente con arquitecturas de aprendizaje profundo como Transformers. Los modelos de lenguaje que transformarán las comunicaciones empresariales en 2026 se basan completamente en redes neuronales profundas.
El reconocimiento de voz, que antes era frustrantemente impreciso, se volvió fiable gracias al aprendizaje profundo. Los asistentes de voz, los servicios de transcripción y las herramientas de accesibilidad utilizan redes recurrentes o convolucionales entrenadas con enormes conjuntos de datos de audio.
El análisis de vídeo, la detección de anomalías en sistemas complejos y la IA generativa (que crea nuevas imágenes, texto o audio) dependen de la capacidad del aprendizaje profundo para modelar patrones intrincados en datos de alta dimensión.
Cómo elegir el enfoque adecuado
Entonces, ¿cómo deciden los profesionales? Varios factores guían la elección:
- El volumen de datos es lo más importante: ¿Tienes millones de ejemplos? El aprendizaje profundo se vuelve viable. ¿Trabajas con cientos o miles? Mejor sigue con el aprendizaje automático tradicional.
- El tipo de datos influye en la decisión: Los datos estructurados y tabulares se inclinan hacia el aprendizaje automático. Las imágenes, el texto, el audio o el vídeo apuntan al aprendizaje profundo.
- Las limitaciones de recursos no pueden ignorarse: El presupuesto limitado y la escasa capacidad de procesamiento favorecen la eficiencia del aprendizaje automático. El acceso a las GPU y el tiempo para un entrenamiento prolongado abren nuevas posibilidades para el aprendizaje profundo.
- Los requisitos de precisión frente a la interpretabilidad generan tensión: ¿Necesitas la máxima precisión posible en una tarea compleja? El aprendizaje profundo podría compensar la opacidad. ¿Requieres transparencia y explicabilidad? Los modelos más sencillos del aprendizaje automático ofrecen claridad.
- La disponibilidad de conocimientos especializados en el dominio influye en la viabilidad de la ingeniería de características: Los expertos en la materia pueden diseñar características eficaces para el aprendizaje automático. La falta de conocimiento del dominio tiende a favorecer que el aprendizaje profundo descubra las características automáticamente.
| Consideración | Aprendizaje automático | Aprendizaje profundo |
|---|---|---|
| Tamaño del conjunto de datos | Cientos a miles | De miles a millones |
| Tipo de datos | Estructurado/tabular | Sin estructura (imagen/texto/audio) |
| Tiempo de entrenamiento | De minutos a horas | De horas a semanas |
| Necesidades de hardware | CPU estándar | Se prefiere GPU/TPU |
| Ingeniería de características | Manual, orientado al dominio | Automático, aprendido |
| Interpretabilidad | Alto (especialmente modelos sencillos) | Bajo (caja negra) |
La relación con la inteligencia artificial
Tanto el aprendizaje automático como el aprendizaje profundo se enmarcan dentro del ámbito más amplio de la inteligencia artificial. La IA abarca cualquier técnica que permita a las computadoras imitar la inteligencia humana, incluidos los sistemas basados en reglas que no aprenden en absoluto.
El aprendizaje automático representa un subconjunto de la IA centrado en aprender a partir de datos. El aprendizaje profundo se especializa aún más como un subconjunto del aprendizaje automático que utiliza redes neuronales con múltiples capas.
La jerarquía se ve así: la IA contiene el aprendizaje automático, que a su vez contiene el aprendizaje profundo. Todo aprendizaje profundo es aprendizaje automático, pero no todo aprendizaje automático es aprendizaje profundo. Todo aprendizaje automático es IA, pero no toda IA es aprendizaje automático.
Según una investigación de MIT Sloan, aproximadamente 351.000 millones de empresas a nivel mundial utilizaban IA en encuestas recientes, y otras 421.000 millones estaban explorando esta tecnología. El desarrollo de la IA generativa, que utiliza potentes modelos de aprendizaje profundo, aceleró su adopción desde 2022.
Pero un momento. Esto no significa que el aprendizaje profundo haya reemplazado al aprendizaje automático. Las distintas herramientas cumplen distintas funciones. Muchos sistemas de producción combinan ambos enfoques, utilizando el aprendizaje automático tradicional para el procesamiento de datos estructurados y aplicando el aprendizaje profundo a entradas no estructuradas.
Tendencias actuales y direcciones futuras
El campo sigue evolucionando. El aprendizaje por transferencia reduce la necesidad de datos del aprendizaje profundo al partir de modelos preentrenados y ajustarlos para tareas específicas, a veces requiriendo solo cientos de ejemplos en lugar de millones.
Las técnicas de compresión de modelos hacen que el aprendizaje profundo sea más accesible, reduciendo el tamaño de las redes para que se ejecuten en dispositivos móviles o hardware de computación perimetral sin una sobrecarga computacional masiva.
Las plataformas AutoML automatizan la selección de modelos y el ajuste de hiperparámetros tanto para el aprendizaje automático como para el aprendizaje profundo, lo que reduce la barrera de conocimientos técnicos para su implementación.
Los enfoques híbridos combinan la interpretabilidad del aprendizaje automático tradicional con la capacidad de reconocimiento de patrones del aprendizaje profundo. Los investigadores exploran redes neuronales que pueden explicar sus decisiones o incorporar conocimiento del dominio a través de arquitecturas estructuradas.
La IA generativa —la tecnología que impulsa herramientas como ChatGPT— representa la última frontera del aprendizaje profundo, ya que crea contenido completamente nuevo en lugar de simplemente clasificar o predecir. Este subconjunto utiliza arquitecturas de transformadores y conjuntos de datos masivos para generar texto, imágenes, código y mucho más.
Preguntas frecuentes
¿Es el aprendizaje profundo mejor que el aprendizaje automático?
Ninguno es universalmente mejor; destacan en tareas diferentes. El aprendizaje profundo ofrece mejores resultados con datos complejos no estructurados, como imágenes y texto, cuando se dispone de grandes conjuntos de datos. El aprendizaje automático tradicional suele ser superior con datos estructurados, conjuntos de datos más pequeños y en escenarios que requieren interpretabilidad o recursos computacionales limitados.
¿El aprendizaje profundo requiere conocimientos de programación?
Crear modelos de aprendizaje profundo desde cero requiere conocimientos de programación, generalmente en Python con frameworks como TensorFlow o PyTorch. Sin embargo, ahora existen plataformas sin código y con poco código que permiten entrenar e implementar modelos mediante interfaces visuales, lo que hace que el aprendizaje profundo sea más accesible para quienes no son programadores.
¿Cuántos datos necesita el aprendizaje profundo en comparación con el aprendizaje automático?
El aprendizaje automático tradicional puede funcionar eficazmente con cientos o miles de ejemplos de entrenamiento. El aprendizaje profundo, en cambio, suele requerir al menos decenas de miles de ejemplos, y los modelos más avanzados a menudo se entrenan con millones o miles de millones de puntos de datos. Las técnicas de aprendizaje por transferencia pueden reducir significativamente estos requisitos.
¿Pueden el aprendizaje automático y el aprendizaje profundo trabajar juntos?
Por supuesto. Muchos sistemas de producción combinan ambos enfoques de forma complementaria. Los equipos pueden usar el aprendizaje automático tradicional para las características de los datos estructurados, mientras aplican el aprendizaje profundo para procesar imágenes o texto, y luego combinar las predicciones de ambos modelos para tomar decisiones finales.
¿Qué debería aprender primero como principiante?
Comenzar con el aprendizaje automático tradicional proporciona una base más sólida. Los conceptos matemáticos, los métodos de evaluación y los principios de flujo de trabajo se aplican a ambos campos. Una vez que se dominan los fundamentos del aprendizaje automático, la transición al aprendizaje profundo resulta más intuitiva, ya que se basa en las mismas ideas centrales.
¿Las redes neuronales siempre superan a los algoritmos tradicionales?
En absoluto. En datos tabulares estructurados, algoritmos como el gradient boosting o los bosques aleatorios suelen igualar o superar el rendimiento de las redes neuronales, a la vez que se entrenan más rápido y requieren menos datos. Las redes neuronales demuestran su eficacia en datos no estructurados, donde los métodos tradicionales presentan dificultades.
¿Cuánto tiempo se tarda en entrenar un modelo de aprendizaje profundo?
El tiempo de entrenamiento varía enormemente según el tamaño del modelo, el tamaño del conjunto de datos y el hardware. Las redes simples pueden entrenarse en minutos en una computadora portátil. Los modelos de lenguaje complejos o los sistemas de visión artificial pueden requerir días o semanas en clústeres de GPU especializados. Los modelos de aprendizaje automático tradicionales suelen entrenarse mucho más rápido, a menudo en minutos u horas.
Avanzando
Comprender la diferencia entre aprendizaje automático y aprendizaje profundo permite discernir qué enfoque se ajusta mejor a cada problema. El aprendizaje automático ofrece versatilidad, eficiencia e interpretabilidad para datos estructurados y escenarios con recursos limitados. El aprendizaje profundo, por su parte, permite un rendimiento sin precedentes en datos complejos no estructurados cuando se dispone de recursos computacionales y grandes conjuntos de datos.
La elección no se trata de seguir tendencias, sino de adecuar las capacidades a los requisitos. Algunos equipos se lanzan al aprendizaje profundo porque es de vanguardia, para luego descubrir que el aprendizaje automático tradicional habría ofrecido mejores resultados con mayor rapidez. Otros se aferran a métodos conocidos cuando el aprendizaje profundo podría resolver problemas que antes eran irresolubles.
Ambos campos siguen avanzando rápidamente. Mantenerse informado sobre sus fortalezas relativas ayuda a desarrolladores, científicos de datos y líderes empresariales a tomar decisiones tecnológicas más acertadas.
¿Listo para aplicar estos conceptos? Empiece por analizar su caso de uso específico: tipo de datos, volumen, requisitos de precisión y limitaciones de recursos. La herramienta adecuada se hace evidente una vez que comprende lo que cada enfoque ofrece realmente.